
基于CUPTI接口的典型GPU程序负载特征分析
2016-07-19 02:14翟季冬陈文光
计算机研究与发展 2016年6期
关键词:性能指标
郑 祯 翟季冬 李 焱 陈文光
(清华大学计算机科学与技术系 北京 100084)(z-zheng14@mails.tsinghua.edu.cn)
基于CUPTI接口的典型GPU程序负载特征分析
郑祯翟季冬李焱陈文光
(清华大学计算机科学与技术系北京100084)(z-zheng14@mails.tsinghua.edu.cn)
摘要基于图形处理器(graphics processing unit, GPU)加速设备的高性能计算机已经成为目前高性能计算领域的一个重要发展趋势.然而,在当前的GPU设备上开发高效的并行程序仍然是一件非常复杂的事情.针对这一问题,1)总结了影响GPU程序性能的5类关键性能指标;2)采用NVIDIA公司提供的CUPTI底层接口,设计并实现了一套GPU程序性能分析工具集,该工具集可以有效地分析GPU程序的性能行为;3)采用该工具集对著名的GPU评测程序集Rodinia中的17个程序和一个真实应用程序进行了负载特征分析.总结出常见性能瓶颈的典型原因,并给出一些开发高效GPU程序的建议.
关键词图形处理器;负载特征分析;Rodinia;硬件计数器;性能指标
近年来,基于加速设备的超级计算机已经成为高性能计算领域一个重要发展趋势.在2014年6月最新发布的超级计算机TOP500排名中,有48个计算机系统使用了GPU加速器.其中,在前15位的超级计算机中有5个计算机使用了GPU加速器.目前,NVIDIA公司的GPU是最主流的GPU加速器,在上述TOP500中有48个使用GPU加速器的超级计算机中,有46个使用的是NVIDIA架构的GPU,其余2个使用了AMD的GPU.
尽管基于加速设备的超级计算机变得越来越流行,但是,在这些系统上编写高效率的并行程序仍然是一件非常复杂的事情.我们以NVIDIA的GPU设备为例,NVIDIA公司推出的通用编程框架CUDA(compute unified device architecture)是目前应用最为广泛的编程模型,但编写高效的CUDA程序非常困难.一方面,GPU设备的存储器层次结构较为复杂,除了片外的全局存储器(global memory)、常数存储器(constant memory)和纹理存储器(texture memory)之外,GPU还向应用开发人员开放了对片内的共享存储器(shared memory)的访问接口,这些存储器都需要程序员在程序中显示地进行管理;另一方面,CUDA编程模型本身也提供多层次的程序组织方式,具有网格(grid)、线程块(thread block)、warp等,不同组织形式下有不同的线程间通信机制和存储器共享与访问机制.这些复杂的编程机制导致GPU程序的编写及优化比较困难.
针对GPU程序性能的瓶颈,目前国内外研究人员提出了很多相关的优化技术.Zhang等人[1]提出了一种软件的方法在运行时优化GPU程序中控制和访存的不规则问题,但是目前该工作只支持简单的访存行为优化,尚不支持较复杂的程序.Yang等人[2]提出一个基于指导编译语句的方式优化GPU程序中的嵌套并行.Margiolas等人[3]开发了一个可移植的框架优化OpenCL程序中CPU和GPU之间通信传输开销高的问题.Xiang等人[4]发现在GPU程序中不同warp间会存在显著的负载不均衡现象,由于目前GPU的warp调度方式会导致GPU资源的显著浪费,针对上述问题他们提出一种新的资源管理方式,可以有效提高GPU程序性能并降低系统的整体能耗.尽管已有大量的研究工作试图自动优化GPU程序的各种性能行为,但是,缺少对典型GPU程序的负载特征的详细分析和总结.
为了有效分析当前典型GPU程序的负载特征,本文首先归纳出GPU程序若干重要性能指标,其中包括计算访存比、实际浮点性能、带宽利用率、GPU占用率、共享存储器访问效率、全局存储器访问效率等.并且,为了有效获取GPU程序的上述指标,我们采用NVIDIA公司提供的底层CUPTI接口(CUDA profiling tools interface)自主开发了一套性能分析工具,该工具可以在不修改用户源码的情况下精确获取GPU程序上述性能指标.本文采用该工具集对著名的GPU评测程序集Rodinia[5]中17个程序和全球正压大气浅水波模式应用程序[6]进行了性能分析,统计了各个程序上述的性能指标,并对部分重要性能指标表现的性能瓶颈进行了程序优化.本文的分析结果对CUDA程序优化及未来GPU体系结构的设计都具有指导意义.
1相关工作
目前已有一些工具可以进行CUDA程序性能分析,但都存在一些不足.PAPI(performance application programming interface)[7]是应用广泛的程序性能分析工具,提供了针对CUDA程序的性能分析接口.使用PAPI接口在待测试程序代码中进行插装,就可以得到CUDA程序的部分硬件计数器值.但如前所述,使用PAPI进行性能测试时需要对源代码进行修改,这增加了性能测试工作的难度和繁琐程度;另外,PAPI性能分析接口每次只能够读取少量的硬件计数器值,为得到大量硬件计数器值,需要多次修改插桩代码并多次运行.TAU(tuning and analysis utilities)[8]提供了功能更为强大的CUDA程序性能分析功能.该工具可以追踪CUDA程序各种库函数操作的执行时间和具体执行信息(如复制函数复制的字节数等),并能够在不修改待测试程序源码的情况下收集程序运行时的硬件计数器指标值.但在CUDA程序的1次运行中,TAU只能够收集少量的硬件计数器指标值,为了收集较多的指标值,需要手动地多次执行整个程序,使用较为繁琐;另外,TAU只能收集单纯的硬件计数器值,不能收集或计算综合性能指标,而独立的硬件计数器值难以直接反映程序的性能特性,这使得其性能分析结果难以引导开发者进行性能优化.Visual Profiler[9]是NVIDIA官方提供的CUDA性能分析工具.该工具提供可视化的操作界面,能够收集GPU上所有的硬件计数器值,且能够收集并计算一些综合性能指标.但该工具对部分重要性能指标默认不做收集,而需要开发者进行指标的选择,初级CUDA程序开发者难以选择出重要的性能指标并通过查看众多性能指标而快速确定程序性能瓶颈.
目前已有一些CUDA程序优化方法的研究.Yang等人[10]的工作中通过对10个开源CUDA程序的分析,总结了若干种导致程序性能低下的程序模式,并通过实验证明对这些程序模式的优化能够显著提高程序性能.Stratton等人[11]的工作中描述了对CUDA程序优化有关键作用的方法,包括数据存储方式的转换、合并访问、负载均衡化、控制并行粒度等方法,这些优化模式应用在CUDA程序上有普遍的性能提高.Yang等人[12]的工作中提出了一个源到源的CUDA程序自动优化工具,其中采用的优化方法包括向量化,全局内存合并访问,线程合并以及数据预取等方法.在Li等人[13]以及Chen等人[14]的工作中,研究了变量存储位置转换的问题.Li等人[13]的工作主要涉及到全局内存和共享内存变量转换为寄存器变量,以及共享内存变量转换为全局内存变量这几个方面;Chen等人[14]的工作则侧重于将全局内存变量转变为其他类型变量,结果显示通过内存变量位置的合理转换,程序性能能够得到很大的提升.Wahib等人[15]的工作中,提出了通过合并核函数的方式进行数据重用的方法,被合并的核函数需要有共同的参数,此时这些参数的访问能够被重用,实验显示该方法对部分程序有很好的优化效果.李建江等人[16]提出了一种将单GPU程序转化为多GPU程序的方法,通过该转化能够使大型程序运行在多GPU上,取得更好的加速效果.这些针对CUDA程序的研究都取得了一定的效果,但这些研究都侧重于以具体的方法对某一类程序进行优化,并没有对普通程序进行性能瓶颈分析和定位.
