
融合分词隐层特征的汉语基本块识别
2016-05-04 02:51李国臣刘展鹏王瑞波李济洪
中文信息学报 2016年2期
李国臣, 刘展鹏,王瑞波,李济洪
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 太原工业学院 计算机工程系,山西 太原 030008;3. 山西大学 计算中心,山西 太原 030006)
融合分词隐层特征的汉语基本块识别
李国臣1,2, 刘展鹏1,王瑞波3,李济洪3
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 太原工业学院 计算机工程系,山西 太原 030008;3. 山西大学 计算中心,山西 太原 030006)
该文以字为基本标注单位,构建了一种汉语基本块识别的神经网络学习模型。模型联合分词任务的神经网络学习模型与基本块识别任务模型,将分词任务模型中学习得到的隐层特征融入基本块识别的模型中,两模型相互交替优化学习模型参数,并实现了以整句似然函数(而非单字似然函数)作为优化目标的算法。实验结果表明:1)以整句似然函数为优化目标的基本块识别的F值比单字似然情形要高出1.33%,特别是在多字块识别中,其召回率比单字似然情形要高出4.68%;2)融合分词任务模型中的隐层特征的汉语基本块识别模型的结果比不做融合的模型要高出2.17%,说明融合分词隐层特征的交替联合学习方法是有效的。
分布表征;汉语基本块识别;神经网络模型;隐层特征; 整句似然函数
1 引言
语块分析任务一直是国内外研究的热点,近些年英语方面关于语块分析中比较有影响的工作包括Kudoh等[1]利用支持向量机以93.48%的F值获得了CoNLL 2000英语语块分析评测任务的第一名;Sha等[2]利用条件随机场模型将F值提高到了94.3%;Shen等[3]使用投票分类策略(voting classifier scheme)使得英语语块分析的F值达到了95.23%。
汉语语块分析方面的研究虽然起步较晚,但近几年随着信息处理技术的发展需求,汉语语块分析(也叫浅层句法分析)的研究越来越受到关注。清华大学周强[4]在分层构建汉语树库中对汉语语块分析给出了一套描述体系。汉语基本块是描述体系中的基本概念,其自动识别任务是汉语语块自动分析中的一个基本任务。周强等[5-6]构造了基于规则的汉语基本块分析器,在其测试集上的F值达到了89.47%,在后续研究中又提出一种基本块规则的自动学习和扩展进化的方法;李超等[7]应用最大熵马尔可夫模型获得了CIPS-ParsEval-2009评测任务的第一名,基本块边界识别F值达到了93.196%;侯潇琪等[8]将词的分布式实值表示应用于基本块识别任务中,比使用传统的词特征表示方法的标记精度提高了1.86%。
上述方法中的绝大部分都需要抽取词和词性等特征,因此实际应用中往往依赖词性标注系统、分词系统的性能。李国臣等[9]给出了一种以字为标注单位,以字为原始输入层,来构建汉语的基本块识别的深层神经网络模型,并通过无监督方法,学习到字的C&W和word2vec两种分布表征,将其作为深层神经网络模型字表示层的初始输入参数来强化模型参数的训练。实验结果表明,使用五层神经网络模型的F值比基于字的CRF高出约5%。这种方法仅抽取语料中的汉字作为特征,避免了对分词及词性标注结果的依赖,但总的识别性能不高,特别是对多字块、多词块的识别精度不高。
