
一种支持混合语言的并行查询纠错方法
2016-05-04 03:11:27熊锦华马宏远程舒杨程学旗
中文信息学报 2016年2期
颛 悦,熊锦华,马宏远,程舒杨,程学旗
(1. 中国科学院 计算技术研究所,北京 100190 2. 中国科学院大学,北京 100190 3. 国家计算机网络应急技术处理协调中心,北京 100029)
一种支持混合语言的并行查询纠错方法
颛 悦1,2,熊锦华1,马宏远3,程舒杨1,程学旗1
(1. 中国科学院 计算技术研究所,北京 100190 2. 中国科学院大学,北京 100190 3. 国家计算机网络应急技术处理协调中心,北京 100029)
中文信息检索系统中的查询语句包含中文字、拼音、英文等多种形式,而有些查询语句过长,不利于纠错处理。现有的查询纠错方法不能很好的解决中文检索系统中的混合语言与中文长查询的问题。为了解决上述两个问题,该文提出了一种支持混合语言的并行纠错方法。该方法通过对混合语言统一编码,建立统一编码语言模型和异构字符词典树,并根据语言特点制定相应的编辑规则对查询词语进行统一处理,其中,针对中文长查询,提出双向并行的纠错模型。为了并行处理查询语句,我们在字符词典树和语言模型的基础上提出了逆向字符词典树和逆向语言模型的概念。模型中使用的训练语料库是从用户查询日志、网页点击日志、网页链接信息等文件中提取的高质量文本。实验表明,与单向查询纠错相比,支持混合语言的并行纠错方法在准确率上提升了9%,召回率降低了3%,在速度上提升了40%左右。
查询纠错;词典树;语言模型;并行纠错
1 引言
查询纠错是针对信息检索系统中查询语句的拼写纠错。据统计,英文搜索引擎的查询中有10%~15%含有拼写错误[1],查询语句直接影响信息检索系统返回结果的可靠性与准确性,所以现有的很多信息检索系统都会对查询语句进行纠错处理,确保返回的检索信息能够满足用户需要,提高用户检索效率和检索结果命中率。
中文信息检索系统中的查询词类型一般有:中文、拼音、英文等形式。中文查询中会出现同音字错误、近音字错误、形近字错误、拼音转汉字、拼音中字母缺失、前后字置换、汉字缺失等现象;英文查询按照错误类型不同,分为非词错误(Non-word Errors)和真词错误(Real-word Errors)[2]。非词错误是指拼写错误的词不存在,例如,将“the”错误拼写为“tha”;真词错误是指那些拼写错误后的词仍然是合法的情况,例如,将“the”错误拼写为“then”。
根据李亚楠、王斌对新浪爱问搜索引擎的查询日志分析[3]可知,不考虑重复查询时,查询的平均字长为8.18;考虑重复查询时,查询的平均字长为6.14;不考虑重复查询时,查询平均词数为4.14,考虑重复查询时,查询的平均词数为3.07;包含三个词的查询最多,占24.055%。此外,对国内某商业搜索引擎的查询日志分析,2012年1月14日查询词(随机抽取1万查询词)的平均字长为8.58(考虑重复查询);2012年5月14日查询词(随机抽取1万查询词)的平均字长为8.19(考虑重复查询)。通过以上分析可知中文搜索引擎的查询词往往很长,而现在的信息检索系统为了减少纠错时间,限定纠错查询语句的长度,对于过长的语句,不进行纠错。我们需要解决信息检索系统中长查询语句的纠错处理问题。
针对以上问题,本文提出一种支持混合语言的并行查询纠错方法,解决中文混合语言和长查询的纠错问题。首先,为了解决混合语言的纠错问题,本文提出一种伪编码的方法,该方法把英文单词和常用字符组合作为独立词进行编码,从而对中文、英文和其他字符组合统一编码;其次,提出并行纠错模型来快速的处理中文长查询语句。并行纠错模型把查询语句长度超过一定阈值M的查询分为两段长度相近的查询语句,然后启动正向查询纠错模块和逆向查询纠错模块分别从正向与逆向并行处理。正向和逆向的查询纠错模块使用制定的编辑规则来处理查询语句。在对语句进行编辑处理的过程中会生成多种候选状态,每个候选状态中会保存候选项和操作代价W等状态信息。最后,根据候选状态的操作代价W给出推荐的查询语句。
