
带后续迭代的双极S函数激励的WASD神经网络*
2016-06-05 15:19:26张雨浓肖争利丁思彤毛明志刘锦荣
中山大学学报(自然科学版)(中英文) 2016年4期
张雨浓,肖争利,丁思彤,毛明志,刘锦荣
(1. 中山大学数据科学与计算机学院,广东 广州510006;2. 华南理工大学自主系统和网络控制教育部重点实验室,广东 广州510640;3. 广东顺德中山大学卡内基梅隆大学国际联合研究院,广东 佛山528300)
带后续迭代的双极S函数激励的WASD神经网络*
张雨浓1,2,3,肖争利1,2,3,丁思彤1,2,3,毛明志1,刘锦荣1
(1. 中山大学数据科学与计算机学院,广东 广州510006;2. 华南理工大学自主系统和网络控制教育部重点实验室,广东 广州510640;3. 广东顺德中山大学卡内基梅隆大学国际联合研究院,广东 佛山528300)
结合Levenberg-Marquardt算法以及权值直接确定法这两种用于神经网络学习训练的方法,提出了一种带后续迭代、面向双极S (sigmoid)激励函数神经网络的权值与结构确定(weights-and-structure-determination, WASD)方法。该方法与MATLAB软件神经网络工具箱相结合,可以解决传统神经网络普遍存在的学习时间长、网络结构难以确定、学习能力和泛化能力有待提高等不足,同时具有较好的可行性和可操作性。以非线性函数的数据拟合为例,计算机数值实验和对比结果证实了WASD方法确定出最优隐神经元数和最优权值的优越性,最终得到的WASD神经网络具有更为优异的学习性能和泛化性能。
神经网络;权值与结构直接确定;后续迭代;双极S激励函数;数值实验
人工神经网络,简称神经网络(neural network),是模拟生物神经系统的组织结构、处理方式和系统功能的简化系统[1]。自1980年代形成热潮至今已近30年,神经网络的应用范围已扩展到许多领域[2-5],其中,前向神经网络在各种类型的神经网络当中应用最为广泛。在现实世界中,很多非线性系统是未知的,而针对这些未知的系统进行建模是非常困难的。由于前向神经网络具有强大的非线性映射能力[6-7],所以,可以在不清楚输入输出变量之间复杂关系的情况下,利用前向神经网络对非线性系统或函数实现建模和数据逼近[8-10],从而为工程方面的应用提供了良好的支撑。相关研究理论已经证明[6-7,9,11-12],一个以S (sigmoid)函数为隐层神经元激励函数的三层前向神经网络可以实现对任何连续函数的任意精度的逼近。
学习能力和泛化能力是神经网络性能的重要反映,没有学习能力和泛化能力的神经网络是没有使用价值的[13]。值得指出的是,影响神经网络这两种能力的因素主要包括激励函数、网络结构和网络学习算法等。因此,如何选择较优的激励函数、网络结构以及网络学习算法来保证神经网络的优良性能显得非常重要[14-15]。针对前向神经网络,一些学者已进行了深入研究,并取得诸多成果[2,16-20]。具体到学习算法而言,也提出了很多有效的算法[16-20]。其中,Levenberg-Marquardt (LM)算法和广义多项式神经网络的权值直接确定法尤为突出[16-17],它们都具有学习速度快和逼近效果好等优点,因而得到较广泛的应用[17]。在网络结构方面也有部分学者提出了一些方法和研究理论[21-23],他们的做法能在一定程度上解决学习时间过长、网络结构难以确定、学习能力和泛化能力不足等问题,但是,就目前而言和整体而言,网络结构的确定和最优化仍然是一个挑战。
