
基于多分类器投票集成的半监督情感分类方法研究
2016-05-04 02:51黄伟,范磊
中文信息学报 2016年2期
黄 伟,范 磊
(上海交通大学 信息安全工程学院,上海 200240)
基于多分类器投票集成的半监督情感分类方法研究
黄 伟,范 磊
(上海交通大学 信息安全工程学院,上海 200240)
情感分类是目前自然语言处理领域的一个具有挑战性的研究热点,该文主要研究基于半监督的文本情感分类问题。传统基于Co-training的半监督情感分类方法要求文本具备大量有用的属性集,其训练过程是线性时间的计算复杂度并且不适用于非平衡语料。该文提出了一种基于多分类器投票集成的半监督情感分类方法,通过选取不同的训练集、特征参数和分类方法构建了一组有差异的子分类器,每轮通过简单投票挑选出置信度最高的样本使训练集扩大一倍并更新训练模型。该方法使得子分类器可共享有用的属性集,具有对数时间复杂度并且可用于非平衡语料。实验结果表明我们的方法在不同语种、不同领域、不同规模大小,平衡和非平衡语料的情感分类中均具有良好效果。
情感分类;集成学习;半监督学习
1 引言
随着网络的发展,人们已从单一地扮演信息接收者的角色,逐渐开始向信息发布者转变,这些信息通常以产品评论、论坛帖子以及博客等形式存在。通过这些信息,政府可以获取百姓的立场和舆论倾向,以便采取相应的措施和制定相应的政策;商家可以及时了解用户的反馈从而有针对性地改善商品,满足顾客需求;顾客可以通过其他人的评论来全方位地了解商品,从而为自己的购买决策提供有力指导[1]。随着这些信息的迅速膨胀,仅靠人工已经难以应对和处理这些海量数据,因此迫切需要计算机工具帮助人们快速获取和整理这些相关的评价信息[2]。
目前情感分类的主流研究方法可分为两种思路:基于情感知识的方法以及基于特征分类的方法。前者主要是依靠一些人工收集的情感词典或领域词典从主观文本中抽取带有情感极性的组合评价单元进行统计,从而获取文本的极性;后者主要是使用机器学习的方法,从文本中抽取大量有用的特征来完成分类任务[2]。
从当前的研究进展来看,在自然语言理解领域还有一些关键技术尚待研究,基于情感知识的方法虽然不需要标注样本,但相比使用机器学习的算法,其性能并无明显优势[3]。
尽管基于机器学习的方法对情感分类任务非常有效,但是监督学习需要依赖大量的标注样本,而获取大量标注样本的成本代价往往很高,需要花费大量的人力、物力。在真实世界中,随着数据采集和存储技术的飞速发展,收集大量未标记样例并不困难。显然如果只使用少量有标记的样例,那么训练出来的学习系统往往很难具有很强的泛化能力;另一方面,如果仅使用少量“昂贵的”标记样本而忽略大量“廉价的”未标记样本,则是对数据资源极大的浪费[4]。半监督学习是一种结合少量标注样本和大量未标注样本进行学习的方法,本文主要基于半监督情感分类进行研究。
在实际应用中,很多时候,人们只有少量的标记样本,却需要预测大量的未标记样本,而这些测试集本身就提供了大量“廉价的”未标记样本。本文的研究主要基于这种场景。
目前情感分类任务中最常用的半监督学习方法是协同训练,协同训练(Co-training)是由Blum和Mitchell[5]在1998年提出的。该方法需要满足两个强条件:(1)样本可以通过两个冗余的独立视图进行表示;(2)每一个视图都可以从训练样本中学习到一个强分类器[6]。
使用Co-training的半监督学习方法来解决情感分类问题存在以下缺陷:
(1) 由于普通情感评论文本并没有天然存在多个独立视图,所以必须以分割特征子空间的方式将文本特征空间分成多个部分作为多个独立视图,然而情感分类中有用的特征并不多,所以很有可能子空间分类器不包含这些有用的特征从而退化成弱分类器;
(2) 在标准的Co-training算法中每次只标记固定的常数个样本,当未标注样本的规模扩大一倍时,训练过程中的迭代次数也随之扩大一倍,算法达到了线性时间复杂度;
(3) 由于在真实情况下未标注样本的平衡性很难预估,每次从未标注样本中挑选多少个正面和负面样本将会成为一个困难的问题。
Thomas G Dietterich[7]指出集成分类器能解决单个分类器训练数据量小、假设空间小和局部最优这三个问题,预测能力会优于单个分类器的预测能力。已有一些学者将集成学习方法应用到了情感分类领域[8-10],并成功提高了分类器的性能。
每个子分类器都会根据自己学习到的模型单独对未标记样本进行预测。一般而言,子分类器意见一致的文本,预测准确率应该比那些子分类器意见有分歧的文本预测准确率更高,且分歧越大,预测的置信度将会越低。本文在大量的、不同领域的数据集上用实验验证了这个猜想:子分类器的意见越统一,预测的置信度越高。
