
RFID系统中基于按段排序的防碰撞算法
2016-07-05 09:41:08陈义,李鸿
淮阴师范学院学报(自然科学版) 2016年1期
陈 义, 李 鸿
(1.湖南工业职业技术学院 电子信息工程教研室, 湖南 长沙 410208; 2.长沙理工大学 电气与信息工程学院, 湖南 长沙 410114)
RFID系统中基于按段排序的防碰撞算法
陈义1, 李鸿2
(1.湖南工业职业技术学院 电子信息工程教研室, 湖南 长沙410208; 2.长沙理工大学 电气与信息工程学院, 湖南 长沙410114)
摘要:针对无线射频识别系统中的标签碰撞问题,在商余排序算法的基础上,提出了一种按段排序的防碰撞算法.该算法通过提取碰撞位构建新的ID,并从ID号最高位开始每4个比特位划为一段,根据标签段序列对争用周期时隙数商余运算的结果,确定标签在段序列对应的争用帧内的发送时隙及发送位,从而确定标签的发送顺序.实验结果表明,相比商余排序算法,该算法性能更稳定,识别耗时更少,识别效率提高46%.
关键词:无线射频识别; 按段排序; 提取碰撞位; 商余运算; 发送时隙
0引言
无线射频识别技术(RFID)作为一种非接触式自动识别技术,可通过无线电讯号识别特定目标并读写相关数据.识别过程中无需人工干预,广泛应用于交通管理智能化、商业自动化,物流跟踪自动化等方面,已经成为了研究的重点与热点,具有广阔的发展前景. 但该技术在识别方面存在着较多技术上的难点,标签碰撞就是其中之一,它影响着识别效率、识别速度与识别的稳定性,因此怎样通过一个高效的算法来解决标签碰撞问题是提高无线射频识别系统性能的关键.
标签冲突的本质是多址接入问题,目前常用的两种基于时分多址的反碰撞算法有:基于二进制树的确定算法和基于ALOHA协议的随机算法,二进制树确定算法如二叉树算法[1]在标签过多情况下会产生大量的碰撞时隙;而在基于ALOHA协议的随机算法中,由于标签响应阅读器是随机的,使得标签长时间无法得到识别,导致识别效率低下,这类算法中时隙ALOHA算法[2]、帧时隙ALOHA算法[3]、动态帧时隙ALOHA算法[4]、分组动态帧时隙ALOHA算法[5]是比较经典的算法,但是在同时隙内碰撞问题上未能得到较好解决,其中解决这类问题的方法有比随机数更好的办法为排序算法,该算法使得标签响应阅读器是按顺序进行的.目前排序算法很少,商余排序算法[6]就是仅有的一种排序算法,但是该算法在标签序列号长的场合发生碰撞时效率低,稳定性差,产生的空隙时隙也比较多,导致时隙利用率不高.
根据现有排序算法的不足,提出了一种按段排序的防碰撞算法,首先对序列号进行预处理,然后分段进行排序,有效地解决了因标签数量多、标签序列号长系统工作性能不高的问题.
1基于按段排序的防碰撞算法
1.1算法的优化
基于按段排序的防碰撞算法在商余排序算法[6]的基础上,作了以下优化:
1) 该算法通过Manchester编码鉴别出标签序列号的碰撞位的特征位置,标签返回自身碰撞位与阅读器通信,即预处理.这样有效的减少了标签的长度,提高了系统的效率.
2) 在确定标签的发送顺序的过程中,该算法采用对部分段序列进行商余运算,代替商余排序算法中对整个序列进行运算,这样有效的减少了不必要的计算,减少了计算耗时,从而减少了识别时间,也降低了计算的复杂程度.
3) 在确定争用周期时隙数过程中,该算法的争用周期时隙数目固定为4,而商余排序算法的时隙数随着标签的长度变化而变化,这样在标签序列号长的场合,商余算法产生空闲时隙多,而按段排序算法有效地减少了空闲时隙,提高了时隙利用率.
