
基于组合混沌遗传算法的最小测试用例集生成
2016-06-28 13:20:15申情蒋云良沈张果楼俊钢
电信科学 2016年6期
申情,蒋云良,沈张果,楼俊钢
(湖州师范学院信息工程学院,浙江 湖州 313000)
基于组合混沌遗传算法的最小测试用例集生成
申情,蒋云良,沈张果,楼俊钢
(湖州师范学院信息工程学院,浙江 湖州 313000)
最 小 测 试 用 例 集 生 成 是 软 件 测 试 的 重 要 研 究 领 域 之 一 。 将 具 有 均 匀 分 布 特 性 的 Chebyshev 和 Logistic混沌映射相结合的混沌序列引入遗传算法的选择、交叉和变异操作,并在遗传测试用例选择方法中添加混沌扰动,实现全局最优,以解决遗传算法用于测试用例集约简时局部搜索能力弱、易早熟收敛等问题。 在随机生成的测试用例需求对应关系及 Siemens 测试套件等实例上进行了实验研究, 并与现有的经典方法在测试用例集生成规模和算法执行时间上进行了比较,实验结果表明,在保持算法执行时间的基础上,在遗传测试用例方法中引入混沌映射有助于生成规模更小的测试用例集。
软件测试;测试用例最小化;混沌遗传算法;测试用例
1 引言
计算机系统已被应用到社会生活各方面,软件形式更加复杂多样,规模越来越大。在这样的背景下,保证软件质量,使其准确完成预期目标变得尤为重要。软件测试是软件质量保证中必不可少的一部分,为满足一定测试需求覆盖率,生成的测试用例数目往往异常庞大;另一方面,软件系统开发过程的迭代需要频繁地进行回归测试,测试冗余严重。为提高测试效率、降低测试成本,减少测试用例的执行、管 理 与 维 护 的开 销 ,测 试 用 例 集的 约 简 是 极为 必 要 的[1-3]。
若 用 R={r1,r2,…,rk}表 示 测 试 需 求 集 ,T={t1,t2,… ,tn}表 示测试用例集,(其中,n 代表测试用例数量,k 代表需求数量 ), 可 用 一 个 n×k 矩 阵 g[i][j]来 表 示 测 试 用 例 ti与 测 试 需 求rj的覆盖关系为:
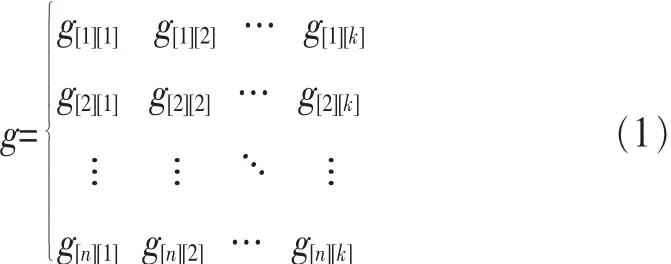
其 中 ,g[i][j]的 取 值 为 0 或 1,g[i][j]=1 则 表 示 用 例 ti可 以 覆盖 需 求 rj,g[i][j]=0 表 示 用 例 ti不 能 覆 盖 需 求 rj。测 试 用 例 最 小化生成问题可以描述如下,给出一个测试用例集 T、一个测试用例需求集 R,R 满足给定程序要求的某种测试覆盖准则,T 可以完成对 R 中所有 ri的测试 ,要 求 从 T 中 找 到一个测试用例优化集,可以满足所有 ri的测试,需要 在大量的测试用例中筛选出最优的测试用例,即能用最少的 测 试 用 例 覆 盖 最 多 的 测 试 需 求[1]。
现有的最小测试用例生成方法主要包括启发式方法,如 Harrold 和 Gupta 使 用 的 贪 心 算 法 和 启 发 式 算 法[4],Chen提 出 的 GE 和 GRE 算 法[5,6];智 能 搜 索 方 法 ,如 邢 颖[7]采 用的 分 支 限 界 搜 索 以 及 爬 山 法 ,Windisch[8]、陈 翔 等 人[9]、王 令赛[10]、史 娇 娇[11]采 用 的 粒 子 群 优 化 算 法 ,Harman、Jones、Lin、Berndt以 及 Michael使 用 的 遗 传 算 法[12-18]等 ;其 他 方 法 还 包括 整 数 规 划 算 法[19]、扩 张 集 算 法[20,21]、有 限 状 态 机[22,23]等 。