针对上述问题,本文利用了集成学习的良好性能提出了基于多分类器投票集成的半监督情感分类方法(Semi-supervised sentiment classification based on ensemble learning with voting combination,以下简称SSEV)。SSEV通过采用不同的训练集、特征参数和分类方法构建了一系列子分类器来取代传统方法中使用不同的视图,使得每个子分类器在保证差异性的前提下都能独享整个特征视图;每次通过简单投票方法进行整合并按预测置信度从高到低选取和训练集同样规模的平衡语料连同它们的预测标签一起加入训练集,有效地将算法降低到了对数时间复杂度;自动识别剩余未标注样本的平衡性,当剩余语料非平衡时结束迭代,兼顾了非平衡语料。实验表明,SSEV适用于不同语种、不同领域、不同规模大小,平衡和非平衡语料的情感分类任务。
本文其他部分安排如下:第二节详细介绍情感分类的相关工作;第三节提出了基于多分类器投票集成的半监督情感分类方法;第四节给出实验结果及分析;第五节给出相关结论,并对下一步工作进行展望。
2 相关工作
2.1 基于监督学习的情感分类方法研究
Pang and Lee[11]首次使用机器学习的方法来处理篇章级的情感分类任务,他们使用了不同的N-gram作为文本特征,BOOL和TF作为特征权重,尝试了NB,ME和SVM这三种不同的文本分类方法。实验结果表明Uni-gram作为文本特征效果最突出,在分类算法中,SVM的效果最佳。Cui等人[12]通过实验证明,当训练语料较少时,Uni-gram的效果的确最优,但随着训练语料规模的扩大,N-gram(n>3)的作用越来越显著。Pang & Lee[13]在后来的工作中对原有方法加以了改进,增加了一个过滤器滤去电影评论中的客观句,让机器学习只把注意力放在主观句上,使准确率从原来的82.9%显著地提高到了86.4%。
在中文文本情感分类方面,谭松波等人[3]分别使用了N-gram以及名词、动词、形容词和副词作为文本特征,以互信息(MI)、信息增益(IG)、CHI统计量和文档频率(DF)作为不同的特征选择方法,并对比了中心向量法、KNN、Winnow、Naive Bayes和SVM这几种不同的文本分类方法,在不同的特征数量和不同规模的训练集下,分别进行了中文情感分类实验。他们的实验结果表明采用Bi-grams特征作为文本特征、使用信息增益特征选择方法和SVM分类方法,在训练集足够大和选择适当数量特征的情况下,情感分类能取得较好的效果。
2.2 基于集成学习的情感分类方法研究
当下四种最流行的集成学习方法分别是Bagging[14]算法,Boosting[15]算法、Stacking[16]算法和Random subspace[17]算法。已有一些学者将不同的集成学习方法用于情感分类,并有效地提高了分类器的性能。Whitehead等人[8]通过实验指出使用集成分类方法可以有效地提高文本分类的准确率,特别是使用bagging和subspace组合的集成学习算法效果最为突出;李寿山等人[9]将四种不同的分类方法应用于中文情感分类任务中,并且采用了一种基于Stacking的集成学习方法用于组合不同的分类方法。实验结果表明该组合方法在每个领域都获得了比最好基分类方法更好的分类效果;Su等人[10]通过实验同样发现基于Stacking的组合分类方法在所有领域都取得了较好的效果,他们同时还指出,这种方法的表现优于简单投票整合的方法。
所有上述学者在使用集成学习方法时都把注意力放在了提高整体的预测准确率上。而SSEV更关心的是如何通过集成分类器抽取一部分预测置信度较高的数据来扩展初始训练样本。
2.3 基于半监督学习的情感分类方法研究
Wan[18]将英语和汉语作为两个不同的独立视图,采用协同训练方法进行半监督情感分类;Li等[19]则是把评价语句分为个人视图(Personal View)和非个人视图 (Impersonal View)这两个不同的独立视图,同样使用了协同训练方法进行半监督情感分类。苏艳等[6]对协同训练方法进行改进,提出了基于动态随机特征子空间的协同训练算法,并通过实验验证了该方法明显优于基于静态随机特征子空间的协同训练方法,特别是当特征子空间数目为4的时候,该半监督学习方法能够取得最好的分类性能。高伟等人[20]提出了一种基于一致性标签的集成学习方法,用于融合两种主流的半监督情感分类方法:基于随机特征子空间的协同训练方法和标签传播方法。他们的实验结果表明该方法能够有效地降低未标注样本的误标注率,从而获得比任一种半监督学习方法更好的分类效果。
值得一提的是,本文假设的场景更贴近实际应用,在很多情况下,人们只有少量的有标记样本,却需要预测大量的未标记样本,而这些测试集本身就包含了大量“廉价的”未标记样本。虽然本文假设的半监督学习在场景上看起来更像是直推学习。但与直推学习不同的是,SSEV并没有将泛化能力有针对性地放在指定的“封闭的”测试集上,因此对于“开放世界”,SSEV很容易进行迁移并同样适用。
3 多分类器投票集成的半监督情感分类方法
3.1 基本猜想
每个子分类器都会根据自己学习到的模型单独对未标记样本进行预测。一般而言,子分类器意见一致的文本的预测准确率应该比那些子分类器意见有分歧的文本预测准确率更高,且分歧越大,预测的置信度将会越低。基于多分类器投票集成的半监督情感分类算法,主要基于这个猜想来利用集成分类器,从未标注样本中抽取置信度较高的样本,连同它们的预测标签一同加入训练集来扩充训练集的规模。
下面是关于这个猜想的理论分析。

