
基于Spark的协同过滤算法的研究
2016-06-14 02:12于娜娜王中杰同济大学电子与信息工程学院上海201804
系统仿真技术 2016年1期
于娜娜,王中杰(同济大学电子与信息工程学院,上海201804)
基于Spark的协同过滤算法的研究
于娜娜,王中杰
(同济大学电子与信息工程学院,上海201804)
摘 要:随着互联网的普及,人们从海量的信息中搜索出自己所需要的信息无疑变得非常困难。推荐系统能够通过分析用户的兴趣和行为而智能地向用户推荐所需信息,因而得到人们的青睐,并激发了各界人士对它的研究兴趣。基于ALS的协同过滤推荐算法是推荐系统中比较常用的一种通过矩阵分解技术进行推荐的算法,它通过综合大量的用户评分数据进行计算,并存储计算过程中产生的庞大特征矩阵,如果在单节点上运行可能会遇到计算速度的瓶颈。SPark是一种新型的分布式大数据通用计算平台,具有优异的计算性能,本文主要对现有的基于ALS的协同过滤算法和SPark进行了研究,实现了基于ALS的协同过滤算法在SPark上的并行化运行,并且通过实验与HadooP对比证明了该算法在SPark上运行的快速性。
关键词:推荐系统;协同过滤;矩阵分解;ALS;SPark
1 引 言
随着互联网的普及和互联网用户数量的迅猛增长,互联网上的信息呈现爆炸式的增长。虽然海量的信息为满足互联网用户纷繁复杂的信息需求带来了前所未有的机遇,但是也对信息处理技术提出严峻的挑战[1],用户无法从海量的信息中快速准确地搜索到自己所需要的信息。在这种背景下,推荐系统应运而生,推荐系统通过收集和分析用户的各种信息来学习用户的兴趣和行为模式,来为用户推荐他所需要的服务[1~3]。协同过滤是推荐技术中运用最成功和最广泛的技术之一,主要分三类:基于用户(User-based)的协同过滤,基于项目(Item-based)的协同过滤和基于模型(Model-based)的协同过滤。本文主要研究基于模型的协同过滤。
基于模型的协同过滤是一个典型的机器学习的问题,主要是基于样本的用户喜好信息,训练一个推荐模型,然后根据实时的用户喜好信息进行预测,计算推荐,核心在于如何将用户实时或者近期的喜好信息反馈给训练好的模型,从而提高推荐的准确度[4]。该算法性能的优劣关键在于好的模型建立与否,因为好的模型相对原始数据集而言小得多却能挖掘出用户和项目之间更多的潜在关系,在一定程度上不仅有效缓解了推荐算法的实时性问题,同时有效解决了用户¯项目评分矩阵的稀疏性问题,在推荐性能上更优[5]。当前,基于模型的协同过滤算法主要包括概率相关模型、线性回归、聚类等数据挖掘和机器学习方面的模型[6]。本文主要介绍的基于ALS矩阵分解算法就属于基于隐语义模型(Latent Factor Model)的协同过滤推荐算法。在这个模型里,用户和商品通过一组隐性因子进行表达,并且这些因子也用来预测缺失的元素,那么学习这些潜在因子的方法本文用的便是交替最小二乘法ALS。
在目前的协同过滤研究中,大多是单节点进行实验和调试的。但随着大数据时代的到来,推荐系统需要存储的用户数据和物品数据迅速增长,在单节点上计算并实现这些算法变得非常慢,使得推荐无法实时进行,推荐周期很长,更新和反馈很慢将会导致用户体验不好,无法满足用户兴趣的变化,因此需要对这些算法进行并行计算,提高算法计算效率,加速推荐结果的产生,适应用户兴趣的变化,同时也会推动大数据协同过滤算法的学术研究和实践应用。
目前的数据并行处理平台有两种,即HadooP 和SPark。由于HadooP的MaPReduce每次计算都要从磁盘读或写数据,同时整个计算模型需要网络传输,这就导致了HadooP越来越不能忍受的高延迟性。SPark,这种新型的分布式大数据计算平台的出现正解决了此困境,基于RDD(弹性分布式数据集),它的Job中间输出和结果可保存在内存中,减少了访问硬盘I/O次数,可以有较高的运算速度。因此本文着重研究基于ALS的协同过滤算法在SPark上的实现问题。
2 Spark平台
2.1Spark平台部署
2.1.1环境说明
本文搭建的SPark集群采用的是实验室的三台普通PC,包括1个Master节点和2个Slave节点,三个节点均为Ubuntu14.10系统,节点之间局域网连接。具体情况如表1所示。

