
基于PDTB体系的隐式篇章关系识别
2016-05-03 13:12周国栋
中文信息学报 2016年4期
李 生,孔 芳,周国栋
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
基于PDTB体系的隐式篇章关系识别
李 生,孔 芳,周国栋
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
识别隐式篇章关系是篇章分析领域中非常有挑战的一个任务。该文基于PDTB语料提出一个隐式篇章分析识别方法,使用传统的特征如动词,极性和句法推导规则等,系统分析了它们对隐式篇章分析的影响。我们利用全部标注数据构建多个分类器并使用加法规则融合分类结果,此外还通过前向特征选择算法确定各分类任务最优的特征集。实验结果表明该方法能显著提升隐式篇章分析的性能。
篇章处理;隐式篇章关系;宾州篇章树库
1 引言
篇章分析旨在确定文本的内在结构,篇章语义关系识别是篇章分析的重要组成部分,它对自然语言处理的其他任务(如信息抽取,自动摘要以及统计机器翻译等[1-3])起着重要的作用,近年来已逐渐成为研究的热点之一。篇章语义关系包含两类: 显式篇章关系(Explicit Discourse Relation),即文本单元间存在显式的篇章连接词(如because,but,so等等);隐式篇章关系(Implicit Discourse Relation),即文本单元间没有显式的连接词,它们间的逻辑语义关系可根据上下文推理出来。已有的相关研究表明,由于篇章连接词在表达的逻辑语义上极少有歧义[4],相对与隐式篇章关系的识别,显式篇章关系的识别要容易的多,性能也更好。例如,在PDTB(Penn Discourse Treebank[5])体系下,仅使用连接词及其前后一个词作为特征,英文显式篇章关系识别在顶层的四大类上就取得了96%的F1值。另一方面,没有了连接词的指引,隐式篇章关系识别任务要困难得多。考虑词法、句法、语义、依存,以及其他大量上下文统计信息,PDTB体系下,顶层四大类隐式关系识别的性能仍然低于50%。但PDTB语料的统计表明,英文中隐式篇章关系约占篇章关系的40%(16224/40600)[4],显然,隐式篇章关系识别的性能已成为篇章关系识别,以及整个篇章分析的瓶颈。
本文主要关注PDTB体系下隐式篇章关系的识别。借鉴已有的研究成果,首先构建了隐式篇章关系识别的基准系统;针对数据分布的不平衡性,将多元分类拆解成多个二元分类问题,并借助分类器融合技术最大化的使用标注语料;考虑不同特征对多个二元分类的贡献度不同,使用前向特征选择算法为不同的二元分类选择最优的特征集合;最后依据最大概率原则,将多个二元分类器融合,形成更加可靠的多元分类结果。PDTB语料上的实验结果表明给出的问题解决方案能很好地提升隐式篇章关系识别的性能。
本文其他部分的组织如下: 第二节简单介绍了PDTB体系及标注语料;第三节给出了PDTB体系下隐式篇章关系识别的相关研究;第四节使用传统的词法、句法、语义和上下文信息,构建了多元分类的隐式篇章关系识别基准系统,并给出了PDTB语料上的实验结果;针对数据的不平衡性以及不同类别的隐式关系依赖不同的特征组合的问题,第五节借助多分类器融合技术和特征选择算法给出了相应的解决方案;最后对本文的工作进行了总结,并对下一步工作进行了展望。
2 PDTB体系及标注语料
近年来,篇章理论的发展以及大规模篇章语料的构建,使得篇章级的分析应用越来越受到研究者的关注。2008年发布的最新版的宾州篇章树库(The Penn Discourse Treebank,PDTB)是一个在D-LTAG[6]框架下标注的篇章级语料库。它以词法为基础,标注了谓词论元形式的篇章结构。该语料库同时还和宾州树库(The Penn Treebank,PTB)[7]进行了对齐,研究者可以很方便的从词法、句法、语义等多个视角分析篇章。PDTB语料库标注了显式和隐式两类关系。其中显式关系由连接词触发,驱动两个论元Arg1和Arg2,形成的关系都具有明确的语义类别。例1是摘自PDTB语料中编号wsj2100文章中的一个显式的Comparison关系,其中But是该关系的篇章连接词。
例1 Arg1: Eventually viewers may grow bored with the technology and resent the cost.
Arg2:But right now programmers are figuring that viewers who are busy dialing up a range of services may put down their remote control zappers and stay tuned.
(Comparison -wsj 2100)
而隐式关系没有连接词,关系语义需要从两个论元的上下文推出。例2是摘自PDTB语料中编号wsj0011文章中的一个隐式的Expansion关系,其中“And”是标注人员从上下文推断出的最适合表达该关系的篇章连接词。
例2 Arg1: From January to October, the nation’s accumulated exports in- creased 4% from the same period last year to $50.45 billion.
Arg2: [And] Imports were at $50.38 billion, up 19%.