为了解决上述问题,综合考虑影响神经网络性能的主要因素,本文,在以双极S激励函数为隐层神经元激励函数的三层前向神经网络模型的基础上,结合两种有效的神经网络学习训练方法(也即,Levenberg-Marquardt算法和权值直接确定法[16-17]),对隐层神经元采用边增边删的结构增长策略[18-19],提出了一种带后续迭代的、面向双极S激励函数神经网络的权值与结构确定(weights-and-structure- determination, WASD)方法。该方法可以在较短时间内确定神经网络结构的同时,实现神经网络性能最优化(即,获得最好的学习能力和泛化能力)。其包括两个过程,即,确定最优隐层神经元数及最优隐层到输出层权值的过程,和输入层到隐层权值的进一步迭代优化的过程。值得指出的是,本文的三层前向神经网络模型(WASD神经网络模型)是以双极S激励函数为隐层神经元激励函数的三层前向神经网络模型,其首次结合Levenberg-Marquardt算法和权值直接确定法,这是以往他人研究工作中没有研究过的,是本文的贡献之一。此外,在本论文中,提出了一个新颖的权值与结构确定及后续迭代的思想。即,先随机获取神经网络的输入层到隐层的权值,再用无迭代的权值直接确定法得到隐层到输出层的最优权值以及对应的最优结构,之后再利用LM算法反过来对输入层到隐层的权值进行后续迭代优化。也即,输入层随机化+隐层直接确定+输入层后续迭代。这是本文工作的另一个贡献之处。更重要的是,计算机数值实验结果证实了该算法的有效性和可行性:用该算法得到的神经网络在非线性函数数据拟合和预测方面获得优异的效果,可以达到优异的学习精度和测试精度。
1 神经网络模型
双极S激励函数是可微和有界的,被广泛应用于神经网络研究当中。研究表明[24-25]:使用双极S激励函数比使用单极S激励函数具有更快的收敛速度,故本文构造了一种双极S激励函数神经网络模型,如图1所示。网络的具体描述如下:输入层神经元个数设为m,神经元阈值恒定设为0,神经元激励函数采用线性恒等激励函数;输入层神经元到隐层神经元的连接权值在(-10,10)区间内随机初始化;隐层神经元个数设为n,其具体个数由后述的WASD算法确定,神经元的阈值在(-10,10)区间内随机初始化,而神经元激励函数采用双极S激励函数,且其倾斜参数c设定为1,即另外,隐层神经元到输出层神经元的连接权值由后述的权值直接确定法无迭代得到;输出层神经元个数为1,其阈值恒定设为0,神经元激励函数也采用线性恒等激励函数。

图1 双极S激励函数神经网络模型Fig.1 Neural network model activated by bipolar sigmoid functions
(1)
1)xv表示一个输入向量的第ν个变量(特征),其中ν=1,2,…,m;
2)ωk,j为第k个输入层神经元和第j个隐层神经元之间的连接权值,其中k=1,2,…,m,j=1,2,…,n;

4)βj为第j个隐层神经元的阈值;
5)wj为第j个隐层神经元和输出层神经元之间的连接权值;
6)y为输出层神经元的输出值。
2 权值阈值计算
实际上,对网络进行学习训练的过程就是神经元之间的连接权值和神经元阈值的修正过程,其最终目的是:使神经网络尽量对学习样本集实现有效逼近;同时,对于学习样本集以外的测试样本或数据,神经网络也能够进行有效的辨识。尽管对神经网络权值和阈值的训练方法有很多,但并非每一种训练方法都是有效的,训练方法的优劣对网络的最终训练效果影响重大。因此,本文结合权值直接确定法和Levenberg-Marquardt算法作为WASD算法的权值和阈值计算方法。
对于图1所示的神经网络模型,在网络学习第i个样本时,第j个隐层神经元的输出表示为
输出层神经元的输出值为
神经网络的隐层神经元到输出层神经元的连接权值向量为
w=[w1,w2,…,wn]T∈Rn
网络的目标输出向量表示为
对应的网络的实际输出向量为
定义网络输出均方误差(meansquarederror,MSE)为
对于所有的学习样本,隐层神经元的输出矩阵为
基于上述定义,根据权值直接确定法[14],隐层神经元到输出层神经元的最优稳态权值向量可无迭代给定为
(2)
其中,P+为矩阵P的伪逆矩阵。
基于图1所示的神经网络模型,在确定了网络隐层神经元到输出层神经元的最优权值以及对应的最优结构后,对输入层和隐层神经元之间的连接权值以及隐层神经元的阈值的修正,本文采用高效的LM迭代计算方法[15,26]。也即,在之后的计算中,将网络隐层神经元的阈值等效为网络输入层到隐层神经元的权值的一部分,具体表示如下:
其中M=nm+n。令ei(χ)=γi-yi(χ),误差向量为e(χ)=[e1(χ),e2(χ),…,eN(χ)]T∈RN。令J(χ)为e(χ)的雅克比矩阵:
因此,根据上述推导,基于图1所示的神经网络模型,输入层到隐层的连接权值以及隐层神经元的阈值可通过Levenberg-Marquardt算法进行如下后续迭代修正:
(3)
(4)
式中,l为迭代计数(l=1,2,3,…),μl>0,I为单位矩阵。值得指出的是,在迭代过程中,μl是一个非常重要的调整变量,其调整策略是:开始时μl取一个较小的正数(如0.001),如果某一次调整不能使网络性能优化函数下降,则μl乘以一个大于1的参数μinc(如10),重复调整,直到使网络性能优化函数下降为止;相反,如果某一次调整可以使网络性能优化函数下降,则μl乘以一个小于1的参数μdec(如0.1)。
3 带后续迭代的WASD算法
神经网络的结构是影响神经网络性能最重要的因素之一,因此,神经网络的结构(也即是隐层神经元数)的选择是一个值得深入研究的问题。如果选取不当,就会影响网络的性能:具体而言,若神经元数过多,网络结构则较为冗余,网络学习与校验时因计算所需的内存空间较大,且可能出现过拟合,使网络的泛化能力下降;相反,若网络的神经元数太少,就会导致欠拟合而弱化网络的学习能力[15]。没有学习能力和泛化能力的网络是没有实用价值的[13],因而在设计网络时,隐层神经元数的选择就极为重要。
针对隐层神经元数的选择,一些学者已进行了深入研究,但大多数的做法在实际问题求解中普遍存在着隐层神经元数庞大、学习过程振荡、学习时间过长和泛化能力较低等不足。实际上,其最终得到的网络结构是和网络的学习算法紧密相关的、非最优的[25]。以函数数据拟合为例,基于前文所述的权值直接确定算法,用图1所示的神经网络模型对如下非线性目标函数进行学习:
(0.5x2-0.5)3+5
学习过程中,隐层神经元数初始化设为1,以后每次增加1个神经元,所得到学习误差E随隐层神经元数n递增而变化的结果如图2所示。

图2 神经网络的学习误差E和隐层神经元数n的关系Fig.2 Relationship between neural network learning error E and neuron number n
由该图可知:随着神经元数的增加,在最初时,网络学习误差下降,且下降速度较快;但当神经元数增加至一定程度,网络学习误差出现振荡,即在一个较小的范围内波动,难以继续下降,这表明,神经网络的隐神经元数开始饱和了。值得指出的是,用不同的目标函数进行实验,最终也得到与图2有相似特征的实验结果。
Levenberg-Marquardt算法是神经网络BP算法中最优越的一个[16],它具有训练速度快的优点,故我们可以用它来得到输入层到隐层的连接权值。结合神经网络权值直接确定法和Levenberg-Marquardt算法的优点[16-17],使用边增边删的神经元增长策略[18-19],本文提出带后续迭代的WASD算法。其具体描述如下。
输入:学习样本、目标精度Eg、最长执行时间Tmax
输出:学习误差E、隐层神经元数n
Step1:初始化神经网络,E←10,n←1,计数器C1←1,执行时间T←0;
Step2:输入层神经元到第n个隐层神经元的连接权值以及隐层神经元的阈值随机获取;
Step3:计算隐层神经元的输出矩阵P,再根据权值直接确定法[即,公式(2)],无迭代直接计算出最优权值w,然后计算出当前学习误差E1;
Step4:若满足E1≤E,则E←E1,增加一个隐层神经元n←n+1,C1←1;否则,删除第n个隐层神经元以及神经元的连接权值,C1←C1+1;
Step5:若C1≤5,则跳至Step2;否则(即,连续5次增加隐层神经元失败),直接进入Step6;
Step6:计算雅克比矩阵J(χl);
Step7:根据LM法[即,公式(4)],计算出Δχl;
Step8:把χl+Δχl作为变量参数,计算出当前的学习误差E2;
Step9:若E2≥E,则μl←μlμinc,然后跳至Step7;否则,E←E2,μl←μlμdec,χl+1←χl+Δχl;