算法1通过伪代码描述了投票整合的具体过程。设总共有m个子分类器(m最好为奇数),文本d初始的预测值pre(d)置为0,对于每一个子分类器fi,当fi对文本d的预测为正面时,pre(d)=pre(d)+1,当fi对文本d的预测为负面时,pre(d)=pre(d)-1。|pre(d)|的值越大,表示子分类器对文本d的预测意见越统一。
假设每个子分类器fi的预测准确率均为p,并且任意两个子分类器对未标注样本的预测结果是独立的。若最终|pre(d)|=|m-2n|(n>m/2),则对于样本d有两种情况:
1.n个(大部分)子分类器预测正确,m-n个子分类器预测错误,投票整合正确;
2.m-n个(小部分)子分类器预测正确,n个子分类器预测错误,投票整合错误。
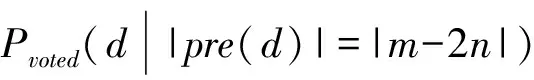
(1)

3.2 基于多分类器投票集成的半监督情感分类算法
SSEV中的集成分类器一共包含九个子分类器,图1显示了SSEV方法的总体框架。
为了确保分类器之间的差异性,每个子分类器都根据bagging算法有放回地抽取训练样例,从而为每一个子分类器都构造出一个跟训练集同样大小但各不相同的训练集。
九个子分类器中的四个使用SMO分类算法,对于特征的选择,首先过滤掉词频低于阈值5的词语,然后根据CHI值来排列特征,选取前1 500维特征。(如果词频高于阈值的词语不足1 500,特征可以小于1 500维),特征权重计算采用TF_IDF算法。
另外五个子分类器使用Voted perceptron (投票感知器)分类算法,特征的选择方法和特征权重的计算方法和前四个子分类器完全相同。
为了保证训练的平衡性,必须确保初始的训练样本是平衡的。在每一次的迭代过程中,分别使用每个子分类器对未标注测试集进行预测,然后通过投票的方式进行整合,对于任意测试样本,均可以获得一个预测值pre(d)。每一次将训练集的大小扩充一倍,并且仍然设法保持训练集的平衡性。设在某次迭代开始时,已标注训练集的大小为m,待标注测试集的大小为n。我们通过以下的方式对训练集进行扩充。
(1) 从pre(d)大于0的样本中按|pre(d)|的值从大到小抽取规模为m/2的样本连同它们的正面标签一起加入训练集;
(2) 从pre(d)小于0的样本中按|pre(d)|的值从大到小抽取规模为m/2的样本连同它们的负面标签一起加入训练集。
通过上述两步的操作,在这一次迭代中,SSEV成功地完成了对m条测试样本的标记,并将它们连同它们的标签一起加入了训练集。未被选入训练集的待标注样本则丢弃它们此轮迭代中获得的pre(d)值,仍然处在待标记测试集中。现在训练样本规模为2m,待标注测试集的数量则变成了n-m,在每一轮训练过程中,训练样本的规模都会翻倍,所以SSEV方法的时间复杂度为对数级。
算法2用伪代码详细描述了这一过程,当满足一定的条件时,迭代就会结束。在决定停止迭代的那一轮(也就是最后一轮迭代中),直接用集成分类器的预测结果来标注剩余所有的待标记测试集样本。
其中P(d)表示预测为正面的文本集合,N(d)表示预测为负面的文本集合,SP(d)为置信度最高的m/2条预测为正面的文本集合,SN(d)为置信度最高的m/2条预测为负面的文本集合。

