
汉语概念复合块的自动分析
2016-05-04 02:50仵永栩吕学强关晓炟
中文信息学报 2016年2期
仵永栩,吕学强,周 强,关晓炟
(1. 北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101;(2. 清华信息科学与技术国家实验室(筹),清华大学信息技术研究院语音与语言技术中心, 北京 100084)
汉语概念复合块的自动分析
仵永栩1,2,吕学强1,周 强2,关晓炟1,2
(1. 北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101;(2. 清华信息科学与技术国家实验室(筹),清华大学信息技术研究院语音与语言技术中心, 北京 100084)
为解决句法分析任务中的块边界识别和块内结构分析问题,该文基于概念复合块描述体系进行了块分析探索。通过概念复合块与以往的基本块和功能块描述体系的对比分析,深入挖掘了概念复合块自动分析的主要难点所在,提出了一种基于“移进-归约”模型的汉语概念复合块自动分析方法。在从清华句法树库TCT中自动提取的概念复合块标注库上,多层次、多角度对概念复合块自动分析性能进行了纵向与横向评估,初步实验结果证明了该分析方法对简单概念复合块分析的有效性,为后续进行更复杂的概念复合块的句法语义分析研究打下了很好的基础。
句法分析;块识别;概念复合块;移进-归约分析
1 引言
块分析是自然语言处理的一个重要技术,是处于词法分析和完全句法分析之间的一个中间步骤。它采取“分而治之”策略,降低句法分析的难度,能够为很多相关语言信息处理提供基础服务。Abney[1]提出了一个完整的语块描述体系。在此基础上CoNLL国际会议在2000年提出块分析共享任务[2],大大促进了块分析技术的研究。2009年第一届汉语句法分析评测学术研讨会(CIPS-ParsEval-2009)也包含了块分析任务[3]。近年来块分析技术逐步受到关注,在语义角色标注[4-5]、机器翻译[6]等领域得到广泛应用。
汉语块研究经历了一个逐步发展的过程,起初侧重于对基本名词[7]、介词短语[8]等的研究。随着语料库的发展,研究者们提出了各自不同的块描述体系,文献[9]将组块定义为围绕一个中心词展开的一种非递归、不重叠、不覆盖的语法结构。文献[10]提出了基于拓扑结构的基本块描述体系,通过成分和关系标记描述组块的外部功能和内部组成。文献[11]定义了不同类型的功能块描述汉语句子的基本骨架。文献[12]定义组块为被标记了句法功能的非递归、非嵌套、不重叠的词序列。这些组块描述体系均注重于把句子解析成较小的单元,只关注句子中相对较简单、功能相对重要的成分。
Abney将句法分析问题分为三个阶段:块识别、块内结构分析、块间关系分析,最终组成完整句法树。现阶段已有的块体系多为线性结构,对块内结构分析已经做了一些工作但关注度仍然较低。文献[10]通过关系标记来确定块的内部结构。目前块处理多数侧重于邻近几个词的组合,块的粒度较小,因此后续的块间关系分析难度依然很大[13]。
本文的研究主要基于汉语概念复合块描述体系*汉语概念复合块标注规范。清华大学信息技术研究院语音和语言技术中心技术报告。。该体系不仅限于处理句子中结构相对简单的较小单元,也着重对跨度较大的成分进行描述,除关注块的边界及其在句子中充当的功能外,也关注块内部的结构以及内部各组成成分之间的关联关系。针对概念复合块特点,我们分析了概念复合块自动处理的难点,并提出一套初步的概念复合块自动分析解决方案。
通过概念复合块的处理,一方面,块的粒度扩大以及包含信息的完整性将为完全句法分析提供更好的帮助;另一方面,将句子分解为“谓词-论元”结构的基本信息单位,为进一步进行汉语句子“谓词-论元”关系分析打下良好的基础。
2 概念复合块简介
简单地说,概念复合块(Concept Compound Chunk, CCC)是由两个或两个以上的词语按照一定的关联关系组合形成的信息描述单位。CCC的自动分析,输入为给定的已经过词语切分和词性标注的句子,目标是自动分析出其中不同实义词和功能词组合形成的概念复合块。CCC的定义与已有的组块描述体系存在很大的区别,以基本块(Base Chunk, BC)[10]及功能块(Functional Chunk, FC)[11]为例,针对以下的原始句子:中国是多民族国家,中华民族是50多个民族的总称。
BC标注形式为:
• [np-SG 中国/nS ] [vp-SG 是/v ] [np-LN 多/a 民族/n 国家/n ] ,/wP [np-ZX 中华/nR 民族/n ] [vp-SG 是/v ] [mp-ZX 50/m 多/m 个/qN ] [np-SG 民族/n ] 的/uJDE [np-SG 总称/n ] 。/wE
FC标注形式为:
• [S中国/nS ] [P 是/vC ] [O 多/a 民族/n 国家/n ] ,/wP [S 中华/nR 民族/n ] [P 是/vC ] [O 50/m 多/m 个/qN 民族/n 的/uJDE 总称/n ] 。/wE
而依照CCC描述体系,该句子将被标注为:
• 中国/nS 是/v [np-AH [np-AH 多/a 民族/n ] 国家/n ] ,/wP [np-AH 中华/nR 民族/n ] 是/v [np-AH [np-CO [np-AH [mp-AH [mbar-XX 50/m 多/m ] 个/qN ] 民族/n ] 的/uJDE ] 总称/n ] 。/wE
每个CCC由成分和关系标记描述其外部句法功能和内部组合关系,为简化描述,采用二叉树结构标注。
以往的组块分析体系往往是线性的,主要关注块边界,典型的如FC体系。BC体系虽然通过关系标记描述块内的基本组合模式,然而BC的处理只针对句子中与实义词紧密组合的内容,并不能覆盖整个句子。CCC标注的最外层块的边界划分与FC类似,将句子切分成可以充当主、谓、宾语的成分,同时对块的内部给出了完整的组织结构。上面例句的拓扑结构如图1所示。
CCC按其内部组成可主要分成以下几个大类:
类别1 多核心CCC:两个核心不分主次。典型结构包括并列、重叠、顺序、复指等,如 “[np-AH [np-CO 自然界/n 的/uJDE ] [np-LH 植物/n [np-FH 、/wD [np-LH 动物/n [np-FH 、/wD 矿物/n ] ] ] ] ]”。
类别2 由功能词控制的单核心CCC(CO,OC):其中的功能词作为控制核心(Operator),直接控制CCC内另一成分,主要由介词、方位词、结构助词、时间词等充当,另一成分作为受该核心控制的补足语(Complement),如“[np-CO 漫长/a 的/uJDE ]”、“[pp-OC 在/p 欧洲/nS ]”等。

