
基于改进的多特征哈希的近重复视频检索
2016-04-05 10:19:56罗红温杨艳芳齐美彬蒋建国合肥工业大学计算机与信息学院安徽合肥30009合肥工业大学电子科学与应用物理学院安徽合肥30009
合肥工业大学学报(自然科学版) 2016年1期
关键词:邻接矩阵
罗红温,杨艳芳,齐美彬,蒋建国(.合肥工业大学计算机与信息学院,安徽合肥 30009;.合肥工业大学电子科学与应用物理学院,安徽合肥 30009)
基于改进的多特征哈希的近重复视频检索
罗红温1,杨艳芳2,齐美彬1,蒋建国1
(1.合肥工业大学计算机与信息学院,安徽合肥230009;2.合肥工业大学电子科学与应用物理学院,安徽合肥230009)
摘要:随着互联网的迅速发展,产生了大量的近重复视频。文章提出了一种改进的哈希算法提高近重复视频的检索准确性,根据语义哈希对图像检索的原理,对算法中的邻接矩阵进行改进。邻接矩阵表示KNN图中样本间的邻接关系,文中不再使用0和1两个值表示样本间的邻接关系,而是引入高斯核函数来表示,提高了模型的检索精度。实验结果表明所提出的方法具有更高的检索精度。
关键词:近重复视频检索;哈希算法;邻接矩阵;高斯核函数;KNN图
齐美彬(1969-),男,安徽东至人,博士,合肥工业大学教授,硕士生导师;
蒋建国(1955-),男,安徽宁国人,合肥工业大学教授,博士生导师.
近重复视频检索的实质是比较2个视频的内在特征,根据结果判断视频是否相似。近重复视频检索一般分为如下3步:关键帧提取、特征提取和检索,其中选择合适的检索方法是近重复视频检索的难点。
近重复视频检索方法一般有如下3类:
(1)直接进行特征匹配的检索方法,需要对视频的关键帧内容两两进行相关性分析。如文献[1]对提取的关键帧的特征进行相关性分析,通过对视频中每2帧内容的相关性进行分析并统计,最终得到能表示视频相似性的参数。文献[2-3]提出了一种分层的方法,首先通过颜色特征过滤一些很不相似的视频,然后采用更精确的局部关键点方法对余下视频进行匹配。这类方法最大的缺点是关键帧间的局部关键点两两比较计算量非常大,因此不适合应用在大规模近重复视频检索上。