Step10:在没有选择手动停止的前提下,若T
显然,该算法是由以下两个过程组成:① 过程1 (Step1至Step5)确定最优隐层神经元数及隐层到输出层最优权值;②过程2 (Step6至Step10)是使用LM算法对输入层和隐层神经元之间的连接权值以及隐层神经元的阈值进行后续迭代优化过程。为了更好地展示该WASD算法,其算法流程图如图3所示。

图3 带后续迭代的WASD算法流程图Fig.3 Flowchart of WASD algorithm with subsequent iterations
值得指出的是,MATLAB软件具有较好的开放性,除内部函数外,所有主包文件和各种工具箱都是可读、可修改的文件[27-28]。故以二输入神经网络为例,本文WASD算法和Levenberg-Marquardt算法结合调用神经网络工具箱的部分实现代码如图4所示。

图4 二输入WASD神经网络涉及工具箱调用的部分实现代码Fig.4 Partial code of implementation of two-input WASD neural network involving toolbox calling
4 WASD网络逼近能力分析
对一个三层的神经网络,许多学者证明了如下的逼近定理[6,11-12]。
定理1 令φ(·)为有界的单调递增连续函数,Hm代表m维单位超立方体[0,1]m。C(Hm)表示定义在Hm上的连续函数构成的集合,则给定任何目标函数γ∈C(Hm)和目标精度ε>0,存在整数n和实常数组{wj}、{βj}和{ωk,j},其中k=1,2,…,m,j=1,2,…,n,使得网络输出
可以以任意精度逼近目标函数γ(x1,x2,…,xm),即
对照和推广上述定理,双极S激励函数为有界的单调递增连续函数,因此可得该激励神经网络能以理论任意精度逼近非线性连续函数。而“边增边删”实际上是在增删神经元的过程中使得神经网络的隐层神经元数不断地逼近神经网络结构最优时的数目。所以,理论而言,当增删神经元的次数趋向于无穷时(实际而言,达到某个较大次数时),我们可以找到使得神经网络结构最优的隐层神经元数(即,定理1中的n值)。而且,作者在之前的工作中已做过大量的数值实验。实验结果显示:随着隐层神经元个数的增加,网络的测试误差呈现一个“V”或“U”字形的图像[29-30]。因此,利用“边增边删”方法可以找到最优隐层神经元数。
5 计算机数值实验验证
为了验证本文提出的WASD神经网络模型的性能,本文以2输入和3输入的数据拟合为例,分别对以下目标函数(5)-(7)进行函数数据拟合实验。
(5)
(6)
(7)
其中,数据产生方法如下:对于目标函数(5)和(6),在区间[0,1]2内(每个维度采样间隔为0.05)均匀产生441个学习样本,在区间[0.05,0.95]2内(每个维度采样间隔为0.017)均匀产生2 809个测试样本;对于目标函数(6),还在区间[0.05,1.04]2内(每个维度采样间隔为0.017)均匀产生3 249个测试和预测样本;对于目标函数(7),在区间[0.1,0.8]3内(每个维度采样间隔为0.01)均匀产生512个学习样本,在区间[0.14,0.76]3内(每个维度采样间隔为0.017)均匀产生50 653个测试样本。另外指出的是,进行该批MATLAB7.6.0数值实验的计算机的硬件配置为Intel(R)Core(TM)2DuoCPU(主频2.2GHz)和2.0GB内存。而使用本文的WASD算法对目标函数(5),(6)和(7)进行函数数据拟合,所得到实验结果(5次实验取平均值)如表1所示。