迭代结束的条件如下:
如果待标注的测试集远大于已标注训练集的规模时,SSEV选择继续迭代;当两者的规模相差不大时,在此轮迭代后,剩余的测试集规模偏小,在这种情况下SSEV选择直接结束迭代;当待标注的测试集与已标注的训练集的规模不满足上述条件的时候,SSEV考察待标注测试集的平衡性,如果待标注测试集的平衡性出现了偏差,为了保持训练样本的平衡性,立刻结束迭代。在极端的情况下,如果待标注的样本严重失衡,SSEV会退化成完全监督学习,SSEV的基本原则是如果在某种情况下,不能比完全监督的方法达到更高的预测准确率,至少该算法不能让它降低。
在某一次迭代过程中,已标注训练集的样本数为m,待标注测试集的样本为n,集成分类器对n个测试样本的预测结果是t个样本被预测为正面,n-t个样本被预测为负面。接下来SSEV需要从t个正面预测样本中挑m/2个置信度最高的正面样本和从n-t个负面预测样本中挑选m/2个置信度最高的负面样本连同它们的标签一起加入训练集。本文约定的具体规则是这样的:
(1) 当2m≤t且2m≤n-t,继续迭代;
(2) 当0.6≥t或0.6m≥n-t,结束迭代;
(3) 当不满足条件(1)和(2)时,我们定义平衡

规则中提到的常数为SSEV中的经验阈值。
算法3用伪代码详细地描述了这一过程。

算法4描述了基于多分类器投票集成的半监督情感方法的整体过程,最后将各迭代过程中标记的测试样本进行汇总,并将它们的预测标签与标准答案进行比较,从而获得整个测试集的预测准确率,这个准确率也反映了我们方法的性能。

