
基于词嵌入扩充的口语对话文本领域分类∗
2016-05-16 05:39杨萌萌黄浩
新疆大学学报(自然科学版)(中英文) 2016年2期
杨萌萌,黄浩
(新疆大学信息科学与工程学院,新疆乌鲁木齐830046)
0 引言
口语对话是指人与计算机之间以某种形式通过语音进行信息交换的过程.典型的口语对话系统主要包括以下五个组成部分:自动语音识别、口语理解、对话管理、语言生成和语音合成.口语理解是实现口语对话系统的关键技术之一,它的任务是对用户的口语化输入和意图进行解析和理解并从用户输入语句中抽取关键信息.口语理解方法[1]主要包含三种:基于规则的方法、基于统计的方法以及两者的结合.口语对话系统可分为两种:限制域口语对话系统和开放域口语对话系统.由于限制域口语对话系统应用的局限性,对开放域口语对话系统的研究越来越受关注.开放域口语对话系统是针对某几个领域口语对话进行综合的系统,要提高开放域口语对话系统的有效性,首先需要对语音识别后的口语对话文本进行正确的领域分类.SVM具有较好的分类性能,但需要对训练数据进行大量人工标注.针对以上问题,本文提出了无监督的概率生成模型LDA主题分类方法,同时针对数据稀疏的问题,采用word2vec对类似于短文本的口语对话文本进行语义扩充,将短文本转化为长文本,使LDA模型更加有效地估计出口语对话文本的隐含主题.
1 相关工作
目前,常见的口语对话系统领域分类方法是SVM,Wu Weilin等人提出了基于SVM的弱监督学习方法[2],采用弱监督的SVM对口语对话文本进行主题分类.
随着LDA主题模型的发展,LDA已在文本主题分类[3,4]、微博话题发现[5,6]、自动问答系统[7,8]、物联网服务发现[9]等领域有了广泛的应用研究.LDA模型在口语对话系统领域的研究是在近几年出现的.Celikyilmaz[10]等人提出了采用LDA模型进行口语理解领域检测,即使用LDA模型对口语对话文本进行主题分类.Morchid[11]等人提出了基于LDA模型和高斯分类器的口语对话分类,采用无监督的LDA模型和基于决策规则的高斯分类器,在手机对话系统中进行手机对话服务文本的主题建模和主题分类.
2 LDA建模方法
LDA最早由Blei[12]提出,首次将隐含变量用服从狄利克雷分布的模型来描述.LDA模型[13]是一种概率生成模型,即将文档中的词按概率分配一定的主题,同时按概率生成文档中的主题.
2.1 LDA模型
LDA模型的基本思想[14,15]是将文档用不同主题的概率分布表示,将主题用文档中词项的概率分布表示.这样就将文档从高维词项空间映射到了低维主题空间,实现了降维目的.
LDA模型是一个三层贝叶斯结构.LDA模型的图模型表示如图1所示.带阴影的圆圈表示可观测变量,不带阴影圆圈表示隐含变量,箭头表示变量之间的依存关系,方框表示重复,其中右下角的字母表示重复次数.各字母表示的含义为:wd,n表示第d篇文档中的第n个词项,zd,n表示第d篇文档第n个词项的主题,N表示第d篇文档中的词项总数,θd表示第d篇文档中主题的概率分布,D表示语料库中文档总数,α表示主题分布服从的狄利克雷参数,βk表示第k个主题下词项的概率分布,K表示主题总数,η表示某一主题下词项分布服从的狄利克雷参数.
LDA模型的生成过程如下:
1)文档中词项总数N服从参数为ξ的泊松分布;
2)对每篇文档d∈{1,2,...,D},按概率生成文档d的主题分布:θd∼Dir(α);
3)对每个主题z∈{1,2,...,K},按概率生成主题z的词项分布:βk∼Dir(η);
4)对文档d中的每个词n∈{1,2,...,N}的生成过程有:
a)按主题分布θd生成文档d中第n个词项的主题:zd,n∼Multi(θd)(多项分布);
b)按词项分布βk生成所选主题的词项:wd,n∼Multi(βk)(多项分布).