对常用CUDA程序做负载分析的相关工作较少.Che等人[5]的工作中,对基准测试程序套件Rodinia进行了多样性分析,说明了Rodinia中程序能够较为广泛地覆盖并行程序的特性,并分析了影响CUDA程序性能的一些问题,但该工作中并没有研究反映CUDA程序性能特性的性能指标,也没有针对CUDA重要性能特性对Rodinia做负载特征分析;同时,该工作中只是对一套基准测试程序套件进行分析,没有对真实应用程序进行性能分析.
目前已有一些针对CUDA程序的部分特性进行性能建模的工作.在Williams等人[17]提出的Roofline模型中,分析了实测浮点性能与理论浮点性能峰值、带宽峰值及操作密度的函数关系.该模型中,操作密度是指单位字节的内存数据传输之下的操作数量,为操作数量与访存数量的比值,对于给定的操作密度,通过该模型可以确定程序是计算受限还是访存受限.本论文中借鉴了该工作的方法,确立了计算访存行为的性能指标.
2CUDA程序性能指标
为了有效地分析CUDA程序的负载特征,明确程序的性能瓶颈,本文提出5类关键性能指标描述CUDA程序的性能行为:
1) 计算访存行为(计算访存比、实测浮点性能和带宽利用率)
计算访存比对于确定程序的类型以及检测程序性能受限因素有重要作用:①对基准测试程序进行计算访存比测试可以统计出通用程序的计算访存特征;②对于单个程序,综合计算访存比、GPU带宽与带宽利用率以及理论浮点性能峰值与实测浮点性能可以看出程序是访存受限还是计算受限[17].科学计算中,大部分计算指令为浮点型指令,而通常影响程序性能的访存方式主要是全局存储器访问,因此,统计浮点计算指令与全局存储器访存比更有意义.
我们定义浮点计算与全局访存比为浮点指令的条数与全局存储器访问字节数的比率,记为Rf-g,记浮点指令条数为If,核函数执行时间为Dk,单位时间内全局存储器的读与写的字节数分别为Tgld与Tgst,则有:
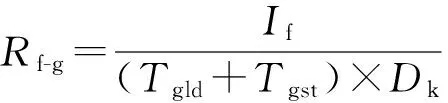
(1)
由于我们收集的Tgld与Tgst为运行时的指标,最终得到的全局存储器访问字节数也是实际值,而非理论值在作分析时,理论的存储器访问量与实际值可能会有偏差.
GPU实测浮点性能Pf-achieved是指GPU每秒实际执行的浮点运算次数,浮点计算单元利用率Uf是指实测浮点性能与理论峰值Pf-peak的比率.这2个指标能够反映出程序的浮点计算量及浮点计算单元的利用情况,其计算方法为

(2)

(3)
GPU带宽利用率Udram可以通过指标Tdramread,Tdramwrite以及GPU的带宽B求得,其中Tdramread和Tdramwrite分别表示单位时间内GPU设备上内存读写字节数.Udram能够综合地反映程序对存储器访问的效率,其计算方法为

(4)
2) GPU占用率
GPU占用率(occupancy)是指实际运行的warp占最大理论warp数量的比值,包括理论GPU占用率和实际GPU占用率.影响理论GPU占用率的指标有3个:每个线程块中线程的数量、每个线程占用的寄存器数量和每个线程块分配的共享存储大小.实际GPU占用率由CUPTI中定义的achieved_occupancy来表示,该值受到每个网格中线程块数量及实际运行环境的影响,需要在程序运行时通过CUPTI相关函数获取.
GPU占用率反映了程序实际开启的并行计算线程数量占理论最大数量的比例,一般来说,比值越大表示程序对GPU资源的利用率越高,并行度越好.一方面,GPU占用率受开发者配置的并行线程数量的影响,开发者配置的线程数过少时GPU占用率会较低;另一方面,GPU占用率受单位线程占用的存储器资源数量的影响,当每个线程中局部变量较多从而占用较多寄存器时,或者每个线程块占用的共享内存数量较多时,会因为存储器资源不足而无法发起太多线程,导致GPU占用率较低.GPU占用率可以反映程序在这2方面的特性.
对于访存受限的CUDA程序,当其并行度较高时,大量的线程并行执行通常能够有效地掩盖数据传输带来的时延,从而提高程序性能.因此GPU占用率是反映访存受限的CUDA程序性能的重要指标.但对于计算密集型程序,单纯提高GPU占用率并不能很有效地提高程序性能.
3) 共享存储器访问效率
反映共享存储器访问效率的指标是shared_efficiency,表示对共享存储器数据访问的请求数据量与实际数据量的比率,其值越大表示共享存储器访问效率越高.
在共享内存的最佳访问状态下,每个half-warp中不同线程访问到不同的bank中(或所有线程访问同一地址),此时各个线程能够同时访问共享内存,shared_efficiency=1.0;当存在bank冲突时,不同线程访问到同一个bank时会使得各线程只能依次访问,此时shared_efficiency降低.因此,shared_efficiency能够反映出共享存储器使用中的bank冲突(bank conflict),当该指标值较低时,往往表示存在bank冲突.
4) 全局存储器访问效率
反映全局存储器访问效率的指标是gld_efficiency和gst_efficiency.gld_efficiency的含义是对全局存储器数据读取的请求数据量与实际数据量的比率,其值越大表示读取数值的效率越高,该比率可能小于1.0,可能等于1.0,也可能大于1.0.gst_efficiency表示对全局存储器数据写入的请求数据量与实际数据量的比率,与gld_efficiency的意义类似,值越大表示效率越高.
全局内存的最佳读取方式是多个线程读取同一地址,此时多个线程只需一次全局内存读取,gld_efficiency>1.0;当同一个half-warp中的线程对全局内存的读取地址连续且满足一定的地址对齐规则时(不同GPU架构下对齐要求不同),该half-warp中各线程对全局内存的读取能够合并为同一条读取指令,此时gld_efficiency=1.0;当half-warp中不同线程对全局内存变量的访问不连续或不满足地址对齐规则时,不同线程需多次读取全局内存,而CUDA中对全局内存读取时是以32 B,64 B或128 B为单位的,单次读取单个变量时会读入大量不需要的内存,gld_efficiency<1.0.对于全局内存的写入和gst_efficiency有类似的结论.
gld_efficiency和gst_efficiency可以有效地检测出非合并访问(uncoalesced access),对于测试CUDA程序全局存储器访问效率很有效.
5) 线程束执行效率
线程束执行效率主要由线程分歧的情况来反映.对于CUDA核函数,当分支条件控制指令数不大于某个阈值时,编译器会使用带有谓词的指令替换分支指令,各个线程会根据控制条件将各条替换过的分支指令与设置为true或false的谓词相关联,此时每一条分支指令都会在任何一个线程中发射,但最终只有谓词为true的指令才会被实际执行;当分支数大于阈值时,编译器不会进行分支谓词替换,此时同一half-warp中执行不同分支的线程无法并行执行,会出现一部分线程等待其他线程的情况.
能够反映核函数执行过程中线程分歧的指标是warp_execution_efficiency和warp_nonpred_execution_efficiency.warp_execution_efficiency是指在流处理器中各个warp中实际运行的线程数量占最大理论线程数量的比值的平均值,该值为1.0时表示不考虑分支谓词替换分支指令的情况下没有线程分歧,否则一定有线程分歧.warp_nonpred_execution_efficiency是指在一个流处理器上各个warp中执行非分支预测指令的线程数量占最大理论线程数量的比值的平均值,该值为1.0时表示没有使用分支谓词替换分支指令,否则存在分支预测.综合2个指标可以全面地了解核函数中的线程分歧情况.