其 中 ,遗 传 算法(genetic algorithm,GA)由 于 其 良 好 的 全局搜索能力,在测试用例最小化生成中取得了较好的应用,该算法借鉴达尔文的遗传选择和自然淘汰的生物进化理论完成对测试用例集约简。遗传算法最早由美国Michigan 大 学[24]的 Holland J 教 授 提 出 ,是 一 种 概 率 性 全 局优化方法,其优化对象不需可导或者连续,有较强的全局和并行性,能自动识别搜索过程中的有益信息以指导优化过程,作为一种高效、并行、全局搜索寻优的方法,具有很强的顽健性与适应性,能解决传统优化方法难以解决的复杂优化问题。基于遗传算法的测试用例生成主要思想如下:首先对原始测试用例集进行编码,在此基础上产生若干个测试用例选择方案,构成初始化种群,种群个体即一种可能的测试用例选择方案;然后从种群中选出两个解,使用交叉算子生成新的解,利用测试覆盖率、测试运行代价等评价个体优劣;随后不断地用新个体替代种群中适应值较差的个体,最后得到最优的个体及最优的测试用例选择方案。
在 遗 传 算 法 应 用 于 测 试 用 例 最 小 化 问 题 研 究 上 ,Ma[14]把程序分为若干的块或者段,用 0-1 关系表示被测程序块和测试用例之间的满足情况,设计个体编码,然后利用测试 覆 盖 率 与 测 试 开 销 等 信 息 构 造 适 应 度 函 数 ;Jones[15]用 实验研究表明,遗传算法生成的测试数据比随机法小 1~2个数 量 级 ;Lin[16]使 用 广 义 海 明 距 离 来 优 化 遗 传 测 试 用 例 方法 中 的 适 应 度 函 数 ,进 一 步 提 高 方 法 的 性 能 ;Berndt[17]将输入空间划分成多个区间,根据待选输入的多种特性创建最 小 化 函 数 ;Michael[13]结 合 覆 盖 表 生 成 一 个 最 小 化 函 数 ,采 用 微 分 遗 传 算 法 进 行 全 局 寻 优 ;Khor[18]将 遗 传 算 法 和 正规 概 念 分 析(formal concept analysis)相 结 合 ,进 行 测 试 用 例集 的 生 成 ;Berndt[17]通 过 模 拟 实 验 等 方 法 分 析 了 各 种 基 于遗传算法的测试用例生成方法的性能。
然而普通遗传算法用于测试用例生成也存在局限性,如接近全局最优解时搜索速度会变慢,个体多样性减少较快导致早熟收敛等。针对此,利用混沌理论的遍历性,提出一种基于组合混沌遗传算法的最小测试用例集生成方法(minimized testcasegenerationbasedoncombinationchaosgeneticalgorithm,TCGCG)。采用一种结合 Chebyshev 混沌映射和 Logistic 混沌映 射 的 组 合 混 沌 序 列 产 生 方 法[25],在 种 群 初 始 化 、 交 叉 和 变异的全过程中使用组合混沌序列,利用混沌序列增加各种运算过程的随机均匀性,以降低同种群间个体的相似度,从而提升算法全局搜索能力;同时结合适应度水平设计自适应的交叉概率及变异概率选取策略,既保证适应度较高的优秀个体保留至下一代,保证了种群的多样性,又提高适应度较低个体的变异概率,加快算法收敛速度,降低时间消耗。
2 基于混沌遗传算法的测试用例集约简方法
提出的 TCGCG 方法利用组合混沌映射生成初始种群,每个种群个体包括 n 个基因,种群个体即一种可能的测试用例选择方案,并将具有均匀分布特性的组合混沌序列引入遗传算法的选择、交叉和变异操作,有效地避免了未成熟收敛,提升算法的全局搜索能力和计算效率,混沌系统产生初始种群基因,然后对各个混沌变量附加混沌小扰动进行种群优化,通过不断进化收敛到一个最适合的个体上。从而将测试用例最小化转化为在种群中寻找基因个数最少的个体覆盖所有测试需求。
基于 TCGCG 的测试用例集最小生成方法的基本步骤如 图 1 所 示 ,主 要 包 括 采 用 Chebyshev 映 射 和 Logistic 映射相结合生成混沌序列、利用混沌序列初始化种群、设定个体适应度函数、计算个体适应度、定义遗传算子(选择、交叉、变异)、添加混沌扰动等步骤。
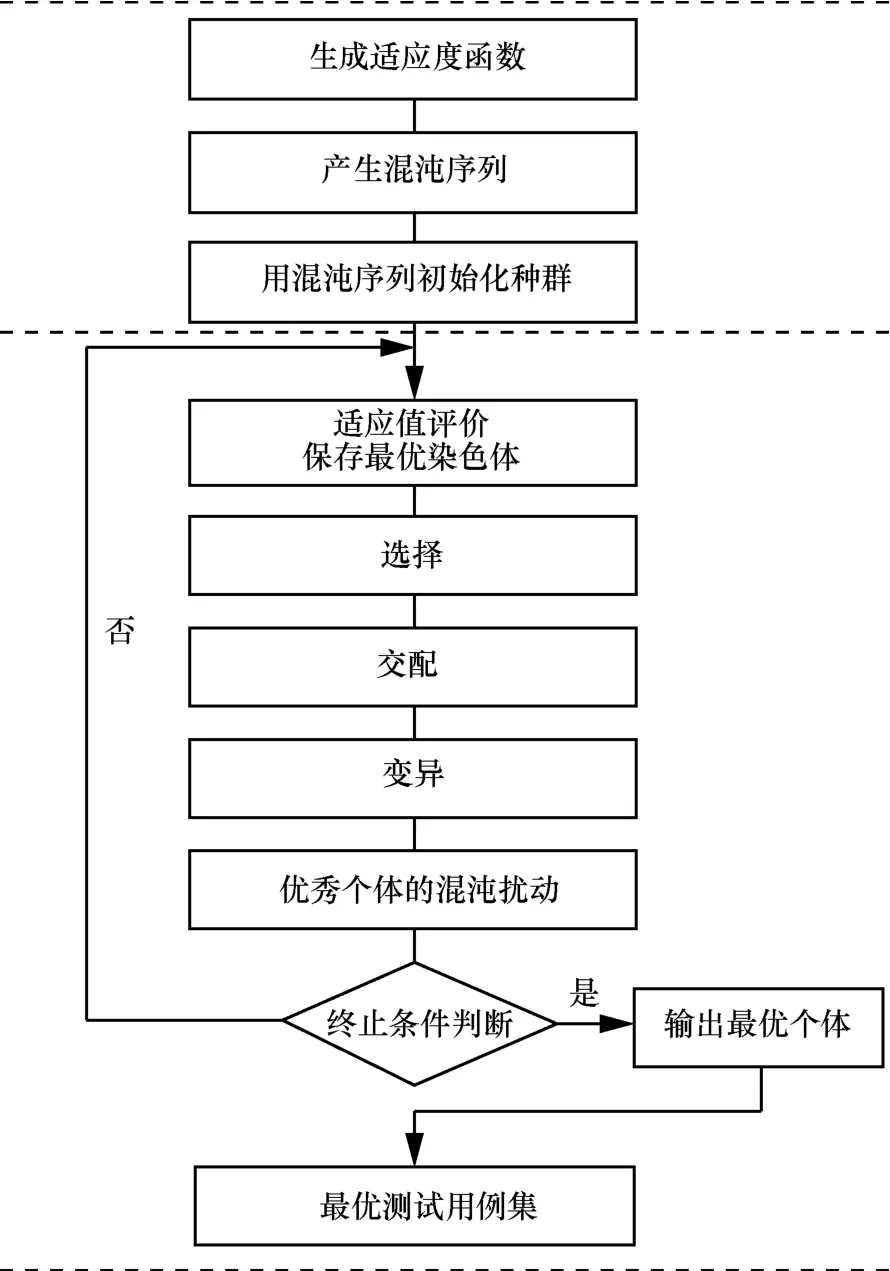
图1 TCGCG 用于测试用例集最小化生成的基本步骤
2.1 产生组合混沌序列
Chebyshev 映 射 :xi+1=cos(karccosxi),xi∈[-1,1],当 映 射阶数 k≥2 时,系统处于混沌状态,不同初值产生的序列间具有自相关性与零值互相关性。