在以上生成过程中,θ,k,d的联合概率为:
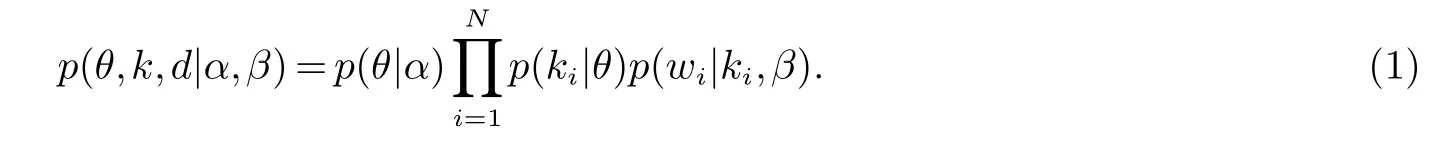
对θ和k进行积分得出d的边缘概率分布:
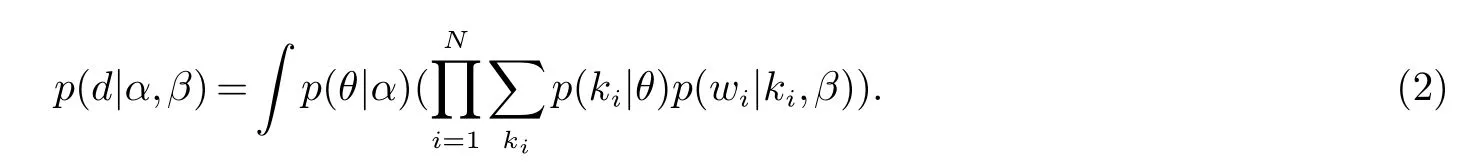
LDA模型的参数为{α,β},LDA模型的参数估计方法有变分推理、吉布斯采样和期望传播.通过以上算法,最终可得出“文档-主题”和“主题-词项”概率分布.
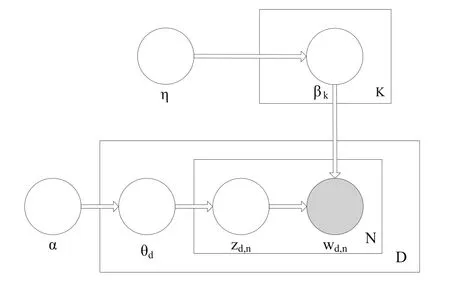
图1 LDA图模型表示
2.2 口语对话文本的LDA建模
我们将口语对话文本集看作是文档集D,将每一次口语对话文本看作是一篇文档d,将口语对话文本中的词语看作词项w,将口语对话文本中的隐含主题看作主题z,其余参数均与以上LDA模型中的参数一致,便完成了口语对话文本的LDA建模.
3 基于word2vec文本扩充的口语对话系统领域分类
口语对话文本类似于短文本,将口语对话文本进行主题分类类似于短文本主题分类,短文本主题分类中常存在数据稀疏的问题.短文本分类方法之一就是文本扩充,将短文本转化为长文本.word2vec[16]文本扩充的基本思想是通过对word2vec进行训练,找到口语对话文本中词语的近义词或同义词,并将这些词和原口语对话文本中的词一并作为口语对话文本的内容,从而将类似于短文本的口语对话文本转化为长文本,然后对其进行LDA建模和主题分类.
3.1 word2vec介绍
word2vec[17]是2013年谷歌发布的基于深度学习的开源工具,利用神经网络语言模型在大量数据集上学习高维向量空间中词的向量分布,并对词与词之间的向量分布进行余弦相似度计算,以此来表示词与词之间的句法或语义依存关系.
word2vec中提出了两种神经网络语言模型:CBOW(Continuous Bag-of-words)模型和Continuous Skipgram模型.CBOW模型是在前馈神经网络语言模型(Feedforward NNLM)基础上的改进.前馈NNLM由四个部分组成:输入层、映射层、隐含层和输出层,通过映射数组实现从输入层到映射层的映射.CBOW模型在前馈NNLM的基础上去掉了权值多、运算量大的非线性隐含层,同时将映射数组改成所有词共享权值的形式,将过去词和未来词作为输入进行训练和学习来预测当前词,最终得出词向量分布,如图2所示.连续Skip-gram模型跟CBOW相反,将当前词作为输入,来训练和学习过去词和未来词.
