
面向雷达信号处理应用的可重构处理器设计
2016-09-13 01:48何国强李世平
现代雷达 2016年8期
何国强,李 丽,李世平
(1. 南京电子技术研究所, 南京 210039; 2. 南京大学 电子科学与工程学院, 南京 210046)
·信号处理·
面向雷达信号处理应用的可重构处理器设计
何国强1,李丽2,李世平1
(1. 南京电子技术研究所,南京 210039;2. 南京大学 电子科学与工程学院,南京 210046)
为满足现代雷达的高性能应用需求,文中提出并设计了一种可重构专用处理(RASP)架构。其采用非规则化微结构和混合重构策略,有效提升了并行流水计算的性能;通过兵乓处理机制掩盖DDR读写时间,充分发挥了运算资源的效率。RASP作为硬件加速核嵌入华睿2号DSP芯片并于TSMC 40 nm工艺下完成流片。测试结果显示,RASP完成1 K(1 024)点FFT的运算时间为2.57 μs,处理效率高达42%,相比于NoC、MorphoSys、C6678、T4240等处理器,性能提升至1.9~30倍,效率达到1.25~4倍。
可重构处理器;快速傅里叶变换;矩阵求逆;脉压;空时自适应处理
0 引 言
随着雷达向数字阵、多功能、智能化方向发展[1-2],对雷达信号处理的运算性能提出了越来越高的需求,通用DSP性能已显不足,专用ASIC或FPGA则灵活性差,且研制周期长、成本高,不能满足多变的应用需求[3-4]。因此,有必要在性能、功耗和功能灵活性等关键指标之间寻找更好的平衡。
自20世纪60年代加州大学洛杉矶分校的Gerald Estrin教授[5]首次提出可重构计算概念以来,通信、多媒体、雷达等多个领域的科学工作者开展了大量的可重构处理器的研究,如:MIT的MATRIX[6]、IMEC的ADRES[7]、PACT公司的XPP[8]、雷声公司的Mornarch[9]、国防科技大学的ASRA[10]等,至今仍然是高效能计算的研究热点。可重构计算是一种由配置流和数据流来共同驱动的计算方式,即在运行时通过配置流动态改变运算单元阵列结构,并由数据流驱动运算单元阵列进行计算。因此,可以同时获得较高的能效和灵活性[11-12],是雷达信号处理高性能处理器的实现途径之一。