通过上述指标的分析,可以清楚地了解CUDA程序的计算特征、访存特征以及GPU特有的性能行为,例如,线程分歧和共享内存使用情况.下面介绍本文如何通过GPU的CUPTI接口获取上述性能指标.
3性能工具的实现
本文设计并实现的性能分析工具能够在待测试程序运行时收集第2节讨论的重要性能指标,使用该工具时无需修改待测试程序源码.为实现该工具,我们对CUDA运行时库函数进行了插桩,重写了部分关键的库函数,并通过设置LD_PRELOAD环境变量使得CUDA程序在调用库函数时链接并执行我们重新实现的版本,进而在执行时运行采集性能指标的程序段.对库函数插桩前后核函数执行流程如图1所示:
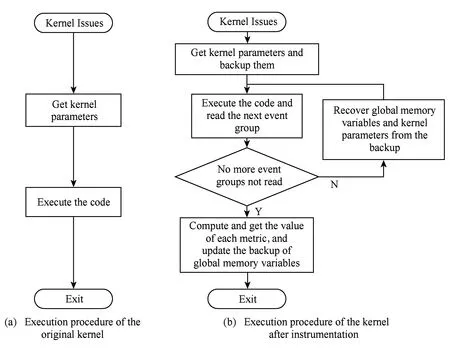
Fig. 1 The processes of the kernel before and after instrumentation.图1 对库函数插桩前后核函数执行流程
我们在插入的代码中使用CUPTI接口[18]来收集CUDA程序的性能指标,CUPTI可以收集的指标主要包括程序运行信息、事件和CUPTI定义的Metric三类.其中,事件指GPU的硬件计数器值,而Metric则是由若干个事件值计算出的综合性指标.在第3节中描述的重要性能指标大部分可以直接由Metric来表示,另外一部分可以通过其他Metric求出,因此我们的目标是收集需要的事件值,进而得到重要的Metric值.
为得到需要的重要Metric值而必须首先得到较多的事件值,而由于硬件计数器数量限制,每次核函数运行时可以收集到的事件值数量有限,因此需要多次执行核函数,分多次收集事件值.为此,我们通过对库函数插桩而改变了核函数的发射过程,使得原先一次执行的核函数被多次发射,从而在每次执行时求得一部分硬件计数器值,最终求出所有需要的性能指标值.通过这样的方式,核函数被多次执行,而整个程序则仍然只需要执行一次,且整个过程对使用者来说是透明的.核函数发射的控制函数主要是cudaConfigureCall,cudaSetupArgument,cudaLaunch,前两者将核函数配置参数与运行参数压入栈中,后者发射核函数,编译时源程序中核函数调用语句会被这3个函数所替代.本文实现的性能分析工具重新实现了这3个函数,在前两者中备份了函数参数,在新的cudaLaunch中多次调用原函数cudaLaunch,从而实现核函数的多次执行,每次调用后收集若干事件值,在收集到所有所需事件值后得到所需的各个Metric值.为了保证多次调用核函数后程序的正确性,需要在每次调用cudaLaunch前恢复部分变量值为进入核函数时的初始值,并重新读取备份的函数参数.
通过修改库函数将原先核函数的每次执行变为多次执行后,如不恢复变量值为进入核函数时的初始值,则可能导致程序的错误,因为核函数执行过程中可能修改部分全局内存变量的值,此时原先只执行一次的核函数被修改为多次执行后会导致部分全局内存变量被累计修改多次,从而导致错误.为了避免这样的错误,需要提前备份可能被修改的变量的值,并在每次重复调用cudaLaunch前将上次执行时被改变的变量恢复为正确的初始值,从而使核函数的多次执行是在同样的初始条件之下进行,在最后一次重复调用cudaLaunch之后更新变量备份值.需要备份的变量为作用域大于核函数作用域且在核函数中可以被改变的变量,满足此条件的变量只有全局存储器变量,为了保证所有可能被改变的全局存储器变量都被备份,我们备份了程序中所有的全局存储器变量,并通过对相应库函数进行插桩而实现了备份值跟随原变量值的同步更新.为了实现变量的备份与同步更新,性能工具实现时维护了一个链表,链表中每个节点对应于一个全局内存变量,节点保存了被备份变量的内存地址及备份值.我们重新实现了cudaMalloc等库函数,每当通过这些函数新创建一个全局内存变量时在链表中增加1个节点,从而保证备份所有的全局内存变量,同时,我们重新实现了cudaMemcpy等函数,每当通过这些函数改变内存变量值时,根据内存变量地址找到对应的备份节点,同步更新节点的备份值,从而实现备份值的同步更新.在每次重复调用cudaLaunch前恢复全部全局内存变量值的方法为:遍历备份链表,将各节点指向的内存地址的内存值恢复为节点存储的备份值;最后一次重复调用cudaLaunch后,则以类似方法将链表中各个节点的备份值更新为对应变量的当前值.
最后,我们对该工具的有效性与正确性进行了验证.该工具收集的部分指标与Visual Profiler一致,对于该部分指标,我们将该工具与Visual Profiler的输出结果进行了对比,结果显示两者没有明显差异;对于在Visual Profiler中没有的指标,其中间结果都可以由Visual Profiler进行收集,我们验证了这些指标的中间结果的正确性,最后通过对CUDA官方示例中部分程序的源码及运行结果进行分析而验证了这些指标的有效性与正确性.
4CUDA程序负载特征分析
本文对著名的CUDA评测程序Rodinia中17个程序和全球正压大气浅水波方程求解应用程序采用上述性能指标进行分析.本文的实验平台为Dell Precision T5600服务器,CPU型号为Intel Xeon E5-2620,内存大小为64 GB,操作系统为Red Hat Enterprise Linux 6.4 Server,GPU型号为NVIDIA Tesla K20c,该GPU的CUDA计算核心数量为2 496个,共享内存大小为4 800 MB.实验中使用的CUDA版本为CUDA 6.0.
Rodinia中程序能够较为广泛地覆盖并行程序的特性,其CUDA版本覆盖了CUDA程序的多方面特性,因此其成为了对CUDA程序进行测试分析的重要程序集.本文分析的Rodinia中17个程序如表1所示:

Table 1 Programs in Rodinia
4.1Rodinia负载分析
1) 计算访存分析结果
Rodinia中17个程序的浮点计算与全局内存访问比如图2所示,可以看出,37个核函数中有9个函数该指标值大于1,其中有4个函数该指标值大于2,有2个函数该指标值大于3,分别是LV程序的核函数(7.97)和KM的函数kmeansPoint(86.25).部分程序的浮点计算访存比为0,该类程序中没有浮点计算.

Fig. 2 The Rf-gvalues of the 17 programs in Rodinia.图2 Rodinia中17个程序浮点计算与全局内存访问比
本文中分析的应用程序为求解全球正压大气浅水波方程的程序,该方程为大气模拟过程中最基础、最重要的方程.该程序支持多种混合架构,我们选取其单GPU版本进行了性能分析.
17个程序的浮点计算单元利用率如图3所示,可以看出,这17个程序的浮点计算单元利用率普遍很低,37个核函数中有36个的该指标值小于0.04,且其中28个核函数该值小于0.01;LV程序的核函数该指标值最高,但也只达到0.177.这说明17个程序对浮点计算单元的利用率普遍较低.