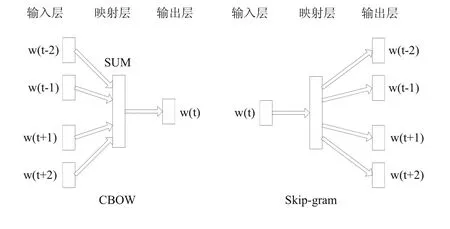
图2 神经网络语言模型表示
3.2 基于word2vec文本扩充的口语对话文本LDA建模
通过word2vec进行文本扩充主要包含以下三个步骤:
1)生成词向量
通过神经网络语言模型对训练数据进行学习,得出每个词的distributed representation即词向量.
2)寻找同义词或近义词
将得出的词向量构建成词向量矩阵,将词与词之间的相似度计算转换为词向量之间的余弦相似度或欧式距离的计算.两个词的词向量越接近,这两个词的相似度就越高.
3)将口语对话文本进行word2vec扩充
首先,通过word2vec找到训练数据中与口语对话文本d中词语wdi最相近或最相似的前L个词:

然后,通过Wdi对口语对话文本d进行扩充,扩充后的口语对话文本表示为:
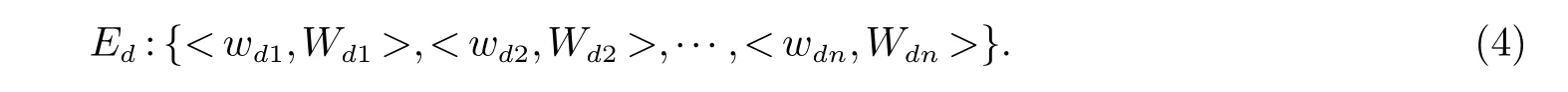
我们将Ed看作是一篇文档,E看作文档集Ed的集合,其LDA建模过程与上节2.2建模过程相同,进而对扩充后的口语对话文本进行主题分类.口语对话系统领域分类的整体框图如图3所示.
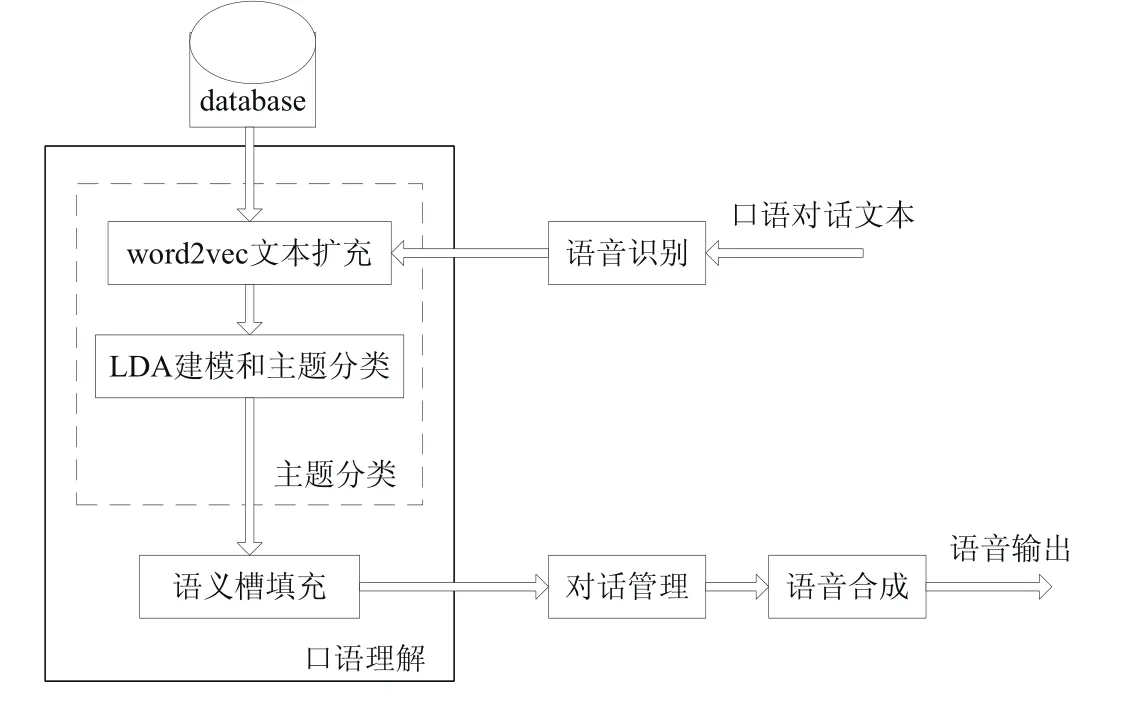
图3 口语对话系统领域分类整体框图
4 实验过程及结果分析
4.1 实验环境和数据准备