1.2算法原理
算法中预处理方法利用了曼彻斯特编码的原理,通过判断标签之间数据位对应的曼彻斯特码的上升沿与下降沿是否相互抵消来确定是否发生了碰撞,并记录碰撞的位置,标签接收到阅读器预处理命令提取碰撞位置的数据位形成新的ID,而段序列进行商余运算引入了商余排序对时隙运算的原理,在争用帧发送时隙与发送位的确定过程中,按段排序采取的是段序列对争用周期中时隙数目的运算,每一不同的段序列对时隙数的商余运算的结果是不同的,具有唯一性,因此标签之间不同段序列对应着不同的争用周期中的发送时隙与发送位,其中商余运算后的余数确定标签在段序列对应的争用数据帧内的发送时隙,商确定标签在段序列对应的发送时隙中的发送位,如果段序列相同则商余运算结果相同,则存在标签共用同一发送时隙中的发送位,因此得对当前段序列的下一段序列进行运算,直到识别为止.
1.3算法步骤
Step1: 阅读器发送预处理指令并激活其周围的标签,标签返回自身的碰撞位作为新的ID号与阅读器通信;
Step2: 阅读器发送分段指令,标签把自身新的ID号从最高位开始以4比特位为单位分成几段;
Step3: 标签分段完成后,阅读器发送信道争用指令,标签同步时钟信号,进入信道争用周期;
Step4: 未休眠标签取下一段序列(从第一段开始)进行商余运算,从而确定标签在段序列对应的发送时隙及发送位,并在发送时隙中的发送位填充数据“1”;
Step5: 标签监听争用数据帧,确定标签在段序列对应的发送周期内的发送顺序;
Step6: 进入数据传送周期,标签根据发送顺序在对应的.发送时隙内发送数据,阅读器接收数据后对识别成功的标签发送休眠指令,使标签休眠,阅读器监听信道,如果还有标签共用同一发送时隙中的同一发送位(认定碰撞,阅读器不会对其发送休眠指令),回到步骤4,否则识别结束.
1.4算法举例
对各标签预处理后的新的ID分段排序:首先用标签新的ID的第一段序列除以争用周期时隙数4,得到的余数确定标签在第一段序列对应的争用数据帧内的发送时隙;利用标签这一段的序列除以争用周期时隙数4的商确定标签在第一段序列对应的发送时隙中发送位,然后在发送位(a0、a1、a2、a3)填充数据“1”,从而确定标签在段序列中的发送顺序,其中标签发送顺序=其当前未发生碰撞的发送位及前面未发生碰撞的发送位中“1”的总数,第一段排序完并识别完后,则利用发生了碰撞的标签的第二段序列进行商余运算,重复第一段的操作,以此类推,直到识别每一个标签.如下面标签C的第一段序列为1010,除以时隙数4得到的余数为2即发送时隙为2,商为2即发送位为a2并在这个位填充数据“1”,它在的发送位前面没有发生碰撞的发送位,前面时隙中发送位填充了两个“1”加上本身在的发送位填充的“1”,发送顺序为3.以15位的ID为例假设标签ID号分别A:100110101010001,B:100110111011010, C:101101101111000, D:101101111110000, E:101101111011001, F:101101111110011,具体识别过程如图1、图2所示. 图1与图2是算法实例的实现过程,在图2中争用周期时隙数目为4,分别是时隙0、时隙1、时隙2、时隙3,发送位也为4位,分别为a0、a1、a2、a3.
