
基于数据挖掘的茶叶价格鉴定
2016-08-04 08:21周绮凤丁健超
厦门大学学报(自然科学版) 2016年4期
刘 臻,周绮凤,丁健超
(厦门大学航空航天学院,福建厦门361005)
基于数据挖掘的茶叶价格鉴定
刘臻,周绮凤*,丁健超
(厦门大学航空航天学院,福建厦门361005)
摘要:针对茶叶价格鉴定中传统感官评审方法遇到的问题与挑战,利用数据挖掘技术,研究茶叶价格自动评定模型与方法.在已有研究的基础上,对茶叶价格鉴定中的多个属性进行重要性分析、关联分析等,并建立一个基于随机森林的茶叶价格评定模型.该模型基于已有历史数据的分析和学习,对新茶叶的价格鉴定可以给出较为客观的评定,从而降低人工评定的代价和人为生理因素的影响.在实际收集的铁观音茶叶数据集上的实验结果表明,所提出的方法与模型具有客观、准确的评价结果,可以作为茶叶价格评定的辅助评价模型.
关键词:数据挖掘;茶叶价格;鉴定;随机森林
茶是我国的传统饮料,居世界三大饮料(茶叶、可可、咖啡)之冠.中国茶文化具有悠久的历史,茶叶品质鉴定是其中的一个重要内容,感官评审和理化检测是最常用的2种评定方法.其中,感官评审主要依靠品茶师的经验,通过对茶叶的观察和品尝,在几秒钟内,对茶叶的外观和内质做出评定.但是,这种依赖于专业品茶师的主观评定方法经常会受到环境条件以及品茶师个人的生理条件和工作经验等因素的影响.对同一个茶样,不同的品茶师可能得到不同结果,即使是同一个品茶师,在不同的环境和生理条件下,也会得出不同的评价结果.此外,评茶过程中所使用的标准样的制作会受到各种条件的限制,很难保持一致,这也影响到评茶的结果[1].
随着计算机技术逐步应用到食品检测等问题中,茶叶生产企业逐步积累了大量检测数据.如何从众多的数据中自动挖掘出有用的知识,成为理论和应用研究的一个共同研究热点.目前数据挖掘技术正在许多领域得到广泛应用[2-4],部分研究者尝试将数据挖掘方法应用到茶叶鉴定中.张超等[5]对数据挖掘在茶叶鉴定中的应用做了简单概述.章文军等[6]利用自组织映射神经网络对国内的茶叶品种进行分类.唐和平等[7]利用人工神经网络(ANN)进行茶叶品质的分析.潘玉成[8]将神经网络应用于茶叶评审中,参照铁观音标准样的5级和茶叶的外形及内质共40条评语(属性值),并随机从市场销售的茶样中抽取了10个样本,建立了一个3层神经网络模型,其评级结果与感官评审结果基本一致.
上述研究是采用数据挖掘技术在茶叶价格鉴定中的初步尝试性工作,这些研究所用的方法单一且实验数据较少,实验结果缺乏统计意义.此外,Dutta等[9]结合主成分分析、模糊C均值聚类、神经网络等方法对茶叶数据进行预处理,并采用氧化锡电子鼻方法对茶叶质量进行预测.Hung等[10]提出一种基于指数距离函数的模糊聚类方法,并将该方法应用于台湾地区茶叶的4个属性多种类型的评估中.迄今为止,基于数据挖掘方法的茶叶价格鉴定研究还较少.由于茶叶种类繁多、价格差异较大,针对大量的茶叶鉴定资料、茶叶种植数据,如何运用数据挖掘技术进行更为深入的分析和研究,建立自动、客观的茶叶价格评价体系和模型,具有实际意义和应用价值.
1茶叶价格鉴定概述
茶叶价格鉴定是茶叶鉴别的主要内容之一,也是影响茶叶销售和茶叶生产企业效益的重要因素.从评价方法上来说,目前茶叶鉴定主要采用理化检测和感官评审2种方法.