实验环境为操作系统为Windows 7的一台Intel(R)Core(TM)电脑;开发工具为Anaconda提供的spyder,开发语言为Python,调用的工具包为gensim.Anaconda是一个科学计算环境,conda是其自带的包管理器,包含了使用gensim之前需要安装的Numpy和Scipy.在Anaconda命令窗口使用pip命令对gensim、jieba等进行安装,就可以在spyder上进行编程和程序调用了.jieba是中文分词工具,用于对问题描述进行中文分词;gensim是一个用python编写的库,包含了TF-IDF、LDA、word2vec等模型工具包的python实现.
本文的数据来源为:一部分从“百度百科”下的金融、法律和音乐分类中搜集来文本,根据搜集的文本人工提问问题,以此来建立问题集,而将搜集来的文本作为word2vec的训练数据;另一部分来自于对以天气为主题的人工提问.我们将以上问题集作为口语对话系统语音识别后的口语对话文本,该问题集总共分为四类,包括金融、法律、音乐、天气.问句集总共有7 069个问句,其中6 050句作为训练样本,1 019句作为测试样本.具体四类主题的问句在训练样本和测试样本上的数量分配见表1.
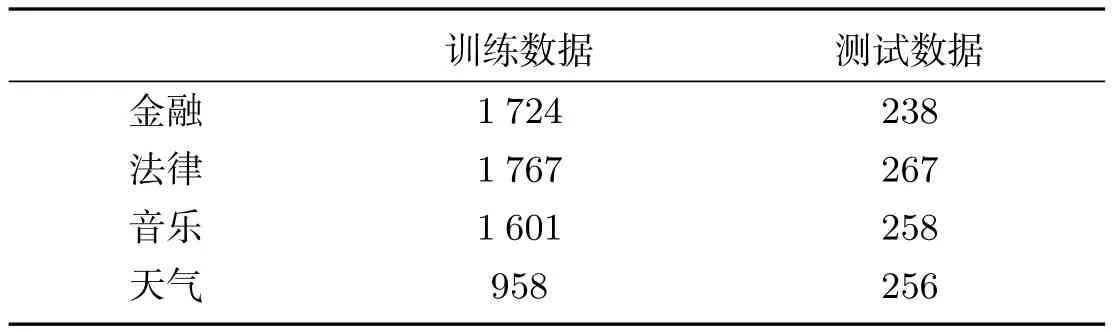
表1 四类主题的问句在训练样本和测试样本上的数量分配
实验前对数据进行预处理.我们将收集到的数据保存成纯文本格式,引入jieba分词工具进行中文分词,建立停用词表,去除疑问词、语气词等无实际意义的词,然后进行相关实验.
