
语义规则与表情加权融合的微博情感分析方法
2016-08-06 01:58:26赵天奇姚海鹏张俊东张培颖
重庆邮电大学学报(自然科学版) 2016年4期
赵天奇,姚海鹏,方 超,张俊东,张培颖
(北京邮电大学 网络与交换国家重点实验室,北京 100876)
语义规则与表情加权融合的微博情感分析方法
赵天奇,姚海鹏,方超,张俊东,张培颖
(北京邮电大学 网络与交换国家重点实验室,北京 100876)
摘要:当前中文微博情感分析的主流做法是将情感极性分类结果的好坏作为评判的标准。从提高微博情感判别准确度的目的出发,尽量多考虑影响微博情感的元素。在统计微博中情感词的基础上,加入了微博表情这一重要元素,采用与文本情感值加权的方式参与微博情感计算,使得对含有表情的微博情感判定结果有了一定程度的提高;在语义规则部分,基本涵盖了汉语中最常用的几种句型规则和句间关系规则,使得对复杂语句的情感分析更加准确。同时,还对每条微博的情感给出了具体的数值,并在正确率、召回率、F值的基础上,提出合格率这一指标,对微博情感判别方法得到的数值准确性进行评价。通过搭建Hadoop平台对测试集的1万条数据进行测试,验证了融合算法的有效性。
关键词:微博;情感分析;语义规则;微博表情
0引言
21世纪是数据信息爆炸的时代,伴随移动互联网、社交网络等发展和普及,数据信息正在疯狂地增长。社交媒体时代,人们更多地通过微博、微信等互联网平台表情达意,“人人都有了自己的麦克风”。而从古代开始就有的“防民之口甚于防川”的说法,甚至今日仍然有着一定的借鉴意义。
数据意味着信息,海量数据意味着巨大的信息。对这些数据加以利用可以获得巨大的潜在价值:对消费者来说,将其他用户对某类产品评价进行汇总和分析可以为其是否购买提供参考;对商业公司来说,分析消费者对产品的评价可以作为其后续改进的基础;对政府部门来说,掌握舆情的发展与走势可以更好地维护社会的稳定。而这些海量信息的获取与分析如果都靠人工来完成,那么是很难应付的,因而如何快速准确地处理和使用信息已经成为当前研究的热点。
本文就是从这样的目的出发,以微博数据作为研究对象,选取1万条用户微博,采用融合语义规则和表情加权的算法对微博情感值进行评判,通过Hadoop平台对数据进行分布式处理。
1相关工作
现阶段,在情感分析领域,英文微博的研究较为成熟,而中文微博相对来说才刚刚起步。因此,用于英文的情感分析资源比较丰富。常用的情感词典包括SentiWordNet和Inquirer等,这些词典的突出特点是能够提供词语在不同语境下的情感倾向,是情感分析准确率的重要保障。另外,英文的标注语料也初具规模,从人工标注到Pak等[1]利用Twitter表情符自动标注,英文标注语料一直在不断扩充和完善,为测试工作提供丰富的原材料。
相比之下,中文的情感分析资源还比较匮乏。常用的情感词典主要有知网情感词典、同义词词林以及包括台湾大学和大连理工大学类似的一些高校提供的情感词汇库,但质量良莠不齐。标注语料方面,虽然近两年出现了一些包括中国中文信息学会信息检索专业委员会举办中文倾向性分析评测(chinese opinion analysis evaluation,COAE)提供的中文情感标注语料在内的标注文本,但总体而言,权威的情感分析语料仍旧不多。
在研究方法方面,目前主流的方法主要是基于语义和机器学习这2种[1]。所谓基于语义,就是通过统计微博文本中情感词的情感值,并通过求平均或者其他运算方式给出语句和文本的情感值;而机器学习就是通过构造分类器,使用标注好的训练集训练分类器,并区分训练集中的正例和反例,常用的方法有朴素贝叶斯法(Naive Bayes)[2-3]、K 最近邻法、中心向量法和支持向量机法(support vector machine,SVM)等。
