
基于HBase的数据共享模型研究
2016-02-24 10:41陆文星涂竹松
计算机技术与发展 2016年4期
陆文星,涂竹松,梁 焱
(1.合肥工业大学 管理学院,安徽 合肥 230009;2.过程优化与智能决策教育部重点实验室,安徽 合肥 230009)
基于HBase的数据共享模型研究
陆文星1,2,涂竹松1,2,梁 焱1
(1.合肥工业大学 管理学院,安徽 合肥 230009;2.过程优化与智能决策教育部重点实验室,安徽 合肥 230009)
在信息化高速发展过程中,如何共享海量数据并提高其应用价值是当今云计算领域的研究热点之一。传统的数据共享方式不能满足大数据的存储要求和解除高速计算问题与数据的高容错性问题,这就需要新的共享方式来实现。文中在数据仓库的数据集成模式的基础上,根据黑板系统的思想和“发布-订阅”数据分发策略,提出了基于HBase数据库的数据共享模型,并分析了该模型的运行机理。基于HBase的数据共享方式不仅能够提高对海量数据的处理能力和速度,还能有效降低原有数据共享方式中在出现故障时对整个业务系统造成的不良影响。文中提出的基于HBase数据共享模型在云环境下实现海量数据共享的问题上为各大型企业提供了参考,不仅能够满足海量数据的量级持续增长和计算的需求,同时提高了系统可靠性。
数据共享;数据集成;HBase;黑板系统
0 引 言
随着科学技术的飞速发展和信息化的不断推进,企业的IT应用也伴随着信息技术的发展而不断前进,各大型企业、政府机构也都构建了能够应用于自身领域的专属系统,例如企业的ERP系统、金融领域的交易系统、医疗领域的医疗卫生系统、教育领域的教务管理系统等等。但IT应用的变化速度与企业的其他变革有着明显的不同。从企业自身的角度看,前期的系统构建缺乏长远及统筹规划,不同阶段只考虑局部需求,使得系统之间存在着巨大的逻辑差异,大量的冗余数据和垃圾数据不断形成造成了企业、政府机构的信息存储效率低、信息利用率低[1-4]。
文中整合数据仓库的数据集成方式和黑板系统的思想,提出了基于HBase的数据共享模型。模型中采用“发布-订阅”数据分发策略来共享数据,在应对企业内部各分支机构系统之间的孤立、海量数据的存储及处理计算等问题上提出了新的解决思路。
1 数据仓库模式集成和HBase数据库
1.1 数据仓库模式
不同的信息系统在实现数据共享的过程中需要向其他的信息系统展现需要共享的数据信息。在这个过程中,需要在逻辑上或者物理上有机地把不同来源、不同格式以及不同特点性质的数据集成起来,为企业的数据提供全面的共享。目前,数据集成领域比较成熟的框架有三种:基于中间件模式、联邦数据库系统模式和数据仓库模式[5]。这三种模式在不同的重点和应用上为企业的数据共享和决策支持提供了可靠有效的支持。文中采用数据仓库模式来构建数据共享模型,下面只对数据仓库模式的数据集成方法作详细介绍。
这里的数据仓库充当的是一个公共数据库的角色[6]。数据仓库在描述存储在异构数据库中的数据时采用的是统一的全局模式,以副本的形式存储各源数据库中需要共享的数据。该模式通过将各个数据源的数据复制到同一处,即数据仓库[7-8]。用户像访问数据库一样访问数据仓库,如图1所示。在数据仓库模式中,采用ETL工具按照特定的需求对源数据库进行抽取、转换和加载后才进行存储。该模式在数据仓库中统一存储不同信息系统间需要进行共享的数据,同时面向所有用户采用统一数据接口的方式,为用户提供数据访问和分析等数据服务。另外,数据仓库模式是为了有效地把操作型数据集成到统一的环境中以提供决策型数据访问的各种技术和模块的总称,所做的
