
哈萨克语句子相似度的计算方法研究与实现∗
2016-05-16 05:39沙力木别克毕山汗古丽拉阿东别克
新疆大学学报(自然科学版)(中英文) 2016年2期
沙力木别克毕山汗,古丽拉阿东别克
(新疆大学信息科学与工程学院,新疆乌鲁木齐830046)
0 引言
句子相似度计算在自然语言处理方面的各个领域都有着广泛的应用,例如在自动问答系统中问题库的检索.根据用户的提问在知识库中查找对应的答案是通过计算提问的句子和知识库中对应的句子之间相似度来解决的.在信息过滤技术中,通过句子相似度计算可自动过滤掉用户可能并不想看到的信息.同样,在机器翻译、自动文摘中均用到该技术获取必要的信息.
句子相似度计算也是基于实例的机器翻译方法(Example Based Machine Translation)中的一个关键技术,其作用是在实例库中查找跟输入句子相似的句子,然后用相似句子的对齐目标句子作为翻译模板进行片段对齐、重组等操作最终完成翻译.因此,句子相似度计算结果的准确性会影响到翻译质量.
1 国内外现状分析
国外对于文本相似度计算的研究起步较早,Gerard Salton于1969年提出的基于向量空间模型(Vector Space Model,VSM)的文本相似度计算模型是目前最成熟和应用最广泛的文本相似度计算模型.它最初被引用到文章中相似度的计算中,后来被引入到句子相似度的计算中.其基本思想是将文本分为若干个特征项,计算出每个特征项的权重,特征项权重用分量的向量来表示,对向量计算来表示文档相似度.在此基础上,很多改进的算法应运而生.
国内在汉语句子的相似度计算方面取得了较好的成果,例如张民等设计了一种基于词的计算相似度方法.而句子相似度计算中的输入句子和实例句子长度相差较大,其中单词个数也不一致,因此,输入句子与实例句子中每个单词都可能存在相关性,这种相关性位置可加权处理.
2 哈萨克语句子相似度计算模型
哈萨克语句子相似度计算模型由快速检索模块和相似度计算模块构成.在快速检索模块中实现实例快速匹配,在找到相似实例句子集合后,作为相似度计算模块的输入.计算相似度模块中用到了两种模型的结合,即基于词的句子相似度计算和基于向量的相似度计算.
2.1 快速检索模块
基于实例的机器翻译中,关键问题是如何从海量实例库中筛选出一定数量的句子作为候选集合,这些集合中包含了与输入句子最相似的句子,为此设计了快速检索模块.
为进一步提高检索速度,对数据库中的句子建立散列单词倒排索引.首先对实例库中实例的各单词建立散列表,然后将每个单词所出现的多个实例编号id建立一个单链表,其结构如图1,其中id是单词出现过的实例编号.
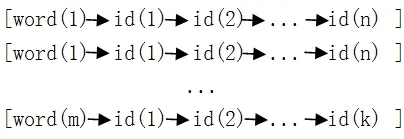
图1 倒排索引图
快速检索的具体过程如下:
Step 1:对输入的句子进行解析,获得单词链表(图1),其中Word是单词,ID是该单词出现过的实例id集合,id是实例编号;
Step 2:统计(A过程),计算出单词链表中频繁出现过的实例的id集合;
Step 3:返回实例id集合,作为相似度计算候选实例集合.
其中A过程如下:
例如输入:
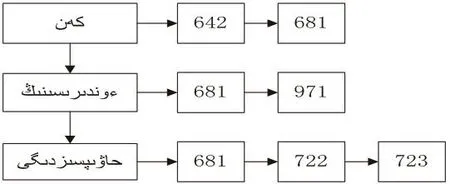
图2 A过程
从图2中可以看到,所有单词在编号为681实例中都出现过,出现频率最高,跟输入句子的关联性比其他实例强.在A过程中对每一个单词的ID进行统计,计算每个id出现的次数,并将统计结果按降序排列.例如图2中的每个id统计结果为[(681,3),(642,1),(971,1),(722,1),(723,1),(724,1)].最终留下频率高的id集合,剩下的都过滤.
2.2 相似度计算模块
2.2.1 基于词的相似度计算
1)词形相似度
词形相似度(词重叠法,英文名称Word Overlap Measures)反映两个句子形态上的相似程度,以两个句子中所含相同词的个数来衡量,由以下公式来表示:
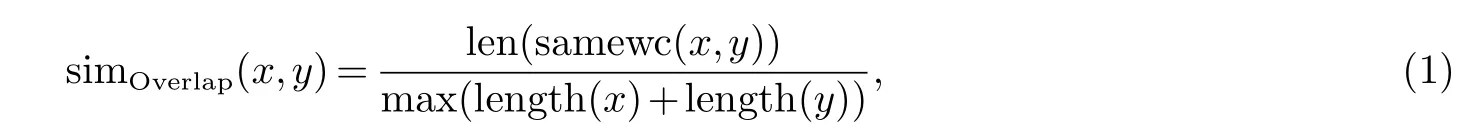
其中len(samewc(x,y))表示输入句子X和实例句子Y中的相似词一一对应的个数,simoverlap表示词形相似度,length(x)表示句子X中的词总个数,length(y)表示句子Y中词的总个数(包括句子中的标点符号).
词形相似度计算过程如下:
输入句子:
实例句子:

