
一种半监督的局部扩展式重叠社区发现方法
2016-07-19 02:15:49陈俊宇
计算机研究与发展 2016年6期
关键词:复杂网络
陈俊宇 周 刚 南 煜 曾 琦
(数学工程与先进计算国家重点实验室 郑州 450002)(junychen1107@gmail.com)
一种半监督的局部扩展式重叠社区发现方法
陈俊宇周刚南煜曾琦
(数学工程与先进计算国家重点实验室郑州450002)(junychen1107@gmail.com)
摘要重叠社区发现是近年来复杂网络领域的研究热点之一.提出一种半监督的局部扩展式重叠社区发现方法SLEM(semi-supervised local expansion method).该方法借鉴了带约束的半监督聚类的思想,不仅利用网络的拓扑结构信息,还充分地利用网络节点的属性信息.首先将网络节点的属性信息转化为成对约束,并根据成对约束修正网络的拓扑结构,使网络中的社区结构更加明显;然后基于网络节点的度中心性选取种子节点,得到分散的、局部节点度大的种子作为初始社区;再采用贪心策略将初始社区向邻居节点扩展,得到局部连接紧密的社区;最后检测并合并冗余社区,得到高覆盖率的社区发现结果.在模拟网络数据和真实网络数据上与当前有代表性的基于局部扩展的重叠社区发现算法进行了对比实验,结果表明SLEM方法在稀疏程度不同的网络上均能发现较高质量的重叠社区结构.
关键词复杂网络;重叠社区发现;半监督聚类;局部扩展;SLEM方法
网络是事物之间相互关联的一种模式,现实世界的很多系统都是由相互联系的实体组成的,自然地以网络的形式存在或者可以用网络来表示[1].复杂网络一般指节点众多、连接关系复杂的网络,能够广泛应用于各科学领域对复杂系统进行建模和分析.复杂网络的社区结构特性是继小世界特性和无标度特性被发现后的又一个重要结构特性.社区结构普遍存在于现实网络中,一般由功能相近或性质相似的网络节点组成,刻画了节点间关系的局部聚集特性,其内部的节点连接相对紧密,不同社区间的连接则相对稀疏[2].近年来,复杂网络中的社区发现已经成为复杂网络领域的研究热点之一.社区发现有助于理解网络的拓扑结构及功能结构,从而为利用和改造网络提供指导,对分析网络特性具有极为重要的意义[3].
早期对于社区发现的研究主要关注网络中非重叠社区结构,即假设每个节点属于单一的社区,而现实世界中的真实社区结构往往会产生交叉重叠.为此,不少重叠社区算法被提出用于解决网络中重叠社区结构发现的问题.这些方法可归纳为基于网络局部拓扑信息和基于网络全局拓扑信息的方法.
基于网络局部拓扑信息的方法,是从网络中的节点开始,利用节点的局部连接结构信息采用优化某种局部目标函数的策略,达到发现社区结构的目的.基于网络局部拓扑信息的方法包括局部扩展法[4-6]和标签(tag)传播法[7-8]:局部扩展法从不同种子节点开始,探索种子所在的局部社区结构,各个局部社区结构融合形成网络整体的重叠社区结构;标签传播法初始给各节点分配唯一标签,然后根据邻居节点信息更新标签直到收敛,最终标签相同的节点被划分到相同社区.该类方法的优势在于有较高的时间效率,不足之处是其社区发现的效果不够好.
基于网络全局拓扑信息的方法,利用网络的全部拓扑结构,对某种全局目标函数进行优化,以发现网络中的社区结构.基于网络全局拓扑信息的方法包括派系过滤法[9-10]、非负矩阵分解法[11-14]以及基于统计模型的方法[15-17]:派系过滤法将社区视为由一些团(全连通子图)构成的集合,团之间通过共享节点而紧密连接;非负矩阵分解法对邻接矩阵或其他特征矩阵进行分解得到各节点对于不同社区的参与度,该方法能够定性和定量地评价节点对于社区的隶属关系;基于统计模型的方法将网络拓扑结构作为观测量,通过假设概率分布参数(通常与社区结构有关)计算节点之间的连接概率,最后生成整个网络,对应的参数即为节点隶属于不同社区的概率.基于网络全局信息的方法能够得到较好的社区发现结果,但其时间开销较大,不容易扩展到大规模网络.
尽管当前学术界对重叠社区发现这一问题的研究已经取得不少成果,随着信息时代数据爆炸式地增长,真实网络的结构变得更加复杂,网络的规模日趋庞大,因此重叠社区发现的难度也随之变大[18-19].重叠社区发现仍然是复杂网络领域中一个值得深入研究的课题.
本文提出一种半监督的局部扩展式重叠社区发现方法——SLEM(semi-supervised local expansion method),包括基于成对约束的网络结构修正、基于节点度中心性的种子选取、局部扩展式的自然社区发现以及社区结果的对比与合并.SLEM方法的主要贡献有3点:
1) 利用部分标注信息指导社区发现算法的执行,避免了传统非监督类算法的盲目性问题;
2) 基于节点度中心性的种子选取规则能够得到局部性好、结构稳定的社区发现结果,避免了结果的抖动性问题;
3) 对社区结果的对比与合并能够在保证高社区覆盖率的前提下尽量减少冗余的社区.
本文分别在基准模拟网络和真实网络上对SLEM方法的性能进行测试,并同当前具有代表性的基于局部扩展的重叠社区发现算法进行了对比分析,结果表明该方法在稀疏程度不同的网络上均能发现较高质量的重叠社区结构.