4.2 评价标准
我们用准确率、召回率和F1值对实验结果进行评价.Am表示测试集中第m类分类正确的问题数,Bm表示测试集中实际分类为m的问题数,Cm表示测试集中标准分类为m的问题数.Pm表示第m类准确率,Rm表示第m类召回率.
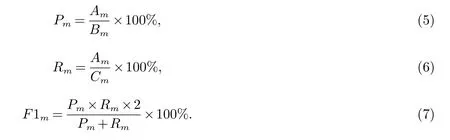
4.3 实验结果及分析
我们以“百度百科”中的相关数据作为word2vec的训练样本,对问题集进行语义扩充,然后对扩充后的问题集进行LDA建模.LDA模型是一种参数化的贝叶斯模型,在训练时需要预先指定主题数目K.我们选取主题数K=4,α=1/k并随机初始化参数β,对扩充后的问题集进行训练.为验证该方法的有效性,我们将该方法与直接使用LDA模型主题分类方法做了比较,分类结果如图4和图5.
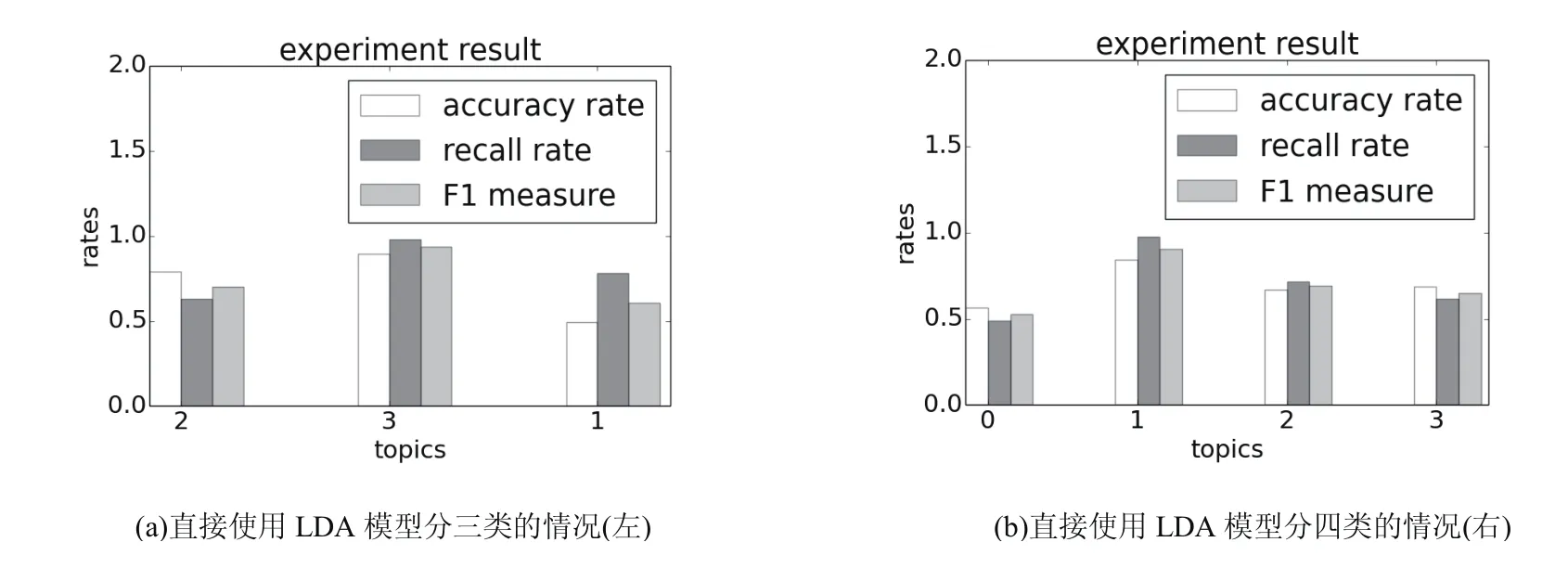
图4 直接使用LDA模型进行主题分类
由图4的实验结果可以得出:在该实验中,直接使用LDA模型进行分类的分类结果并不稳定,实验分类结果会出现两种情况,即分为三类和四类的情况.由图5的实验结果可以得出:word2vec文本扩充方法的分类结果与扩充长度L有关.当L=8,10时,实验测试数据可准确且稳定地分为四类,当L=5,12,15,20时分为三类.由此我们可以得出:实验数据的分类效果与文本扩充长度L有关,当L为8和10时可以准确地分为四类,准确率、召回率和F1值最高,分类效果最好;当L逐渐增大时,实验分类效果会随之降低,也就是说并不是扩充长度越长主题分类效果就越好.我们将图4中分类效果较好的(b)图同图5中分类效果较好的L=8时的(b)图进行比较,详细数据见表2.由此可以看出,扩充后的主题分类的平均准确率、平均召回率和平均F1值与未扩充的主题分类的平均准确率、平均召回率和平均F1值相比分别高出26.1%、25.5%、27.2%,这表明了基于woed2vec文本扩充方法在口语对话系统领域分类的有效性.