通过计算公式可以计算出两个句子的相似度
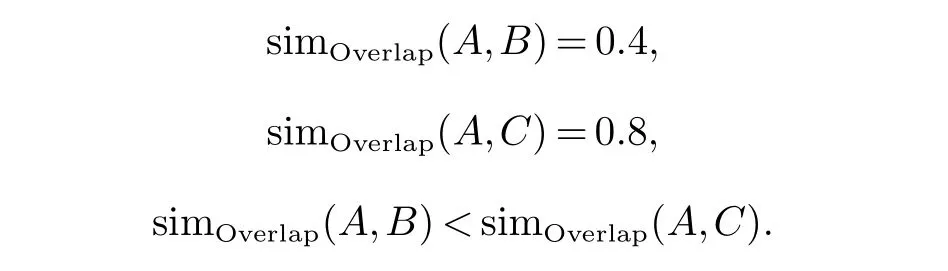
这说明C句子比B句子在形态上更接近A句子.
2)基于逆序数词序相似度算法
两个句子中出现的单元可能完全相同,但我们不能确定这两个句子完全相同.两个句子中各个单元出现的位置不同可能导致两个句子表示完全不同的意思,所以必须进行词序上的相似度计算.
对于包含n(n∈N)个不同元素的序列,先规定各元素之间有一个标准次序(例如n个不同的自然数,规定由小到大为标准次序).在这n个元素的任一排列中,当某两个元素的先后次序与标准次序不同时就称为一个逆序.一个排列中所有逆序的总数叫做这个排列的逆序数.
词序反映两个句子中所含相同单元在位置关系上的相似程度,以两个句子中所含相同单元的相邻顺序逆向的个数来衡量.设x,y表示两个句子,ordoccur(x,y)表示在句中都出现且只出现一次的单元集合,pfir(x,y)表示ordoccur(x,y)中的单元在X中的位置序号构成的向量,psec(x,y)表示pfir(x,y)中的分量按对应单元在y中次序排列生成的向量.
例1的词序相似度计算方法为:ordoccur(A,C)={},它所构成的pfir(x,y)={0,2,3,4},psec(x,y)={0,2,3,4},rew(x,y)表示psec(x,y)相邻分量的逆序数.上例中:0<2,2<3,3<4得到rew(x,y)=0,句子x,y的词序相似度计算公式如下