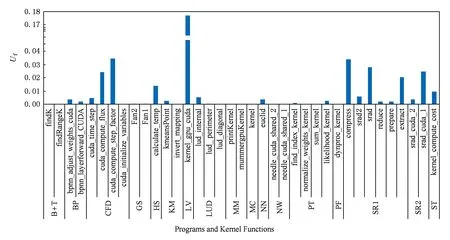
Fig. 3 The Ufvalues of the 17 programs in Rodinia.图3 Rodinia中17个程序的浮点计算单元利用率
17个程序的带宽利用率Udram指标值如图4所示,可以看到,在37个核函数中有28个核函数的带宽利用率小于0.5;CFD的函数cuda_time_step的该值最高,为0.7267.程序带宽利用率整体不够高的原因可能有2个:①程序本身的特性,部分程序由于算法本身的特性及程序规模等原因,使得其即使访存方式达到最优也无法太多地利用带宽;②程序本身访存方式设计不够合理,导致带宽利用率较低.另外,与浮点计算单元利用率相比,程序的带宽利用率整体高于前者.

Fig. 4 The Udramvalues of the 17 programs in Rodinia.图4 Rodinia中17个程序的带宽利用率指标值

Fig. 5 The achieved_occupancy values of the 17 programs in Rodinia.图5 Rodinia中17个程序各核函数的实际occupancy值
从以上分析可知,Rodinia中程序的浮点计算单元利用率普遍较低,程序带宽利用率普遍优于浮点计算单元利用率.同时,多数程序的浮点计算与全局内存访问比较低,说明程序的全局内存访问量相对浮点运算而言更多,这与带宽利用率相对略高而浮点计算单元利用率低的趋势是一致的.由此可见,程序的带宽利用率与浮点计算单元利用率一定程度上受程序本身计算访存数量特征的影响.
2) occupancy分析结果
Rodinia中17个程序的occupancy如图5所示,在37个核函数中有22个达到了0.7,其他15个核函数的occupancy值较小,其中GS程序的函数Fan2、LUD程序的函数lud_perimeter与lud_diagonal、MC程序的核函数kernel值最低,都为0.2,其理论occupancy值也较低,为0.25.
对于GS程序的函数Fan2,在输入为1 024×1 024的矩阵的情况下,程序网格的维数为(256,256,1),线程块维数为(4,4,1),由此可见,线程块维数较小最可能是导致occupancy值较低的原因.修改代码,将线程块维数设置为(16,16,1),测试结果显示实际occupancy值提升为0.86.
修改程序前后测试信息如表2所示,可以看出增大线程块维数进而增大occupancy值能够有效地减少核函数执行时间(减小了0.56).同时,在采用此方法增大occupancy之后,程序的全局存储器访问效率有所降低(gld_efficiency与gst_efficiency值减小),这说明在增大occupancy之后,程序中同时运行的warp更多,程序并行性更高,高并行性使得访存时延被大量的计算指令的执行有效地掩盖了.

Table 2 Optimization Result of Fan2 Function in GS Program

Fig. 6 The shared_efficiency values of the 17 programs in Rodinia (0 means no use of shared memory).图6 Rodinia中17个程序各核函数的shared_efficiency值(值为0表示没有使用共享内存)
3) shared_efficiency分析结果
Rodinia中17个程序的shared_efficiency值如图6所示,在37个核函数中有14个使用了共享存储器,在这14个函数中有8个程序的shared_efficiency指标值达到了1.0,2个程序的shared_efficiency指标值达到了0.8,其他4个函数的shared_efficiency指标值较小,其中LV程序的函数kernel_gpu_cuda有最低的利用率,为0.4211.
图7显示了LV程序的函数kernel_gpu_cuda在使用共享内存时存在bank冲突.该函数中定义了2个共享内存数组rA_shared和rB_shared,数组元素都是结构体,大小为32 B.在计算能力为3.5的GPU中,共享存储器被分为32个bank,该程序运行时bank的存储单元大小为4 B,则每访问连续的32个4 B后会回到原先访问的bank中.由此可知,该程序中同一个warp中对2个共享内存数组的第n个元素的访问与第n+4个元素的访问会产生bank冲突.对于数组rA_shared,warp中不同的线程之间会产生大量的bank冲突;对于数组rB_shared,由在循环中访问的过程中,half-warp的不同线程可能访问到相同的bank中,从而造成bank conflict冲突.
4) 全局存储器访问效率分析结果
Rodinia中17个程序的gld_efficiency与gst_efficiency值如图8所示.对于gld_efficiency,MM程序的函数mummergpuKernel有最低值0.032,PT程序的函数find_index_kernel有最高值7.3438;对于gst_efficiency,MM程序的函数printKernel有最低值0.0938,CFD的函数cuda_time_step及其他程序的部分函数有最高值1.0.
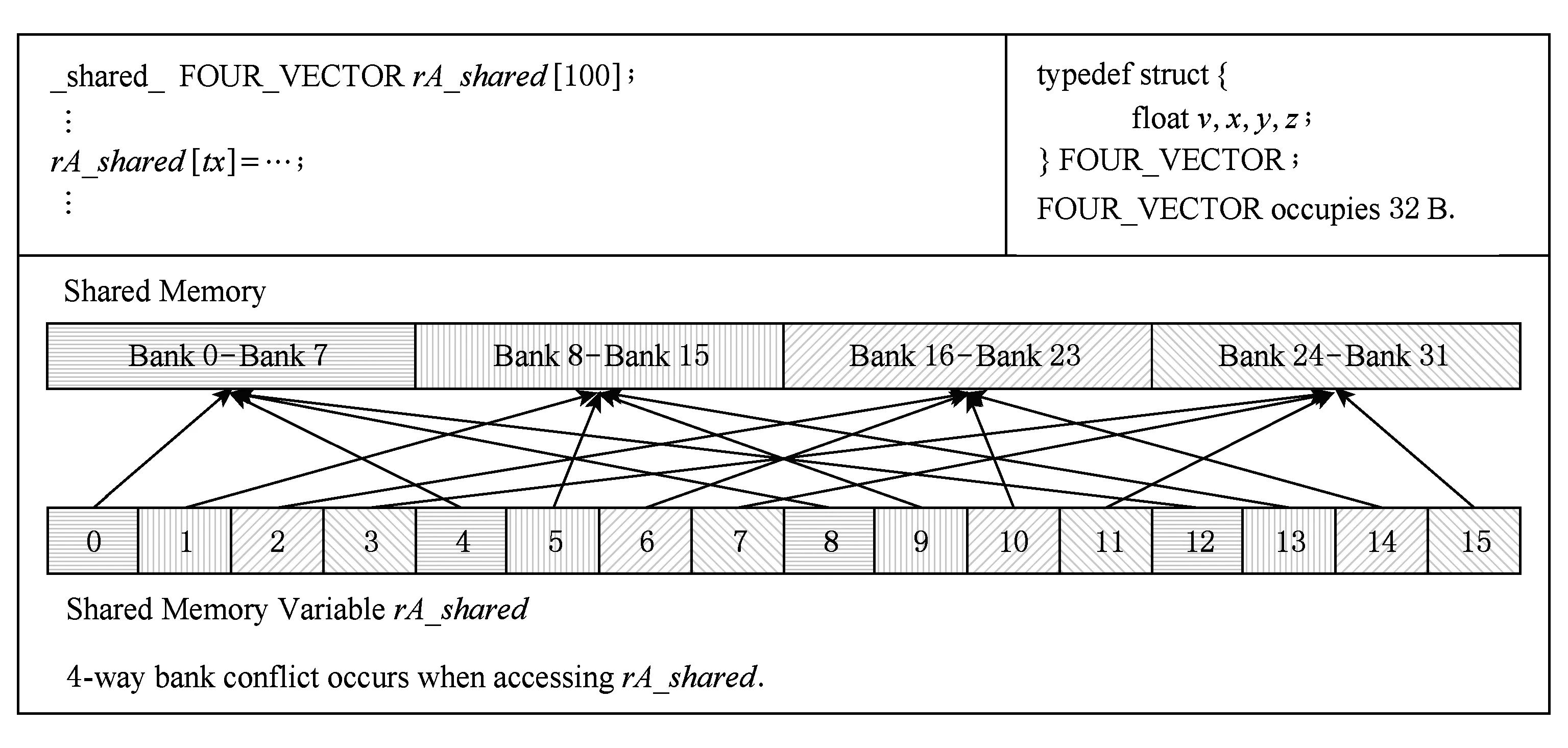
Fig. 7 The bank conflict for function kernel_gpu_cuda in program LV accessing rA_shared.图7 LV程序函数kernel_gpu_cuda访问变量rA_shared时的bank冲突
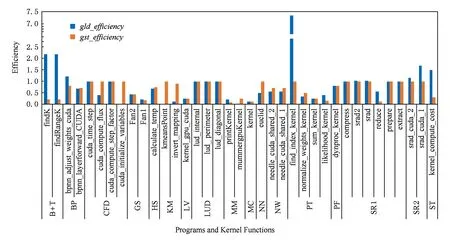
Fig. 8 The gld_efficiency and gst_efficiency values of the 17 programs in Rodinia.图8 Rodinia中17个程序各核函数的全局存储器访问效率
如图9所示,MM程序的函数mummergpu-Kernel中对全局内存的访问存在非合并访问的现象.在同一个线程中,对全局内存数组多次以比较随机的索引值进行访问,warp中的不同线程对该数组的访问的位置也很难连续,因此无法合并访问.最终该函数的gld_efficiency=0.032.
