
社交网络用户标签预测研究
2016-05-04 02:52:52邢千里刘奕群马少平
中文信息学报 2016年2期
刘 列,邢千里,刘奕群,张 敏,马少平
(清华大学 智能技术与系统国家重点实验室,清华信息科学与技术国家实验室(筹),清华大学 计算机系,北京 100084)
社交网络用户标签预测研究
刘 列,邢千里,刘奕群,张 敏,马少平
(清华大学 智能技术与系统国家重点实验室,清华信息科学与技术国家实验室(筹),清华大学 计算机系,北京 100084)
随着社交网站的流行以及用户的大规模增加,社交网络用户行为分析已经成为社交网站进行网站维护、性能优化和系统升级的重要基础,也是网络知识挖掘和信息检索的重要研究领域。为了更好地理解社交网络用户添加个人标签的行为特征,该文基于大约263万个微博用户的真实数据,对用户标签的分布进行了研究和分析。我们主要考察了用户标签的宏观分布特征,以及用户标签与关注对象的标签分布之间的联系,发现微博用户给自己添加标签时,在开始阶段倾向于使用反映个性的标签,之后会出于从众心理而选用大众化标签。我们将研究发现运用到基于关注关系的标签预测算法中,结果证实相关分析对于社交网站的标签推荐等课题具有一定的参考意义。
社交网络;用户行为分析;标签预测
1 引言
近几年,国内外互联网上逐渐兴起一大批社交网站,在国外以Twitter、Facebook为代表,在国内则以新浪微博、腾讯微博、人人网等为代表,随着用户规模的不断扩大,这些网站逐步成为众多网民获取信息、发表意见、制造舆论的主要途径。以微博为例,据最新CNNIC统计报告显示[1],截至2012年12月底,中国微博用户规模达3.09亿,较2011年底增长5 873万,增幅达到23.5%,网民中的微博用户比例由2011年底的48.7%增长到2012年底的54.7%。微博已经成为了中国网民使用的主流应用,庞大的用户规模进一步巩固了其网络舆论传播中心的地位。
如何为用户提供优质的服务,帮助用户及时高效地获取所需信息,最大规模地吸引用户群,一直是社交网站所关注的重点。用户行为分析是了解用户行为习惯和使用意图的主要方法之一。社交网站提供的服务多种多样,导致用户行为的种类也具有多样性,常见的用户行为包括发布原创信息、转发、评论、添加标签等,这也进一步导致了用户信息的复杂多样。针对其中一种或多种信息进行分析,均可以挖掘出许多有价值的发现,而本文则主要着眼于对用户添加个人标签的行为特征进行分析。个人标签是用户根据自身情况对自己标注的文本内容,可以反映用户的身份、特长、爱好、专业领域等信息,多为字数较少的词或者短语。研究用户标签的分布特征,可以为社交网站的标签推荐、专家搜索、用户分类等应用提供一定参考。
本文通过对大约263万个微博用户的信息进行分析,主要研究两个方面的特征:一是用户标签分布的宏观特征;二是用户标签与其关注对象的标签分布之间的联系。与以往工作不同的是,我们在分析过程中,重点考察了用户标签列表不同位置上的标签分布情况。通过分析,我们希望能够了解用户添加个人标签的行为特点,为社交网站相关应用的算法优化提供一定依据和方向。