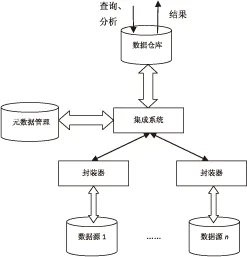
图1 数据仓库集成模式
一切都是为了让用户能够对其所需要的信息进行更快、更方便地查询,以便提供决策支持。
1.2 HBase数据库
HBase的原型来自于Google在2006年11月发表的一篇名为《Bigtable:A Distributed Storage System for Structured Data》[9]的论文。HBase是一种构建在HDFS之上的分布式、面向列的存储系统[10-12]。在需要实现读写、随机访问超大数据集时,可以使用HBase这一Hadoop应用。HBase数据库通过Java编程语言编写而成,其数据模型采用键/值形式,而且存储技术具备开源、分布式、面向列、高可用等特性。HBase不仅能够适合非结构化数据的存储,而且不同于其他基于行模式的关系型数据库,它采用的是基于列的模式。另外,作为Hadoop应用下的分布式数据库,HBase在存储结构化数据时依然具有高可靠性。与传统的关系型数据库不同的是,列式存储是按某列将数据存储在表中,在查询时对字段个数的要求就会降低。这样不仅能解决数据的稀疏性问题,大大减少读取的数据量,在很大程度上为其节约了存储开销,而且能在查询发生时,大大降低磁盘I/O。
在现代大型企业的应用系统中,其关系型数据库的扩展性和海量数据的分析处理能力提升不大主要是基于其关系型数据库连接操作和事务的ACID(Atomicity(原子性)、Consistency(一致性)、Isolation(隔离性)和Durability(持久性))特点。从信息系统整合的集约化原则和保持原有的业务系统角度出发,同时针对不同应用系统间的不同种类(结构化、半结构化和非结构化)的数据,通过借鉴云计算存储和数据仓库共享数据的先进理念,在存储共享数据方面合理运用HBase数据库。这样不仅能够将NoSQL数据库和云计算的有利优势体现出来,而且能够满足海量数据的共享要求。
2 模型的构成
目前国内的大型企业都普遍存在一个显著的特点:下属各级子公司或部门都拥有各自的应用管理系统,而这些管理系统都是相对独立的,系统之间存在着数据的不一致和难以及时准确共享的缺陷。但是随着企业信息化的不断发展,各部门单位信息系统间的数据共享以及新系统的开发对企业数据集成也在不断提高。
在黑板系统的基础上,文中提出了一种基于HBase的数据共享模型。该模型是基于数据仓库的数据集成模式,其中HBase数据库是数据共享的中介仓库,一方面提供虚拟的全局模式视图供各源数据库使用,另一方面对各源数据库有固定订阅需求和共享频率高的数据以数据重建和数据复制方式实现共享。基于HBase的数据共享模型架构如图2所示。
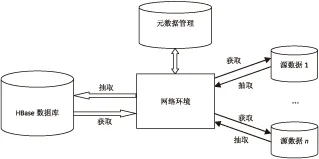
图2 基于HBase的数据共享模型架构
作为模型中数据共享的信息中介平台,HBase数据库与多个源数据库形成交互,维护每个源数据库共享的信息内容,而各源数据库通过HBase数据库共享企业的数据信息。其中,作为企业各应用系统的数据中心存在的各源数据库是相互独立的数据库系统。
2.1 元数据管理
元数据即描述数据的数据,是对应用系统中业务流程、对象信息等数据的描述,常见的数据字典就属于元数据的范畴[13]。技术元数据(Technical Metadata)和业务元数据(Business Metadata)是元数据的两种分类。前者是关于数据仓库技术细节的数据的描述,这些元数据应用于开发、管理和维护数据仓库;后者从商业和业务的角度描述数据仓库的数据,提供了良好的语义层定义,业务元数据使业务人员能够更好地理解数据仓库分析出来的数据,通过分析业务的变化对应用模块的影响,可以帮助用户发现、描述和理解数据,其最大的作用体现在数据质量的保证、资源的管理和对数据的一致性理解上。数据的存储处理不只是ETL过程需要元数据的支持,整个数据仓库建立过程都离不开元数据。
