
机器译文自动评价中基于IHMM的近义词匹配方法研究
2016-05-03 13:11李茂西王明文
中文信息学报 2016年4期
李茂西,徐 凡,王明文
(江西师范大学 计算机信息工程学院,江西 南昌 330022)
机器译文自动评价中基于IHMM的近义词匹配方法研究
李茂西,徐 凡,王明文
(江西师范大学 计算机信息工程学院,江西 南昌 330022)
机器译文的自动评价推动着机器翻译技术的快速发展与应用,在其研究中的一个关键问题是如何自动的识别并匹配机器译文与人工参考译文之间的近义词。该文探索以源语言句子作为桥梁,利用间接隐马尔可夫模型(IHMM)来对齐机器译文与人工参考译文,匹配两者之间的近义词,提高自动评价方法与人工评价方法的相关性。在LDC2006T04语料和WMT 数据集上的实验结果表明,该方法与人工评价的系统级别相关性和句子级别相关性不仅一致的优于在机器翻译中广泛使用的BLEU、NIST和TER方法,而且优于使用词根信息和同义词典进行近义词匹配的METEOR方法。
机器译文自动评价; 近义词匹配; 间接隐马尔可夫模型; 单语句子词对齐; 相关性
引言
机器译文自动评价方法是机器翻译研究的直接推动力,它极大地促进了机器翻译系统的研制和开发[1-3]。对于使用机器翻译系统的用户,译文质量的自动评价结果方便他们选择更好的翻译系统。对于机器翻译系统的研发者,译文质量的自动评价结果能够使他们及时地了解系统性能,以便开发更好的翻译系统。例如,对于统计机器翻译系统,开发者需要掌握调整某些特征权重后系统的性能是否得到优化;而对于基于规则的翻译系统,为了避免“跷跷板”现象,在调整部分规则后,开发者需要知道翻译系统总体性能是否改善[4-5]。研究结果表明,利用一个与人工评价相关性高的译文质量自动评价方法指导统计翻译系统的特征权重调整,能够使研究者开发出一个性能更优的翻译系统[6]。
1 相关工作
目前,机器译文自动评价方法主要是通过对比机器翻译系统的输出译文和人工参考译文来定量计算译文的质量,评价的出发点是“机器译文越接近于参考译文,译文质量越高”[1]。在机器译文和参考译文比较时,一些译文评价方法,如BLEU[1],NIST[2],TER[7],CDER[8]等,使用词形信息进行机器译文中的词和参考译文中的词之间的匹配,即词形完全相同的两个词才认为表达同一个含义。而在自然语言处理中由于语言表达的多样性,同义词情况很普遍。仅仅使用词形信息并不能准确的匹配机器译文和人工参考译文之间的近义词。例如,机器译文“heboughtalaptop”与参考译文“hebuysacomputer”对比时,使用词形信息“laptop”与“computer”这两个词形完全不同的近义词就不能正确的得到匹配。
针对使用词形信息近义词不能准确匹配的情况,研究者们提出了许多解决方法。刘洋等考虑在词形匹配后机器译文和参考译文之间未匹配的词语中可能还包含被忽略的近义词对,提出了一种自动搜索模糊匹配词对的方法,该方法使用0与1之间的实数值来刻画词语之间的相似度,这个相似度可以通过词形相似度和结构相似度来计算[9],由于结构相似度的可靠性不强,该方法对于同根词和词形相似的情况有较好的效果,而对于词形变化较大的近义词则很难准确匹配。Satanjeev Banerjee 和 Alon Lavie等提出了自动评价尺度METEOR[3],METEOR首先匹配词形完全相同的词语,然后在未匹配的词语中分别使用词根信息和近义词信息来进行更准确的词语匹配,提高自动评价方法与人工评价的相关性。对于目标语言是欧洲语言的情况,词语的词根信息可以通过词干化工具Snowball[10]抽取;近义词则通过WordNet词典通过交叉计算获取。Yee Seng Chan 和 Hwee Tou Ng提出了自动评价尺度MAXSIM,MAXSIM在词根信息和同义词信息的基础上,加入了词性和依存句法的知识来计算机器译文和参考译文的最大相似度[11]。