国外的研究主要针对Twitter的数据进行展开。2005年Pak在进行标注Twitter文本情感极性数据集的基础上实现了基于朴素贝叶斯、支持向量机和条件随机场的情感分类器。2009年Go等[4]采用无监督指导的朴素贝叶斯、最大熵和支持向量机3种机器学习方法,并加入表情符号这一特征,大大提高了情感倾向判别的准确率。2011年Jiang等[5]运用五折交叉验证的方法验证了情感词典和主题相关特征可以提高分离效果的准确性。
国内的研究主要针对新浪微博、腾讯微博等进行展开。徐琳宏等[6]考虑句子的词汇和结构2个层面,根据影响语句情感的9个语义特征构建了情感词汇库,进行了情感分析的初步尝试。李钝等[7]结合语言学知识,在获得词语语义倾向时采用了“情感倾向定义”权重优先的方式,为粗粒度的文本情感分析奠定基础。刘志明等[8]通过对比3种机器学习算法、3种特征项权重计算方法和3种特征选取算法,发现使用SVM、词频-逆文本频率(term frequency-inverse document frequency,TF-IDF)及信息增益(information gain,IG)选择特征项权重时效果最佳。谢丽星等[9]在对新浪微博数据进行情感分析研究时提出了基于层次结构的多策略方法,并采用主题相关特征进行特征提取,提高了准确率。
但总体来说,目前的情感分析效果并不十分理想。在目前常用的2种方式中,基于语义词汇的情感分析算法实现的粒度更细,但把词语从句子中孤立出来,忽略词语的上下文关系及句法规则,反映微博消息的情感倾向时不够完善;而基于机器学习的方法在处理新闻、论坛等长文本情况时效果较好,对微博短文本的分析不够理想。因此,本文利用现有的研究成果及分析方法,采用情感词典加语义规则的计算模型进行微博情感计算,并利用表情词典对最终的结果加以修正。
2情感分析算法的设计
2.1情感分析流程
图1是本文提出的微博情感分析算法流程,输入为整条微博。文本预处理实现的功能之一是正则匹配“[]”内的字符,从而提取表情符号的文字表示,构建表情的集合,通过在表情数据库中查询其对应的情感值并求和,得到微博表情部分的情感分数。文本预处理的另一个作用是对微博纯文本按照“。” “;”“!”“?”进行分句操作,得到多个复句。通过对句号、分号、叹号和问号的识别判断各个复句的句型,并给予相应的权值。对复句按照“,”进行分句操作,得到复句中每个分句,通过识别转折、递进、假设3种句间关系的关键词来判断各分句间的关系,并对相应的分句赋予一定的权值。在分句中通过查找情感词典库确定情感词的极性和数值,并根据情感词前出现的程度副词和否定副词进行相应的数值修正。最后,根据各部分得到的数值加权求和得到最终的微博情感结果。
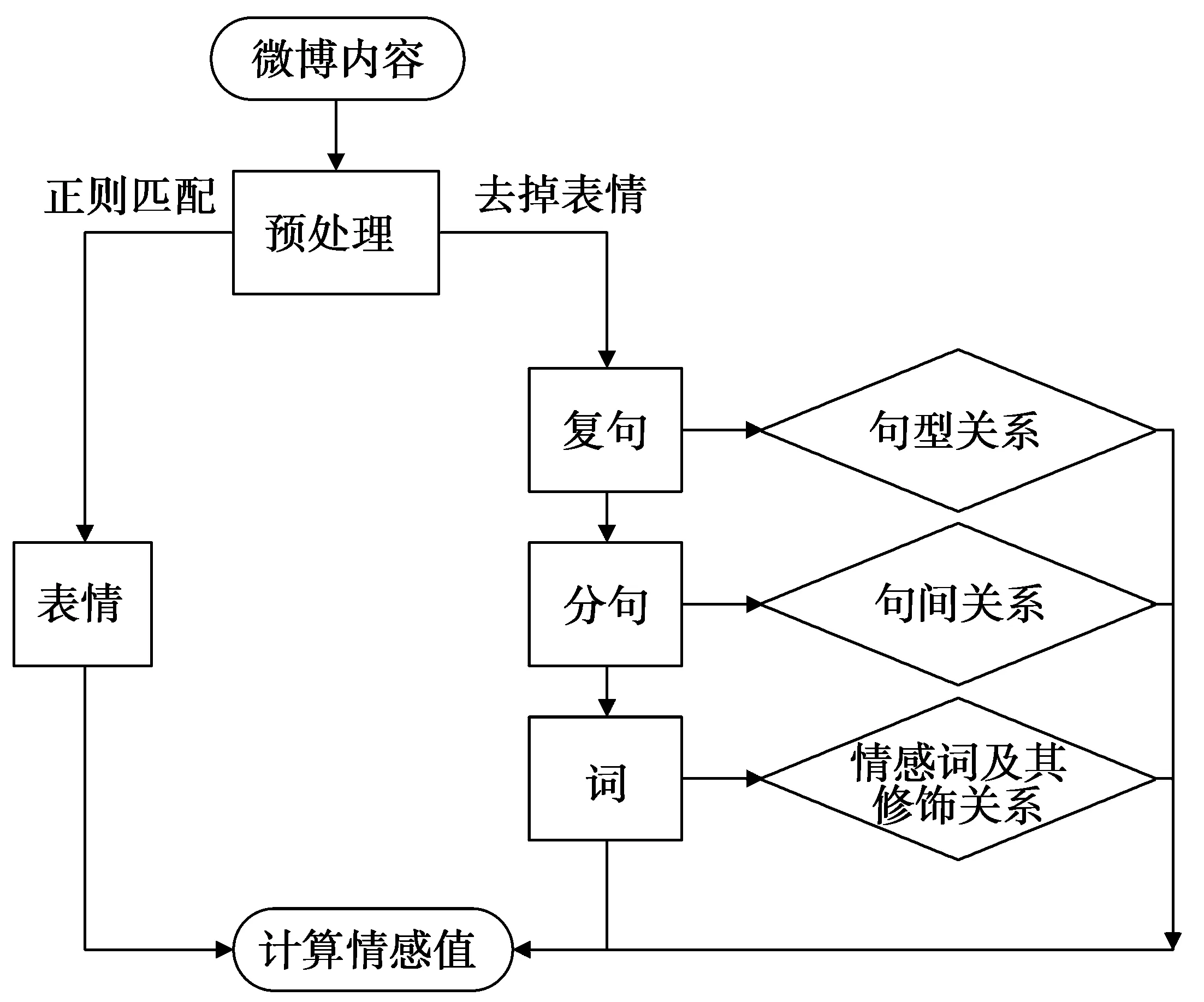
图1 微博情感分析流程图Fig.1 Microblog sentimental analysis flow chart
2.2情感词典的构建
情感词典是情感分析的基础,情感词典的质量直接决定了情感分析的效果。目前使用最多的中文情感词典主要是知网的中英文情感词典、大连理工情感词汇本体库、台湾大学中文情感词典等。知网的情感词典包括正面情感词语、正面评价词语等6个词表的中英文版本,分类细致,词语全面,但只有词语本身,缺少对应的词性标注及情感强度等标签,在情感数值的计算上存在难度;台湾大学的情感词库也是如此,将正向情感词和负向情感词分别放在2张表中,但没有词性标注和情感强度;大连理工情感词典相比较而言,词语的指标更为全面,词性、情感强度、情感极性都进行了标注,方便用于情感值的计算。