由于以字为标注单位的方法增大了基本块识别的难度,因此我们借鉴了Collobert等人[10]文章提出的以整句似然函数代替单字似然函数作为似然函数的方法,由于整句似然函数考虑到了相邻标记间的转移概率,因此对于多字块、多词块等较长语块的识别应该会好于单字似然函数。此外我们希望能在以汉字分布表征作为输入的神经网络模型中,融合分词任务模型中的隐层特性以改善基本块的识别性能。为此本文提出一种联合分词任务与基本块识别任务的神经网络模型,两个任务共享同一个汉字分布表征参数矩阵并共同对该参数矩阵进行更新,将分词模型的隐层特征与基本块识别模型的字特征共同作为基本块识别模型的输入层,两模型相互交替优化学习模型参数,并实现了以整个句子似然函数(而非单个字似然函数)作为优化目标的算法。
本文首先设计实验对比了单字似然函数与整句似然函数的差别,实验结果表明,整句似然函数下基本块的识别结果好于单字似然的结果,特别是对多字块、多词块的识别的召回率要好于单字似然函数。在分词任务与基本块识别任务联合模型的性能调优时,本文设计了多种配置下的实验,联合模型中最终结果的F值提高了2.17%。
本文第二节主要介绍了联合模型的实现细节;第三节对实验设置、语料数据以及评价指标等做了阐述;第四节给出了实验结果,并对结果做了分析;最后是对本文工作的总结和对未来研究工作的展望。
2 基于字分布表征的联合分词任务的汉语基本块识别模型
2.1 基本块识别任务描述
汉语基本块识别任务是给定一个句子,准确识别出该句子中全部基本块的左右边界,以确定每个基本块的正确位置。为正确识别出每个基本块的边界,通过“IOBES”标记策略将基本块识别任务转换成基于“B、I、E、S、O”五种标记的序列标注问题。假设句子S由n个字构成,即S={x1x2…xn},则句子中每个字xi对应一个分割标记yi∈{B,I,E,S,O},yi=B表示xi为块首字,yi=I表示xi为块内字,yi=E表示xi为块尾字,yi=S表示xi为单字块,yi=O表示xi为块外字。基本块识别任务可以表示为,给定句子S={x1x2…xn},找出其最优的分割标记序列Y={y1y2…yn}。
2.2 基于字分布表征的神经网络的汉语基本块识别模型
李国臣等[8]的文章中提到,以字为标注单位的方法,应用深层神经网络模型比应用传统的机器学习模型(如最大熵、条件随机场等)在基本块识别任务中性能更佳。本文参照李国臣等的方法构造了基于字分布表征神经网络的汉语基本块识别模型的结构(下文称基本块模型), 如图1所示。

图1 基于字分布表征的神经网络的汉语基本块识别模型
模型结构包含表示向量提取层、隐藏层与输出层三层。表征向量提取层的作用是将字特征通过字的分布表征矩阵转化为特征表示向量,图中所示的是开3窗口的字特征转化为表示向量的过程。首先本层中应有一个大小为m*n的参数矩阵,称为字分布表征矩阵,其中m为每个字的分布表征向量的维度,n表示字表的长度,则矩阵中每一列都可以表示字表中的一个具体的字。设{W1,W2,W3}为某标记单位对应的开3窗口特征三元组,{W1_INDEX,W2_INDEX,W3_INDEX}为此三元组在字表中对应的位置索引,我们将字的位置索引作为本层的输入,并通过索引值找到每个字在分布表征矩阵中对应的列向量,然后将这些列向量拉直形成特征表示向量。
隐藏层的输入为上一层的输出向量,设F为本层输入向量,W为本层的权重参数矩阵,b为本层的偏移项,则线性计算过程可表示为:Linear(F)=W×F+b。我们选择ReLu函数[11]作为隐藏层的激活函数,设x为线性计算输出结果的任一神经元,ReLu函数形式如式(1)所示。

(1)
从公式(1)中可以看出,ReLu函数形式很简单,但是优点却很明显:首先,由于函数大于0的部分梯度为1,可以使下层的梯度完整传递到上层从而避免梯度消失问题(gradient vanishing problem),训练深层神经网络模型时可以不依靠预训练;其次,强行剔除了小于0的神经元,使模型具备了一定的稀疏性。因此,ReLu在深层神经网络研究领域得到广泛应用[12-13]。