元数据在结构上有三种分类:内容结构、句法结构和语义结构。内容结构在包括编码语言、命名空间、描述元素等信息上对元数据的构成元素和标准进行定义;句法结构在元素的组织、描述方法上对元数据的格式和描述进行定义;元数据的表示含义的描述要求属于语义结构定义的范畴。
元数据的管理主要针对的是技术元数据和业务元数据,管理目标旨在提升共享水平和对企业信息资产的理解。从管理的细节来看,主要操作是对元数据的获取和处理。基于元数据的管理与数据库、应用系统、分析处理共享平台有密不可分的关系,企业管理元数据的途径往往是运用成熟的元数据管理工具,同时建立自身的元数据管理平台。针对元数据的管理存在着两个重要任务:一是元数据库中元数据的存储和维护工作;二是数据仓库中各种工具(如建模工具、数据获取工具等)间的信息传递,以及各模块与工具之间的协调工作。
2.2 黑板系统
文中所提出的基于HBase的数据共享模型主要是基于黑板系统的思想。黑板的概念最早是由Newell提出。1973-1976年间,美国Carnegie-Mellon大学在研制出语音理解系统HEARSAY-II的过程中提出了黑板的问题求解模型[14-15]。其基本思想是:多个个体专家针对同一个问题进行协作求解,在求解过程中拥有一个共享的工作空间即“黑板”,并且所有专家都能“看到”黑板。当黑板上出现求解的问题及求解所需的原始数据时,求解过程开始,所有专家通过“观察”黑板并运用其自身的经验知识开始求解问题。当某个专家发现能通过黑板上现有的信息进行进一步求解,他会将求解的阶段性结果呈现在黑板上,这些新增的信息可能会使其他专家进行进一步求解,不断重复这一过程直到获得最终结果,彻底解决最初问题[16]。
黑板系统主要由三个部分组成:“黑板”、知识源(KS)和监控机构。模型结构如图3所示。

图3 黑板模型
黑板:从前面对黑板系统的介绍来看,“黑板”是一个全局的工作区。文中它是一个存储各个阶段数据的全局数据库。
知识源:就是一个知识模块。上文在介绍黑板系统基本思想时提到的“专家”就是知识源。所有知识源之间相互独立,并且它们之间的联系和调用是通过黑板来完成的。
监控机构:由监控和调度程序组成的一个推理机构,旨在顺利完成问题的求解。监控程序负责监控黑板状态,调度程序则根据黑板状态通过自身策略调度合适的“专家”来解决问题。
文中黑板就是基于HBase的数据共享模型中以数据仓库形式存在的HBase数据库,相应的每个源数据库就是黑板系统中对应的众多的知识源,而共享模型中元数据管理模块就是监控机构。
2.3 数据分发策略
运用“发布-订阅”模型对数据进行分发在目前被各个分布式数据库所采用,该模型主要由消息发布者、消息订阅者和发布订阅服务器三部分组成[17]。订阅者先注册感兴趣的主题,并在主题信息有变化时接收信息,当发布者把一条信息发送至发布订阅服务器时,服务器根据订阅条件与消息进行匹配比较,把信息发送给符合订阅条件的订阅者。模型架构如图4所示。

图4 发布—订阅模型
消息发布者:负责对数据源的数据进行发表的服务器。消息发布者管理多个数据源,将描述数据源的元数据即共享数据模型发布到若干个公共的信息目录服务器上。
消息订阅者:负责接收消息发布者发布出来的数据的服务器。消息发布者既可以对已经发布的数据进行修改,也可以作为其他消息订阅者的发布订阅服务器。