1相关工作
1.1基于局部扩展的重叠社区发现算法
复杂网络通常可由图G=(V,E)来表示,其中V={v1,v2,…,vn}表示节点的集合,n为节点个数;E={e1,e2,…,em}表示边的集合,m为边的条数.复杂网络中的重叠社区发现问题可以描述为找到图G的一个划分P=(C1,C2,…,CK),满足条件:

基于局部扩展的重叠社区发现算法,通常从不同种子节点开始,根据设定的某优化函数,探索种子所在的局部社区结构,各个局部社区结构融合形成网络整体的重叠社区结构.代表算法有LFM算法[4]和GCE算法[5].
1) LFM算法
LFM算法的基本思路是每次在网络中随机选取一个尚无社区标签的节点作为种子,然后采用一种贪心的策略将种子扩展为一个局部自然社区,直到网络中所有节点都有社区标签为止.
在局部扩展的过程中,LFM算法通过不断对当前子图增加或者删除节点使得适应度函数值达到局部最大值,其设定的适应度函数(fitness function)为
(1)

具体地, LFM算法每一次迭代都会对当前社区C添加一个节点使得适应度函数达到最大,得到社区C′,然后重新计算C′内所有节点的适应度,删除适应度为负的节点,得到社区C″.重复执行直到适应度函数不再增大时停止.其中节点v的适应度定义为

(2)
LFM算法随机选取种子节点导致其存在社区发现结果依赖所选种子质量的问题.该算法扩展策略的删除节点操作可能会导致最初的种子节点被删除,使得扩展过程不再围绕该种子进行,违背社区的“局部性”[6,18].
2) GCE算法
GCE算法在整个算法执行的初始阶段,在网络中找出所有节点规模不小于k的最大团(全连通子图)作为种子;然后同样采用贪心的策略对种子进行扩展得到局部自然社区,其设定的适应度函数与LFM算法相同.
该算法在扩展的每一次迭代中仅添加使得适应度函数最大的节点,得到社区C′.重复执行直到适应度函数不再增大,然后将此时的社区Ct同之前已检测到的所有社区C1,C2,…,Ct-1按照距离计算公式:
(3)
计算二者的距离,如果δ小于某个给定的阈值ε则判定为相似,舍去Ct,否则保留Ct.
GCE算法选取的种子存在相似性,导致不同种子扩展得到非常相似甚至冗余的社区.该算法在种子扩展的过程中由于存在社区删除操作,会使得最终得到的所有社区只能覆盖到整个网络的一部分节点,而非整个网络,即在算法执行结束后存在一部分社区标签仍然未知的节点.
1.2带约束的半监督聚类
机器学习中的聚类问题通常意义上讲属于非监督学习的范畴,因为一般认为没有已知标签的数据点.但是当对数据引入成对约束(pairwise constraints),或者已知部分数据点有明确的簇类标签时,这些信息能够给聚类过程提供指导,从而提高聚类的效果,此时聚类就变成一个半监督的学习问题[20-21].
成对约束通常包括必然连接(must-link)和不可能连接(cannot-link).必然连接表示一对数据点属于同一个簇类,不可能连接表示一对数据点属于不同的簇类.
对于一些实际应用中的聚类问题,事先准确得到某一个数据点的簇类标签是不现实的,因为在得到聚类结果前无法获知数据集由哪些具体的簇类组成.然而,某一对数据点是否属于同一个簇类,则可通过人工对这一对数据点进行简单比较获知.因此,成对约束信息相比于明确的数据标签信息更容易获得.
类似地,复杂网络中的某一个节点的社区属性是不可能提前被获知的,而一对节点是否同时属于一个社区则可通过网络结构以及节点的某些属性信息进行判断.因此,在复杂网络中进行社区发现前,事先抽取一定数量的节点对,并人工对其进行标注,作为成对约束信息指导社区发现过程的执行,可以避免无监督社区发现方法的盲目性,使社区发现结果的质量得到提升.
2半监督的局部扩展式重叠社区发现方法
本文提出一种半监督的局部扩展式的重叠社区发现方法,该方法综合利用网络的拓扑结构信息和网络节点属性信息,首先根据网络中的部分节点属性信息对网络的拓扑结构进行修正,然后利用网络节点的拓扑特征(度中心性)选取种子节点作为初始社区,再采用贪心策略将种子扩展为局部自然社区,最后将不同社区进行对比与合并得到最终的社区发现结果.
2.1算法描述
1) 网络结构修正
社区发现问题传统的解决方案仅仅是针对网络的拓扑结构设计和执行的.在现实网络中,研究人员不但能够得到整个网络的拓扑结构,还能够获取网络中节点的某些属性,仅针对网络拓扑结构设计的社区发现算法忽略了大量的节点属性信息.
因此,本文提出一种基于成对约束的网络结构修正算法.该算法的核心思想是先随机选取网络中的一个节点对,再利用这2个节点的信息将此节点对进行标注为必然连接或不可能连接,然后将此成对约束通过同网络结构融合,对网络的结构进行修正.
该算法的核心步骤是节点对的人工标注和成对约束与网络结构的融合.网络中任意节点的属性信息可由一些标签组成的集合来表示,对随机选取的一个节点对,若二者的标签集合的交不为空,则表明这2个节点在某些属性上具有相似性,然后人工地对这些共有属性进行判断,确定此对节点是否应当属于相同的社区.