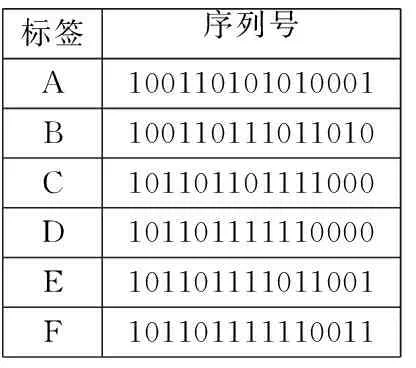
标签序列号A100110101010001B100110111011010C101101101111000D101101111110000E101101111011001F101101111110011

预处理后序列号A:01000001B:01010110C:10101100D:10111000E:10110101F:10111011
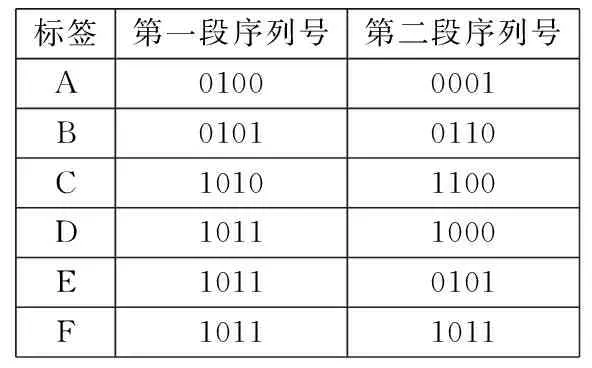
标签第一段序列号第二段序列号A01000001B01010110C10101100D10111000E10110101F10111011
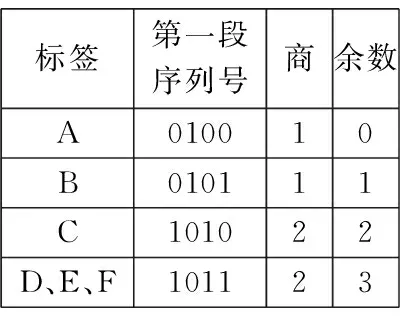
图1 预处理与分段
标签根据在第一段序列中的发送顺序发送数据
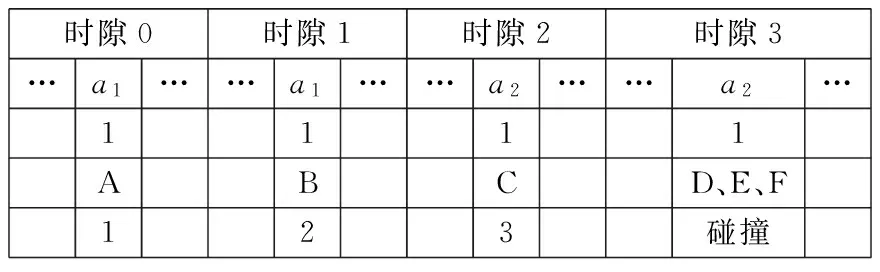
时隙0时隙1时隙2时隙3…a1……a1……a2……a2…1111ABCD、E、F123碰撞
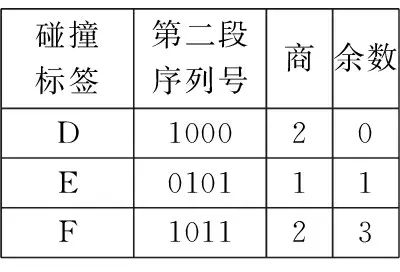
碰撞标签第二段序列号商余数D100020E010111F101123
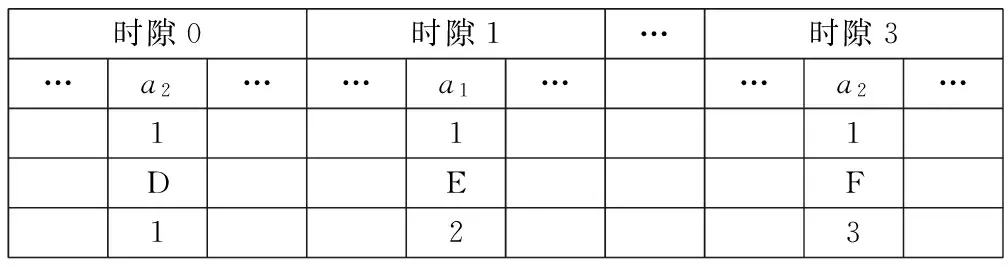
碰撞的标签根据在第二段序列中的发送顺序发送数据
图2段序列的商余运算及争用数据帧填充与排序
2算法分析
假设标签的序列号长度为L,预处理后的标签序列号长度为L1,标签的数量为N,预处理后的标签i在第j段的段序列号为Iij,信道争用开始指令发送时间为T0,阅读器发送预处理命令、分段指令与休眠指令的发送时间分别为Tpre、Tr、T1,数据发送周期的数据帧长度为T,运算过程中位处理时间为,标签i在第j段序列对应的争用周期的发送时隙为Sij,标签i第j段的段序列号对固定时隙数4的商为Qij,标签i在第j段对应的发送顺序为Tij,则:
Sij=Iij/4
(1)
Qij=Iij/4
(2)
式(2)中Qij决定着发送位的大小,当Qij=0,对应于发送位a0;当Qij=1,对应于发送位a1;当Qij=2,对应于发送位a2;当Qij=3,对应于发送位a3.