图1 CCC标注句子示例
类别3 实义词与附加体组合而成的单核心CCC(HA,AH):语义核心部分(Head)主要为名、动、形容词等实义词,另一成分直接依附于语义核心,成为附加体(Adjunct),如“[np-AH 针灸/n 专著/n ]”、“[vp-HA 产生/v 了/uA ]”等。
类别4 实义词与连词、标点等组合而成的单核心CCC(HF,FH):语义核心部分同类别3,但另一成分与核心并不直接发生依存关系,直接体现出不同的句法功能,作为内部附加功能成分(Functional Constituent),多为连词、标点符号等,如“[np-FH 《/wLB [np-HF 山海经/nR 》/wRB ] ]”。
以上四个类别占总数的92%以上,此外还包括少量的其他组合类型,如嵌套事件句式中的HC(Head-Complement)组合结构等。
3 概念复合块分析难点
为了准确把握对CCC进行自动分析的难点,本文从不同角度对CCC,BC和FC进行了统计分析。统计数据来源为依照CCC描述体系从TCT树库[14]转化得到的CCC标注库以及按照文献[10-11]中描述转化得到的BC和FC标注库,选取其中学术及新闻类的文本,基本统计数据为:文件数185,句子总数16 200,词语总数443 594,平均句子长度为27.38词。在提取的基础上,按照比例从每个类别中抽取一定的文件数,最终抽取样本为40个文件,包含句子2 467,总词数约5万词。对这部分自动提取的正确性进行了人工校对,最终数据表明,程序自动提取的CCC标注库准确率达99%以上。
表 1为几种常见成分类型的CCC和BC平均长度的对比(BC中不包含的类型用"-"表示),BC中包含大量由单个词语构成的块,而CCC并不关注单个词形成块的情况,因此统计中排除BC中的单词块。一般来说组块的长度越大,其本身的正确分析就越困难,组块的词长越小,其本身的正确分析则相对越容易[13]。表 1中可以看出,任何一种成分类型,CCC的组块平均词长均大于BC,而从整体看,CCC的平均长度大于BC的两倍,因此相对而言进行CCC自动分析的难度更大。