因此,本文采用大连理工情感词汇本体库作为基础,并对其进行了简化处理,只保留了词语名称、词性、情感强度和极性4个基本属性。情感分类按照论文《情感词汇本体的构造》所述,情感分为7个大类21个小类。情感强度分为5档,用1,3,5,7,9来表示,1为强度最小;9为强度最大。每个词在每一类情感下都对应了一个极性,其中,0代表中性,1代表褒义,2代表贬义,3代表兼有褒贬两性。同时,作为补充,还选取了褒义基准词和贬义基准词各40个并手动将其情感倾向值设为9,即最大强度[10]。因为微博中的句子并不是简单情感词的叠加,所以,只有情感词词典对于文本的情感分析肯定是不够用的。我们考虑到语义规则对文本情感分析的影响,引入了程度副词词典和否定副词词典。其中,程度副词词典采用知网提供的程度级别词语(中文)共219个,沿用蔺璜等[11]提出将这些词分为4个等级的做法,即极量、高量、中量和低量。否定词典由整理出的19个否定副词构成,权值为-1。程度副词和否定副词词分别如表1和表2所示。

表1 程度副词示例表

表2 否定副词示例表
除此之外,我们还将新浪微博中常用的共计77个表情在[-1,1]进行人工标注,作为表情数据集使用,如图2所示。图2中的“笑哭了”表情,在数值上体现为1,“怒”在数值上体现为-1,“挤眼”为0.7等。
至此,情感词典的构建工作已经完成,由大连理工情感词典本体库、褒义基准词典、贬义基准词典、程度副词词典、否定副词词典及表情词典共6部分构成。
2.3语义规则
由于汉语的博大精深,人们在表达的时候往往不是靠堆叠情感词来表达自己的情感,也就是说我们在分析微博情感时不能只采用统计情感词的方式,而是应该更多地考虑人们在表达时的一些特殊方法,如句式、句型和修辞上的不同。本文从这一目的出发,在微博情感分析时加入了句型规则和句间关系规则[11],下面就这2个规则进行阐述。

图2 微博表情Fig.2 Microblog emoticons
2.3.1句型规则
经过分词以后的文本由各简短子句组成,用集合表示为{S1,S2,…,Si,…,Sn}。我们这里所讲的句型规则是定义在一个完整句子上的,即以句号、分号、问号或叹号结尾的句子,可以简单地理解为一个复句。一个复句可以用Si来表示,其中包括s1到sn共n个子句。考虑4种常见的句型:感叹句、反问句、疑问句和陈述句,定义Ti表示句型规则下的权值,Ti的数值由以下4条规则决定。
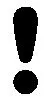

④如果复句为陈述句,即Si以其他标点结尾,则Ti=1。
2.3.2句间关系规则
在语句级别的分析上,除了句型的判断外,在一个复句中,多个子句间的关系也会对情感分析有一定的影响。本节将一个复句中的各个子句作为研究对象,考虑句间的3种常见关系:转折关系、假设关系、递进关系,定义ri表示句间关系权值,其数值由以下规则决定。
1)转折关系规则。一般情况,转折复句前面分句提出某种事实或情况,后面分句转而述说与前面分句相反或相对的意思,即后面分句才是说话人所要表达的真正意图。故定义规则如下。
①如果复句Si中有单一转折后接词(如:“但是”“但”“却”“可是”)且出现在分句sj上,则r1,r2,…,rj-1=0;rj,rj+1,…,rn=1。
②如果复句Si中有成对转折标志词(如,“虽然…但是”)且在分句sj中出现转折后接词,则r1,r2,…,rj-1=0;rj,rj+1,…,rn=1。
③如果复句Si中有单一转折前接词(如:“虽然”)且出现在分句sj上,则r1,r2,…,rj-1=1;rj,rj+1,…,rn=0。
