
基于Clique聚类的精神分裂症多文档自动摘要研究
2016-03-21 08:53,
中华医学图书情报杂志 2016年3期
,
多文档自动摘要的任务是利用自然语言处理等信息处理技术分析文献内容,从中提取出重要信息并生成简洁的摘要。因其能够使用户快速了解、选择文献集中的重要信息而受到越来越多的关注。近年来,随着科技文献的迅速增长,科技人员对摘要的需求越来越大;而作者摘要仅能提供单篇论文的缩略信息,不能提供相关主题的整体研究概况。多文档摘要,尤其是针对大型专题文献集,则能有效地解决这一问题,为用户节省更多的时间与精力,具有重要的意义。
目前多文档自动摘要研究多集中在对新闻事件、网页信息等进行摘要,鲜有对科技论文进行摘要的研究。其原因是科技论文报道的内容复杂多样,需要在对内容理解的基础上进行摘要,因此要借助于领域知识库的支撑。在生物医学领域,一体化医学语言系统(UMLS)的研究和开发为医学文献向知识单元的语义表达发展提供了基础,也为自动摘要研究开辟了新的途径。本研究旨在探索从节点、边以及网络凝聚子群(clique)三个层次抽取文献集关键信息生成摘要,并利用clique共有概念对其聚类以发现摘要子主题的方法;同时借助于医学术语表及自然语言处理工具,对文献内容进行语义表达并抽取,生成文献摘要的语义网络图,使摘要内容表达形象、简洁。
1 基于图的多文档自动摘要研究现状
1.1 图属性在自动摘要研究中的应用
文档自动摘要是从单篇文档或文档集中自动提取出核心信息,按摘要生成方式分为抽取式摘要(extractive)和理解式摘要(abstractive)两种。抽取式摘要是从源文档中抽取出重要的句子组成摘要,句子重要性的确定多基于文本的物理信息(如词的位置、句子的位置、词的频率等),这种机械的句子抽取难以产生高质量的摘要。理解式摘要是在理解文档内容的基础上,利用自然语言处理技术(如文本表达、句子重构等)生成新句子组成摘要,它涉及信息处理、知识表达等方面,难度较大,进展缓慢。
近年来越来越多的研究将图排序及聚类等技术应用于自动摘要任务。该方法以图形的形式表现论文[1-7],节点代表论文的信息单元。大多数研究以句子为节点,如LexRank系统[1],也有研究采用段落或词为节点[7]。以节点之间的相似度为边,可以构建论文集的网络图。这些研究通常采用节点的中心性(centrality)作为摘要句排序和抽取的标准,其依据是节点的中心性越高,其位置在网络中越重要。