从表1可以看出:通过WASD算法训练得到的WASD神经网络,学习误差和测试误差均可达到非常小的数量级,网络具有优异的学习能力和泛化能力,对非线性函数数据的逼近效果理想;而且算法执行时间较短。为了和WASD算法进行比较,本文也分别单独使用Levenberg-Marquardt算法和文献[20]中所提出的算法(即,LMFNN算法)进行对比性数值实验。由于单独的LM算法需要提前给定隐层神经元数,但是,对于不同的训练样本,网络的最优隐层神经元数是不同的,因此我们在对比实验中分别选择了25、50、100和200个隐层神经元进行实验。此外,本文使用的是只有一层隐含层的神经网络结构。根据文献[20]的算法,对目标函数(5)和(6),可求得其隐含层神经元数为110;对目标函数(7),其隐含层神经元数为128。为了便于实验对比,在迭代过程中均采用手动停止的操作。Levenberg-Marquardt算法和LMFNN算法的数值实验结果(5次实验取平均值)分别在表2和表3中给出。
从表2可以看出:①当隐层神经元数较少时,通过LM算法训练得到的神经网络(简称LM神经网络) 的学习误差和校验误差相对较大,其学习能力和泛化能力一般表现出轻微的欠拟合现象,此外,网络的学习时间相对较长;②当隐层神经元数进一步增加时,LM神经网络的学习误差和测试误差变得较小,具有较好学习能力和泛化能力,然而,网络的学习时间也稍长;③当隐层神经元数较多时,LM神经网络的学习误差较小,但校验误差较大,两者不一致,反映出LM网络的学习能力较好而泛化能力却差的过拟合现象。结合上述分析,可以大概找到LM神经网络的较优隐层神经元数,即学习能力和泛化能力均较优的LM神经网络结构。另外,从表3可以看出:相比于LM网络,LMFNN算法的学习误差和测试误差均处在较小的数量级,且执行时间也相对较短,能得到较优神经网络结构,能实现对目标函数的有效逼近。
综合表1-3可知,无论在网络性能还是运行时间方面,WASD算法均优于单独使用LM算法或者LMFNN算法。而且,相对于单独使用LM算法而言,WASD算法可以自动确定最优隐层神经元数,单独的LM算法则需要提前设定隐层神经元数(其一般难以达到最优)。所以,如果要确定LM神经网络的最优隐层神经元数,以试错法形式的反复测试校正将会耗费非常长的计算时间。而对比于LMFNN算法(其测试误差较低),WASD算法能得到更优的隐含层神经元数、网络结构和性能。

表1 WASD神经网络的学习与测试结果
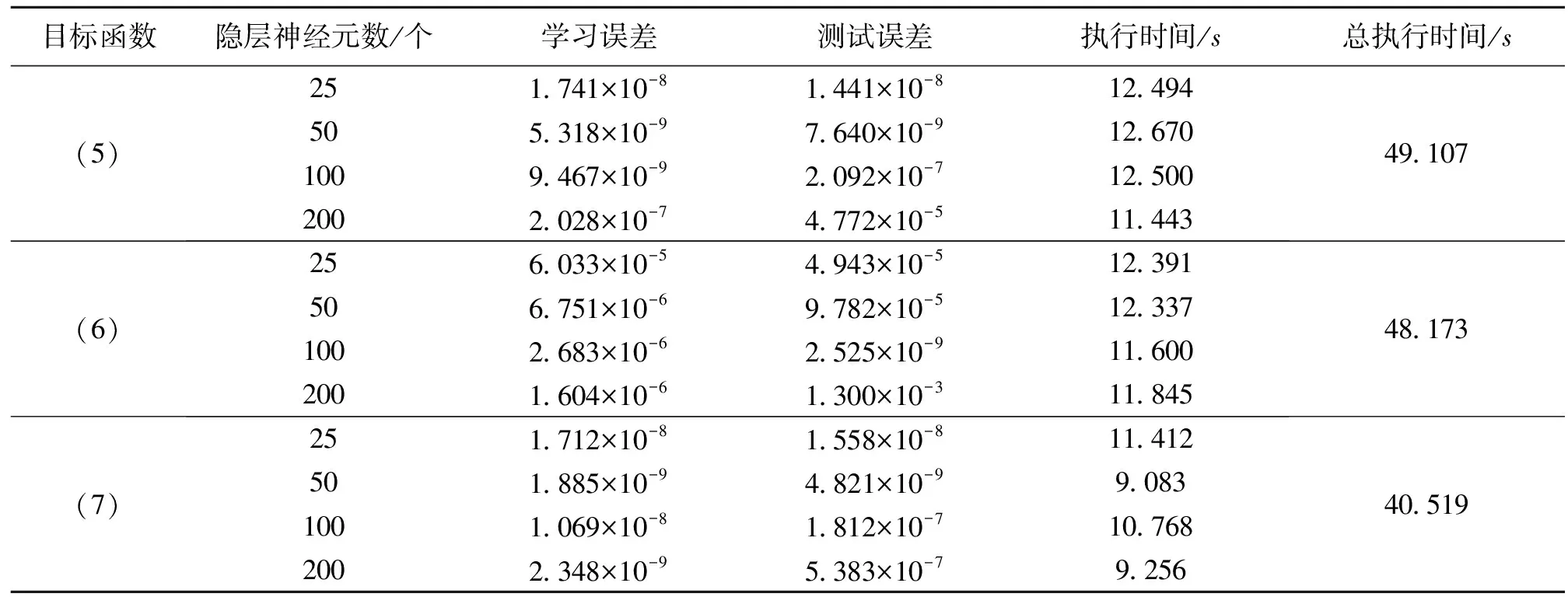
表2 用于对比的LM神经网络学习与测试结果

表3 用于对比的LMFNN神经网络学习与测试结果
为了更进一步地验证和展示基于双极S激励函数神经网络的WASD算法的有效性,下面以目标函数(6)为例(设定执行时间为100s),进行数值实验,实验结果如图5至图9所示。
具体而言,图5显示了WASD算法在两个学习过程当中,网络学习误差的变化情况。在过程1 (Process1)中,随着神经元数的增加,网络的学习误差逐渐降低,由于采用了边增边删的策略,期间并无发生振荡现象,最终确定的隐层神经元数为207;进入过程2 (Process2)后,网络的学习误差一直下降,直至程序(达到结束条件)结束,最终训练停止时,网络的学习误差到达8.455×10-7。图6是神经网络对目标函数(6)的学习结果和校验结果。此外,图7和图8展示了WASD神经网络对目标函数(6)在[0.05,1.02]2内的测试和预测结果。可以看出,此时神经网络的测试和预测误差均较小,尤其是在[0.05,1.01]2内的测试和预测误差小于0.015。更进一步地,图9显示了WASD神经网络对目标函数(6)在[0.05,1.04]2内的测试和预测结果。虽然网络输出与目标输出函数之间存在差别,但结果还是令人满意的。从上述结果可知,通过该算法得到的WASD神经网络具有较好的泛化能力。

图5 WASD神经网络的学习误差E和神经元数n的关系Fig.5 Relationship between WASD neural network learning error E and neuron number n

图6 WASD神经网络对目标函数(6)在区间[0,1]2内的学习结果Fig.6 Learning results of WASD neural network for target function (6) in [0,1]2

