
基于迂回二次聚类的微博用户细分研究
2016-05-11 01:47陈可嘉罗晓莉
福州大学学报(哲学社会科学版) 2016年1期
关键词:微博
陈可嘉 罗晓莉
(福州大学经济与管理学院, 福建福州 350116)
基于迂回二次聚类的微博用户细分研究
陈可嘉罗晓莉
(福州大学经济与管理学院, 福建福州350116)
摘要:对于开展微博营销的企业而言,挖掘微博用户信息,进行用户细分,是企业实现精准网络营销的迫切需求。为此,首先运用API和网络爬虫技术,获取@戴尔中国的粉丝列表及相关用户信息。通过数据预处理,得到有效数据样本。然后对变量进行相关性分析,引入微博热度、互粉率变量,确定性别、地域、粉丝数、关注数、等级、认证类型、互粉率、微博热度等8项用户细分变量。基于迂回二次聚类,将@戴尔中国的微博粉丝用户划分为草根明星型、活跃女性型和默默关注型三类。在此基础上,帮助戴尔针对不同的用户群制定微博营销策略,为戴尔开展精准营销提供参考。
关键词:微博; 用户细分; 迂回二次聚类; 戴尔中国
近年来,由于互联网技术的发展,尤其是web2.0网络应用的兴起,微博、微信等社交类应用在短时间内迅速崛起。根据中国互联网络信息中心(CNNIC)发布的《2014年中国社交类应用用户行为研究报告》,我国整体网民中,社交网站覆盖率为61.7%,其中微博覆盖率为43.6%;微博品牌的覆盖率,新浪微博所占网民比例位居第一,腾讯微博紧跟其后。
微博的日趋流行造就了企业营销管理的新格局。一方面,微博用户群迅猛增长,不同地域、性格和特点的用户群,用户需求呈现差异化;另一方面,微博中存储了海量的用户数据,这些数据蕴含着用户潜在的行为特征,为识别用户需求提供了可能性。当前,微博已成为企业与用户互动交流的重要平台,企业非常注重在微博上进行用户关系管理。挖掘微博用户信息,进行微博用户细分,是企业实现精准化营销的迫切需求。[1]
基于微博用户数据的分析研究引起了国内外学者的广泛关注,成为了当前社交网络研究中的热点方向。在国外,研究者主要集中关注Twitter网站上的数据分析,采用不同方法对Twitter用户及微博信息进行研究。Cha等比较分析了与Twitter用户影响力相关的三个指标,分别为粉丝数、被转发数和评论数,发现用户的粉丝数量并不能直接反映用户的影响力,并将用户间的转发率作为计算用户影响力的主要变量[2];Kwak等运用PageRank算法计算了Twitter用户的排名,研究了微博信息传播机制、微博影响力与用户粉丝数量的相关性、用户网络的粉丝分布以及微博话题分布等问题[3];Shen等使用ROST软件对微博垃圾信息进行了文本挖掘,分析了微博垃圾信息的扩散网络[4];Fischer等运用归纳理论构建法讨论了Twitter的互动运行机制及其对用户认知和行为的有效影响,认为通过Twitter进行社交互动的两个主要影响因素分别是社区定位和对社区规范的遵守。[5]在国内,研究对象主要为新浪微博、腾讯微博等用户群体多、影响力广的微博平台,探讨较多的是微博用户影响力、微博用户特征、微博用户关系以及微博信息传播等问题。王晓光以“新浪微博”为例,对微博的基本结构以及信息传播模式进行了研究,考察了微博用户的行为特征和关系特征,构建了微博影响力回归方程[6];何黎等运用数据挖掘技术研究了微博用户特征,分析了通过对微博网络进行核心用户挖掘从而开展个性化营销的可行性[7];平亮和宗利永以新浪微博为研究对象,利用社交网络中心性分析方法,结合微博用户之间的网络拓扑关系,探讨了微博信息的传播模式[8];杨小朋和何跃引入博文魅力指数和博主收听人数两个变量,采用K-Means聚类算法对腾讯微博用户进行了聚类,挖掘了腾讯微博用户的特征[9];原福永等借助用户被关注度,计算了微博用户的活跃度与影响力,在此基础上,建立了用户影响力指数模型。[10]
