
文本聚类的重构策略研究
2016-05-04 03:10陈笑蓉刘作国
中文信息学报 2016年2期
陈笑蓉,刘作国
(贵州大学 计算机科学与技术学院,贵州 贵阳 550025)
文本聚类的重构策略研究
陈笑蓉,刘作国
(贵州大学 计算机科学与技术学院,贵州 贵阳 550025)
该文提出面向文本距离并独立于聚类过程的聚类重构策略。提出邻近域的概念并阐述了邻近域规则,设计了高斯加权邻近域算法。利用高斯函数根据样本与聚簇中心的距离为样本赋权,计算聚簇间距。基于邻近域权重对文本聚类的结果实施重构。使用拆分算子拆分稀疏聚簇并调整异常样本;使用合并算子合并相似聚簇。实验显示聚簇重构机制能够有效地提高聚类的准确率及召回率,增加聚簇密度,使得形成的聚类结果更加合理。
文本聚类;聚簇重构;邻近域规则;高斯加权
1 引言
文本聚类是信息处理领域的研究热点。由于聚类之初难以获得先验知识,对样本空间分布情况做出的假设可能过于理想化,从而导致聚类结果偏离实际。此外,样本规模的不断扩大可能致使原有聚类结果发生改变。例如,一篇关于酿酒工艺的文章,最初可能与其他科普知识同归于科教类。随着“舌尖上的中国”风靡全国,各地饮食文化报道激增,这些文章可能被归为饮食类。
虽然国内外有一些文献提出聚类重构的概念,但主要是针对样本空间描述或文本表示模型进行重构[1-2],重构的是聚类过程而非聚类结果。为提高聚类的准确性和灵活性,本文引入一种针对聚类结果的重构机制,对形成的聚簇进行优化。
2 相关工作
2.1 文本表示
重构过程并非聚类过程,而是针对聚类结果进行优化,必须采用与聚类算法一致的文本表示模型及相似性度量。当前主要有基于文本距离、基于密度、基于网格、基于语义的聚类模型,其中基于VSM的聚类模型是较为常见的。本文采用VSM模型进行文本表示,以文本距离D(ti,tj)作为相似性度量实施聚类及重构。
聚簇重构的目标是调整聚类结果中内部松散或存在异常样本的聚簇。重构机制需要处理三类关系,即样本与样本的关系、样本与聚簇的关系、聚簇与聚簇的关系[3]。
2.2 聚簇中心
文本处理通常使用几何中心来定义聚簇的中心,并通过聚簇密度描述聚簇内样本的相关性。
定义1(聚簇中心): 聚簇C的中心定义为其几何中心,如式(1)所示。
(1)
式(1)中,聚簇中心K(C)的各维分量分别是各样本对应分量的向量均值。
定义2(聚簇密度): 聚簇C的密度定义为式(2)。
(2)
簇内样本与聚簇中心越接近,聚簇密度就越高,重构的必要性就越小。优先选择密度较低的聚簇实施重构可以提高效率。
2.3 簇间距离
评价聚簇间距离的算法包括最小距离算法(SingleLink)、最大距离算法(CompleteLink)、平均距离算法(AverageLink)、重心距离算法(GravityLink)等。最小距离算法及最大距离算法只使用一对样本点进行计算,对噪声较为敏感。平均距离算法及重心距离算法虽然抗噪能力较强,但缺乏单调性[4]。
文献[4]认为样本空间分布具有正太分布的性质,靠近聚簇中心的样本权重较高,对聚簇间距的影响较大。本文参考其中思想,设计一种高斯加权算法来计算聚簇间距,使算法向聚簇中心的高密度区域靠近。
定义3(簇间距离): 样本x在聚簇C中的高斯权重为式(3)。
(3)
样本x与聚簇C的距离为式(4)。
(4)
聚簇Ci与Cj的距离为式(5)。
(5)
为便于计算,式(3)取

3 聚簇重构规则
3.1 邻近域规则
聚簇重构机制根据聚簇的密度及各样本的距离调整聚簇,聚簇形状可能影响重构机制对聚簇密度的计算以及对聚簇中心的判定,导致产生不正确的重构结果[5]。如图1中所示。