(Expansion -wsj 0011)
此外,PDTB体系还提供了三层篇章语义关系的分类体系,表1给出了前两层的语义关系。本文侧重第一层四大类语义关系(即Comparison, Contingency, Expansion, Temporal)的研究。第二层包含16种语义关系,但类别太细,使得数据稀疏和分布不均衡问题更加严重。此外,顶层的四大类语义信息已经能很好的满足大多数其他应用的需求。

表1 PDTB中篇章语义关系的上两层分类
3 相关工作
近年来,篇章理论的发展以及大规模篇章语料库的构建使得篇章级的分析受到越来越多的关注。识别隐式篇章关系的研究可以归纳为三类: 基于伪隐式篇章关系语料的研究,基于纯隐式篇章关系语料的研究和基于伪隐式和纯隐式的篇章关系混合语料研究。
基于伪隐式关系的研究的代表性工作包括: Marcu和Echihabi[8]首次提出使用无监督的方法识别隐式篇章关系。他们使用一系列文本模式从网络上自动获取语料资源,同时去除篇章连接词构成一个伪隐式篇章关系语料。他们的实验表明使用词对(word-pairs)特征给识别隐式篇章关系提供了帮助。Saito等人[9]扩展了他们的工作,从文本域中提取短语模式特征,实验表明同样有助于提高隐式篇章分析的性能。尽管如此,我们认为伪隐式篇章关系并不能从真正意义上代表纯隐式篇章关系,因为它们在表示关系上存在着很多不同,比如隐式关系的存在表明上下文的联系足够强而不需要使用篇章连接词来衔接。
随着PDTB 2.0的发布,该语料显式的区分了隐式篇章关系和显式篇章关系,并且仅针对段落内相邻句子间的隐式篇章关系进行标注。至此,很多工作开始侧重研究纯隐式篇章关系识别。这方面代表性的工作包括: Pitler等人[10]首次提出使用不同的语言学特征,比如动词,极性和上下文环境等,识别隐式篇章关系。Lin等人[11]受Pitler等人的启发,首次提出使用两类句法特征,即成分句法推导规则和依存句法推导规则,来识别PDTB中第二层隐式篇章关系。Park和Cardie[12]使用了贪婪的特征选择算法确定了识别隐式篇章关系的最优特征子集。他们的实验在第一层四大类关系上取得了最好的F1值。
近年来,一些研究表明样本不平衡问题成为了提高隐式篇章分析性能的重大阻碍。有人提出使用伪隐式和纯隐式关系混合的篇章关系分析。相关工作包括: Zhou等人[13]使用语言模型去计算困惑度来判断相邻句子间插入连接词的合理性。Biran和McKeown[14]使用聚集词对尝试解决特征稀疏问题,但他们的实验表明性能提升很小。为了解决隐式关系标注样本缺少的问题,Lan等人[15]提出使用多任务学习的方法引入伪隐式篇章关系来辅助隐式篇章关系识别。周等人[16]提出一种基于信息检索的无监督方法识别隐式篇章关系,他们利用Web上的资源提取大量的伪隐式关系辅助识别隐式篇章关系。
尽管这些研究都表明了隐式篇章分析在一定程度性能得到了提升,但他们的结果却很难公平的比较,因为他们各自使用了不同的数据切分方法。基于前人提出的有效特征,本文首先使用PDTB语料构建了能进行顶层四大类语义关系识别的基准系统;针对数据分布的不均衡性,给出了借助多个二元分类间接完成多元分类任务的解决方案,并借助多分类器融合技术,最大化的利用标注语料;分析各特征对不同二元分类任务贡献度的基础上,借助前向特征选择策略,分而治之地为多个二元分类任务选定了最优特征集合,并融合这些二元分类器完成了多元语义关系的识别任务。
4 基准系统: 基于最大熵模型的隐式关系识别方法