输出层是对上一层的输出的线性计算过程,线性计算的结果即为模型的输出,但要注意的是输出层的输出向量的维度应与对应的标记数量一致,如图所示,以“BMESO”标记策略作为基本块识别的输出标记,则输出层的每个输出值都表示对某个标记的输出概率。
2.3 基于字分布表征的联合分词任务的汉语基本块识别模型
为了将词特征融入到基本块识别模型中,我们分别构造出基于同一表示向量提取层的分词模型与基本块识别模型,并将两者结合在一起构成基于字分布表征的联合分词任务的汉语基本块识别联合模型(下文称联合模型)。对于联合模型的分词部分,直接构造以分布表征向量作为输入的神经网络模型。对于基本块识别部分,则首先要通过分词部分计算出隐藏层的输出向量,将此输出向量与特征表示向量拉直作为基本块识别模型的输入,然后以此输入构造联合模型的基本块识别部分的神经网络模型。图2为基于字分布表征的联合分词任务的汉语基本块识别模型结构图。

图2 基于字分布表征的联合分词任务的汉语基本块识别模型
将分词模型隐藏层的输出作为基本块识别模型的输入是出于如下两点的考虑。首先,隐藏层可以认为是对输入层的一种优化表示,其压缩了特征表示向量的长度同时保留了对目标任务有作用的部分信息;其次,我们还可以认为它是对输出层的一种间接反映,比仅包含分词标记概率的输出层携带更多的词层面信息。因此,将分词隐藏层作为特征融入基本块识别模型中可能增强模型的识别效果。
2.4 似然函数与优化方法
本文采用极大似然估计法作为模型参数的估计方法。似然函数参考Collobert等人[10]文章中提出的单字似然函数与整句似然函数。两种似然函数的区别在于单字似然函数只考虑每个字的输入特征与输出标记间的概率函数,而整句似然函数不仅要考虑每个字输入特征与输出标记间的概率关系,还要考虑同一句子中所有输出标记之间的转移概率,因此,整句似然函数需要一部分额外的参数用来记录标记与标记间的转移概率,并以整个句子的似然最大作为优化目标。因此,整句似然函数情形下,对于较长语块的边界识别性能会好于单字似然函数。本文实验中对汉语基本块识别任务的不同模型,分别采用以上两种似然函数作为优化目标做了对比。
2.5 训练方法
2.5.1 参数优化算法
本文中提到的模型均采用带mini-batch的随机梯度下降(SGD)算法作为参数的优化算法。由于考虑到整句似然函数每次迭代的输入为一整条句子,我们以句子数作为抽取的每批次训练样例的单位。设训练中每批次抽取的训练样例的句子数为m,L1,L2,…,Lm表示每条句子的长度(包含字的个数),则对于字分布表征的参数以及神经网络中每一层的参数,采用公式(2)进行更新。
(2)
对于整句似然函数中的状态转移参数,则用公式(3)更新。
(3)
其中θ表示原始参数,θ′表示更新后的参数,α为学习率,grad(θ)表示同一批次训练样例对参数θ求得的梯度之和,由于求grad(θ)的过程中状态转移参数共计累加m次,其他参数共计累加L1+L2+…+Lm次(对状态转移参数每个句子只有一个梯度,对其他参数句子中每个字都有一个梯度),因此对于不同的参数,我们先以梯度和除以累加次数得到平均梯度,再用于参数更新。
2.5.2 联合模型的交替训练方法
对于联合模型,我们采用两个目标任务交替训练的方法进行训练。假设每批次数据量的大小为m,则包含分词任务与基本块识别任务的交替训练每次迭代都应包含以下步骤:(1)在分词数据中抽取m个数据,通过模型计算分词任务的似然与分词模型涉及到的参数的梯度,根据梯度更新分词任务涉及到的参数;(2)在基本块识别任务数据中抽取m个数据,通过模型计算基本块识别模型的似然与基本块识别任务模型涉及到的参数的梯度,根据梯度更新基本块识别任务涉及到的参数。需要注意的是,由于字分布表征矩阵由两个任务所共享,因此对每个任务的参数进行更新时都需要更新字分布表征矩阵的参数。