Logistic 映 射 :xi+1=μ·xi·(1-xi),对 初 值 敏 感 ,非 周 期 ,不收敛,μ=4 时处于完全混沌状态。
采 用 Chebyshev 和 Logistic 混 沌 映 射 结 合 的 生 成 方 法 :令 y0=x0为 初 始 值 ,使 用 Chebyshev 映 射 yi+1=cos(karccosyi)得 到 一 个 伪 随 机 序 列 {y0,y1,y2,… ,yl},然 后 将 序 列 取 绝 对 值之 后 与 Logistic 映 射 求 和 temp=μxi(1-xi)+|yi+1|,每 次 迭 代 后采用映射 xi+1=mod(temp,1)保 证 混 沌 序 列 取 值 为(0,1),其中,mod(x,1)算子代表取实数 x 的小数部分。生成混沌序列时,取 μ=4,k=4,可以保证序列完全混沌。该映射将Chebyshev映射和 Logistic 映射中的 两 个 变 量 联 系 起 来 ,以 父 代 混 沌 映射的结果作为子代混沌序列的种子值,提高了伪随机数分布的均匀性,并形成统一的输出序列。
2.2 利用混沌序列初始化种群
假设初始种群中个体数目为 M,未约简前总测试用例数量为 n,则初始种群及种群中个体可分别表示为:
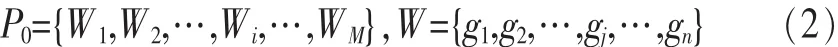
其中,P0表示初始种群,W 表示种群中的个体,Wi表示初始种群中的第 i个初始个体,gj表示该个体上的第 j号染色体。采用第 2.1 节的方法由 M 个不同初值产生 M 个长 度 均 为 n 的 混 沌 序 列 ,对 W1,W2,…,WM上 的 染 色 体 进 行赋值,方法如下:
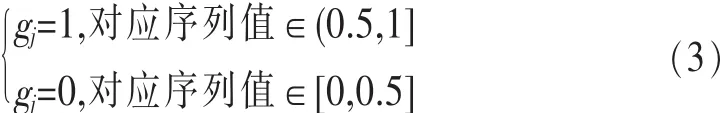
由此完成初始种群中个体的初始化。gj=1 表示第 j号染色体对应的测试用例 被选中,gj=0 表示未被选中 ,一个个体基因编码可以表示所有测试用例是否被选中。
2.3 个体适应度函数
当个体编码改变时需重新计算其适应度,使用传统适应度函数计算式,针对本文的基因编码方式将适应度计算的对象变为对个体 Wi按式(4)进行适应度计算:

其 中 ,Coυ(Wi)指 个 体 的 测 试 覆 盖 度 ,Cost(Wi)是 个 体的 测 试 运 行 代 价 。覆 盖 程 度 Coυ(Wi)为 计 算 父 体 编 码 Wi中覆盖测试需求集的个数。实验中暂不考虑不同测试需求的测试代价不同的影响,对所有的测试用例的代价都设置为 1。
2.4 定义遗传算子
遗传算子包括选择、交叉、变异 3 步,主要对个体进行遗传变异,对其进行优化,最终得到新的个体,新个体的生产可能会增加向最优解变异的机会,因此在遗传算子结束后需再对新的个体进行适应值评价,判断是否满足输出条件。
(1)选择
采用改进的轮盘赌选择算法,利用各个体适应度的概率 决 定 其 遗 留 可 能 性 。 若 某 个 体 Wi的 适 应 度 为 F(Wi),依次计算种群中每个个体的适应度,则第 i个个体的适应度累计值假 设 需 要 选 择 S 个 个 体 直 接 遗 留 到下一代个体,利用第 2.1 节中的混沌映射产生长度为 S 的序 列 {y0,y1,y2,… ,yS},由 于 组 合 混 沌 映 射 生 成 的 组 合 混 沌 序列在统计特性上呈现均匀分布,序列值均匀分布在区间(0,1)上 ,选 择 所 有 满 足 Ci≤yj≤Ci+1,j=0,1,2,…,S 的 S 个 个 体Wi,利用该序列可增加选择运算的随机均匀性,有效提升算 法 的 全 局 搜 索 能 力 ,另 外 Wi被 选 择 的 概 率 为 PWi=从 而 可 以 保 证 适 应 度 越 大 的 个 体 遗 留 的 可 能 性也越大。
(2)交叉