图7 WASD神经网络对目标函数(6)在区间[0.05,1.01]2内的测试和预测结果Fig.7 Testing and forecasting results of WASD neural network for target function (6) in [0.05,1.01]2

图8 WASD神经网络对目标函数(6)在区间[0.05,1.02]2内的测试和预测结果Fig.8 Testing and forecasting results of WASD neural network for target function (6) in [0.05,1.02]2

图9 WASD神经网络对目标函数(6)在区间[0.05,1.04]2内的测试和预测结果Fig.9 Testing and forecasting results of WASD neural network for target function (6) in [0.05,1.04]2
综上所述,WASD算法可以根据已有的样本数据,通过网络的学习训练,无需人工干预,自动地确定出最优隐层神经元数,同时实现对权值和阈值的后续有效调整,而且执行时间较短,最终得到的WASD网络具有很好的学习能力和泛化能力,能够对非线性函数数据进行有效的拟合。相比较而言,单独LM神经网络的隐层神经元数需要人为提前设定,如果想要获得较好的效果和性能,需要反复地进行尝试或者根据设计者的经验进行隐层神经元数的人为优化,过程相当耗时。而LMFNN算法,虽然可以自动确定隐层神经元数和网络结构,但由于其算法受到样本大小影响,当学习样本的数量和分布不够合理时,所得到的隐层神经元数和网络结构未必保证是最优。
此外,为了验证WASD算法中LM方法的有效性和优越性,针对目标函数(5) 、(6)和(7),使用不同的训练方法(即,在后续迭代中采用LM算法)来优化输入层和隐层神经元的连接权值以及隐层神经元的阈值。表4为对应的数值结果(取5次实验平均值)。

表4 不同训练方法的性能对比
从表4中可以看出:LM方法的训练误差和测试误差总体而言优于其它的训练方法(如BFGS和最速下降法)。此结果说明了LM方法在WASD算法中的有效性及优越性。此外,针对目标函数(5),本文使用WASD算法进行50次实验,其目标精度设置为5.0×10-12,执行时间为20s,表5为50次实验的统计结果。

表5 WASD算法50次实验的统计结果
从表5中可以看出:WASD算法的学习误差与测试误差的均值和标准差都处于10-9这一微小量级。此结果(特别是其标准差处于较小的量级)说明了WASD算法具有较好的稳定性和收敛性。
值得指出的是,我们还在神经网络算法性能实验中采用了交叉验证的评价方法。具体而言,针对目标函数(5)进行了10折(10-fold)交叉验证。在10次验证中,学习误差最小为2.000×10-12,此时的测试误差为5.512×10-10;测试误差最小为3.797×10-10,此时学习误差为9.793×10-12。总体而言,10折交叉验证学习误差的均值为2.349×10-10,测试误差的均值为2.304×10-7。可以看出,本文提出的算法在多重交叉验证实验中,学习误差和测试误差也均处于较小的量级。该结果进一步证实了所提出算法的有效性和优越性。
6 结 语
本文首先构造了一种三层的双极S激励函数前向神经网络模型,进而提出了一种带后续迭代的权值与结构确定算法。为了实现在较短时间内确定最优隐层神经元数的同时,使神经网络获得更好的学习性能和泛化性能,该算法创造性地结合了权值直接确定法与Levenberg-Marquardt算法各自的优点,并采用了边增边删的结构增长策略。计算机数值实验和对比结果表明:基于WASD算法的双极S激励函数神经网络具有更为优异的学习能力和泛化能力,学习时间少(或适中),在非线性函数数据拟合方面可表现出很好的效果。本文提出的带后续迭代的神经网络权值与结构确定算法因此可具有广泛的应用前景(其限于篇幅不再赘述)。而如何在更进一步的实际应用中发现本算法的不足和做出相应的改进措施或也是下一步工作的重点和未来研究方向。
[1] 张青贵. 人工神经网络导论[M]. 北京: 中国水利水电出版社, 2004.