根据公式2,我们可以计算出A,C两个句子的词序相似度为
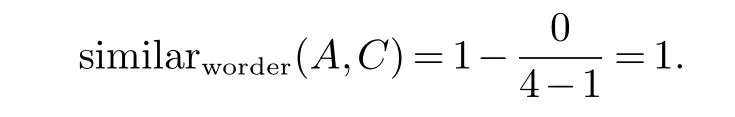
3)句长相似度
从句子长度上来标注句子的相似性一定程度上反映句子形态上的相似性.实例句和输入句长度差会影响到句子相似度.句长相似度公式如以下:
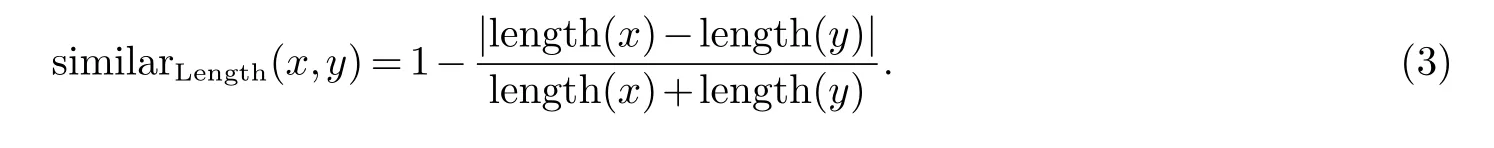
输入句子x和实例句子y的词相似度计算公式similarWStn(x,y)为
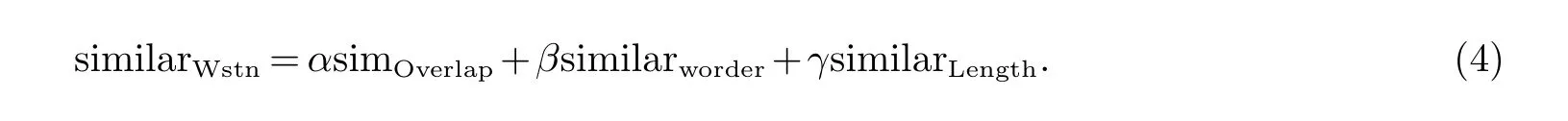
其中的α,β,γ是实验值.
2.2.2 基于向量空间模型的TF_IDF相似度计算方法
TF_IDF是基于向量空间模型中最广泛使用的方法之一.若输入句子与实例句子中包含的所有词为w1,w2,···,wn,那么输入句子和实例句子可以用n维向量t=
同样,我们可以计算出实例句子的n维向量q=
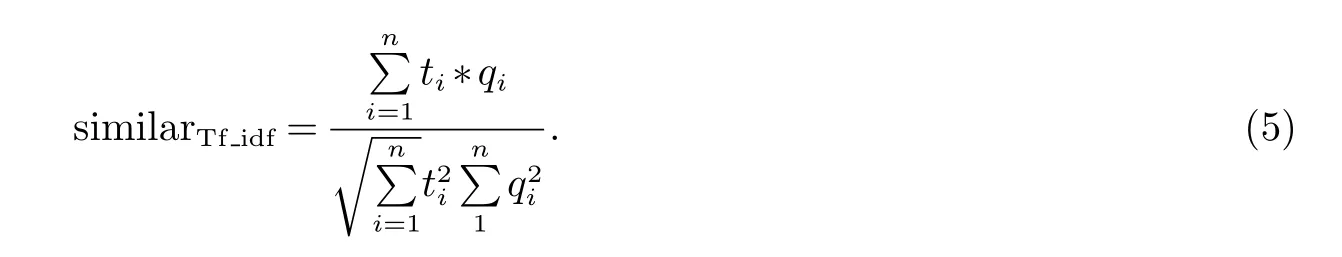
2.2.3 总相似度计算
计算基于词特征和向量特征相似度以后总相似度similarZong计算公式,
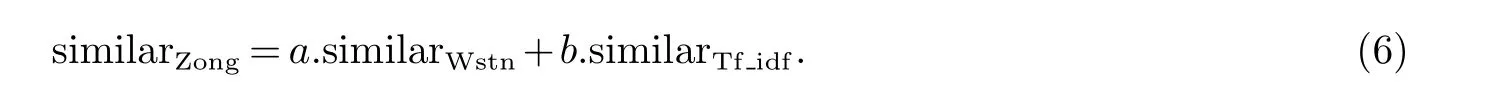
在计算句子相似度时,输入句子和实例句子中出现同义词,例如:

两个句子所表达的意思相同.但实例句子中出现了同义词,不进行同义词替换直接进行相似度计算会影响到计算准确率.为了避免这种情况的出现,本文中提出了同义词替换,算法流程如图3所示.
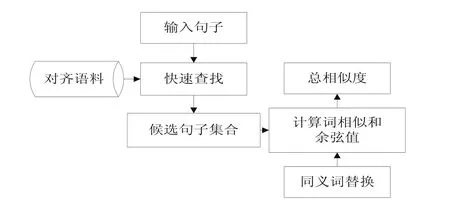
图3 算法流程
3 哈萨克语句子相似度计算模型实现
本程序包括两大模块:倒排索引模块和计算相似度模块.倒排索引模块先把新的实例句子分成词,然后把它添加到倒排索引库.
句子相似度计算界面中,计算输入句子和实例句子相似度按相似度降序返回结果如图5.