本文面向雷达信号处理应用,提出并设计了一种可重构专用处理架构(RASP),主要包括6个可重构处理单元和32个存储单元,通过混合重构策略和乒乓处理机制,可以高效实现FFT、矩阵求逆、FIR等基本算子的硬件加速,进而由基本算子组合实现数字脉压、STAP等雷达信号处理功能。实测结果显示:与同类型可重构处理器相比,RASP处理性能及效率均有着显著优势。
1 RASP架构
1.1架构简述
RASP核的架构如图1所示。其主体结构包括主控制单元、可配置上下文存储单元、可重构计算阵列、存储阵列、DMA控制器和AXI总线。
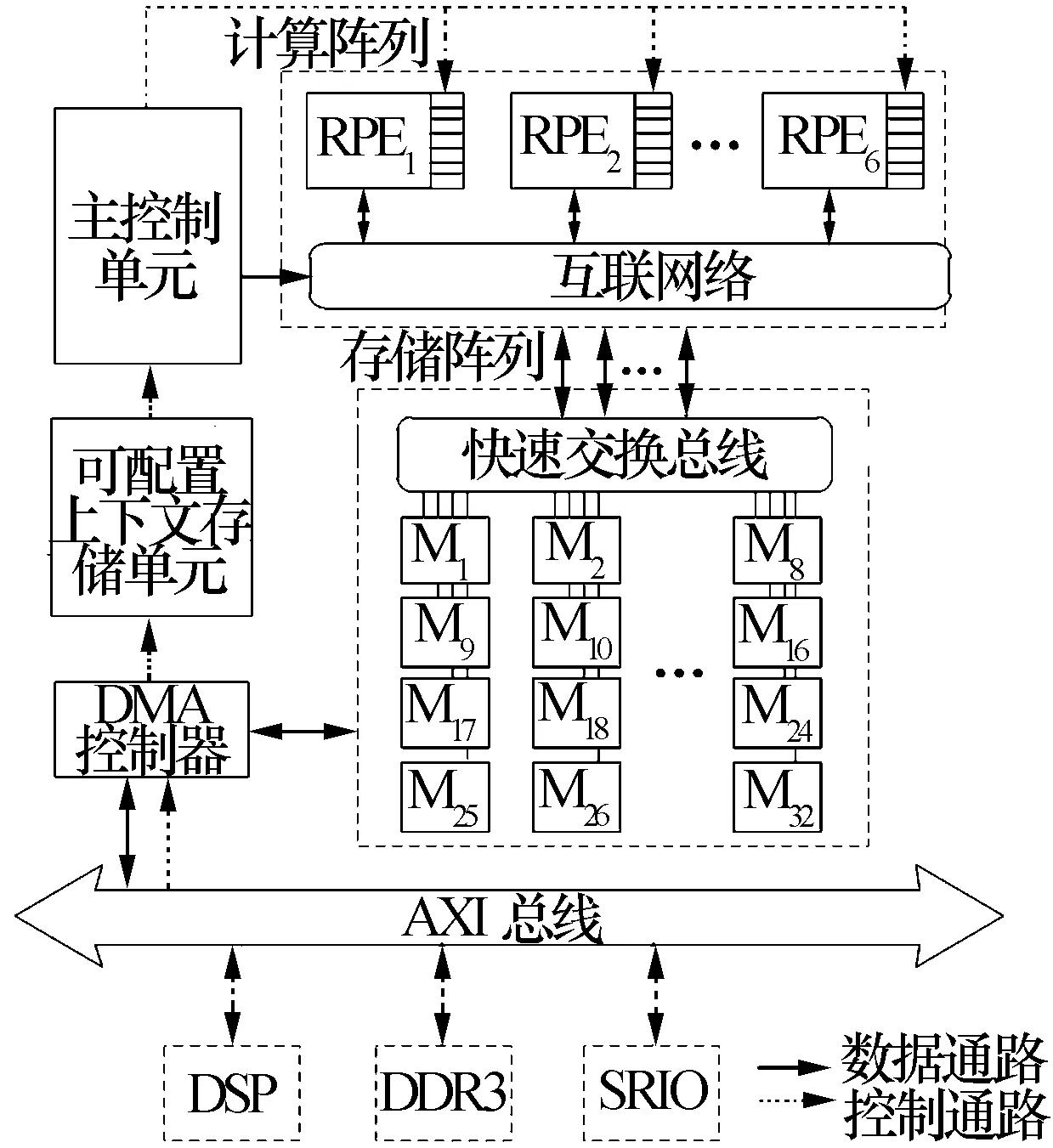
图1 RASP架构图
可重构计算阵列由6路可重构处理单元(RPE)和互联网络组成,通过对RPE内部、RPE间的互连方式的配置,可以构造出不同类型的计算部件,如:蝶形运算、向量复乘、向量乘累加等,进而实现FFT、FIR、矩阵乘、矩阵求逆等多种基本算子。
存储阵列中包含32个64 KB的数据存储单元,提供了32组读写端口,最高可并行读写32个浮点复数,总容量2 MB。快速交换总线用于完成32组读写端口与32个数据存储块之间的数据交换,使得RPE可以访问到任意一个存储单元。
上下文存储单元存储用于实现信号处理功能的基本算子指令组合,组合可以是同类型指令,如:N条1K点FFT,也可以是不同类型指令,如:向量乘、FFT、IFFT等。这些指令组合可通过DMA导入。
主控制单元用于完成核内各模块的调度控制,其先从上下文存储单元中读取待执行的基本算子指令,然后根据指令类型对各个RPE内部及其之间的互连结构进行相应配置,再通知DMA从外部DDR中导入(或直接从存储阵列中读入)源数据并启动指令运算,运算结果可缓存在存储阵列中用作下一条指令的源数据,也可通过DMA输出到外部DDR中。多条指令之间顺序执行,部分指令还支持乒乓处理机制,即当前指令的源数据导入与上一条指令的运算并行执行,可有效掩盖数据传输的时间,提升运算效能。
1.2RPE微结构
RASP的6个RPE中,RPE1~RPE4主要用于进行复数乘、加运算,RPE5用于实现除法及定浮转换,RPE6则为矩阵求逆预留扩展单元,内含2个实数乘法器、1个实数加法器、2个浮点除法器和1个复数乘法器,主要用于完成LU分解。