使用前人提出的五类有效特征,即动词(Verbs)、极性(Polarity)、情态(Modality)、First-Last,First3和成分句法推导规则(Production rule),本文首先构建了一个对PDTB顶层四大类隐式篇章语义关系进行识别的基准系统。本节详细介绍这一基准系统。
4.1 特征
基准系统并不关注特征集合,仅采用了相关研究中已证实有效的五类特征,它们包括:
1.动词(Verbs)特征: 与Pitler等人给出的动词特征类似,我们首先提取篇章关系中两个论元包含的动词,并将它们组合形成多个动词对(verb-pair),再统计动词对中两个动词的Levin verb class[17]的最高类别相同的数目,将其作为一个特征。此外,我们还引入了两个论元中平均动词短语的长度和两个论元的主动词的词性(本文直接认为论元中的第一个动词作为主动词)这两个与动词相关的特征。统计表明,类别相同的动词对越多,篇章关系越有可能是Expansion类别。
2.极性(Polarity)特征: 直觉上,篇章关系中的两个论元如果包含了极性相反的词对,它们很可能表述Comparison类型的篇章关系。具体地,我们将极性分成积极(positive)、消极(negative)、否定积极(negated positive)和中立(neutral)四类,分别统计两个论元中属于不同极性的词的数目。此外这四个极性的交叉积也被引入作为特征。每个词的极性参考MPQA语料[18]提供的极性信息进行确定,此外,对于否定积极(negated positive),我们使用了General Inquirer Tag语料[19]来判断一个积极(positive)词的紧邻的前文是否还有否定词(negated word),具体算法可参见文献[15]。
3.情态(Modality)特征: 情态词表达了可能性,情态词的出现暗示了两个文本单元间很有可能存在Contingency类别的篇章关系。本文引入了三类与情态相关的特征: 论元中是否有情态动词,论元中具体的情态动词的词频,以及两个论元中不同类型情态词的词频交叉积。
4.First-Last,Fisrt3特征: 这组特征包括: 每个论元中的第一个词,每个论元中的最后一个词,Arg1和Arg2的第一个词的组合,Arg1和Arg2的最后一个词的组合,Arg1的前三个词,以及Arg2的前三个词。需要说明的是,我们并没有对这些词做任何预处理(例如,取词根),而是直接参与特征值的计算。
5.句法推导规则(Production rule)特征: Lin等人[11]的研究表明,论元中的句法规则与某些篇章关系的出现存在一定的相互制约性。本文使用了三个句法推导规则,分别是: 句法规则是否出现在Arg1中,句法规则是否出现在Arg2中和句法规则是否同时出现在Arg1和Arg2中。本文舍弃了那些在训练数据中出现次数小于5的句法规则。
4.2 基于最大熵模型的四元分类
PDTB体系关注的是局部篇章关系,即相邻文本单元间的语义关系,它将隐式篇章关系分成四大类,利用4.1节给出的五类特征,使用最大熵模型,我们构建了一个可对四类语义关系进行识别的四元分类器。
最大熵模型是通过最大熵原理推导出的,该模型的一个优点是可以加入各种不同的特征,其参数化的表示形式如式(1)所示。
(1)
其中,
(2)
这里,x∈Rn为输入,y∈{1,2,…,K}为输出,w∈Rn为权值向量即模型参数,fi(x,y),i=1,2,…,n为任意实数值特征函数,y′∈{1,2,…,k}为可能的输出类别取值。模型学习时在给定训练数据条件下对模型进行正则化极大似然估计,本文采用L1范式的正则化模型来防止过拟合,即优化如下目标函数,如式(3)所示。