本文提出的方法使用了字符词典树和语言模型来分别判定词语本身的信息和词语所在上下文的信息。模型使用的训练语料是从用户查询日志、网页点击日志、网页链接信息等文件中提取的高质量文本。为了逆向处理查询语句,我们在正向字符词典树和正向语言模型的基础上提出了逆向字符词典树和逆向语言模型的概念。根据中文和英文的特点,分别制定了中文处理规则和英文处理规则。实验表明,并行查询纠错模型比单向查询纠错模型快了40%左右,准确率提升9%左右。
本文内容的组织结构如下:第二部分总结相关工作;第三部分介绍面向混合语言的并行查询纠错的方法;第四部分给出实验及结果分析;第五部分进行总结。
2 相关工作
查询纠错主要用于分析用户输入查询中的错误,并在合理的时间范围内返回其正确形式,因此主要考虑响应时间和返回结果的正确性这两个方面。当前中文信息检索系统中主要进行两种类型的查询纠错任务:英文查询纠错和中文查询纠错。
英文查询纠错技术主要分为两种:基于词语的拼写纠错和基于上下文信息的纠错技术。基于词语的拼写纠错注重对单个词拼写错误的纠正,经典的方法有编辑距离方法[4-5]、K-gram重合度方法[6-7]以及基于语音的拼写纠错方法[8];基于上下文信息的纠错的目标不仅包含词典以外的拼写错误的单词,还包含上下文中使用不当的单词,这种方法主要利用语言模型对查询中每个关键词评估,并选出最优的组合形式,其中经典的方法有基于噪声信道模型的查询纠错[9-10]、基于贝叶斯分类器的查询纠错[11]和基于最大熵模型的查询纠错[12-13]。
在英文纠错技术中,编辑距离方法和K-gram重合度方法着重于单个词语的纠错,能够快速的找到与错误单词相似的词典规范词,这两种方法无法处理上下文包含使用不当的正确单词的情况;基于噪声信道模型的纠错、基于贝叶斯分类器的纠错和基于最大熵模型的纠错能够解决这一问题。目前英文纠错技术仅考虑了英文搜索引擎中查询包含的错误,即英文单词的拼写错误、使用不当和空格的缺失等,中文搜索引擎中包含的错误类型更多,语言的形式更复杂,简单的套用上述方法无法达到很好的效果。
现有的中文查询纠错方法多采用将查询词内的中文字转换为拼音,然后查找词典中拼音与该查询词拼音字符串相似或相同的候选词条,最后通过词频或语言模型的方式决定候选词条是否为纠错结果。
周博等人在专利中对如何纠正中文搜索引擎中的英文查询提出了一种解决方法[14]。该专利的做法是,通过词典来判断查询是否包含错误的英文单词: 以空格作为英文单词的分隔符,将查询分割为单词,并在一定编辑距离范围内搜索每个单词的混淆集。然而,这种方法并未具体谈及如何区分拼音和英文,只是采用英文词典来简单的对英文单词进行判断,极有可能将类似于英文单词的拼音串纠错成为英文词语,不能很好的处理中文搜索引擎中包含多种语言形式的错误。
为了提高纠错的速度,李晓东在文献[15]中使用多字驱动词典、基于拼音hash词典的纠错算法以及字符串匹配纠错算法来处理查询词中出现的同音别字、多字漏字等错误。然而,这种方法与上述方法类似,都只能处理查询中仅包含单个词条的情况,同时也没有考虑到中文搜索引擎中包含的多种错误形式。
上述方法没有考虑到中文信息检索系统中包含了包括中文、拼音、英文、数字等多种语言组合形式,同时对于中文长查询没有提出很好的解决办法。我们受到以上相关工作的启发,提出了一种支持混合语言的并行查询纠错方法。
3 支持混合语言的并行纠错方法
3.1 混合语言编码
中文查询纠错是以汉字为单位进行纠错处理,汉字是由拼音指定的,每个汉字可以对应一串或几串(多音字)拼音字母组合。英文查询纠错是以英文单词为单位进行处理。英文是由英文字母组合而成,每个英文单词对应一串字母组合。可以通过对英文单词进行编码,把英文单词和汉字映射到统一的编码区域,从而对英文和中文进行统一处理。在unicode编码中,英文字母的编码范围:0x0041—0x007a。中文常用字的编码范围:Ox4E00—0x9FFF(表1)。对于中文搜索引擎,0x9FFF以上的unicode字符可以不进行处理。