为了充分发掘FFT、矩阵乘等常用雷达信号处理算法的性能,RPE1~RPE4采用了如图2所示的非规则化微结构,共包括1个复数乘法器、4个复数加法器和1个实数乘法器。不同于传统规则化微结构所需要的复杂的流水线配置和任务编译技术,非规则化微结构仅面向雷达信号处理所需的有限个计算部件,能够充分发挥各个运算资源的效率,从而更加有效地提升并行流水计算性能,尽管牺牲了一定的灵活性,但获得了显著的性能提升。
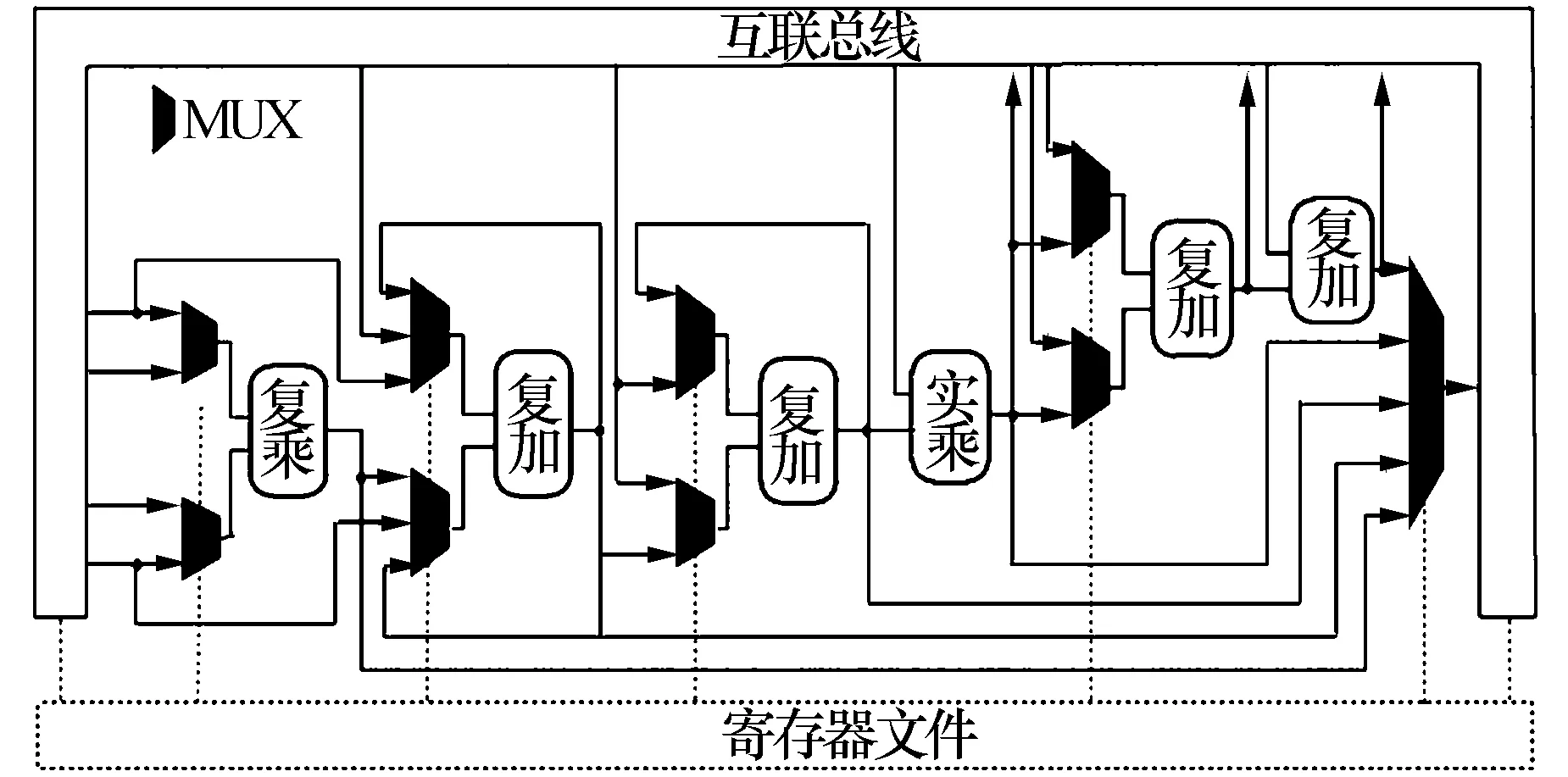
图2 RPE微结构图
RASP是通过控制MUX和互连方式来实施重构的,所有MUX的控制值以及互连网络互连方式控制值均存在在寄存器文件中,寄存器文件则由主控制器读取基本算子指令后根据算法类型更新。
1.3重构策略
RASP采用了RPE内及RPE间的混合重构策略,每个RPE可以独立重构成复乘、复加、乘累加等基本计算部件,从而支持4路并行计算,同时,RPE之间还可通过互连网络通信,进一步重构成FFT用混合基蝶形单元、相关用含除法向量乘累加等扩展计算部件,兼顾了运算并行度和流水性能,有效提高了FFT、相关等常用基本算子的性能。
1.4兵乓处理机制
可重构处理器进行运算时,通常会先从DDR中读取源数据,然后进行运算,运算结果再写回DDR。随着计算资源的增大,并行度逐渐增高,当数据长度较小时,受DDR带宽限制,读写DDR所消耗的时间将上升到与运算时间可比拟的程度。以2 K点FFT为例,受DDR宽带的限制,读取或写回DDR所需时间约3.8 μs,运算时间约4.6 μs量级。可见,读写DDR总共耗时已超过运算时间,运算效率(运算时间占总处理时间的比例)仅38%。
为提高数据长度较小时的运算效率,RASP有针对性地采用了乒乓处理机制,在执行含多条基本算子指令的批处理任务时可大大提高运算效率。其运算横道图如图3所示。将整个存储阵列等分为两组,记为组1和组2,两组RAM乒乓工作,基本流程为:
(1) 源数据1从DDR读出后存入RAM 组1,然后启动运算,同时,源数据2也从DDR读出,并存入RAM组2;