(3)
我们选择能极大化目标函数L(w)的模型参数w*,即
(4)
实际中我们采用L-BFGS梯度优化算法寻求最优模型参数,γ可以通过在开发集上调参得到最优结果。
4.3 实验结果与分析
实验设置
本文所有实验均使用PDTB2.0语料,将其中的section 02-20作为训练集,section21-22作为测试集,section 00-01作为开发集。与Zhou等人[13]的实验设置一致,本文只关注隐式篇章关系的识别。PDTB语料中将非显式篇章关系(non-Explicit)细分成隐式篇章关系(Implcit),实体关系(EntRel),AltLex关系和没有关系(NoRel)四种,构建训练模型时,仅Implicit类型的篇章关系参与训练实例的生成,测试时则考虑了Implicit和NoRel两种类型。文中所有实验均使用PTB(Penn Treebank)语料提供的标准句法树。Mallet*http://mallet.cs.umass.edu提供的L1正则化的最大熵模型被用于分类器的构建,所有参数均采用默认值。系统性能的评测指标采用的是标准的准确率(Precision),召回率(Recall),F1值和正确率(Accuracy)。值得说明的是,PDTB语料在进行关系语义类别标注时允许出现某一关系具有多个语义类别的情况,本文统一仅考虑第一个语义类别。
实验结果及分析
表2给出了基准系统的实验结果。从实验结果我们可以发现,在四类关系的识别中,Expansion类型的识别取得了最好的F1性能,为58.50%,而Temporal关系的识别性能最差,F1值仅为8.57%。Comparison和Contingency类型的关系识别性能也只取得了32.41%和32.09%的F1值。但系统的总体正确率却达到了43.25%。
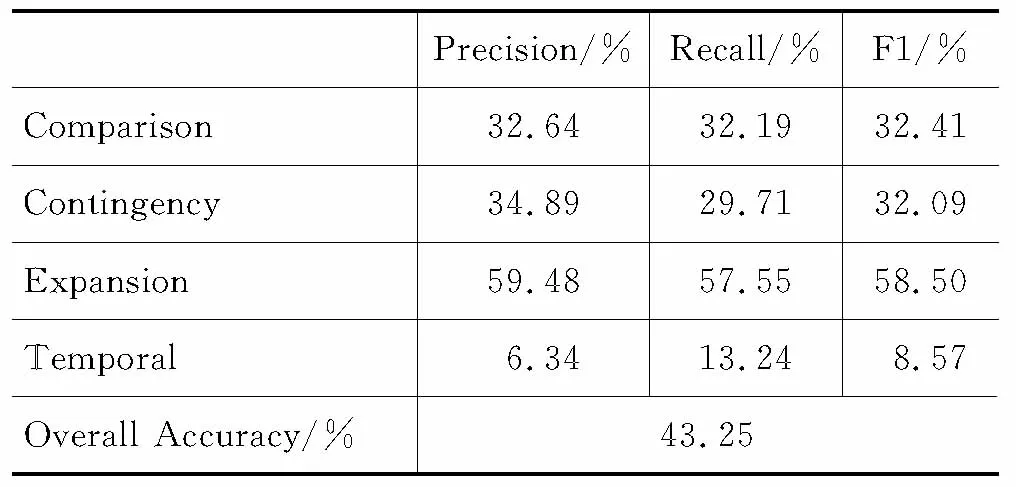
表2 四元分类的隐式篇章关系识别性能
从表3给出的统计数据不难发现:
1) 四类关系的分布是非常不平衡的。Expansion关系占到了50%以上,而Temporal关系仅有5%~6%。因此不难理解四元分类结果中,Expansion关系的识别性能最好,而Temporal关系的识别性能最差。
2) 虽然基准系统的整体正确率达到了43.25%,但如果我们使用多数原则将所有关系都标注成Expansion类型,依据测试集的分布,系统的整体正确率为52.5%,高于我们的基准系统。因此可以看到,篇章分析中系统的整体正确率并不能准确的衡量系统的性能。
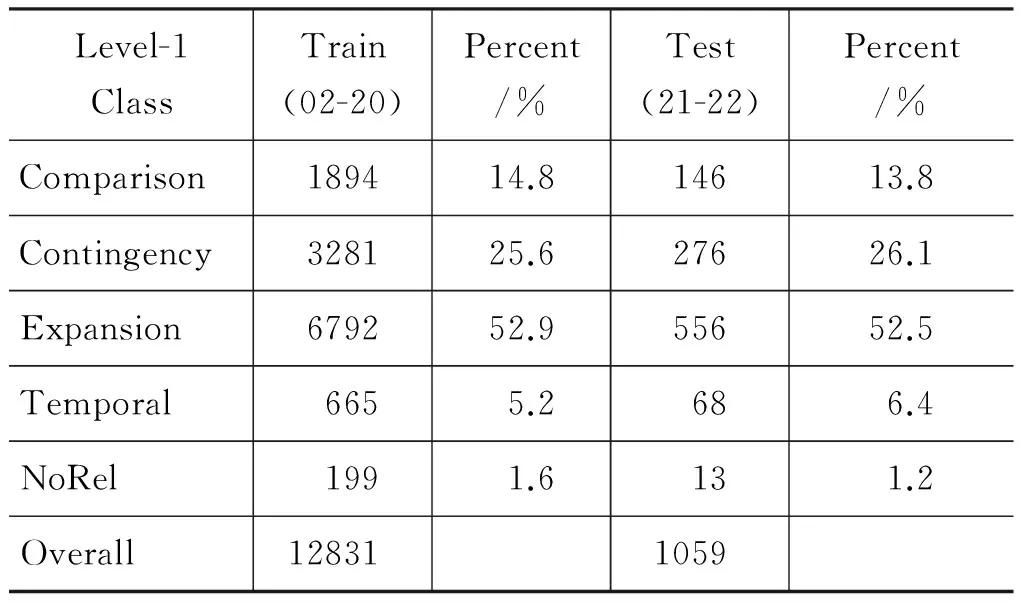
表3 训练集和测试集各关系实例分布情况
5 改进系统: 基于分类器融合的隐式关系识别方法
分析基准系统的性能以及语料分布的情况可以发现:
1) 数据分布的不平衡,使得系统的性能偏向实例较多的Expansion类型,相对的,实例较少的Temporal类型的关系识别性能极低。
2) 采用统一的特征集识别所有类型的篇章关系并不合适。例如,直觉上极性特征对Comparison类型的关系更有效,而动词特征更利于Expansion类型的关系识别。
