
基于复杂网络理论的汉语复句关系词搭配网的统计特征研究
2016-05-03 13:00刘延申
中文信息学报 2016年4期
胡 泉,谢 芳,李 源,刘延申
(1.华中师范大学 物理学院,湖北 武汉 430079;2.湖北工业大学 计算机学院,湖北 武汉 430068;3.华中师范大学 计算机学院,湖北 武汉 430079)
基于复杂网络理论的汉语复句关系词搭配网的统计特征研究
胡 泉1,谢 芳2,李 源3,刘延申1
(1.华中师范大学 物理学院,湖北 武汉 430079;2.湖北工业大学 计算机学院,湖北 武汉 430068;3.华中师范大学 计算机学院,湖北 武汉 430079)
汉语复句关系词是汉语复句在语表形式上的标记,是复句中标识关系的重要构件,在现代汉语复句研究领域起着关键作用。汉语复句关系词的搭配是指在汉语语篇中两个或两个以上的复句关系词形成的句法共现形式,它不仅影响着分句的语义,而且影响着复句层次关系的划分。该文利用复杂网络的理论,基于已获取的470个复句关系词构建了一个“现代汉语复句关系词搭配网络”。通过对该网络中的平均路径长度、聚集系数和度分布等特征的统计,用来发现汉语复句关系词之间的搭配能力和搭配强度,这些结果能够帮助复句层次关系和复句逻辑语义的自动识别。
汉语复句关系词搭配;复杂网络;平均路径长度;聚集系数;度分布
1 前言
复杂网络是从全局的视角来研究复杂系统的新方法,无论网络的结构多么复杂,规模有多大,它都是采用节点和边两大基本要素来研究复杂的网络系统[1]。
20世纪末,美国康奈尔(Cornell)大学的博士生D J Watts及其导师S H Strogatz于1998年6月在《Nature》上发表了题为Collectivedynarnicsof‘small-world’networks的文章[2]。该文章揭示了小世界特征,并进一步建立了一个小世界网络模型。美国圣母(Notre Dame)大学物理系的A L Barabasi教授及其博士生R Albert于1999年10月在《Science》杂志上发表了一篇题为Emergenceofscalinginrandomnetworks的论文,进一步揭示复杂网络的无标度特性,并建立相应的无标度网络模型[3]。这两篇文章的发表,使得复杂网络开始成为数学、物理、生物,以及管理和工程技术人员等各个学科领域的学者们共同研究的新内容、新方法,其研究方法还被称为“网络思维”[4-5]。“网络思维”所关注的不是任何物理事物的本身,而是研究事物之间的联系,或者说是事物内部及其与外界的各种关系[1,4]。
