
基于LDA模型的文本相似度研究
2016-02-24 10:41王海晖
计算机技术与发展 2016年4期
陈 攀,杨 浩,吕 品,2,王海晖,2
(1.武汉工程大学 计算机科学与工程学院,湖北 武汉 430073;2.武汉工程大学 智能机器人湖北省重点实验室,湖北 武汉 430073)
基于LDA模型的文本相似度研究
陈 攀1,杨 浩1,吕 品1,2,王海晖1,2
(1.武汉工程大学 计算机科学与工程学院,湖北 武汉 430073;2.武汉工程大学 智能机器人湖北省重点实验室,湖北 武汉 430073)
LDA主题模型是近年来提出的一种具有文本表示能力的非监督学习模型。考虑到传统主题模型在处理大规模文本时存在的局限性,文中提出一种基于LDA模型的文本相似度计算方法。利用LDA为语料库建模,通过Gibbs抽样间接估算模型参数,将文本表示为固定隐含主题集上的概率分布,以此计算文本之间的相似度。最后将K-means算法作为文本相似度的评估指标。实验结果表明,与LSI模型相比,该方法能有效地提高文本相似度计算的准确性和文本聚类效果。
文本挖掘;LDA模型;Gibbs抽样;文本相似度
0 引 言
近年来,互联网作为一个开放的信息平台得到快速发展,网络上文本信息量也以指数级的方式飞速增长。在大数据时代,信息中包含很多数据,这些数据大部分以文本的形式存在。面对如此多的文本信息,如何高效地进行文本挖掘是目前研究的重点问题,这使得文本挖掘成为大数据时代信息处理领域的热点。
常用的文本挖掘方法是潜在语义索引LSI(Latent Semantic Indexing)模型[1]。利用LSI模型对文本进行挖掘时,由于考虑了词间的语义关系,具有很好的降维效果,但对重要稀有类别的分类特征,LSI模型可能过滤了它们,从而造成分类性能不佳。LDA(Latent Dirichlet Allocation)模型[2]改进了LSI模型在文本挖掘中的不足,有效解决了文本挖掘中的特征稀疏和分类性能受损问题。文中基于LDA模型进行文本相似度计算,采用传统的聚类算法对实验结果进行评估,并获得了较好的效果。
1 相关工作
在文本挖掘领域,国内外研究人员都进行了大量的工作。Salton等提出向量空间模型(Vector Space Model,VSM)[3]是常用算法。Hastie等提出KNN(K-Nearest Neighbor)[4]方法来计算文本相似度。Blei等[2]提出LDA主题模型。该模型以文本特征为对象,将文本语料表示为各个主题空间,通过找到文本中不同隐含主题与词间的关系,得到文本主题概率分布。
目前,国内研究人员主要对LDA算法进行改进。刘振鹿等[5]基于LDA模型研究潜在语义分析,将语义划分为三个不同频段的语义区。通过语义互作用机制和文本类别对聚类结果进行修正,得到了较好效果。李文波等[6]在传统主题模型中融入文本类别信息,提出了一种附加类别的LDA模型方法来提高LDA模型的分类性能。石晶等[7]基于LDA模型进行文本建模,结合特征词相关扩充和背景特征词聚类,把特征词应用到待分析的文本中,找到特征词下的文本语义,提高文本分析的性能。
2 LDA模型
LDA模型是由Beli提出的针对离散数据集[8]建模的主题生成模型,它是一个三层贝叶斯网络结构,分为文档层、主题层和词层。其有向概率图[9]如图1所示。
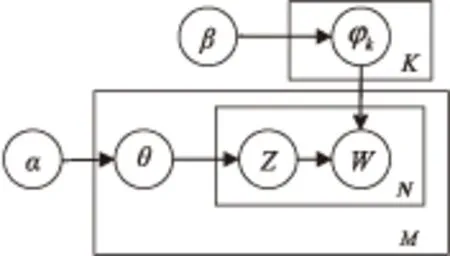
图1 LDA有向概率图
图1中,参数α反映出文本集中不同隐含主题间的相对强弱关系,参数β则代表主题自身的概率分布。Z表示隐含主题,W表示词表的每个词,即观察值。θ代表文本-主题概率分布,φk代表主题-词概率分布。对于给定的文本集D,包含M个文档,T个主题,而每个文档d中又包含N个词。
2.1 相关符号含义
LDA模型中的对应符号[10]解释如下:

(3)文档集由文档组成,每个文档集中包含若干文档,用D={d1,d2,…,dm}表示,其中dm表示第几篇文档。
假设主题数为K,则文档d中的第i个词wi的概率为:
(1)
式中:zi是隐含主题变量,表示第i个词wi属于zi主题;P(wi|zi=j)表示词wi对主题j的贡献概率;P(zi=j)表示文档d对主题j的贡献概率。
词w在文本d中“出现”的概率可表示为:
(2)
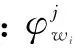
通过EM算法[11]可求出最大似然函数:
(3)
其中,α、β为最大似然估计量,通过估算α和β的参数值从而确定LDA模型。则文本d“发生”的条件概率分布可用式(4)表示[12]:
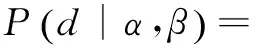
(4)
2.2 参数估计
在MCMC[13]中Gibbs抽样[14]是间接计算LDA模型参数的常用有效方法。具体步骤如下:
(1)将主题zi的值随机设定为1到T内某个整数,i是语料库所有文本中特征词的个数,它与词表规模和所在位置有关。
(2)迭代足够多次,直到Markov链[15-16]接近目标分布,此时的主题zi可按如下公式估算φ和θ的值:
(5)
(6)
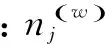
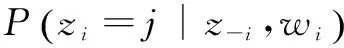
(7)

2.3 相似度计算
文本相似度计算的核心是通过计算文本间的主题概率分布来实现。当用LDA模型找到了文本的隐含主题后,文本的相似度可通过计算对应的隐含主题概率分布的相似度来表示。通常用KL距离[18]公式作为相似度度量的标准,公式如下:
(8)
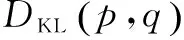
(9)
当λ=0.5时,KL距离公式可转化为JS距离公式[20]:
(10)
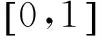
3 实验设计和结果分析
文本相似度计算的步骤如图2所示。

图2 文本相似度计算
(1)对文本进行预处理,包括去除分词、停用词、符号等操作。
(2)将文本向量化,构成文本—词矩阵。
(3)利用向量化矩阵进行LDA建模,得到文本的主题概率分布。
(4)通过JS距离公式计算文本间的相似度,得到相似度矩阵。采用K-means算法对文本进行聚类,用聚类结果对文本相似度计算的准确性进行评估。
主题建模过程中,假定主题数K为2,α和β为经验值[21],分别为50/K、0.1。为确保实验结果的准确性,Gibbs抽样迭代次数需达到1 000次以上。改变主题数K值,根据聚类结果来评价最优主题数。
3.1 语料选择
实验预料数据来自复旦大学的一个英文语料库,共6个类别,2 246篇文本。其中训练语料50篇,测试语料2 196篇,分别为Science类、Art类、Business类、Movie类、Sport类和Travel类。
3.2 评估方法
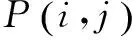
(11)
式中:nj表示判断属于类别j的文本数目;ni表示实际属于类别i的文本数目;nij表示判断属于j同时实际也属于i的文本数目。
F度量值可定义[11]为:
(12)
则文本集聚类的F度量值定义为:
(13)
3.3 实验结果分析
当主题数K值为2时,α、β分别为50/K、0.1,测试文本为50。此时迭代结果如图3所示。
图3 实验结果
改变主题数K的值,依次取值为2、5、10、30、50、70、90。通过不同主题数进行多次聚类实验,确定最优主题数K。
从图4中可以看出,当主题数K为50时,F度量

图4 不同主题数的聚类效果
值最高,可以确定最优主题数为50。同时,LDA模型的聚类效果F度量值相比LSI模型更具有优势。