以下内容首先介绍了本研究课题的相关工作;然后介绍了新浪微博的个人标签功能和本研究使用的数据集;接着,从两个方面对用户标签的分布进行特征分析;再尝试将相关发现运用到基于关注关系的标签预测算法中;最后给出工作总结和启示。
2 相关研究工作概述
近几年,对于社交网络的相关研究一直是国内外信息检索领域的热门课题。国外学者在做相关研究时大多以Twitter作为研究对象,而国内学者则比较喜欢用新浪微博作为研究对象。尽管Twitter和新浪微博在功能上有很多相似之处,但也存在一些差异,比如Twitter提供了话题标签功能,却没有提供个人标签功能,而新浪微博则同时向用户提供了话题标签和个人标签功能。这也导致在标签预测方面的研究主要是针对文档标签或者资源标签[2-3],针对用户标签的研究则相对较少。
许多关于社交网络的研究是通过建立反映用户兴趣的描述文档,对用户进行个性化的内容推荐或好友推荐,因此,如何建立准确的描述文档对于个性化服务的质量有着重要的影响。一般建立用户文档的方法是从用户发布的内容中提取关键词,如Weng[4]等人在TwitterRank中使用的topic model,或者根据他人对某个用户的描述建立关键词列表,如Ghosh[5]等人使用Twitter的list功能建立专家搜索系统。这些方法都是从侧面建立用户描述,并没有使用用户对自己的描述信息,导致结果会出现一定偏差。而新浪微博提供的个人标签功能可以看做是用户感兴趣话题的直接反映,因此研究用户的个人标签对于建立更准确的用户描述有重要意义。2011年,陈渊[6]等人针对微博用户提出了一种标签推荐方法,他们根据用户的关注人数、粉丝人数和发布的微博数对用户群体进行分类,针对不同群体分别使用关注对象的标签集合、粉丝的标签集合或从微博中提取的关键词等作为标签推荐的依据。他们针对个别用户进行了实验,结果表明这种方法具有一定的效果。与以往工作不同的是,本文主要分析了用户添加个人标签的行为特征,特别是针对不同位置的标签分布进行分析,相关发现可以为进一步的标签预测、专家寻找、用户分类等研究提供一定的参考依据。
3 分析数据介绍
本研究使用的用户数据集是在2011年9月至2012年5月之间抓取的2 631 061个新浪微博用户信息,包含用户的ID、个人标签、关注关系等。新浪微博虽然为用户提供了添加个人标签的功能,但限制每个标签最多包含七个中文字符,且每个用户最多只能添加十个个人标签。比如创新工场CEO李开复先生(微博地址: http://weibo.com/kaifulee)为自己添加的十个标签是“风险投资”、“微博控”、“创新工场”、“教育”、“科技”、“电子商务”、“移动互联网”、“创业”、“IT互联网”、“世界因你不同”。
图1展示了数据集中拥有不同数量标签的用户所占比例。