对于PT程序的函数find_index_kernel,其对全局内存块arrayX和arrayY的访问一般是连续多次访问同一个地址,这种情况下warp在执行访存指令时可以只进行一次访存,访存效率较高,gld_efficiency=7.3438.
图10为MM程序的函数printKernel中部分代码结构,该函数中存在大量对结构体类型的全局内存数组元素的成员的访问,访问的地址难以满足合并访问所要求的对齐规则,且warp中各个线程访问的地址可能不连续,使得出现大量非连续访问,gst_efficiency值较低,gst_efficiency=0.0938.
在CFD的cuda_time_step等函数及其他程序的部分函数中,对同一warp中对全局内存的访问是连续的并且是对齐的,因此访问效率很高,gst_efficiency=1.0.
5) warp执行效率分析结果
Rodinia中17个程序的warp执行效率值如图11所示,图11中包括2项指标:warp_execution_efficiency与warp_nonpred_execution_efficiency.可以看到,在37个核函数中,大部分函数的warp执行效率指标值达到或接近0.8,只有少数函数的指标值较低,同时可以看到大部分核函数中,warp_execution_efficiency值都会略大于warp_nonpred_execution_efficiency值,说明在大部分核函数中都存在分支指令的谓词替换.
MC程序中函数kernel的warp执行效率值最低,warp_execution_efficiency=0.0344,warp_non-pred_execution_efficienc=0.0328.如图12所示,MC程序的kernel运行时只使用了2个warp,而每个warp中只有一个线程在执行串行程序,其他31个线程空闲,从而使线程分歧比较严重,线程利用率非常低.