2)假设关系规则。假设关系在实际的表达中更倾向于强调前提条件,而弱化后半部分,故有如下定义。
①若复句Si中存在假设关系后接词(如“那么”)且出现在分句sj中,则r1,r2,…,rj-1=1;rj,rj+1,…,rn=0.5。
②若复句Si中存在否定假设关系前接词(如:“如果不”),且否定关系后接词(如“那么”)出现在分句sj中,则r1,r2,…,rj-1=-1;rj,rj+1,…,rn=-0.5。
3)递进关系规则。递进关系是指能够表示在意义上进一层关系的,且有一定逻辑的词语。现定义规则如下。
如果复句Si中存在递进关系标志词(如:“更加”“更有甚者”)且出现在分句sj中,则r1,r2,…,rj-1=1,rj,rj+1,…,rn=1.5。
除了这3类常见的句间关系外,还有因果关系、并列关系以及其他一般关系,这些关系的前后分句在情感上变化不大,所以,不做区分,分句情感的权值设为1。
2.4表情加权
在对存在表情的微博进行分析时,如果只考虑文本的情感值而忽略表情对整条微博情感值的影响,那么将是对数据信息的一种浪费。在现有的微博情感研究工作中主要采用2种方式对表情符号进行处理:①将表情符号并入情感词典中,即将表情的情感极性按照情感词的方式进行统计,这种方式对于表情符号信息的利用并不十分充分;②王文[13]提出的将表情情感值与文本情感值加权处理作为最后的结果,这样可以为细粒度的情感数值计算提供方便且充分利用了表情符号的信息。故本文采用这一方法对表情加以利用。
表情与文本情感值的比例选择问题也会对最终的结果产生影响。在文献[13]中,通过对数据集的测试发现,当表情与文本的比例为0.4和0.6时,加权后正负面情感倾向的判断准确率有明显提升,在其测试集中判断准确率从78.6%提升到83.4%。因此,本文算法也沿用0.4和0.6这一加权比例,对微博最终情感进行计算。
2.5微博综合情感计算
通过前面的准备工作,我们得到了一条微博在表情、复句、分句、词语4个层面上的参数,本节将给出如何利用这些参数进行最终的情感值计算。现从词语到复句的顺序进行分析,即颗粒度由小到大,用Emotion的首字母E来表示情感值。
1)词语情感值E(Wi)表示为
E(Wi)=Neg×ad×seni
(1)
(1)式中:Neg表示情感词对应的否定副词;ad表示情感词对应的程度副词;seni表示句中情感词与情感词库匹配后得到的情感值。
词语级的情感值是情感词语本身及其对应的程度副词和否定副词修正后的结果。由于代码实现上的原因,当匹配到情感词后,向前至多取2个词,如果存在程度副词和否定副词,则按程度副词词典和否定副词词典对应的权值进行修正;如果在2个词的范围内没有找到程度副词和否定副词,则按权值为1对待,即不对情感词本身的极性和情感值产生影响。
2)分句情感值E(si)表示为
(2)
(2)式中:∑E(Wi)表示分句内所有词语情感值的和;ri表示当前分句的句间关系系数。
分句情感值由分句内所有词语情感值之和乘以分句的句间关系权值确定。由2.3.2节提出的规则确定。
3)复句情感值E(Si)为
(3)
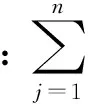
复句情感值由复句内各分句情感值求和乘以复句的句型系数得到。
4)文本情感值Etext为
(4)
微博文本的情感值由各复句的情感值求和得到。
5)表情情感值Eemotion为
(5)
表情的情感值由微博中出现的所有表情的情感值求和取平均确定。
6)微博情感值为
(6)