发布订阅服务器:连接消息发布者和消息订阅者的桥梁,负责将发布者发布的数据传送到订阅者。发布订阅服务器提供数据缓存,负责将消息发布者传递过来的发布数据临时存储到分发数据库当中,按一定策略将数据分发给相应的服务器,并且负责维护分发服务器。
这里的消息发布者、消息订阅者和发布订阅服务器只是角色上的描述,理论上这三个角色可以在同一台服务器上实现任意组合,但在实际操作中要考虑系统的性能,通常会对其做出一定的限制。
3 基于HBase的数据共享模型
在基于HBase的数据共享模型中,充当数据仓库的HBase数据库与源数据库构成的数据共享模型主要由5部分组成:共享接口、数据复制、订阅数据、共享数据管理器数据源和元数据管理模块。如图5所示,其中HBase数据库中还另外包含了全局模式视图。
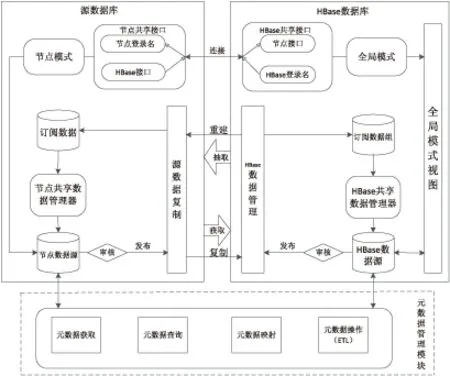
图5 基于HBase的数据共享模型
对上述数据共享模型运行机制的具体介绍如下:
在基于HBase的数据共享模型中,作为“黑板”出现的HBase数据库与每个源数据库也就是各个“知识源”之间是通过其HBase共享接口与节点共享接口的连接实现数据重建和数据复制共享的。其中对数据的重建是HBase数据库共享数据的方式,主要是在数据管理方面对来自于其他系统的数据进行重建,分开存储这些需要共享的数据与系统的其他数据,形成集中管理。这种共享模式通过虚拟映射全局模式和节点模式之间的关系来实现,各源数据库的映射接口由HBase数据库和共享接口来提供,通过映射已经形成连接的共享接口,全局模式会在一定的转换条件下通过定义视图的方式进行映射。另外,全局模式通过重新组合各节点模式的数据,形成全局模式视图。其中,源数据库通过节点共享接口访问HBase数据库的全局模式视图获取数据,而在HBase数据库中当其接收到具体的数据获取请求时,全局模式视图会根据需求完成对源数据库的数据抽取工作,然后将抽取来的数据转换成全局模式数据用以提供给其他源数据库获取。基于HBase的数据共享模型是运用黑板模型的思想构建的,HDFS元数据管理模块就是其“监控机构”。正是通过该模块对元数据的抽取重组形成模式信息,并通过特定的模式管理机制(数据的获取、查询、映射和ETL等操作)对元数据进行监控,通过对其变化情况进行观察,确保模式信息与元数据实时统一。节点数据源通过审核发布共享数据,以数据复制方式并通过HBase数据管理的操作将数据存放到HBase数据库中的订阅数据组当中,然后HBase数据库中的共享模式管理器将这些订阅数据转换为全局模式的共享数据并将其存放在HBase数据源中,同时向发送请求的源数据库发布共享数据或者将共享数据提供给全局模式视图。其中,HBase数据库向源数据库发布共享数据大致与其向源数据库复制抽取数据的过程相同,只不过对数据的操作由复制转换成了重建。数据源通过审核发布共享数据,以数据重建的方式将新的数据存放到源数据库的订阅数据中,然后源数据库中的节点共享数据管理器将这些共享数据转换为该模式下的共享数据存放在节点数据源中。
基于HBase的数据共享模型的性能分析如下:
(1)具有高效的数据操作能力。HBase数据库在对海量数据进行处理时采用Hadoop架构体系的Map/Reduce技术,在处理过程中可以对数据进行高吞吐量的读、写操作,同时在针对海量数据的访问和处理方面具有随机性、实时性。