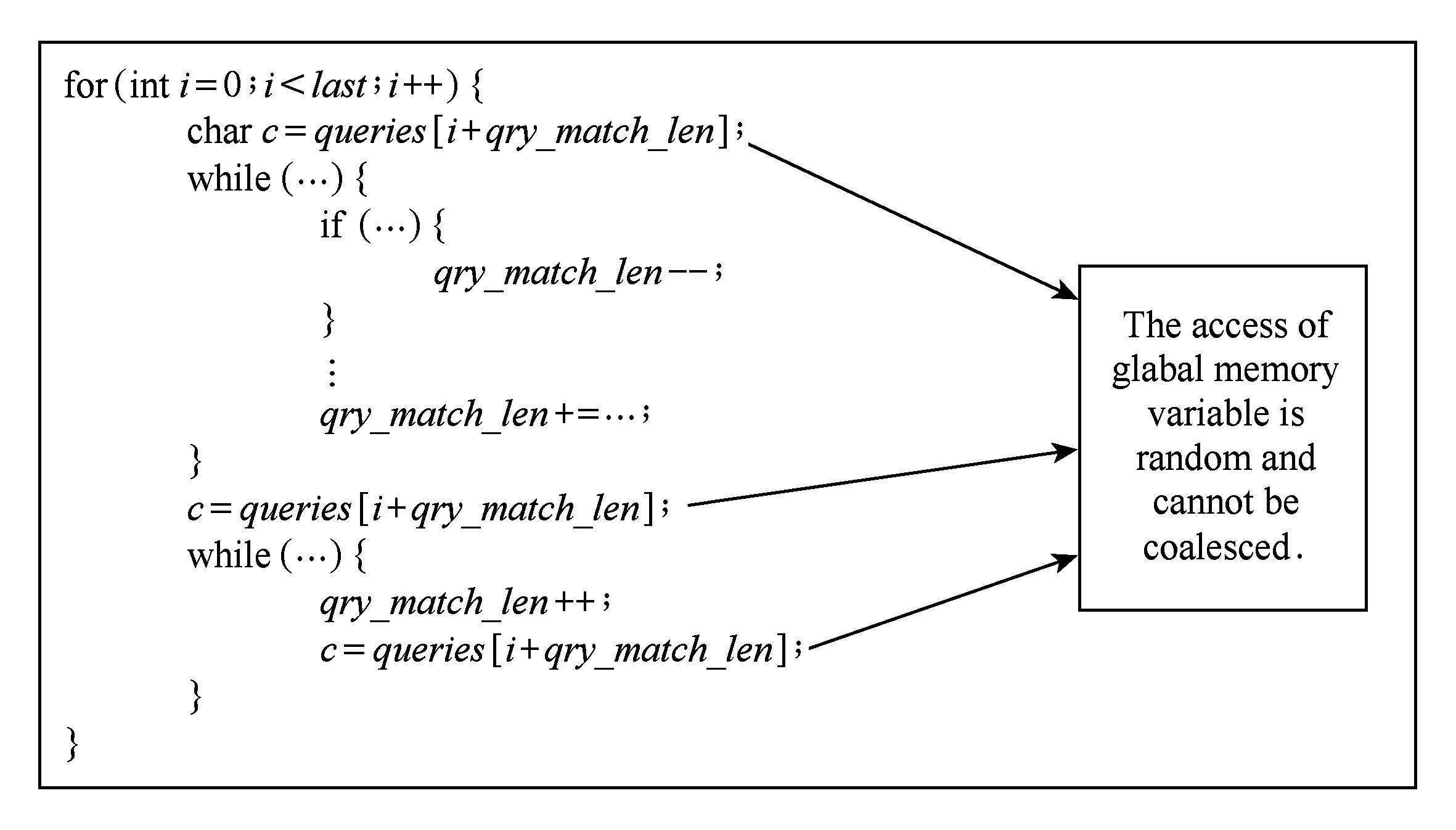
Fig. 9 The analysis of the performance bottleneck of function mummergpuKernel in program MM.图9 MM程序的函数mummergpuKernel性能瓶颈分析
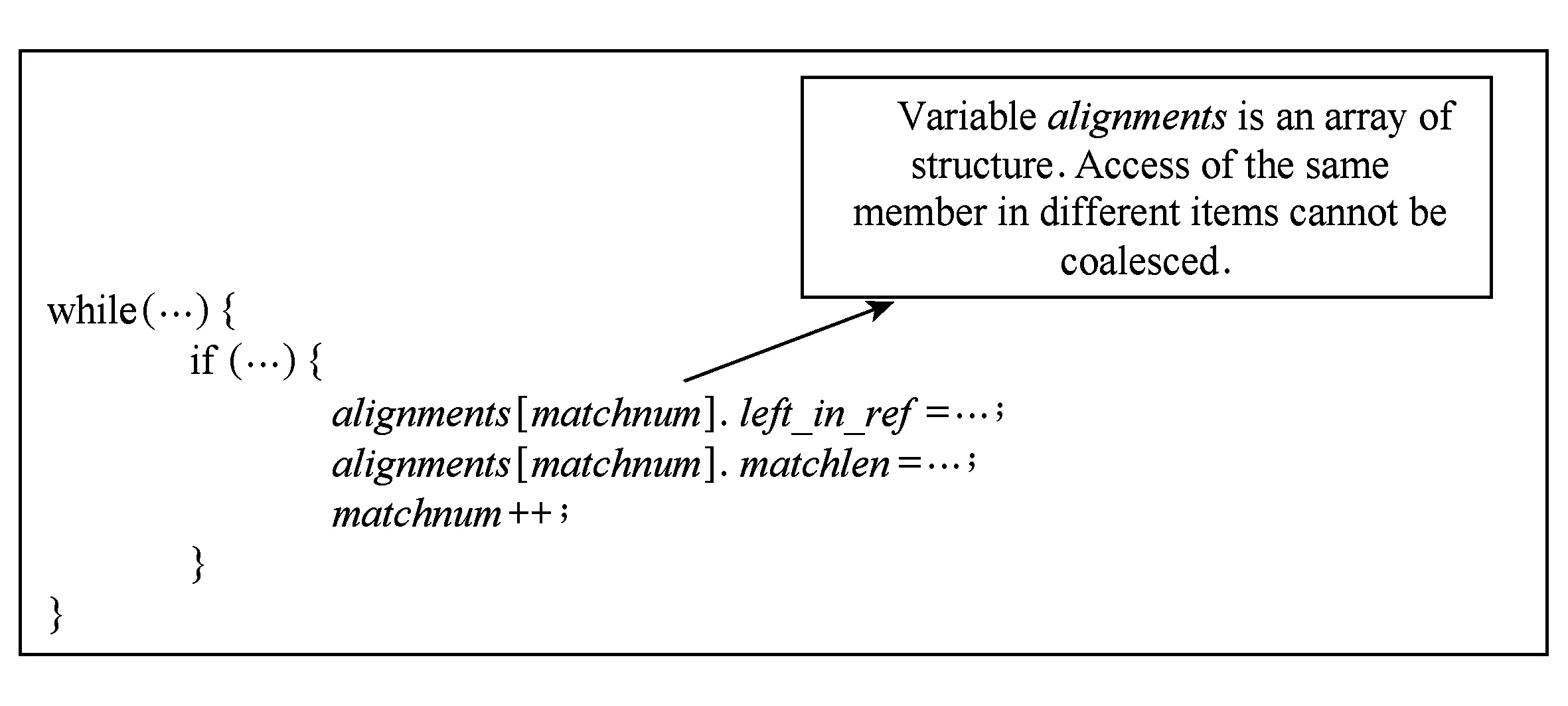
Fig. 10 The analysis of the performance bottleneck of function printKernel in program MM.图10 MM程序的函数printKernel性能瓶颈分析

Fig. 11 The warp execution efficiency of the 17 programs in Rodinia.图11 Rodinia中17个程序各核函数的warp执行效率
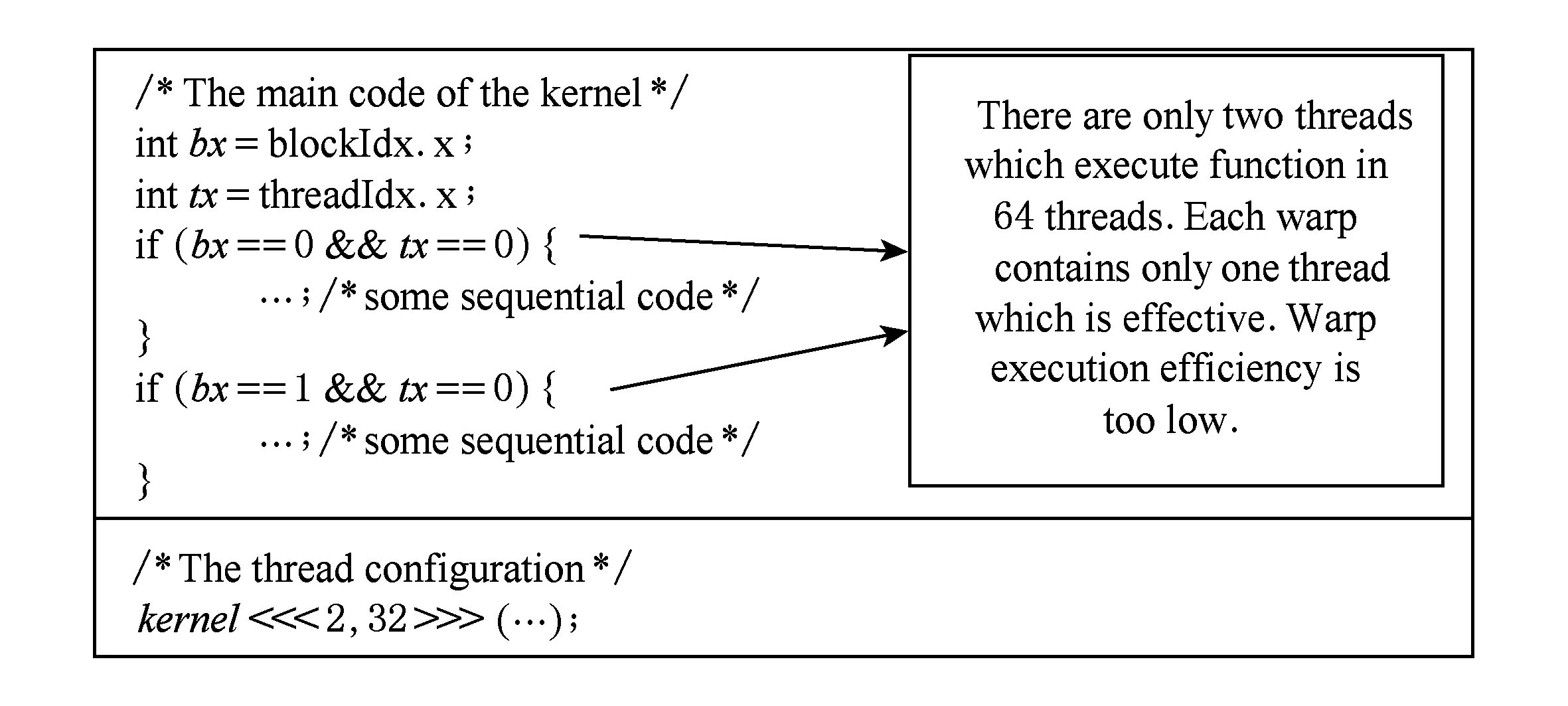
Fig. 12 The analysis of the performance bottleneck of function kernel in program MC.图12 MC程序的函数kernel性能瓶颈分析
LUD程序的函数lud_internal不存在分支指令,warp中所有线程执行路径一致,因此不存在线程分歧,warp执行效率最高,warp_execution_efficiency和warp_nonpred_execution_efficiency值都为1.0.