上述基于图的文本摘要研究仅以节点的中心性为指标对重要信息进行提取。文献网络图的组成部分除节点外,还包括边以及子网络,在复杂网络分析中它们都是网络图的重要属性。高继平等[8]提出目前国内外针对基于词共现的文献网络分析多依据节点在网络中的影响力进行评价,忽视另一个重要指标—边,进而对基于频次和基于连通性的权重抽取重要边的效果进行比较研究。此外,网络中的社区也能准确揭示知识主题。文献网络中的社区指凝聚性较高的子网络,如clique,k-core等。这类子网络通常揭示了网络的核心内容。如王晓光[9]的研究发现词共现网络中的社区与学科体系存在一定的对应关系。在此基础上,白如江等[10]利用k-clique社区网络揭示知识创新情况及其演化方向。此外,高雯珺等[11]综述了凝聚子群在发现合著团体以及学科研究的子领域方面的应用。
本研究拟将凝聚子群—clique应用到摘要内容的提取中。在网络分析研究中,clique是指由两两均相连的点构成的小团体,也称完备子群或完全子图,根据包含节点数将clique更加准确地记为n-clique。基于clique聚类的思想是从网络中的clique出发,通过分析clique的重叠部分实现网络类的划分。与基于词共现的聚类分析相比,凝聚子群分析允许将一些重要的节点(如词汇)划入多个类目中,这更符合现实要求,因此在蛋白质功能预测[12]、文献主题划分[13]等研究中得到广泛应用。目前基于clique聚类算法包括派系过滤算法(CPM)[14]、基于最大clique的层次凝聚聚类算法 (EAGLE)[15]、基于clique共节点的层次聚类法等。本研究采用的是第三种方法。
1.2 医学知识库在自动摘要研究中的应用
生成高质量的摘要需从语义、语用层次上对文本进行理解和表达,需要学科领域知识库[16]及自然语言理解技术的支撑。在生物医学领域,UMLS的研究和开发为医学文献向知识单元的语义表达发展提供了基础,也为自动摘要研究开辟了新的途径。利用UMLS能够对医学文献中的信息进行深度表达,并能构造出完整、细致的语义关系,是医学信息检索、自动摘要和知识发现的基础[17]。
目前利用UMLS对医学文献进行自动摘要包括两大类。一类是以抽取概念为主,具体为利用MetaMap工具对医学论文进行断句、切词,并将文本词匹配为UMLS超级词表的概念。概念之间的关系较单纯,通常为概念间共现或词表所规定的概念间的等级关系。然后基于图排序或统计学方法来确定文献集中的重要信息,如Reeve的摘要系统[18-19]、Plaza[20]的摘要系统以及Yoo等人[4]的系统。但利用MetaMap对医学文献内容的揭示比较浅显,不能表达出概念间的诸如诊断、治疗、引起等语义关系。另一类研究除了抽取UMLS的概念外,还对概念之间的语义关系进行抽取,利用的工具为SemRep。该工具首先调用MetaMap抽取出医学文本中的概念,然后抽取共句的两个概念之间的语义关系(即谓词),将文本处理成形如“主语—谓词—宾语”的语义述谓项,进而实现从语义和语用层次对文本进行表达,使生成的摘要信息更丰富完善。例如Fiszman[21]利用语义述谓项中概念的语义类型与语义关系的组配形式,预设了4个摘要主题搭配模式(Schema),自动生成关于疾病治疗、药物相互作用、疾病诊断和药物遗传学等四方面的摘要网络图。Fiszman系统的特点之一是以网络图的形式显示摘要信息,这样既使摘要清晰明了,又避免了对大量文档进行摘要句抽取时句子重复、连贯性差等问题。但该研究仅从构建语义搭配模式出发,将摘要局限在预设主题模式所规定的范围,缺乏广适性。