复杂网络的研究具有极强的交叉学科特征,目前,复杂网络已经在各个层面、各个领域都得到了广泛的应用[1,5-6]。在复杂网络的研究中,语言网络作为一个新的研究方向,已经悄然兴起[7-9]。早先研究语言网络的是Cancho和Sole于2001年采用复杂网络的方法构建了一个英文词共现的语言网络[10]。2004年韦洛霞和李勇等构建了一个汉字网络,研究了该网络的三度分隔与小世界效应问题[11];2005年又构建了一个汉语词组网络,研究了它的组织结构与无标度特性[12];2007年刘知远和孙茂松采用复杂网络的方法构建了一个汉语词同现网络,研究了该网络的小世界效应和无标度特性[13];2008年又构建了一个汉语依存句法网络,研究了它的复杂网络性质[14]。从此许多语言学家和计算机工作者共同研究了一系列语言网络,这些研究表明: 人类语言也是人类复杂系统中的一种复杂网络,尽管各种不同语言网络的构造原理和构造方法不同,但各种语言网络都具有类似的统计特性[9-21]。
上述这些研究都是选取一种语言中的部分字和词构造一个复杂网络,带有一定的验证性,均未涉及到某种完整的词库或者句子。目前,中文信息处理正面临着句处理和篇章处理的研究难题,在“句处理”方面,主要分为单句处理和复句的处理。现在研究汉语单句信息处理的成果较多,然而复句是连接单句与篇章的桥梁,是汉语语法的重要实体单位,它表达的语义信息丰富而复杂,因而在信息处理领域具有更加重要的研究价值[22]。
关系词是复句、句群或语篇中用来连接句子表明逻辑关系的词语,是句子间的逻辑语义关系的重要标志之一,在句法结构分析中具有形式上和语义上的双重作用[22-23]。
从1957年英国语言学家Firth正式将搭配(collocation)作为语言学术语提出至今,经过近60年的研究积累和完善,搭配已发展为一个重要的语言学概念和研究领域[24]。
汉语复句关系词的搭配是汉语语篇中两个或两个以上的复句关系词形成的句法共现,它是复句中用来联结分句、标明分句间语义关系并形成复句句式的标记成分,是分句间句法关联和语义关系的形式标志。汉语复句关系词的搭配不仅影响着分句的语义,而且影响着复句层次关系的划分[25]。研究发现,汉语篇章中绝大多数关系词都具有搭配特性(占86%以上),有些关系词还只能以搭配的形式存在[26]。
汉语关系词搭配的研究具有很高的应用价值: 关系词搭配的研究在对外汉语教学、机器翻译、信息检索、词义消岐和情感分析等各个方面的应用都具有非常重要的意义[25-27]。
本文基于复杂网络的理论和研究方法对汉语复句关系词的搭配关系进行研究,在 “汉语复句关系词本体知识库”的基础上[28],抽取其中470个搭配关系词构建了一个现代汉语“复句关系词搭配网”,并对该网络的平均路径长度、聚集系数和度分布等三个基本统计特性进行分析研究。研究表明: 现代汉语复句关系词搭配网络不仅是一个典型的复杂网络,而且这些统计特性反映了复句关系词的搭配能力和搭配对象之间的强弱关系,它们是深入研究现代汉语复句关系词、复句层次关系和复句逻辑语义的自动识别与处理的重要基础[25-26]。
2 现代汉语复句关系词搭配网络
定义1 在汉语中,能构成句法搭配的关系词称为“搭配关系词”(或称“搭配关系标记”),如“不但…而且…”是一组搭配关系词,“只有…才能…”和“除非…否则…”都是搭配关系词;在关系词之间的搭配行为称作“关系词搭配”(或称“关系标记搭配”),研究“关系词搭配”,即发掘关系词搭配的机制与规律;设wi、wj∈W,W={wj|wj是复句关系词,j∈N},若D={