表1 不同成分CCC与BC平均词长对比
FC体系注重描述块在句子层面担当的句法功能,主要包括主、谓、宾、状、定语等类型,表 2列出FC中主要类型的长度统计信息(排除单个词形成的FC)。从平均长度上来看,FC与CCC更为接近。CCC长度大于BC和FC,说明CCC的复杂性更大;而FC的长度大于BC,说明FC的分析比BC难度更高,这与前人研究中的理论分析[13]及实践验证[11,15]均一致,体现了上述推断的合理性。

表2 不同类型的FC平均长度
以上为CCC与以往组块体系分析难度的横向对比。从CCC体系本身来看,几个主要类别的平均长度见表 3,主要类别分布于不同区间的比例见表 4,不同长度的分布见图 2。CCC的长度跨度非常大,当长度大于30时,CCC数量相对稀少,为方便观察分布规律,图中仅展示长度不大于30的块分布。从以上统计可看出类别3为CCC中的优势类别,而类别1的平均长度最大,随着长度增加,各个类别的数量逐渐下降。类别2、3、4均在长度2达到峰值,类别1的两个峰值分别为3和5,并且下降趋势更为平缓,类别1在长度较大的区间具有较大的比例(见表4),这是由于类别1中包含大量复杂多核心成分。从平均长度来看类别1>类别4>类别2>类别3,说明了不同类别CCC内部组成具有不同的复杂性,对其进行自动分析的预期难度序列可能为:类别1>类别4>类别2>类别3。

表3 CCC主要类别的平均长度

表4 CCC主要类别长度分布对比

图2 CCC主要类别长度分布
名词性和动词性块在CCC占近80%的比重,是CCC处理的重点,尤其是名词性块,在CCC中比重及平均长度均为最大,是CCC自动分析的重点和难点问题。对CCC中不同类型的np, vp块统计长度分布情况如图 3和图 4所示。可以看出,各个类别的分布规律与在CCC中整体分布大致相同,但在不同的成分类型中分布情况存在着一定的差异。相比np,vp中类别1的比重更多,这些vp中的多核心结构也是自动分析的难点。np中类别3随着长度的增加下降趋势比vp平缓,主要是由于在np中存在一些嵌套的事件句式(Event Construction, EC),以及一部分跨度较大的并列结构等。CCC中比重最大的两个成分中均有相当比例的块长度在6以上,进一步体现了对CCC进行自动分析的难度。

图3 np主要类别的长度分布

图4 vp主要类别的长度分布
CCC的体词性块中有些包含嵌套的事件句式,其中主要为定语部分由动词性成分或小句充当的复杂定语从句结构,它们是CCC自动分析的主要难点之一。考虑到其内部组成规则上与其他CCC类型块存在着较大的区别,且为CCC中的弱势组合,因此本文暂不处理这部分包含EC的CCC。即便如此,CCC自身的复杂度仍然很高,自动分析复杂度远大于之前的组块体系。
4 概念复合块自动分析
CCC的分析工作包括CCC边界界定和CCC的成分和关系标记类型识别。与以往的组块分析不同,CCC分析需给出块内部的完整结构,常见的序列标注模型不能满足CCC分析的需求。与完全句法分析相比,CCC的分析更关注局部语境,确定性更强,因而本文采用“移进-归约(Shift-Reduce, SR)”模型实现CCC分析器(SR CCC Parser),该模型不但更适应CCC的局部语境组合分析特点,且更易于训练,与全局寻优的算法相比,该方法分析速度快,更能适应实际应用的需求。
4.1 移进-归约块分析方法
SR CCC Parser分析的输入为已经分词并带有词性标注的句子,分析过程主要的数据结构为一个栈(S)和一个队列(Q),输入的<词,词性>对按顺序存储于队列中,栈中存放分析过程中每一步产生的部分句法树,对于每一个分析步骤,其状态由当前栈和队列中的内容表示。
本文采用SVM分类器[16]对当前的状态做出动作决策。动作模式主要分为两大类。第一类为“移进(shift)”动作,代表从队列中取出第一个元素并将其压入栈顶;第二类为“归约(reduce)”动作,代表连续出栈两次,将栈顶的两个元素合并为一个新节点,两个元素分别作为新节点的左右孩子,按照归约产生新节点的标记类型,对归约进行分类,例如“reduce: np-AH”,表示两个节点归约为一个右孩子为语义核心的np块。
针对完整句法树的SR分析将持续到栈中元素归约为一个节点且队列为空,此时一个句子分析成功。在块分析中,一个句子的理想分析结果为若干词、CCC的序列,体现在数据结构上是一个森林,因此与完全句法分析不同,CCC分析的停止条件为:队列为空,且分类器不再做出任何归约动作。
分析处理流程如图5所示。