(2) 当源数据1的运算结束后,结果由RAM组1写入DDR,同时,RAM组 2中缓存的源数据2启动运算,当RAM组1的结果写完后,紧接着从DDR中读取源数据3并存入RAM 组1。
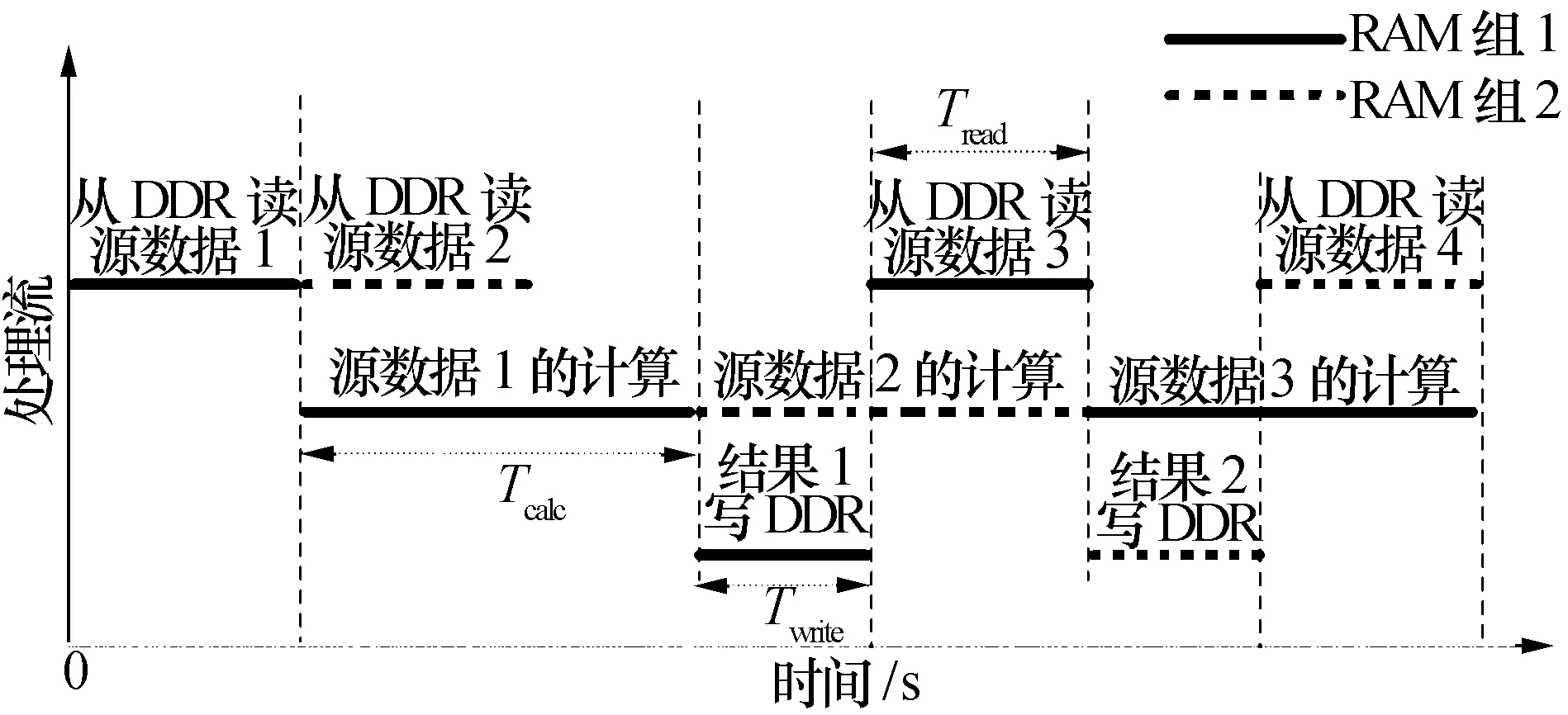
图3 乒乓处理运行横道图
记运算时间为Tcalc,从DDR读取源数据的时间为Tread,运算结果写回DDR的时间记为Twrite。可以看到,当循环执行N次运算时,采用兵乓处理机制消耗的总时间为
(1)
当Tcalc≥Tread+Twrite时,除第1次源数据读取和第N次结果回写的时间外,运算始终执行,读写数据的时间几乎被完全掩盖。因此,当N足够大时,运算效率近乎100%。
2 基本算子指令设计
RASP通过计算资源的实时重构可支持FFT、FIR、矩阵乘、矩阵求逆等多种基本算子指令,下面分别对典型的FFT和矩阵求逆指令的重构设计进行说明。
2.1FFT
对于长度为N的输入序列,FFT结果为
(2)
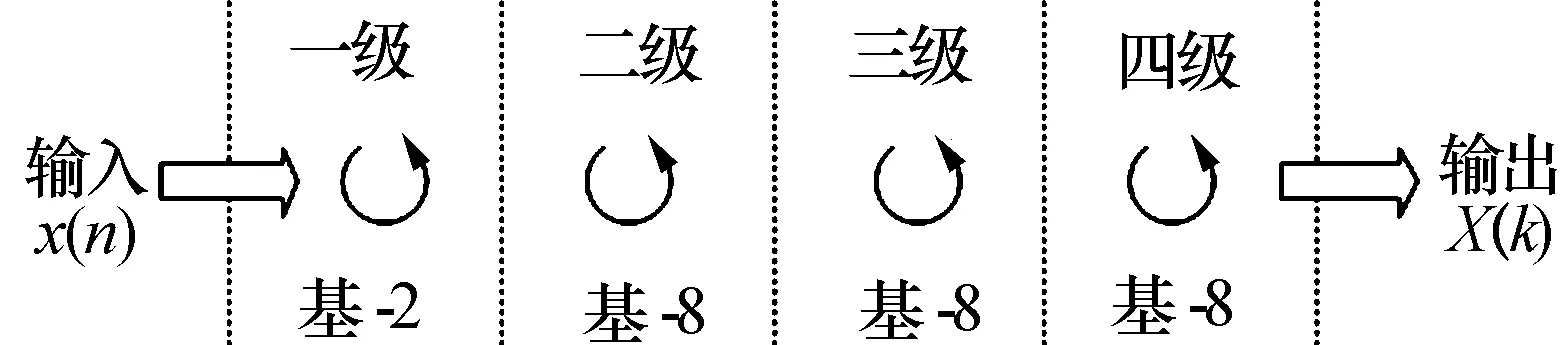
图4 1 K点FFT计算流程示意图
2.2矩阵求逆
RASP计算矩阵求逆采用了LU分解法,分三个步骤:列选主元LU分解、三角矩阵求逆、矩阵相乘。
设矩阵A为非奇异矩阵,并且所有顺序主子式不为0,则矩阵A可以唯一分解为一个主对角元素全为1的下三角矩阵L和一个上三角矩阵U的乘积,即A=LU。为避免主元很小时因计算机精度限制所导致的下溢问题,采用了列选主元LU分解法,循环执行选主元、归一化、数据更新三个步骤。其中,选主元和归一化步骤均使用RPE6中的计算资源,数据更新则使用RPE1~RPE4中的复数乘加器,四路并行处理。
三角矩阵求逆则分别计算L和U的逆矩阵L-1和U-1,主要使用求倒和乘累加器,其中,求倒由RPE6实现,乘累加器由RPE1~RPE4实现,四路乘累加器分2组同时并行计算L和U的逆矩阵。
将U-1、L-1相乘并进行适当变换即可得到A矩阵的逆矩阵A-1,主要运算为矩阵相乘,其使用每个RPE中的1个复数乘法器和2个复数加法器构成一个全流水的复数浮点乘累加器,共四路乘累加器并行运算。
3 典型功能实现
