
基于工具书语料的国史知识库构建和检索
2016-02-15 09:00:44辉王颖张智雄
现代情报 2016年1期
孙 辉王 颖张智雄
(1.中国社会科学院当代中国研究所,北京100009;2.中国科学院文献情报中心,北京100190)
基于工具书语料的国史知识库构建和检索
孙 辉1王 颖2张智雄2
(1.中国社会科学院当代中国研究所,北京100009;2.中国科学院文献情报中心,北京100190)
工具书语料是构建知识库的基本知识来源。本文给出基于工具书语料的知识库构建和检索流程,从概念关系模型构建、初始实例获取和知识库编辑等方面探讨基于工具书语料的国史知识库构建;除了实现对象属性检索和语义关联检索外,利用工具书衍生的变体词表还可以实现问答式检索。文章还指出工具书语料在知识来源揭示、超文本检索方面的作用。
工具书语料;国史;知识库;语义检索
[9]提出的知识采集模型,本文在文献[10]提出的七步法基础上,提出基于工具书语料的知识库构建和检索流程,如图1所示(单线箭头表示知识库构建流程,双线箭头表示知识库检索过程)。
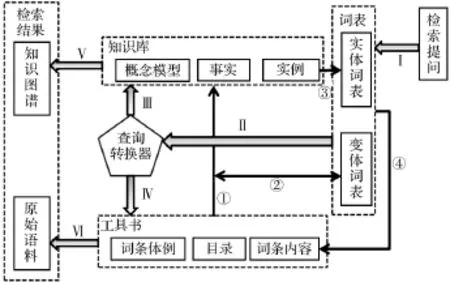
图1 基于工具书进行知识库构建和检索的流程框架
①通过信息抽取,工具书语料向知识库进行知识迁移;
②在知识迁移过程中,通过对词条体例和词条内容分析,找到部分自然语言与知识库中实例类型、属性的可能对照关系,形成变体词表,变体词表可以辅助信息抽取;
③部分初始实例来源于工具书中的经过清洗的词表和目录标题,随着实例增加,定期将所有实例和其别称转换成实体词表;
④用实体词表和变体词表对词条内容进行语义标注,辅助信息抽取。
Ⅰ输入检索问句;
Ⅱ用实体词表切分检索问句,得到实例;用变体词表切分检索问句,经转换,得到相关实例概念类型和属性;
Ⅲ经过查询转换器,得到相应的检索模式,对知识库进行对象检索、关联检索和提问检索等语义检索;
Ⅳ对工具书进行全文检索;
Ⅴ知识库的检索结果为知识图谱,知识图谱中给出实例或事实的语料来源;
Ⅵ语料库的检索结果为有关工具书词条。
2 基于工具书语料的国史知识库构建
在工具书语料向知识库进行迁移时,各种工具书语料对知识库构建的贡献不同,同一工具书的不同要素也分别发挥不一样的作用,具体如表1所示。

表1 各种知识来源对国史知识库的贡献
2.1 概念模型构建
2.1.1 从工具书种类和目录中提取核心概念及其层次关系
国史工具书一般为人物名录、地区名录、机构名录、大事年表等,这些图书的类型本身就反映了“人物”“地区”“机构”“事件”等是国史领域的关注重点,可以成为知识库的核心概念。国史领域的相关词表,如《中图法》中《中国地区复分表》,其反映的地区之间的层次关系,可以直接利用。一些工具书的目录结构,反映了领域知识的分类和层级关系,例如《中国共产党历史大辞典》,按“人物”“事件”“会议”“组织”“文件”“著作”“报刊”“名词术语”“路线方针”类别来组织词条,非常合理地体现了国史领域的核心概念类型;《中华人民共和国职官志》的目录将“组织机构”分为“中央”和“地方”两类,其中“中央”包括“中国共产党”“全国人民代表大会”“中华人民共和国政府”“中国人民政治协商会议”“中国人民解放军”“各民主党派和工商联”“各人民团体”,“地方”包括地方的党政军机构,可直接用于“组织机构”类的概念层次划分。