从已有的相关文献来看,微博数据挖掘研究大多集中于微博的网络结构、用户特征、用户影响力及微博信息传播等方面,而针对微博用户细分的研究较为缺乏。杨小鹏等运用聚类算法实现了对微博用户的划分,证明了聚类分析方法在微博用户细分中应用是可行的[11],但其仅仅采用单一的K-Means聚类算法。
聚类分析起源于分类学,是数据挖掘中一个重要的研究课题,被广泛地应用于用户细分、识别潜在用户等领域。[12]最常用的两种聚类分析方法是K均值(K-Means)聚类和系统聚类。K-Means聚类在效率、精确度等方面优于系统聚类,但也有一个明显的缺陷就是需要事先确定聚类个数。
基于此,本文选取戴尔的新浪微博作为研究对象,利用API和网络爬虫技术,获取@戴尔中国的粉丝用户列表及用户信息,综合系统聚类和K-means聚类的优点,提出迂回二次聚类方法,实现微博用户细分,通过分析用户分群的特征,挖掘微博用户的差异化需求,帮助企业制定精准营销策略。
一、微博用户细分模型
基于数据挖掘的微博用户细分步骤包括微博用户细分目标确立、微博用户数据预处理、微博用户细分变量确定、微博用户细分算法设计、微博用户细分实现、微博用户细分结果分析与精准营销指导等。[13]
(一)微博用户数据预处理
由于微博用户数据可能存在缺失值、异常值和数据类型多样化等情况,在进行微博用户细分之前,需要对微博用户数据进行预处理,预处理步骤如图1所示。
(1)企业微博粉丝用户中存在部分的虚假粉丝或活跃度极低的真实粉丝,统称为“僵尸粉”。该类用户一般表现为没有粉丝或基本没有粉丝,无微博或长期未更新微博。这类用户对于企业微博营销意义不大,因而在对微博用户进行细分之前,首先对“僵尸粉”予以剔除,剔除的标准为粉丝数≤α(α≥0)或微博数≤β(β≥0)。
(2)由于微博用户数据可能存在缺失值、异常值、无效值等,这些都会对分析结果造成影响。为了确保分析的准确性和真实性,剔除数据质量差的变量。此外,考虑数据挖掘算法对于数据差异性的要求,对数据分布过于集中的变量,同样予以剔除。最终将数据质量差的标准定义为数据缺失率≥γ(γ≥0)或数据集中率≥δ(δ≥0),其中,映射在某变量上的数据缺失率=变量值缺失的样本数/总有效样本数,映射在某变量的数据集中率=出现频率最高的变量值对应的样本数/总有效样本数。
(3)对于剩余变量,可能还存在用户样本在变量的映射含有缺失值、异常值等,剔除这些数据异常的用户样本。
(4)数值化处理。对于名义型变量,转化为对称数值;对于有序型变量,转化为序数值。
(5)数据分段处理。考虑变量数据离散性,对部分变量数据进行分段处理。
(二)微博用户细分变量确定
经过数据预处理,初步得到可用于微博用户细分的有效用户数据。要确定微博用户细分变量,还需要进一步考察变量的相关性。由于相关性较强的变量会将某些因素放大而影响聚类效果,故需对变量进行相关性分析,标识出相关性强的变量加以分析,合理去除高相关变量。通过计算变量间的Pearson相关系数,将相关系数r≥ε(0≤ε≤1)的变量列出,对于相关性较高的变量,结合各变量的具体含义及对应关系,进行合理地剔除,最终确定微博用户细分变量。