对 2 个 个 体 W1={x1,x2,… ,xn},W2={y1,y2,… ,yn}进 行 交 叉操作时,如果交叉点选择得不适合,则可能出现与父代个体一样的子代个体,导致交叉操作无效。因此,针对遗传算法中交叉算子的不足,首先确认个体交叉点的有效区域,然后在该区域内随机选择交叉点,确保交叉点操作能生成新的和父代个体不同的子代。交叉点的有效区域如下:
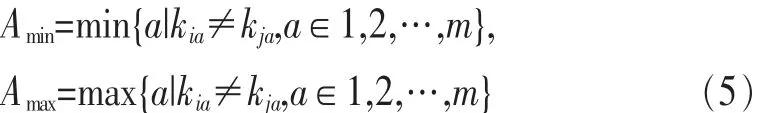
交 叉 点 有 效 区 域 为 (Amin,Amax), 例 如 2 个 个 体 X=(110101),Y=(111010),其 交 叉 点 有 效 区 域 为(3,6)。
在交叉与变异操作中,交叉概率和变异概率的选取对提高搜索性能尤为重要,交叉概率和变异概率越大,则产生新个体的速度就越快,但若选取过大,可能会影响算法中一些重要的数学特性和搜索能力。对于适应度较高的个体,为使其顺利进入下一代,应该给予比较低的概率,而对 于 适 应 度 较 低 的 个 体 则 刚 好 相 反 ,因 此 采 用Srinvivas[26]提出的个体适应度自适应调整办法,具体如式(6)、式(7)所示。
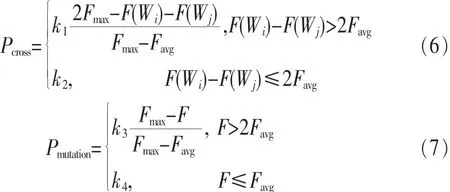
式 (6)中 ,Pcross为 参 与 交 叉 运 算 的 两 个 个 体 的 交 叉 概率 ,Fmax为 群 体 中 适 应 度 的 最 大 值 ,F(Wi)与 F(Wj)分 别 为 待交 叉 的 两 个 个 体 的 适 应 度 值 ,Favg为 群 体 内 所 有 个 体 的 适应 度 均 值 ;式 (7)中 ,Pmutation为 个 体 的 变 异 概 率 ,F 为 参 加 变异运算个 体 的 适应度值 ,k1、k2、k3、k4为常量 系 数。 采用 自适应的交叉概率及变异概率选取策略,既保证了适应度较高的优秀个体保留至下一代,保证了种群的多样性,又提高了适应度较低个体的变异概率,加快了算法的收敛速度。
2.5 添加混沌扰动
对当前种群中适应度后 90%的个体,利用混沌系统,对其进行一定程度的微小扰动,从而提高其适应度。将选中的个体所指代的二进制的每一位都加一混沌扰动,按式(8)进行添加,然后按式(9)映射为优化变量,进行迭代计算。
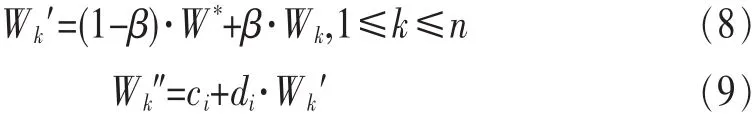
其中,W*为当前最优个体,Wk为当前个体,k 为迭代次 数 ,在式 (9)中 ,ci、di为变换常数。 通 过 式(8)可 得 到 一 组新个体:
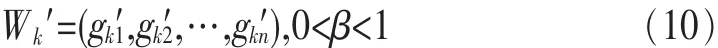
对于式(8)中 β的取值,按照式(7)进行自适应选取:
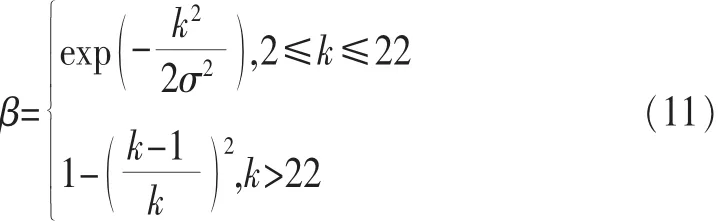
在搜索阶段的初期,希望 Wk取值变动较大,随着搜索逐渐接近最优点,需将 β逐渐缩小,以保证在小范围内找到搜索最优解。
3 实验分析
为验证提出的基于混沌遗传算法测试用例约简方法的有效性,开发相关的测试用例约简工具进行实验研究,比较了 TCGCG 方法与一些其他的遗传算法用于测试用例集约简方法在随机生成的测试用例需求对应关系及Siemens 测试套件等实例上的测试用例集规模和算法执行时 间 。实 验 所 用 计 算 机 处 理 器 配 置为 Intel Core i7-4600U@ 2.10 GHz 2.70 GHz,内 存 为 4 GB,操 作 系 统 为 Windows 7旗 舰 版 64 位 。实 验 中 设 定 最 大 迭 代 次 数 为 1 000,若 迭代 10 代后无明显改进则退出迭代,种群中个体数目 M=50,k1=k3=1,k2=k4=0.5。
3.1 用于比较的遗传测试用例生成算法
实验中用于比较的方法包括:基于一般遗传算法的测试 用 例 生 成 方 法 (test case generation based on genetic algorithm,TCGG)[17]; 在 TCGG 基 础 上 的 对 变 异 算 子 进 行 优化 后 的 改 进 遗 传 算 法 测 试 用 例 最 小 生 成 方 法(modified test case generation based on genetic algorithm ,MTCGG),对 变 异算 子 优 化 采 用 Srinvivas 提 出 的 个 体 适 应 度 自 适 应 调 整 办法,如式(6)、式(7)所示。