本文对分词和基本块识别两个目标任务交替进行训练,而不是预先训练好分词部分的参数,再训练基本块识别部分的参数的原因在于:首先,两个目标任务交替训练,可以防止分词部分的参数对分词任务过于拟合而影响到基本块的识别性能;其次,由于我们模型中共享了字分布表征,交替训练的方法可以使字分布表征的参数不会过于偏向其中某个任务目标而影响整体性能。
3 实验设置
3.1 实验语料
3.1.1 基本块识别语料
本文采用的基本块识别任务的实验语料来自CIPS-ParsEval-2009评测任务[14]中发布的汉语基本块分析语料。我们统计了该语料的部分信息并在表1中展示。

表1 基本块识别语料规模
3.1.2 分词语料
为了验证基于不同的分词语料对实验结果可能带来的影响,我们共选取三组分词语料:一是山西大学构建的山大500万字分词语料中的一部分,称为山大语料;二是Sighan 2005 backoff评测任务中由北京大学标注的分词语料,称为北大语料;为了验证与基本块任务采用相同的语料是否对标注性能有帮助,我们剔除了基本块识别任务语料中的训练数据集中的词性与基本块标记信息,只保留了其中的词语信息,将处理后的基本块语料作为第三组分词语料,称为基本块语料。表2展示了全部分词语料的规模。

表2 分词语料规模
3.2 评价指标
以基本块识别任务的F值作为模型整体性能的评价指标,其计算方法简要概括如下:
设:A=预测结果中完全识别正确的基本块的个数。
B=测试数据集中全部基本块的个数。
C=预测结果中全部基本块的个数。
则:准确率=A/C,召回率=A/B,F值=2*准确率*召回率/(准确率+召回率)。
而模型对单字块和多字块的识别性能则采用其召回率作为评价指标。
4 实验结果和分析
为了方便对比,并且考虑到计算复杂度的问题,本文中实验参数均参照表3设置。

表3 试验参数
4.1 两种似然函数的基本块识别实验结果
为了验证单字似然函数和整句似然函数的性能,实验中将不同似然函数应用于基本块模型(没有联合分词任务的模型)上,并统计了实验结果的准确率、召回率、F值、单字块以及多字块的召回率,见表4。
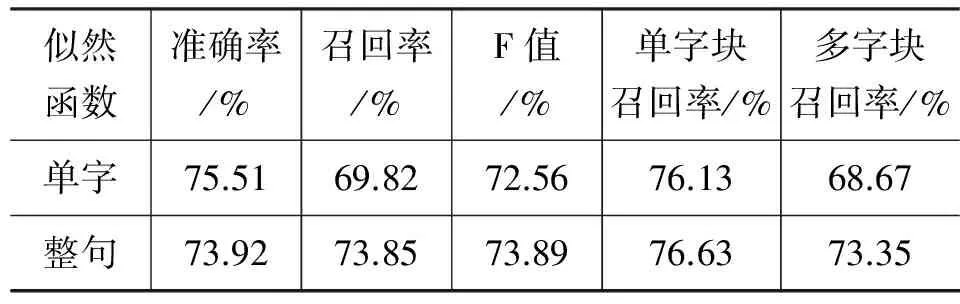
表4 两种似然函数的基本块识别实验结果
实验结果中,整句似然函数比单字似然函数识别结果的F值高约1.34%,在多字块的召回率上,整句似然函数要明显优于单字似然函数,而准确率方面略低于单字似然函数。我们抽取出测试语料具有代表性的一条样例语句并展示了两种不同似然函数对该样例的识别结果,并且以中括号标注了结果中能构成完整基本块的标记序列。
例句 [中国古代][财政][为][“度支”]、[“国用”]、[“岁计”]、[“国计”]。
正确的标记序列应为:[BMME][BE][S][BMME]O[BMME]O[BMME]O[BMME]O
单字似然函数预测结果:[BMMMME]OOMEEOOMMOOOMEOOOBMMOO
整句似然函数预测结果:[BMMMME][S][BME]OO[BMME]O[BMME]O[BMME]O
可以看出,由于单字似然函数不考虑标记间的转移概率,致使预测结果中包含大量的非法序列(不能构成完整基本块的标记序列,如BMMO),而且将大部分的引号标注为块外标记O;而相对的整句似然函数的识别结果中,几乎不存在非法序列,而且对[“度支”]、[“国用”]、[“岁计”]、[“国计”]几个带引号的块也几乎完全识别正确。因此,整句似然函数识别出的基本块数要明显大于单字似然函数,特别是对多字块的召回率都明显高于单字似然函数。单字似然函数由于识别出的基本块数较少,因而准确率要略高于整句似然函数。