(4)
其中,Aij为邻接矩阵第i行第j列的元素值,修正权重β≥1.通过这种方式,将成对约束融合到网络结构中,实现对网络结构的修正.
整个执行过程的伪代码如下:
算法1. 基于成对约束的网络结构修正算法.
输入:网络G=(V,E)、权重β、节点对数量n;
①VertexPairs←∅,count←0;
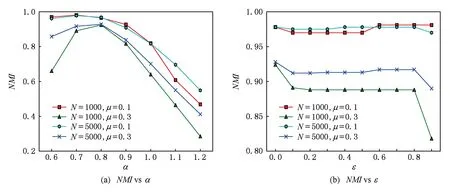
② whilecount ③ 从V×V中随机选取(u,v); ④ if (u,v)不在VertexPairs中 then ⑤ 人工标注(u,v); ⑥ if (u,v)是必然连接 then ⑦e.weight←β; ⑧ else if (u,v)是不可能连接 then ⑨ 删除e; ⑩ end if 这种基于成对约束的网络结构修正算法将传统的无监督社区发现转化为半监督社区发现,能够较显著地提升社区发现结果的质量. 2) 种子选取 对于大部分局部扩展式的重叠社区发现算法,种子的选取会影响其社区发现结果的质量[18].文献[4]提出的LFM算法采用随机选取种子的方法,不可避免地存在社区发现结果的不稳定性.文献[5]中的GCE算法则选取网络中的最大团作为种子,最大团表示网络中的全连通子图,即其包含的节点两两互相连接.如图1所示,节点集合{A,B,C}表示一个3-团,节点集合{A,B,C,D}表示一个4-团. Fig. 1 Demonstration of maximal cliques.图1 最大团示例 在给定的某个图中,相对于节点而言,最大团所处的位置是固定的,这使得种子选取的过程更遵循规则,避免了社区发现结果不稳定的问题. 然而这种种子选取方法却存在新的问题:1)引入了参数k,用于限制最大团的大小.较小的k会导致种子规模过大,使得社区的个数变大,不可避免地存在冗余社区;较大的k则会导致社区个数小,社区发现结果的覆盖率低,即存在一部分节点的社区属性未知.2)不同的最大团之间存在相似性.例如图1中节点集合{A,B,C,D}以及{A,B,C,E}都为4-团,而二者都包含子集{A,B,C},因此这2个种子是相似的,这种相似性导致通过不同种子扩展得到的社区是相似的,甚至是完全相同的冗余社区. 针对以上问题,本文提出选取网络中的核心节点作为社区种子.在现实网络中,核心节点对信息传播的贡献较大,通常位于网络中节点连接较紧密的区域.社区内部节点连接紧密,不同社区间节点连接稀疏,故网络中不同的社区恰好可同一部分互不邻接的、分散的核心节点形成一一对应,因而可选取网络中的一部分核心节点作为种子.核心节点可通过多种节点中心性指标定义,本文考虑其中最简单的节点度中心性作为核心节点的特征指标.整个种子选取过程的伪代码如下: 算法2. 种子选取算法. 输入:网络G=(V,E); 输出:种子集合S. ①S←∅; ②V中所有节点初始化为无标记; ③ whileV≠∅ do ⑤ forMaxDegreeSet中所有的vido ⑥ ifvi无标记 then ⑦ 设置vi的标记为i; ⑧S←S∪{vi}; ⑨ end if ⑩ 设置vi的邻居节点N(vi)标记为vi.label; 考虑到网络中可能存在若干个节点同时满足度最大的情况,算法2每轮迭代都会找出当前节点集合V中所有度最大节点构成的集合MaxDegreeSet,然后依次将点vi以及其邻居节点N(vi)作标记,再将vi加入种子集合S中,最后从节点集合V中移除已标记的节点集{vi}∪N(vi). 对于一对节点vi和vj同时为度最大节点且相邻接的情况,算法2在处理vi的过程中会用vi的索引值i对vj进行标记,在处理vj时vj是已被标注的节点,此时只用vj的标签i对其邻居节点进行标记,整个过程仅选取其中点vi作为种子加入到集合S中. 此种子选取策略的好处是能够在网络中发掘彼此分散的、局部节点度数大(即节点的度数相对于其邻居节点的度数较大)的节点,通过这些节点扩展得到的自然社区的局部性好,社区发现结果对全网络的覆盖率高. 3) 局部扩展发现自然社区 类似文献[4-5]中的LFM和GCE算法,本文采用贪心的策略对种子进行扩展得到相应的社区. 在局部目标函数的构造上,由于本文在整个算法第一阶段对网络中的连接进行修正,原始的无权网络G=(V,E)转变为加权网络G=(V,E,W),因此需要对式(1)进行修正. 定义2. 给定无向加权网络G=(V,E,W),∀vi∈G,定义vi的加权节点度di为与vi所有连边权重之和,即: (5) 其中,N(vi)表示节点vi所有邻居节点构成的集合.容易得到对于无权网络,连接的权重可视为1,此时式(5)等价于di=ki,即为vi的节点度. 定义3. 对于网络G=(V,E)的某个子图(即社区)C⊆G,社区C的邻居N(C)定义为 (6) 也可由节点邻居的定义推广得到: (7) 即社区C中所有节点的不在C中的邻居构成的集合. 定义4. 对于加权网络G=(V,E,W)中的某个社区C⊆G,社区C的适应度f(C)定义为 (8) (9) 由种子向局部扩展成为社区的策略与LFM算法类似,也是通过对当前社区C增加或者删除节点使得社区的适应度函数f(C)达到最大值.对某个给定种子节点s,其扩展为社区的执行过程的伪代码如算法3所示: 算法3. 种子扩展成社区. 输入:网络G=(V,E,W)、种子s、参数α; 输出:社区C. ①C←{s}; ②flag_1=0; ③ whileflag_1=0 do ④ for 对C的邻居节点集N(C)中所有 neighbordo ⑤ 计算f(neighbor); ⑥ end for ⑧ iff(v)<0 then ⑨flag_1=1; ⑩ else iff(v)≥0 then 可以看出,在每一轮迭代中都涉及到社区的更新,考虑到重新计算所有社区内节点以及社区邻居节点的适应度会增大计算开销,本文在算法3的实现中,对社区的内、外加权度数和进行更新为 (10) (11) 然后再按照式(8)对社区适应度进行计算. 另外,在此种扩展策略下,参数α实际上能够控制社区C的大小,故称α为分辨率参数: 4) 社区的对比与合并 非重叠社区发现问题要求不同社区的节点集是彼此互斥的,而重叠社区发现问题允许2个不同社区包含一些公共的节点,因此社区之间存在一定的相似性.当相似性达到一定程度时,则会出现“过度重叠”的现象,产生冗余的社区[5-6].因此有必要对社区发现结果进行后处理,发现冗余社区,简化社区结构. 类似GCE算法,本文采用式(3)计算不同社区间的距离.与其不同的是,本文在整个社区发现算法执行结束后再对社区结果进行处理. 具体地,对2个不同社区C1和C2,将由式(3)计算得到的距离δ(C1,C2)同设定的参数阈值ε进行比较.