3.2 实验一
通过随机函数生成 0-1 矩阵,表示测试用例与测试需求之间的关系,矩阵的规模分 10 组,分别为 20× 20、40×40、60×50、60×60、80×80、90×80、100×100、150× 100、200×150 以 及 300×200,每 组 中 包 含 30 个 矩阵,矩阵 内 各 点通 过 随 机 的 方 式 取 值 为 “1”或 者 “0”,并且确保每个需求至少被 5个测试用例覆盖,每个矩阵各不相同,从而保证实验随机性。对每组对应关系分别运行 TCGG、MTCGG 以及 TCGCG,并 记 录 每 个 矩 阵约 简 花 费 时 间(单 位 为 ms)以 及 约 简 后 的 大 小 ,各 种 情况下每组 30 个矩阵的平均值见表1。表 1 中小括号中的百分比表示总覆盖率未达到 100%。
表1 中列出了在每组数据上使用 TCGG、MTCGG 以及TCGCG 3 种方法约简后平均最小测试用例数、平均花费时间。从表 1 中可以看出,除了使用 TCGG 方法的 100×100矩阵,MTCGG 方法的 60×60、100×100 矩阵,TCGCG 方法的 60×60 矩 阵 ,其 余 情 况 下 使 用 3 种 方 法 都 能 得 到100%的覆盖率,说明遗传算法具有不错的搜索能力 。10组实验中,在平均最小用例数指标上,TCGCG 方法在其中 7组表现最优,包括 20×20(并列)、40×40、80×80、90×80、150×100、200×150、300×200;而 MTCGG 方 法 有 3 组 最优,分别是 60×50、60×60 和 100×100;而采用 TCGG 方法只 有 在 20×20(并 列)矩 阵 上 表 现 最 优 。在 花 费 时 间 指 标上,TCGCG 方法在其中 8 组的表现要优于 TCGG 方法和MTCGG 方法。
图2 中列出了在不同矩阵规模下使用 TCGG、MTCGG以 及 TCGCG 3 种 方 法 约 简 后 平 均 最 小 测 试 用 例 数 的 比较 。从 图 2 中 可 以 看 出 ,大 部 分 情 况 下 使 用 TCGCG、MTCGG 方 法 优 化 得 到 的 最 小 测 试 用 例 集 数 量 要 少 于TCGG。说明通过优化变异算子有助于提高遗传算法的搜索效率,提高寻优能力。
图3 中 列 出 了在不同 矩 阵规模下 使 用 TCGG、MTCGG以 及 TCGCG 3 种 方 法 约 简 后 平 均 花 费 时 间 的 比 较 。 从图3 可 以 看 出 ,矩 阵 规 模较 小 的 时 候 ,TCGCG 与 MTCGG方法可以得到相近的平均最小测试用例数量以及平均花费时间,然而随着矩阵规模变大,TCGCG 方法的优势越来越明显。
3.3 实验二
选 用 space 程 序 以 及 Siemens 提 供 的 5 个 C 程 序 和 相关 的 测 试 套 件 进 行 约 简 算 法 的 比 较[27,28],每 个 程 序 均 设 计了大量测试用例并保证每个需求至少被 30个测试用例覆盖 ,表 2 中给出了每个程序的总 需求数(包 括分支、定义 引用对)以及对应的可执行测试用例数。

表1 不同方法所花费时间及平均最优用例大小比较
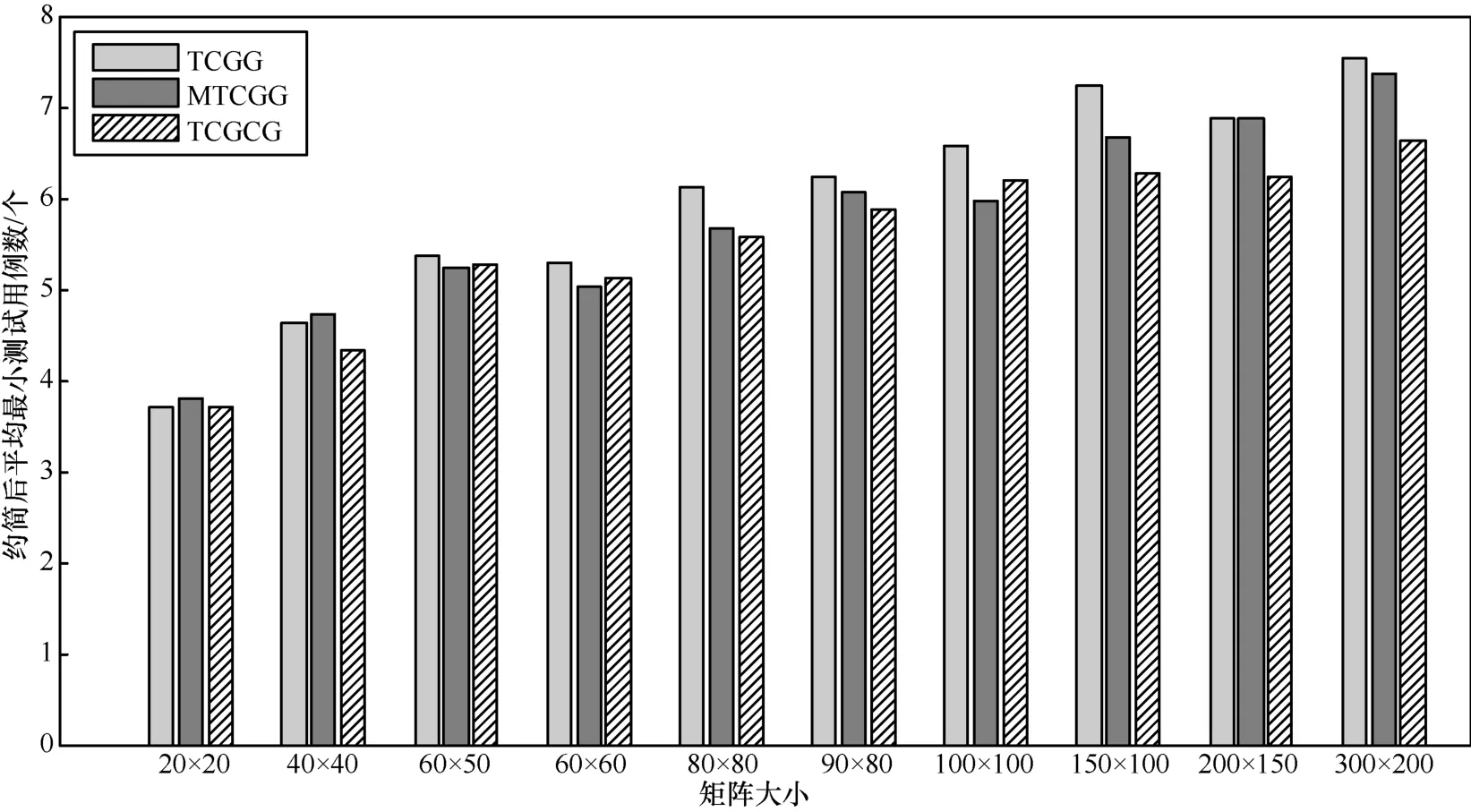
图2 不同矩阵规模下3种方法最小测试用例数比较
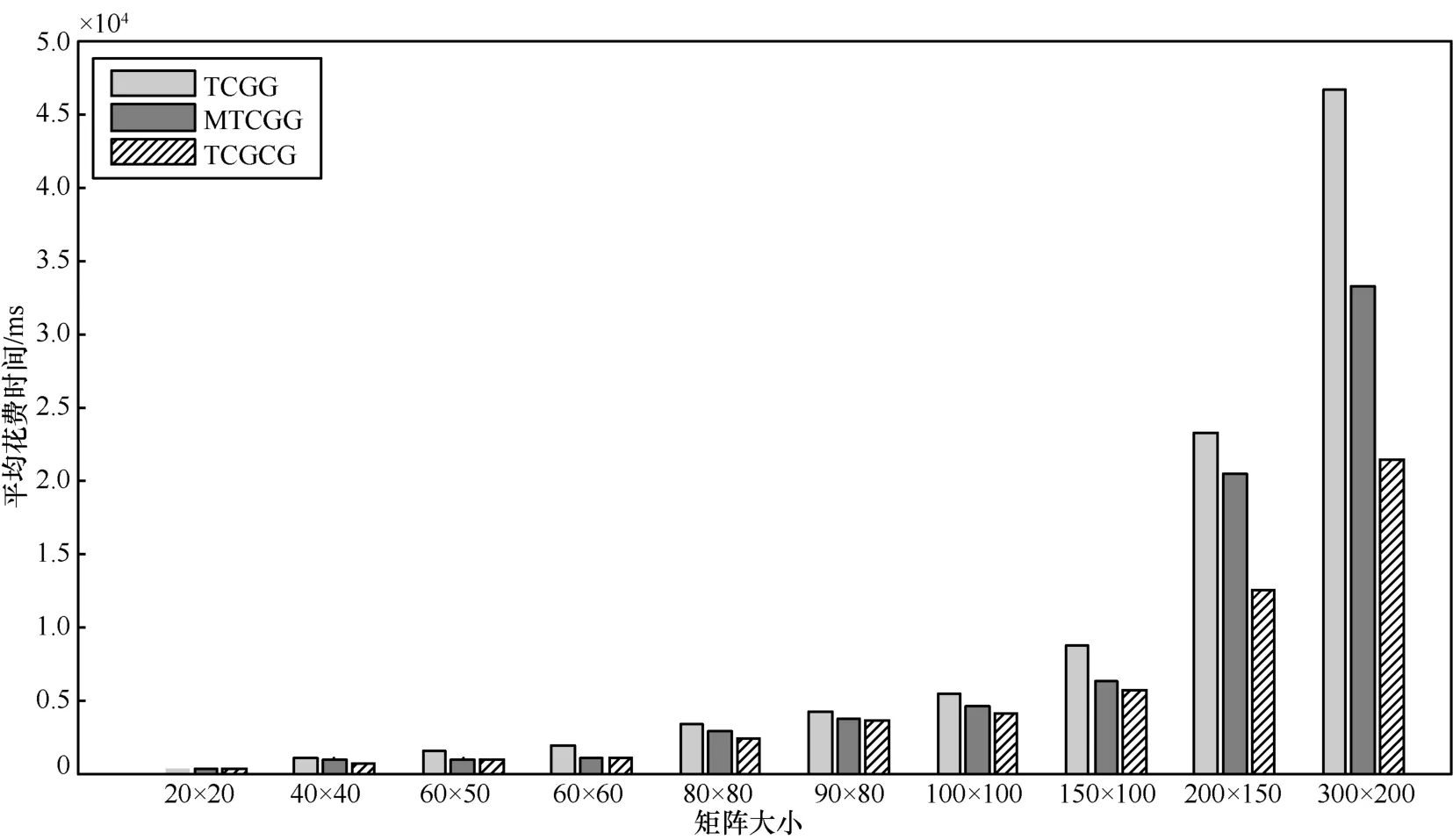
图3 不同矩阵规模下3种方法平均花费时间比较
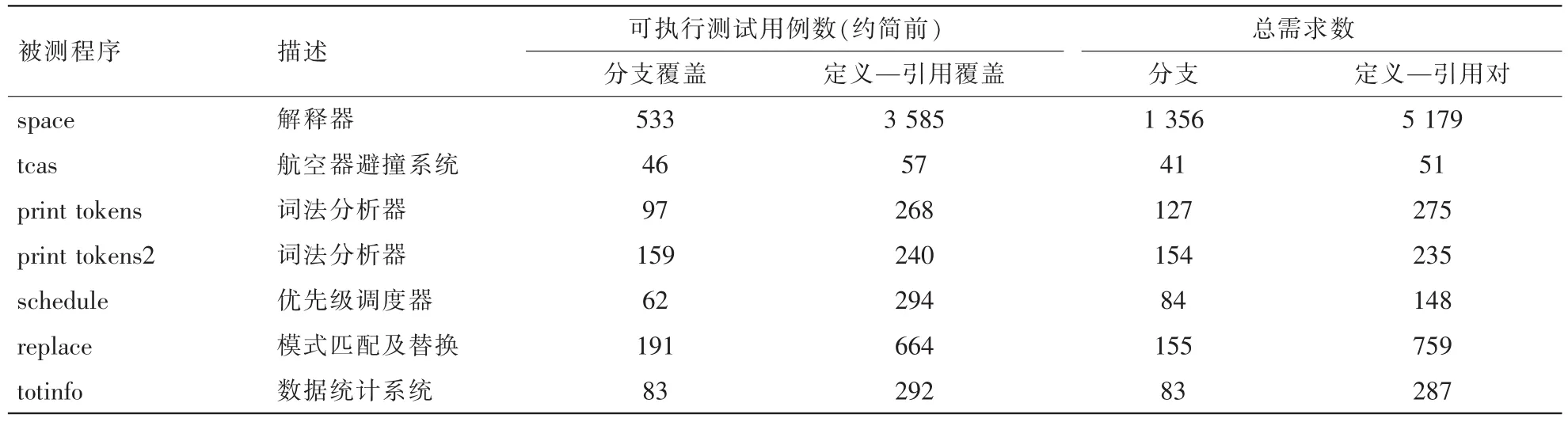
表2 实验评测程序