基于RASP所支持的基本算子指令集,使用不同的指令组合,可以极其便捷地实现不同的雷达信号处理功能,用户仅需要通过软件编程配置相应的指令组合即可。例如,常规脉压算法的计算公式为
Y=IFFT[FFT(X)·Cdpc]
(3)
式中:X为输入向量;Y为输出结果;Cdpc为脉压系数。显然,脉压算法可由FFT、向量乘、IFFT三条基本算子指令组合实现,运算流程见图5a)。

图5 RASP实现典型雷达信号处理算法的运算流程
STAP算法需先计算输入矩阵X的协方差R=XXH,然后对R求逆得到R-1,再利用导向矢量s计算最优权
(4)
最后进行向量矩阵乘Y=WHX,于是,STAP算法可由矩阵协方差、求逆、相乘、点乘、除法等多条基本算子指令组合实现,主要运算流程见图5b)。
在脉压和STAP运算过程中的所有中间值R、R-1、U、V等均存于内部RAM中,可以有效降低读写DDR的时间消耗。
4 实验测试
4.1测试平台
RASP作为一个硬件加速核集成在华睿2号DSP芯片中,芯片采用40 nm的工艺流片,主频可达1 GHz,其中,RASP核面积20 mm2(包含2 MB SRAM),芯片实物如图6a)所示,设计的相应测试模块见图6b)。

图6 含RASP核的华睿2号芯片及测试模块实物
4.2基本算子指令性能测试
不同点数FFT和不同阶数矩阵求逆的性能测试结果如图7所示,其中,纵坐标为以2为底的对数坐标,因DDR读写时间受DDR传输带宽限制,且批处理时有可能被掩盖。因此,为评估RASP的运算效能,此处仅关注运算的时间消耗。
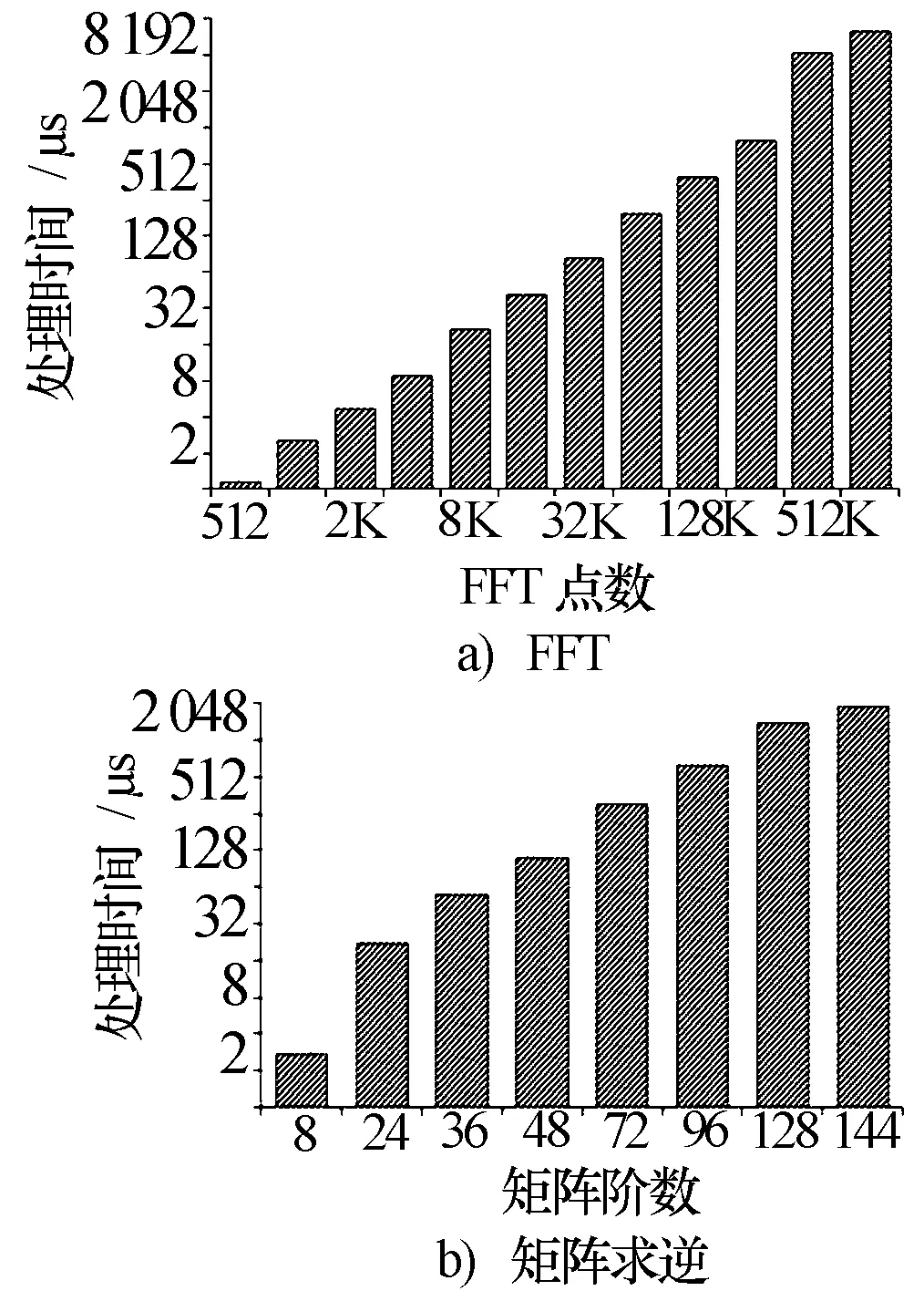
图7 RASP基本算子指令性测试结果
可以看到,随FFT点数增大,处理时间基本呈现NlbN趋势增大,1 K点FFT时间仅2.57 μs,当FFT点数大于256 K点时,受片内存储阵列容量限制,需采用二维FFT实现,故运算时间陡然增多。随矩阵阶数增大,运算资源的并行处理效率越充分,等效于并行度提高,因此处理时间增加趋势渐缓,48阶矩阵求逆时间110.4 μs。