若δ(C1,C2)<ε,则认为C1和C2是相似的,保留C1∪C2作为一个社区;若δ(C1,C2)≥ε,则保留C1和C2这2个社区. 2.2方法时间复杂度分析 3实验结果与分析 本文分别在模拟网络数据和真实网络数据上对SLEM方法的性能进行验证,并同2种当前有代表性的LFM算法[4]和GCE算法[5]进行对比,二者都是基于局部扩展的重叠社区发现算法.另外,为验证基于成对约束的网络结构修正算法对传统非监督的局部扩展式方法的社区发现结果质量的提升效果,本文还将SLEM方法同朴素局部扩展方法(naive local expansion method, NLEM)进行了对比实验. 3.1在模拟网络数据集上的实验 1) LFR基准测试网络介绍 通过对LFR模型参数的调节,可以得到不同的拓扑结构性质逼近真实网络的模拟网络数据.此外,LFR模型还能够生成网络节点的社区划分,便于算法发现的社区划分结果同生成的社区结构进行对比,验证算法结果的准确性和算法的性能. 2) 社区发现结果评价指标 对于LFR基准测试网络,由于其社区结构已知,重点比较不同社区发现算法的结果与LFR网络的社区结构之间的相似程度.这种比较基于信息论的思想,采用规范互信息(normalized mutual information, NMI)指标[4]来度量. (12) X对Y的规范化条件熵为 (13) 类似可计算出Y对X的规范化条件熵H(Y|X),则规范化互信息可计算为 (14) 此评价指标NMI(X|Y)的取值范围为0~1,当NMI(X|Y)=1时,X与Y完美匹配. 3) 实验结果比较 实验根据N∈{1 000,5 000}和μ∈{0.1,0.3}生成4组不同节点规模和混合参数的LFR基准测试网络,其中每组LFR网络的参数Om∈[2,8],即每组包含7个重叠程度不同的网络数据集.其他参数设置相同的值:平均节点度k=10;最大节点度kmax=50;幂律分布指数τ1=-2,τ2=-1;重叠节点个数On=0.1N;社区大小的上下界cmin=20,cmax=100. 由于LFR模型能够生成网络节点的社区划分,本实验将LFR网络中节点的属性信息对应的标签集合抽象为该节点所属社区的ID编号组成的集合,对从网络中随机选取的2个节点,若二者标签集合的交不为空,则表明这2个节点属于相同社区,从而标注该节点对为必然连接,否则标注为不可能连接. 实验对于不同算法设置不同的参数,并选取各参数下NMI值中的最大值作为最终结果进行对比.具体地,对于LFM算法,与文献[4]相同,设置其参数α∈[0.8,1.6],取值间隔为0.1,运行次数r=3;对于GCE算法,与文献[5]相同,设置其参数k∈{3,4},参数α∈[0.8,1.6],取值间隔为0.1,参数ε=0.6;SLEM方法中,设置参数n=0.05N(N-1)2,设置β=1,参数α∈[0.6,1.2],ε∈[0,0.9],取值间隔均为0.1;NLEM算法不需要设置参数n和β,其他参数设置与SLEM方法相同. 各种算法在4组不同LFR基准测试网络下社区发现结果的NMI值如图2所示,其中横轴坐标表示重叠节点所属社区个数Om,纵轴坐标表示相应的NMI值. Fig. 2 Experimental results on LFR networks.图2 LFR网络上的社区发现结果 整体上看,随着重叠节点所属社区个数Om的增加,社区发现的难度越来越大,导致4种算法的社区发现结果质量逐渐降低,因此在所有网络上这4种算法得到的NMI值呈现下降的趋势. 当固定混合参数为μ时,随着节点数N从1 000增加到5 000,4种算法得到的NMI值基本保持稳定.这是因为基于局部扩展的方法仅从网络中的某个种子出发,探索其局部自然社区,并且探索的策略和过程仅与包含该种子的某个子图有关,与整个网络的全局拓扑结构无关.这表明基于局部扩展的重叠社区发现方法对网络的规模表现出一定的鲁棒性. 当固定节点数为N时,随着混合参数μ从0.1增加到0.3,网络中社区的内部节点连接社区外部节点的机会增大,导致社区的结构变得模糊,因此4种算法得到的NMI值都有不同程度的下降.其中NLEM和LFM算法相对于GCE算法的降幅更大.这表明在社区结构较不明显的网络中,基于团的种子选取表现出一定优势. 比较图2中NLEM算法与LFM算法的曲线可以看出,NLEM算法在绝大多数网络上的社区发现结果较明显地好于LFM算法.这是因为NLEM算法选取网络中的核心节点作为种子,扩展得到的社区具有更好的局部性;而LFM算法随机选取种子,其在扩展过程中可能因为某些种子的适应度函数值为负而被删除,导致社区的扩展过程不再围绕该种子进行,最终得到局部性较差的社区[6,18]. 比较图2中SLEM方法与GCE算法的曲线可以看出,SLEM方法的社区发现结果略好于GCE算法,特别在重叠节点所属社区个数2≤Om≤5时,SLEM方法社区发现结果的质量表现出一定优势.这是因为SLEM方法对社区发现结果进行了后处理,将冗余的社区合并而不是直接舍弃,保持网络社区高覆盖率,更符合社区的真实情况;而GCE算法则会存在一部分社区标签仍然未知的节点,导致社区发现结果质量较低. 比较图2中SLEM方法与NLEM算法的曲线可以看出,在网络的混合参数较低(μ=0.1)时,二者得到的NMI值非常接近.这是因为此时网络中的社区结构较为明显,非监督的NLEM重叠社区发现方法能够较准确地发现网络中的社区.当网络的混合参数较高(μ=0.3)时,NLEM算法得到的NMI值大幅下降,这时网络中的社区结构不明显,非监督的方法又存在一定盲目性,故得到的社区发现结果质量降低;而此时半监督的SLEM方法则表现出明显优势,这是因为其利用少量的成对约束对网络拓扑结构进行了修正,使整个社区发现过程在这些约束信息的指导下完成,因而能够发现更高质量的社区.另外,可以观察到随着网络中重叠节点所属社区个数Om逐渐增大,SLEM方法和NLEM算法的NMI值差距逐渐缩小.这表明当社区结构的重叠程度变大时,社区发现的难度变大,需要增加成对约束的数量才能保持社区发现结果质量的显著提升. 综上,SLEM方法相对于NLEM算法、LFM算法和GCE算法在LFR基准测试网络上能够得到较高质量的社区发现结果. 3.2在真实网络数据集上的实验 1) 真实网络数据介绍 实验在8个不同规模、不同类型的真实网络数据集上对算法的性能进行了对比验证.这些真实网络数据包括人物关系网络(Zachary,Lesmis,Football,PGP)、动物关系网络(Dolphins)、论文合作网络(CA-GrQc)、文件共享网络(P2P)以及产品销售记录网络(Amazon),基本信息如表1所示.更多信息可在http:www-personal.umich.edu~mejnnetdata以及 http:snap.stanford.edudata上找到. Table 1 Real World Network Datasets 2) 社区发现结果评价指标 对于真实网络数据,由于其实际社区结构是未知的,无法直接将社区发现结果与真实社区进行对比.