此外,主题数取值不同,实验的迭代时间会随主题数的增加而线性增长,如图5所示。

图5 不同主题数下实验运行的时间
实验过程中,发现改变主题数K的值,相应的α值也会改变。K值和α成反比关系,显然K值越小,α值就越大,表明每个文档含更少的主题。β一般为经验值,它表示每个主题分布在若干个词上。另外,训练语料的数目S会影响迭代次数Ite,二者成正比关系,但训练语料数目不会影响迭代时间Ite-time。
实验结果如表1所示。
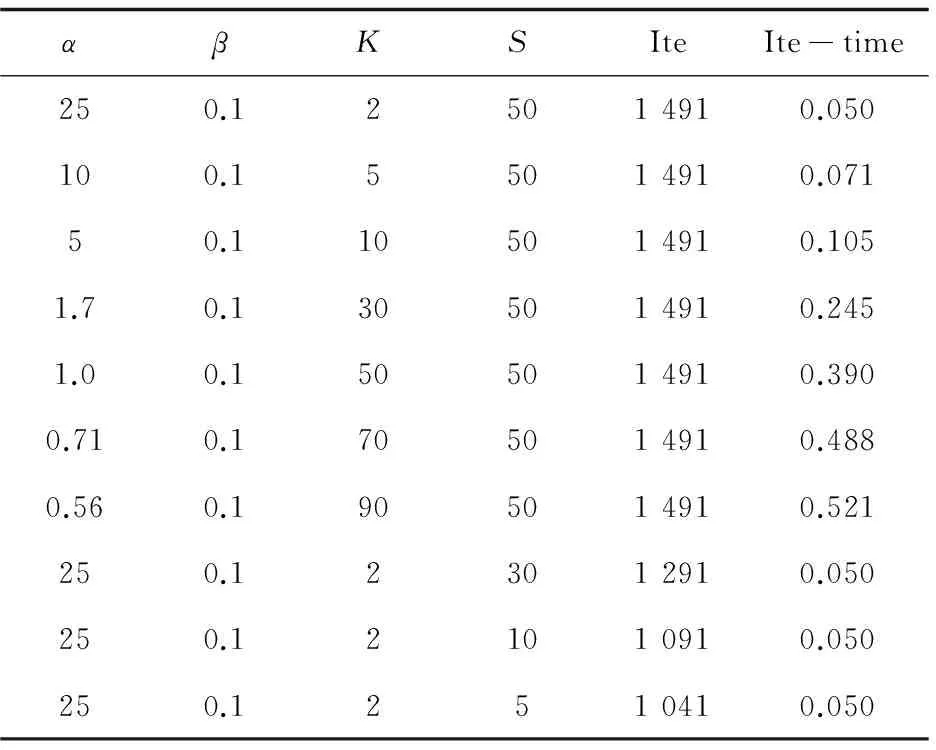
表1 主题数、训练语料数对实验的影响
4 LDA应用于文本挖掘的研究展望
目前,基于LDA模型的主题句抽取方法应用广泛并取得了较好效果。下一步将重点研究如何选择大量未标注的可靠主题句来扩充训练LDA模型,以及如何使用关键词准确地抽取主题句以及候选主题句。通过两者相互促进,提高整体的抽取性能。
基于LDA模型的文本聚类比传统聚类效果更加优越,但这种方法只针对普通文档集。对于数字图书的特殊语料,则需要联合数字图书的信息目录和正文信息进行主题建模的方式进行聚类研究。
基于LDA模型的文本分割在预处理领域极为重要。实验研究过程中,除了需要直接测试,更需要间接测试,即将文本置于应用系统中考查,工作重点是进行更有效的测试。
5 结束语
文中介绍了LDA主题模型,该模型有效解决了LSI模型在文本挖掘中的特征稀疏和分类性能受损问题。实验结果表明,LDA模型应用于文本相似度计算,相对于LSI模型更具有优越性,效率也更高。同时文中简要列举了LDA模型在文本挖掘中的不同应用,并总结了LDA模型在文本挖掘中面临的一些挑战和待解决的问题。LDA模型应用于文本相似度计算,考虑到LDA模型具有易扩展性,下一步工作将在LDA模型的基础上,继续研究、改进文本建模方法及基于其上的文本挖掘。
[1] Deerwester S,Dumais S T A.Indexing by latent semantic analysis[J].Journal of the Society for Information Science,1990,41(6):391-407.
[2] Blei D,Ng A,Jordan M.Latent Dirichlet allocation[J].Journal of Machine Leaning Research,2003,3:993-1022.
[3] Salton G,Wong A,Yang C S.A vector space model for automatic indexing[J].Communications of the ACM,1975,18(11):613-620.
[4] Hastie T,Tibshirani R.Discriminant adaptive nearest neighbor classification[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1996,18(6):607-616.
[5] 刘振鹿,王大玲,冯 时,等.一种基于LDA的潜在语义区划分及Web文档聚类算法[J].中文信息学报,2011,25(1):60-65.
[6] 李文波,孙 乐,张大鲲.基于Labeled-LDA模型的文本分类新算法[J].计算机学报,2008,31(4):620-627.
[7] 石 晶,胡 明,石 鑫,等.基于LDA模型的文本分割[J].计算机学报,2008,31(10):1865-1873.
[8] 徐 戈,王厚峰.自然语言处理中主题模型的发展[J].计算机学报,2011,34(8):1423-1436.
[9] 王李冬,魏宝刚,袁 杰.基于概率主题模型的文档聚类[J].电子学报,2012,40(11):2346-2350.