4.2 联合模型的实验结果
我们对两个任务目标分别应用不同的似然函数,共设计三组实验,每组实验中的分词部分都使用了上文中提到的三种不同分词语料作为训练语料,表5展示了三组实验的F值。

表5 联合模型实验结果
可以看出三组实验中表现最好的是第二组,即分词任务的似然函数采用单字似然函数,基本块识别任务的似然函数采用整句似然函数。可见整句似然函数在分词部分的表现并不好,考虑到由于分词任务语料中词语的平均长度只有1.6字左右,可见大多数词均为单字词与二字词,整句似然函数对于长语块的识别精度高的优势无法体现。而三种分词语料中,山大语料与北大语料的结果差不多。
4.3 以不同汉字分布表征为初始输入的结果
我们利用基本块模型实验与联合模型实验中表现最好的实验模型,加入由word2vec[15]中包含的Skip-gram算法和CBOW算法训练得到的字的表征向量作为两种模型中字分布表征矩阵的初始值,并将其结果与随机初始值的结果进行对比,其结果展示如表6所示。

表6 加入预训练字分布表征的实验结果
结果表明,使用经Skip-gram算法得到的预训练的字分布表征作为初始输入之后,使总体性能得到一定的提升,经CBOW算法得到的分布表征与随机值作为初始化参数结果差异不大。 最终结果是联合模型的F值(76.06%)比基本块模型(没有联合分词任务的模型)中的F值73.89%提高了2.17%。
5 总结与展望
本文引用单字似然函数与整句似然函数作为极大似然估计的似然函数,分别构造了基于基本块识别任务的基本块模型,以及融合分词隐层特征的基本块识别联合模型,实验证明联合模型的性能比基本块模型有了一定的提升。但由于联合模型结构上比较复杂,且存在训练时间较长,收敛速度慢的缺点。因此,后续研究当从以下几个方面展开:
(1) 改进训练算法,加快收敛速度;
(2) 融入词性标注等其他任务的隐层特征,设计三个以上任务的联合模型;
(3) 进一步测试融入不同任务隐层特征对基本块识别性能的提升效果。
[1] Kudoh T, Matsumoto Y. Use of support vector learning for chunk identification[C]//Proceedings of the 2nd Workshop on Learning Language in Logic and the 4th Conference on Computational Natural Language Learning-Volume 7. Association for Computational Linguistics, 2000: 142-144.
[2] Sha F, Pereira F. Shallow parsing with conditional random fields[C]//Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology-Volume 1. Association for Computational Linguistics, 2003: 134-141.
[3] Shen H, Sarkar A. Voting between multiple data representations for text chunking[M]. Springer Berlin Heidelberg, 2005.
[4] 周强, 任海波, 孙茂松. 分阶段构建汉语树库[C]//第二届中日自然语言处理专家研讨会,2002.
[5] 周强. 基于规则的汉语基本块自动分析器[C]//第七届中文信息处理国际会议.2007.