(2)通过建立索引进行检索的方法,可以提高检索速度,其中最常用的是KD树,如文献[4-5]中介绍了一些常用的有效的索引方法。文献[6]介绍了树形索引结构在高维空间的最近邻查找。这类方法计算量虽然减少了,但是当特征维度比较大时,树形索引往往效果较差,出现所谓的“维度灾难”。
(3)语义哈希的检索方法。其准则是在原始空间中相似的视频有相似的哈希码。其原理是利用图的拉普拉斯矩阵[7]进行编码,最终经语义哈希映射成的二进制码把训练集高度压缩,其结果能代表训练集的内容,同时该方法在汉明空间中求异或操作速度很快。因此语义哈希被广泛应用在近重复视频检索上。
前期的基于语义哈希的检索都是应用单特征,并且采用现有的哈希函数模型,如文献[8]介绍了谱哈希应用在大规模数据集上。采用谱哈希的方法进行检索大大提高了检索的精度,但是要求训练数据服从统一分布。文献[9]介绍了自学哈希在快速相似性检索上的应用,在谱哈希的基础上提高了检索精度,但是当有新视频时,使用该方法需要重新进行训练。但是这2种哈希方法都只是使用了单特征,并且可扩展性较差。文献[10-11]提出了一种哈希算法,该算法有很强的可扩展性和可移植性,并且同时得到哈希码和哈希函数。该模型简单,对训练数据的分布没有任何限制,准确性、可扩展性和可移植性较强,但是检索精度需要近一步提高。因此本文对该算法进行了改进。
本文在文献[11]的基础上提出了一种改进的多特征哈希的方法,对拉普拉斯矩阵中的邻接矩阵进行改进,用高斯核函数的值来表示邻接矩阵的元素,这样可以更加精确地表示帧间的相似程度,从而提高了模型的检索精度。
1 多特征哈希原理
1.1相关术语和符号
下面介绍模型中相关向量及含义。本文采用了HSV和LBP 2种特征,每个特征对应的训练数据集为:
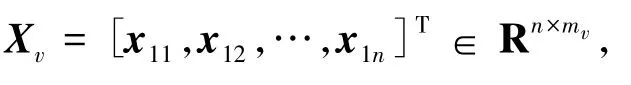