定义2 搭配关系词对
一个实际的网络可以形式化抽象为一个由节点集V和边集E组成的图形,即G=(V,E),其中,V中的元素称为节点(vertex),节点数为N=|V|;E中的元素称为边(edge),边数为M=|E|;而且E中的每条边都对应有V中的一对节点(x,y)。[1,29-30]
通过对文献[28]所介绍的汉语“复句关系词本体知识库”中的470个搭配关系词进行分析、研究,构造了图1所示的现代汉语复句关系词搭配网络。

图1 470个现代汉语复句关系词搭配网络的总体结构图

图2 图1中关系词节点“接着”的局部放大图
图1中,以搭配关系词为节点,以关系词的搭配关系为连接边。根据定义2,任何一对关系词的搭配关系,都具有前呼标和后应标,所以它们是一种有向网络,每条边都是由前呼标指向后应标。例如,“不但”与“而且”是一对搭配关系词,“不但”是前呼标,“而且”是后应标,于是网络中的连线是由“不但”指向“而且”,即“不但”-→“而且”。图1包含有470个汉语复句搭配关系词的所有节点,以及这些节点之间所具有的3 958条边,这些节点和边所构建的网络是一个非连通的复杂网络。
由于许多关系词既可以是前呼标,又可以是后应标,例如,关系词“但是”,当其作为“前呼标”时,它可以与“反”、“反倒”、“反而”等12个“后应标”搭配;而当关系词“但是”作为“后应标”时,它又可以和“倒”、“倒是”、“即便”等28个“前呼标”搭配,所以在图1中,许多关系词节点既有入度(箭头指向该节点),又有出度(由它出发指向其他关系词节点)。例如,图2为图1中关系词节点“接着”的放大图,由图2可以看出,关系词“接着”既有12个入度,又有28个出度。
通过对图1的分析研究,不仅可以深入挖掘汉语复句关系词的搭配能力和搭配强度,对于进一步研究复句层次结构的自动识别,以及复句逻辑语义的自动分析均具有重要的应用价值,而且对于复杂网络的本体和应用研究也将产生促进作用。
3 现代汉语复句关系词搭配网络的平均路径长度
定义3 平均路径长度(averagepathlength): 复杂网络中,两个节点i和j之间的距离dij,定义为该两个节点之间的最短路径上的边数;网络中任意两个节点之间的距离的最大值叫做网络的直径(diameter),记作D,即
(1)
实际上,D为网络中任意两个节点的最短路径长度。网络的平均路径长度,定义为任意两个节点之间的平均值,即
(2)
其中,n为整个网络的节点数目[1,5]。

表1 图1中部分节点的最短路径长度
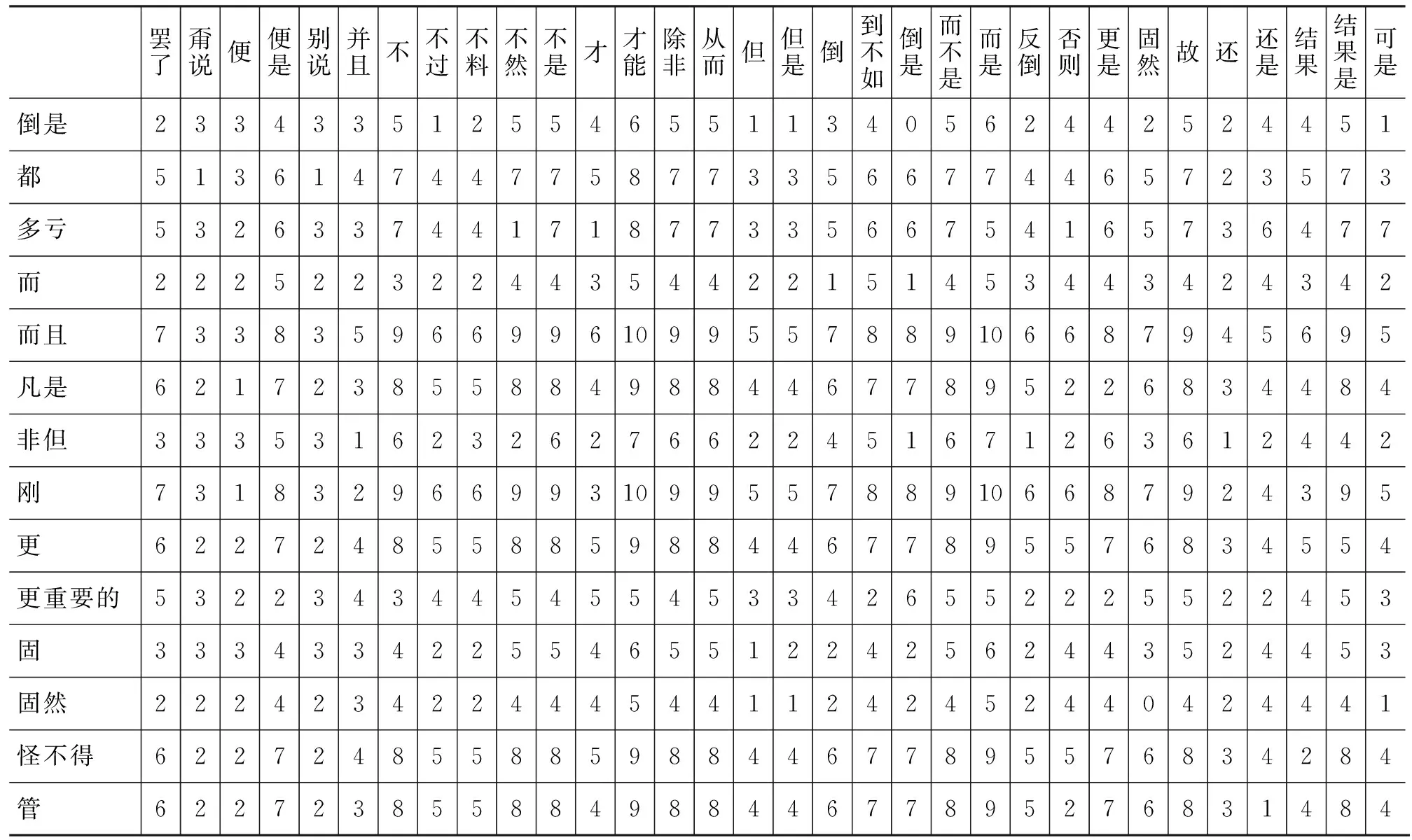
续表
通过对图1进行统计分析,在现代汉语复句关系词搭配网络图中,网络的直径D=10,表1给出了图1中部分节点的最短路径长度D。由表1可以看出,D为10的路径有多条,例如,关系词节点“但是”到“不然”、“从而”、“而不是”、“故”和“结果是”等关系词节点的最短路径长度均为10。