理化检测使用仪器仪表、分析化验等物理和化学方法鉴定茶叶所含的各种成分.由于理化检测对检验环境的要求比较高,而且检验时间比较长,一般的茶叶销售企业和地方检测机构都难以配置.茶叶产品的感官审评主要根据国家标准中对各类茶叶品质特征的描述和要求,以及实物标准样和贸易样等,对拟检茶叶产品进行评审.与理化检测相比,评茶师评定的方法较为简单,但如上所述,这种方法太依赖个人的主观情况,因此,评价结果也缺乏准确性.

图1 茶叶感官评审过程Fig.1Tea sensor-based evaluation process
茶叶评审内容通常包括外观和内质两个方面.其中外观评审主要通过对茶叶外观的大小、松紧、色泽、嫩度、平滑程度等的观察,来判断茶叶产品是否符合其茶类的品质要求并判定其在该茶类中所处的级别.内质评审则主要依据品尝茶叶的香气类型、滋味鲜爽度、浓度,观察茶汤颜色与明亮程度,以及茶底的颜色和匀整度等特征来判断.茶叶感官评审过程如图1所示,这些过程通常由经验丰富的品茶师及相关辅助人员共同完成.
2基于数据挖掘的茶叶价格鉴定模型
茶叶感官评审通过多年的品质鉴定已积累了大量的审评数据,如何利用这些数据构建一种客观、准确、便捷,能适应生产、加工、检验各环节使用的评定方法,克服鉴定师的主观鉴定缺陷,是茶叶加工企业亟待解决的一个问题.数据挖掘作为一种决策支持过程,能自动地对大量数据进行分析,挖掘隐含在海量数据中的潜在知识,从而帮助决策者做出正确的决策.本文中通过对茶叶数据的整理和分析,利用数据挖掘的回归、分类、特征选择等算法建立一个高效准确的茶叶价格鉴定模型,该模型如图2所示,主要包括数据预处理、重要属性分析和预测模型几个模块.
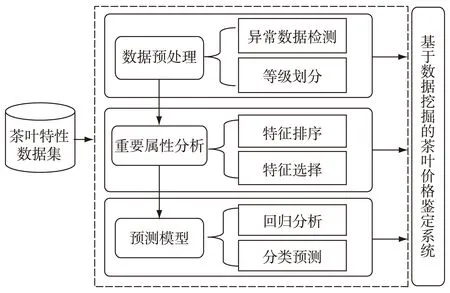
图2 基于数据挖掘的茶叶价格鉴定系统Fig.2Evaluation system of tea price based on data mining
2.1数据预处理
由于茶叶品种众多,品质差异较大,且在收集过程中存在误差等问题,在进行茶叶价格自动鉴定之前需要对众多的茶叶数据进行分类和过滤,对不同系列的茶叶产品需要分别进行价格评审[11-12].
2.2重要属性分析
本模型采用基于随机森林(random forests, RF)的变量重要性排序,找到影响茶叶价格的重要属性,从而为最终的定价提供参考[13-15].
基于RF的变量重要性[16]: RF的性质之一是在学习过程中可以很自然地提供变量重要性(即特征排序),其过程如下:
2) 从Dn中有放回的随机抽取n1个样本,得到训练集Xi,每个决策树在训练过程中没有采用的样本称为OOB(out of bag)样本.

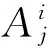
5) 第i个特征的重要性得分根据下面式子计算:
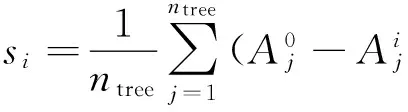
6) 对这些得分按从大到小进行排序得到{sd1,sd2, …,sdn},那么{d1,d2,…,dn}就是所求的特征排序.