将RASP实现1 K点FFT的性能与其他处理器进行对比,包括可重构处理器NoC[14]、MorphoSys[15],以及商用DSP或CPU,如:TI公司C6678、Freescale公司T4240、Intel公司Xeon E5-2648L V2,结果如图8所示。其中,商用DSP或CPU测试性能时均采用了变址模式。通常用式(5)中的MFLOPS描述处理器实现FFT算法的有效处理能力
(5)
由图8a),RASP实现1 K点FFT仅2.57 μs,有效处理能力高达20 GFLOPS,是E5-2648L的1.9倍,是TI C6678的4.7倍,与NoC相比,则高达30倍。
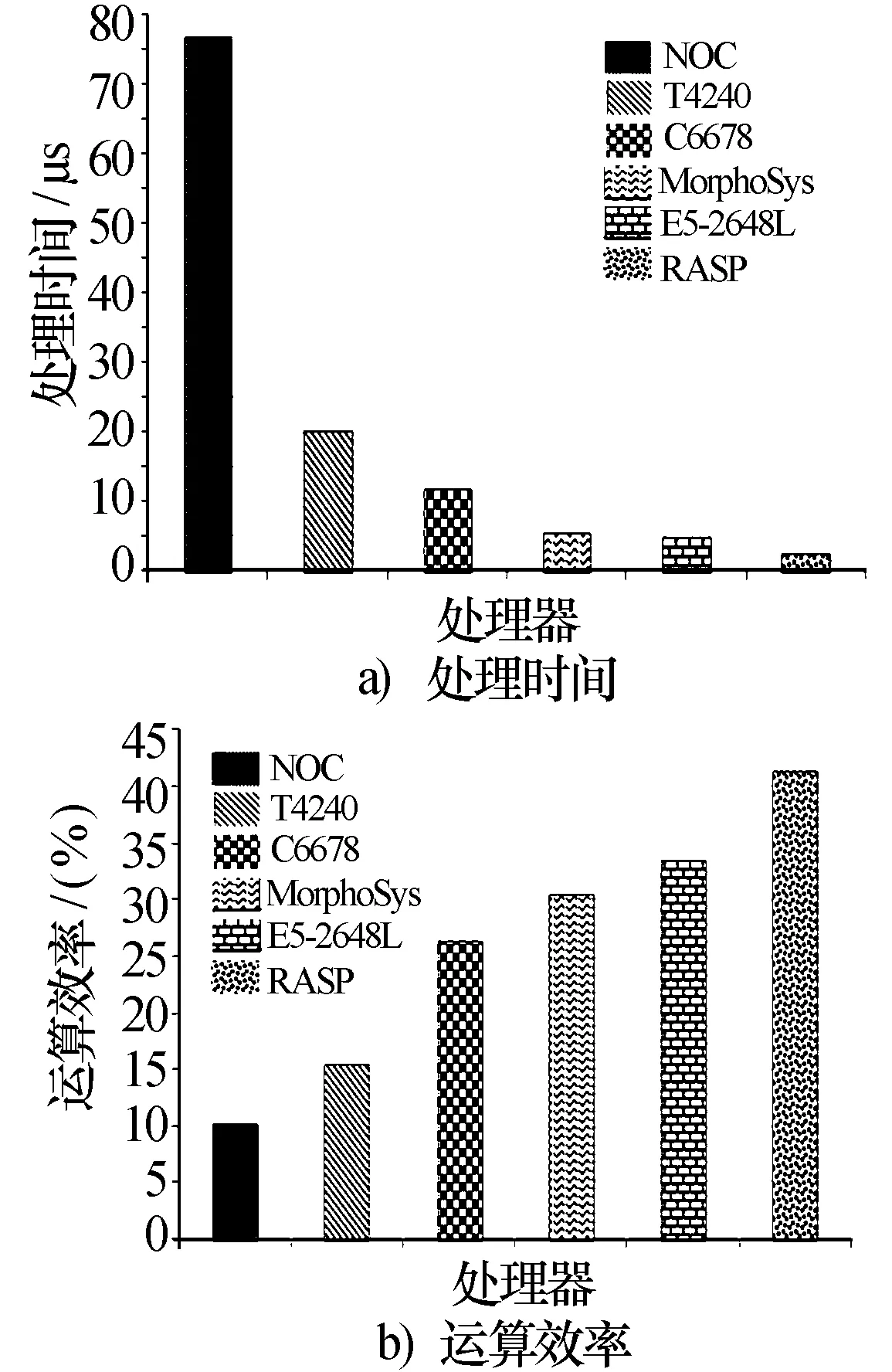
图8 1K点FFT在不同处理器的性能比较
因不同处理器的主频和运算资源均存在区别,通常用运算效率(有效处理能力与峰值处理能力的比值)来表征处理架构的性能,考虑到RASP实现FFT时所使用的RPE资源,主频1 GHz下峰值运算能力达48GFLOPS,运算效率42%。Xeon E5-2648L V2主频1.9 GHz,单核8个MAC,峰值运算能力30.4 GFLOPS,运算效率34%,将不同处理器的运算效率对比如图8b),可以看到,RASP运算效率可以达到其他处理器的1.25~4倍。
4.3典型雷达信号处理算法性能测试
以一个带宽B=2 MHz,时宽T=250 μs,采样频率fs=2 MHz的线性调频信号进行脉压处理,波形见图9a),采用汉明窗加权后主副瓣比MSR可达48.69 dB,与matlab计算的理论值相比,最大相对误差0.03%。完成2 K点脉压处理的时间见表1,共15.3 μs,16 K点脉压处理时间131 μs。
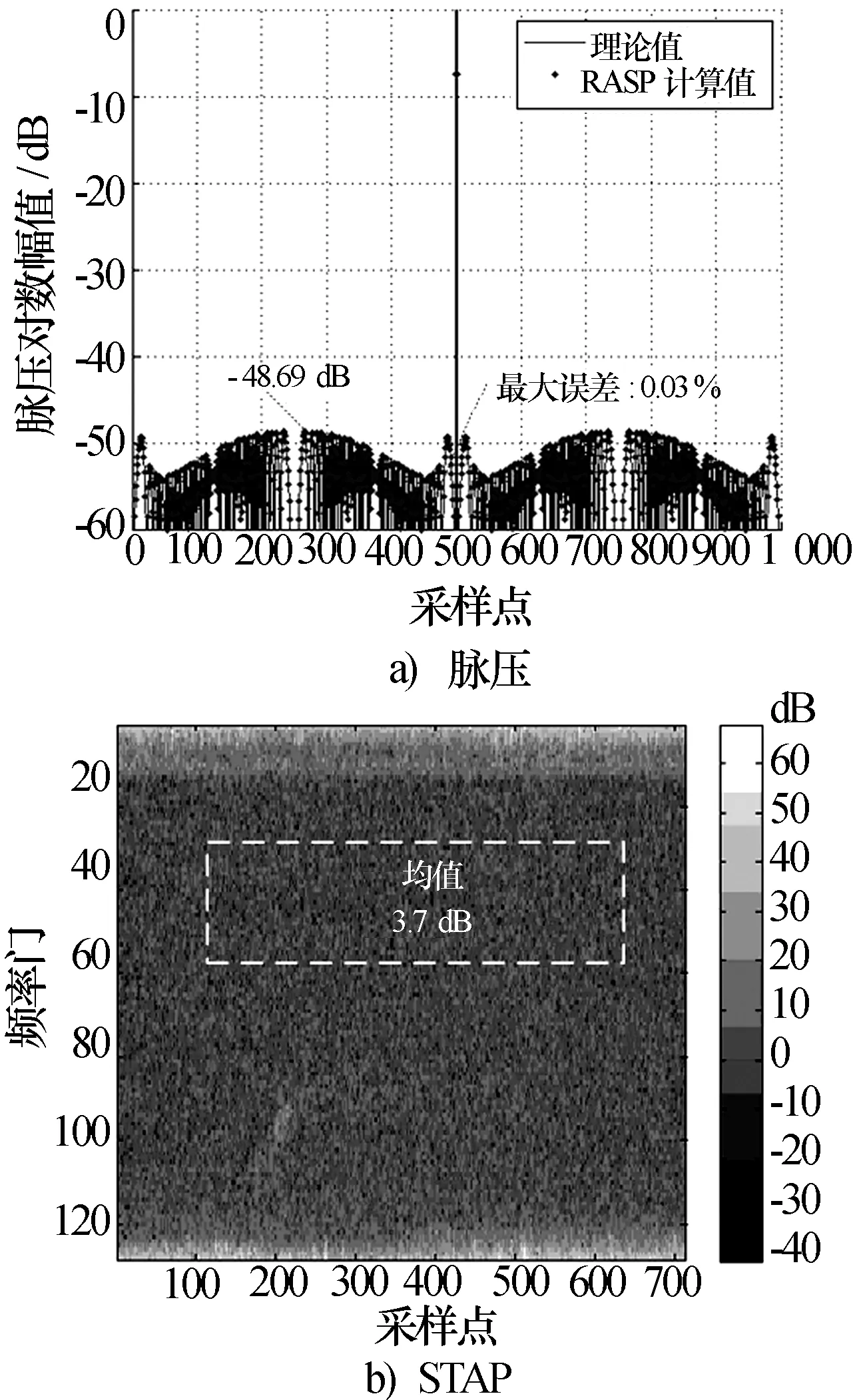
图9 RASP实现脉压和STAP运算的结果
从表1可以看到,运算效率受DDR读写时间影响仍然较大,2 K点时为64%,因FFT运算时间呈MlbN增长,DDR读写时间则线性增长,故点数越大运算效率会越高,16 K点时达66.5%。此外,若连续进行M次脉压运算且点数较大时,还可以考虑采用批处理方法实现,即依次进行M次FFT、M次向量乘、M次IFFT,以尽可能掩盖DDR读写时间,提高运算效率。
表1不同点数下RASP实现脉压算法的性能μs