本研究在Fiszman系统的基础上,利用文献网络图的属性从文献集中提取重要信息,避免了摘要生成固定在预设主题范围内的局限。与已有研究相比,本文不仅利用概念对源文档进行表达,同时抽取出概念之间的语义关系,弥补了现有词共现网络概念间关系不清的弊端,使摘要主题内容的表达更加准确。在摘要信息抽取方面,采用复杂网络分析指标,除了传统的高中心度节点,还融入了关键边和凝聚子群,从多角度抽取网络关键信息,为医学文档自动摘要提供了新的解决思路。
2 研究步骤与方法
本研究分为以下五个步骤(图1)。

图1 研究技术路线
2.1 数据采集
从PubMed、Web of Science等数据库中检索某一主题的文献,并将其保存为纯文本格式,该主题即为摘要主题。
2.2 语义述谓处理
利用SemRep将文献集中的各个句子处理为如“主语|语义类型|语义关系|谓语|语义类型”的语义述谓项。其中主语及宾语为UMLS超级词表中的概念,谓词来自于UMLS语义网络中的语义关系,如句子“Clozapine is the most effective treatment of aggressive behavior in schizophrenia”,经处理后生成如下2条语义述谓项:
Clozapine|phsu|TREATS|Aggressive behavior|mobd
Aggressive behavior|mobd|COEXISTS_WITH|Schizophrenia|mobd
以第1条为例,Clozapine为主语,其语义类型为phsu(pharmacologic substance,药物),TREATS 为语义关系,Aggressive behavior为宾语,其语义类型为mobd(Mental or behavioral dysfunction,精神/行为功能失常)。
2.3 数据预处理
去除Patient等含义比较宽泛的概念。宽泛概念的定义标准为处于UMLS概念等级结构二级及以上的概念[21-22],共633个。如果语义述谓项中的主语或宾语中有一个属于宽泛概念,则将该语义述谓项删除。
2.4 摘要信息提取
首先利用得到的语义述谓项集合构建文献网络图,对网络图进行如下定义:由节点和边组成,节点即语义述谓项中的概念(主语或宾语)。如果两个节点分别是一条语义述谓项的主语和宾语,则两点之间有边连接,两点及其间的边对应一条语义述谓项。通过计算该条语义述谓项出现的频次对其赋权。该网络图具备如下属性:节点的颜色标识其语义类型,大小表示其频次;连线的颜色标识语义关系,宽度表示语义述谓项的频次,绘图工具采用Pajek,输入文件的定义和格式详见文献[22]。