实验采用重叠模块度(overlapping modularity,记为Qov)、社区连接密度(community link density, 记为Dav)和网络覆盖率(network cover rate, 记为Rcv)这3种指标对算法的性能进行验证. 重叠模块度[18]是将模块度[23](modularity,记为Q)的概念推广到重叠社区发现问题的一种被普遍用于验证重叠社区发现算法性能的指标.模块度能够度量划分得到的社区结构的稳定性,其定义如下: (15) (16) 其中,m为网络中总边数,K为社区个数,Aij为邻接矩阵第i行第j列的元素值,di为节点vi的度,Oi为节点vi所属社区的个数.可以看出对于非重叠社区划分,∀vi∈V有Oi=1,此时Q=Qov. 根据社区的定义,社区内部节点之间的连接较紧密,不同社区间的连接相对稀疏[2].社区内部的连接密度越大,表明社区的结构越明显.社区连接密度定义为 (17) 社区发现的目标是找出网络中每个节点所属的一个或多个社区.这对于基于局部扩展的重叠社区发现方法是一种比较理想的目标,在实际情况中此类算法在执行结束后会存在一部分社区标签仍然未知的节点,算法的实际目标是使发现的社区结构覆盖到网络中尽可能多的节点.因此针对基于局部扩展的重叠社区发现算法性能的验证,本文还引入网络覆盖率作为验证社区发现结果质量的指标.其定义为 (18) 其中,N为网络中节点总数,K为社区个数,Ck表示第k个社区. 以上3种评价指标的取值范围均为0~1,值越大表明社区发现的结果质量越好. 3) 实验结果比较 对于需要设置参数的算法,其参数的设置与3.1节相同,并选取各参数下的最好结果进行对比. 特别地,对于SLEM方法,由于所选数据集仅包含网络的拓扑结构信息,无法直接对节点对进行标注.实验采用Infomap算法[24]对网络数据进行社区发现,再以此结果为依据选取5%的节点对作为成对约束.Infomap算法是一种非重叠社区发现算法,Lancichinetti等人[25]对比了多种非重叠社区发现算法,指出Infomap算法在时间效率和结果质量上均优于其他算法.类似1.3节中在虚拟网络上实验的标注方式,将网络中各节点的属性信息对应的标签抽象成该节点在Infomap算法下所属社区的ID编号,对随机选取的一个节点对,若二者在Infomap算法结果中属于同一社区,则将其标注为必然连接,否则标注为不可能连接. 各种算法在8个真实网络下的社区发现结果质量的评价值如图3所示,其中横轴表示节点规模随坐标递增的真实网络数据集,纵轴表示不同算法在对应数据集上社区发现结果质量的评价值. 不同算法在真实网络上社区发现结果对应的重叠模块度如图3(a)所示.可以看出SLEM方法在大部分真实网络上得到的重叠模块度是最好的,或与LFM算法的结果相当,二者较NLEM算法和GCE算法表现出一定优势,表明SLEM方法能够得到质量较高的重叠社区结构.这是由于SLEM方法根据成对约束对网络的拓扑结构进行了修正,使得网络中的社区结构更加明显,进而使算法结果的质量得到有效提高. Fig. 3 Experimental results on real world networks.图3 真实网络上的社区发现结果 从图3(b)可看出,SLEM方法在所有真实数据集上都取得最高的社区连接密度,NLEM算法次之,LFM算法得到的社区连接密度最低.这是由于SLEM方法和NLEM算法的种子节点选取方法好于LFM算法随机选取的方法,使得社区扩展的过程围绕所选取的种子进行,从而得到局部性较好的社区,即种子所在社区的内部节点连接相对于不同社区之间的节点连接更加稠密,这更符合社区的一般定义. 图3(c)展示出SLEM方法、NLEM算法和LFM算法在不同网络上均能够得到较高、较稳定的网络覆盖率,而GCE算法的结果较差且波动性大.LFM算法每一个社区的种子总是从尚无社区标签的节点中随机选取,故在算法结束时仅剩余极小部分社区标签不明确的节点(文献[4]称之为homeless node),因此LFM算法得到的社区覆盖率最高.SLEM方法和NLEM算法选取的种子之间的相似性相对于GCE算法更低,在网络中的分布更加分散,因此扩展得到的社区能够覆盖到网络中较多的节点,即便出现冗余社区的情况,SLEM方法和NLEM算法也是将二者合并,以保持网络的高覆盖率.实验进一步对3种评价指标对应的社区发现结果进行融合,以综合评价4种方法和算法的性能.具体地,先对各方法、算法在每个网络得到的每个指标的评价值进行规范化,即赋每组数据的最大值为1,其余赋值为原始值占最大值的比值;再将不同指标的规范化评价值相加得到最终的综合评价值,综合评价值的取值范围是0~3.不同方法、算法在稀疏程度不同的网络上的社区发现结果质量的综合评价值如图3(d)所示. 整体上看,SLEM方法的综合评价值最高,NLEM算法和LFM算法的结果相当,GCE算法的结果相对较低.4种算法的综合结果存在不同程度的波动性,其中SLEM方法的结果波动程度相对较小,LFM算法和GCE算法的结果随网络稀疏程度的增加呈上升趋势.这表明SLEM方法在稀疏程度不同的网络上均能够取得高质量的社区发现结果;而LFM算法和GCE算法仅能够在较稠密的网络上取得较高质量的社区结构,而在较稀疏网络上结果较差.例如GCE算法在平均节点度为2.4的P2P网络数据上仅发现到1个规模为310个节点的社区,其余节点的所属社区标签均未知,其重叠模块度为0,社区连接密度为0.48,网络覆盖率不足0.005. 综上,SLEM方法在稀疏程度不同的真实网络数据上均能取得较高质量社区发现结果. 3.3SLEM方法参数的选取 与LFM,GCE算法相同,SLEM方法的社区发现结果依赖于参数的选取.SLEM方法需要设置的参数包括节点对数目n、社区结构修正权重β、分辨率参数α以及社区距离阈值ε.本节通过理论证明和实验分析,讨论这些参数的选取规则. 参数n和β的设置是依赖于数据的,即需要根据网络数据集的具体实际情况选取.设置这2个参数的目的是利用有限的成对约束尽可能大程度地修正网络的结构,从而提升社区发现结果的质量.为度量网络结构的修正效果,定义修正贡献的概念: (19) 由上述定义可知,当|Con(i,j)|>0时,成对约束(i,j)对网络结构产生修正的效果. 给定参数n和β,所有成对约束对网络结构的修正贡献的总和为 s×|β|+t×|β-1|+p×0+q×|-1|= (20) 其中,s=|SML-E|,t=|SML∩E|,p=|SCL-E|,q=|SCL∩E|,满足n=s+t+p+q. 通过式(20)可知,当成对约束集合SML和SCL固定时,式(20)中β的系数s+t固定,修正贡献总和Con随β线性递增.