表1 节点具体说明Tab.1 The details of th ree nodes
2.1.2软件安装
JavaJDK用的是jdk -7u75 -linux-i586.gz,hadooP版本为hadooP -2.6.0.tar.gz,安装过程中最重要的一点就是配置SSH实现无密码远程登陆与管理。搭建好HadooP集群之后,在此基础上进行SPark的安装,其版本为SPark1.2.0,开发环境IntelliJIDEA 14.0.3,对应的Scala为scala-sdk -2.10.4。所有软件在三台机器上安装并配置好后即可启动SPark分布式集群。
2.2Spark集群的特点
APache SPark官方的定义是[7]:SPark是一个通用的大规模数据快速处理引擎。可以简单地理解为SPark就是一个大数据分布式处理框架。SPark具有以下优势:快速性,SPark基于内存的计算速度比HadooP MaP Reduce快很多。易用性,提供多语言编程,简洁的函数式编程语言Scala能快速实现应用。通用性,提供了一个强大的技术堆栈,如机器学习工具MLlib,图计算工具GraPhX,实时流处理工具SPark Streaming等,尤其是MLlib使得原本复杂的机器学习在理解和使用上变的灵活而简易。本文的协同过滤算法即是基于MLlib实现的。
RDD(Resilient Distributed Datasets)是SPark的核心,是分布于各个计算节点存储于内存中的数据对象集合,可以让用户在执行多个查询时显式地将数据缓存在内存中,在后续的查询过程中能够重用这些数据集,从而提供了低延迟性。RDD具有很好的容错机制,它能记住构建它的操作图,记录如何从其他RDD转换而来(即Lineage),当执行任务的数据节点出现故障,可以通过操作图获得之前执行的操作而恢复丢失的分区即重建丢失的数据。RDD只能通过在其他RDD执行确定的转换操作而创建,与大多数的分布式数据集采用的需付出高昂成本代价的数据检查点的容错性实现方式不同,RDD只包含如何从其他RDD衍生所必需的信息,不需要检查点操作就可以重构丢失的数据分区。
2.3Spark的工作流程
在SPark中,数据集的划分和任务调度都是系统自动完成的,其工作流程如图1所示。
SPark程序在运行时,首先会创建SParkContext来作为任务调度的总入口,在其初始化工作环境过程中会创建DAGScheduler(进行Stage调度)和Task Scheduler(进行Task调度)两个模块。DAGScheduler模块负责为每个SParkJob计算具有依赖关系的多个Stage任务阶段,然后将每个Stage划分为具体的一组任务(可以在worker节点上并行执行的tasks),并以TaskSet的形式提交给TaskScheduler模块来执行。
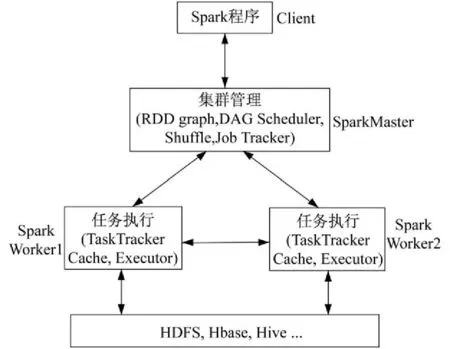
图1 Spark工作流程Fig.1 W ork ing Process of Spark
3 基于ALS的协同过滤算法
基于矩阵分解模型的协同过滤推荐算法主要有:SVD(奇异值分解)和ALS。实际上,矩阵分解模型与前面提到的隐语义模型是一个意思,即通过降维的方式将评分矩阵补全。早期的SVD首先通过加权平均值等方法对用户评分矩阵R中的空缺元素补全得到矩阵R΄,然后利用数学中的SVD对R΄进行分解。Simon、Korean[8]等人也提出新的SVD++模型,然而这种方法的计算复杂度非常高,很难在实际的推荐系统中应用[9]。随着Netflix Prize比赛的进行,先后出现了一些高效的矩阵分解算法,其中Zhou等[10]人提出的基于交替最小二乘法(ALS)的协同过滤算法是一个强大的矩阵分解算法,能很好的扩展到分布式计算以及解决数据稀疏问题。下面以用户与电影评分矩阵为例来讲述基于ALS协同过滤算法的原理[11]。

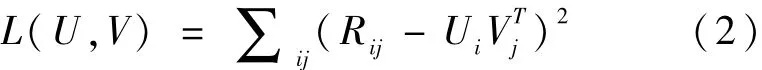
为了防止过拟合,给上式添加二阶正则化项,即为:

如果已知V,可以使用岭回归(Ridge Regression)预测U的每一行,反之亦可。因此,固定V矩阵,对Ui求导,得到下面求解Ui.的公式

在上式中,Ri.表示用户i对电影的评分向量,Vui表示由用户i评价过的电影的特征向量组成的特征矩阵。nui表示用户i评价过的电影数量。同理,固定U矩阵,得到下面求解Vj.的公式