由于前人在进行近义词匹配时使用的词根信息和近义词信息依赖于额外的语言学资源,并且仅适用于欧洲语言,缺乏普遍性。因此,我们尝试使用间接隐马尔可夫模型(Indirect Hidden Markov Model, IHMM)来进行词语匹配,在不使用额外语言学资源的情况下,提高近义词匹配的精度。另外,间接隐马尔可夫模型建模时完全与语言种类无关,因此,它能适用于任何语言种类中的近义词匹配。
2 利用近义词匹配增强机器译文自动评价方法
2.1 基于IHMM的近义词匹配
间接隐马尔可夫模型是隐马尔可夫模型在隐含状态转移概率和观测状态发射概率可以直接计算时求取隐含状态的方法,它已成功的应用于机器翻译系统融合中,用来对齐不同翻译系统输出的翻译假设构建混淆网络[12]。
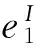
(1)
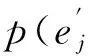
(2)
在计算人工参考译文中的词和机器译文中对应词的相似度时,对于词形相同或变化较小的词语,它们之间的相似度主要通过词形相似度进行刻画;对于词形变化较大的近义词,它们之间的相似度主要通过语义相似度进行计算。利用待翻译的源语言句子作为桥梁,将双向词汇化概率在源语言句子上进行逐词累加求和获取语义相似度,如式(3)所示。
(3)
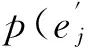
使用动态规划算法,将计算最大概率的过程分解为递推,将求取最优词语之间映射关系分解为回溯,即可建立机器译文和人工参考译文中词语语义之间的映射关系。图1以机器译文“heboughtalaptop”和人工参考译文“hebuysacomputer”为例,介绍了词语匹配的过程。在建立词语之间的映射关系之前,我们在两个译文的前面均插入了一个空词节点(ε)作为对齐基准,图1中的每一个状态(人工参考译文中的词)均可以映射到观察序列中的状态(机器译文中的词),状态转移过程以虚箭头标出,实箭头表示最终的人工参考译文生成机器译文的最大概率的一条状态转移路径。通过以上过程,可以建立人工参考译文中的词和机器译文中的词之间的映射关系,发现它们之间的近义词匹配,例如,近义词“computer”和“laptop”以及“buys”和“bought”均可以准确的进行匹配。
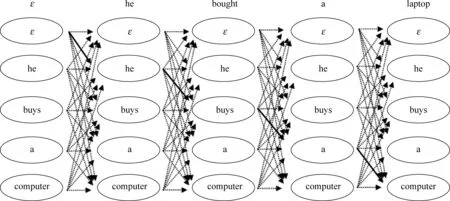
图1 一个基于IHMM的近义词匹配示例
进一步分析,我们发现使用IHMM的最大优势在于,建模时不仅考虑词语匹配过程中位置的变化,而且利用了待翻译的源语言句子和双向词汇化翻译概率。对于词形变化较大的近义词,后者更能发现机器译文和人工参考译文之间的近义词,提高匹配的精度。
2.2 利用词语匹配信息进行机器译文自动评价