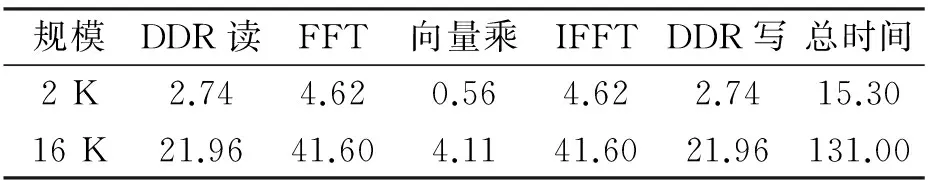
规模DDR读FFT向量乘IFFTDDR写总时间2K2.744.620.564.622.7415.3016K21.9641.604.1141.6021.96131.00
分别对24通道、256距离门以及48通道、1 024距离门两种规模的矩阵进行STAP处理,性能见表2。24×256规模的STAP耗时70.9 μs,48×1 024规模的STAP耗时798 μs。
表2不同规模下RASP实现STAP算法的性能μs

规模DDR读协方差矩阵求逆矩阵乘除法DDR写总时间24×2568.2338.0022.301.740.270.3470.9048×102465.90607.00110.0013.300.541.37798.00
选择20通道、128频率门、715距离门的实录数据进行STAP处理,采用和通道导向矢量,输出幅度分布见图9b),在频率门27~58,距离门101~616的清晰区内,杂波剩余3.7 dB,与预期值相符。
5 结束语
本文提出并设计了一种面向雷达信号处理应用的可重构专用处理RASP架构,其采用了非规则化微结构和混合重构策略,并通过兵乓处理机制有效掩盖了DDR读写时间,能够充分发挥各运算资源的效率,1 K点FFT运算时间2.57 μs,处理效率高达42%,是同类型其他处理器的1.25~4倍,处理性能是同类型其他处理器的1.9~30倍。RASP作为协处理器被嵌入华睿2号DSP芯片并在TSMC 40 nm工艺下流片,经测试,雷达数字脉压(2 K点)和STAP(48×1 024)处理的时间分别为15.3 μs和798 μs,适用于对处理性能和灵活性均有较高要求的雷达信号处理和电子对抗等领域。
[1]BROOKER E. Recent developments and future trends in phased arrays[C]// IEEE International Symposium on Phased Array Systems & Technology. Waltham, MA: IEEE Press, 2013: 43-53.