2.1.2 从工具书编纂体例凝练概念关系及其约束
在词条编纂过程中,大型工具书都规范的体例。例如,“人物”词条,一般描述了人物的籍贯、出生和死亡时间、曾用名、所属党派、学历,并以工作时间为序介绍其含所担任的行政职务和社会职务;“文件”词条,描述了文件的起草者、发布时间、发布场合、发布内容等。这些体例反映了概念的基本属性。
在工具书语料中选取典型词条文本,以语句为单元进行分析,可以发现,每条语句包含一条或多条RDF三元组事实,一般主语直接包含主体名称或别称,宾语包含客体名称或别称,而谓词一般隐含在谓语动词中。同时,某些谓语动词、介词、时间地点状语等,往往与一类概念或一种关系的多个自然词汇相关。建立变体词表,存储这些“自然语言”与“相关概念类型”“相关属性”之间的对应关系。变体词表既可以通过文本标注辅助关系抽取,又可以参与问答式检索的分词。典型词条语料分析,有助于归纳凝炼出某类概念的共同特质,包括概念属性和约束。表2给出了文本分析样例,该文本来自《中华人民共和国史百科》中的“中共七届六中全会”词条(图2),表3为经文本分析而归纳衍生的变体词表(部分)。国史概念关系模型(片段)如图3所示。

图2 词条样例
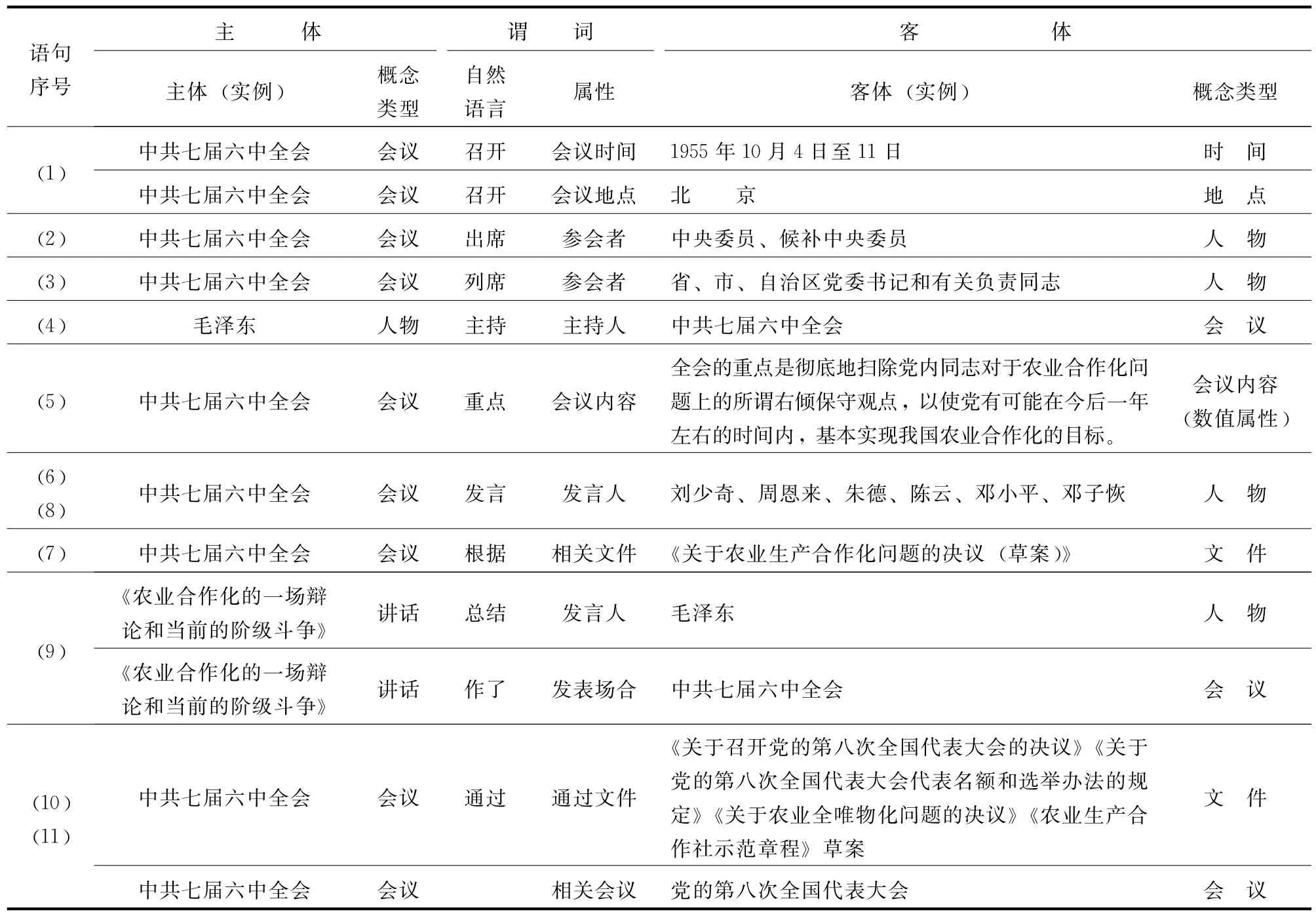
表2 文本分析样例

表3 变体词表(片段)
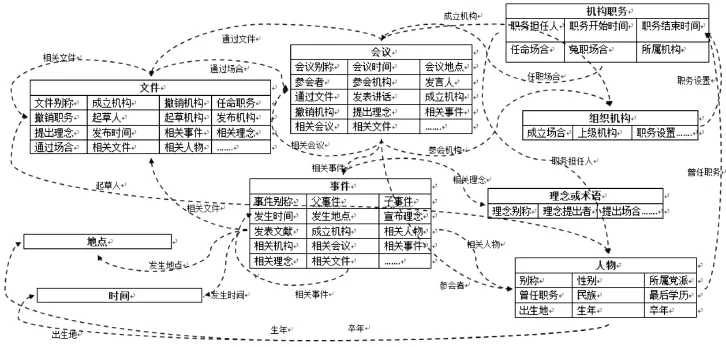
图3 国史概念模型(片段)
通过语料分析发现,在国史概念模型中,以下属性约束尤其重要。
(1)名称约束
实例名称惟一,即实例名称与其他实例的名称或别称不能相同,但不同实例允许具有相同的别称。例如,国史上“王力”有两个,一个是语言学家“王力”,一个是文革人物“王力”,那么前者的实例名称是“语言学家王力”,后者的实例名称是“文革王力”,二者的别称都是“王力”,这种约束设定是体现了实体命名规范性,又兼顾了自然语言,方便了语料的实体抽取后续检索词切分和定位。
(2)层级约束
在“组织机构”和“事件”中存在上下位等级传递关系,不能出现越级情况。例如,A的上位词为B,且B的上位词为C,此时B和C的上位词不能是A。由于知识库编辑是多用户离散式的,层级约束的检查很重要。
(3)互逆关系
互逆关系指谓词存在逆属性,如果属性P1与P2是互逆属性inverseOf(P1,P2),那么(A,P1,B),(B,P2,A)是成对出现的三元组。例如,在“会议”类中有“通过文件”这一属性,在“文件”类中有“通过场合——会议”这一属性,“通过文件”与“通过场合——会议”是互逆关系,当增加“中共七届六中全会——通过文件——《关于农业合作化问题的决议》”这一条事实的同时,知识库中自动增加“《关于农业合作化问题的决议》——通过场合——中共七届六中全会”这一事实。工具书语料中的词条由于编写角度不同,往往包含重复的事实,这种约束设定,可减少多用户语义冲突,也节约了建库时间。
2.2 初始实例获取
国史知识库的初始实例来源于各类工具书,具体如下:
人物:《党史大辞典(人物篇)》、《中华人民共和国史百科》(人物)、《中华人民共和国主要事件人物》、《中华人民共和国资料手册》(人物)部分的词条名称直接转化并整合;