图5 算法流程图
4.2 特征选择
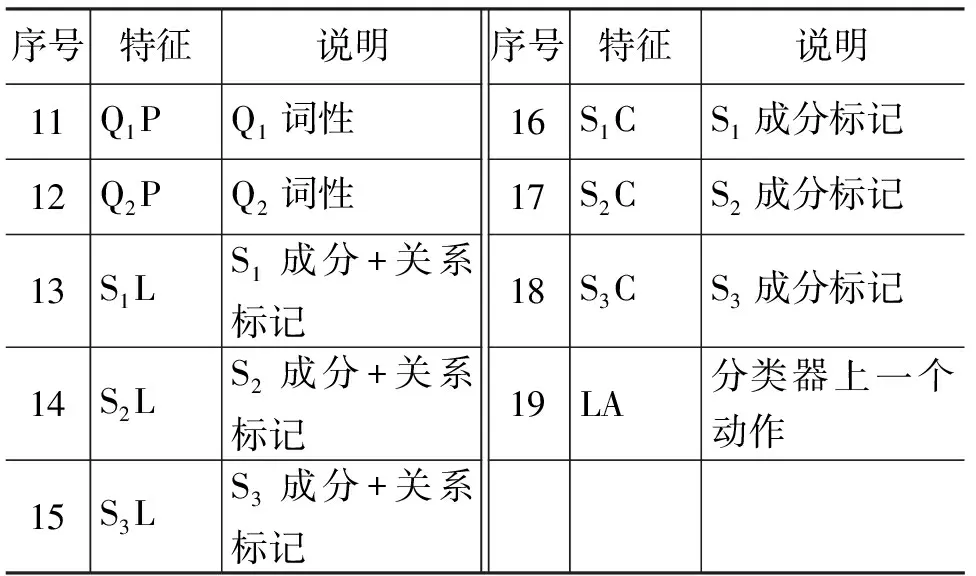
在CCC分析过程中,分类的准确度是影响分析器性能的至关重要的因素。对于CCC分析,将要进行的每一个动作为一个事件,由栈和队列中的节点信息来确定一个事件的特征集合。根据影响当前动作决策的各种因素,可供选择的特征如下:(1) 当前词、词性;(2) CCC双标记;(3) CCC核心词及词性;(4) 动作: 分类器的上一个动作决策;(5) CCC成分。
已有句法分析方法在搜索短语的核心词时,通常采取规则方法,而SR CCC Parser根据CCC关系标记精确搜索任意块的核心词节点,采取自顶向下的递归搜索算法,直到遇到叶子节点返回,即可得到CCC的核心词节点,表 5列出本文对于不同类型CCC的核心词搜索规则。
设Si为S中第i个节点,Qi为Q中第i个节点,最终使用的特征模板如表 6所示。

表5 CCC核心词搜索规则

表6 CCC分析特征模板
续表
5 实验与分析
5.1 实验设置
为全面评测目前CCC自动分析的效果,对本文SR CCC Parser分析结果进行了纵向及横向对比,所用语料选取自TCT中的学术及新闻类的文本,共计185个文件,包含完整汉语句子16 200句,约44万词,不同实验所用的数据分别为由这部分语料产生的不同层次标注库。
(1) CCC Data Set: 根据CCC描述体系自动转换得到的CCC标注库,包含CCC共255 828个*根据第三节的描述,本文所有实验数据集排除了包含嵌套事件句式的名词性概念复合块。,作为SR CCC Parser纵向分析及与Berkeley Parser横向比较的训练及测试语料。
(2) TCT Data Set: TCT原始标注文件,作为验证Berkeley Parser在CCC体系下性能可靠性的训练及测试语料。
(3) BC Data Set: 按照BC定义自动提取形成的BC标注库,由于处理的出发点不同,排除了BC体系中的单词语块,提取BC中与CCC交集的部分,包含BC共82 164个,作为CCC Parser与BC Parser横向比较的训练及测试语料。
(4) FC Data Set: 按照FC定义自动提取形成的FC标注库,排除单个词语形成的FC和包含事件句式的复杂功能块,提取FC中与CCC交集的部分,包含FC共72 465个,作为CCC Parser与FC Parser横向比较的训练及测试语料。
实验采用PARSEVAL[17]评价体系中的准确率(Precision, P)、召回率(Recall, R)作为评价指标,另外计算F1值(F1-measure, F)作为综合评价。令分析结果中正确的块个数为A,测试集中标准的块数量为B,分析结果中的块数量为C,则P=A/C, R=A/B, F=2PR/(P+R)。
5.2 SR CCC Parser纵向性能分析
以CCC Data Set为实验数据集,将语料随机分为三等份,记为PA、PB、PC。采用交叉实验方法分为三组进行验证,首先,第一组实验使用PA与PB为训练集,测试集从PC中随机选取10%;其次,第二组实验使用PA与PC为训练集,测试集从PB中随机选取10%;最后,第三组实验使用PB与PC为训练集,测试集从PA中随机选取10%。三组实验的训练集规模均为10 800句,测试集均为540句。其对应的测试集包含的CCC个数分别为8 034、7 890、7 734个。第一组实验所得SR CCC Parser性能见表7。