图1 聚簇形状对重构机制的影响
聚类算法形成的聚簇时常不是规则的球形,甚至是凹形。图1中样本x应当属于聚簇a,但由于两个聚簇并非规则的球形,聚簇中心距d1>d2,重构机制错误地将x划分入聚簇b。
通常的解决方案是构建标准坐标系进行空间变换,选择具有一定区分度的方向构建新的坐标系,根据固有簇的特性重新定义距离标度,使得各聚簇在新坐标系下更接近球形[6-7]。
坐标系的空间变换较繁琐,可能影响样本距离的计算,使得聚类结果失真。由于聚簇形状主要影响异常样本的调整,本文设计一种邻近域(NearestDomain)算法处理不规则聚簇中的异常样本。
规则1(单向原则): 若a是b的最邻近对象,b未必是a的最邻近对象。
单向原则使样本a可能进入到邻近对象b所属聚簇,同时确保a不影响b与所属聚簇的关系。即b不会由于a的“吸引”而背离其所属聚簇。
规则2(就近原则): 设样本x的最邻近样本为a,x只有两种可能的聚类归属: (1)x与a同属一个聚簇;(2)x独自形成聚簇。
就近原则限定了异常样本的移动范围,如果x与最邻近样本a不属于同一聚簇, 则x不可能与其他任何聚簇相关,它只能独立形成聚簇。
就近原则的缺陷在于只考虑一个最邻近的样本点。如图2中,样本x最邻近样本为y,但其他邻近样本大部分属于聚簇a,因此不应当将x从聚簇a中划出。

图2 就近性原则的缺陷
文献[8]提出一种IMP_CBC聚类算法,选定多个聚簇核心,删除冲突的核心并逐渐合并核心外的样本。本文提出一种类似的邻近域算法,解决就近原则的缺陷。
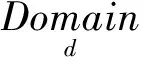
(6)
式(6)称为x在Ci上的d邻近域权重。
3.2 邻近域算法

根据邻近域规则,设计邻近域算法如下。
Step1 确定聚簇C的候选异常样本集;

Step4 调整异常样本,若D(x,K(Ck))≤D(x,K(C)),则x∈Ck;否则x独立形成聚簇;
Step5 更新聚簇中心并依次处理C中所有异常样本;
Step6 依次处理所有密度低于阈值的聚簇;
设样本规模为n,邻近域算法平均计算复杂度T(n)=O(n×logn)。
3.3 邻近域的半径选择
邻近域半径直接影响邻近域算法的性能。半径过小导致邻近域内样本点数量不足,半径过大(超过聚簇中心)则将涵盖聚簇中心另一侧的样本点,使得算法产生错误的结果。
设样本x的最邻近聚簇为CN,最邻近样本为tN,对邻近域半径d的基本要求是D(x,tN)≤d≤D(x,CN),可以考虑取式(7),
(7)
或式(8)。
(8)
本文取d=D(x,CN)进行实验。
4 文本重构机制
4.1 重构策略
聚簇重构需要考虑以下情形:
(1) 异常样本调整。若聚簇内少数样本与簇内其他样本联系较弱,应当将这些“另类”样本调整到其他聚簇中;
(2) 稀疏聚簇拆分。若聚簇密度过低,说明簇内样本分布稀疏,应当将稀疏聚簇拆分为多个密集聚簇;
(3) 相似聚簇合并。若多个聚簇联系紧密,考虑将它们合并为一个聚簇,合并后可能需要考虑(1)、(2)类问题。
(1)类问题采用邻近域算法处理;(2)~(3)两类问题分别采用拆分算子和合并算子进行处理。聚簇过于稀疏不利于判断聚簇间距,会影响聚簇合并,因此聚簇重构应当先拆分后合并,并优先处理密度低的聚簇[9]。重构机制总体过程如下。
Step1 获取聚类结果;
Step2 计算聚簇中心及密度;
Step3 采用邻近域算法处理异常样本;
Step4 采用拆分算子处理稀疏聚簇;
Step5 采用合并算子处理相似聚簇;
Step6 更新重构结果并实施迭代。
4.2 拆分算子
本文参照文献[10]阐述的聚类改进策略,设置密度阈值来限定拆分算子的作用范围,聚簇拆分的算法如下。
Step1 在密度低于阈值的聚簇中选择密度最低的聚簇Ci;
Step2 获取簇内任意未处理成员t;
Step3 寻找t最近聚簇Cj;
Step4 若Ci=Cj转Step6,否则继续