[6] 周强. 汉语基本块规则的自动学习和扩展进化[J]. 清华大学学报:自然科学版, 2008, 48:88-91.
[7] 李超,孙健,关毅,等. 基于最大熵模型的汉语基本块分析技术研究 [R]CIPS-PaysEval. 2009.
[8] 侯潇琪, 王瑞波, 李济洪. 基于词的分布式实值表示的汉语基本块识别[J]. 中北大学学报:自然科学版, 2013, (5):582-585.
[9] 李国臣,党帅兵,王瑞波,等.基于字的分布表征的汉语基本块识别[J]. 中文信息学报, 2014, 28(6):18-25.
[10] Collobert R, Weston J, Bottou L, et al. Natural language processing (almost) from scratch. [J]. Journal of Machine Learning Research, 2011, 12(1):2493-2537.
[11] Nair V, Hinton G E. Rectified Linear Units Improve Restricted Boltzmann Machines.[C]//Proceedings of the 27th International Conference on Machine Learning (ICML-10). 2010:807-814.
[12] Zeiler, M.D, Ranzato M, Monga R, et al. On rectified linear units for speech processing[C]//Proceedings of Acoustics, Speech, and Signal Processing, 1988. ICASSP-88., 1988 International Conference 2013:3517-3521.
[13] Wu Y, Zhao H, Zhang L. Image Denoising with Rectified Linear Units[C]//Proceedings of Spriner International Publishing,2014:142-149.
[14] 周强,李玉梅.汉语块分析评测任务设计[J]. 中文信息学报,2010, 24(1): 123-129.
[15] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[DB]. arXiv preprint arXiv:1301.3781, 2013.
Chinese Base-Chunk Identification Using Hidden-Layer Feature of Segmentation
LI Guochen1,2, LIU Zhanpeng1, WANG Ruibo3, LI Jihong3
(1. School of Computer and Information Technology, Shanxi University, Taiyuan, Shanxi 030006, China;2. Department of Computer Engineering, Taiyuan Institute of Technology, Taiyuan, Shanxi 030008, China;3. Computer Center of Shanxi University, Taiyuan, Shanxi 030006, China)
Based on the unit of Chinese character, a neural network learning model for Chinese base-chunk identification is constructed. The model combines the neural network learning model of segmentation task with the model of base-chunk identification by using the hidden-layer features of segmentation. The sentence-level likelihood function for base-chunk identification task is employed as the optimization target. The parameters of the two learning model are trained in turn. The experimental results show that: 1) the F-score of base-chunk identification with sentence-level likelihood function is 1.33% higher than that with character-level likelihood function, and especially, the recall for the multi-characters chunk identification is improved as much as 4.68%. 2) The final result of using hidden-layer features of segmentation task is 2.17% higher.
distributed representation; Chinese base-chunk identification; neural network model; hidden-layer features; sentence-level likelihood function

李国臣(1963—),教授,主要研究领域为中文信息处理。E⁃mail:ligc@sxu.edu.cn刘展鹏(1991—),通信作者,硕士,主要研究领域为中文信息处理。E⁃mail:842888676@qq.com王瑞波(1985—),讲师,主要研究领域为中文信息处理。E⁃mail:wangruibo@sxu.edu.cn
1003-0077(2016)02-0012-06
2014-08-19 定稿日期: 2014-10-19
国家自然科学基金(61503228);国家自然科学基金委员会—广东省政府联合基金(第二期)超级计算科学应用研究专项(NSFC 2015—268)
TP391
A
猜你喜欢
通信技术(2021年12期)2022-01-25
校园英语·月末(2021年13期)2021-03-15
邯郸学院学报(2020年2期)2020-08-11
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
——以方正诉宝洁案为例
法制博览(2018年20期)2018-01-22
中华诗词(2016年11期)2016-07-21
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
西南学林(2013年1期)2013-11-22