表7 不同类别CCC的分析效果
第二组实验所得SR CCC Parser性能见表8。

表8 不同类别CCC的分析效果
第三组实验所得SR CCC Parser性能见表9。

表9 不同类别CCC的分析效果
最终三组实验所得的P、R、F平均值为0.832 3、0.782 1、0.806 4。整体的F值为0.806 4,类别1的分析效果较差,相比其他类别有较大的差距,体现了多核心CCC的复杂性,为下一阶段的研究需要重点关注的问题之一。现阶段SR CCC Parser对类别2、3的处理效果较好,说明这两类CCC中组合规则的一致性较好,作为语义核心及控制核心的词区分度高,因此这两类CCC具有更强的规律性。不同类别CCC的性能表现与第三节的定性分析结论基本一致。不同长度的CCC分析性能见图6。

图6 不同长度的CCC性能
从图中可见,长度为2的块,F值达到了90%,随着块长度的增加,块数量减少,性能曲线出现上下波动,通过趋势线可以看出分析性能呈明显下降趋势,在长度大于30的区间,块数量较为稀疏,性能曲线不连续,故图中不展示30以上长度的性能数据。不同长度的CCC的分析效果,与预期的结果相一致,实验结果中,长度6词以上的CCC自动分析性能较低(低于75%),如何提升这部分CCC的分析性能,是后续研究所要关注的主要方向。
5.3 SR CCC Parser横向性能比较
(1) SR CCC Parser与BC,FC parser对比实验
在BC层面,比较对象为CIPS-ParsEval-2009的基本块分析任务中,开放测试效果最好的基本块自动分析器(Base Chunk Parser, BC Parser)[15],它首先使用最大熵马尔可夫模型(MEMM)识别基本块边界和成分标记,然后进一步使用最大熵模型(MEM)识别基本块关系标记;在FC层面,比较对象为CIPS-ParsEval-2009的功能块分析任务性能最好的功能块自动分析器(Functional Chunk Parser, FC Parser)[18],该方法采用基于CRF的序列标注模型识别FC块。
实验所用语料与SR CCC Parser对应,从BC Data Set及FC Data Set中选取每类前五个文件作为测试集,其余为训练集,测试集包含句子数1 464,BC实验测试文件包含BC个数6 730,FC实验测试文件包含FC个数6 571。在此层面上对SR CCC Parser与BC, FC Parser分析结果进行比较,如表 10,表11所示。
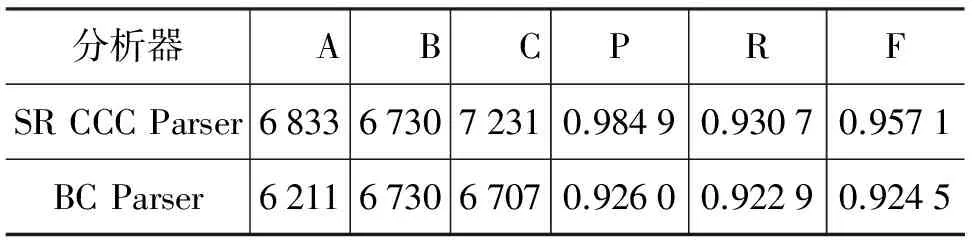
表10 SR CCC Parser与BC Parser性能比较