2.3预测模型
回归分析:传统的感官评审采用对各个特征分别打分,再通过浮动参考价格,进行人工微调,累计得到最终的价格.利用回归分析,可以确定茶叶品质特征(属性)与最终定价之间的定量关系,并得到一个自动评分模型.
分类预测:茶叶的价格是决定茶叶等级的最主要因素.本研究根据茶叶价格对数据进行分类处理,建立基于RF的分类预测模型,该模型可以根据茶叶的品质特征自动预测茶叶所属的等级.
基于RF的茶叶分类预测模型:
1) 设N为训练样本个数,M为变量重要性分析后选取的评估特征数目.
2) 输入特征数目mtry,用于确定决策树上一个节点的决策结果,其中mtry应远小于M.
3) 从N个训练样本中采用bootstrap方法采样,形成一个训练集,并用未抽到的样本(OOB样本)作预测,评估其误差.
4) 对于每一个节点,随机选择mtry个特征,根据这mtry个特征,计算最佳的分裂方式.
5) 每棵树都不用剪枝(pruning),任其生长,最终生成ntree棵树.
6) 采用多数投票法对新样本进行分类.
3实验及分析
以实际收集到的福建省某企业铁观音茶叶数据为例,对所提出模型进行验证.该数据集包括1 604个样本,外观特征:条形、色泽;内质特征:香气、汤色、滋味、叶底、质量、总分,样本点的分布如图3所示.
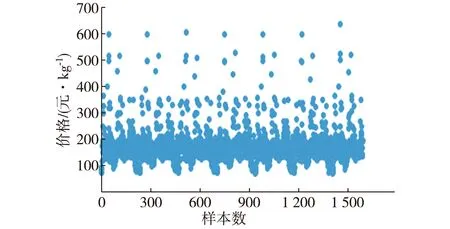
图3 铁观音茶叶数据分布图Fig.3Distribution of Tieguanyin tea data
根据样本点的分布及茶叶定价体系,把数据分为4个等级,如表1所示.
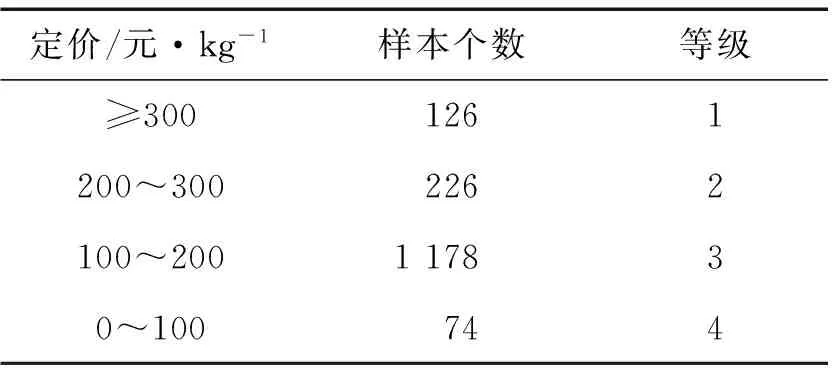
表1 样本等级Tab.1 Sample grades
3.1异常值检测
采用凝聚层次聚类(agglomerative hierarchical clustering )对样本数据进行聚类.实验中采用单链法(single linkage method)计算邻近度矩阵,聚类评价指标采用KL(Krzanowski-Lai)指标,记为PKL计算每个类紧密度的平均值,KL值越大越好.

(1)
其中,
R(i)=
(2)
是紧密度.这里R(i)的紧密度定义是Pearson相关系数的平方和,这个系数用来衡量两个数据集合的线性相关关系.
利用上述方法,剔除茶叶数据中的异常值,部分异常值如图4所示.
3.2回归分析
利用回归分析可以自动地确定茶叶属性和最终定价之间的依赖关系.图5所示为各个特征和定价的散点图.
在实际应用中,关注的一个问题是总分与茶叶的定价之间是否有显著的相关性,即传统的打分法得到的总分是否可以客观地反应茶叶的定价.利用回归分析,对原始数据与定价做了相关分析,结果如表2所示.