由于本文的目的是对微博的情感给出具体的数值表示,而不是正负倾向性分析,所以情感词汇和表情的情感值都取值[-1,1],但由于句间关系和句型关系的修正,结果的绝对值可能会超出[-1,1]的限制,因此,这里我们规定,如果最终的情感值的E绝对值超过1,则E取1;不超过1时,不进行修正和取舍。
3情感分析实验
3.1实验数据
由于目前中文微博的分析起步不久,暂时还没有标准的微博情感分析语料可供分析,所以,本文通过爬虫的方式爬取新浪微博的原始数据40余万条,从中筛选原创微博1万条。由于本文实现的微博情感分析算法会给出一个[-1,1]的数值作为微博的情感值,因而选取5名志愿者对筛选出的1万条微博情感值进行讨论式的人工判定,在[-1,1]给出每条微博的情感值。
在这个过程中,由于无法避免主观因素对情感判定的影响,以及算法对非情感句进行的情感相似度处理造成的误差,所以,本文在实验分析中对3种情感分类的标准做了一定的调整,[-0.2,0.2]为中性微博,(0.2,1)为正向微博,[-1,-0.2]为负向微博。

(7)
在这1万条原创微博的分类结果中,正向微博有2 683条,中性微博有5 065条,负向微博2 252条。从这一分类结果中可以看到,中性微博占据较大的比例,正向微博和负向微博比例相对较小且正向微博稍多。
3.2实验性能评估指标
本文采用第2节提出的算法对每条微博进行情感分析,将分析的结果与人工标注的结果进行比对,采用正确率 (Precision)和召回率 (Recall)及F值(F)[14]作为微博情感极性判别的标准。同时,还需对微博情感分数判别的准确率进行评判,如果算法判定的结果与人工标注结果的误差在±0.1内,则认为合格,用合格率表示微博情感分数判定的准确程度。
下面给出正确率、召回率、F值及合格率的计算公式
(8)
(9)
(10)
(11)
3.3实验设计与结果分析
根据3.1节提出的情感分类判别方法以及3.2节提出的合格率判断标准,对爬取到的微博数据通过Hadoop进行离线处理,如图3所示。然后对结果进行指标评价。
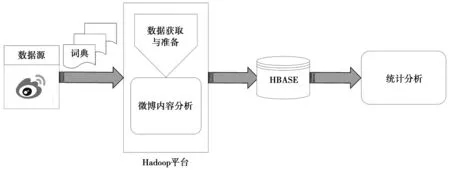
图3 数据测试流程图Fig.3 Data test flow chart
实验测试了本文提出的算法及支撑本文的2篇文章中提出的算法[11,13],并对测试结果进行了比较。由于本文只采取了这2篇文章中的主要思想进行融合,并没有融合其全部工作,因而在比较的时候只选择了语义规则+情感词典和表情加权+情感词典2种方式,即2篇论文中的主体思想,所以在测试的指标上可能与2篇论文给出的结果有所偏差。测试结果如表3,表4所示。
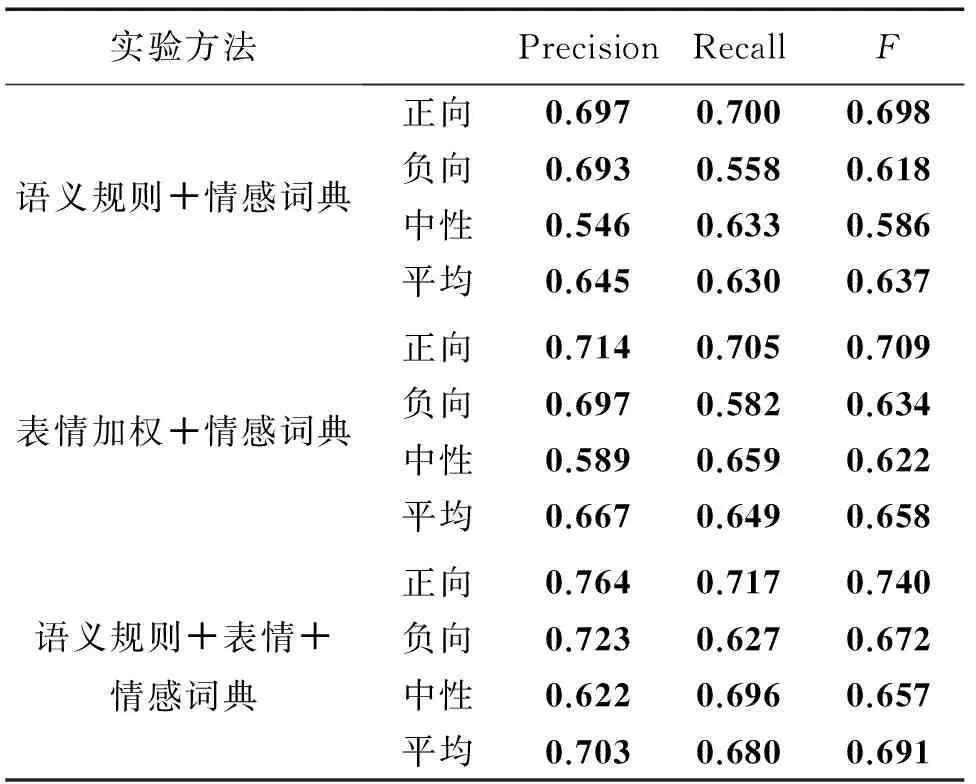
表3 正确率、召回率、F值
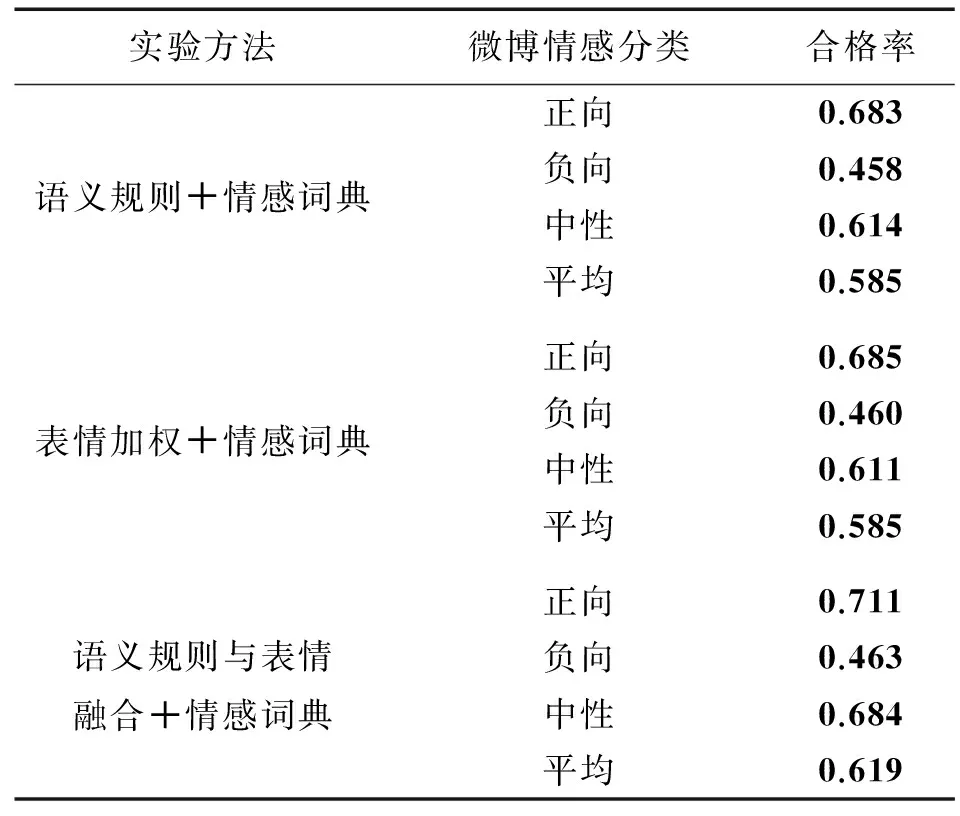
表4 合格率
表3和表4中的“语义规则+情感词典”是指通过查找微博中的情感词并结合语义规则对微博情感进行判定,“表情加权+情感词典”是指将微博中的情感词数值求和取平均并结合表情符号的加权对微博情感进行判定,2种方法中的情感词典、语义规则和表情加权与本文2.2节、2.3节和2.4节是一致的,没有差别。现对表3和表4的统计数据进行分析如下。
1)表3的准确率一列,3种方法均表现出正向、负向数值高,中性数值低的特点。造成这种现象的原因是中性区间为(-0.2,0.2),相比于中性区间为0的情况扩大了范围,导致有一部分正向和负向的微博被判断为中性微博,使得准确率计算公式中的分母增大,数值减小。