根据式(1)和式(2),由图1可以计算出复句关系词搭配网中的总路径长度如式(3)所示。
(3)
由于图1的节点数是n=470,所以由式(2)得到该网络的平均路径长度如式(4)所示。
(4)
现代汉语复句关系词搭配网络的路径长度和平均路径长度反映了两个关系词之间的距离。例如,从表1可以看出,关系词“但是”与关系词“便是”之间的距离是7,即“但是”→“却”→“不料”→“倒”→“基本上”→“是”→“不是”→“便是”。然而关系词“但是”与“不料”、“倒”、“基本上”、“是”、“不是”和“便是”等六个关系词均不搭配,它们只是一种间接关系,即关系词“但是”与关系词“却”搭配,关系词“却”与关系词“不料”搭配,关系词“不料”与关系词“到”搭配,关系词“到”与关系词“基本上”搭配,关系词“基本上”与关系词“是”搭配,关系词“是”与关系词“不是”搭配,关系词“不是”与关系词“便是”搭配。如果关系词“但是”与关系词“便是”出现在同一个复句中时,它们可能会跨越多个复句的层次。
现代汉语复句中,两个关系词之间的距离体现了复句关系词的离析度,文献[25]和文献[31]讨论了离析度在复句关系和层次自动分析中的意义。所以,现代汉语复句关系词搭配网络中的路径长度和平均路径长度是进一步研究计算机自动识别复句层次关系的一种基本依据。
4 现代汉语复句关系词搭配网络的聚集系数
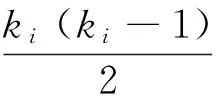
(5)
显然,Ci=[0,1],即0≤Ci≤1;当ki=1时,Ei=0,只有当ki>1时才有可能Ei>0。
设整个网络的节点数为n,则整个网络的聚集系数C即为所有节点的聚集系数Ci(其中i=1,2,3,…,n)的平均值[1,5]。即:
(6)
式(6)中0≤C≤1 。如果当且仅当网络中所有的节点均为孤立节点时,则C=0,这时整个网络中没有任何连接边;如果当且仅当整个网络中任何两个节点都直接相连,则C=1 ,这样的网络称为“全局耦合网络”[1,5]。
在现代汉语复句关系词搭配网络中,聚集系数可以用来度量一个关系词节点与其相邻的任意关系词节点之间产生搭配关系的可能性和搭配强度。
由定义4和式(5)可知,图1中的470个搭配关系词构成了470个子网络,图3展示了图1中搭配关系词节点“但是”与其可能搭配的关系词节点之间所构成的子网。从图3可以看出,该子网中有k73=k“但是”=40个的节点数与节点“但是”相连,这40个节点之间存在的实际边数是E73=E“但是”=74条。于是搭配关系词“但是”节点的聚集系数如式(7)所示。
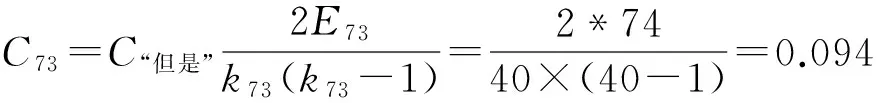

(7)
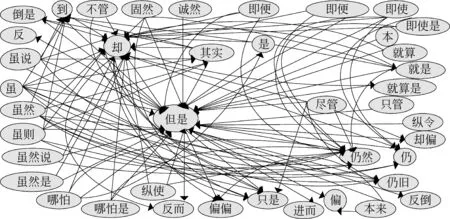
图3 图1中搭配关系词节点“但是”与其可能搭配的40个关系词节点之间所构成的子网图
表2给出了图1中部分子网的节点数ki、实际边数Ei和相应的聚集系数Ci的值。