表11 SR CCC Parser与FC Parser性能比较
在BC层面,SR CCC Parser性能对比BC Parser有着较明显的优势,说明该分析方法对于范围较小、聚合紧密的块体系分析比序列标注模型更加有效。对于FC的分析,SR CCC Parser性能优势并不明显,由于FC块只关注整体的边界划分,而CCC内部具有完整层次结构,任一内部成分的分析错误都有可能导致最上层边界的划分错误,因而分析难度更大。以上实验结果证明,在BC及FC层面,SR CCC Parser方法都是有效的。
(2) SR CCC Parser与Chart-based Chunk Parser对比实验
Berkeley Parser[19-20]是一个基于线图(Chart)的概率上下文无关文法句法分析器,可进行短语结构语法体系下的句法分析,其句法分析性能较好,运行速度快,可支持中文,在ACL*Association for Computational Linguistics: http://www.aclweb.org/,NAACL*The North American Chapter of the Association for Computational Linguistics: http://naacl.org/等主流国际会议论文中广泛被使用,经过多次的版本更新,最新版本为2012年10月更新的1.7版本。CCC标注形式可视为部分句法树,因此可以通过Berkeley Parser进行训练和分析(Berkeley CCC Parser)。Berkeley CCC Parser实验语料同SR CCC Parser实验,所得实验结果如表 12,图7所示。

表12 不同类别上SR CCC Parser与Berkeley CCC Parser性能比较

图7 不同长度的SR CCC Parser与Berkeley CCC Parser性能比较
从实验结果可得,对于类别1和4,Berkeley CCC Parser性能强于SR CCC Parser,说明了Berkeley CCC Parser对较长、较复杂的块分析效果好于SR CCC Parser,但对于CCC中的优势类别2和3,SR CCC Parser的性能更好,由于SR CCC Parser更关注CCC中占比重较大的np、vp块,这两种块的长度集中在区间1到7的范围内,且在长度为2时达到峰。在长度>5时,Berkeley CCC Parser性能强于SR CCC Parser,然而总体效果上SR CCC Parser优于Berkeley CCC Parser。下一步需要进一步改善移进-归约方法,使得对长度较大的CCC分析更加准确。
在CCC Data Set上训练得到的Berkeley Parser的性能低于文献[20]中报告的数值,推测是由于Berkeley Parser处理的关键之一是在学习语法过程中对非终结节点的语法功能进行进一步的分类,例如将作为主语的np成分与作为宾语的np成分加以区别,而在CCC体系中,句子被分解为谓词-论元的基本信息单元,丢失了进行重分类学习的基础标注数据,从而使相关分析器没能达到理想的效果,为验证这一推断,采用TCT Data Set进行了Berkeley Parser训练和测试,并对测试结果中属于CCC层面的相应成分进行性能评价,训练集测试集比例与上述实验相同,所得结果见表 13。可见用完整TCT训练得到的Berkeley Parser,在CCC层次上的性能表现要好于现阶段的SR CCC Parser及Berkeley CCC Parser,验证了上述推断的合理性。