4.2应用程序分析
求解全球正压大气浅水波方程的程序分为使用共享内存的版本和不使用共享内存的版本,我们对使用共享内存的版本做了分析,分析结果如表3所示:
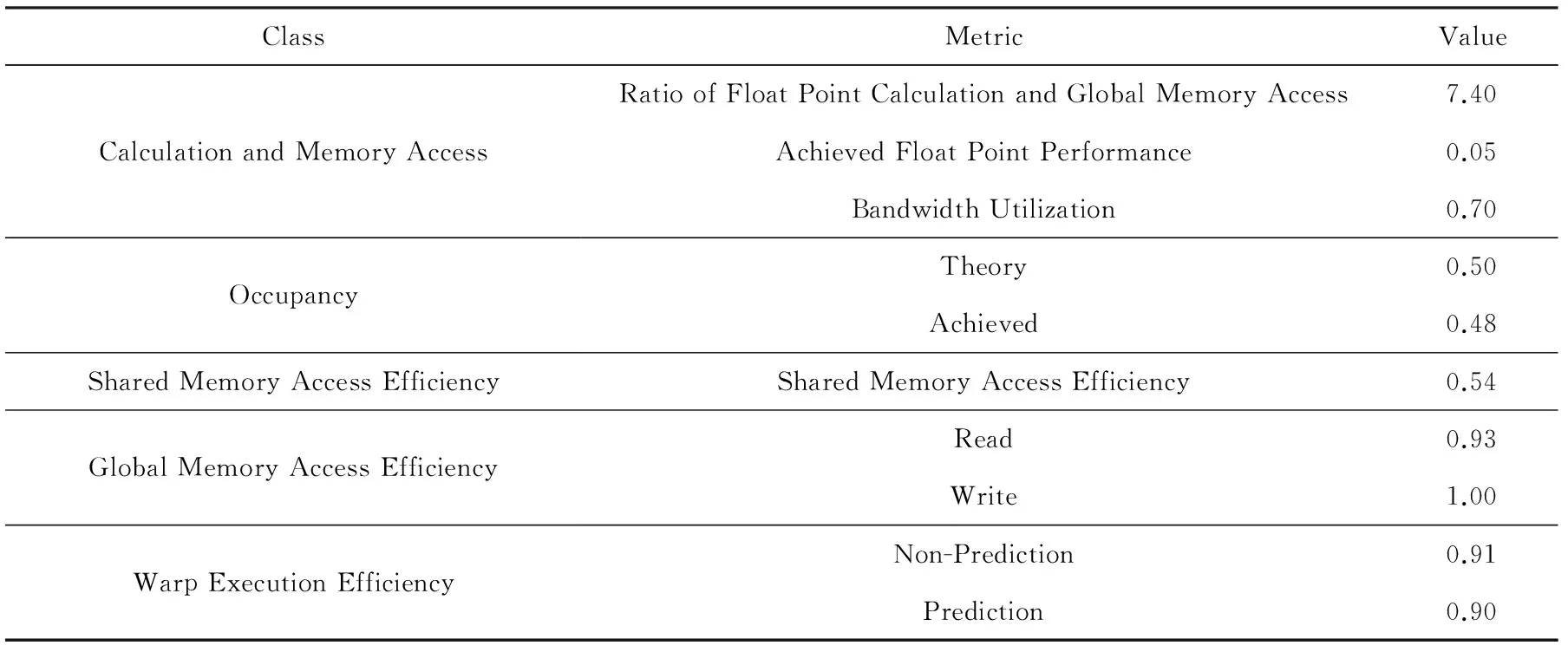
Table 3 The Analysis Result of The Cubed-sphere Shallow-water Model Program
该程序浮点计算与全局内存访问比较高,分析代码可知,程序计算指令比较多且大多数访存是针对的共享存储器,从而有比较高的浮点计算与全局内存访问比值.程序的实测浮点性能与浮点计算单元利用率比较低,而带宽利用率较高,因此,优化时需要重点针对计算指令进行.
程序的GPU占用率指标值较低,分析代码可知,程序中使用了大量的共享内存(每个线程使用40.5 KB共享内存),且大量的局部变量占用了大量的寄存器(每个线程使用63个寄存器),从而使程序无法同时执行太多的线程,导致并行度不够高.优化时,可以将局部变量和共享内存中的常量存储于常数存储器中或使用宏定义来代替,以减少对共享内存和寄存器的使用.
程序的共享内存访问效率比较低,存在bank冲突.优化时需要改变共享内存数组的组织与访问形式,消除bank冲突.程序的全局内存访问效率很高,说明很好地利用了合并访问的机制;程序线程束执行效率很高,不存在大量的影响性能的条件分支.
总体来说,程序应该从计算指令吞吐率、GPU占用率、共享内存数据结构设计和访问方式3个方面来进行优化.
5CUDA程序性能建议
根据对Rodinia和浅水波应用程序的负载分析,本文总结出CUDA程序的性能建议:
1) GPU占用率(occupancy)是反映程序性能的重要指标,能够反映出程序对GPU并行计算单元的利用情况,该值较低表示程序对GPU并行计算单元的利用率较低.影响程序occupancy的指标包括线程块中线程数量、线程占用的寄存器数量和线程块分配的共享存储大小,其中,线程数量反映开发者分配的最大并行线程量,寄存器数量和共享存储大小反映单位线程占用的存储器资源大小.在开发CUDA程序时,一方面要尽量减少核函数中局部变量的数量,以减少对寄存器的占用,同时控制共享内存的占用,通过减少单位线程占用的资源量来增大可以同时发起的线程数量;另一方面,在寄存器和共享内存占用量足够的情况下,按照程序输入规模尽量多地开启并行执行的线程.
2) 共享存储器访问效率(shared_efficiency)反映的是程序中共享内存的使用效率,能够反映程序的bank冲突,该值低于1.0时表示存在bank冲突.不同的GPU架构之下,共享内存会被分为16或32个bank,bank的存储单位大小为4 B或8 B.使用共享存储器时,需要根据变量所占存储空间大小进行控制,尽量使half-warp中的不同线程不访问同一个bank(除非是访问同一个变量).计算能力不小于2.x的GPU的bank数量为32,这是目前主流的GPU结构.对于这其中bank大小为4 B的GPU,共享内存数组元素存储大小不大于8 B时,在每个线程只访问一个元素的情况下各线程连续访问时恰好不会发生bank冲突;大于8 B时可能发生bank冲突,典型地,当数组元素为8 B的2倍及以上的整数倍时会发生bank冲突,由此可知数组元素为基本变量类型时一般不会发生bank冲突,数组元素为存储大小较大的结构体时容易发生bank冲突,bank大小为8 B的GPU在以上情况下发生bank冲突的数组元素存储大小为以上对应大小的倍数.开发者使用共享内存时需要注意以上规律.
3) 全局存储器访问效率(gld_efficiency和gst_efficiency)反映程序中全局内存的访问效率,对应值较小时表示全局内存访问模式或访问时对齐方式没有达到最优.全局内存的合并访问机制大大提高了其访问效率,合并访问对于访问方式有一定的要求,不同的GPU架构之下其要求不尽相同,但都是针对访问地址的连续和对齐2方面.全局内存访问的典型不合理模式包括:依次连续访问元素类型为结构体的数组中结构体元素的同一个成员,进而导致访问地址不连续;条件控制语句中根据变化的条件访问全局内存,导致访问地址的离散化.全局内存访问相对较慢,可以使用其他类型存储器来代替全局存储器以加速数据访问速度,对于常量可以使用常数存储器存储,对于需要多次访问的大量数据则可以存储于共享内存中;对于由于数据量过大等原因而无法存储于其他存储器的全局内存变量,对其访问时尽量使访问地址连续,尽量不要使用结构体数组的数据结构形式,该数据结构形式下很容易使内存访问地址离散化,也要尽量避免在条件控制语句中出现的离散访问;同时,对于不同的GPU架构,需要注意对全局内存数据访问的对齐方式,以充分利用合并访问特性进行访存加速.