表2中,i为图1中关系词节点(子网)的编号,Ni为关系词子网名,ki为相应子网的节点数,Ei为该子网中的实际边数,Ci为该子网相应的聚集系数值。
根据式(6),在这n=470个节点的“现代汉语复句关系词搭配网络”中,整个网络的聚集系数C就是所有关系词节点i(i=1,…,470)的聚集系数Ci的平均值,即
(8)
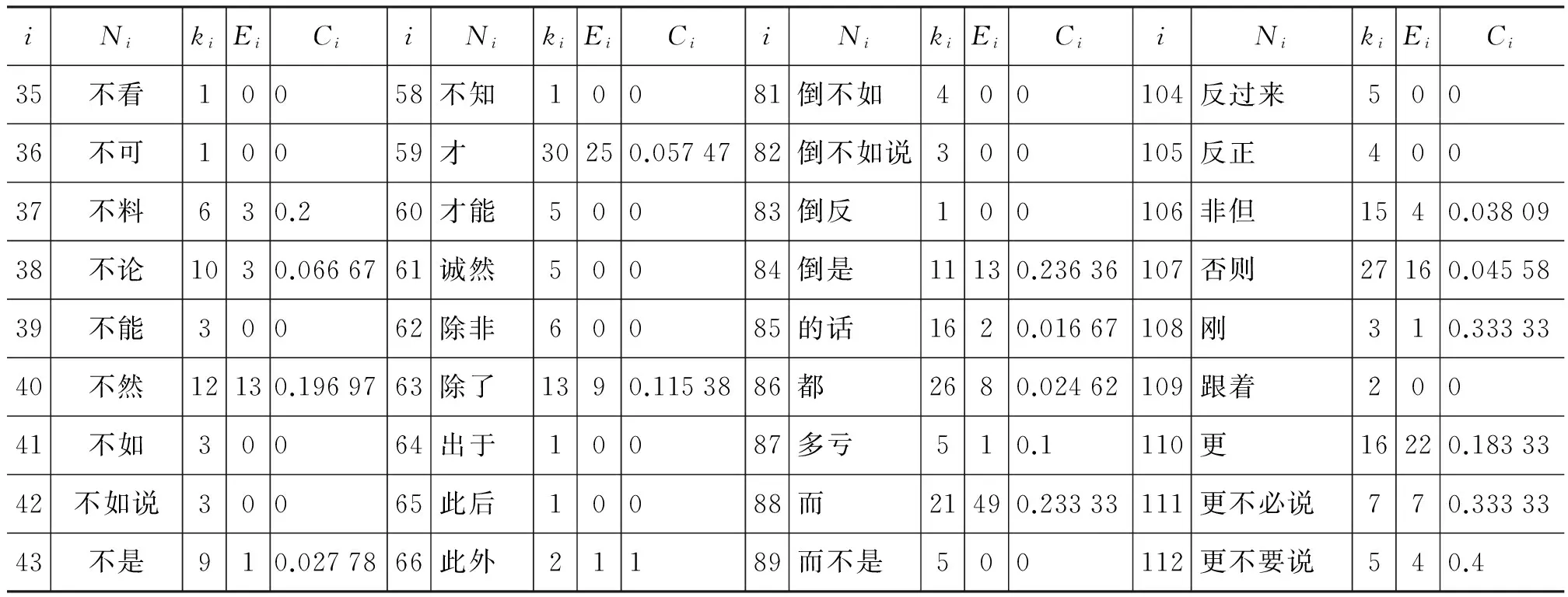
表2 图1中部分子网的节点数ki、实际边数Ei和相应的聚集系数Ci的值
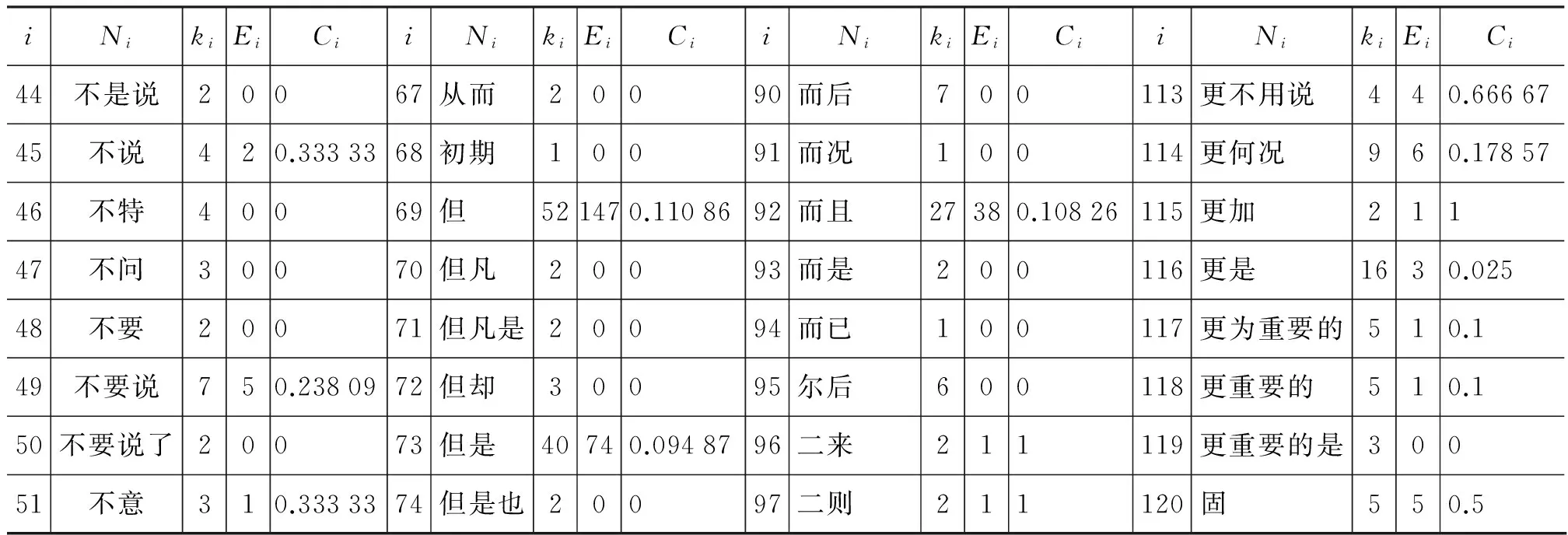
续表
在图1所示的现代汉语复句关系词搭配网络中,其平均路径长度为2.291 9,平均聚集系数为0.175 53,这些数据说明图1的现代汉语复句关系词搭配网络具有典型的“小世界效应”[1]。它体现了汉语“复句关系词本体知识库”中的470个搭配关系词之间的搭配关系都具有较好的搭配能力和大小不同的搭配强度。
5 现代汉语复句关系词搭配网络中的度分布
定义5 节点“平均度”: 在复杂网络中,所有节点i的度ki的平均值就叫做该网络的节点“平均度”,用
(9)
于是,复杂网络中节点的度的分布情况就可以采用度分布函数P(K)来刻画[1,5]。
定义6 度分布函数P(K): 设网络中一个随机选定的节点的边的条数为N,该节点的度为k,于是度分布函数如式(10)所示。
(10)
式(10)中,K表示该节点的度的参数;P(k)的含义是: 网络中任意一个随机选定的节点i的度,恰好等于k的概率[1,5]。
在有向网络中,一个节点的度可以划分为“入度”(in-degree)和“出度”(out-degree)两种。所谓节点的入度是指从其他节点指向该节点的边的数目;所谓节点的出度是指该节点指向其他节点的边的数目。
由图1可以统计出470个关系词节点的总入度值是1 979和总出度值是1 979,合计度数是3 958,这些度值就是网络中的实际边数。
根据式(9),图1中470个关系词节点i的平均度

(11)
在现代汉语复句关系词搭配网络中,平均度
复杂网络中的度分布概率刻画了该复杂网络的“无尺度”现象,利用式(10)可以计算出“现代汉语复句关系词搭配网络”中470个节点的度分布概率,这些概率值进一步刻画了图1是一种典型的“无尺度语言网络”。表3给出了图1中部分复句关系词节点的度分布数据及其度分布概率值,图4给出了部分节点的概率分布情况。
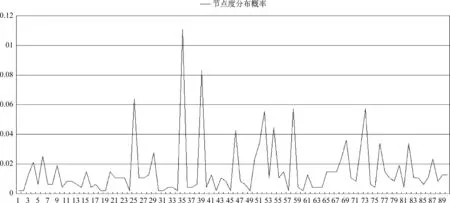
图4 图1中部分节点的度的概率分布图
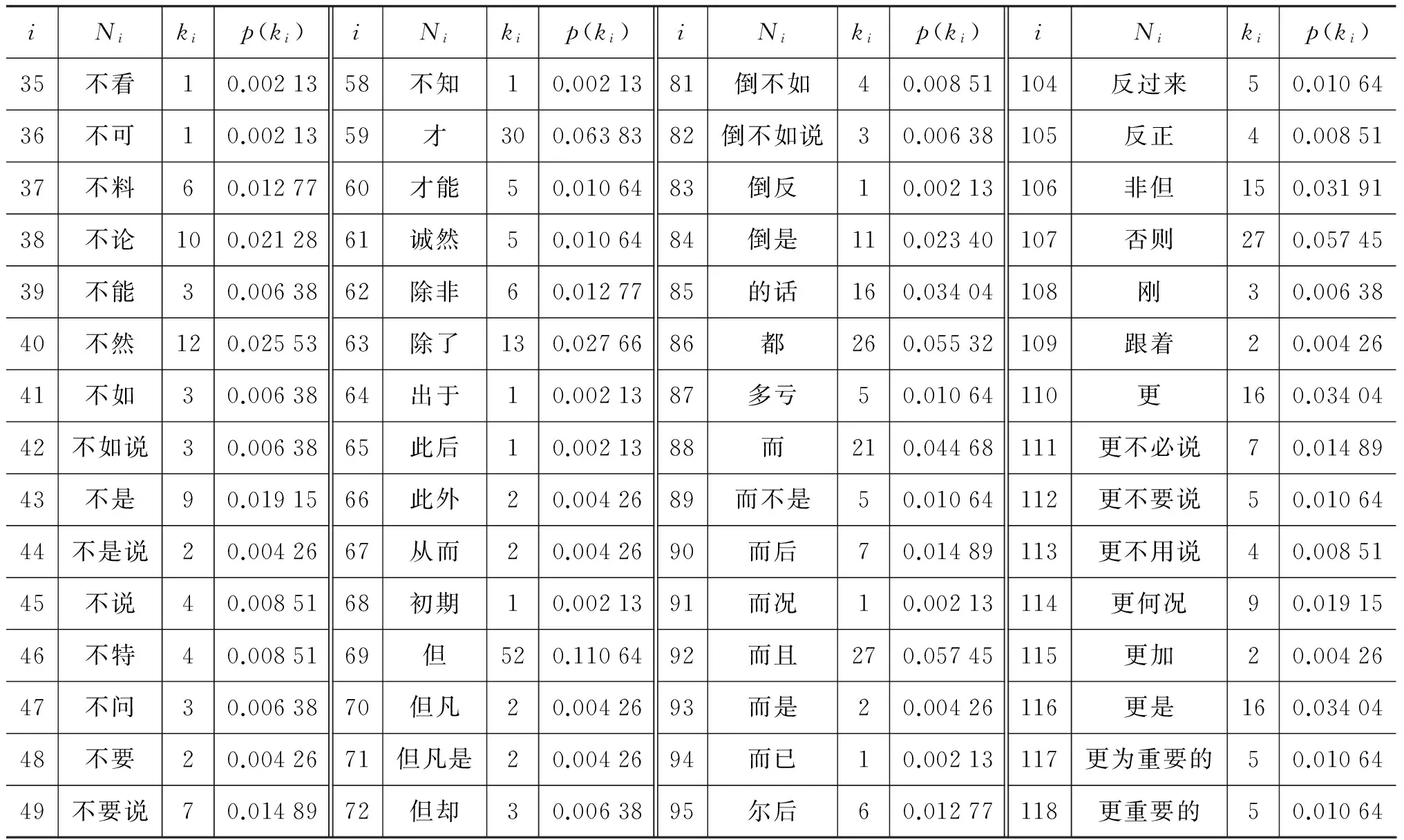