[2]张光义, 赵玉洁. 相控阵雷达技术[M]. 北京: 电子工业出版社,2006.
ZHANG Guangyi, ZHAO Yujie. Technology of phased array radar[M]. Beijing: Publishing House of Electronics Industry, 2006.
[3]IQBAL M A, AWAN U S. RISP design using tightly coupled reconfigurable FPGA cores[C]// International Conference on Information & Communication Technologies. Karachi: IEEE Press, 2009: 249-254.
[4]王新安,叶兆华,戴鹏, 等. 可重构阵列DSP结构ReMAP[J]. 深圳大学学报理工版,2010,27(1): 16-20.WANG Xinan, YE Zhaohua, DAI Peng, et al. ReMAP: a reconfigurable array DSP architecture[J]. Journal of Shenzhen University Science and Engineering, 2010, 27(1):16-20.
[5]ESTRIN G. Organization of computer systems: the fixed plus variable structure computer[J]. IEEE Computer Society, 1960, 133(37): 33-40.
[6]MIRSKY E, DEHON A. MATRIX: a reconfigurable computing architecture with configurable instruction distribution and deployable resources[C]// IEEE Symposium on FPGAs for Custom Computing Machines. Mapa Valley, CA: IEEE Press, 1996: 157-166.
[7]MEI B, VERNALDE S, VERKEST D, et al. ADRES: an architecture with tightly coupled VLIW processor and coarse-grained reconfigurable matrix[C]// International Conference on Field Programmable Logic & Applicaiton. Lisbon: IEEE Press, 2003(2778): 61-70.
[8]BAUMGARTE V, EHLERS G, MAY F, et al. PACT XPP-A self-reconfigurable data processing architecture[J]. The Journal of Supercomputing, 2003, 26(2): 167-184.
[9]HENTRICH D, ORUKLU E, SANIIE J. Polymorphic computing: definition, trends, and a new agent-based architecture[J]. Circuits and Systems, 2011, 2(4): 358-364.
[10]LIULei,YANGZiyu,LISikun,etal.Implementationofhigh-throughputFFTprocessingonanapplication-specificreconfigurableprocessor[C]// 2012 2ndInternationalConferenceonComputerScienceandNetworkTechnology.Changchun:IEEEPress, 2012: 1284-1288.
[11]魏少军,刘雷波,尹首一. 可重构处理器技术[J]. 中国科学:信息科学,2012,42(12): 1559-1576.
WEIShaojun,LIULeibo,YINShouyi.Keytechniquesofreconfigurablecomputingprocessor[J].ScienceChina:InformationSciences, 2012,42(12): 1559-1576.
[12]CHALAMALASETTISR,PUROHITS,MARGALAM,etal.MORA-anarchitectureandprogrammingmodelforaresourceefficientcoarsegrainedreconfigurableprocessor[C]// 2009NASA/ESAConferenceonAdaptiveHardwareandSystems.SanFrancisco,CA:IEEEPress, 2009: 390-396.
[13]于苏东,刘雷波,尹首一, 等. 嵌入式粗颗粒度可重构处理器的软硬件协同设计流程[J]. 电子学报,2009, 37(5): 1136-1140.
YUSudong,LIULeibo,YINShouyi,etal.Hardware-softwareco-designflowforembeddedcoarse-grainedreconfigurableprocessor[J].ActaElectronicaSinica, 2009, 37(5): 1136-1140.
[14]BAHNJH,YANGJS,BAGHERZADEHN,etal.ParallelFFTalgorithmsonnetwork-on-chips[J].JournalofCircuitsSystem&Computers, 2011, 18(2): 255-269.
[15]KAMALIZADAH,PANC,BAGHERZADEHN.FastparallelFFTonareconfigurablecomputationplatform[C]//Proceedingsofthe15thSymposiumonComputerArchitectureandHighPerformanceComputing. [S.l.]:IEEEPress, 2003: 254-259.
何国强男,1977年生,高级工程师。研究方向为雷达信号处理、数字芯片设计。
李丽女,1975年生,教授,博士生导师。研究方向为超大规模集成电路设计。
Design of Reconfigurable Processor for Radar Signal Processing Application
HE Guoqiang1,LI Li2,LI Shiping1
(1. Nanjing Research Institute of Electronics Technology,Nanjing 210039, China)(2. School of Electronic Science and Engineering, Nanjing University,Nanjing 210046, China)
To meet the demands of high performance applications in modern radar, RASP architecture is presented in this paper. Through anomalistic microstructure and mixed reconfigurable strategy, the performance of parallel-pipeline compute improves in effect. With ping-pang processing method which conceals DDR read-write time, RASP also gives full play to the efficiency of computing resources. As a co-processor, RASP is tapped out and integrated in the DSP chip Huarui-2 with TSMC 40 nm. The test results demonstrate that 1 K FFT calculating only needs 2.57 μs. The processing efficiency is as high as 42%. The performance is about 1.9~30 times and the efficiency is about 1.25~4 times as other FFT processors like NoC, MorphoSys, C6678, T4240, et al.
reconfigurable processor; FFT; matrix inverse; pulse compression; STAP
10.16592/ j.cnki.1004-7859.2016.08.011
何国强Email:guoqiang_he@sohu.com
2016-04-22
2016-06-24
TN957
A
1004-7859(2016)08-0046-05
猜你喜欢
数学物理学报(2021年2期)2021-06-09
应用数学(2020年2期)2020-06-24
数学年刊A辑(中文版)(2018年2期)2019-01-08
信号处理(2018年5期)2018-08-20
信号处理(2018年5期)2018-08-20
信号处理(2018年8期)2018-07-25
信号处理(2018年8期)2018-07-25
家庭科学·新健康(2018年5期)2018-06-08
数学物理学报(2016年3期)2016-12-01
中国当代医药(2015年7期)2015-03-01