在上式中,R.j表示给电影j评过分的用户的评分向量,Umj表示由为电影j评过分的用户的特征向量组成的特征矩阵。nmj表示为电影j评过分的用户数量。I为一个d×d的单位矩阵。
基于交替最小二乘法(ALS)的协同过滤算法,即是交替调用公式(4)、(5)更新计算U,V。直到计算出的结果收敛或者迭代的次数达到最大值,然后结束计算。最终求出逼近矩阵X,使用X进行电影的推荐。
在SPark上实现算法时,首先将原始的数据集存放在分布式文件系统HDFS上,然后读取HDFS上的数据,并将其转化为压缩矩阵,根据转化后的矩阵数据创建RDD,将每次迭代产生的中间数据U和V,以及数据集缓存(cache)到内存中[12]。
4 实验结果分析
4.1实验数据集
由于搜集满足条件的数据集不是很方便,所以本文采用了网上公开的MovieLens的数据集[13],在这里选用的是100K(10万条),1M(约100万条)和从100K中随机抽取的1万条这三组的数据进行实验,分别随机取数据集中的80%作为训练集,20%作为测试集。
4.2结果分析
4.2.1准确度
该算法是一个典型的基于评分的用户-商品推荐算法,推荐结果的准确度必是推荐中的核心问题,我们一般采用均方根误差(RMSE)来评价评分预测的准确度。误差越小,意味着准确度越高。其公式为:
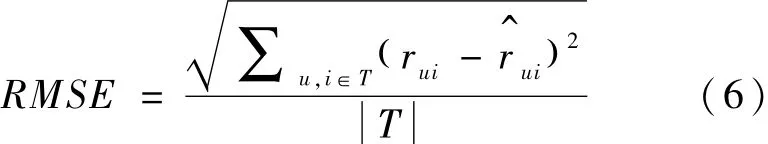
在式(6)中,rui表示用户u对电影i的实际评分,是通过推荐算法预测的评分。该部分选用的是100K数据集。
在上述ALS算法中,我们知道需要设置一些训练参数,参数选择的好坏直接决定了模型的好坏。ALS训练算法中最重要的参数是正则化常数λ和迭代次数。当两个参数取值不同时,实验结果如表2所示。由图可以看出,正则化常数对结果影响非常大,迭代次数影响稍小。通过不断地尝试,找到最佳模型参数取值。当然,其他的模型参数如矩阵因子排名,特征值个数对结果也有影响,还有待研究。
4.2.2快速性
快速性是推荐系统中至关重要的问题,它决定了一个算法能否根据用户兴趣和喜好的变化实时的推荐相关物品,我们分别采用1W、10W和100W条数据对HadooP和SPark的快速性分别进行了分析,如图2所示。