4 实验结果与分析
4.1 实验设置
对于中文语料,SSEV首先使用中国科学院的分词软件ICTCLAS 2013对文本进行分词,然后将所有繁体字转换成简体字,选取基于词的Uni-gram + Bi-gram特征。
对于英语语料,SSEV的处理就简单得多,将所有单词小写并且去除标点符号,然后按空格分词,选取基于词的Uni-gram特征。
实验选择的语料数据集涵盖了英文和中文,覆盖了不同的领域,并且数据集的规模也不尽相同。
1. Movie Dataset[21],正反各1 000篇;
2. Large Movie Dataset[22],正反各5 000篇;
3. Large Movie Unbalanced Dataset[22],正1 000篇,反2 000篇;
4. Blitzer et al.收集的Book语料[23],正反各1 000篇;
5. Blitzer et al.收集的DVD语料[23],正反各1 000篇;
6. Blitzer et al.收集的Electronic语料[23],正反各1 000篇;
7. Blitzer et al.收集的Kitchen语料[23],正反各1 000篇;
8. 谭松波整理的酒店评论语料[24],正反各2 000篇;
9. 谭松波整理的笔记本电脑评论语料[24],正反各2 000篇;
10. 谭松波整理的书本评论语料[24],正反各2 000篇;
说明:语料2和3是从原始的Large Movie Dataset中截取部分语料组成的。
实验共分为两个部分。在第一部分中,我们将在这些数据集上用实验来验证我们的猜想:子分类器的意见越统一,预测的置信度越高;在第二部分中,我们将考察基于多分类器投票集成的半监督情感分类方法的实际效果。
4.2 猜想验证
语料的编号可以参考4.1节,P@N%的含义为置信度最高的前N%的测试样本的预测准确率。具体的做法是将文本d按|pre(d)|的值从大到小排列,取|pre(d)|值大的前N%的语料,统计它们的准确率,从而获得P@N%。不难得到P@100%即是整体准确率。
对于初始训练集的选取,我们确保它们是平衡的。以语料3为例,语料3是非平衡语料,规模为3 000。当训练集比例为25%时(训练集大小为750),我们抽取整体语料中的375篇正面样本和375篇负面样本用于训练,剩下的625篇正面样本和1625篇负面样本用于测试。表1显示我们的实验结果。

表1 P@N%对照表
① 当初始比例为75%时,需要1125篇正面样本,语料中正面样本总共只有1000篇,所以这里我们使用的初始比例为25%

续表
在实验(1)、(2)和(9)、(10)中,我们使用了同一个训练集,只是训练集的比例不同。(1)、(2)是英语语料,(9)、(10)是中文语料;在实验(4)中,我们的语料采用了非平衡语料;在实验(2)、(3)中,我们的语料都是Movie领域,训练集的比例相同,只是语料的规模不同;在实验(5)~(8)和实验(10)~(12)中,我们分别在英语和中文的不同领域中进行了实验。通过在不同语种、不同规模、不同领域,平衡和非平衡的语料上,采用不同的训练集比例,我们可以清晰地发现我们的猜测是正确的:子分类器的意见越统一,预测的置信度越高。
4.3 基于多分类器集成的半监督情感分类结果
在本小节中,我们将基于多分类器投票集成的完全监督方法作为Baseline,与我们的基于多分类器投票集成的半监督学习算法进行对比,在本小节的最后,我们还将SSEV和基于随机特征子空间的半监督情感分类方法[6]进行了对比。
表2显示了语料2(语料规模为10 000)在初始标注比例为1%时的表现,由于SSEV的集成分类器中的每个子分类器,都根据bagging算法有放回地抽取训练样例, 从而为每一个子分类器都构造出一个跟训练集同样大小但各不相同的训练集。为了规避子分类器在抽取训练样例时的随机性,对于每个训练集我们都进行三次实验。

表2 语料2在初始标注比例为1%的表现表


由于初始训练集比例较低,随机选取不同的训练集可能会对结果产生一定的影响,为了规避这种影响,在每种初始比例下都随机选取三组不同的训练集,在每组选定的训练集下都进行三组实验,最终的Baseline值由这九组Baseline的值取平均,SSEV值也由这九组SSEV的值取平均,为了节省篇幅,接下来的实验我们只给出最终取好平均的Baseline和SSEV值,不再如表2提供各轮迭代的具体数据。
语料规模后面的字母E表示是英语语料,C表示中文语料。