[2] 张雨浓,王茹, 劳稳超,等. 符号函数激励的WASD神经网络与XOR应用[J]. 中山大学学报(自然科学版), 2014, 53(1): 1-7.
[3]SHRIVASTAVAS,SINGHMP.Performanceevaluationoffeed-forwardneuralnetworkwithsoftcomputingtechniquesforhandwrittenEnglishalphabets[J].AppliedSoftComputing, 2011, 11(1): 1156-1182.
[4] 杨文光. 权值直接确定的三角型模糊前向神经网络[J]. 中山大学学报(自然科学版), 2013, 52(2): 33-37.
[5] 蔡娟,蔡坚勇, 廖晓东,等. 基于卷积神经网络的手势识别初探[J]. 计算机系统应用, 2015, 24(4): 113-117.
[6]HORNIKK,STINCHCOMBEM,WHITEH.Multilayerfeedforwardnetworksareuniversalapproximators[J].NeuralNetworks, 1989, 2(5): 359-366.
[7]CHENT,CHENH.Universalapproximationtononlinearoperatorsbyneuralnetworkswitharbitraryactivationfunctionsanditsapplicationtodynamicalsystems[J].IEEETransactionsonNeuralNetworks, 1995, 6(4): 911-917.
[8]GUERRAFA,COELHOLS.Multi-stepaheadnonlinearidentificationofLorenz’schaoticsystemusingradialbasisneuralnetworkwithlearningbyclusteringandparticleswarmoptimization[J].ChaosSolitonsandFractals, 2008, 35(5): 967-979.
[9] 王建军,徐宗本. 多元多项式函数的三层前向神经网络逼近方法[J]. 计算机学报, 2009, 32(12): 2482-2488.
[10] 李凯,翟振华. 神经网络在函数逼近问题中的应用研究[J]. 计算机工程, 2001, 27(5): 189-190.
[11]COTTERNE.TheStone-Weierstrasstheoremanditsapplicationtoneuralnetworks[J].IEEETransactiononNeuralNetworks, 1990, 1(4): 290-295.
[12]CYBENKOG.Approximationbysuperpositionofasigmoidalfunction[J].MathematicsofControl,Signals,Systems, 1989, 2(4): 303-314.
[13] 魏海坤,徐嗣鑫,宋文忠. 神经网络的泛化理论和泛化方法[J]. 自动化学报, 2001, 27(6): 806-815.
[14]JAINAK,MAOJC,MOHIUDDINKM.Artificialneuralnetworks:atutorial[J].Computer, 1996, 29(3): 31-34.
[15]LAWRENCES,GILESCL,TSOIAC.Whatsizeneuralnetworkgivesoptimalgeneralization?Convergencepropertiesofbackpropagation,UMIACS-TR-96-22andCS-TR-3617 [R].CollegePark:UniversityofMarylandCollegePark, 1996.
[16] 苏高利,邓芳萍. 论基于MATLAB语言的BP神经网络的改进算法[J]. 科技通报, 2003, 19(2): 130-135.
[17] 张雨浓,杨逸文,李巍. 神经网络权值直接确定法[M]. 广州: 中山大学出版社, 2012.
[18] 张雨浓,罗飞恒,陈锦浩,等. 三输入伯努利神经网络权值与结构双确定[J]. 计算机工程与科学, 2013, 35(05): 142-148.
[19]ZHANGY,DINGS,LIUX,etal.WASPneuronetactivatedbybipolar-sigmoidfunctionsandappliedtoglomerular-filtration-rateestimation[C].The26thChineseControlandDecisionConference(CCDC),IEEE, 2014: 172-177.
[20] 李鸿儒,王晓楠,何大阔,等. 一种优化计算确定神经网络结构的方法[J]. 系统仿真学报, 2009, 21(1): 104-107.