图4 倒排索引界面
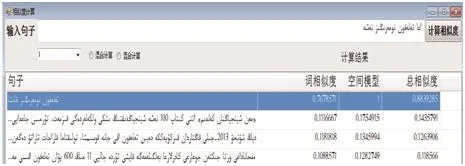
图5 句子相似度计算界面
4 实验结果与分析
哈萨克语句子相似度计算尚处于初期阶段,用以评价哈萨克语句子相似度的标准很少.目前对齐实例库中有1 000个句子和3 500多个已经倒排索引好的词,相似度计算实验结果如表1,表2,表3.

表1 基于向量空间模型不进行同义词替换相似度计算

表2 基于向量空间模型和基于词相结合的相似度计算(替换同义词之前)

表3 基于向量空间模型和基于词相结合的相似度计算(替换同义词之后)
从三次实验结果来看,基于向量空间模型和基于词相结合的计算相似度计算方法比基于向量空间模型和相结合的不进行同义词替换方法,在哈萨克语句子相似度中的正确率有所提高.
5 总结
散列的倒排索引能够有效地实现快速查找.为了从双语对齐实例库中快速地查找候选句子集合作为下一步工作的输入,计算输入句子与实例句子的词相似度和向量余弦值,然后结合两种方法整合句子的相似度.为了避免同义词产生的歧义,计算过程中使用了同义词替换,同义词替换可以提高相似度计算的正确率.由于现在对齐实例库规模不大,句子相似度计算结果还差强人意,下一步工作将继续扩大对齐实例库,继续提高搜索速度,更多的引入哈萨克语语法、语义知识,提高正确率,从而提高翻译质量.
参考文献:
[1]阿力木塞买提·阿布力哈孜.基础哈萨克语[M].乌鲁木齐:新疆大学出版社,2009,3.
[2]田生伟,吐尔根·依布拉音,禹龙.一种维吾尔语句相似度算法的研究[J].计算机工程与应用,2009,45(26):144-146.
[3]南铉国,崔荣一.基于多层次融合的语句相似度计算模型[J].延边大学学报(自然科学版),2007,33(3):191-194.
[4]卡哈尔江·阿比的热西提,吐尔根·依布拉音.一种改进的维吾尔语句子相似度计算方法[J].中文信息学报,2011,25(4):50-53
[5]达吾勒·阿布都哈依尔,海拉提·克孜尔别克,等.基于规则的哈萨克语词干提取算法的研究[J].新疆大学学报(自然科学版),2011,28(2):238-241.
[6]南铉国,崔荣一.基于多层次融合的语句相似度计算模型[J].延边大学学报(自然科学版),2007,33(3):191-194
[7]周法国,杨炳儒.句子相似度计算新方法及在问答系统中的应用[J].计算机工程与应用,2008.44(1):165-167
[8]江阿古丽·哈依达尔,卡哈尔江·阿比的热西提,阿里木江·亚森,等.一种哈萨克语句子相似度计算方法的研究[J].新疆大学学报,2012,29(4):473-477.
[9]王长胜,刘群.基于实例的汉英机器翻译系统研究与实现[J].计算机工程与应用,2002,38(8):126-127.
[10]吉胜军.基于Levenshtein Distance算法的句子相似度计算[J].电脑知识与技术,2009,5(9):143-144
猜你喜欢
小学生学习指导(低年级)(2021年9期)2021-10-14
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
小学生学习指导(低年级)(2018年9期)2018-09-26
语言与翻译(2015年3期)2015-07-18
语言与翻译(2015年1期)2015-07-18
语言与翻译(2015年1期)2015-07-18
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29

- 新疆大学学报(自然科学版)(中英文)的其它文章
- The Absolute Ruin Risk Model with Constant Interest Investment and Linear Threshold Dividend Strategy∗
- 煤基活性炭的氧化改性及其对Cd2+的吸附性能∗
- 细菌诱导光滑鳖甲幼虫抑制差减cDNA文库的构建与分析∗
- 资源型产业与制造业集聚特征与影响因素异同分析∗
- Distance Signless Laplacian Integral Complete R-partite Graphs∗
- Finite-time Stability of Continuous-time Systems with Time-varying Delays∗