其中,n为训练集中关键帧的总数;mv为第v个特征对应2种特征的维度;Xv为所有关键帧的第v个特征,且v≤2。
某一关键帧的特征向量可以表示为xl=[(x1l)T,(x2l)T]∈R1×(m1+m2),则所有关键帧的全部特征可以被向量X=[x1,x2,…,xn]∈Rn×(m1+m2)表示。线性哈希函数集为{ h1(·),h2(·),…,hp(·)},其中哈希函数如(1)式所示,p为哈希码的码长。
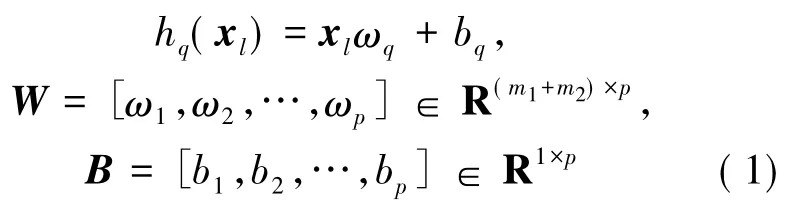
并且定义常用向量I1∈Rn×1为元素值全为1的列向量;I∈Rn×n为矩阵;In∈Rn×n为对角阵,且主对角线上元素的值为1;Id∈R(m1+m2)×(m1+m2)为对角阵,且主对角线上元素的值为1。训练集哈希码为:
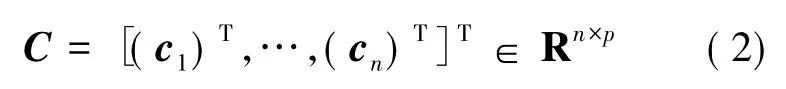
Cv表示第v个特征的哈希码。
1.2多特征哈希模型

在该模型中,采用了拉普拉斯矩阵Lv。拉普拉斯矩阵的定义为:其中,Dv为度矩阵;Gv=Av+δBv,Av为邻接矩阵,Av表示关键帧的单个特征的结构信息;Bv表示关键帧是否属于同一视频;δ表示Av和Bv的权重。Av和Bv表示为:

最终生成的目标函数为:
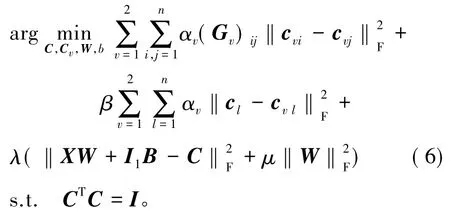
其中,(6)式中第1项表示单个特征的个体的结构信息,第2项表示所有特征的结构信息,第3项保证了哈希函数的经验误差最小。
对(6)式中的目标函数进行化简求解[11],通过化简可以得到训练集的哈希码和一系列的哈希函数。为了进一步提高该模型的检索精度,本文针对模型中的拉普拉斯矩阵进行了改进。
2 改进的多特征哈希
2.1改进后的多特征哈希模型
在多特征哈希模型(MFH)中,采用最简单的0和1来表示邻接矩阵的元素,这种表示虽然简单,但是会导致k近邻中所有数据的值都是一样的,表达结果不精确,从而使检索准确性降低。