建立了机器译文和人工参考译文中词语之间的匹配关系后,机器译文中词语的一元文法匹配准确率P和召回率R可以用作描述机器译文的翻译质量。为了均衡一元文法匹配的准确率和召回率,我们使用了与METROE方法相同的计算公式对机器译文进行自动评价,即使用F测度,并考虑语块连贯性惩罚因子Penalty来对机器译文进行打分,如式(4)和式(5)所示。
(4)
(5)
机器译文的最终评价得分通过式(6)计算。
(6)
尽管在计算最终译文质量得分时我们采用了与METEOR方法一致的计算公式,本文方法与METEOR方法的不同在于,我们完全使用IHMM匹配机器译文和人工参考译文中的词语,因此,它是一步完成的、算法与目标语言种类无关,并且不需要额外的语言学资源;而METEOR方法基本版本仅使用词形信息进行匹配,使用词根信息和同义词典版本的METEOR方法是分步进行匹配的,同根词信息采用与目标语言相对应的Snowball 词干化工具提取,同义词则利用WordNet词典进行匹配,而Snowball 词干化工具和WordNet词典仅适用于欧洲语言,不能应用于亚洲语言,因此,它的处理依赖于具体语言种类。
3 实验
3.1 实验设置
为了测试本文提出方法的性能,我们分别在公开发布的大规模语料LDC2006T04和WMT’10任务上进行了实验。在实验时,我们将本文方法在评价译文质量时的性能与译文自动评价尺度METEOR、BLEU、NIST和TER进行了比较,包括系统级别相关性和句子级别相关性(或一致性)。
自动评价结果与人工评价结果的系统级别相关性通过斯皮尔曼等级相关系数(Spearman’s rank correlation coefficient)进行计算,如式(7)所示。
(7)
其中n是待评价的翻译系统个数,di是第i个翻译系统人工排名和自动评价尺度给出的排名之间的差值。ρ的值介于-1和1之间,它的绝对值越大,相关性越大。
由于机器译文句子级别人工评分包括流利度/忠实度的方法和基于排名的方法,因此,自动评价结果与人工评价结果的句子级别相关性的计算方法也有两种。对于人工给出的译文忠实度/流利度分值,我们把忠实度和流利度平均后的分值作为该译文的人工给出的分值,句子级别相关性通过皮尔逊相关系数计算,如式(8)所示。
(8)
对于基于排名的方法,句子级别一致性使用肯德尔等级相关系数(Kendall’s tau rank correlation)计算,如式(9)所示。
(9)
肯德尔等级相关系数把译文质量之间的人工排名转换成两两比较,通过汇总对比人工和自动评价方法在两个译文质量优劣判断上的一致性计算句子级别一致性。
3.2 对比的机器译文自动评价尺度
BLEU: BLEU评价尺度建立的出发点是机器翻译越接近于专业的人工翻译,翻译的质量越高。它通过计算机器翻译的n元文法在参考译文中的准确率的几何平均,乘以相应的简短惩罚系数得到式(10)。
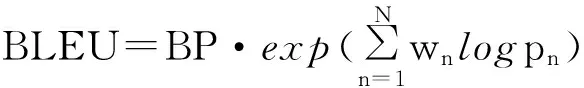
(10)
其中pn是n元文法的准确率,n的取值一般为4,即计算至四元文法。
NIST: NIST评价尺度在BLEU评价尺度的基础上,考虑了信息增益。它通过计算机器翻译的n元文法在参考译文中的准确率的算术平均,乘以相应的信息权重得到。不同于BLEU评价尺度计算至四元文法,NIST评价尺度一般计算至五元文法。本文实验数据中的BLEU和NIST值都是通过“mteval-v13a.pl*ftp://jaguar.ncsl.nist.gov/mt/resources/mteval-v13a.pl” 脚本程序计算。