Step5 更新聚簇中心及聚簇密度;
Step6 迭代处理聚簇Ci内所有样本。
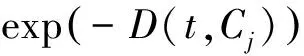
设样本规模为n,理论上拆分算子完成所有计算的平均复杂度为O(n2),由于聚簇中心、聚簇密度、高斯权重等复杂计算在聚类过程中已经完成,拆分算子实际时间开销为O(n×logn)。
4.3 合并算子
聚簇合并的算法如下。
Step1 整个聚簇集添加到未处理聚簇集合Cu;
Step2 获取任意未处理聚簇Ci;
Step3 寻找Ci最近聚簇Cj;
Step4 分析Ci与Cj关系:

Step5Cu中删除已处理聚簇;
Step6 迭代处理Cu中所有聚簇。
理论上合并算子复杂度为O(n2),实际为O(n×logn)。
重构机制示例: 假设样本空间共包括三类16个文本,用三种图形各代表一类文本。初始状态文本集被分为四类,星形表示各聚簇几何中心,箭头指向文本的最近聚簇。理想状态重构过程如图3。

图3 聚类重构示例
经过聚簇重构,稀疏聚簇得到优化,初始状态对聚类结果的影响也被削弱。聚簇的拆分及合并使得聚簇数目动态调整,无需用户干预,更符合聚类处理的实际应用需求。
5 实验分析
5.1 实验策略
以复旦大学中文语料库进行实验。采用K-means算法和SOM模型分别进行聚类,对聚类结果实施重构,以验证聚类重构机制的有效性。单次实验流程如下。
Step1 从语料库中随机选择十个类别,再从这十类中随机抽取共计n个文本作为样本集。要求每个类别至少有一个文本;
Step2 对文本进行编号并由人工记录所属类别,以便作者分析实验结果;
Step3 实施文本聚类;
Step4 实施聚类重构,进行对比。
5.2 实验结果及分析
本节对文本聚类及聚类重构的结果进行对比分析。类别Ci的准确率Pi、召回率Ci及F-score值定义如下。
定义7(准确率、召回率、F值):
Pi=正确分入Ci的文本数/Ci实际文本数;
Ri=正确分入Ci的文本数/Ci应有文本数;

由于重构机制对某些聚簇实施了拆分或合并,形成的聚簇与人工标注结果不是一一对应关系。本节采取子类分析策略统计准确率及召回率。


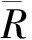

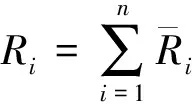
以下采用K-means及SOM分别进行聚类处理并实施重构。实验结果如表1、2、3、4所示。

表1 500样本K-means聚类及重构结果对比

表2 1000样本K-means聚类及重构结果对比

续表

表3 500样本SOM聚类及重构结果对比

表4 1000样本SOM聚类及重构结果对比
实验结果显示重构机制对聚类结果的处理是有效的。在K-means及SOM两种聚类算法中,经过重构处理后各类文本准确率、召回率均有显著提升,聚簇密度有所提高,说明重构之后聚簇内部样本关联性更强。
从表1及表2可见,艺术类准确率、召回率及聚簇密度较低,这是因为语料库对文本的人工标注不够细致。语料库艺术类包括音乐、书画、舞蹈、美学等多个领域的文章,虽然这些领域都属于“艺术”范畴,但文本的词汇特征相差甚远。通过聚簇重构,“艺术”类被划分为四个子类,如表5所示,每个子类密度仍然是可接受的。