表13 SR CCC Parser, Berkeley CCC Parser及Berkeley TCT Parser在CCC层面对比
6 相关工作评述
前人在汉语组块分析方面,已经有了很多类似的工作,研究者们根据自己的资源及研究目的,分别提出了很多种组块描述体系。针对不同的组块定义,研究者们提出了相应的分析方法。
对组块定义的研究,比较有代表性的有清华大学[4,10-11]、北京大学[13]、微软亚洲研究院[21]及东北大学[22]等,以上组块定义有的无缝覆盖整个句子,如文献[11]将句子划分为基本的主谓宾等功能骨架结构,文献[13]将连词、虚词等归入特殊的组块类型;有的处理特定的短语类型,如文献[4]中将汉语名词短语分成三类,并对最长名词短语的识别进行了深入的研究。它们的共同点在于均为线性结构,侧重于对块边界的界定及句法成分的标注问题。文献[10]通过三种基本拓扑结构描述块内部的组合规则,但其组块描述体系只针对句子中直接相邻的、由实义词与邻接词直接聚合而成的小粒度块,具有一定的局限性。
组块分析方法方面,组块边界的划分常采用BIO及类似标记方式,将组块分析问题视为序列标注问题,用机器学习的方法如条件随机场[12,17-18],隐马尔科夫支持向量机[25],最大熵马尔科夫[15]等,组块类型的确定常采用最大熵[15],支持向量机[26]等分类器。
本文工作与以上的研究相比,具有如下特点:
(1) 通过对句子进行CCC标注,将句子中可作为“谓词-论元”基本信息单元的成分捆绑在一起,将句法分析中“词语→小句”的任务合理分解为“词语→概念复合块→小句”,降低了后续谓词论元关系分析的处理难度。
(2) 区别于常规组块“不嵌套”的原则,CCC描述体系不但注重块边界与句法成分,同样注重块内部的层次结构以及内部词、块之间的关系,通过成分、关系标记与树形结构标注,完整地描述块的各种信息。
(3) 提出“移进-归约”式的CCC自动分析方法,不但对具有层次结构的概念复合块具有较好的分析效果,在内部结构为线性序列的块层面上与前人方法相比也有更优的性能。
7 结论与展望
块分析是介于词法分析和句法分析之间的一个自然语言处理技术。确定适当的粒度,能够对句子中一些基本结构进行分析,为完全句法分析提供帮助。概念复合块不但关注块的边界和外部句法功能,同样注重内部词、块间的关联关系。其目标为将句子处理为基本的谓词-论元信息单元的序列。
本文针对概念复合块特点,提出了一套概念复合块的自动分析方法,不但能准确识别块的边界及句法成分类型,更能对块内部子树结构以及内部组成关系进行完善的分析,对概念复合块的分析性能优于已有的句法分析方法,并且在以往研究的单层次块分析上性能优于传统块分析方法。
本文充分分析了概念复合块自动分析的难点所在,并提出了初步的解决方案,对分析性能从多个层次和角度进行了详细的分析。在后续的工作中,可以对复杂名词性成分中包含变形事件句式的结构及进行深度的剖析,对包含多个核心动词的动词性块以及长度大于6的各种块结构进一步研究合适的处理方法,并不断完善理论体系。从语法知识表示和分析方法两方面作为切入点,不断提高自动分析的性能,为后续深层次的研究工作提供更有利的帮助。
致谢
本文主要工作是论文第一作者在清华大学信息技术研究院语音与语言技术中心访问时完成的,期间使用了清华句法树库(TCT)及其从中自动提取出的概念复合块、基本块和功能块标注库,在此一并表示感谢。
[1] Abney S P. Parsing by chunks[M]. Springer Netherlands, 1992.
[2] Tjong Kim Sang E F, Buchholz S. Introduction to the CoNLL-2000 shared task: Chunking[C]//Proceedings of the 2nd Workshop on Learning language in Logic and the 4th Conference on Computational Natural Language Learning-Volume 7. Association for Computational Linguistics, 2000: 127-132.
[3] 周强, 李玉梅. CIPS-ParsEval-2009评测报告[C]//第一届汉语句法分析评测学术研讨会论文集(CIPS-ParsEval-2009),北京,2009
[4] 王鑫, 孙薇薇, 穗志方. 基于浅层句法分析的中文语义角色标注研究[J]. 中文信息学报, 2011, 25(1): 116-122.
[5] 丁伟伟, 常宝宝. 基于语义组块分析的汉语语义角色标注[J]. 中文信息学报, 2009, 23(5): 53-61.
[6] 李沐, 吕学强, 姚天顺. 一种基于 E-Chunk 的机器翻译模型[J]. Journal of Software, 2002, 13(4): 669-676.
[7] 周强, 孙茂松, 黄昌宁. 汉语最长名词短语的自动识别[J]. 软件学报, 2000, 11(2): 195-201.
[8] 王立霞, 孙宏林. 现代汉语介词短语边界识别研究[J]. 中文信息学报, 2005, 19(3): 80-86.
[9] 李素建, 刘群, 白硕. 统计和规则相结合的汉语组块分析[J]. 计算机研究与发展, 2002, 39(4): 385-391.
[10] 周强. 汉语基本块描述体系[J]. 中文信息学报, 2007, 21(3): 21-27.
[11] 周强, 赵颖泽. 汉语功能块自动分析[J]. 中文信息学报, 2007, 21(5): 18-24.
[12] 孙广路.基于条件随机域和语义类的中文组块分析方法[J].哈尔滨工业大学学报,2011,43(7): 135-139.
[13] 李素建, 刘群, 孙茂松. 汉语组块的定义和获取[C]//语言计算与基于内容的文本处理——全国计算语言学联合学术会议 (SWCL2003) 论文集. 北京: 清华大学出版社. 2003: 110-115.
[14] 周强.汉语句法树库标注体系[J].中文信息学报,2004,18(4):1-8.
[15] 李超等.基于最大熵模型的汉语基本块分析技术研究[C]//第一届汉语句法分析评测学术研讨会论文集(CIPS-ParsEval-2009),北京,2009.
[16] Chang C C, Lin C J. LIBSVM: a library for support vector machines[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2011, 2(3): 27.
[17] Abney S, Flickenger S, Gdaniec C, et al. Procedure for quantitatively comparing the syntactic coverage of English grammars[C]//Proceedings of the Workshop on Speech and Natural Language. Association for Computational Linguistics, 1991: 306-311.
[18] 王昕, 王金勇, 刘春阳等. 基于CRF的汉语语块分析和事件描述小句识别[C]//第一届汉语句法分析评测学术研讨会论文集(CIPS-ParsEval-2009),北京,2009.
[19] Petrov S, Barrett L, Thibaux R, et al. Learning accurate, compact, and interpretable tree annotation[C]//Proceedings of the 21st International Conference on Computational Linguistics and the 44th Annual meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2006: 433-440.
[20] Petrov S, Klein D. Improved Inference for Unlexicalized Parsing[C]//Proceedings of HLT-NAACL. 2007: 404-411.
[21] Li H, Huang C N, Gao J, et al. Chinese chunking with another type of spec[C]//Proceedings of The Third SIGHAN Workshop on Chinese Language Processing. 2004: 24-26.
[22] 李珩, 谭咏梅, 朱靖波, 等. 汉语组块识别[J]. 东北大学学报 (自然科学版), 2004, 25(2): 114-117.
[23] 周俊生,戴新宇,陈家骏等 基于大间隔方法的汉语组块分析[J]. 软件学报,2009,20(4) : 870-877.
[24] 周俏丽, 刘新, 郎文静, 等. 基于分治策略的组块分析[J]. 中文信息学报, 2012, 26(5): 120-128.
[25] 王仲华, 卢娇丽, 付继宗. 基于 HMSVM 模型的中文浅层句法分析[J]. 电脑开发与应用, 2013, 26(2): 30-32.
[26] 孔令鹏, 张琛, 张权. 基于 SVM 的快速中文组块分析方法[J]. 现代电子技术, 2012, 35(21): 93-96.
Automatic Parsing of Chinese Concept Compound Chunk
WU Yongxu1,2, LV Xueqiang1, ZHOU Qiang2,GUAN Xiaoda1,2
(1. Beijing Key Laboratory of Internet Culture and Digital Dissemination Research,Beijing Information Science and Technology University, Beijing 100101, China;(2. Tsinghua National Laboratory for Information Science and Technology(TNList), Center for Speech and Language Technologies, Research Institute of Information Technology, Tsinghua University, Beijing 100084, China)
In order to solve the problems of chunk boundary identification and intra-chunk structure analysis, this paper explores a new chunk parsing task based on the Chinese concept compound chunk (CCC) scheme. After making detailed comparisons with previous base chunk and functional chunk schemes, the main parsing difficulties for CCC chunking are revealed. Therefore, the paper proposes a CCC parsing method based on the “shift-reduce” model. The experiments on the CCC bank automatically extracted from Tsinghua Chinese Treebank (TCT) show the feasibility of the method for parsing some simple CCCs, which facilitates further syntactic and semantic parsing on complex CCCs.
syntactic parsing; chunk recognition; concept compound chunk; shift-reduce parsing