本论文中把0x9FFF以上的编码unicode编码用做英文单词的编码,从而把英文单词和中文字转化到字符序列进行统一处理。英文单词有几十万个,在中文搜索引擎中,用户查询词涉及到的英文单词涵盖范围没有那么广泛,只需要统计查询日志中常用的英文单词进行编码即可。除了英文外,也可以对查询中常出现的字母、数字等符号的组合进行编码,例如,“360buy”、“taobao”等,作为文字单位进行编码。

表1 unicode中文编码范围
在支持混合语言的并行纠错方法中,使用上述编码方式对训练文本中的数据进行预处理,使用编码后的训练数据构建下文所提出的字符词典树和语言模型,从而统一处理了中文、英文和其他常用字符组合的纠错问题。
3.2 并行纠错模型
对于中文长查询,采用单一方向的查询纠错模型进行处理,纠错时间会相应的增加,纠错模型的准确率也会相应降低。为了解决这一问题,本模块提出了双向并行纠错模型。
并行纠错处理是从查询词的两端同步进行纠错,对于正向(从句子的左端到右端)查询纠错模块需要建立正向字符词典树与正向的语言模型,然后根据编辑规则,对查询词语从左到右进行纠错处理;逆向(从句子的右端到左端)查询纠错模块需要建立逆向的字符词典树与逆向的语言模型,从查询语句的右端开始进行纠错处理。当正向的纠错处理模块与逆向的纠错处理模块在切分点P处重合时,对重合部分拼接,最终得到一条完整的纠错语句。并行纠错模型的处理过程如图1所示。

图1 双向纠错模型处理过程
3.2.1 构建词典树与语言模型
3.2.1.1 构建字符词典树
字符词典树是一种快速检索的多叉树结构,利用字符串的公共前缀来节约存储空间。字符词典树的根节点不包含字符,除根节点以外的每个节点只包含一个字符。如果从根节点到某个节点构成的字符串是一个伪编码处理后的合法词语,则标记该节点为完成节点并在此节点上存储对应的词语信息。整个字符词典树上的节点分为完成状态节点与非完成状态节点,“和”这个词语在字符词典树种对应的拼音串路径为:h-e,在节点e会标记为完成节点,并在此节点存储:“和”、“喝”…等词语信息。如图2所示,虚线代表没画出来的分支。
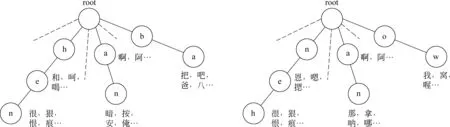
(a) 正向字符词典树 (b) 逆向字符词典树图2 字符词典树
本文在正向字符词典树的基础上,提出了逆向字符词典树的概念。逆向字符词典树是把词语对应的拼音字符串倒转,然后存储路径上的词语信息。例如,“很”对应的拼音字符串为:“hen”,倒转后变为“neh”;先前所述的字符词典树是在字符“n”处标记为完成节点并存储“很,狠,恨…”等词语,逆向的字符词典树则在字符“h”节点处标记为完成节点,并存储“很,狠,恨…”等词语。逆向字符词典树中的节点类型同样分为完成节点与未完成节点。
3.2.1.2 构建语言模型
正向的语言模型表示在一系列活动出现之后的概率[16],n-gram语言模型表示第n个词的概率是由已经产生的n-1个词决定的。以三元语法模型为例,我们可以认为一个词的概率只依赖于它前面的两个词,那么当n>2时,一个长度为L个基元(基元可指字、词、短语)构成的语句s出现的概率可以表示为式(1)。
(1)
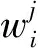
(2)
由于训练语料库中的数据是根据网页日志和查询日志得到的,不能覆盖所有自然语言,会出现 p(s)=0的情况,需要使用平滑技术来解决这种零概率问题。在此使用Witten-Bell平滑的方法,在此方法中,n阶平滑模型被递归的定义为n阶最大的似然模型和n-1阶平滑模型的线性插值,如式(3)所示。
(3)
(4)
(5)
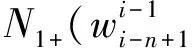
逆向的语言模型表示在一系列活动出现之前的概率,逆向语言模型的构建是从句子尾部开始处理。正向语言模型是根据历史信息来估计当前词语出现的概率,逆向语言模型在正向语言模型的基础上进行变形,根据未来信息来估计当前词语出现的概率。对于由L个基元(基元可指字、词、短语)构成的语句s出现的概率p(s)表示为式(6)。