2)表3的召回率一列,3种方法都表现出正向、中性数值高,负向数值偏低的特点。造成这一现象的原因主要是情感词库中负向情感词不够完善,导致部分负向情感的微博不能准确识别。还有一部分原因是因为特殊的修辞手法或非常规的表达方式,如“不!对!是!被!蚊!子!咬!了!三!个!包!”。
3)表3的F值一列,3种方法的平均F值分别为0.637,0.658和0.691。在对比中我们发现,由于表3是对极性判别准确度的一种考量,所以,当文本情感值判定有偏差时,表情加权可以对其进行修正,所以其结果准确程度相对于语义规则来说更高。当本文算法将语义规则和表情加权结合到一起的时候,F值有了较为明显的提升,平均F值达到0.691,正向情感微博的F值达到0.740,效果已属于良好。
4)在合格率方面,可以看到在加入规则和表情加权后平均合格率已经达到0.619,即经过程序计算后有61.9%的微博情感值与人工标注的情感值在±0.1的误差之内,已经属于比较不错的结果。另外,正向和中性的微博在合格率上提升幅度相对较大,负向微博的合格率提升幅度较小。其中的原因除了情感词的识别存在误差以外,还跟人们在使用文字表达情感上的习惯有关:人们在表达负向情感的时候较少使用复杂的句式,一般简洁明了,而在表达正向和中性情感时对复杂句式的使用相对较多,所以,语义规则在分析复杂句式上的优势就体现不出来了。
5)在对合格率的误差进行分析时,我们发现大部分误差产生的原因主要有2方面:①分词结果存在误差;②情感词典不完善。如“严格规范执法队伍人员行为”中的“严格”,在句中是作为副词出现的,但在分词时被当作形容词。还有一些不可避免的情况是因为很多词语有一词多义的现象,在不同的语境下可能表现为相反的词性,在情感词典库中被标注为中性,这种词在处理的时候很难准确识别其词性及强度,造成对结果的干扰。
6)本文提出的融合算法将语义规则与表情加权结合在一起,融合了2种方法在进行情感分析时的优点:融合算法与语义规则+情感词典的方法相比,加入了表情的修正,在对情感极性判别的准确度方面有所提升;与表情加权+情感词典的方法相比,加入了语义规则,不仅对极性判别有修正作用,也对复杂句式的处理提供帮助,主要体现在合格率这一参数上。
4结束语
中文微博的情感研究起步较晚,受限于目前并不完善的情感词典及测试集,本文提出的融合算法对情感分类的判别结果有所提升,但提升幅度有限。其中,表情加权规则的加入对微博极性的判断有一定的修正作用,语义规则的加入对含有复杂句式较多的正向微博和中性微博的情感数值判定有一定的提升作用,但总体效果仍旧难以达到理想的程度。
后续的改进可以着手于添加更多的语义规则以及对句子主题的提取,也可以融合机器学习或深度学习,使得在分析微博情感的时候能够有更多的特征可供使用,结果自然也更准确。
参考文献:
[1]PAK A, PAROUBEK P. Twitter as a corpus for sentiment analysis and opinion mining[C]∥Proceedings of the Seventh Conference on International Language Resources and Evaluation. Valletta, Malta: LREC,2010:1320-1326.
[2]周胜臣,瞿文婷,石英子,等. 中文微博情感分析研究综述[J]. 计算机应用与软件,2013,30 (3):161-164,181.
ZHOU Shengchen, QU Wenting, SHI Yingzi, et al. Overview on sentiment analysis of Chinese microblog[J]. Computer Applications and Software, 2013,30 (3):161-164,181.