由图1可以看到,大约40%的用户给自己添加了至少一个标签。而在有标签的用户集合中,有一至九个标签的用户数目分布比较平均,而有十个标签的用户则相对较多,占有标签用户的20%左右。可以猜测,一个用户在填写或者修改个人标签信息时,如果看到了新浪微博提示的“最多十个标签”,便会不自觉地给自己添加满十个标签,使有限的“资源”得到充分利用。
基于上述数据集合,我们可以从多种角度对微博用户的标签分布进行深入的分析和研究,考察社交网络用户添加个人标签的行为特征。注意,为了避免英文字母的大小写影响分析结果,我们在分析之前将数据集中的英文字母统一做了小写处理。
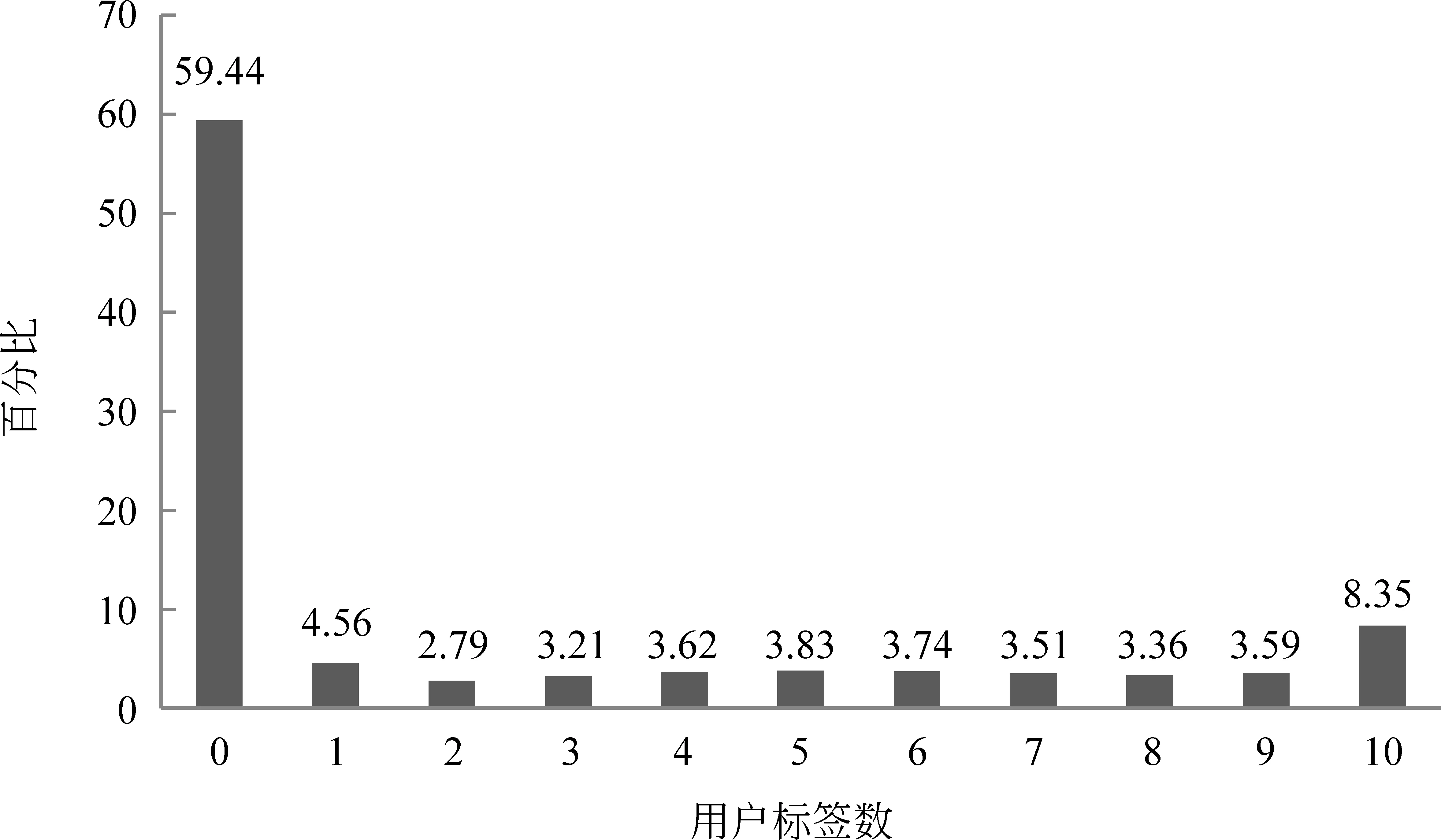
图1 拥有不同数量标签的用户所占比例
4 用户添加个人标签的行为分析
4.1 用户标签的宏观分布分析
由于微博用户在添加个人标签时,除了字数限制外,在内容上并没有严格的限制,所以不同用户添加的标签在内容上可能会多种多样。同时,有一些标签可能会出现在许多用户的标签列表中,被大量用户共享。我们首先从以下几个角度分析用户标签分布的宏观特征。
4.1.1 不同标签的标签数分布
经过统计,数据集中的所有用户共有标签 6 395 232个,平均每个用户有2.43个标签。除去重复的标签,数据集中共包含900 119种不同的标签。这些不同的标签在数据集中出现的次数差异很大,比如出现次数最多的标签“音乐”共出现了195 542次,而仅出现一次的标签则有698 275种,占所有不同种类标签的77.58%。图2显示了不同种类标签出现次数的分布。
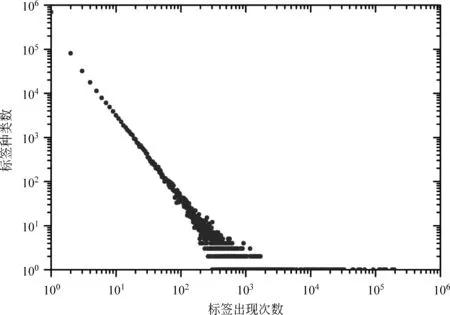
图2 用户标签出现次数分布
由图2可以看出,除去一些出现次数较多的标签,大多数标签出现的次数与标签种类数呈指数分布关系。绝大部分标签出现次数很少,我们将这些标签视为少数用户特有的“个性标签”,例如,有96.23%的标签仅出现了十次或十次以下;另一小部分标签在数据集中则大量出现,被许多用户共享,我们将这些标签视为“大众标签”。表1给出了在数据集中出现次数最多的十种大众标签,及它们的出现次数在所有标签总数中所占的比例。
由表1可以看到,大众标签大多是大家普遍关注的话题,比如电影、美食等,而且多与娱乐、休闲有关。仅前十种大众标签就占了所有标签的20%左右,可见其出现次数之多。

表1 出现次数最多的10种标签
4.1.2 不同位置的标签熵
我们在研究过程中发现,用户标签列表不同位置上的标签分布是不同的,而且存在一定规律性。为了观察用户标签列表的不同位置上标签的分布差异,我们将有标签的用户按照标签数(1至10个)进行分类,计算了每一类用户在不同位置上的标签熵。计算公式如式(1)所示。
(1)
其中,假设一个集合中共有n个不同的标签,pi代表第i个标签在该集合中出现的频率。
图3显示了在数据集上求标签熵的结果。图中每条曲线代表拥有特定标签数的一类用户,横轴代表标签在用户标签列表中所处的位置。