(6)
其中,wi(0<=i<=L)产生的概率是由未来信息wi+1wi+2...wL决定的。
对于逆向语言模型同样使用平滑技术来解决零概率问题。在此使用Witten-Bell变形的平滑方法来处理数据平滑问题。
3.2.2 编辑规则处理
对于查询语句s,先把s转化为字符序列(中文转换为拼音形式、英文和数字等形式保持不变),然后逐个字符进行编辑处理。如果字符是中文字符,则对其进行中文规则编辑;如果字符是英文字符,则对其进行英文规则编辑。中文编辑处理比较严格,英文处理时则宽松一些。限制中文编辑是因为对中文拼音进行替换、插入等操作会生成庞大的中文字符集,一方面增大了存储空间,另一方面会形成大量完全偏离原始查询词的纠错结果。
中文规则编辑包括同音匹配、多音匹配、近音替换、删除;形近字替换、前后字符交换。其中同音匹配是指在中文字符仅对应一种拼音形式时,将该字符替换为其拼音;多音匹配是指在中文字符对应多种拼音形式时,将该字符替换为其多个拼音形式;近音替换是指将中文字转换为其近似拼音;形近字替换是将中文字转换为其形近字的拼音,对应的形近字可在形近字表中查询。英文规则编辑包括匹配、替换、插入、删除、前后字符交换。其中匹配是指编辑所得的字符串即为该英文字符;替换是指将该英文字母替换为除该字母以外的其他25个英文字母;插入是指在英文字母后插入26个英文字母,产生26个字符串作为编辑结果。
根据相应的规则进行编辑后,查找字符词典树,如果编辑后的序列在字符词典树中存在对应的中文词语,则把当前状态标记为完成状态并加入到完成状态队列和未完成状态队列;否则标记为未完成状态并加入未完成状态队列。这里把完成状态词语同时加入到完成状态队列和未完成状态队列,主要是为了保存最大匹配和最小匹配生成的所有状态,确保分词的准确性(图3)。
状态队列中的每个状态都保存着当前状态的操作代价W,在本模型中,操作代价是编辑操作的代价与语言模型概率的线性组合,具体形式如式(7)所示。其中edit_cost代表编辑操作的代价,ngram_cost代表语言模型计算的概率,α,β∈[0,1]且α+β=1。

(7)
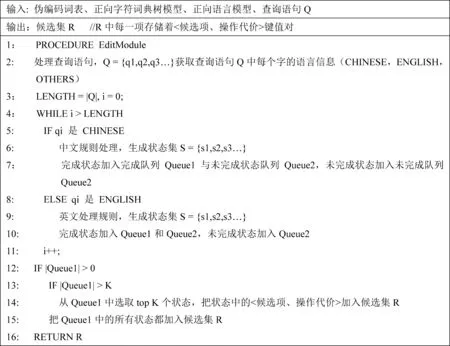
图3 EditModule函数处理过程
3.2.3 确定切分点
并行纠错模型中的切分点P是通过计算词语之间的互信息得到的。对于中文长查询,扫描字符串,计算相邻两个词语之间的互信息。对有序汉字串AB中汉字A、B之间的互信息定义为式(8)。
(8)
其中P(A,B)为汉字串AB出现的概率,P(A)为汉字A出现的概率,P(B)为汉字B出现的概率。如果I(A,B)>0,则AB间是正相关,当I(A,B)大于某个给定阈值,可认为AB基本成词;如果I(A,B)=0,则AB间是不相关的;如果I(A,B)<0,则AB间是互斥的,这时AB间基本不会结合成词。
本文中,从长查询的中间部分向左端、右两端依次计算字与字之间的互信息,选取两端长度相差最小的切分点。然后分别从查询词的两端开始进行查询纠错处理,直到查询切分点处结束。
4 实验及结果分析
4.1 实验数据集
本实验的训练数据是从某中文商业搜索引擎的查询日志、用户点击日志,网页链接文本等日志文件中获取的,字符词典树的训练数据约135万条,伪编码的词条有21万条数据,语言模型的训练数据有 1 400万条。
从某搜索引擎查询日志中随机抽取的3 675条查询数据作为测试数据,其中含有字母组合100条,数字组合49条,字母数字组合35条,汉字、字母、数字组合的查询词语有3 059条。3 675条查询数据中错误的查询词有173条,占整个查询数量的4.7%。当设定切分查询语句的长度阈值为6时,3 675条查询数据中有1 812条查询为长查询,占整个查询的49.3%。
4.2 评估方法
本实验将采用正确率(Precision)、召回率(Recall)、F值(F measure)这三个指标来评估系统,其含义具体如式(9)~(11)所示。
(11)