本文采用高斯核函数的值来表示邻接矩阵中的元素。采用高斯核函数是因为:高斯核函数对没有先验知识的数据效果最好,并且其值的范围是(0,1)。本文中Av表示了2帧图片特征值的相似程度,2帧图片越接近时,Av值越大。对高斯核函数来说,远离中心时核函数取值很小,每一帧图片特征都可以看作一个中心。改进后的Av定义如下:

其中,ξv表示训练集特征的方差。这样不仅提高了精度,而且相对于全部用高斯核来说,减少了无效的运算。
为了得到目标函数,本文遵循语义哈希准则,即在原始空间中相似的视频有相似的哈希码。为了满足上述准则,应使k近邻的关键帧间的哈希码尽可能相似,可用下面的最优化公式来表示:
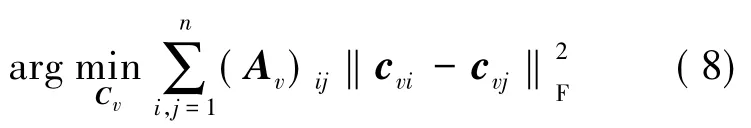
为了更好地表示视频中关键帧的信息,也采用了矩阵Bv,并且有Gv=Av+δBv,此时目标函数表达式为:
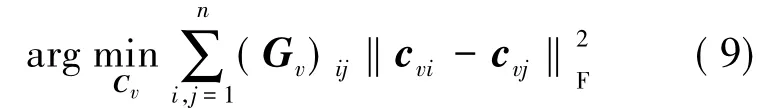
(9)式中的目标函数只是考虑了单个特征个体的结构信息,还需要全局地考虑所有特征的结构信息。为了提高算法的准确性,应使每个特征尽可能地表示该帧图像的内容,即应保证该帧图像单特征形成的哈希码和多特征形成的哈希码尽可能相似。因此,加入所有特征的结构信息的目标函数被重新定义为:
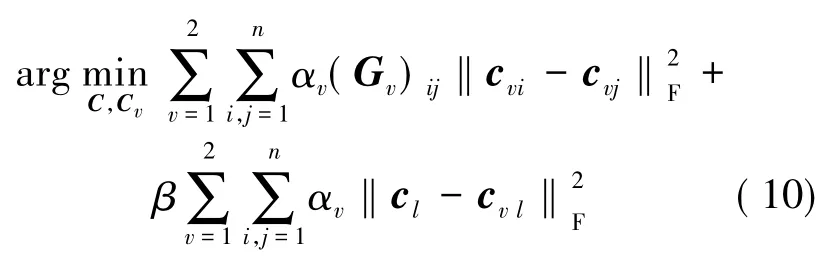
其中,αv为表示特征间的权重;β为2个部分之间的权重。
在产生关键帧哈希码的同时产生哈希函数,当有新的数据产生时可以直接处理,不需要重新训练。为了保证在产生哈希码的同时产生哈希函数,结合了机器学习中的经验风险最小化知识,目标函数近一步表示为:
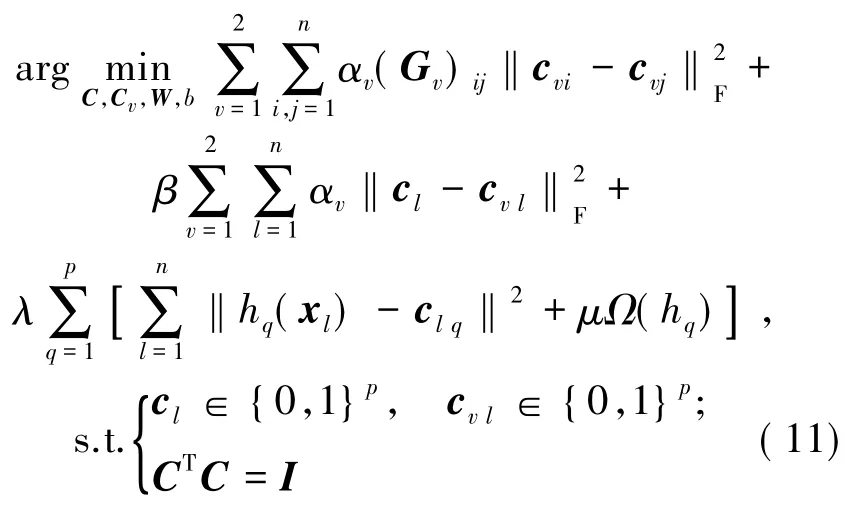
其中,Ω(hq)为hq的归一化函数;clq为对应关键帧xl的的第q位哈希码;λ和μ为参数;约束条件是为了保证产生二进制码和避免繁琐解。同谱哈希算法一样,在该约束条件下,它是一个NP-hard的问题,无法求解(11)式。因此,需放宽约束条件,只保留CTC=I。同时结合(1)式、(11)式以及之前定义的向量,目标函数可以化为:
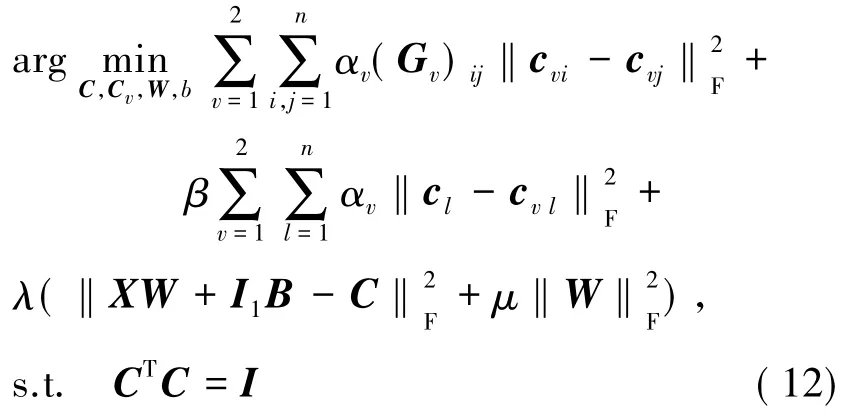
2.2生成二进制码
语义哈希对图像的编码过程可以看成是图分割问题,其借助于相似图的拉普拉斯矩阵的特征值和特征向量的分析,得到图分割问题的一个松弛解,然后对特征向量进行二值化,从而产生哈希码。本文在多特征哈希模型的基础上对拉普拉斯矩阵进行改进,该模型属于语义哈希的一类,整个模型的编码过程与语义哈希一致。本文采用多特征哈希中对目标函数化简的方法,对(12)式的目标函数进行化简。通过对(12)式的W和B分别求偏导,从而确定哈希函数。
分别对(12)式的W和B求偏导,令偏导数为0,可得:
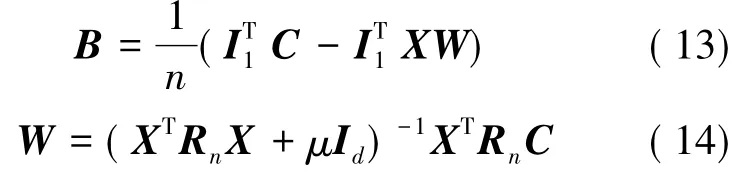
其中,Rn=In-I1I1T/n为一个中心矩阵。
把(13)式、(14)式分别带入(12)式中,化简目标函数可得:
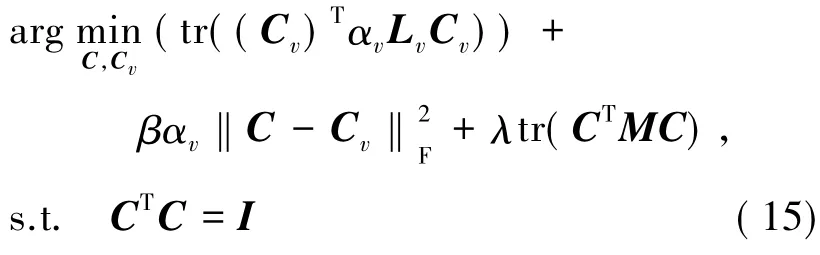
其中,Lv为第v个特征的拉普拉斯矩阵;M=Rn-RnX(XTRnX+μId)-1XTRn。对(15)式中的Cv求偏导,并令导数为0,可得:
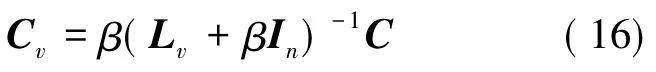
令Dv=β(Lv+βIn)-1,则Cv=DvC,代入(16)式可得最终的目标函数为:
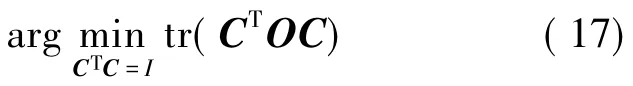
其中,O的表达式为:
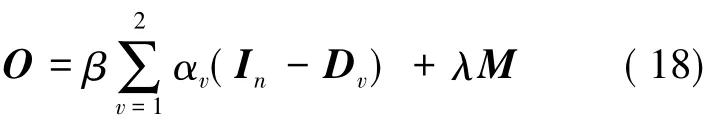
本文通过求解矩阵O的特征值和特征向量,其中C为前p个最小的特征值对应的特征向量。对C进行二值化即可得到视频的哈希码。然后根据(13)式、(14)式分别求出W和B,同时产生了哈希码和哈希函数。
2.3算法步骤
训练步骤如下:
(1)根据(1)式求所有特征的拉普拉斯矩阵Lv。