由于多文档摘要通常是对大规模文献集进行分析、处理,因此语义述谓网络往往是非常庞大的。利用复杂网络拓扑结构的属性指标(如中心性、凝聚性、聚类系数等)能够揭示网络的结构特征,发现网络中的关键信息,为摘要信息抽取服务。本研究依次从节点、连线以及簇结构(clique)三个层次对语义述谓网进行压缩,实现关键信息的抽取。
第一步为关键节点(概念)的提取。目前基于图的自动摘要研究对信息的提取多采用节点中心度(Centrality)指标。文献[15]计算并比较了采用语义述谓网络中不同节点中心度(点度中心度、特征向量中心度、中介中心度、接近中心度)在抽取与疾病治疗相关重要概念的效果,最终发现与人工标准相比。利用节点的度中心度抽取概念的效果最佳,因此本研究采用节点的度中心度对关键节点进行抽取的计算公式为:CD(ni)=d(ni)/(n-1) ,式中d(ni)为节点ni的度,n是网络内节点总数,并抽取中心度高的节点所组成的语义述谓项。
第二步为关键边的提取。边为网络的二元结构,也是网络的基本组成单位。本研究以文档频次为指标,抽取频次高的边所对应的语义述谓项。如果同一语义述谓项在不同文章中重复出现,则可认定为文献集的核心内容。
第三步为clique提取,即提取clique作为文献集的摘要。由底向上的网络子结构分析方法将网络看成是由二元结构和群组成的[23]。二元结构即两个节点之间的关系,为最基本的结构单位,在此基础上增加一个与其相连的节点,则构成了最小的完备群,即3-clique。医学文献中小规模的clique往往能表达更完整的含义,成为网络的核心。例如图2中3-clique表达了“两种药物Risperidone和Olanzapine对精神分裂症时的疗效比较”(图中TR为语义关系“TREATS",CW为语义关系”COMPARED_WITH")。本研究采用最大clique搜索算法,在剩余的语义述谓项中提取clique作为最终的摘要。

图2 3-clique示例
2.5 摘要主题聚类及可视化
对clique进行聚类,每一类即为摘要的一个子主题,利用Pajek对摘要进行可视化。为研究所生成的摘要中蕴含的子主题,对提取的clique进行聚类。本研究采用的是UCINET的clique交叠聚类算法[24]。目前的研究大多对节点进行聚类,其弊端是一些可能被多个类共有的核心节点(如主题概念“精神分裂症”)仅能出现在一个类中,与实际情况不符。clique交叠聚类能够有效地避免这一问题。由于一个clique中包含至少3个节点,N个clique通过寻找clique-clique之间共有的节点,可以生成N×N的矩阵,利用Pearson相关系数生成clique相似矩阵,采用组间距离法,对该矩阵做系统聚类,通过分析聚类内容,实现摘要子主题的识别。