上述问题可以借助分类器融合技术进行改进。针对第一个问题,我们借鉴LibSVM[20]中将多元分类问题分解成多个一对多分类器决策的过程,将隐式篇章关系的识别拆解成四个二元分类问题;针对第二个问题,在拆解成多个二元分类问题的基础上使用前向特征选择算法[21]为每种篇章关系识别任务选择不同的最优特征子集。下面分别介绍多个二元分类器的构建和最优特征子集的选择。
5.1 多个二元分类器的构建
多元分类可以借助多个二元分类任务完成,但语料中篇章关系分布不均衡的状况仍然存在。例如,构建Temporal类型的关系识别模型时,训练集中包含665个Temporal类型的篇章关系(即正例),11 967个其他类型的篇章关系(即,1 894个Comparison类型,3 281个Contingency类型和6 792个Expansion类型的篇章关系,它们都被看作负例)。对此,常见的方法在构建训练集时通过欠采样(Down-sampling)负样本来构建一个正负例平衡的分类器。但是欠采样方法的明显缺点就是舍弃了大量的标注样本,未能重复利用所有标注数据,然而标注样本是极其宝贵的资源。因此,本文借助分类器融合技术极大化地利用所有的标注数据。我们同样以Temporal类型为例。将负例按照正例的数目划分,在我们的例子中负例被分成17份,每份包含665个负例。然后用正例和这17份负例分别构建17个分类器。最后通过加法规则去融合多个分类器的结果来确定最终的关系类别。加法融合规则如式(5)所示。
(5)
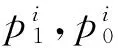
5.2 最优特征子集的选择
不同的特征对不同类型的篇章关系识别的贡献度并不相同,将多元分类问题拆解成多个二元分类任务后,为每个二元分类任务选定合适的最优特征子集是非常自然的。借助开发集,我们针对每个二元分类任务采用前向特征选择算法进行了最优特征子集的选择。图1给出了前向特征选择算法的流程,从算法流程可以看到,该算法是一个贪心选择算法。
5.3 实验结果与分析
使用与4.3节相同的实验设置,同样采用Mallet提供的L1正则化最大熵模型构建二元分类器,改进方法得到了如下实验结果。
特征贡献实验
我们首先分析了五类特征对多个二元分类任务的贡献度。表4给出了具体的实验结果, 表格最后一列也给出了使用全部五类特征得到的分类器性能。
从表4的结果我们可以看到:
1) 对Comparison关系,尽管我们认为Polarity特征应该在Comparison关系上能获得较好的性能,但实验表明Verbs特征和Product特征取得了最好的性能。比较Polarity和Product特征可以看出,Product特征在F1值上高于Polarity特征约9%。

前向特征选择算法描述:输入:候选特征集FC,训练集TS,开发集DS;输出:该任务的最优特征集FS;开始:1)将FC中的候选特征按照其对系统的单独贡献(如F1值)从大到小进行排序,即FC_sort={f1,f2,…,fn};2)FS={f1},FR=FC_sort-FS;3)循环N次:a)将FR里的每个特征和FS进行特征组合,并依次在DS上进行测试;b)对FR中的特征按照按照a)中的结果从大到小进行排序,如果最好的一个特征结果高于仅使用FS中的特征结果,则将该特征加入到FS中;反之则退出循环;c)FR=FC_sort-FS,若FR=⌀,则退出循环;4)FS即为该任务的最优特征集。图1 前向特征选择算法
2) 对Contingency关系,情态特征Modality表达了可能性意义,从实验结果来看该特征的确取得了较好的性能,F1值在47.97%。另外,仅使用Product特征下得到了最好的性能F1值为48.95%。