(2)根据(17)式求出矩阵O,并求出矩阵O的前p个最小的特征值对应的特征向量C。
(3)根据(13)式、(14)式分别求出W和B。检索过程步骤如下:
(1)对每个视频中所有关键帧映射成的哈希值求平均。
(2)对该哈希值二值化,每个视频产生一个p位的哈希码。
(3)通过W和B求查询视频的哈希码,和训练集的哈希码在汉明空间求异或,输出检索结果。
3 实验结果及分析
为了验证本算法的准确性,在公开的数据集CC-WEB-VIDEO上进行了实验。实验的环境为:VS2010和OpenCV2.4.3,64位Win7系统。
本文采用的数据库中种子视频的若干关键帧如图1所示。

图1 种子视频
训练集主要有完全相同的视频、相似视频、巨大改变的视频、不相似的视频4类,其中,完全相同的视频不再贴图,其余几类的若干关键帧如图2~图4所示。

图2 相似视频

图3 巨大改变的视频

图4 不相似的视频
实验中各参数设置为:μ=1,λ=103,δ=103,β =1,α1=1,α2=1,k=0.1×num,num为训练集中关键帧的总数。编码长度p=320。HSV特征为162维,LBP特征为256维。
本文不仅和多特征哈希[11]法做了对比,还和一些主流方法做了对比,LF代表文献[3]中的局部特征分层检索方法,ST-lbp和ST-ce分别代表文献[12]中的时空特征检索方法,GF为只使用了HSV特征的哈希模型的检索方法,IMmfh为本文算法。本文从MAP值和P-R曲线分析算法。MAP值的比较见表1所列,P-R曲线的比较如图5所示。从表1中可以看出,本文方法的MAP值结果最好。从图5中可以看出,GF在这些方法中效果最差,本文方法效果最好,其余几种方法效果接近。
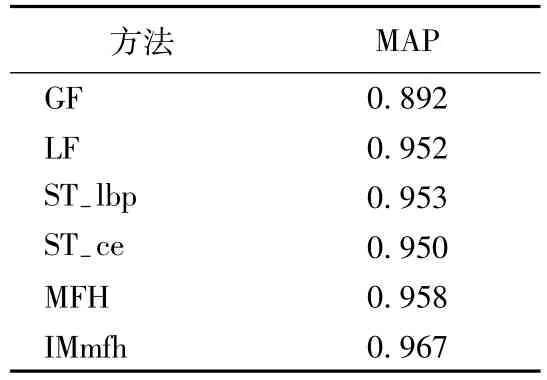
表1 MAP值的比较
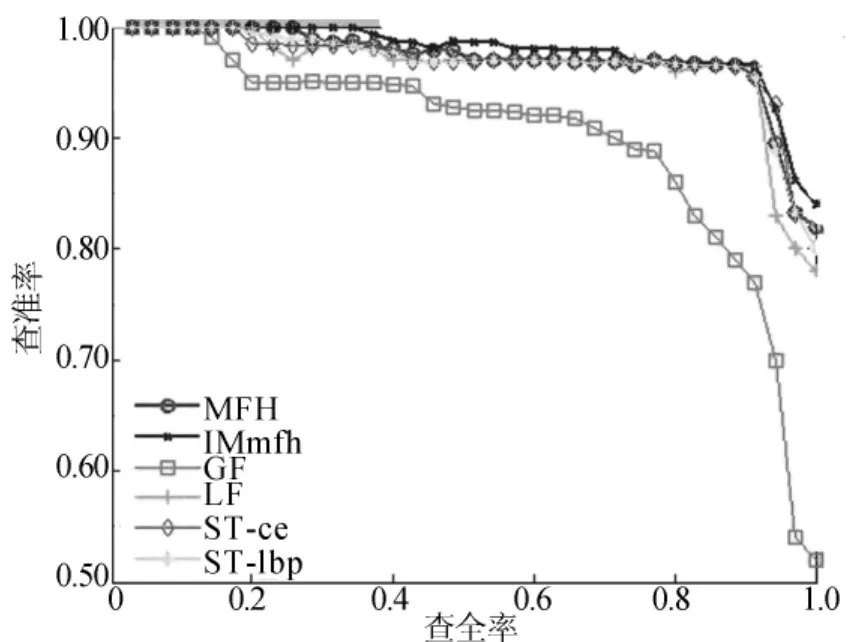
图5 P-R曲线的比较