图3 标签列表中不同位置的标签熵
观察图3中的每一条曲线可以看到,对于每一类用户而言,随着标签位置由前至后,标签熵呈现明显递减的趋势。这说明在用户标签列表中,靠前的位置标签的分布比靠后的位置更加离散。而比较图2中不同曲线的高低可以看到,对于同一标签位置而言,基本上标签数越多的用户群对应的标签熵越高。说明标签数越多的用户群在某一位置上的标签分布相对离散,而标签数少的用户在同一位置上的标签分布则相对集中。猜测其原因,可能是用户标签列表中位置靠前的标签包含更多反映用户特点或者个性的标签,而靠后的标签则包含更多大众化的标签,进一步猜想,用户在添加个人标签时,在开始阶段会倾向于添加个性标签,而之后则会出于从众心理添加大众化的标签。为了更好地证实这一猜想,下面一节我们将举例统计大众标签在用户标签列表不同位置所占的比例。
4.1.3 不同位置的大众标签比例
我们以表1中的大众标签为例,统计了在标签列表的不同位置上,排名前几位的标签出现次数在该位置所有标签个数中所占的比例之和,结果如图4所示。图中sum3、sum5、sum10分别代表在表1中排名前三、前五、前十的标签所占的比例之和。
观察图4可以看出,在标签列表越靠后的位置,大众标签在数量上所占的比例越大, 而且基本呈现随位置线性增长的趋势。这也符合之前的猜想,即用户在给自己添加标签时,在添加完反映个性的标签后,会倾向于使用大众化的标签填充自己标签列表。
4.2 用户标签与其关注对象的标签分布之间的关系分析

图4 若干流行标签(如表1所示)在不同位置的分布情况
上面我们分析了用户标签宏观分布的一些特征,下面我们通过分析用户标签与其关注对象的标签分布之间的关系,进一步考察用户添加个人标签的行为特征。
4.2.1 用户标签在其关注对象的标签集合中出现的情况
新浪微博作为一个社交平台, 其最大的特色就是用户可以自由地关注感兴趣的其他用户,并随时浏览关注对象发布的微博。因此关注关系在一定程度上说明了用户之间的相似性,而这种相似性也可能体现在用户标签上。我们对拥有不同标签数的用户群分别统计了平均每个用户有多少比例的标签会出现在其关注对象的标签集合中,作为对比,我们对每个用户随机选取了和其关注对象个数相等的若干非关注对象,并做了相同的统计。图5显示了统计结果。
从图5中可以看出,无论一个用户的标签数是多少,基本上其将近一半的个人标签会出现在关注对象的标签集合中,对其标签与非关注对象的标签的重复度仅为30%左右,这反映了具有关注关系的用户在兴趣、专业等方面存在一定的相似性。
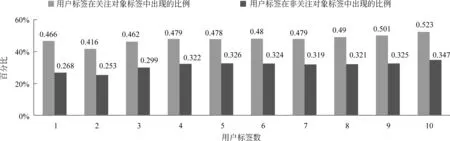
图5 用户标签在其关注对象和非关注对象的标签中出现的平均比例
4.2.2 不同位置的标签在用户关注对象的标签集合中出现的情况
为了进一步考察用户标签和关注对象的标签分布之间的关系,我们对拥有特定标签数(1—10个)的用户群,分别统计了在标签列表不同位置上的标签出现在其关注对象标签集合中的平均比例和平均次数,结果如图6和图7所示。图中每条曲线代表拥有特定标签数的一类用户,横轴代表标签在用户标签列表中所处的位置。