(三)微博用户细分算法设计
聚类分析能够根据用户属性变量将用户划分为具有不同特征的用户群,故本文选取聚类分析作为微博用户细分的方法。聚类分析通常有两类方法:分层方法和划分方法,其中最常用的分别是系统聚类和K-Means聚类。
1. 系统聚类
系统聚类属于聚类分析中的分层方法,是聚类分析中使用最多的方法,其基本步骤如图2所示。
系统聚类的基本原理是将距离近的对象先进行聚类,距离远的后进行聚类,对数据反复进行分裂或合并,直到满足某个条件为止,可以通过绘制聚类树图直观地反映整个聚类过程。
系统聚类的最大缺陷在于,分裂或合并的步骤一旦完成无法纠正,这意味着如果某个步骤的结果不好,则无法进行改正,最终将导致聚类效果不好。此外,系统聚类法主要适用于样本量较少(通常指小于100)的样本聚类及变量聚类,对于大数据,处理性能较差。
2. K-Means聚类
K-Means聚类属于聚类分析中的划分方法,其基本步骤如图3所示。
K-Means聚类的基本思想是将对象在类间进行移动,通过反复迭代改变初始聚类,使得类内对象间距离最短,类间距离最大。
K-Means聚类具有计算速度快、伸缩性好、精确度高的优点,但是由于不同的初始聚类中心会导致不同的聚类结果,使得聚类结果存在较大
的不确定性,且算法对离群点异常敏感,离群点的存在会对聚类结果造成极大的影响。此外,K-Means聚类还有一个明显的缺陷就是需要事先给出聚类个数k,而k值的准确给出是非常困难的。
3. 迂回二次聚类
本文在进行微博用户细分时,充分发挥系统聚类和K-Means聚类的优点,提出了迂回二次聚类算法:
(1)系统聚类方法确定。使用六种系统聚类方法对用户数据进行第一次系统聚类,对比不同的聚类方法得到的聚类结果,确定系统聚类方法。
(2)聚类个数初试。选取聚类效果最好的系统聚类方法,对用户数据抽取小样本实施第二次系统聚类,观察所得聚类树图,判断不同的聚类个数下,类的大小的分布,初步得出合适的聚类个数范围。
(3)聚类个数确定。绘制聚类个数与组内平方和的散点折线图,观察得出推荐的聚类个数,结合第二次系统聚类结果,最终确定聚类个数k。
(4)初始中心确定。将探索确定的聚类个数k以参数形式回传给K-Means聚类进行迭代,对随机初始中心的选取次数进行尝试,一般增加选取次数可以改善聚类效果,依据聚类效果最好的选取次数,最终确定初始聚类中心。
(5)K-Means聚类。根据上述步骤获得的聚类个数及初始类中心,利用K-Means聚类对原始样本重新划分,最终确定聚类结果。
二、基于迂回二次聚类的戴尔新浪微博用户细分
本文对于微博用户细分的实证研究,选取戴尔的新浪官方微博@戴尔中国为例。戴尔是微博营销中的经典案例,对其微博用户进行细分具有重要意义。
(一)微博用户数据采集与预处理
1. 微博用户数据采集
目前微博数据采集主要有基于API的数据获取和基于网络爬虫的页面解析两大方式。[14]新浪微博API接口共开放39项用户变量信息,针对本文研究的需要,利用API接口获取14项用户变量信息,包括用户UID,昵称,所在省,所在城市,所在地,个人描述,性别,粉丝数,关注数,微博数,收藏数,注册时间,微博认证类型,互粉数。此外,借助基于网络爬虫的页面解析技术,获取7项用户变量信息,包括标签,教育信息,兴趣(达人),等级,活跃天数,信用等级,积分(达人)。