(3)
式(3)中Pkj=第j段序列对应的发送时隙k内1的个数(其中发送时隙内“1”的个数不包括碰撞的发送位中填充的数据“1”的个数),发送顺序不仅与发送时隙的大小有关,而且与发送位的大小有关,发送时隙不变,发送位越大(Qij越大),发送顺序就越靠后,发送位不变,发送时隙越大(Sij越大),发送顺序也越靠后.
系统效率和识别速度是衡量系统性能的关键因素,这里通过对运算耗时与效率的计算来对系统性能进行分析.按段排序算法采取以4比特位为单位分段运算耗时最少,证明如下:
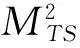
(4)
T耗时min=2L分段/L分段×L1×tb
(5)
令标签预处理后的标签序列号长度L1与位时间长度tb不变,不凡设x=L分段构建一个函数y=2x/x,对y求导数:
y′=(2xln2×x-2x)/x2(x≥4)
(6)
y′>0
(7)
Tn=Tpre+Tr+T0+Tm+T休眠
算法效率的计算公式为:
(8)
3算法仿真
为了从实验角度证明按段排序算法的有效性与优越性,采用了常见仿真工具MATLAB对按段排序算法、商余算法进行了仿真实验.假设电子标签是均匀分布的,通过多次模拟实验求平均的方法得出了按段排序算法的几个参数的值,其中T0=0.05s,T=0.1s,tb=0.001s,,Tpre=0.05s,Tr=0.03s,T1=0.05s.仿真结果在相同的实验条件下进行,分别对以上两种算法的总的运算耗时与系统效率进行了对比.从表1中可以看出,在总的运算耗时中,按段排序算法用时比商余排序算法少.

表1 运算耗时比较
待识别标签数目与标签的序列号长度是影响系统效率的重要因素. 从图3、图4和图5可以看出在标签序列号长度一致的情况下, 文中的按段排序算法的系统效率明显高于商余排序算法且随着标签序
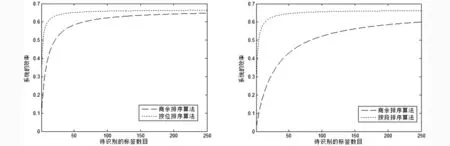
图3 L=32时标签数量与系统效率关系图 图4 L=64时标签数量与系统效率关系图
列号长度变大时,按段排序的效率更是优于商余排序算法.从图6可以看出,当标签数目一定的条件下,标签序列号长度不断增加,商余排序算法的系统效率最差情况下维持在17%左右,按段排序算法维持在63%左右,先比之下效率提高了46%左右.综合分析这4幅图,可以看到在标签数目与标签序列号的长度变化的时候,按段排序算法的效率比较稳定,商余排序算法的效率出现了比较大的变化,因此就稳定而言,按段排序算法更具稳定性.综上,在相同的条件下,按段排序算法的效率与稳定性都比商余排序算法好.
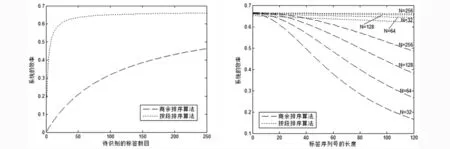
图5 L=128时标签数量与系统效率关系图 图6 标签序列号与系统效率关系图
4结论
提出了一种应用于标签碰撞的按段排序防碰撞算法,应用了预处理与按段进行商余运算的方法,解决了在标签数目多且标签序列号长情况下效率低的问题.相比商余排序算法,按段排序算法更具优越性,不仅效率有了较大改善,而且更好地兼顾了系统的稳定性,提升了系统的性能.但是该算法沿袭了ALOHA与二进制算法的思想,要求各标签需同步.