METEOR: METEOR计算机器翻译的一元文法的准确率和召回率,用准确率和召回率的几何加权平均值乘以相应的语块惩罚系数作为系统的最终打分。在一元文法匹配时,它使用了词根和同义词等信息来增加匹配准确率。在计算时,它进行了几个阶段的匹配: 词形匹配、 词根匹配、同义词匹配。每一个阶段仅考虑上一个阶段没有匹配的一元文法。在实验中,本文使用该自动评价尺度的最新工具包METEOR V1.2*http://www.cs.cmu.edu/~alavie/METEOR/index.html#Download。
3.3 实验结果
3.3.1 在标准测试语料LDC2006T04上的实验结果
为了促进机器译文自动评价方法的发展,旨在比较不同译文自动评价方法效果时有一个共同的语料基础,LDC发布了LDC2006T04语料,它包含TIDES′2003机器翻译评测中英任务的测试集,六个机器翻译系统的输出译文以及译文的人工流利度/忠实度评分结果。该测试集包含100篇中文文档,共919个句子,每个中文句子有四个英文参考译文。六个参与的机器翻译系统编号分别为E09,E11,E12,E14,E15和E22。
表1和表2分别给出了在LDC2006T04语料上不同的译文评价尺度的评价结果与人工评价结果的相关性。在系统级别相关性上,利用IHMM模型进行同义词匹配的方法(简写为IHMM)比使用词根信息和同义词典的评价尺度METEOR(exact+stem+synonym)高1%,比仅仅使用词形信息进行精确匹配的自动评价尺度METEOR(exact),BLEU,NIST以及TER至少高2%,在显著性水平p=0.05时该相关性的提高是统计显著的。这表示利用IHMM模型进行同义词匹配的方法可以减少1-2次系统的错误排序个数。在句子级别上,我们分别以每一个机器翻译系统为单位,测试了不同自动评价尺度的性能。实验结果显示对E09、E11、E12、E14和E15系统结果的评价上,利用IHMM模型进行同义词匹配的方法平均优于METEOR(exact+stem+synonym)。尽管在对E22系统结果的评价中利用IHMM模型进行同义词匹配的方法低于METEOR(exact+stem+synonym) 1%,但是总体上,利用IHMM模型进行同义词匹配的方法比METEOR(exact+stem+synonym) 高 1%,并且统计显著的优于使用词形进行精确匹配的自动评价尺度METEOR(exact),BLEU,NIST以及TER
(p=0.01)。这证实了利用IHMM模型进行同义词匹配的方法能提高译文中词语匹配的准确度,将它的匹配结果应用于译文自动评价中能够提高评价结果与人工评价的相关性。
表1 不同的译文评价尺度在LDC2006T04语料上的系统级别相关性
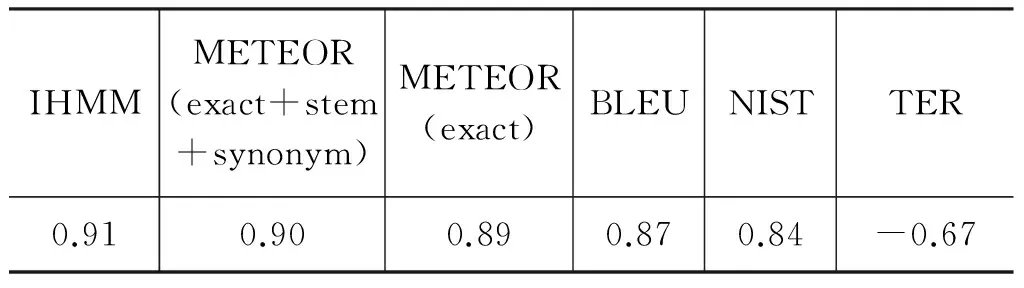
IHMMMETEOR(exact+stem+synonym)METEOR(exact)BLEUNISTTER0.910.900.890.870.84-0.67
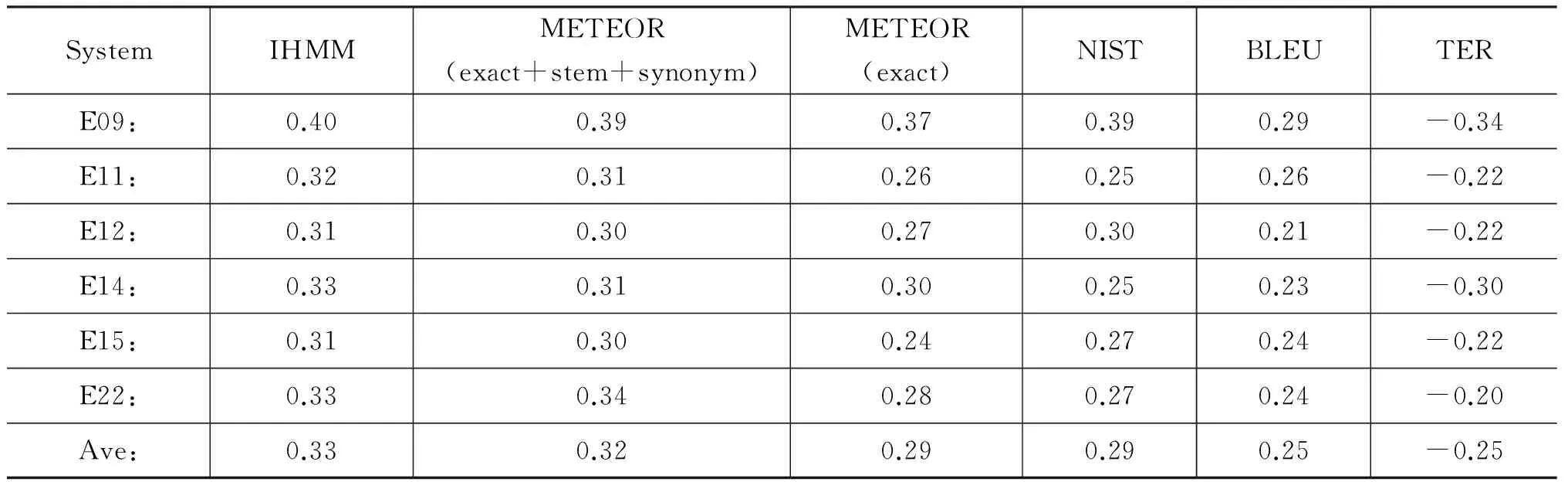
表2 不同的译文评价尺度在LDC2006T04语料上的句子级别相关性
3.3.2 在WMT’10翻译成英语任务上的实验结果