由散点图和相关分析的结果可以看出,总分与定价之间具有较大的相关性.在此基础上,进一步通过回归分析建立回归模型.由实验数据得到的线性拟合结果如图6(a)所示,该模型误差较大;由实验数据得到的二次拟合结果如图6(b)所示,该模型与数据分布拟合效果较好,其曲线为:y=213.488-5.381 2x+0.051 2x2.

图4 异常值检测Fig.4Outlier detection
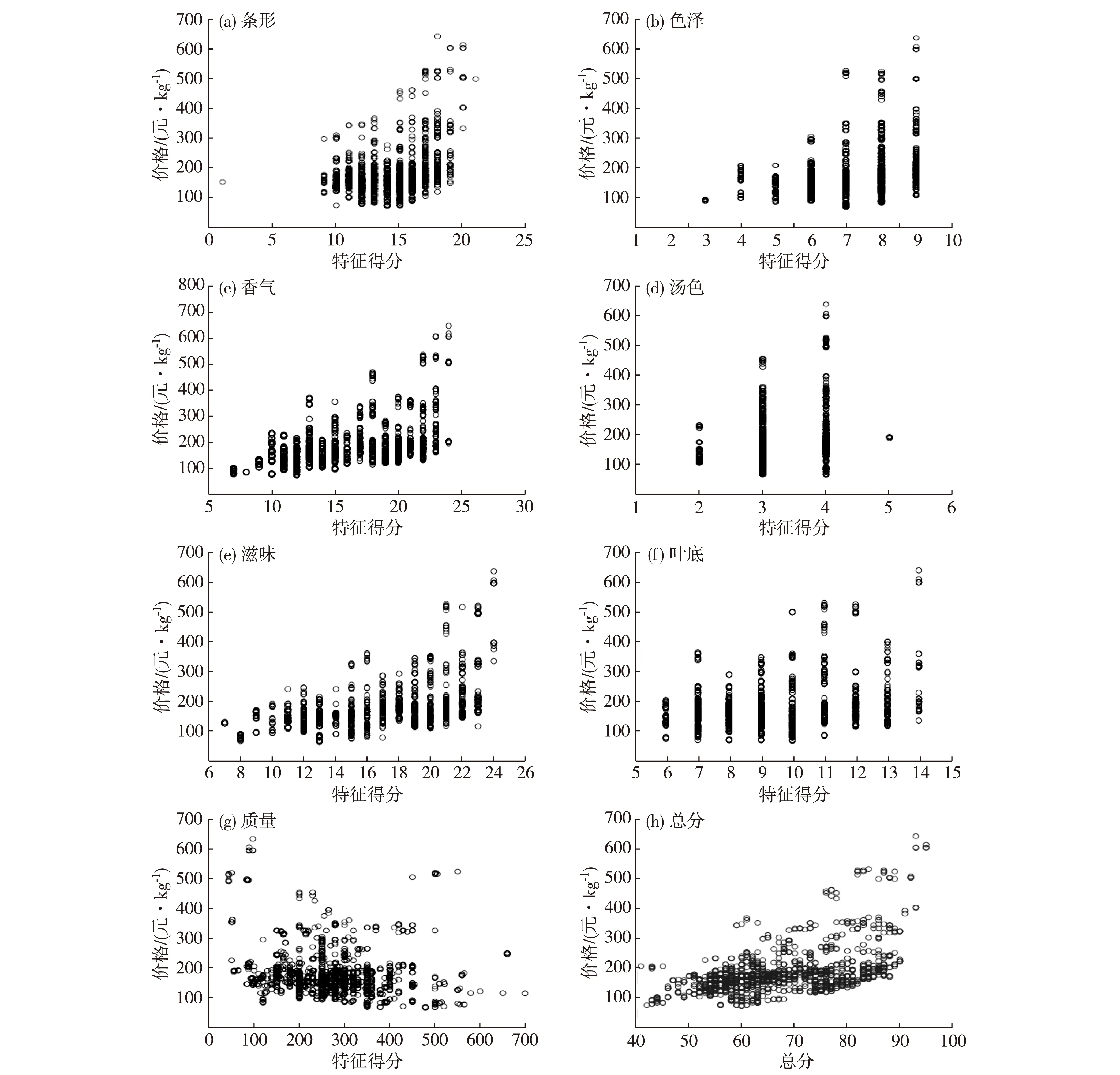
图5 铁观音茶叶数据属性与定价散点图Fig.5Scatterplot between attributes and price

相关系数r条形色泽香气汤色滋味叶底质量总分0.360.300.450.250.450.30-0.0830.50
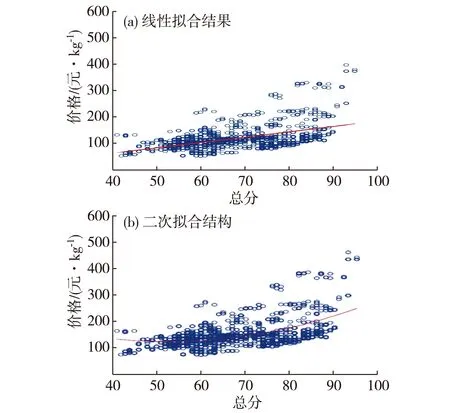
图6 总分与定价之间的拟合结果Fig.6Results of regression analysis between total score and price
3.3分类预测及变量重要性分析
采用RF对预处理后的数据进行建模,用十折交叉验证的方法检验数据的预测准确率,其中选择决策树的个数为ntree=1 500, 叶节点上随机分裂属性个数为mtry=3.根据茶叶的外形和内质6个特征,我们得到变量重要性从大到小的排序,依次为:香气、滋味、叶底、条形、色泽、汤色,该结果与回归分析结果相一致.同时利用各特征建立的分类预测模型(RF)及和常用的ANN方法的性能比较如表3所示.