表5 “艺术”子类
从表1与表2,表3与表4的对比中可知,不同样本规模下准确率、召回率有一定差别,但重构后聚簇密度却相差无几,这说明聚类算法对样本规模是敏感的,但重构机制不受到样本规模的影响。
6 总结
本文提出一种文本聚类结果的重构机制,可适用于基于文本距离或文本相似度的聚类算法,对获得的聚类结果实施优化。文章探讨了样本分布特征及聚簇形状对重构机制的影响,采用邻近域规则进行聚簇优化。实验表明,重构机制在不影响聚类处理策略的前提下拆分或合并聚簇,能够有效地提高聚类精度,保证聚簇的紧密性,其算法时间开销在可接受范围。
重构机制所需的样本距离、聚簇中心、聚簇密度等参数由聚类过程计算获得,因此重构机制对聚类过程有一定的依赖性,要求在进行文本聚类的同时保存相关参数,增加了额外的空间开销。利用XML等数据存储格式可以高效地存取数据,有利于重构算法执行效率的提高及适用范围的扩展。
[1] MShahriar Hossain, Praveen Kumar Reddy Ojili, Cindy Grimm, et al. Scatter/Gather Clustering: Flexibly Incorporating User Feedback to Steer Clustering Results[J]. IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS, 2012, 18(12): 2829-2838.
[2] 王灿田,孙玉宝,刘青山.基于稀疏重构的超图谱聚类方法[J].计算机科学,2014,41(2): 145-148,156.
[3] Jinjiang Li, Hui Fan, Da Yuan, et al. Kernel Function Clustering Based on Ant Colony Algorithm[C]//Guo Maozu. ICNC 2008. Jinan, China. 2008: 645-649.
[4] 季铎,王智超,蔡东风,等.基于全局性确定聚类中心的文本聚类[J].中文信息学报,2008,22(3): 50-55.
[5] 曾依灵,许洪波,吴高巍,等.一种基于空间映射及尺度变换的聚类框架[J].中文信息学报,2010,24(3): 81-88.
[6] Nisha M N, Mohanavalli S, Swathika R. Improving the quality of Clustering using Cluster Ensembles[C]//Proceedings of 2013 IEEE Conference on Information and Communication Technologies. 2013: 88-92.
[7] 刘金岭,冯万利,张亚红.初始化簇类中心和重构标度函数的文本聚类[J].计算机应用研究,2011,28(11): 4115-4117.
[8] 陈建超,胡桂武,杨志华,等.基于全局性确定聚类中心的文本聚类[J].计算机工程与应用,2011,47(10): 147-150.
[9] Amineh Amini, Teh Ying Wah, Mahmoud Reza Saybani, et al. A Study of Density-Grid based Clustering Algorithms on Data Streams[C] //Ding Yongsheng. FSKD 2011. Shanghai, China. 2011: 1652-1656.
[10] 曾依灵,许洪波,吴高巍,等.一种基于语料库特征的聚类算法[J].软件学报,2010,21(11): 2802-2813.
Research on Reorganization of Text Clustering Results
CHEN Xiaorong, LIU Zuoguo
(College of Computer Science & Technology,Guizhou University, Guiyang,Guizhou 550025, China)
This paper illustrates a distance oriented reorganization strategy in which clusters could be reorganized in independence from clustering process. The concept of Nearest Domain is proposed and Nearest Domain rules are elaborated. Then Gauss Weighing Algorithm is designed to re-wieght a text by the distance from cluster kernel. At last, Nearest Domain Weights will separates sparse clusters and adjusts abnormal texts while combines similar ones. Clustering experiment shows that reorganization process effectively improves the accuracy and recall rate and makes result more reasonable by increasing the inner density of clusters.
text clustering; cluster reorganization; nearest domain rule; Gauss weighing

陈笑蓉(1954—),硕士,教授,主要研究领域为中文信息处理。E⁃mail:xrchengz@163.com刘作国(1987—),博士研究生,主要研究领域为中文信息处理。E⁃mail:412769371@qq.com
1003-0077(2016)02-0189-07
2013-12-11 定稿日期: 2014-05-15
国家自然科学基金(61362028)
TP391
A
猜你喜欢
数学物理学报(2022年5期)2022-10-09
数学物理学报(2022年4期)2022-08-22
哈尔滨工业大学学报(2022年5期)2022-04-19
摄影世界(2022年1期)2022-01-21
数学物理学报(2021年2期)2021-06-09
数学物理学报(2021年1期)2021-03-29
铁道通信信号(2019年6期)2019-10-08
商周刊(2017年6期)2017-08-22
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