为确保随机性,实验设计如下:设待测程序测试用例集为{t1,t2,…,tN},选择数量分别为 N1、N2、N3、N4、N5的测试用例进行约简,在不同的初始值 yj0,j=1,2,…,20 的情况下,采用第 4.1 节的方法可产生 20 组 不 同 的 混 沌 序 列{yj0,yj1,yj2,…,yjli},j=1,2,…,20表 示 向 上 取 整 运 算 ),其 中 ,li表 示 每 个 序 列 的 长 度 ,计 算方式为,i=1,2,3,4,5,接 着 在 {t1,t2,… ,tN}中 选 取 编号分别为的测 试 用 例 ,剩 余 的 Ni-li个 测 试 用 例 选 取 要 保 证 所 有测试需求能被 100%覆盖。实验中各待测程序在分支覆盖及 定 义 引用对覆盖时 的 N 值以及 N1、N2、N3、N4、N5值 的选择见表3。

表3 实验评测程序选取的测试用例数量情况
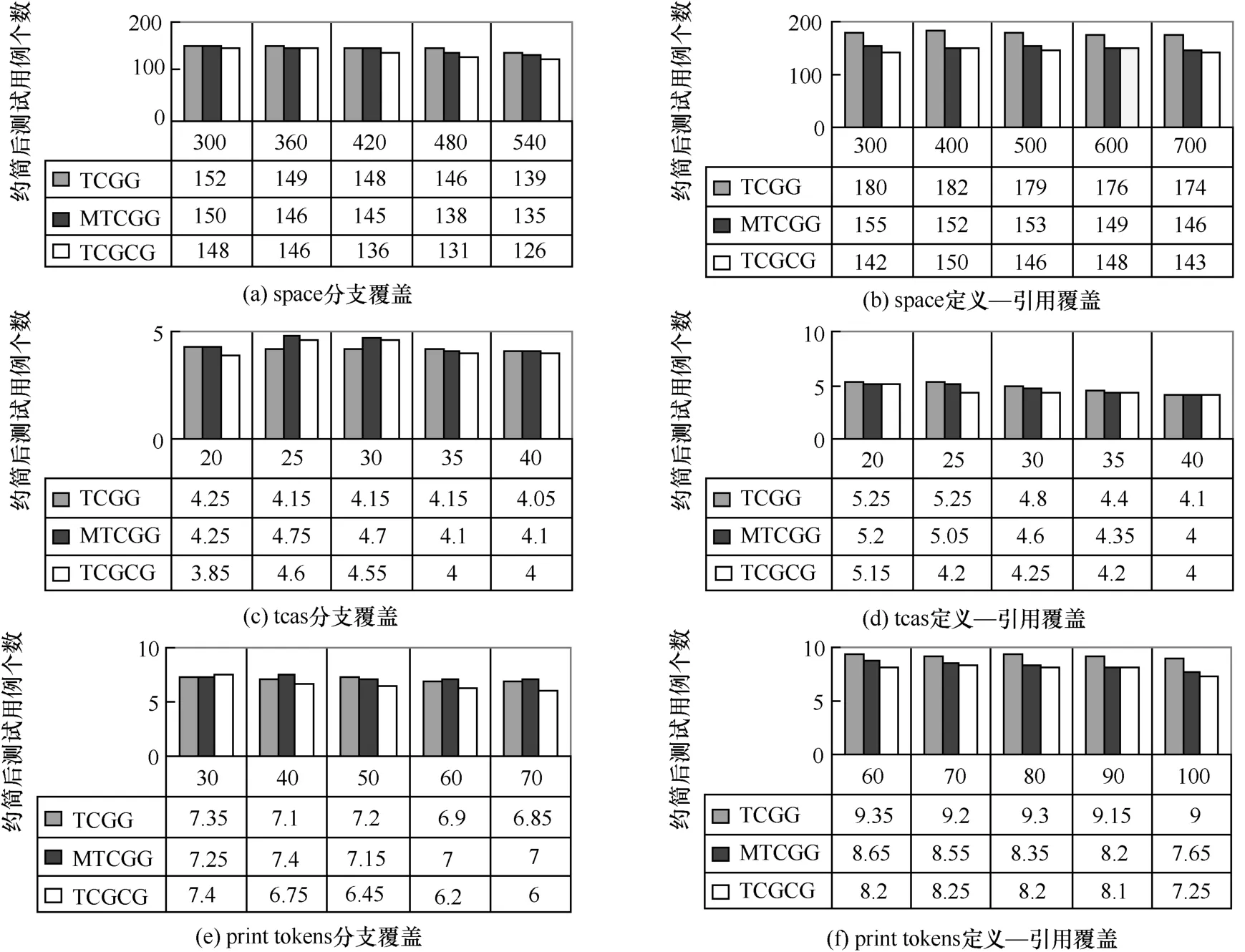
图4中给出了各待测程序在不同初始测试用例集数量情况下 20组测试用例集的平均约简结果,从图 4中可以看出,无论是分支覆盖还是定义—引用覆盖,在大部分情况下,本文提出的 TCGCG 方法要优于 TCGG 方法和MTCGG 方法,可以得到更少的测试用例精简集合。
3.4 实验结果讨论
从两个实验中可以看出,TCGCG 方法和 MTCGG 方法相比 TCGG 方法,可以在更短时间内获得最好的约简效果。这主要是因为它们通过采用自适应的交叉概率及变异概率选取策略,保证了适应度较高的优秀个体保留至下一代,从而提高了适应度较低个体的变异概率,加快算法的收 敛 速 度 ;另 外 一 方 面 ,通 过 将 Chebyshev 和 Logistic 混 沌映射结合的混沌序列引入基于遗传算法的测试用例生成方法的选择、交叉和变异操作,使得种群构造更具均匀分布特性,降低了同种群间个体的相似度,可以提升算法全局搜索能力,因此提出的 TCGCG 方法比 MTCGG 方法以及TCGG 方法在大部分情况下可以得到更好的约简效果。
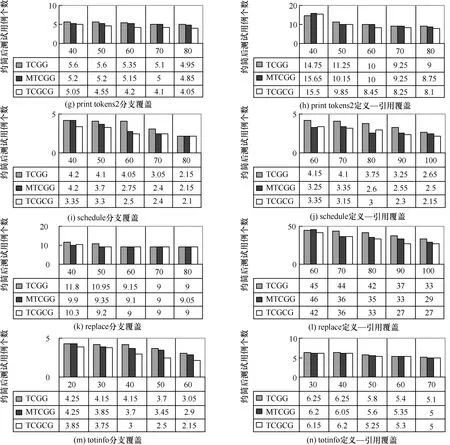
图4 各待测程序不同初始测试用例集数量情况下的平均约简结果
4 结束语
针对测试用例约简的特点,介绍了一种基于组合混沌遗传算法的测试用例约简方法,它将混沌机制引入遗传算法中,并且改进了交叉、变异算子,使得最终能快速搜索到全局最优解。实验证明,这种新的方法能够有效克服遗传算法的早熟收敛等缺陷,对测试用例生成效率有一定的提高 。主 要 工 作 为 : 具 有 均 匀 分 布 特 性 的 Chebyshev 和Logistic 混 沌 映 射 结 合 的 混 沌 序 列 引 入 了 基 于 遗 传 算 法 的测试用例生成方法的选择、交叉和变异操作;采用了一种基于个体适应度的自适应调整的交叉、变异算子,并设计了一种混沌扰动设定的自适应方法;与传统遗传算法在最小测试用例集生成规模和算法执行时间上进行了比较,以验证本文提出方法的有效性。
进一步 的 研 究 工 作 包 括:k1、k2、k3、k4等 参 数 以 及初 始种群规模 M 取值对算法性能、收敛效率的影响;利用已有的测试数据优化初始群体以提高算法收敛速度。
[1] TODD L.An empiricalstudyofregression testselection techniques [J].ACM Transactions on Software Engineering and Methodology,2001,10(2):185-207.
[2] NIE C,LEUNG H.The minimal failure-causing schema of combinatorialtesting [J].ACM Transactions on Software Engineering and Methodology,2011,20(4):1-38.