[10] 姚全珠,宋志理,彭 程.基于LDA模型的文本分类研究[J].计算机工程与应用,2011,47(13):150-153.
[11] Andrzejewski D,Buttler D.Latent topic feedback for information retrieval[C]//Proceedings of 17th ACM SIGKDD international conference on knowledge discovery and data mining.New York:ACM Press,2011:600-608.
[12] Friedman N,Geiger D,Goldszmidt M.Bayesian network classifiers[J].Machine Learning,1997,29(2-3):131-163.
[13] Doucet,Godsill S,Andrieu C.On sequential Monte Carlo sampling methods for Bayesian filtering[J].Statistics and Computing,2000,10(3):197-208.
[14] 马海云.基于Gibbs抽样的测试用例生成技术研究[J].自动化与仪器仪表,2011(3):11-12.
[15] Griffiths T L,Steyvers M.Finding scientific topics[J].PNAS,2004,101(1):5288-5235.
[16] Chang Chih-Chung,Lin Chih-Jen.LIBSVM:a library for support vector machines[EB/OL].2011.http://www.csie.ntu.edu.tw/~cjlin/libsvm.
[17] 杨 潇,马 军,杨同峰,等.主题模型LDA的多文档自动文摘[J].智能系统学报,2010,5(2):169-176.
[18] Duda R O,Hart P E,Stork D G.Pattern classification[M].李宏东,姚天翔,译.2nd ed.北京:机械工业出版社,2003:508-576.
[19] 张明慧,王红玲,周国栋.基于LDA主题特征的自动文摘方法[J].计算机应用与软件,2011,28(10):20-22.
[20] Lin J.Divergence measures based on Shannon entropy[J].IEEE Transactions on Information Theory,1991,37(1):145-151.
[21] Ruthven I,Lalmas M.A survey on the use of relevance feedback for information access systems[J].Knowledge Engineering Review,2003,18(2):95-145.
[22] 王 燕.一种改进的k-means聚类算法[J].计算机应用与软件,2004,21(10):122-123.
[23] 王振振,何 明,杜永萍.基于LDA主题模型的文本相似度计算[J].计算机科学,2013,40(12):229-232.
[24] 周昭涛.文本聚类分析效果评价及文本表示研究[D].北京:中国科学院研究生院,2005.
[25] 姜 园,张朝阳,仇佩亮,等.用于数据挖掘的聚类算法[J].电子与信息学报,2005,27(4):655-662.
Study on Text Similarity Based on LDA Model
CHEN Pan1,YANG Hao1,LÜ Pin1,2,WANG Hai-hui1,2
(1.School of Computer Science and Engineering,Wuhan Institute of Technology,Wuhan 430073,China; 2.Hubei Province Key Laboratory of Intelligent Robot,Wuhan Institute of Technology,Wuhan 430073,China)
LDA topic model is an unsupervised model which exhibits superiority on latent topic modeling of text data in the research of recent years.Considering the disadvantage of the traditional topic model when dealing with the large-scale text corpuses,a method which improves text similarity computations by using LDA model is proposed.It models corpus with LDA,parameters are estimated with Gibbs sampling.Each document is represented for the probability distribution of fixed implied theme set and computed the similarity between the texts.Finally,theK-meansalgorithmisselectedastheevaluationindexoftextsimilarity.ExperimentalresultsshowthismethodcanimprovetheaccuracyoftextsimilarityandclusteringqualityoftexteffectivelycomparedwithLSImodel.
text mining;LDA model;Gibbs sampling;text similarity
2015-07-16
2015-10-21
时间:2016-03-22
湖北省高等学校优秀中青年团队计划项目(T201206);湖北省智能机器人重点实验室开放基金(HBIR201409)
陈 攀(1993-),男,研究方向为文本挖掘与自然语言处理;吕 品,博士,副教授,研究方向为数据挖掘、情感分析;王海晖,博士,教授,硕士生导师,研究方向为智能系统与机器视觉。
http://www.cnki.net/kcms/detail/61.1450.TP.20160322.1521.080.html
TP
A
1673-629X(2016)04-0082-04
10.3969/j.issn.1673-629X.2016.04.18
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
厦门大学学报(自然科学版)(2021年4期)2021-06-22
魅力中国(2020年23期)2020-07-19
计算机应用与软件(2018年9期)2018-09-26
电机与控制学报(2018年9期)2018-05-14
科技视界(2016年19期)2017-05-18
电脑爱好者(2017年7期)2017-05-06
科学家(2016年3期)2016-12-30