因此当网络数据集仅包含小部分(如不足1%)节点的属性信息时,参数n只能取较小的值(n<10-4N(N-1)2),此种情况下,为尽可能大地修正网络的拓扑结构,修正权重β就应当设置较大的值(如β≥2),否则整个修正过程对最终的社区结果的质量提升不明显;当网络数据集包含较多节点的属性信息时,这些节点自然能够组合更多的节点对,参数n可取较大的值,此时选取β=1即可显著提升社区结果的质量,否则会增加不必要的计算开销.对于LFR基准测试网络,其节点社区属性已知,本实验选取n=0.05N(N-1)2,β=1,相对于NLEM算法,社区发现结果的质量提升是显著的,如图2所示. 参数α和ε的选取则是依赖于结果的,即可以通过人工调节,选取评价值最好的社区发现结果对应的参数值.本实验设置参数α∈[0.6,1.2],ε∈[0,0.9],取值间隔均为0.1,图4以4组参数不同的LFR网络数据中Om=2的数据集为例,展示出各参数值对应的社区发现结果的NMI值. 图4(a)(b)分别展示了最高NMI值随参数α和ε值的变化曲线.从图4(a)可以看出,社区发现结果的NMI值随参数α的增大呈先增后减的趋势,在区间α∈[0.7,0.8]取到极大值.对于混合参数较小的网络(μ=0.1),NMI在α=0.7处达到极大值;对于混合参数较大的网络(μ=0.3),NMI在α=0.8处达到极大值.从图4(b)可看出,在混合参数μ=0.1的网络上,社区发现结果的NMI值在整个区间ε∈[0,0.9]上保持平稳,在ε=0.6处取极大值;在混合参数μ=0.3的网络上,除去区间的2个端点外,NMI值基本保持不变,在ε=0处和ε=0.9处分别取极大值和极小值. Fig. 4 NMI value with different parameters on LFR benchmarks.图4 LFR网络上不同参数对应的NMI值 综上,对于LFR基准测试网络中Om=2的4个网络数据集,当μ=0.1时,选取参数α=0.7,ε=0.6;当μ=0.3时,选取参数α=0.8,ε=0.在实际应用中,对于参数α,可先求出SLEM方法在α=α0∈[0.7,0.8]的结果,再求出算法在α0附近的结果,进行比较得到最优的参数值;对于参数ε,可先求出SLEM方法在区间[0,0.9]两端点的结果,比较二者的差异,若差值较大,则在较大结果对应的点附近继续计算再作比较,反之则在二者的中值点附近继续查找最优参数值. 4结束语 本文提出一种半监督的局部扩展式重叠社区发现方法——SLEM.该方法除利用网络数据的拓扑结构信息外,还根据部分节点属性信息对网络的拓扑结构进行修正,相对于传统的非监督重叠社区发现算法,其社区发现过程是在成对约束的监督下执行的.此外,该方法采用更规则化的种子选取方式,使种子扩展得到的社区结构质量更好.对社区发现结果的后处理能够减少冗余社区,同时保持社区的高覆盖率.通过在LFR基准测试网络和真实网络数据集上的实验,结果表明SLEM方法相对于当前有代表性的LFM,GCE算法能够在稀疏程度不同的网络上取得较好社区发现结果.最后对SLEM方法参数的选取进行了讨论分析,并总结出较合理的、可行的参数选取经验和方法. 此外,实验发现在原始网络中不相邻接的且被标注为不可能连接的节点对数量占全部所选节点对的比例达到90%以上,而这类成对约束对网络结构没有修正作用,导致人工标注的效率较低.下一步工作将对节点对的选取规则以及节点对的标注方法进行深入研究,在提升社区发现结果质量的同时提高人工标注的效率,避免人力的浪费. 参考文献 [1]Newman M E J. The structure and function of complex networks[J]. SIAM Review, 2003, 45(2): 167-256 [2]Fortunato S. Community detection in graphs[J]. Physics Reports, 2010, 486(3): 75-174 [3]Liu Dayou, Jin Di, He Dongxiao, et al. Community mining in complex networks[J]. Journal of Computer Research and Development, 2013, 50(10): 2140-2154 (in Chinese)(刘大有, 金弟, 何东晓, 等. 复杂网络社区挖掘综述[J]. 计算机研究与发展, 2013, 50(10): 2140-2154) [4]Lancichinetti A, Fortunato S, Kertész J. Detecting the overlapping and hierarchical community structure in complex networks[J]. New Journal of Physics, 2009, 11(3): 033015 [5]Lee C, Reid F, McDaid A, et al. Detecting highly overlapping community structure by greedy clique expansion[EB/OL]. 2010 [2014-11-10]. http://arXiv.org/abs/1002.1827 s[6]Havemann F, Heinz M, Struck A, et al. Identification of overlapping communities and their hierarchy by locally calculating community-changing resolution levels[J]. Journal of Statistical Mechanics: Theory and Experiment, 2011, 2011(1): P01023 [7]Gregory S. Finding overlapping communities in networks by label propagation[J]. New Journal of Physics, 2010, 12(10): 103018 [8]Xie J, Szymanski B K. Towards Linear Time Overlapping Community Detection in Social Networks[M]. Berlin: Springer, 2012: 25-36 [9]Palla G, Derényi I, Farkas I, et al. Uncovering the overlapping community structure of complex networks in nature and society[J]. Nature, 2005, 435(7043): 814-818 [11]Psorakis I, Roberts S, Ebden M, et al. Overlapping