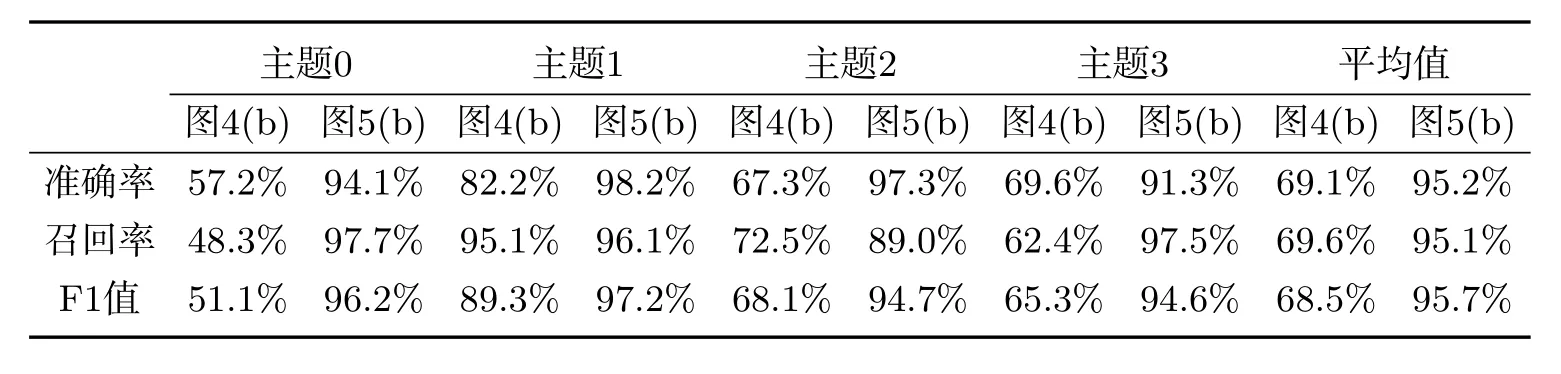
表2 图4(b)和图5(b)的分类效果比较
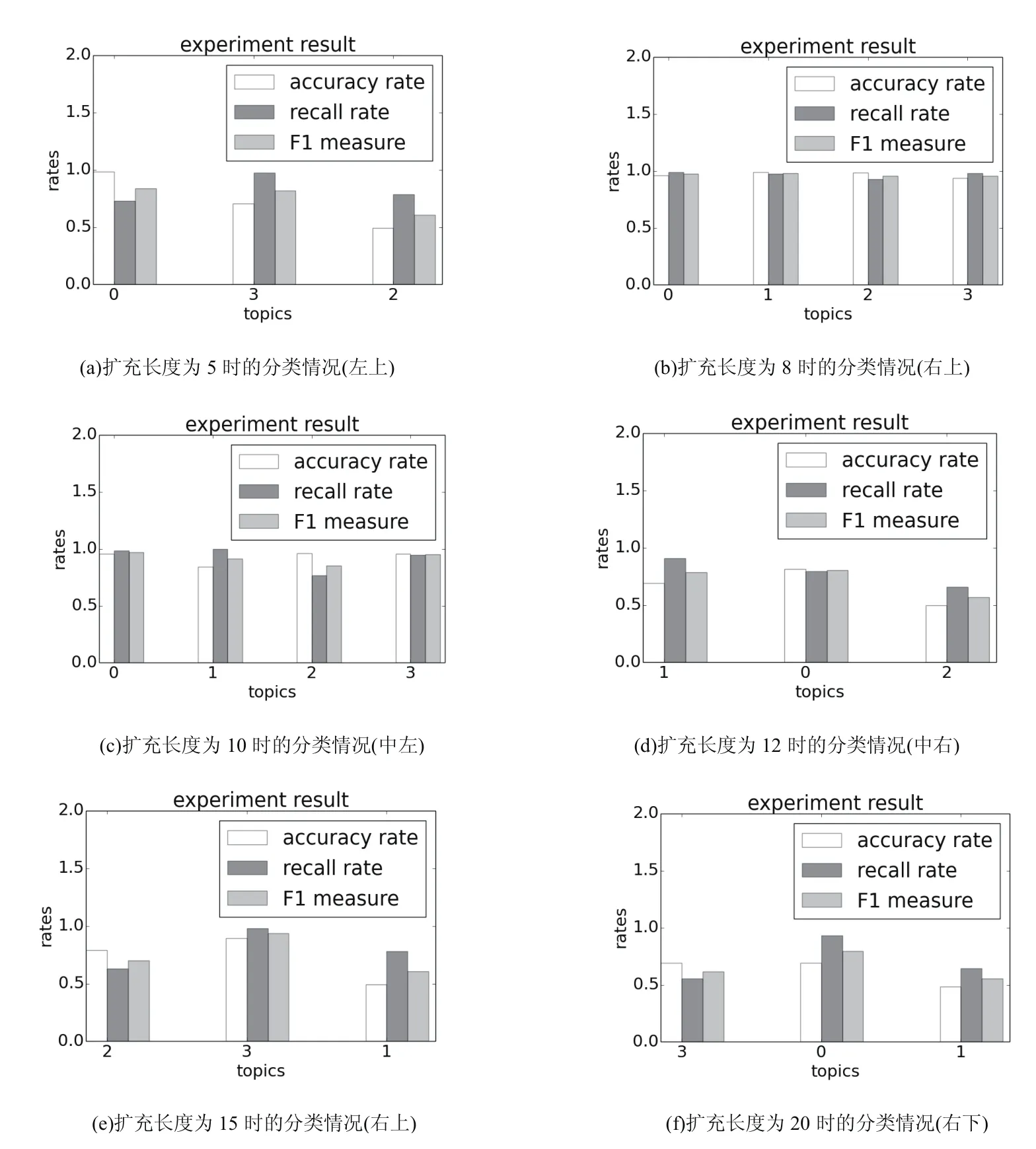
图5 基于word2vec文本扩充的LDA主题分类(分别为L=5,8,10,12,15,20的分类情况)
5 结束语
针对口语对话系统领域分类任务中传统分类方法需要人工标注的问题,本文提出了基于LDA模型的领域分类方法,针对口语对话文本主题分类数据稀疏的问题,在使用LDA模型基础上,提出了基于word2vec文本扩充的主题分类方法.与直接进行LDA主题分类方法比较,选取合适扩充长度L的word2vec文本扩充LDA主题分类方法能够稳定地进行主题分类,且主题分类的准确率、召回率和F1值均有明显提高.这表明了基于woed2vec文本扩充方法在口语对话系统领域分类的有效性.在今后的工作中,将继续扩充实验数据,对语音识别后的包含一定识别错误的口语对话文本进行主题分类,进一步提高主题分类的鲁棒性.