表3 Baseline与SSEV的预测准确率对比表
实验结果(表3)表明SSEV对于不同语种、不同领域、不同规模大小,平衡和非平衡语料都有一定的提高。语料(1)和(2)都是Movie领域,语料(1)初始比例为5%的结果与语料(2)初始比例为1%的结果类似,语料(1)初始比例为10%的结果与语料(2)初始比例为2%的结果类似。我们可以推测SSEV的准确率与初始训练集的规模有关,而与训练集的初始比例无关。语料(4)~(7)在初始比例为1%和2%的情况下(图中的阴影部分)无论Baseline还是SSEV都没有获得较好的预测结果,这和初始训练样本的规模过小有关。

表4 SSEV与基于随机特征子空间的半监督情感分类方法的预测准确率对比表

虽然SSEV在每轮迭代过程中都使用同一个集成分类器,但是随着新的训练集的自动加入,每次都会有部分新的特征取代原有的特征,并且根据TF_IDF算法计算得到的特征权重也在不断地发生着变化,所以每次的训练模型都会发生很大的变化,这也是SSEV之所以奏效的重要原因。
5 结论和下一步工作
情感分类的半监督学习存在很多需要解决的问题,我们不仅需要利用未标记样本提高学习结果的准确率,而且需要关注如何解决大量的未标记样本的计算代价问题。本文提出的基于多分类器投票集成的半监督情感分类方法,不仅利用未标记样本提高了学习结果的准确率,而且同样降低了使用大量未标记样本的计算代价问题,有效地将计算代价降低到了对数时间复杂度,另外本文提出的方法也同时兼顾到了非平衡语料。
考虑到如果有三个分类器,其中一个分类器以90%的置信度给文本标上neg标签,另外两个分类器以30%的置信度给文本标上pos标签,按照我们的方法,通过投票整合后,该文本将会被冠以pos标签,实际上该文本的实际标签很有可能是neg的。我们可以参考Zhou等[25]提出的方法,让每个子分类器根据各自预测的置信度给予有权重的投票,直觉上这样整合出来的结果,可以从待标注测试集中挑选出准确率更高的测试样本,连同它们的标签一起加入训练集,可以减少误标率,从而提高学习结果的准确率。
[1] 来火尧, 刘功申. 基于主题相关性分析的文本倾向性研究[J]. 信息安全与通信保密, 2009, 3: 77-81.
[2] 赵妍妍, 秦兵, 刘挺. 文本情感分析[J]. 软件学报, 2010, 21(8): 1834-1848.
[3] 唐慧丰, 谭松波, 程学旗. 基于监督学习的中文情感分类技术比较研究 [J]. 中文信息学报, 2007, 21(6): 88-94.
[4] 周志华, 王珏. 半监督学习中的协同训练风范[J]. 机器学习及其应用, 北京: 清华大学出版社, 2007: 259-275.
[5] Blum A, Mitchell T. Combining labeled and unlabeled data with co-training[C]//Proceedings of the eleventh annual conference on computational learning theory. ACM, 1998: 92-100.
[6] 苏艳, 居胜峰, 王中卿, 等. 基于随机特征子空间的半监督情感分类方法研究[J]. 中文信息学报, 2012, 26(4): 85-90.
[7] Dietterich T G. Ensemble methods in machine learning[M].Multiple classifier systems. Springer Berlin Heidelberg, 2000: 1-15.
[8] Whitehead M, Yaeger L. Sentiment mining using ensemble classification models[M].Innovations and Advances in Computer Sciences and Engineering. Springer Netherlands, 2010: 509-514.
[9] 李寿山, 黄居仁. 基于 Stacking 组合分类方法的中文情感分类研究[J]. 中文信息学报, 2010, 24(5): 56-61.
[10] Su Y, Zhang Y, Ji D, et al. Ensemble learning for sentiment classification[M]//Chinese Lexical Semantics. Springer Berlin Heidelberg, 2013: 84-93.
[11] Pang B, Lee L, Vaithyanathan S. Thumbs up?: sentiment classification using machine learning techniques[C]//Proceedings of the ACL-02 conference on empirical methods in natural language processing-Volume 10. Association for Computational Linguistics, 2002: 79-86.
[12] Cui H, Mittal V, Datar M. Comparative experiments on sentiment classification for online product reviews[C]//Proceedings of the AAAI. 2006, 6: 1265-1270.
[13] Pang B, Lee L. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts[C]//Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics. Association for Computational Linguistics, 2004: 271.
[14] Breiman L. Bagging predictors[J]. Machine learning, 1996, 24(2): 123-140.
[15] Schapire R E. The strength of weak learnability[J]. Machine learning, 1990, 5(2): 197-227.
[16] Wolpert D H. Stacked generalization[J]. Neural networks, 1992, 5(2): 241-259.