其中,Ns代表查询纠错模块进行纠错的查询数量;Nmc代表查询纠错系统输出的正确纠错的数量;Nmt代表测试集中包含的错误查询数量。
4.3 实验对比
实验中,QueryCorrection是根据我们前期提出的一种面向中文搜索引擎混杂语言的查询纠错方法及系统[1]实现的。ReverseQueryCorrection是在逆向字符词典树与逆向语言模型基础上,从查询语句尾部(从右向左)进行纠错的模型。ParallelQueryCorrection是我们提出的双向并行纠错模型。实验数据如表2所示。

表2 QueryCorrection、ReverseQueryCorrection和ParallelQueryCorrection实验对比
从实验结果上来看,对于中文长查询,单向纠错会消弱每个词语的操作代价,从而容易把正确的查询词语纠成错误的候选。而Parallel Query Correction模型通过把长查询变为短查询,增强了每个词语的操作代价,提高了正确率。
但是,Parallel Query Correction模型在使用互信息将长查询切分为短查询的同时,查询词语的上下文信息也会相应的减少,一些局部正确但是整体有误的查询语句不能够得到正确的修改,造成了正确纠错数量的减少。此外,长查询语句的不适当切分也会减少正确纠错的数量,降低了召回率,总体上看,召回率降低了3%。从速度上看,Parallel Query Correction采用双向的纠错方法,使得纠错速度比单向查询纠错模型快了40%左右。
5 结束语
本文提出了一种支持混合语言的并行查询纠错方法。我们提出了对包含中文、拼音、英文等混合语言的统一处理的解决方法。在正向字符词典树和正向语言模型的基础上提出了逆向字符词典树和逆向语言模型的概念。通过编辑操作获得查询词的候选项集合,通过编辑距离权重和语言模型概率的线性组合来获取候选项。引入双向纠错模型来处理中文长查询的速度问题。实验表明,与单向查询纠错相比,支持混合语言的并行纠错方法在准确率上提升了9%,召回率降低了3%,在速度上提升了40%左右。
为了进一步提高响应时间,下一步的工作将围绕多路并行纠错进行相关研究,展示出更充分的实验评测结果。此外,可以考虑通过挖掘用户的搜索日志中有用的反馈信息,如用户点击信息,研究如何利用这一信息改进查询纠错系统,进一步提高其准确率和召回。
[1] 程舒杨,熊锦华,公帅等.一种面向中文搜索引擎混杂语言的查询纠错方法及系统:中国, 201210320575.[P].2013-01-09.
[2] Zhang Lei, Zhou Ming, HuangChangning, et al. Automatic Detection and Correction of Typed Errors in Chinese text [C]//Proceedings of the Applied Linguistics, 2001(1).
[3] 李亚楠,王斌.一个中文搜索引擎的查询日志分析[C].中国.数字图书馆论坛.2008.
[4] Levenshtein V I. Binary codes capable of correcting deletions, insertions, and reversals [J]. Soviet PhysicsDoklady, 1966, 10(8): 707-710.
[5] Wagner R A, Fischer M J. The string-to-string correction problem [J]. Journal of the Association for Computing Machinery, 1974, 21(1): 168-173.
[6] Riseman E M, Hanson A R. A contextualpostprocessing system for error correction using binary n-grams [J]. IEEE Transactions on Computers, 1974, 23(5): 480-493.