iNikip(ki)iNikip(ki)iNikip(ki)iNikip(ki)35不看10.0021358不知10.0021381倒不如40.00851104反过来50.0106436不可10.0021359才300.0638382倒不如说30.00638105反正40.0085137不料60.0127760才能50.0106483倒反10.00213106非但150.0319138不论100.0212861诚然50.0106484倒是110.02340107否则270.0574539不能30.0063862除非60.0127785的话160.03404108刚30.0063840不然120.0255363除了130.0276686都260.05532109跟着20.0042641不如30.0063864出于10.0021387多亏50.01064110更160.0340442不如说30.0063865此后10.0021388而210.04468111更不必说70.0148943不是90.0191566此外20.0042689而不是50.01064112更不要说50.0106444不是说20.0042667从而20.0042690而后70.01489113更不用说40.0085145不说40.0085168初期10.0021391而况10.00213114更何况90.0191546不特40.0085169但520.1106492而且270.05745115更加20.0042647不问30.0063870但凡20.0042693而是20.00426116更是160.0340448不要20.0042671但凡是20.0042694而已10.00213117更为重要的50.0106449不要说70.0148972但却30.0063895尔后60.01277118更重要的50.01064
表3中,i为图1中关系词节点的编号,Ni为该节点名,ki为该节点的度,p(ki)为该关系词节点的度分布概率值。
6 结束语
本文基于复杂网络的理论与研究方法对汉语复句关系词本体知识库中470个搭配关系词进行分析
研究,构建了一个现代汉语复句关系词搭配网络,得到470个节点间的最短路径长度、网络的聚集系数和度分布等三大基本统计值,这些统计值是复句关系词搭配能力和搭配对象之间的关系,以及它们的搭配强度的反映。通过对现代汉语复句关系词搭配网络的三大统计特征的分析研究,可进一步探讨复句的层次关系和复句逻辑语义关联的特点与规律,是进一步研究复句层次关系和复句逻辑语义自动识别、自动处理的重要基础与理论依据。
现代汉语复句关系词搭配网络是基于汉语“复句关系词本体知识库”而构建的,它具有典型的动态性,所以从分类模型角度分析,它属于动态网络;而从搭配角度分析,它是共现网络;从搭配关系词本体角度分析,它是典型的语义网络;从搭配关系词的前呼和后应关系角度分析,它是一种依存关系网络[7]。
汉语复句是连接分句与篇章的桥梁,是汉语语法的重要实体单位,它表达的语义信息丰富而复杂,所以研究复句和复句关系词的计算机自动识别与处理显得更为重要、更加迫切,然而这又是非常艰难的研究任务。本文所研究的现代汉语复句关系词搭配网络的平均路径长度、聚集系数、度分布等统计特征,体现了现代汉语复句关系词之间的搭配能力和搭配强度,文献[25]指到,搭配能力和搭配强度是进一步研究复句层次关系和复句逻辑语义自动识别的基础。所以,在本文的研究基础上,将进一步研究现代汉语复句关系词搭配依存网络,为深入研究现代汉语复句层次关系和复句逻辑语义的计算机自动识别与自动处理奠定基础。