[3] BIBLE J,ROTHERMEL G,ROSENBLUM D.A comparative study of coarse- and fine-grained safe regression test selection techniques [J].ACM Transactions on Software Engineering and Methodology,2001,10(2):149-183.
[4] HARROLD M,GUPTA R,SOFFA M.A methodology for controlling the size of a test suite [J].ACM Transactions on Software Engineering and Methodology,1993,2(3):270-285.
[5] CHEN T,LAU M.A new heuristic for test suite reduction [J]. Information and Software Technology,1998,40(5):347-354.
[6] CHEN T,LAU M.On the divide and conquer approach towards test suite reduction [J].Information Sciences,2003,152 (1):89-119.
[7] 邢颖,宫云战,王雅文. 基于分支限界搜索框架的测试用例自动 生 成[J]. 中国科 学:信 息 科 学,2014,44(10):1345-1360. XING Y,GONG Y Z,WANG Y W.Based on branch threshold search framework of automatic generation of test cases[J].China Science:Information Science,2014,44(10):1345-1360.
[8] WINDISCH A,WAPPLER S,WEGENER J.Applying particle swarm optimization to software testing [C]//The 9th Annual Conference on Genetic and Evolutionary Computation,April 4-8,2007,London,UK.New Jersey:IEEE Press,2007:1121-1128.
[9] 陈翔,顾庆,王子元.一种基于粒子群优化的成对组合测试算法框架[J]. 软件学报,2011,22(12):2879-2893. CHEN X,GU Q,WANG Z Y.A paired combination test algorithm based on particle swarm optimization framework [J]. Journal of Software,2011,22(12):2879-2893.
[10]史娇娇,姜淑娟,韩寒. 自适应粒子群优化算法及其在测试数据生成中的应用研究[J]. 电子学报,2013,41(8):1555-1559. SHI J J,JIANG S J,HAN H.Adaptive particle swarm optimization algorithm and its application in test data generation[J].Electronic Journals,2013,41(8):1555-1559.
[11]王令赛,姜淑娟,张艳梅.基于正交搜索的粒子群优化测试用例生成方法[J]. 电子学报,2014,42(12):2345-2351. WANG L S,JIANG S J,ZHANG Y M.Particle swarm optimization based on orthogonal search method for generating test cases[J].Electronic Journals,2014,42(12):2345-2351.