另外,为了验证本文方法的有效性,对24类数据集均做了实验,并且和Content方法[2]、Layer方法[3]、多特征哈希(MFH)的方法做了对比,实验结果分别如图6所示。
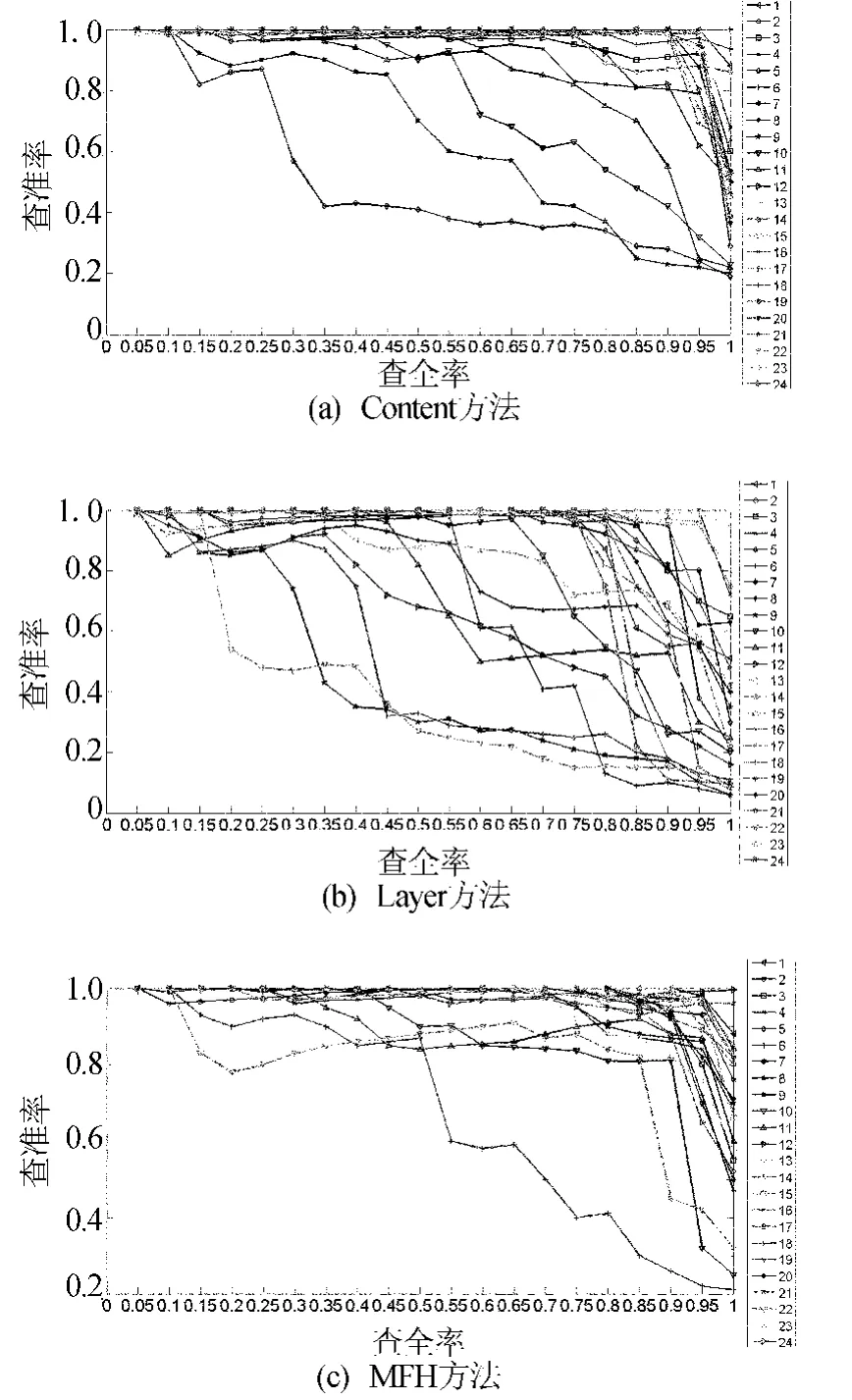
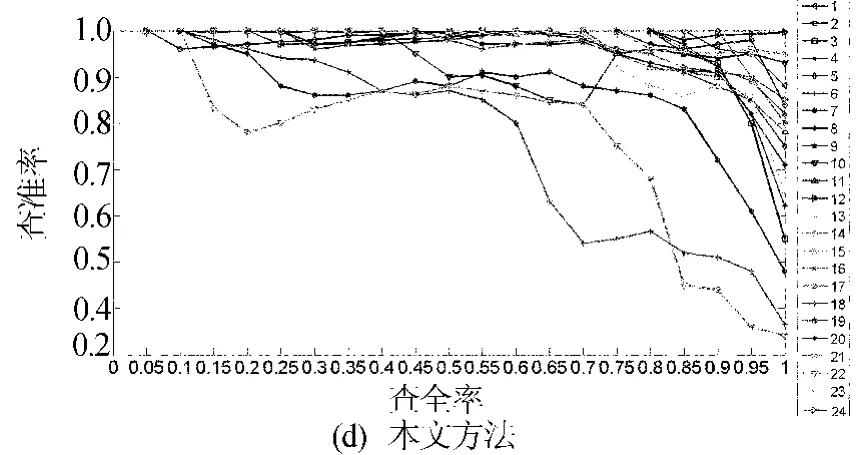
图6 4种方法检索实验结果
从图6中可以看出图6a的结果最差,其主要原因在于判断视频是否是近重复视频时,该方法先通过视频时间长短滤除部分视频,然后再通过视频的内容信息判断是否是近重复的。但是因为视频的版本不同,时间上相差较大的视频也可能是近重复视频,因此造成了漏检。本文方法更优于MFH方法,虽然18类和22类效果不太理想,但是其效果仍然优于MFH,该类数据集中的视频变化比较复杂,通过引入时间信息和改进拉普拉斯矩阵更加精确地表示视频结构和内容,从而提高了检索精度。
4 结束语
本文提出了一种改进的多特征哈希的算法,主要改进了邻接矩阵。实验表明,和多特征哈希[11]的算法相比,本文算法不仅提高了检索的精度,同时还保持了可扩展性和可移植性。进一步的研究工作是应用能表示视频的时间信息和能表示视频的动作特征对监控视频进行检索。
[参考文献]
[1]Liu J,Huang Z,Shen H T,et al.Correlation-based retrieval for heavily changed near-duplicate videos[J].ACM Transactions on Information Systems,2011,29(4):21.1-21.25.
[2]Wu X,Ngo C W,Hauptmann A G,et al.Real-time near-duplicate elimination for web video search with content and context [J].IEEE Transactions on Multimedia,2009,11(2):196-207.