参考文献:
[1]王雪,钱志鸿. 基于二叉树的RFID防碰撞算法的研究[J]. 通信学报,2010,31(6):49-57.
[2]翟霞晖,唐明浩,金慧芬. 一种基于时隙ALOHA的RFID系统防碰撞算法[J].微计算机信息,2008,24(6):239-240.
[3]Park J, Chung M Y, Lee T J. Identification of RFID tags in framed-slotted ALOHA with robu st estimation and binary selection[J]. IEEE Comm unications Letters, 2007, 11(5): 452-454.
[4]EOM J.LEE T. Accurate tag estimation for dynamic framed-slotted ALOHA in RFID system[J].IEEE Communications Letters,2010,14(1):60-62.
[5]尹君,何怡刚.基于分组动态帧时隙的RFID防碰撞算法[J].计算机工程,2009,35(20):267-269.
[6]王晓华,周晓光,孙百生.射频识别系统中的防碰撞算法设计[J].北京邮电大学学报,2007,20(2)59-62.
[7]魏静,冯秀芳.基于自适应分组的帧时隙ALOHA算法在RFID中的研究[J].计算机技术与发展,2012,22(11):57-60.
[8]Choe J H,Lee D,Lee H. Query tree based reservation for efficient RFID tag anti-collision[J].IEEE Communications Letters,2007,11(1):85-87.
[9]周晓光.射频识别技术原理与应用实例[M].北京:人民邮电出版社,2006.
[10]孙文胜,陈安辉.高效的RFID混合询问树防碰撞算法[J].计算机应用研究,2011,28(10):3717-3719.
[11]李全.基于改进后退策略的按位二进制防碰撞[J]. 机工程,2012,38(3):280-283.
[12]Ryu J,Lee H,Seok Y. A hybrid query tree-protocol for tag collision arbitration in RFID systems[M].//ICC07:IEEE.International Conference on Communications. Picataway, NJ: IEEE Press,2007: 5981-5986.
[13]Sung Hyun Kin, Poo Gyeon. Park an efficienttree based tag anti-collision Protocol for RFID systems[J].IEEE Communication-letters,2007,11(5):449-451.
[14]Seol J M, Kim S W. Collision-resilient multi-state protocol for fast RFID tag identification[M].//International Conference on Computational Intelligence and Security,2006:1159-1162.
[15]Myung Jihoon, Lee Wonjun, Srivastava J, et al. Tag splitting: Adaptive arbitration protocol for RFID tag identification[J]. IEEE Transactions on Parallel and Distributed System, 2007,18(6): 763-775.
[责任编辑:蒋海龙]
Anti-collision Algorithm in RFID System based on
Segment Sorting Algorithm
CHEN Yi1, LI Hong2
(1.Department of Electrical and Information Engineering, Hunan Industry Polytechnic, Changsha Hunan 410208, China)
(2.College of Electrical and Information Engineering, Changsha University of Science and technology, Changsha Hunan 410114, China)
Abstract:To solve the tag collision problem in Radio Frequency Identification(RFID) system, a kind of segment sorting anti-collision algorithm based on quotient and remainder sorting algorithm is proposed. The algorithm is obtained by extracting the collision information to construct new ID and every four bits is divided into a segment starting from the highest bit of ID, through quotient and remainder operating result of tags’ segment sequence to the timeslot number of competitive frame, sent slots and sent bits of tags are determined in the corresponding competitive frame of segments, such that sent sequences of tags in segments are determined. The results show that, compared with quotient and remainder sorting algorithm, the proposed algorithm is more stable and the consuming time of identification is less, the identification efficiency is enhanced by 46%.
Key words:radio frequency identification devices; segment sorting; extracting the collision information; quotient and remainder operation; sent slots
收稿日期:2015-12-11
基金项目:国家自然科学基金资助项目(61074018); 长沙市科技计划项目(K1203020-11)
通讯作者:陈义(1984-),男,湖南常德人,讲师,硕士研究生,研究方向为智能检测与控制技术. E-mail: 40385700@qq.com
中图分类号:TP391.44
文献标识码:A
文章编号:1671-6876(2016)01-0033-05