[21]BAHIJM,CONTASSOT-VIVIERS,SAUGETM.Anincrementallearningalgorithmforfunctionapproximation[J].AdvanceinEngineeringSoftware, 2009, 40(8): 725-730.
[22]BENARDOSPG,VOSNIAKOSGC.Optimizingfeedforwardartificialneuralnetworkarchitecture[J].EngineeringApplicationsofArtificialIntelligence, 2007, 20(4): 365-382.
[23]TSAIJT,CHOUJH,LIUTK.TuningthestructureandparametersofaneuralnetworkbyusinghybridTaguchi-geneticalgorithm[J].IEEETransactionsonNeuralNetworks, 2006, 17(1): 69-80.
[24]ARULAMPALAMG,RAMAKONARV,BOUZERDOA,etal.Classificationofdigitalmodulationschemesusingneuralnetworks[C].The5thInternationalSymposiumonSignalProcessingandItsApplications(ISSPA),IEEE, 1999, 2: 649-652.
[25]HAYKINS.Neuralnetworks:acomprehensivefoundation[M]. 2nded.EnglewoodCliffs,NJ:PrenticeHall, 2004.
[26]HAGANM,DEMUTHH,BEALEM.Neuralnetworkdesign[M].Beijing:ChinaMachinePress, 2002.
[27] 傅荟璇,赵红.MATLAB神经网络应用设计[M]. 北京: 机械工业出版社, 2010.
[28]DEMUTHH,BEALEM,HAGANM.Neuralnetworktoolbox6user’sguide[M].TheMathWorksPress, 2009.
[29]ZHANGY,YUX,GUOD,etal.Weightsandstructuredeterminationofmultiple-inputfeed-forwardneuralnetworkactivatedbyChebyshevpolynomialsofclass2viacross-validation[J].NeuralComputingandApplications, 2014, 25(7/8): 1761-1770.
[30]ZHANGY,YINY,GUOD,etal.Cross-validationbasedweightsandstructuredeterminationofChebyshevpolynomialneuralnetworksforpatternclassification[J].PatternRecognition, 2014, 47: 3414-3428.
WASD neural network activated by bipolar sigmoid functions together with subsequent iterations
ZHANGYunong1,2,3,XIAOZhengli1,2,3,DINGSitong1,2,3,MAOMingzhi1,LIUJinrong1
(1. School of Data and Computer Science, Sun Yat-sen University, Guangzhou 510006, China;2. Key Laboratory of Autonomous Systems and Networked Control, Ministry of Education,South China University of Technology, Guangzhou 510640, China;3. SYSU-CMU Shunde International Joint Research Institute, Foshan 528300, China)
A weights-and-structure-determination (WASD) algorithm is proposed for the neural network using bipolar sigmoid activation functions together with subsequent iterations, which is the combination of the Levenberg-Marquardt algorithm and the weights-direct-determination method for neural network training. The proposed algorithm, combined with the Neural Network Toolbox of MATLAB software, aims at remedying the common weaknesses of traditional artificial neural networks, such as long-time learning expenditure, difficulty in determining the network structure, and to-be-improved performance of learning and generalization. Meanwhile, the WASD algorithm has good flexibility and operability. Taking data fitting of nonlinear functions for example, numerical experiments and comparison results illustrate the superiority of the WASD algorithm for determining the optimal number and optimal weights of hidden neurons. And the resultant neural network has more excellent performance on learning and generalization.
neural networks; weights-and-structure-determination (WASD) algorithm; subsequent iterations; bipolar sigmoid activation functions; numerical experiments
10.13471/j.cnki.acta.snus.2016.04.001
2015-07-07
国家自然科学基金资助项目(61473323);广州市科技计划资助项目(2014J4100057);自主系统与网络控制教育部重点实验室开放基金资助项目(2013A07);大学生创新创业训练计划资助项目(201410558065,201410558069)
张雨浓(1973年生),男;研究方向:人工神经网络、冗余机器人;E-mail:zhynong@mail.sysu.edu.cn
TP183
A
0529-6579(2016)04-0001-10
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
自然杂志(2021年6期)2021-12-23 08:24:46
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
人民珠江(2019年4期)2019-04-20 02:32:00
现代装饰(2018年5期)2018-05-26 09:09:01
自动化学报(2017年7期)2017-04-18 13:41:02
电源技术(2015年5期)2015-08-22 11:18:38
弹箭与制导学报(2015年1期)2015-03-11 15:32:06
计算机工程(2014年9期)2014-06-06 10:46:47
机械工程与自动化(2014年3期)2014-05-07 12:49:22