3) 对Expansion关系,Expansion关系在整个数据分布中是比例最多的关系,我们认为动词的特征能够获得较好的分类性能,实验中我们发现First-Last,First3特征取得了最好的F1性能66.87%,而相对应的Verbs特征仅有64.19%。
4) 对Temporal关系,时序关系是分布最少的关系约5%~6%,这给分类造成了一定的难度。实验中我们发现仅用Product特征能取得最好的F1性能19.69%。此外Verbs特征和Modality特征也能获得较好的性能。
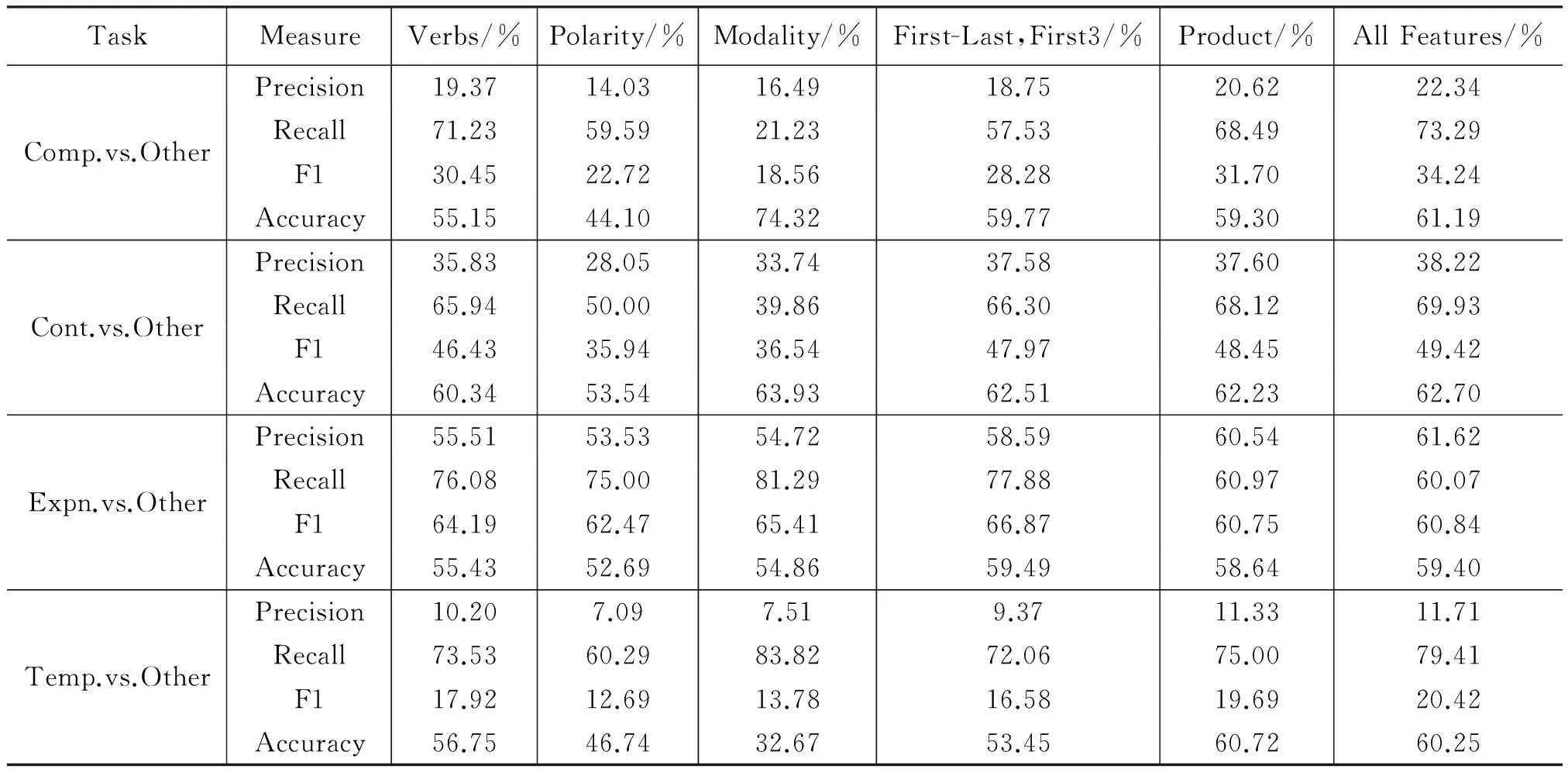
表4 每类特征对各任务的贡献
总结各类特征对不同二元分类任务的贡献度,我们发现:
1) Product特征在Expansion除外的其他三类关系的识别中都取得了最好的性能。这一结论与Park和Cardie的结论吻合。针对Expansion关系的识别,使用First-Last,First3特征可以得到最佳结果。
2) 每个分类任务的最优性能可能不是由我们直觉上认为合适的特征得到的,需要从实验数据推断出。以Comparison为例,极性特征Polarity的不如动词特征Verbs的性能好,这说明Comparison关系中并非总是存在Polarity相异的词。同样的以Expansion为例,我们的最优性能也并非是动词特征Verbs得到的。
3) 每个分类任务可能存在不同的最优特征组合。以Expansion为例,使用单个特征First-Last,First3,系统获得了最好的F1性能66.87%,但使用全部五类特征,系统的F1值仅为60.84%,可以推断该关系的最优特征组合并不是全部的五类特征。
前向特征选择实验
在开发集(00-01)上借助前向特征选择算法进行最优特征子集的选定,然后使用选定的最优特征子集在测试集上进行测试,我们得到了如表5所示的结果。

表5 最优特征子集下的各二元分类任务的性能
表5的第二列给出了开发集上为各二元分类任务选定的最优特征组合。可以看到,每类篇章关系所选定的最优特征子集是不一样的。使用所有五类特征,Comparison关系的识别获得最佳性能;而1&4&5特征的组合,即Verbs特征、First-Last,First3特征和Product特征的组合,Contingency类别的识别获得了最佳性能;Expansion关系在Modality特征和First-Last,First3特征的组合下可以得到最好的F1值;而对Temporal关系而言,最优特征组合是Modality和Product特征。
选定最优特征组合后,借助最优特征子集,我们重新对测试集进行了评测,表5中的第3~6列分别给出了系统的Precision、Recall、F1值和Accuracy。对比表4我们可以发现,四类关系的识别性能均有所提升,特别是Comparison类型的关系识别,提升最为明显。
与state-of-the-art系统的比较
我们的实验数据的划分与Zhou等人[13]的研究一致,表6给出了两个系统结果的比较。从比较结果来看,在Comparison和Contingency关系上我们的识别性能显著优于Zhou等人的系统,在Temporal关系上我们取得了与之可比较的性能,而在Expansion关系的识别上,我们系统的性能低于Zhou等人的性能,F1值相差约3%。对于这一结果,我们分析了各自方法上的差异。
1) 在每个二元分类任务中,借助多分类器融合技术, 我们使用了全部的标注数据构建多个分类器