本文的微博数据采集工作分两次进行:第一次抓取时间为1月,完成了基于新浪微博API的数据采集;第二次抓取时间为3月,通过网络爬虫采集了微博用户数据。
由于微博用户数量庞大,仅抽取@戴尔中国的部分用户作为样本,利用新浪微博API和网络爬虫两种方式,共获取包含21项用户变量信息的4 856条@戴尔中国粉丝用户数据。获取的微博用户数据存储于MySQL数据库中,作为微博用户细分的样本数据。
2. 微博用户数据预处理
根据数据预处理步骤,具体操作如下:
(1)根据百度百科对于“僵尸粉”的定义以及@戴尔中国微博粉丝用户的粉丝数和微博数的分布情况,取α=5,β=5,即粉丝数≤5或微博数≤5的用户视为“僵尸粉”予以剔除。共剔除325条用户样本,剩余4 531条用户样本。
(2)定义变量值为空值(NULL)或空字符串‘ ’的数据为缺失值,取γ=30%,共剔除6项数据缺失率≥30%的用户变量,包括个人描述、收藏数、标签、教育、兴趣、达人积分,数据缺失率分别为60.8%、57.7%、45.2%、91.0%、84.1%、84.0%。此外,根据样本数据的分布情况,取δ=90%,信用等级变量的数据分布过于集中,除去141项空值外,4693项均为“正常”,数据集中率≥90%,不符合聚类分析对于数据差异性的要求,予以剔除。
(3)针对数据质量满足要求的变量,剔除在这些变量的映射中含有缺失值的样本,共剔除143条异常样本。针对研究问题的特定背景,将省份变量取值“其他”“海外”“香港”“台湾”视为异常值,共剔除468条省份变量信息异常的样本。
(4)根据聚类分析对于数据类型的要求,对性别、用户创建时间、微博认证类型、所在地4项非数值型变量进行数值化处理。性别为名义型变量,值域为{“男”,“女”},对应转化为{1,-1};将用户创建时间替换为与实验时点的时间差,代表用户的“微博年龄”,以天为计量单位;微博认证类型为有序型变量,值域为{“普通用户”“初级达人”“中高级达人”},相应转化为{0,1,2};所在地为名义型变量,形如“福建 福州”,分别与省份、城市变量相对应,且省份、城市变量均为数值型,故剔除所在地变量。
(5)由于用户省份变量取值的值域过大,造成聚类过程运算量大,且可能导致聚类结果的分辨性不够,参照2014年中国地理区划,对省份变量数据进行分段处理,将省份划分为华北、华东、华中、华南、西南、西北、东北7个区域,新建数值型地域变量,分别对应为{1,2,3,4,5,6,7}。
经过数据预处理,此时有效样本数n=3920,变量数p=14。
(二)微博用户细分变量确定
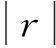
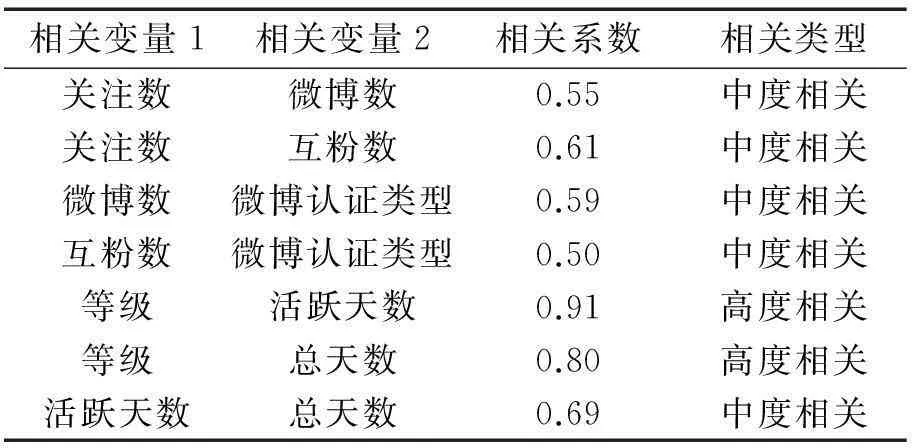
表1 较强相关变量
通过变量相关性分析,最终确定8项微博用户细分变量:性别、地域、粉丝数、关注数、当前等级、微博认证类型、互粉率、微博热度,其中性别和地域属于传统意义的人口统计变量,其余则是具有社交网络特性的变量。
(三)基于迂回二次聚类的微博用户细分实现
在聚类分析中,大多数据由于不在同一数量级而存在绝对值差异,往往不能直接参与运算,需要进行中心化或标准化处理,弱化不同变量绝对值差异对于聚类结果的影响。本文对进行聚类分析的3920条样本数据的8个细分变量进行了中心化和标准化处理,使得各变量的均值为0,标准差为1。