[1] 汪小帆,李翔,陈关荣编著.复杂网络理论及其应用[M].北京: 清华大学出版社,2006: 9-29.
[2] D J Watts,S H Strogatz.Collective dynamics of‘small- world’networks[J]. Nature.1998,393(6684): 440-442 .
[3] A L Barabasi,R Albert.Emergence of scaling in random networks[J].Science.1999, 286(5439): 327-335.
[4] Barabási A L. Linked: The New Science of Networks. Massachusetts[M].Persus Publishing, 2002: 223-256.
[5] 周涛,柏文洁,汪秉宏等.复杂网络研究概述[J].系统工程理论与实践,2005,34(1): 31-36.
[6] 范超,王厚峰.社交网络中的社团结构挖掘[J].中文信息学报,2014,28(1): 56-63.
[7] 韩普,王东波,路高飞,等.语言网络研究进展[J].中文信息学报,2014,28(1): 9-18.
[8] Amancio D R,Antiqueira L Pardo T A S,etl.Complex networks analysis of manual and machine translations[J].International Journal of Modern Physics C.2008,19(4): 583-598.
[9] 刘海涛.汉语语义网络的统计特征[J].科学通报,2009,54(14): 2060-2064.
[10] Cancho R F I,Sole R V.The Small World of Human Langquage[C]//Proceedings of the the Royal Society of London Series B-Biological Sciences,2001(1482): 2261-2265.
[11] 韦洛霞,李勇,李伟,等.汉字网络的3度分隔与小世界效应[J].科学通报,2004,49(24):2615-2616.
[12] 韦洛霞,李勇,康世勇,等.汉语词组网的组织结构与无标度特性[J].科学通报,2005,50(15): 1575-1579.
[13] 刘知远,孙茂松.汉语词同现网络的小世界效应和无标度特性[J].中文信息学报,2007,21(6):52-58.
[14] 刘知远,郑亚斌,孙茂松.汉语依存句法网络的复杂网络性质[J].复杂系统与复杂性科学,2008,5(2): 37-45.