在WMT’10评测的机器输出译文上,我们测试了对目标语言是英语的任务的评价中,不同译文自动评价尺度与人工评价的相关性。WMT’10评测的翻译成英语任务分为捷克语-英语(CZ-EN)、法语-英语(FR-EN)、德语-英语(DE-EN)和西班牙语-英语(ES-EN)等四个翻译方向。对于每个翻译方向的多个系统输出译文中,评测方人工抽取了部分机器译文进行排名评价。在每个方向的翻译任务中参与的系统个数和人工排名评价中两两比较的次数如表3统计所示。
表3 WMT’10翻译成英文任务上参与的系统个数与译文两两比较的次数
表4和表5分别给出了在WMT’10翻译成英文任务上不同的译文自动评价尺度的评价结果与人工评价结果的系统级别相关性和句子级别一致性。在系统级别相关性比较中,利用IHMM模型进行同义词匹配的方法与使用词根信息和同义词典的评价尺度METEOR(exact+stem+synonym)的平均系统级别相关性相同,均是0.90;这也与仅仅使用词形信息进行精确匹配的TER尺度相同。这表明这三种评价尺度都能较好的对参与的翻译系统进行排名。值得注意的是在WMT’10 Metrics task中最好的系统“i-letter-BLEU”的系统级别的相关性是0.94,比利用IHMM模型进行同义词匹配的方法高出4%,因此,它还有进一步提升的空间。
由于WMT’10评测提供的是基于排名的人工评价结果,因此,肯德尔等级相关系数被用来测量句子级别一致性。在句子级别一致性的比较中,在CZ-EN翻译任务上利用IHMM模型进行同义词匹配的方法比METEOR(exact+stem+synonym)的一致性高3%,在平均句子级别一致性上利用IHMM模型的方法比METEOR(exact+stem+synonym)高1%,统计显著的优于使用词形进行精确匹配的自动评价尺度METEOR(exact),BLEU,NIST以及TER (p=0.01)。这同样表明利用IHMM模型进行同义词匹配的方法能提高同义词匹配的准确度。
4 总结与讨论
本文提出借助源语言句子作为桥梁,在机器译文自动评价中利用IHMM提高同义词匹配精度的方法。该方法不仅不需要额外的语言学资源,例如,词根信息或同义词典等。而且实验结果表明它在译文自动评价中的性能略高于使用词根信息和同义词典的自动评价尺度。
该方法的不足之处在于它需要双语平行语料来训练词汇化翻译概率。幸运的是,目前统计机器翻译的研究中有大量公开发布的双语平行语料可供使用。因此,该方法在实践中也有一定的应用价值。
[1] Kishore Papineni, Salim Roukos, Todd Ward, et al. BLEU: a Method for Automatic Evaluation of Machine Translation[C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, Pennsylvania, 2002: 311-318.
[2] George Doddington. Automatic Evaluation of Machine Translation Quality Using N-gram Co-occurrence Statistics[C]//Proceedings of the second international conference on Human Language Technology Research (HLT'02), San Diego, California, CA, USA, 2002: 138-145.