1. 系统聚类方法确定
对用户数据进行第一次系统聚类,利用数据挖掘工具R语言中提供的聚类分析包,分别使用六种定义类间距离的方法建立系统聚类模型,评价六种聚类方法获得的聚类结果,最终确定系统聚类方法。
(1)计算距离矩阵。使用欧氏距离定义样本间距离,对提取的3920条数据的8个细分变量计算距离矩阵。
(2)系统聚类方法尝试。使用hclust函数建立系统聚类模型,系统聚类首先将每个样本作为一类,再将类间距离最近的样本合并,合并后重新计算类间距离,重复步骤直到将所有样本归为一类。定义类间距离有如下六种常见的方法:最短距离法、最长距离法、中间距离法、类平均法、重心法、离差平方和法(Ward法)。为了使聚类结果更加准确,分别使用六种定义类间距离的方法建立系统聚类模型。
(3)确定系统聚类方法。使用plot函数绘制聚类树图,对比六种聚类方法的树形聚类图,根据类的大小的分布均匀性,直观上看,最短距离法的聚类效果较差,Ward法的聚类效果较好,最终将系统聚类方法确定为Ward法。
2. 聚类个数初试
由于数据集过大,得出的聚类树图太密集,无法观察判断合适的阈值,同时考虑到系统聚类的特性(适用于小样本),故取前40条用户记录(样本总数的1%)作为抽样样本,利用Ward法对用户抽样数据进行第二次系统聚类,绘制聚类树图(图4)。树形图中纵轴为阈值,代表类间的距离,横轴为用户id,代表样本所属的类别,对应不同的阈值,可得到不同的聚类结果。
取阈值为5,得到类间距离大于5的聚类结果,以类的大小、类间距离作为评价标准,评价聚类效果,考察不同聚类个数下,各类的大小的分布,计算标准差。根据表2的计算结果,结合类间距离,初步得出合适的聚类个数范围在3-6之间。
利用Ward法重新对总体样本进行系统聚类,分别得到分为3至6类的聚类结果,结果证明将用户总体分为3至6类是比较合适的。
3. 聚类个数确定
根据两次系统聚类结果,得出了合适的聚类个数的范围,为了更好地确定聚类个数,进行第二次聚类个数尝试。利用R语言中的NbClust包,绘制散点折线图(图5),用于判断聚类个数,其中横轴代表聚类个数,纵轴代表组内平方和(SSE)。
根据折线图中组内平方和减小的趋势可知(表3),曲线在聚类个数为3时第一次出现明显的拐点,表明组内平方和减小的趋势变缓,综合考虑系统聚类得到的聚类个数范围,最终确定推荐的聚类个数为3。
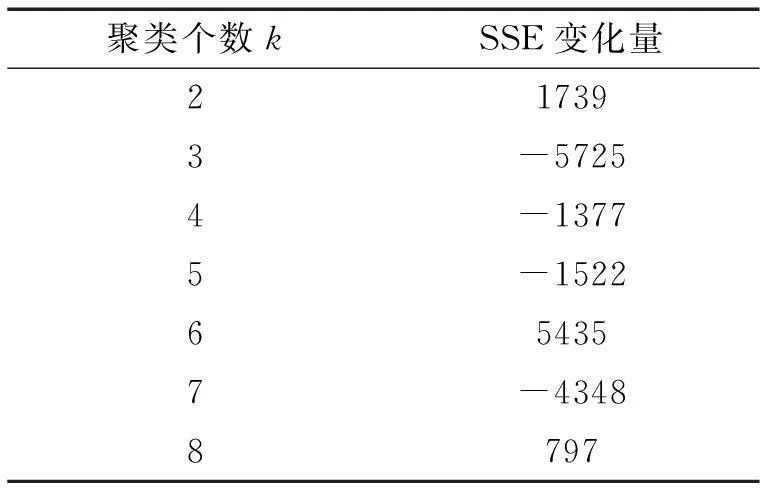
表3 组内平方和随聚类个数k变化情况
4. 初始中心确定
将探索确定的聚类个数k传递给K-Means聚类,并对选取随机初始中心的次数进行尝试,确定初始中心。
在K-Means算法中,初始中心的选择对用户聚类结果具有很大影响。为了使用户聚类的效果尽可能好,本次实验利用R语言中的k-means函数,尝试用不同的初始中心进行建模,观察组内平方和的变化情况。结果显示,将随机选取初始中心的次数设定为15进行K-Means聚类时,组内平方和最小,聚类效果最好。
5. K-Means聚类
利用R语言中的k-means函数建模,将聚类个数k设定为3,随机选取初始中心的次数nstart设定为15,对用户样本进行聚类,获得最终的微博用户细分结果(表4)。