进行决策,而Zhou等人[13]的系统采用欠采样负样本的方式随机选择了部分数据构建二元分类器进行实验,其结果具有一定的随机性。
2) 我们通过特征选择算法使用开发集确定了最优的特征组合,而Zhou等人[13]的结果仅使用单个特征。Zhou等人[13]的最优结果是应用了语言模型特征辅助得到的,在没有语言模型的情况下,Expansion关系的识别F1值仅有65.95%,略低于我们的最优结果。
3) 前向特征算法在Temporal关系上陷入了局部最优解,实验表明使用全部的五类特征,系统F1可达到20.42%(表4)。
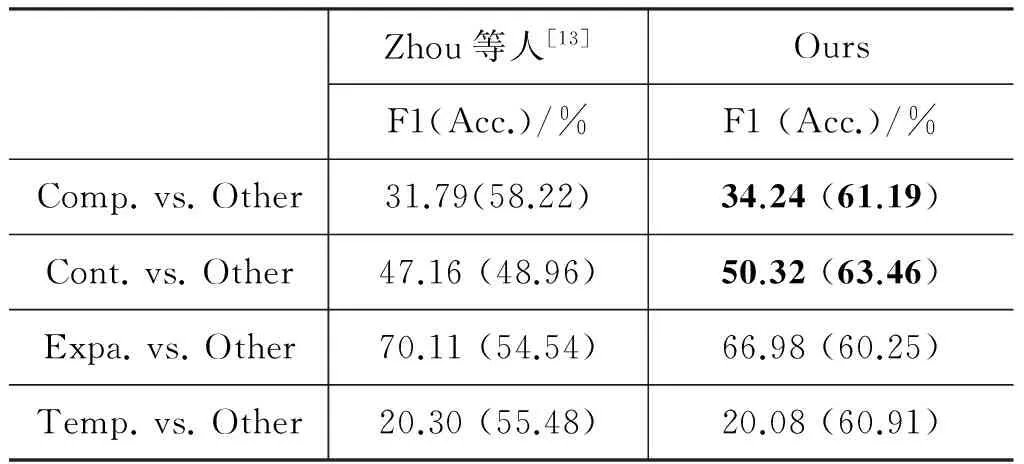
表6 与Zhou等人[13]系统进行比较结果
隐式关系识别性能实验
构建生成四个二元分类器后,我们采用类似于LibSVM的策略,选取四个分类器中概率最大的语义类别最为最终的结果。表7给出了基于四个二元分类器融合的隐式关系识别的性能(括号中列出了第4.3节中表2给出的基准系统的对应结果)。
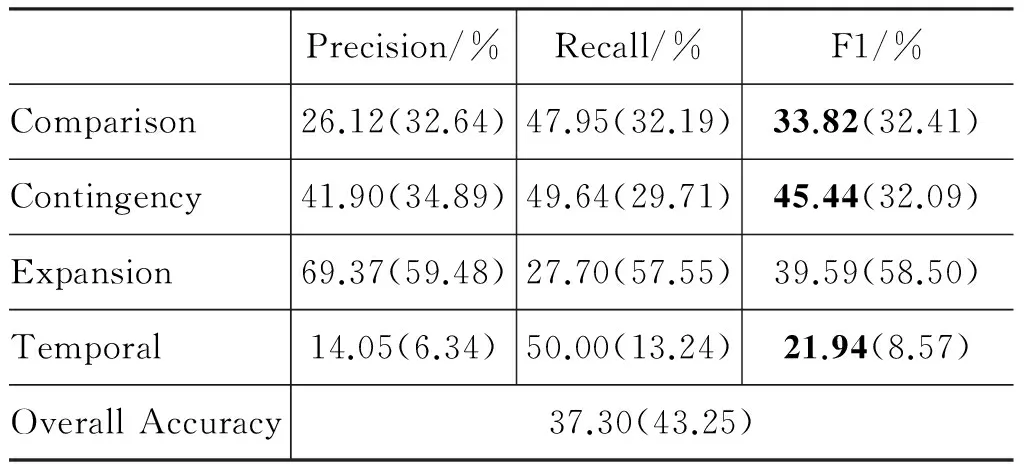
表7 一对多策略的四路识别性能
分析表7的实验结果可以发现:
1) 通过一对多策略,除Expansion关系外,其他关系的识别性能都有所提升,尤其是样本数目最少的Temporal关系的识别,其F1值提升了约13%。相对而言,Expansion关系的性能下降了,这主要是由于系统召回率大幅降低。
2) 虽然除Expansion关系外,每类关系识别的性能都有所提升,但隐式篇章分析的整体正确率目前仅有37.30%,还不能有效地应用到其他自然语言处理任务中。
6 总结
使用传统的词法、句法、语义和上下文信息,首先构建了多元分类的隐式篇章关系识别基准系统;通过对实验结果和语料中关系分布不均衡问题的分析提出了借助多分类器融合技术和特征选择算法进行系统优化的解决方案。PDTB语料上的实验结果表明,提出的解决方案方案能有效地提升隐式篇章关系识别的性能。目前隐式篇章关系识别的总体正确率仍然偏低,还不能很好地服务于其他自然语言处理任务,在未来的工作中,我们将尝试借助大规模的未标注数据来辅助隐式篇章关系的识别。
[1] Lin Z, Liu C, Ng H T, et al. Combining coherence models and machine translation evaluation metrics for summarization evaluation[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics. 2012:1006-1014.
[2] Meyer T, Webber B. Implication of discourse connectives in (machine) translation[C]//Proceedings of the Workshop on Discourse in Machine Translation. 2014:19-26.
[3] Ng J P, Kan M Y, Lin Z, et al. Exploiting discourse analysis for article-wide temporal classification[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. 2013:12-23.