观察图6和图7可以看出,对于一个用户而言,他的标签列表中位置越靠后的标签,在其关注对象的标签集合中出现的可能性越大,而且出现的平均次数也比位置靠前的标签多。还可以观察到,图6和图7中的曲线基本都呈现出近似的线性上升趋势。结合4.1.3的分析,某一位置的大众标签所占比例会随着位置由前至后近似线性增加,而相对于个性标签,大众标签更可能被有关注关系的用户共享,这也就导致了上述两幅图中的曲线呈现出近似线性上升的趋势。这一结果进一步说明了用户在添加个人标签时,会倾向于先添加个性标签,而越往后则越倾向于使用大众标签。
5 基于关注关系的标签预测
为了更好地观察上述发现对于社交网络用户的标签预测等工作的参考意义,本文提出了一种基于关注关系的标签预测算法,并通过比较说明上述发现的应用价值。
5.1 基于关注关系的标签预测算法
算法的基本思想是使用微博用户所有关注对象的标签集合作为依据对用户做标签预测,同时将用户标签列表不同位置的标签分布特征考虑进预测过程。
具体而言,假设用户A关注了n个用户B1、B2、……、Bn。其中,用户Bi有m个标签,按照在Bi标签列表中的先后顺序依次记为Ti,1、Ti,2、……、Ti,m,m的取值范围是1~10。对标签Ti,j按照式(2)赋予权重:
(2)
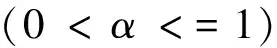
其中,α为可变系数。按照式(2),Bi的标签所得到的权重会随着位置由前至后线性增加,而Bi的所有标签获得的权重之和正好等于Bi的标签个数m。
将A所有关注对象的标签集合中相同标签获得的权重累加,并根据最终得到的标签权重对用户A所有关注对象的标签按权重由高到低进行排序,取权重较高的若干标签作为预测结果。
5.2 三种作为对照的标签预测算法
• 对照算法一:在5.1算法的基础上使用权重如式(3)所示。
(3)
• 对照算法二:在5.1算法的基础上使用权重如式(4)所示。
(4)
• 对照算法三:将在全体数据集中出现次数最多的若干大众标签按照出现次数由多到少排序,作为预测结果。
其中,前两种对照算法是在5.1算法的基础上改变权重公式得到的。按照式(3),Bi的所有标签会得到相同的权重1;按照式(4),Bi的标签所得到的权重会随着位置由前至后线性减小。两个公式均保证Bi的所有标签获得的权重之和等于m。
5.3 算法预测结果与分析
对于有特定标签数(1~10个)的每一类用户群,我们都从数据集中随机抽取了1万个用户作为测试样本。使用5.1算法和5.2中提到的三种对照算法对测试集中的10万个用户做标签预测,限制最多预测30个标签。