3 研究结果与分析
3.1 数据采集
以精神分裂症(schizophrenia)为主要主题词,于2015年9月在PubMed数据库中检索2005-2015年近10年发表的论文,并限定语种为英文,共获得了19 661篇论文(带摘要)。
3.2 数据处理结果
19 661篇文献经SemRep处理后,得到132 587条语义述谓项,包含7 865个节点,其中包含宽泛概念55个。去除含宽泛概念的语义述谓项后,剩余7 119个节点,经过反复测试,将节点度中心度阈值设置为0.05(即每个节点至少与其他20个节点相连),频次阈值设为14,剩余178条语义述谓项,114个节点。采用最大clique搜索算法获得31个clique,包含35个节点。31个clique中包含8个5-clique,4个4-clique以及19个3-clique。聚类树图见图3,在距离小于15处将clique分为4类,即为摘要的4个子主题。利用Pajek显示摘要图(图4),其布局依据聚类的结果做调整。为了增加图的可读性,仅用颜色代表语义关系,省略了文字标签。利用节点的语义类型及语义关系搭配,可实现对子主题内容的标注。
UMLS在其语义网络中对概念的语义类型及语义关系赋予详细的定义,利用其组配模式能对医学文献内容进行详尽的表达,从而实现对研究主题的标注。图4所涉及的语义搭配模式及其对应的含义见表1。
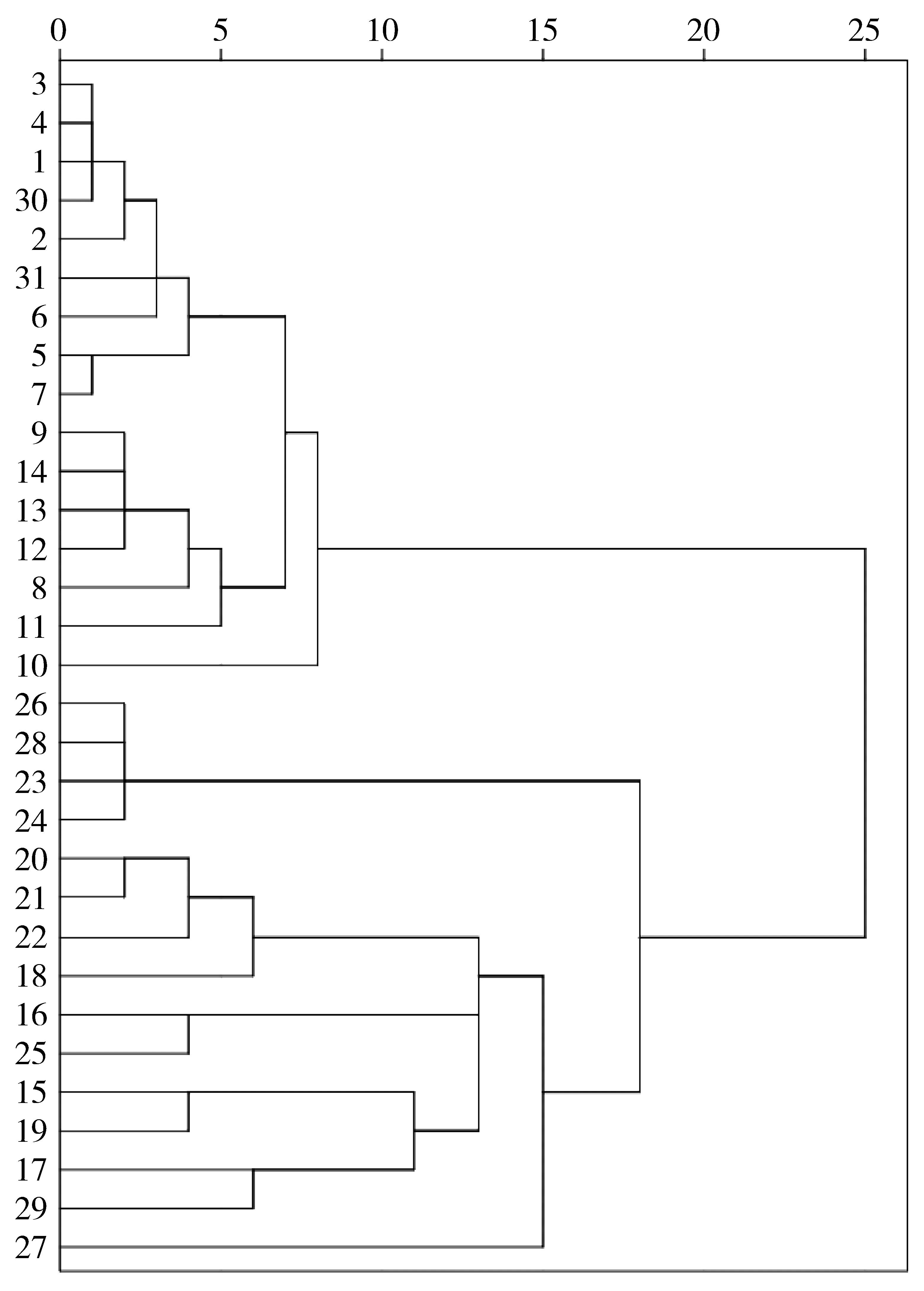
图3 clique系统聚类树图
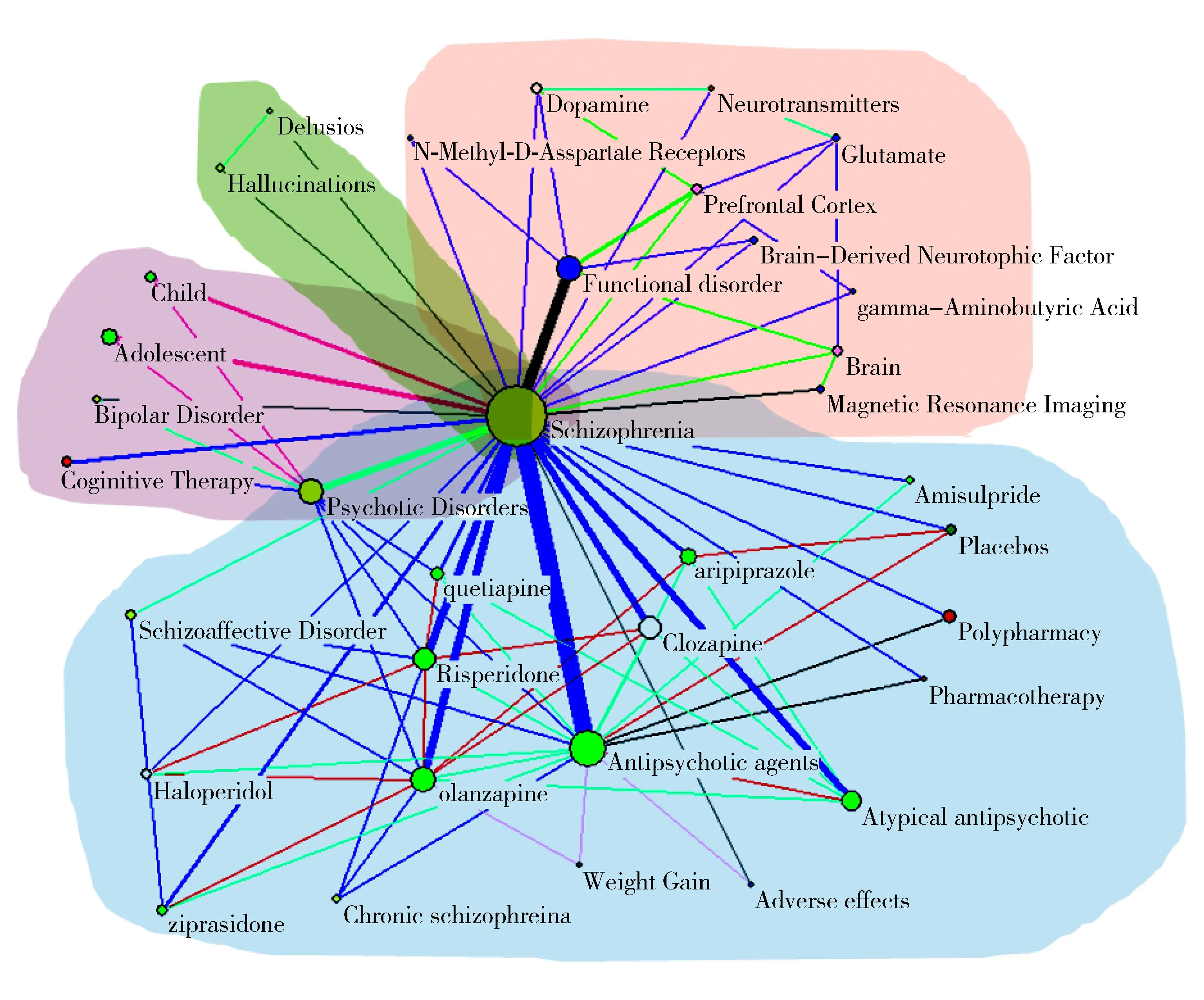
图4 精神分裂症文献集摘要图

表1 研究子主题语义搭配及含义
子主题1:位于图4左上方,为精神分裂症的发病特殊人群及非药物疗法。由此类可看出,该病多发于儿童及青壮年,可用认知疗法进行治疗。图4中深蓝色线条表示的语义关系为“Treats”,红色线条为“Process_of”。
子主题2:位于摘要图4上方豆绿色背景区域,为精神分裂症的症状,包括幻觉和妄想,其语义关系为“Coexists_with”(灰色)。
子主题3:位于图4右上方,为精神分裂症的致病因素及发病部位。其致病因素包括位于大脑前额叶皮质的神经递质(如多巴胺、谷氨酸、γ-氨基丁酸等)异常,导致神经递质系统功能受损而发病。图中紫色为“Associated_with”,绿色为“Location_of”,浅蓝色为“ISA”。
子主题4:位于图4下方,为精神分裂症的药物疗法、药物之间的比较以及产生的副作用。图中深蓝色为“Treats”,黄色为“Compared_with”,红色为“Causes”,浅蓝色为“ISA”。
3.3 实验结果评价