(2)支持对系统集成的公共数据应用变更的需求。由于HBase数据库在存储数据时能够动态变动其数据库表格,而这一优势在其充当数据仓库时更能凸显出来。HBase数据库在作为数据仓库面对各应用系统相互之间对彼此的数据需求发生变化时,并在能够确保系统其他模块的功能不受干扰的前提下,可以对其数据库表的列簇个数进行动态的增、删、改、查操作,从而达到支持共享应用需求变动的效果。
(3)高效的系统可靠性和可用性。HBase数据库作为数据仓库在存储共享数据方面融合了分布式数据库的分布式存储和关系型数据库的集中管理整个数据库的优势,其多副本的存储机制通过统一的节点HMaster对多个服务节点上的多个副本进行管理。HBase数据库中只要其单个数据节点或单条数据链路正常使用就能正常运行,因此当出现突发状况(如其中某个节点出现故障或者某条链路发生瘫痪时),不会对HBase数据库的正常运行造成影响,其可靠性比其他数据共享方式具有明显的优势。同时,系统的容灾性在多副本存储这一特点上得到显著增强,有利于被破坏数据的恢复。
(4)具有高扩展性。对于传统的数据库来说,扩展就意味着升级服务器,复制数据,但是升级服务器的开销大而且在数据复制的过程中操作繁琐且容易出错。HBase数据库作为公共的数据仓库存储共享数据时可以实现对现有廉价服务器的充分利用,因此扩展对于HBase来说比较简单,无需再购置诸如数据库管理系统、服务器等相关产品。针对HBase的扩展工作,只用在增加其HRegionServer节点之后修改下相关配置文件中的配置信息,再重启HBase和Hadoop即可,其他的工作HBase和Hadoop会自行完成。
(5)具有故障自动恢复能力。HBase数据共享方式在面对系统故障、事务故障、磁盘故障和计算机病毒这四种故障时,具有自动修复的功能。HBase数据库对数据的多副本存储是分布式的,从前文可靠性分析中可以知道,单个数据节点的故障不会对HBase数据库的正常运行造成影响,而该故障节点经过修复后还能通过其他的数据节点服务器对数据进行自动复制。
4 结束语
文中提出的基于HBase的数据共享模型对于目前各大型企业内部相对独立的应用管理系统间数据的不一致和难以及时实现共享等问题是一个良好的解决方案。在企业的信息化建设中,该数据共享模型将企业的信息进行集成,各个部门仍然可以沿用自己独立的应用管理系统,只是将各部门都需要使用的共享数据存储在HBase数据库中。这样一来当其中某个部门需要使用其他部门的信息数据时,就可以直接从HBase数据库中获得,而不再走繁琐的内部流程获取想要的数据。从全局的角度看,这种共享模式有效地促进了企业原系统间的整合和新系统的加入。
[1] 杨善林,罗 贺,丁 帅.基于云计算的多源信息服务系统研究综述[J].管理科学学报,2012,15(5):83-96.
[2] 郭文越,陈 虹,刘万军.基于SOA的数据共享与交换平台[J].计算机工程,2010,36(19):280-282.
[3] 汪晓庆,郑彦兴,史美林.一种有效的数据共享环境多数据源选择算法[J].软件学报,2008,19(2):314-322.
[4] 诸云强,冯 敏,宋 佳,等.基于SOA的地球系统科学数据共享平台架构设计与实现[J].地球信息科学,2009,11(1):1-9.
[5] 陈跃国,王京春.数据集成综述[J].计算机科学,2004,31(5):48-51.
[6]WuD,HåkanssonA.Applyingaknowledgebasedsystemformetadataintegrationfordatawarehouses[M]//Knowledge-basedandintelligentinformationandengineeringsystems.Berlin:Springer,2010:60-69.