我们将预测结果与用户的原始标签(预测标签属于原始标签集合则视为正确结果)比较,计算了三种方法的MAP值(Mean Average Precision),结果如图8所示(α=0.2,β=1)。图中MAP0、MAP1、MAP2和MAP3分别代表使用5.1算法、对照算法一、对照算法二和对照算法三得到的预测结果的MAP值。图中横轴代表用户的标签数。

图8 具有不同标签数的用户预测结果的MAP
对比图8中MAP0、MAP1、MAP2的值可以看出,使用式(2)得到的预测效果最好,式(3)次之,式(4)最差。MAP0是在MAP1的基础上使用户标签列表中位置靠后的标签获得较高的权重得到的预测结果,结合上文对用户添加标签的行为特征的分析,可以发现MAP0的计算过程会使位置靠后的大众标签获得更高的权重,从而被“正确”地预测出来或者在预测结果的列表中获得更高的排序,因此使用式(2)得到的MAP值要高于使用式(3)得到的结果。而使用式(4)则会使位置靠后的大众标签获得较低的权重,同时位置靠前的个性标签得到较高的权重,因此预测结果的MAP值低于另外两种方法。
但是,整体而言,这三种基于关注关系的预测算法做标签预测的效果均不理想,MAP值都在0.1至0.18之间。对比MAP0和MAP3可以发现,除了对标签数小于3的用户做预测的结果差别较大外,二者基本相同,MAP0略高于MAP3。这说明5.1算法预测出的正确标签大多都是大众标签。
6 结论与启示
本文通过对以新浪微博为代表的社交网络用户数据的分析,研究了用户在社交网络环境下添加个人标签的行为特征,挖掘了用户标签分布的宏观特征、用户标签与其关注对象的标签分布之间的关系等。经过分析,我们发现,在系统限制了标签个数的情况下,大多数用户会倾向于添加标签到不能再添加为止。而在添加标签的过程中,用户在开始阶段一般会添加一些反映个人身份、专业特长、兴趣爱好等信息的个性标签,而在最后则会处于从众心理,选择一些大众化的标签填充自己的标签列表。这导致了用户标签在标签列表不同位置上分布的差异性——位置靠前的标签更可能是个性标签,而位置靠后的标签则更可能是大众标签。我们将此发现运用在一个基本的基于关注关系的标签预测过程中,结果显示这一发现对于提高标签预测的准确率有一定的参考价值。如果要将这一发现运用于社交网络中的专家搜索,可以想象,在设计算法的过程中,应该更加重视用户标签列表中位置靠前的标签,因为这些标签更能反映用户的专业、特长等信息。
研究社交网络用户添加个人标签的行为特征以及用户标签的分布特点,对于社交网络的标签预测、专家用户推荐、用户分类等课题的研究均有一定的参考意义,也能够帮助社交网站改进算法,向用户提供更优质的服务。在今后的工作中,我们将进一步挖掘用户标签的相关信息,并尝试将发现运用到多种实用任务中,为优化社交网络的服务提供更多的参考。
[1] 中国互联网络信息中心.第31次中国互联网发展状况报告[R],2013.
[2] 孙宪策.基于内容的社会标签推荐与分析研究[D].清华大学博士学位论文,2010.
[3] 袁柳,张龙波.基于概率主题模型的标签预测[J].计算机科学,2011,30(7):175-180.