经过迂回二次聚类,最终将微博用户样本分为三类,各类的样本数分别为697、1111、2112,由聚类结果可得到各类的中心。

表4 微博用户细分结果
(四)微博用户细分结果分析与精准营销建议
根据用户聚类结果,计算三类用户各项变量的算术平均值(表2),结合用户各项变量的取值范围,分析得出各类用户不同的属性特征。可以发现,@戴尔中国的粉丝群体中男性居多,这与男性多偏爱电子产品相关;粉丝群主要分布在华东和华中地区,这可能与戴尔的市场重心有关;戴尔的粉丝用户很大一部分为普通用户,达人用户所占比例较低,这也是戴尔在新浪微博营销中需要关注的一点。
根据微博用户细分结果,每类用户群在活跃度、影响力各方面均存在较大不同。针对用户细分群体特征,向@戴尔中国提出精准的个性化营销建议。
默默关注型。所占比例超过一半,且基本为男性,属于@戴尔中国的坚实用户基础;用户群的关注数大于粉丝数,发博数较少,导致粉丝数较少,此类用户习惯接收信息,不善于主动创造信息。建议根据其标签、爱好、话题等信息,定期对其推送相关感兴趣的信息,并适时邀请此类用户参加举办的一些微博活动,提高用户活跃度,增大影响力,争取发展成为活跃用户。
活跃女性型。唯一的女性占大比例的用户细分群体,微博热度最高,发博数较多,粉丝数与关注数居中,有较高的影响力和活跃度。女性作为消费的一大主力,对于企业来说有很大价值。建议适当在微博内容和微博活动中添加女性关注的内容,并在产品设计中添加女性元素,增强女性用户的忠实度,扩大女性用户群体。
草根明星型。粉丝数与关注数均远远超过其他两类,互粉率最高,发微博数远高于其他两类,普遍为等级较高的达人用户;此类用户属于微博中的积极分子,在微博中影响力较大,属于高质用户。建议主动与其进行互动,参与其发布的话题讨论,通过其庞大的粉丝群,拓展自身的粉丝群;还可以通过其他途径,如招纳其进行校园代理、微博营销代理等,增强企业微博的影响力。
三、结语
开展微博营销的企业可以利用数据获取技术和数据挖掘算法,对微博用户信息进行聚类分析,从而实现微博用户细分,并根据用户细分结果,进行更有针对性的消息推送和互动,制定营销策略,实现精准营销。本文运用数据挖掘工具中的聚类算法,对目标企业@戴尔中国的微博粉丝实现了用户细分。首先,运用API和网络爬虫技术,获取@戴尔中国的粉丝列表及相关用户信息。通过数据预处理,得到有效数据样本。然后,对变量进行相关性分析,引入微博热度、互粉率变量,确定了性别、地域、粉丝数、关注数、等级、认证类型、互粉率、微博热度等8项用户细分变量。基于迂回二次聚类,最终将@戴尔中国的微博粉丝用户划分为草根明星型、活跃女性型和默默关注型三类。针对戴尔新浪微博粉丝用户细分结果,提出了精准营销建议。
注释:
[1] 郝 玫、王道平:《面向供应链的产品评论中客户关注特征》,《现代图书情报技术》 2014年第4期。
[2] Cha M., Haddadi H., Benevenuto F., et al. ,MeasuringUserInfluenceinTwitter:TheMillionFollowerFallacy, Proceedings of the 4th International Conference on Weblogs and Social Media, 2010,pp.10-17.