[7] Zobel J, Dart P. Finding approximate matches in large lexicons [J]. Software-Practice and Experience, 1995, 25(3): 331-345.
[8] Rogers H J, Willett P. Searching for historical word forms in text databases using spelling-correction methods: reverse error and phonetic coding methods [J]. Journal of Documentation, 1991, 47(4): 333-353.
[9] Duan H, Hsu B P. Online spelling correction for query completion [C]//Proceedings of the 20th International Conference on World Wide Web: WWW 2011. New York, NY, USA: ACM, 2011: 117-126.
[10] Sun X, Gao J, Micol D, et al. Learning phrase-based spelling error models fromclickthrough data [C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics: ACL 2010. Stroudsburg, PA, USA: Association for Computational Linguistics, 2010: 266-274.
[11] Toutanova K, Moore R C. Pronunciation modeling for improved spelling correction [C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Stroudsburg, PA, USA: Association for Computational Linguistics, 2002: 144-151.
[12] Golding A R. A Bayesian hybrid method for context-sensitive spelling correction [C]//Proceedings of the 3rd Workshop on Very Large Corpora. Stroudsburg, PA, USA: Association for Computational Linguistics, 1995: 39-53.
[13] Li M, Zhu M, Zhang Y, et al. Exploring distributional similarity based models for query spelling correction [C]//Proceedings of the 21st International Conference on Computational Linguistics and the 44th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA, USA: Association for Computational Linguistics, 2006: 1025-1032.
[14] 周博,刘奕群,张敏,等.一种中文搜索引擎中查询词的拼写校正方法:中国, 200810224323.3.[P].2009-2-18.
[15] 李晓东.搜索引擎中中文分词与纠错模块的设计与实现[D].北京交通大学硕士学位论文,2008.
[16] 宗成庆 .统计自然语言处理[M].北京:清华大学出版社,2008: 75-93.
Aparallel Query Correction Method for Mixed Language
ZHUAN Yue1,2, XIONG Jinhua1, MA Hongyuan3, CHENG Shuyang1, CHENG Xueqi1
(1. Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China; 2. University of Chinese Academy of Sciences, Beijing 100190, China; 3. National Computer Network Emergency Response Technical Team Coordination Center of China, Beijing 100029, China)
Query in Chinese information retrieval system often contains Chinese, Chinese phonetic alphabet and English etc. Existing method can not solve the issue of mixed language and long Chinese query. In order to solve these problems, we propose a parallel query correction method for mixed language. The method establishes language model with mixed language and built the heterogeneous character dictionary tree according to the corresponding edit rules to process the query words. For the long Chinese query, we put forward spell correction model of two-way parallel. For paralle processing, we put forward the concept of reverse character dictionary tree and reverse language model. The training corpus used in the model is extracted from the user query log, click log, web links and other information. Experiment shows that the parallel query correction method for mixed language increases the accuracy by 9%, reduces the recall by 3%, and, especially, speeds up the processing by 40% compared to single pass query correction.
spell correction; dictionary tree; language module; parallel spell check

颛悦(1988-),硕士,主要研究领域为自然语言处理。E⁃mail:zhuan_yue@163.com熊锦华(1972-),通讯作者,博士,副研究员,主要研究领域为互联网搜索与挖掘,大规模数据处理,分布式计算。E⁃mail:xjh@ict.ac.cn马宏远(1981—),博士,主要研究领域为信息检索、智能信息处理。E⁃mail:mahongyuan@foxmail.com
1003-0077(2016)02-0099-08
2013-08-09 定稿日期: 2014-01-09
国家重点基础研究发展规划(973计划)项目(2014CB340406,2012CB316303,2013CB329602);国家自然科学基金(61173064,61300206);国家科技支撑计划项目(2015BAK20B03);国家科技支撑计划课题(2011BAH11B02);国家242专项(2013G129);国家科技支撑专项(2012BAH46B04)
TP391
A
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
文苑(2019年24期)2020-01-06 12:06:50
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:36
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:10
小天使·一年级语数英综合(2015年8期)2015-07-06 06:16:26
小天使·一年级语数英综合(2015年3期)2015-04-20 05:57:18
小天使·一年级语数英综合(2015年2期)2015-01-14 06:07:04