参考文献:
[1]吴尉林,陆汝占,段建勇,等.基于两阶段分类的口语理解方法[J].计算机研究与发展2008,45(5):861-868.
[2]Wu W L,Lu R Z,Duan J Y,et al.A weakly supervised learning approach for spoken language understanding[C].Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing.Association for Computational Linguistics,2006:199-207.
[3]李文波,孙乐,张大鲲.基于Labeled-LDA模型的文本分类新算法[J].计算机学报,2008,31(4):620-627.
[4]王细薇,樊兴华,赵军.一种基于特征扩展的中文短文本分类方法[J].计算机应用,2009,29(3):843-845.
[5]姜晓伟,王建民,丁贵广.基于主题模型的微博重要话题发现与排序方法[J].计算机研究与发展,2013,50(Suppl):179-185.
[6]高明,金澈清,钱卫宁,等.面向微博系统的实时个性化推荐[J].计算机学报,2014,37(4):963-975.
[7]余正涛,樊孝忠,郭剑毅,等.基于潜在语义分析的汉语问答系统答案提取[J].计算机学报,2006,29(10):1889-1893.
[8]Celikyilmaz A,Hakkani-Tur D,Tur G.LDA based similarity modeling for question answering[C].Proceedings of the NAACL HLT 2010 Workshop on Semantic Search.Association for Computational Linguistics,2010:1-9.
[9]魏强,金芝,许焱.基于概率主题模型的物联网服务发现[J].软件学报,2014,25(8):1640-1657.
[10]Celikyilmaz A,Hakkani-T¨ur D Z,T¨ur G.Approximate Inference for Domain Detection in Spoken Language Understanding[C].INTERSPEECH,2011:713-716.
[11]Morchid M,Linares G,El-Baze,et al.Theme identification in telephone service conversations using quaternions of speech features[C].INTERSPEECH,2013:1394-1398.
[12]Blei D M,Ng A Y,Jordan M I.Latent dirichlet allocation[J].the Journal of machine Learning research,2003,3:993-1022.
[13]李晓旭.基于概率主题模型的图像分类和标注的研究[D].北京邮电大学,2012.
[14]徐戈,王厚峰.自然语言处理中主题模型的发展[J].计算机学报,2011,34(8):1423-1436.
[15]张小平,周雪忠,黄厚宽,等.一种改进的LDA主题模型[J].北京交通大学学报:自然科学版,2010(2):111-114.
[16]MIKOLOV T,SUTSKEVER I,CHEN K,et al.Distributed representations of words and phrases and their compositionality[C]//NIPS 2013:Conference of Neural Information Processing Systems Foundation.Harrahs and Harveys,Lake Tahoe,Nevada,United States:Neural Information Processing Systems Foundation,2013:3111-3119.
[17]SU Z,XU H,ZHANG D,et al.Chinese sentiment classification using a neural network tool—Word2vec[C]//IEEE MFI 2014:2014 IEEE International conference on Multisensor Fusion and Information Integration for Intelligent Systems.Beijing,China:2014 International Conference on IEEE,2014:1-6.
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
文苑(2018年22期)2018-11-19
哲学评论(2018年1期)2018-09-14
学生天地(2017年10期)2017-05-17
大学教育(2017年5期)2017-05-10
电脑爱好者(2017年7期)2017-05-06
小天使·三年级语数英综合(2016年6期)2016-05-14
西南交通大学学报(社会科学版)(2015年4期)2016-03-29

- 新疆大学学报(自然科学版)(中英文)的其它文章
- The Absolute Ruin Risk Model with Constant Interest Investment and Linear Threshold Dividend Strategy∗
- 煤基活性炭的氧化改性及其对Cd2+的吸附性能∗
- 细菌诱导光滑鳖甲幼虫抑制差减cDNA文库的构建与分析∗
- 资源型产业与制造业集聚特征与影响因素异同分析∗
- Distance Signless Laplacian Integral Complete R-partite Graphs∗
- Finite-time Stability of Continuous-time Systems with Time-varying Delays∗