[7] 张兴会.数据仓库与数据挖掘技术[M].北京:清华大学出版社,2011.
[8] 周长春,徐宏炳,张小伟.基于共享数据库的数据集成方案的改进[J].计算机工程与设计,2007,28(8):1917-1919.
[9]ChangF,DeanJ,GhemawatS,etal.Bigtable:adistributedstoragesystemforstructureddata[J].ACMTransactionsonComputerSystems,2008,26(2):4-4.
[10] 刘 刚,侯 宾,翟周伟.Hadoop开源云计算平台[M].北京:北京邮电大学出版社,2011.
[11] 陆嘉恒.Hadoop实战[M].北京:机械工业出版社,2011.
[12]WhiteT.Hadoop:thedefinitiveguide[M].[s.l.]:O’ReillyMedia,Inc.,2012.
[13] 李光焰.数据仓库中元数据分类及管理系统研究进展分析[J].情报科学,2004,22(7):889-892.
[14] 冯少荣,肖文俊.并行分布环境下的黑板模型[J].华东理工大学学报:自然科学版,2008,34(1):96-102.
[15] 张松懋.关于黑板模型和分布式黑板模型[J].微电子学与计算机,1993,10(8):1-4.
[16]McManusJW.Designandanalysistechniquesforconcurrentblackboardsystems[J].IEEETransactionsonSystem,ManandCyberneticsPartA:SystemsandHumans,1996,26(6):669-680.
[17] 唐晓光.基于订阅机制的数据共享平台的研究与设计[D].大庆:东北石油大学,2013.
Research on Data Sharing Model Based on HBase
LU Wen-xing1,2,TU Zhu-song1,2,LIANG Yan1
(1.School of Management,Hefei University of Technology,Hefei 230009,China; 2.Key Laboratory of Process Optimization and Intelligent Decision-making of Ministry of Education, Hefei 230009,China)
During the process of high-speed development of informatization,one of the research hotspots in the cloud computing area at present is how to share the tremendous amount of information and improve its application value.The traditional data sharing method cannot satisfy the storage requirements of large data and also cannot solve the problem of high speed calculation as well as the high fault tolerance,which requires a new sharing method.Based on the data integration pattern of data warehouse,according to the idea of the blackboard system and “Publish-Subscribe” data issue strategy,a data sharing model based on HBase database is put forward and the operating mechanism of it is analyzed.Data sharing based on Hadoop not only improves the ability and speed of processing of massive data,but also reduces the potential damage the original data sharing method may cause to the entire system.The study of data sharing based on Hadoop gives reference to large enterprises for sharing of massive data,which not only fulfills the needs of continual steep increasing and computation of massive data,but also improves the reliability of the system.
data sharing;data integration;HBase;blackboard system
2015-01-25
2015-05-18
时间:2016-03-22
国家自然科学基金重点项目(71331002);国家自然科学基金青年基金项目(71201045);安徽省科技攻关计划项目(1301041173)
陆文星(1971-),男,副教授,硕士生导师,研究方向为信息管理和信息系统、项目管理、决策支持系统;涂竹松(1989-),男,硕士研究生,研究方向为云计算。
http://www.cnki.net/kcms/detail/61.1450.TP.20160322.1517.014.html
TP31
A
1673-629X(2016)04-0036-05
10.3969/j.issn.1673-629X.2016.04.008
猜你喜欢
小学生作文(低年级适用)(2021年4期)2021-04-25
电子乐园·下旬刊(2021年3期)2021-02-08
少先队活动(2020年8期)2020-09-11
小型微型计算机系统(2019年3期)2019-03-13
诗潮(2019年1期)2019-01-25
计算机与生活(2018年3期)2018-03-12
山东工业技术(2016年15期)2016-12-01
国外科技新书评介(2016年8期)2016-11-16
电脑爱好者(2015年20期)2015-09-10
卷宗(2014年12期)2014-04-02