4) 线程束执行效率(warp_execution_efficiency与warp_nonpred_execution_efficiency)反映了程序的线程分歧情况,前者没有考虑分支预测,后者反映分支预测的情况,综合2个指标可以全面了解线程分歧情况.线程分歧会导致大量线程等待或执行无效指令,对程序性能影响很大,程序开发者应尽量减少控制语句的使用,使用一些方法将控制语句转化为非控制语句;对于无法避免的控制语句,尽量使其分支以half-warp来划分,使得同一个half-warp中执行同一个分支,从而避免线程分歧.
6结论
本文中,我们分析总结了CUDA程序的重要性能指标,基于CUPTI接口开发了能够获取这些性能指标的性能分析工具,使用该工具对Rodinia中的程序进行了负载分析,并对主要性能指标显示的部分程序的性能瓶颈在源代码中进行了原因分析,之后对全球正压大气浅水波模式应用程序进行了性能分析,讨论了其性能特性.对Rodinia的负载分析结果较全面地反映了常用CUDA程序在各方面的负载特征,该结果可以为未来CUDA程序优化分析及GPU系统结构优化分析提供数据资料.通过对重要性能指标反映有性能瓶颈的部分程序进行分析,我们为开发者展示了常见性能瓶颈的典型原因,并提出了一些开发高效程序的建议.
参考文献
[1]Zhang E Z, Jiang Y, Guo Z, et al. On-the-fly elimination of dynamic irregularities for GPU computing[J]. ACM SIGPLAN Notices, 2011, 46(1): 369-380
[2]Yang Y, Zhou H. CUDA-NP: Realizing nested thread-level parallelism in GPGPU applications[J]. Journal of Computer Science and Technology, 2015, 30(1): 93-106
[3]Margiolas C, O’Boyle M F P. Portable and transparent host-device communication optimization for GPGPU environments[C] //Proc of Annual IEEE/ACM Int Symp on Code Generation and Optimization. New York: ACM, 2014: 55-65
[4]Xiang P, Yang Y, Zhou H. Warp-level divergence in GPUs: Characterization, impact, and mitigation[C] //Proc of the 20th Int Symp on High Performance Computer Architecture (HPCA). Los Alamitos, CA: IEEE Computer Society, 2014: 284-295[5]Che S, Boyer M, Meng J, et al. Rodinia: A benchmark suite for heterogeneous computing[C] //Proc of IEEE Int Symp on Workload Characterization. Piscataway, NJ: IEEE, 2009: 44-54
[6]Yang C, Xue W, Fu H, et al. A peta-scalable CPU-GPU algorithm for global atmospheric simulations[J]. ACM SIGPLAN Notices, 2013, 48(8): 1-11
[7]Browne S, Dongarra J, Garner N, et al. A portable programming interface for performance evaluation on modern processors[J]. International Journal of High Performance Computing Applications, 2000, 14(3): 189-204
[8]Shende S S, Malony A D. The TAU parallel performance system[J]. International Journal of High Performance Computing Applications, 2006, 20(2): 287-311
[9]NVIDIA Corporation. NVIDIA visual profiler[CP/OL]. 2014 [2014-07-15]. https://developer.nvidia.com/nvidia-visual-profiler
[10]Yang Y, Xiang P, Mantor M, et al. Fixing performance bugs: An empirical study of open-source GPGPU programs[C] //Proc of the 41st Int Conf on Parallel Processing (ICPP). Piscataway, NJ: IEEE, 2012: 329-339
[11]Stratton J A, Anssari N, Rodrigues C, et al. Optimization and architecture effects on GPU computing workload performance[C] //Proc of Innovative Parallel Computing. Piscataway, NJ: IEEE, 2012: 1-10
[12]Yang Y, Xiang P, Kong J, et al. A unified optimizing compiler framework for different GPGPU architectures[J]. ACM Trans on Architecture and Code Optimization, 2012, 9(2): 970-983
[13]Li C, Yang Y, Lin Z, et al. Automatic data placement into GPU on-chip memory resources[C] //Proc of IEEE/ACM Int Symp on Code Generation and Optimization (CGO). Piscataway, NJ: IEEE, 2015: 23-33
[14]Chen G, Wu B, Li D, et al. PORPLE: An extensible optimizer for portable data placement on GPU[C] //Proc of the 47th Annual IEEE/ACM Int Symp on Microarchitecture (MICRO). Piscataway, NJ: IEEE, 2014: 88-100
[15]Wahib M, Maruyama N. Scalable kernel fusion for memory-bound GPU applications[C] //Proc of the Int Conf for High Performance Computing, Networking, Storage and Analysis. Piscataway, NJ: IEEE, 2014: 191-202
[16]Li Jianjiang, Li Xinggang, Lu Chuan, et al. A template technology for transplanting from single-GPU programs to multi-GPU programs[J]. Journal of Computer Research and Development, 2010, 47(12): 2185-2191 (in Chinese)(李建江, 李兴钢, 路川, 等. 一种单 GPU 程序向多GPU移植的模板化技术[J]. 计算机研究与发展, 2010, 47(12): 2185-2191)
[17]Williams S, Waterman A, Patterson D. Roofline: An insightful visual performance model for multicore architectures[J]. Communications of the ACM, 2009, 52(4): 65-76

Zheng Zhen, born in 1991. PhD candidate. His main research interests include high performance computing.

Zhai Jidong, born in 1981. PhD and assistant professor. His main research interests include high performance computing and performance evaluation.

Li Yan, born in 1985. PhD. His main research interests include high performance computing and parallel computing.

Chen Wenguang, born in 1972. PhD and professor. His main research interests include high performance computing and compiler optimization.
Workload Analysis for Typical GPU Programs Using CUPTI Interface
Zheng Zhen, Zhai Jidong, Li Yan, and Chen Wenguang
(DepartmentofComputerScienceandTechnology,TsinghuaUniversity,Beijing100084)
AbstractGPU-based high performance computers have become an important trend in the area of high performance computing. However, developing efficient parallel programs on current GPU devices is very complex because of the complex memory hierarchy and thread hierarchy. To address this problem, we summarize five kinds of key metrics that reflect the performance of programs according to the hardware and software architecture. Then we design and implement a performance analysis tool based on underlying CUPTI interfaces provided by NVIDIA, which can collect key metrics automatically without modifying the source code. The tool can analyze the performance behaviors of GPU programs effectively with very little impact on the execution of programs. Finally, we analyze 17 programs in Rodinia benchmark, which is a famous benchmark for GPU programs, and a real application using our tool. By analyzing the value of key metrics, we find the performance bottlenecks of each program and map the bottlenecks back to source code. These analysis results can be used to guide the optimization of CUDA programs and GPU architecture. Result shows that most bottlenecks come from inefficient memory access, and include unreasonable global memory and shared memory access pattern, and low concurrency for these programs. We summarize the common reasons for typical performance bottlenecks and give some high-level suggestions for developing efficient GPU programs.
Key wordsgraphics processing unit (GPU); workload analysis; Rodinia; performance counter; performance metric
收稿日期:2014-12-10;修回日期:2015-08-11
基金项目:国家自然科学基金项目(61103021);国家“八六三”高技术研究发展计划基金项目(2012AA010901)
中图法分类号TP338.4
This work was supported by the National Natural Science Foundation of China (61103021) and the National High Technology Research and Development Program of China (863 Program) (2012AA010901).
猜你喜欢
石油沥青(2021年1期)2021-04-13
空间科学学报(2020年4期)2020-04-22
绿色科技(2017年10期)2017-07-05
科学家(2017年3期)2017-05-22
电子技术与软件工程(2017年1期)2017-03-06
考试周刊(2017年7期)2017-02-06
制冷技术(2016年4期)2016-08-21
测绘科学与工程(2016年4期)2016-04-17
湖南大学学报·自然科学版(2014年5期)2014-08-08
电测与仪表(2014年16期)2014-04-22