仵永栩(1989—),硕士研究生,主要研究领域为自然语言处理。E⁃mail:372281543@qq.com吕学强(1970—),博士,教授,主要研究领域为中文与多媒体信息处理。E⁃mail:lvxueqiang@aliyun.com周强(1967—),博士,研究员,主要研究领域为自然语言理解。E⁃mail:zq⁃lxd@mail.tsinghua.edu.cn
1003-0077(2016)02-0001-11
2013-11-18 定稿日期: 2015-03-10
国家重点基础研究发展计划资助项目(2013CB329304);国家自然科学基金(61373075,61271304);北京市教委科技发展计划重点项目暨北京市自然科学基金B类重点项目(KZ201311232037); 北京市优秀人才培养资助青年骨干项目(2014000020124G099)
TP391
A
猜你喜欢
小学生学习指导(低年级)(2020年10期)2020-11-26
数学小灵通(1-2年级)(2020年9期)2020-10-27
中学课程辅导·教师通讯(2020年22期)2020-02-04
中文信息学报(2019年12期)2019-12-30
民族古籍研究(2018年1期)2018-05-21
作文大王·低年级(2017年11期)2017-12-05
学苑创造·A版(2017年1期)2017-01-19
西夏学(2016年2期)2016-10-26
中国海上油气(2016年1期)2016-06-09
浙江大学学报(工学版)(2015年1期)2015-03-01