目前摘要评价方法主要有以人工标注摘要为标准进行评价和基于任务的评价两类。由于缺乏公用的医学文本语料库,且请专家对上万篇文献提供人工标注的参考摘要不现实,因此本研究采用第二种方法,即基于概念提取和主题划分的评价方法,考察本研究提取的各摘要主题概念的覆盖情况。我们请两名医学博士以其专业知识为基础,同时参考英文原版精神病学教科书Review of General Psychiatry、教育部及卫生部“十二五”规划教材《精神病学》以及循证医学资源Up-To-Date中关于精神分裂症的专家综述,从发病人群及非药物疗法、症状、病因及发病部位和药物疗法四方面提取相关概念为人工标准。当两名专家意见不一致时,通过协商获取一致性意见。以准确率、召回率及F值为评价指标,结果见表2。
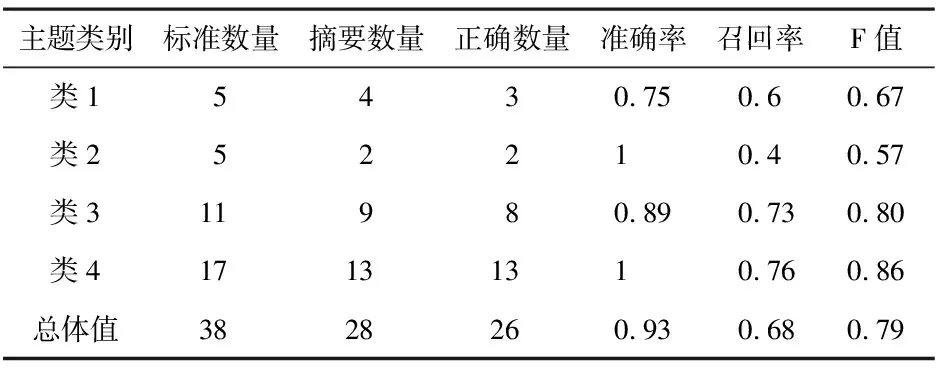
表2 实验结果与人工标准的对比
评价结果表明,准确率普遍比较高,召回率相对较低。摘要信息的质量与多方面因素有关。首先就信息源而言,本研究采集的是科技论文摘要,疾病症状、药物副作用等概念出现在作者摘要的几率较低,易被预设阈值过滤。如果采集的信息是文献全文,就能够全面地获取信息,但会造成干扰信息过多,从而导致准确率下降。其次在文献内容表达方面,领域知识库的完备程度及自然语义处理工具(如SemRep)对信息处理的准确性也同样会影响摘要提取的质量。SemRep对疾病类、化学物质类概念提取的效果好,对基因名、蛋白名提取的效果相对差,这与其利用的词表UMLS搜集词汇的侧重点有关。因此在对基因等作摘要时,建议用专有的提取工具来提取命名实体。此外,阈值的设定对摘要的准确率和召回率起反向作用。如欲使摘要召回率增加,可适当降低阈值。当中心度阈值降到0.028时,能将副作用“嗜睡”纳入进来,但会导致摘要过大,降低准确率和易读性。最后,本研究对簇结构的识别采用最大完全子群搜索算法。尽管大部分都是规模相对较小的3-clique,但可能会导致一些不能构成clique的重要概念丢失,从而降低召回率。今后可尝试采用Quasi Clique,k-core等簇发现算法,使摘要的覆盖面适当增加。
4 结论
本研究利用自然语言处理工具SemRep对医学文本所涵盖的语义述谓项进行提取并生成表达文献内容的网络图,利用网络图的中心性及凝聚属性从中提取出文献集的核心内容生成图形摘要。该研究方法能为知识图谱、临床问题自动应答系统的开发提供新的思路。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
科学与信息化(2021年8期)2021-03-31
开放教育研究(2020年2期)2020-03-31
活力(2019年21期)2019-04-01
电脑爱好者(2017年7期)2017-05-06
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