[3] Satanjeev Banerjee, Alon Lavie. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments[C]//Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, 2005: 65-72.
[4] 李茂西, 江爱文, 王明文. 基于ListMLE 排序学习方法的机器译文自动评价研究[J]. 中文信息学报, 2013, 27(4): 22-29.
[5] 李良友, 贡正仙, 周国栋. 机器翻译自动评价综述[J]. 中文信息学报, 2014, 28 (3): 81-91.
[6] Chang Liu, Daniel Dahlmeier, Hwee Tou Ng. Better Evaluation Metrics Lead to Better Machine Translation[C]//Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, Scotland, UK, 2011: 375-384.
[7] Matthew Snover, Bonnie Dorr, Richard Schwartz, et al. A Study of Translation Edit Rate with Targeted Human Annotation[C]//Proceedings of Association for Machine Translation in the Americas, 2006: 223-231.
[8] Gregor Leusch, Nicola Ueffing, Hermann Ney. CDER: Efficient MT Evaluation Using Block Movements[C]//Proceedings of the 11th Conference of the European Chapter of the ACL (EACL 2006), Trento, Italy, 2006: 241-248.
[9] 刘洋, 刘群, 林守勋. 机器翻译评测中的模糊匹配[J]. 中文信息学报, 2005, 19 (3): 45-53.
[10] Robyn Schinke, Mark Greengrass, Alexander M Robertson et al. A stemming algorithm for Latin text databases[J]. Journal of Documentation, 1996, 52 (2): 172-187.
[11] Yee Seng Chan, Hwee Tou Ng. MAXSIM: A Maximum Similarity Metric for Machine Translation Evaluation[C]//Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics (ACL 2008), Columbus, Ohio, 2008: 55-62.
[12] Xiaodong He, Mei Yang, Jianfeng Gao, et al. Indirect-HMM-based Hypothesis Alignment for Combining Outputs from Machine Translation Systems[C]//Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing Honolulu, 2008: 98-107.
[13] Franz Josef Och, Hermann Ney. Discriminative Training and Maximum Entropy Models for Statistical Machine Translation[C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, Pennsylvania, 2001: 295-302.
Research on IHMM-Based Synonyms Matching for Automatic Evaluation of Machine Translation
LI Maoxi, XU Fan, WANG Mingwen
(School of Computer and Information Engineering, Jiangxi Normal University, Nanchang, Jiangxi 330022, China)
Automatic evaluation of machine translation promotes the rapid development and application of machine translation. And how to automatically identify and match the synonyms between the machine translation and human reference translation is a key issue. We take the source language sentence as a bridge, utilizes the indirect hidden Markov model to align the machine translation with reference translation, and matches the synonyms among them, to improve the correlation between automatic approaches and human judgment. Experimental results on LDC2006T04 corpus and WMT datasets show that the system-level correlation and the sentence-level correlation between the proposed approach and human judgment not only consistently outperform the widely used automatic metrics BLEU, NIST and TER, but also outperform the METEOR metrics that take use of word stem information and thesaurus.
automatic evaluation for machine translation; synonyms matching; indirect hidden Markov model; word alignment for monolingual sentences; correlation

李茂西(1977-),博士,副教授,主要研究领域为自然语言处理和机器翻译。E-mail:mosesli@jxnu.edu.cn徐凡(1979-),博士,讲师,主要研究领域为自然语言处理和篇章分析。E-mail:xufan@jxnu.edu.cn王明文(1964-),教授,博士生导师,主要研究领域为信息检索、数据挖掘、机器学习。E-mail:mwwang@jxnu.edu.cn
1003-0077(2016)04-0117-07
2014-09-01 定稿日期: 2014-12-23
国家自然科学基金(61203313, 61462044, 61402208, 61272212)
TP391
A
猜你喜欢
小学生学习指导(低年级)(2021年5期)2021-07-21
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
韩国语教学与研究(2020年4期)2020-05-17
新生代(2019年7期)2019-11-13
小天使·一年级语数英综合(2019年6期)2019-06-27
山东青年(2018年7期)2018-11-06
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
雕塑(2000年2期)2000-06-22