[15] 刘海涛.汉语句法网络的复杂性研究[J].复杂系统与复杂性科学.2007,4(4): 38-44.
[16] 赵鹏,蔡庆生,王清毅,等.一种基于复杂网络特征的中文文档关键词抽取算法[J].模式识别与人工智能,2007,20(6): 827-831.
[17] 刘海涛.语言复杂网络的聚类研究[J].科学通报,2010,55(27-28): 2667-2674.
[18] 陈芯莹,刘海涛.汉语句法网络的中心节点研究[J].科学通报,2011,56(10): 726-731 .
[19] Yu S,Liu H,Xu C.Statistical properties of Chinese phonemic networks[J].Physics A.2011,390(7): 1370-1380.
[20] 赵辉,刘怀亮,范云杰.复杂网络理论在中文文本特征选择中的应用研究[J].现代图书情报技术,2012,224(9): 23-28.
[21] 孙茂松,刘 挺,姬东鸿,等.语言计算的重要国际前沿[J].中文信息学报,2014,28(1):1-8.
[22] 邢福义.汉语复句研究[M].北京: 商务印书馆,2001: 26-37.
[23] 鲁松,白硕,李素建,等.汉语多重关系复句的关系层次分析[J].软件学报,2001,12(7): 987-995.
[24] 孙茂松,王昌宁,方捷.汉语搭配定量分析初探[J].中国语文,1997,256(1): 29-38.
[25] 姚双云.复句关系标记的搭配研究[M].武汉: 华中师范大学出版社.2008: 75-180.
[26] 姚双云,胡金柱,等.关联词搭配的自动发现[J].计算机应用研究,2011,28(12): 4426-4428,4432.
[27] 鲁松,宋柔.汉英机器翻译中描述型复句的关系识别与处理[J].软件学报,2001,12(1): 83-93.
[28] 胡金柱,吴锋文等.汉语复句关系词库的建设及其利用[J].语言科学,2010,(2): 133- 142.
[29] Huanshen Jia,Haixing Zhao.Spanning Trees in a Class of Four Regular Small World Network Computer Science and Application[J].2014,4(4): 43-49.
[30] Ke Zhang,Haixing Zhao,Faxu Li,et al.A Kind of Deterministic Small-World Networks Model and Analysis of Their Characteristics[J].2014,4(4): 27-31.
[31] 刘云.汉语虚词知识库的建设[M].武汉: 华中师范大学出版社.2009: 204-302.
[32] Hu Quan,Liu yanshen,et al. Research on the Automatic Identification method of the Collocation of Relative Word in Chinese Complex Sentences[C]//Proceedings of the 2013 3rd International Conference on Advanced Materials and Information Technology Processing, Los Angeles, CA, USA.2013,10: 1-2.
Statistical Analysis of the Collocation Networks of Relative Words in Chinese Complex Sentences Based on Complex Network Theory
HU Quan1, XIE Fang2, LI Yuan3, LIU Yanshen1
(1. College of Physical Science and Technology,Central China Normal University, Wuhan, Hubei 430079, China;2. College of Computer, Hubei University of Technology, Wuhan, Hubei 430068, China;3. College of Computer, Central China Normal University, Wuhan, Hubei 430079, China)
The relative words are markers in Chinese Complex Sentences, indicating the relationships between the clauses. The collation relationship of relative words means the co-occurrence form of one or more relative words in one complex sentence. It can influence the semantic and gradation relationship of the clauses. This paper constructs a Collation Network of relative words of Chinese Complex Sentences with 470 relative words based on the complex networks. We study the characteristics of average length of path, clustering coefficient, and distribution of degree depending on the collation network. These results can be applied to analyze the collation strength of relative words, which might help identify the gradation relationship and logic semantics of complex sentence automatically.
the collocation of relative words of Chinese complex sentences;complex networks;average path length;clustering coefficient; distribution of degree

胡泉(1980—),博士,讲师,主要研究领域为计算机软件工程和中文信息处理。E-mail:123750955@qq.com谢芳(1981—),博士,讲师,主要研究领域为业务流程建模、自然语言处理。E-mail:33460694@qq.com李源(1972—),博士,副教授,主要研究领域为计算机软件工程和中文信息处理。E-mail:yuanli@mail.ccnu.edu.cn
1003-0077(2016)04-0056-09
2014-03-08 定稿日期: 2015-01-30
国家社科青年基金(13CYY037);教育部社科基金(14YJA740020);国家自然科学基金(61177063)
TP391
A
猜你喜欢
成都理工大学学报·社会科学版(2022年1期)2022-05-26
韩国语教学与研究(2021年2期)2021-11-24
华北电力大学学报(社会科学版)(2021年2期)2021-07-21
延边大学学报(社会科学版)(2021年4期)2021-07-14
汉字汉语研究(2020年3期)2020-12-14
山西教育·招考(2020年3期)2020-05-14
开放教育研究(2020年2期)2020-03-31
山西教育·招考(2019年3期)2019-09-10
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