community detection using Bayesian non-negative matrix factorization[J]. Physical Review E, 2011, 83(6): 066114 [12]Zhang Y, Yeung D Y. Overlapping community detection via bounded nonnegative matrix tri-factorization[C] //Proc of the 18th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining (SIGKDD’12). New York: ACM, 2012: 606-614 [13]Yang J, Leskovec J. Overlapping community detection at scale: A nonnegative matrix factorization approach[C] //Proc of the 6th Int Conf on Web Search and Data Mining (WSDM’13). New York: ACM, 2013: 587-596 [14]Zhang Z Y, Wang Y, Ahn Y Y. Overlapping community detection in complex networks using symmetric binary matrix factorization[J]. Physical Review E, 2013, 87(6): 062803 [15]Ball B, Karrer B, Newman M E J. Efficient and principled method for detecting communities in networks[J]. Physical Review E, 2011, 84(3): 036103 [16]Yang J, Leskovec J. Community-affiliation graph model for overlapping network community detection[C] //Proc of the 12th IEEE Int Conf on Data Mining (ICDM’12). Piscataway, NJ: IEEE, 2012: 1170-1175 [17]Wang Z, Hu Y, Xiao W, et al. Overlapping community detection using a generative model for networks[J]. Physica A: Statistical Mechanics and Its Applications, 2013, 392(20): 5218-5230 [18]Xie J, Kelley S, Szymanski B K. Overlapping community detection in networks: The state-of-the-art and comparative study[J]. ACM Computing Surveys, 2013, 45(4): 43 [19]Zhu Mu, Meng Fanrong, Zhou Yong. Density-based link clustering algorithm for overlapping community detection[J]. Journal of Computer Research and Development, 2013, 50(12): 2520-2530 (in Chinese)(朱牧, 孟凡荣, 周勇. 基于链接密度聚类的重叠社区发现算法[J]. 计算机研究与发展, 2013, 50(12): 2520-2530) [20]Chapelle O, Schölkopf B, Zien A. Semi-Supervised Learning[M]. Cambridge, MA: MIT Press, 2006 [21]Zhang Z Y. Community structure detection in complex networks with partial background information[J]. Europhysics Letters, 2013, 101(4): 48005 [22]Lancichinetti A, Fortunato S. Benchmarks for testing community detection algorithms on directed and weighted graphs with overlapping communities[J]. Physical Review E, 2009, 80(1): 016118 [23]Newman M E J. Modularity and community structure in networks[J]. Proceedings of National Academy of Sciences, 2006, 103(23): 8577-8582 [24]Rosvall M, Bergstrom C T. Maps of random walks on complex networks reveal community structure[J]. Proceedings of National Academy of Sciences, 2008, 105(4): 1118-1123 [25]Lancichinetti A, Fortunato S. Community detection algorithms: A comparative analysis[J]. Physical Review E, 2009, 80(5): 056117 Chen Junyu, born in 1989. Master. Student member of China Computer Federation. His research interests include complexsocial network and machine learning. Zhou Gang, born in 1974. Associate professor. Member of China Computer Federation. His research interests include data mining, complexsocial network and machine