[3]ZHANG H. The optimality of naive bayes[C]∥Proceedings of the Seventeenth International Florida Artificial Intelligence Research Society Conference. Miami Beach, Florida, USA: DBLP, 2004:562-567.
[4]GO A, BHAYANI R, HUANG L. Twitter sentiment classification using distant supervision[J]. CS224N Project Report, Stanford, 2009, 44(1):1-12.
[5]JIANG Long,YU Mo,ZHOU Ming,et al. Target-dependent twitter sentiment classification[J]. Meeting of Association for Computational Linguistica, 2011, 26(3): 151-160.
[6]徐琳宏,林鸿飞. 基于语义特征和本体的语篇情感计算[J].计算机研究与发展,2007,44(3):356-360.
XU Linhon, LIN Hongfei. Discourse affective computing based on semantic features and ontology[J]. Journal of Computer Research and Development, 2007,44(3):356-360.
[7]李钝,曹付元,曹元大,等. 基于短语模式的文本情感分类研究[J].计算机科学,2008,35(4):132-134.
LI Dun, CAO Fuyuan, CAO Yuanda, et al. Text Sentiment Classification Based on Phrase Patterns[J]. Computer Science, 2008,35(4):132-134
[8]刘志明,刘鲁. 基于机器学习的中文微博情感分类实证研究[J]. 计算机工程与应用, 2012,48(1):1-4.
LIU Zhiming, LIU Lu. Empirical study of sentiment classification for Chinese microblog based on machine learning[J]. Computer Engineering and Applications, 2012,48(1):1-4.
[9]谢丽星,周明,孙茂松. 基于层次结构的多策略中文微博情感分析和特征抽取[J].中文信息学报, 2012,26(1):73-83.
XIE Lixing, ZHOU Ming, SUN Maosong. Hierarchical structure based hybrid approach to sentiment analysis of Chinese mico blog and its feature extraction[J]. Journal of Chinese Information Processing, 2012,26(1):73-83.
[10] 朱嫣岚,闵锦,周雅倩,等. 基于HowNet的词汇语义倾向计算[J]. 中文信息学报, 2006(01):14-20.