[4] Jianshu Weng, Ee-Peng Lim, Jing Jiang, et al. TwitterRank: finding topic-sensitive influential twitterers [C]//Proceedings of the 3rd ACM international conference on Web search and data mining (WSDM ’10). ACM, New York, NY, USA, 2010: 261-270.
[5] Saptarshi Ghosh, Naveen Sharma, Fabricio Benevenuto, et al. Cognos: crowdsourcing search for topic experts in microblogs [C]//Proceedings of the 35th international ACM SIGIR conference on research and development in information retrieval (SIGIR ’12). ACM, New York, NY, USA, 2012: 575-590.
[6] 陈渊, 林磊, 孙承杰, 等. 一种面向微博用户的标签推荐方法[J].智能计算机与 应用,2011, 1(50): 21-26.
[7] Aditya Pal, Scott Counts. Identifying topical authorities in microblogs[C]//Proceedings of the 4th ACM international conference on Web search and data mining (WSDM ’11). ACM, New York, NY, USA, 2011: 45-54.
[8] Q Vera Liao, Claudia Wagner, Peter Pirolli, et al. Understanding experts’ and novices’ expertise judgment of twitter users[C]//Proceedings of the 30th ACM conference on human factors in computing systems (SIGCHT). 2012: 2461-2464.
[9] Meeyoung Cha, Hamed Haddadi, Fabricio Benevenuto, et al. Measuring user influence in Twitter: The million follwer fallacy [C]//Proceedings of the 4th international AAAI conference on Weblogs and social media. 2010.
[10] I Weber, C Castillo. The demographics of web search [C]//Proceedings of the 33rd international ACM SIGIR conference on reaearch and develpment in information retrieval. 2010, 179: 523-530.
User Behavior Analysis of Person Tags in SNS
LIU Lie, XING Qianli, LIU Yiqun, ZHANG Min, MA Shaoping
(State Key Laboratory of Intelligent Tech. & Sys.,Tsinghua National Laboratory for Information Science and Technology, Department of Computer Science and Technology, Tsinghua University, Beijing 100084, China)
With the popularity of social network sites (SNS) and the massive increase in SNS users, the behavior analysis of SNS users is of substantial importance in website maintenance, performance optimization and system upgrade. It’s also a very important research area of network knowledge mining and information retrieval. For a better understanding of the user behaviors in adding tags for themselves in SNS, this paper analyses the distribution of user tags based on the data of about 2.63 million Weibo users. This paper investigates the macroscopic distribution characteristics of user tags, and the relation of tag distributions between a user and the people he follows. We reveal that when Weibo users add tags for themselves, they tend to use tags which can reflect their characteristics in the beginning, then, they tend to select popular tags out of a herd mentality. We applied research findings to a tag prediction algorithm based on following relationships, and the results prove that the correlation analysis provides certain reference significance to tag recommendation in social networks.
SNS; user behavior analysis; tag prediction

刘列(1991—),本科生。E⁃mail:lieliu213@gmail.com邢千里(1987—),博士研究生,主要研究领域为信息检索。E⁃mail:xingqianli@gmail.com刘奕群(1981—),博士,副教授,主要研究领域为信息检索。E⁃mail:yiqunliu@tsinghua.edu.cn
1003-0077(2016)02-0056-08
2013-09-15 定稿日期: 2014-03-15
TP391
A
猜你喜欢
小学生学习指导(高年级)(2024年4期)2024-05-07 03:28:46
睿士(2023年2期)2023-03-02 02:01:09
小学生学习指导(中年级)(2021年4期)2021-04-27 10:14:56
课堂内外(初中版)(2020年5期)2020-06-19 08:11:11
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
意林(2018年3期)2018-03-02 15:17:24
厦门理工学院学报(2016年1期)2016-12-01 04:50:48
公民与法治(2016年10期)2016-05-17 04:12:58
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:48