由表3可知,基于RF的茶叶价格预测模型能够给出较为准确的预测结果.与传统的ANN方法相比,RF在准确率和稳定性方面都有更好的表现,这也体现出RF作为一种组合分类器方法的优势.此外,由表3可知,在所有的属性中,内质的4个特征,即:香气、汤色、滋味、叶底对定价预测准确率的提高效果最明显,这也是茶叶消费者最注重的特征,符合茶叶市场的定价规律.因此,本文提出的基于数据挖掘方法的茶叶价格鉴定系统具有较好的预测准确率和实用价值.

表3 基于RF的分类模型预测结果Tab.3 The predicting results of classification model based on RF
注:表中数据为平均值±标准差.
4结论
基于数据挖掘的茶叶价格自动鉴定是填补目前人工鉴定方法中存在的不足的一种有效途径.本文中利用茶叶的属性数据,提出一种基于数据挖掘的茶叶价格自动鉴定系统,并通过回归分析、特征选择、分类预测等数据挖掘方法,建立了一个茶叶价格鉴定模型.该模型基于已有历史数据的分析和学习,对新茶价格的评估可以给出较为客观的评定,从而降低人工鉴定的代价和人为生理因素的影响.由于茶叶价格的最终确定还需要考虑茶叶的生产时间、天气、产地等因素,未来的研究将在外观和内质的基础上考虑上述因素,提出更全面的评价模型.
参考文献:
[1]霍红.模糊数学在食品感官评价质量控制方法中的应用[J].食品科学,2004,25(6):185-188.
[2]李涛,唐良,李磊,等.数据挖掘的应用与实践:大数据时代的案例分析[M].厦门:厦门大学出版社,2013:10.
[3]ZHOU Q,ZHOU H,ZHU Y,et al.Data-driven solutions for building environmental impact assessment[C]∥ IEEE International Conference on Semantic Computing(ICSC).Anaheim:IEEE,2015:316-319.