组织机构:经《职官志》的目录标题直接转化,再通过后期补充。“组织机构”的概念层次和初始实例的基本属性如表4所示,经转化,在知识库中以三元组形式存储。
国家和地区:经《中图法》通用复分表(世界地区表和中国地区表)转化而来,反映了地区间的层次关系和地区别称。
会议:对《党史大辞典(社会主义建设时期)》、《中华人民共和国史百科》、《中华人民共和国主要事件人物》、《中华人民共和国资料手册》《中华人民共和国大事记》的“会议”类词条进行整合,整理其别称。
事件:由于各工具书对事件命名有较大分歧,这项工作需要在国史专家指导下进行整合。
需要说明的是,在语料的实体抽取中,实例别称能帮助识别对不同自然语言表达的同一概念,对于多用户协同编辑的知识库,有效防止同一概念多次命名。因此,在初始实例整理中,应尽量通过自动转换或人工增加方式补全实例别称。
2.3 实例和事实编辑
基于工具书构建的概念关系模型与国史知识库有较高的吻合度,实例和事实的编辑过程就是对工具书相关语料进一步进行事实抽取的过程。文献[8]给出基本思路。本文对其流程作简略描述。
2.3.1 建立实例与语料的对应关系
国史知识库的事实和实例来源于相关语料,需要建立实例与词条语料之间的关联。系统首先对语料进行素材管理,语料以词条为记录单元进行管理,每条记录包括词条名称、词条种类、词条来源、词条内容等字段;再根据实例名称或别称自动建立部分实例与词条之间的关联。对于“人物”“组织机构”“会议”“文献”类实例,实例与词条按名称基本对应;对于“事件”类实例,各种知识来源表达不一致,甚至描述的侧重点也不同,需要人工建立二者之间的关联。图为“素材遴选”界面。需要说明的是,实例和工具书的词条并不是一一对应关系,一个实例的知识来源可以是不同工具书的多个词条,同样一个词条可以作为多个实例的知识来源,比如,有些“事件”实例和“文献”实例的知识来源于同一“文献”类词条。用户在编辑时,可参照多方面的语料,如果二者说法有冲突,人工给出判断。

表4 “组织机构”初始实例
图4 素材遴选
2.3.2 从词条语料获取事实和实例
在概念模型和基础实例相对稳定后,后续的实例增加和事实填充,由编辑根据语义标注后的词条文本人工完成,增加的实例定期导入实体词表,这种循环迭代的方式(图1中的步骤④)复用了知识库的知识,有利于信息抽取,也减少了大量重复编辑。图2中的“黑体”为第一次标注的词条文本(在系统中不同概念大类用不同颜色字体表示),“黑体加下划线”为经后续经实体词表更新标注的。对于“时间”,虽然国史工具书的时间表述有时比较模糊,但有其特定含义,现抽取其语料原文为“时间”实例名称,系统对这种模糊表达按一定规则定义数值属性“开始时间”和“结束时间”,以方便国史知识库的时序检索。例如,“时间”实例名称为“1956年末”(直接取自语料),其缺省的数值属性“开始时间”值为“1956-10-01”,“结束时间”值为“1956-12-31”。由于国史知识库协同编辑的需要(该部分另文论述[11]),编辑人员采用“主体编辑模式”和“事实编辑模式”两种方式进行编辑。在编辑过程中,系统结合“素材遴选”中的词条来源给出每一条事实的知识来源,并在知识图谱中提示,体现了知识库编辑人员的责任意识。