ZHU Yanlan, MIN Jin, ZHOU Yaqian, et al. Semantic Orientation Computing Based on HowNet[J]. Journal of Chinese Information Processing, 2006(01):14-20.
[11] 蔺璜,郭姝慧. 程度副词的特点范围与分类[J]. 山西大学学报:哲学社会科学版,2003(02):71-74.
LIN Huang, GUO Shuhui. The feature scope and classification of adverb of degree[J]. Journal of Shanxi University: Philosophy & Social Science, 2003(02):71-74.
[12] 王志涛,於志文,郭斌,等. 基于词典和规则集的中文微博情感分析[J]. 计算机工程与应用,2015,51(8):218-225.
WANG Zhitao, YU Zhiwen, GUO Bin, et al. Sentiment analysis of Chinese micro blog based on lexicon and ruleset[J]. Computer Engineering and Applications, 2015,51(8): 218-225.
[13] 王文,王树锋,李洪华. 基于文本语义和表情倾向的微博情感分析方法[J]. 南京理工大学学报,2014(06):733-738,749.
WANG Wen, WANG Shufeng, LI Honghua. Microblogging sentiment analysis method based on text semantics and expression tendentiousness[J]. Journal of NanJing University of Science and Technology. 2014(06):733-738,749.
[14] LI Guangxia,HOI S C H,CHANG Kuiyu,et al. Micro-blogging sentiment detection by collaborative online learning[C]//Proceedings of the 2010 IEEE International Conference on Data Mining. Sydney,Australia: IEEE, 2010:893-898.
DOI:10.3979/j.issn.1673-825X.2016.04.010
收稿日期:2016-02-14
修订日期:2016-04-15通讯作者:赵天奇 zhaotianqi@bupt.edu.cn
基金项目:国家自然科学基金(61471056);江苏省科技计划项目(BY2013095-3-1,BY2013095-3-03)
Foundation Items:The National Natural Science Foundation of China (61471056);The Science and Technology Program of Jiangsu Province(BY2013095-3-1,BY2013095-3-03)
中图分类号:TP391
文献标志码:A
文章编号:1673-825X(2016)04-0503-08
作者简介:

赵天奇(1992-),男,内蒙古赤峰人,硕士研究生,主要研究方向为大数据技术、自然语言处理。E-mail:zhaotianqi@bupt.edu.cn。

姚海鹏(1983-),男,河北张家口人,讲师,硕士生导师,主要研究方向为未来网络体系架构、网络大数据、新一代移动通信体系架构及关键技术、物联网体系架构等。

方超(1985-),男,湖北武汉人,博士,主要研究方向为未来网络体系架构设计、内容中心网络缓存、能效、移动性管理技术,网络大数据架构设计及关键技术。
张俊东(1992-),男,北京人,硕士研究生,主要研究方向为大数据技术,自然语言处理等。
张培颖(1981-),男,辽宁盘锦人,博士研究生,主要研究方向为网络大数据架构及关键技术,信息中心网络关键技术等。
(编辑:刘勇)
Microblogging sentiment analysis method with the combination of semantic rules and emoticon weighting
ZHAO Tianqi, YAO Haipeng, FANG Chao, ZHANG Jundong, ZHANG Peiying
(State Key Laboratory of Networking and Switching Technology, Beijing University of Posts and Telecommunications, Beijing 100876, P.R. China)
Abstract:Current Chinese microblog sentiment analyses usually use emotional polarity classification result as evaluation standard. To improve the accuracy of the result, this paper considers the elements which may have influence on micro-blog sentiment as much as possible. On the basis of microblogging emotional words, emoticon information is additionally considered for weighted processing, improving the emotional polarity classification result of microblogs which contain emoticons. Then semantic rules, including several common sentence rules and sentence relationship rules, are covered to make a better result of sentimental analyses of complex statements. Meanwhile, we calculate the score of each blog, which is judged by qualification rate. Finally, through Hadoop platform, 10 000 sets of data were tested and verified the validity of the fusion algorithm.
Keywords:microblog; sentiment analysis; semantic rules; emoticon
猜你喜欢
中国校外教育(2024年3期)2024-07-13 00:00:00
电脑知识与技术(2017年3期)2017-03-27 14:05:09
智能计算机与应用(2017年1期)2017-03-23 13:24:04
物联网技术(2016年11期)2017-01-12 19:41:22
电子技术与软件工程(2016年22期)2016-12-26 21:36:42
预测(2016年5期)2016-12-26 17:16:57
中国市场(2016年38期)2016-11-15 23:47:47
人间(2016年26期)2016-11-03 18:19:04
中国科技博览(2016年18期)2016-10-19 08:07:17
电脑知识与技术(2016年5期)2016-04-14 13:51:02