learning (gzhougzhou@gmail.com). Nan Yu, born in 1978. Lecturer. Member of China Computer Federation. Her research interests include data mining and machine learning (ddapple2011@163.com). Zeng Qi, born in 1992. Master candidate. Student member of China Computer Federation. His research interests include machine learning and natural language processing (windddk@163.com). Semi-Supervised Local Expansion Method for Overlapping Community Detection Chen Junyu, Zhou Gang, Nan Yu, and Zeng Qi (StateKeyLaboratoryofMathematicalEngineeringandAdvancedComputing,Zhengzhou450002) AbstractOverlapping community detection has become one of the hottest research issues in the field of network science, as well as attracted the attention of researchers with different backgrounds. A novel semi-supervised local expansion method (SLEM) is proposed for detecting overlapping communities more effectively in real world networks. The proposed method makes use of not only the topology information of the network but also the attribute information of partial vertices. Inspired by the idea of semi-supervised clustering with constraints in the field of machine learning, SLEM starts from utilizing the attribute information of partial vertices to get pairwise constraints which can be used to modify the topology structure of the original network. Afterward, a vertex degree centrality-based seeding method is proposed for selecting seeds as initial communities. Then these seeds expand into local communities by a greedy strategy, after which partial connected close-knit communities are formed. Finally, similarities between different communities are computed on the basis of a community distance measurement, and then near-duplicated communities are combined. Taking more advantage of network information than traditional unsupervised community detection methods, SLEM can produce communities with higher structure quality. Experimental results on both synthetic benchmark networks and real world networks show that SLEM can achieve better effect than the state-of-the-art local expansion methods on the networks of different sparsity degrees. Key wordscomplex network; overlapping community detection; semi-supervised clustering; local expansion; semi-supervised local expansion method (SLEM) 收稿日期:2014-12-09;修回日期:2015-03-19 基金项目:数学工程与先进计算国家重点实验室开放基金项目(2013A02) 中图法分类号TP391 This work was supported by the Open Program of State Key Laboratory of Mathematical Engineering and Advanced Computing (2013A02).









































猜你喜欢
计算机应用(2016年12期)2017-01-13 19:59:45
对外经贸(2016年11期)2017-01-12 01:12:53
无线互联科技(2016年13期)2017-01-10 02:30:36
中小企业管理与科技·上旬刊(2016年10期)2016-11-15 10:00:25
电脑知识与技术(2016年18期)2016-11-02 19:00:03
科技视界(2016年20期)2016-09-29 11:19:34
电脑知识与技术(2016年16期)2016-07-22 19:22:34
电脑知识与技术(2016年11期)2016-06-17 19:19:44
中国市场(2016年13期)2016-04-28 09:14:58
商情(2016年11期)2016-04-15 22:00:31