表2 参数影响Tab.2 Effects of param eters

图2 快速性比较Fig.2 The com parison of rapid ity
由图2可以看出,当数据量很小时,HadooP 与SPark的运行时间差别不大,当数据量越大,SPark的基于内存计算的优势越能够体现出来,而且当数据量增大时,SPark的运行时间增加得比较缓慢,HadooP增加得比较快速,可以想象,当数据量非常大时,HadooP运行将会非常慢,从而不能够及时地向用户推荐当下喜欢的物品。
5 结束语
本文主要是研究了基于ALS的协同过滤推荐算法在SPark平台上的实现,通过实验表明,SPark作为新一代数据并行处理平台,在运行时间和运行准确度上都有良好的表现,能够有效地处理大数据的运算问题,而且数据量越大,这种优势越明显。但SPark作为新出现的并行数据处理平台,后续还有很多工作要做,如(1)对SPark平台工作原理深入研究,在任务调度方面进行优化,达到负载均衡,提高运算速度。(2)ALS模型训练参数的选择,寻求一种智能算法,能帮我们自动的选择最优的参数,而不是手工尝试。(3)增加SPark集群节点数目,在故障性和扩展性方面进行研究。
参考文献:
[1] Ricci F,Rokach L,ShaPira B,et al.Recommender system handbook[M].[S.l.]:SPringer,2011.
[2] 李改,李磊.基于矩阵分解的协同过滤算法[J].计算机工程与应用,2011,47(30):4 -7.
LIGai,LILei.The collaborative filtering algorithm based on matrix decomPosition[J].ComPuter Engineering and APPlications,2011,47(30):4 -7.
[3] 刘青文.基于协同过滤的推荐算法研究[D].中国科学技术大学,2013.
LIU Qingwen.Research of recommendation algorith -mbased on collaborative filtering[D].University of Science and Technology of China,2013.
[4] 王家林.大数据SPark企业级实战[C].北京:电子工业出版社,2015,431 -450.
WANG Jialin.The enterPrise actual combat of big data SPark[C].Beijing:Publishing House of Electronics Industry,2015,431 -450.
[5] 王全民,苗雨,何明,郑爽.基于矩阵分解的协同过滤算法的并行化研究[J].计算机技术与发展,2015,25 (2):55 -59.
WANG Quanmin,MIAO Yu,HE Ming,ZHENG Shuang. Parallelize research of collaborative filtering algorithm based on matrix factorization[J].ComPuter Technology and DeveloPment,2015,25(2):55 -59.
[6] 刘希伟.基于协同过滤的大数据挖掘分析方法研究[D].浙江工业大学,2014.
LIU Xiwei.Research on big datamining analysismethod based on collaborative filtering[D].Zhejiang University of Technology,2014.
[7] httP:∥sPark.aPache.org/
[8] Pan R,Zhou Y,Cao B,et al.One-class collaborative filtering[C]∥Data M ining,2008.ICDM΄08.Eighth IEEE International Conference.IEEE,2008:502 -511.
[9] 刘强.协同过滤推荐系统中的关键算法研究[D].浙江大学,2013.
LIU Qiang. Research on the key algorithm in collaborative filtering recommendation system[D]. Zhejiang University,2013.
[10] Zhou Yunhong,W ilkinson D,Schreiber R,et al.Large-scale Parallel collaborative filtering for the netflix Prize [C]∥Proc of the 4 th international conference on algorthmic asPects in information and management. Shanghai:SPringer,2008:337 -348.
[11] httP:∥www2.research.att.com/~volinsky/PaPers/ ieeecomPuter.Pdf
[12] 高彦杰.SPark大数据处理,技术、应用与性能优化[C].北京:机械工业出版社,2015,215 -237.
GAOYanjie.The Processing of SPark big data,technology,aPPlication and Performance oPtim ization[C]. Beijing:China Machine Press,2015,215 -237.
[13] httP:∥grouPlens.org/datasets/movielens/
[14] Y.Koren.Factorization Meets the Neighborhood:a Multifaceted Collaborative Filtering Model. In Proceedings of the 14 th ACM SIGKDD International Conference on Know ledge Discovery and Data Mining,ACM,2008:426 -434.
[15] 孙远帅.基于大数据的推荐算法研究[D].厦门大学,2014.
SUN Yuanshuai.Recommendation A lgorithms in the big data Era[D].Xiamen University,2014.

于娜娜 女(1990 -),山东曲阜人,硕士生,主要研究方向为控制理论与控制工程,分布式计算等。

王中杰 女(1971 -),辽宁葫芦岛人、博士、教授,主要研究方向为智能系统、优化理论与技术、大数据应用。
Research on Collaborative Filtering Algorithm Based onSpark
YU Nana,WANG Zhongjie
(Tongji University,College of Electronic and Information,Shanghai201804,China)
Abstrac t:W ith the PoPularity of the Internet,it undoubtedly becomes very difficult for PeoPle to search the information they need from the vast amounts of information.Recommendation system can recommend related information to users intelligently through the analysis of the interests and behaviors of users. Therefore,it got the favor of PeoPle and insPired researchers' interests in study.The collaborative filtering recommendation algorithm based on ALS is one of a relatively common algorithm by matrix factorization technique from recommendation systems.Because it combines a lot of ratings data to calculate and store characteristic matrix in the Process of calculation,itmay encounter the bottleneck of com Putation sPeed if it runs on a single node.SPark is a new kind of distributed comPuting Platform in the big data era and it has excellent comPuting Performance.In this PaPer,firstly,we make research on the existing collaborative filtering algorithm based on ALS and the big data distributed com Puting Platform of SPark.Then,I realize Parallel oPeration of the algorithm on SPark.Finally,I Prove the quickness of the collaborative filtering recommendation algorithm runs on SPark by exPeriment comPared w ith HadooP.
Key words:recommendation system;collaborative filtering;matrix factorization;alternating least squares;sPark
中图分类号:391
文献标识码:A
猜你喜欢
软件(2016年4期)2017-01-20
计算机时代(2016年12期)2017-01-14
计算机应用(2016年12期)2017-01-13
中国新通信(2016年22期)2017-01-13
软件导刊(2016年11期)2016-12-22
现代情报(2016年11期)2016-12-21
电脑知识与技术(2016年28期)2016-12-21
电脑知识与技术(2016年27期)2016-12-15
电脑知识与技术(2016年27期)2016-12-15
电脑知识与技术(2016年26期)2016-11-24