[4]李涛,曾春秋,周武柏,等.大数据时代的数据挖掘:从应用的角度看大数据挖掘[J].大数据,2015,1(4):2015041.
[5]张超,张娅玲,杨如艳.数据挖掘在茶叶鉴定中的应用[J].安徽农业科学,2012,40(2):1219-1220.
[6]章文军,许禄.自组织特征映射神经网络——用于茶叶分类[J].计算机与应用化学,2000,17(1):85-87.
[7]唐和平,黎星辉.神经网络技术及其在茶叶中的应用[J].茶叶通讯,1999,3:29-31.
[8]潘玉成.人工神经网络及其在茶叶审评中的应用[J].茶叶科学技术,2007(3):34-37.
[9]DUTTA R,HINES E L,GARDNER J W,et al.Tea quality prediction using a tin oxide-based electronic nose:an artificial intelligence approach[J].Sensors and Actuators B:Chemical,2003,94(2):228-237.
[10]HUNG W L,YANG M S.Fuzzy clustering on LR-type fuzzy numbers with an application in Taiwanese tea evaluation[J].Fuzzy Sets and Systems,2005,150(3):561-577.
[11]ZHENG L,LI T.Semi-supervised hierarchical clustering[C]∥11th International Conference on Data Mining(ICDM).Vancouver:IEEE,2011:982-991.
[12]TAN P N,STEINBACH M,KUMAR V.Introduction to data mining[J].Silicates Industriels,2006,50(4):209-210.
[13]BREIMAN L.Random forests[J].Machine Learning,2001,45(1):5-32.
[14]BREIMAN L.Bagging predictors[J].Machine Learning,1996,24(2):123-140.
[15]HO T K.The random subspace method for constructing decision forests[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1998,20(8):832-844.
[16]周绮凤,洪文财,杨帆,等.基于随机森林相似度矩阵差异性的特征选择[J].华中科技大学学报(自然科学版),2010,38(4):58-61.
doi:10.6043/j.issn.0438-0479.201507001
收稿日期:2015-07-01录用日期:2016-04-27
基金项目:国家自然科学基金(61503313);江苏省社会安全图像与视频理解重点实验室创新基金(30920140122007)
*通信作者:zhouqf@xmu.edu.cn
中图分类号:TP 18
文献标志码:A
文章编号:0438-0479(2016)04-0586-06
Data Mining Based Solutions for Tea Price Evaluation
LIU Zhen,ZHOU Qifeng*,DING Jianchao
(School of Aerospace Engineering,Xiamen University,Xiamen 361005,China)
Abstract:Traditional tea price evaluation mainly depends on the experience of tea experts and evaluating results are usually unstable and imprecise.To solve this problem and obtain some more objective evaluation results,we propose a data-driven tea price evaluation framework.This framework incorporates the outlier detection,feature-importance analysis,regression,and classification forecast models.Experimental evaluation on the real Tieguanyin tea data demonstrates the effectiveness of our proposed framework.
Key words:data mining;tea price;evaluation;random forest
引文格式:刘臻,周绮凤,丁健超.基于数据挖掘的茶叶价格鉴定[J].厦门大学学报(自然科学版),2016,55(4):586-591.
Citation:LIU Z,ZHOU Q F,DING J C.Data mining based solutions for tea price evaluation[J].Journal of Xiamen University(Natural Science),2016,55(4):586-591.(in Chinese)
猜你喜欢
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
安徽农学通报(2017年1期)2017-02-15
软件(2016年7期)2017-02-07
南水北调与水利科技(2016年6期)2017-01-06
职工法律天地·下半月(2016年10期)2016-11-30
资治文摘(2016年7期)2016-11-23
农业与技术(2016年15期)2016-11-09
电脑知识与技术(2016年23期)2016-11-02
企业导报(2016年8期)2016-05-31