[12]YOO S,HARMAN M.Regression testing minimization,selection and prioritization:a survey [J].Journal of Software Testing, Verification and Reliability,2012,22(2):67-120.
[13]MICHAEL C C,MCGRAW G E,SCHATZ M A.Generating software test data by evolution[J].IEEE Transactions on Software Engineering,2001,27(12):1085-1110.
[14]MA X Y,SHENG B K,YE C Q.Test-suite reduction using geneticalgorithm [C]//The6th InternationalWorkshop on Advanced Parallel Processing Technologies,April 5-10,2005,Hong Kong,China.New Jersey:IEEE Press,2005:253-262.
[15]JONES B,EYRES D.A strategy for using genetic algorithms to automate branch and fault-based testing [J].The Computer Journal,1998,41(2):98-107
[16]LIN J C,YEH P L.Using genetic algorithms for test case generation in path testing [C]//The 9th Asian Test Symposium,October 3-5,2000,Washington D C,USA.New Jersey:IEEE Press,2000:241-246
[17]BERNDT D,FISHER J,JOHNSON L.Breeding software test cases with genetic algorithms [C]//The 36th Hawaii International Conference on System Sciences,May 5-8,2003,Hawaii,USA. New Jersey:IEEE Press,2003:17-26
[18]KHOR S,GROGONO P.Using a genetic algorithm and formal conceptanalysis to generate branch coverage testdata automatically [C]//The 26th IEEE/ACM International Conference on Automated Software Engineering (ASE 2011),IEEE Computer Society,November 6-10,2004,Lawrence,KS,USA.New Jersey:IEEE Press,2004:346-349.
[19]LEE J,CHUNG C.An optimal representative sets election method [J].Information and Software Technology,2000,42 (1):17-25.
[20]MARRE M,BERTOLINO A.Using spanning sets for coverage testing [J].IEEETransactionsonSoftwareEngineering,2003,29(11):974-984.
[21]JEFFREY D,GUPTA N.Improving fault detection capability by selectively retaining test cases during test suite reduction [J]. IEEE TransactionsonSoftwareEngineering,2007,33 (2):108-123.
[22]张涌,钱乐秋,王渊峰.基于扩展有限状态机测试中测试输入数据自动选取的研究[J]. 计算机学报,2003 26(10):1295-1303. ZHANG Y,QIAN L Q,WANG Y F.Based on extended finite state machine test input data in the automatic selection of research[J].Journal of Computer,2003,26(10):1295-1303.
[23]杨瑞,陈振宇,张智轶. 一种基于扩展有限状态机的自动化测 试 用 例 生 成 方 法 [J]. 中 国 科 学 :信 息 科 学 ,2014,44(5):588-609. YANG R,CHEN Z Y,ZHANG Z Y.Based on extended finite state machine automation test case generation method [J].China Science:Information Science,2014,44(5):588-609.
[24]HOLLAND J.Adaption in natural and artificial systems [M]. Boston:MIT Press,2015:126-137.
[25]俎云霄,周杰.基于组合混沌遗传算法的认知无线电资源分配[J]. 物理学报,2011,60(7):079501. ZU Y X,ZHOU J.Based on the combination of chaos genetic algorithm in cognitive radio resource allocation [J].Journal of Physics,2011,60(7):079501.
[26]SRINIVASM, PATNAIK L M.Adaptiveprobabilitiesof crossover and mutation in genetic algorithms [J].IEEE Transactions on System,Man and Cybern,1994,24(4):656-667.
[27]HARMAN M.The current state and future of search based software engineering[C]//The 29th IEEE International Conference on Software Engineering.Minneapolis, May 23-25, 2007,Minneapolis,MN,USA.New Jersey:IEEE Press,2007:342-357.
[28]University of Nebraska-Lincoln.Computer science&engineering[EB/OL].(2016-02-11)[2016-03-12].http://www.cse.unl.edu.
Test case minimizing based on combination chaos genetic algorithm
SHEN Qing,JIANG Yunliang,SHEN Zhangguo,LOU Jungang
School of Information Engineering,Huzhou University,Huzhou 313000,China
Test case minimizing is one of the most important research fields in software testing.Uniformly distributed Chebyshev and Logistic chaos sequence were introduced in the selection,crossover and mutation of genetic algorithm.Chaos disturbance was also added in genetic testing suite to address the common problems of weak ability in local search and premature convergence,thus to optimize the test result.Experiments were conducted in randomly generated test suites and Siemens test suites.Comparisons were also made with classical methods regard to the scale of production of test suite and the execution time of the algorithms.The results of the experiment indicate that based on the same execution time of the algorithms,a smaller scale test suite can be produced by introducing chaotic sequence in genetic testing suite selection.
software testing,test cases minimizing,chaos genetic algorithm,test case
s:The National Natural Science Foundation of China (No.61103051),Natural Science Foundation of Zhejiang Province(No.LY15F020018),Zhejiang Provincial Science and Technology Plan of China (No.2015C33247),Science and Technology Program of Huzhou City (No.2014GZ02)
TP311
:A
10.11959/j.issn.1000-0801.2016178

申情(1982-),女,湖州师范学院讲师,主要研究方向为软件测试、人工智能、系统性能评估等。

蒋云良(1967-),男,博士,湖州师范学院教授,主要研究方向为智能信息处理、GIS 等。

沈张果(1982-),男,湖州师范学院讲师,主要研究方向为大数据分析、软件可靠性建模、智能交通等。

楼俊钢(1982-),男,博士,湖州师范学院副教授,主要研究方向为软件可靠性建模、软件测试、大数据分析等。
2016-02-23;
:2016-06-14
蒋云良,jyl@zjhu.edu.cn
国家自然科学基金资助项目(No.61103051);浙江省自然科学基金资助项目(No.LY15F020018);浙江省公益性技术应用研 究计 划 基 金 资 助 项 目(No.2015C33247);湖州市科技计划基金资助项目(No.2014GZ02)
猜你喜欢
计算机仿真(2022年8期)2022-09-28 09:53:02
铁道通信信号(2020年6期)2020-09-21 09:23:22
成都信息工程大学学报(2019年2期)2019-08-28 10:00:46
传感器与微系统(2018年7期)2018-08-29 00:44:18
自动化学报(2018年2期)2018-04-12 05:46:01
成都信息工程大学学报(2017年1期)2017-07-21 14:14:11
中国塑料(2016年11期)2016-04-16 05:26:02
浙江理工大学学报(自然科学版)(2015年7期)2015-03-01 02:54:29
河南科技(2014年7期)2014-02-27 14:11:29
教育与职业(2014年16期)2014-01-19 01:24:36