[3]Wu X,Hauptmann A G,Ngo C.Practical elimination of nearduplicates from web video search[J].Proceedings of International Conference on Multimedia,2007:218-227.
[4]Glowacki P,Pinheiro M A,Turetken E,et al.Reconstructing evolving tree structures in time lapse sequences[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).IEEE,2014:3035-3042.
[5]Ai L,Yu J,He Y,et al.High-dimensional indexing technologies for large scale content-based image retrieval:a review[J].Journal of Zhejiang University:Science C,2013,14(7):505-520.
[6]Tao Y,Yi K,Sheng C,et al.Efficient and accurate nearest neighbor and closest pair search in high-dimensional space[J].ACM Transactions on Database Systems(TODS),2010,35 (3):20.
[7]蒋云志,王年,汪斌,等.基于图的Laplace矩阵和非负矩阵的图像分类[J].合肥工业大学学报:自然科学版,2011,34(9):1330-1334.
[8]Weiss Y,Torralba A,Fergus R.Spectral hashing[C]//Advances in Neural Information Processing Systems,2009:1753-1760.
[9]Zhang D,Wang J,Cai D,et al.Self-taught hashing for fast similarity search[C]//Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval.ACM,2010:18-25.
[10]Song J,Yang Y,Huang Z,et al.Multiple feature hashing for real-time large scale near-duplicate video retrieval[C]//Proceedings of the 19th ACM International Conference on Multimedia.ACM,2011:423-432.
[11]Song J,Yang Y,Huang Z,et al.Effective multiple feature hashing for large-scale near-duplicate video retrieval[J].IEEE Transactions on Multimedia,2013,15(8):1997-2008.
[12]Shang L,Yang L,Wang F,et al.Real-time large scale near-duplicate web video retrieval[C]//Proceedings of the International Conference on Multimedia.ACM,2010:531-540.
(责任编辑张镅)
A near-duplicate video retrieval method based on improved multiple feature hashing
LUO Hong-wen1,YANG Yan-fang2,QI Mei-bin1,JIANG Jian-guo1
(1.School of Computer and Information,Hefei University of Technology,Hefei 230009,China;2.School of Electronic Science and Applied Physics,Hefei University of Technology,Hefei 230009,China)
Abstract:With the development of Internet,a large number of near-duplicate videos are produced online each day.In this paper,an improved hashing algorithm is proposed to improve the accuracy of near-duplicate video retrieval.According to the theory of semantic hashing based image retrieval,the adjacency matrix is improved.Adjacency matrix is a representation of the sample’s adjacency of K-nearest neighbor(KNN)graph.The adjacency relationship is presented by Gaussian kernel function instead of 0 or 1,thus improving the accuracy of retrieval.The experimental results show that the proposed method has higher retrieval accuracy.
Key words:near-duplicate video retrieval;hashing algorithm;adjacency matrix;Gaussian kernel function;K-nearest neighbor(KNN)graph
作者简介:罗红温(1987-),女,河北衡水人,合肥工业大学硕士生;
基金项目:安徽省科技攻关计划资助项目(1301b)
收稿日期:2014-12-17;修回日期:2015-04-24
Doi:10.3969/j.issn.1003-5060.2016.01.013
中图分类号:TN919.81
文献标识码:A
文章编号:1003-5060(2016)01-0067-06
猜你喜欢
长春师范大学学报(2022年12期)2023-01-13 11:41:32
软件导刊(2020年5期)2020-06-22 13:15:56
现代电子技术(2018年20期)2018-10-24 04:39:04
科学与财富(2018年27期)2018-10-19 16:09:08
现代商贸工业(2018年24期)2018-09-21 10:54:02
魅力中国(2017年13期)2017-09-20 00:31:40
网络空间安全(2016年3期)2016-06-15 20:27:07
电脑知识与技术(2015年17期)2015-09-11 13:43:38
读写算·教研版(2015年13期)2015-07-28 07:13:11
湖南师范大学学报·自然科学版(2014年3期)2014-10-24 16:11:06