[3] Kwak H., Lee C., Park H., et al.,WhatisTwitter,asocialnetworkoranewsmedia?,Proceedings of the 19th International Conference on World Wide Web, 2010,pp. 591-600.
[4] Shen Y., Li S., Ye X., et al. ,“Content mining and network analysis of microblog spam”,JournalofConvergenceInformationTechnology, vol.5,no.1(2010), pp. 135-140.
[5] Fischer E., Reuber A. R., “Social interaction via new social media: How can interactions on Twitter affect effectual thinking and behavior?”,JournalofBusinessVenturing, vol.26,no.1(2011),pp. 1-18.
[6] 王晓光:《 微博客用户行为特征与关系特征实证分析——以 “新浪微博” 为例》,《图书情报工作》 2010年第14期。
[7] 何 黎、 何 跃、 霍叶青:《微博用户特征分析和核心用户挖掘》,《情报理论与实践》2011年第11期。
[8] 平 亮、 宗利永:《 基于社会网络中心性分析的微博信息传播研究——以Sina微博为例》,《 图书情报知识》2011年第6期。
[9][11] 杨小朋、何 跃:《腾讯微博用户的特征分析》,《情报杂志》2012年第3期。
[10] 原福永、冯 静、符茜茜:《微博用户的影响力指数模型》,《现代图书情报技术》2012年第6期。
[12] Byrne D., Uprichard E.,Clusteranalysis,London: Sage, 2012.
[13] King R. S.,ClusterAnalysisandDataMining:AnIntroduction, Dulles: Mercury Learning & Information, 2014.
[14] 廉 捷、 周 欣、 曹 伟等:《新浪微博数据挖掘方案》,《清华大学学报》(自然科学版) 2011年第10期。
[责任编辑:黄艳林]
中图分类号:TP393
文献标识码:A
文章编号:1002-3321(2016)01-0042-07
作者简介:陈可嘉, 男, 福建福州人, 福州大学经济与管理学院教授、 硕士生导师, 博士;
基金项目:国家自然科学基金项目(61179061); 教育部新世纪优秀人才支持计划(NCET-11-0903)。
收稿日期:2015-10-05
罗晓莉, 女, 福建连城人, 福州大学经济与管理学院硕士研究生。
猜你喜欢
电脑知识与技术(2016年26期)2016-11-24
电脑知识与技术(2016年25期)2016-11-16
中国市场(2016年38期)2016-11-15
出版科学(2016年5期)2016-11-10
文艺生活·中旬刊(2016年9期)2016-11-07
人间(2016年26期)2016-11-03
人民论坛(2016年27期)2016-10-14
科技传播(2015年12期)2015-09-16
意林(2013年15期)2013-05-14