[4] PDTB-Group. The Penn Discourse Treebank 2.0 Annotation Manual[OL]. The PDTB Research Group. 2007.
[5] Rashmi Prasad, Nikhil Dinesh, Alan Lee,et al. The Penn Discourse Treebank 2.0[C]//Proceedings of the 6th International Conference on Language Resources and Evaluation. 2008.
[6] Bonnie Webber. D-LTAG: Extending lexicalized TAG to discourse[M]. Cognitive Science, 2004, 28(5):751-779.
[7] Mitchell P Marcus, Beatrice Santorini, Mary Ann Marcinkiewicz. Building a Large Annotated Corpus of English: the Penn Treebank[J]. Computational Linguistics, 1993, 19(2):313-330.
[8] Marcu D, Echihabi A. An unsupervised approach to recognizing discourserelations[C]//Proceedings of 40th Annual Meeting of the Association for Computational Linguistics. 2002:368-375.
[9] Saito M, Yamamoto K, Sekine S. Using phrasal patterns to identify discourse relations[C]//Proceedings of the Human Language Technology Conference of the NAACL. 2006:133-136.
[10] Pitler E, Louis A, Nenkova A. Automatic sense prediction for implicit dis- course relations in text[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP. 2009:683-691.
[11] Lin Z, Kan M Y, Ng H T. Recognizing implicit discourse relations in the Penn Discourse Treebank[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing. 2009:343-351.
[12] Park J, Cardie C. Improving implicit discourse relation recognition through feature set optimization[C]//Proceedings of the 13th Annual Meeting of the Special Interest Group on Discourse and Dialogue. 2012: 108-112.
[13] Zhou Z M, Xu Y, Niu Z Y, Lan M, et al. Predicting discourse connectives for implicit discourse relation recognition[C]//Proceedings of the Coling 2010: Posters. 2010: 1507-1514.
[14] Biran O, McKeown K. Aggregated word pair features for implicit discourse relation disambiguation[C]// Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. 2013:69-73.
[15] Lan M, Xu Y, Niu Z. Leveraging synthetic discourse data via multi-task learning for implicit discourse relation recognition[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. 2003:476-485.
[16] 周小佩,洪宇,车婷婷等. 一种无指导的隐式篇章关系推理方法研究[J]. 中文信息学报, 2013,27(02):17-25.
[17] B L. English Verb Classes and Alternations: A Preliminary Investigation[M]. Chicago, IL, 1993.
[18] Wilson T, Wiebe J, Hoffmann P. Recognizing contextual polarity in phrase-level sentiment analysis[C]//Proceedings of Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing. 2005:347-354.
[19] Stone P J, Dunphy D C, Smith M S. The General Inquirer: A Computer Approach to Content Analysis[M]. MIT Press, 1996.
[20] Chih-Chung Chang, Chih-Jen Lin. LIBSVM: a library for support vector machines[J]. ACM Transactions on Intelligent Systems and Technology, 2011:1-27.
[21] John G H, Kohavi R, Pfleger K. Irrelevant features and the subset selection problem[C]//Proceedings of the Machine Learning: Proceedings of the Eleventh International. 1994:121-129.
Recognizing PDTB Style Implicit Discourse Relations
LI Sheng, KONG Fang, ZHOU Guodong
(School of Computer Sciences and Technology, Soochow University, Suzhou, Jiangsu 215006, China)
Recognizing implicit discourse relation is a challenging task in discourse parsing. In this paper, we propose an implicit discourse relation recognizing method in the Penn Discourse Treebank (PDTB) considering some traditional features (e.g., verbs, polarity, production rules, and so on), and provide a systematic analysis for our implicit discourse relation method. We apply all labeled data to build multiple classifiers, and use the adding rule to identify final classification result for each instance. We also use forward feature selection method to select an optimal feature subset for each classification task. Experimental results in the PDTB corpus show that our proposed method can significantly improve the state-of-the-art performance of recognizing implicit discourse relation.
discourse processing; implicit discourse relation; PDTB

李生(1989—),硕士研究生,主要研究领域为自然语言处理,篇章分析。E-mail:shengli.ls@aliyun.com孔芳(1977—),博士,副教授,主要研究领域为机器学习,自然语言处理,篇章分析。E-mail:kongfang@suda.edu.cn周国栋(1967—),博士,教授,主要研究领域为自然语言处理,篇章理解。E-mail:gdzhou@suda.edu.cn
1003-0077(2016)04-0081-09
2014-05-05 定稿日期: 2015-03-09
国家自然科学基金(61472264,61273320,61333018,61331011);国家863项目(2012AA011102)
TP391
A
猜你喜欢
通信技术(2021年12期)2022-01-25
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
自动化学报(2017年5期)2017-05-14
电子制作(2017年23期)2017-02-02
智能系统学报(2015年4期)2015-12-27
民族古籍研究(2014年0期)2014-10-27
航天返回与遥感(2014年5期)2014-07-31
外语教学理论与实践(2014年2期)2014-06-21
中原工学院学报(2014年4期)2014-04-01