[17] Ho T K. The random subspace method for constructing decision forests[J]. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 1998, 20(8): 832-844.
[18] Wan X. Co-training for cross-lingual sentiment classification[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 1-Volume 1. Association for Computational Linguistics, 2009: 235-243.
[19] Li S, Huang C R, Zhou G, et al. Employing personal/impersonal views in supervised and semi-supervised sentiment classification[C]//Proceedings of the 48th annual meeting of the association for computational linguistics. Association for Computational Linguistics, 2010: 414-423.
[20] 高伟, 王中卿, 李寿山. 基于集成学习的半监督情感分类方法研究[J]. 中文信息学报, 2013, 27(3): 120-126.
[21] http://www.cs.cornell.edu/People/pabo/movie-review-data/
[22] http://ai.stanford.edu/~amaas/data/sentiment/
[23] Blitzer J, Dredze M, Pereira F. Biographies, bollywood, boom-boxes and blenders: Domain adaptation for sentiment classification[C]//Proceedings of the ACL.2007, 7: 440-447.
[24] http://www.searchforum.org.cn/tansongbo/corpus-senti.htm
[25] Zhou Y, Goldman S. Democratic co-learning[C]//Proceedings of the Tools with Artificial Intelligence, 2004. ICTAI 2004. 16th IEEE International Conference on. IEEE, 2004: 594-602.
Semi-supervised Sentiment Classification Based On Ensemble Learning with Voting
HUANG Wei, FAN Lei
(School of Information and Security Engineering, Shanghai Jiaotong University, Shanghai 200240, China)
Recently, sentiment classification has become a hot research topic in natural language processing. In this paper, we focus on semi-supervised approaches for this issue. In contrast to the traditional method based on co-training, this paper presents a semi-supervised sentiment classification via voting based ensemble learning. We construct a set of diversified sub classifiers by choosing different training sets, feature parameters and classification methods. During each voting round, samples with highest confidence are picked out to double the size of training set and then to update the model. This new method also allows sub classifiers to share useful attributes sets. It has a logarithmic time complexity and can be used for non-equilibrium corpus. Experiments show that this method has achieved good results in the sentiment classification task with corpus in different languages, areas, sizes, and both balanced and unbalanced corpus.
sentiment classification;ensemble learning;semi-supervised learning

黄伟(1990—),硕士研究生,主要研究领域为自然语言处理、情感分析。E⁃mail:huangwei.900721@163.com范磊(1975—),副教授,主要研究领域为数据挖掘、网络安全管理、密码学等。E⁃mail:fanlei@sjtu.edu.cn
1003-0077(2016)02-0041-09
2013-11-21 定稿日期: 2014-04-25
TP391
A
猜你喜欢
通信技术(2021年12期)2022-01-25
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
民族古籍研究(2014年0期)2014-10-27
航天返回与遥感(2014年5期)2014-07-31
外语教学理论与实践(2014年2期)2014-06-21