通过多用户协同编辑,当前国史知识库包含19个概念大类、22个数值属性、72个对象属性(图5);实例共约11 618个,其中人物3 480个、组织与机构2 581个、特殊群体103个、会议694个、事件1 711个、理念与术语1 446个、文件1 085个、报告讲话518个,事实共26 780个,实现可视化的问答式检索、时序检索和关联检索功能。

图5 国史知识库包含元素
3 基于工具书语料的国史知识库检索
基于工具书语料的国史知识库建成后,工具书语料并非弃之不用,它仍然保留在系统中,在知识库检索中继续发挥作用。国史知识库使用SQL SERVER存储国史工具书语料和国史本体知识库的加工数据,利用Neo4j存储国史本体知识库并构建了Solr索引,使用Cytoscape Web可视化工具进行知识图谱展示,实现了知识导航、时序检索、实体检索、关联检索、问答式检索和全文检索。时序检索针对具有时间特征(文献发表时间、事件发生时间、会议时间)的对象(文献、事件、会议)提供时间段检索,例如,列举出1951-1952年的国史大事,具备大事记的功能(图6)。实体检索就是构建类似SPARQL查询语句进行RDF三元组检索,关联检索就是利用Neo4j图遍历机制查询RDF图路径,路径越短,概念之间的关系越密切,从而可以发现知识点之间的潜在关联。例如检索对看似不相关的两个人物对象“毛泽东”与“胡耀邦”进行关联检索,检索结果如图7所示,其中最近的路径为经过“1961年全党大兴调查研究之风”这个事件节点,经查证,当年,胡耀邦领导的辽宁海城调查组参与了毛泽东领导的这个事件,这个关联检索反映了胡耀邦“实事求是”的工作作风的形成历程,有利于国史人物研究。

图6 时序检索
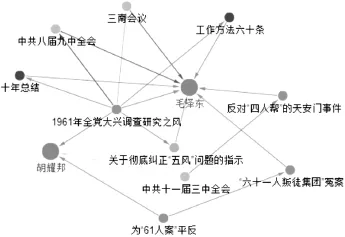
图7 关联检索
问答式检索综合利用文本分析、实体检索、关联检索等手段,对用户的自然语言提问给予回答,检索结果为知识图谱和相关工具书语料,工具书语料衍生的变体词表(表3)在问答式检索中发挥重要作用;系统采用超文本技术实现知识点和相关语料之间的跳转;点击知识图谱的实例或事实,系统显示这条知识来源于哪条工具书语料。在知识库建立之后,工具书语料并没有弃之不用,它在知识库检索中再次发挥作用。本文将具体就此进行分析。
3.1 问答式检索
为满足用户使用自然语言提问的检索需求,系统设计和实现了国史知识问答功能。利用自然语言处理技术对用户提出的问题进行分析,构造针对国史本体知识库的结构化检索式,返回知识图谱和相关语料。将自然语言提问转换成知识库查询是问答式检索的难点。工具书语料本身是用自然语言撰写的,在知识库构建过程中,通过文本分析形成的变体词表曾在概念模型构建和信息抽取中发挥辅助作用,在知识库问答式检索中,该变体词表再次用于提问句切分和识别。
如图8所示,基于自然语言的问答式检索包括以下几步,第一步,提问语句切分;第二步,提问模式识别;第三步,根据提问模式拟定查询语句;第四步,知识图谱展示。
系统利用“实体词表”和“变体词表”对提问语句进行切分(本次切分,不采用传统的分词词典),切分时采用最长匹配方法。“实体词表”的切分结果为实例名称或别称,“变体词表”的切分结果转换为对应的“相关概念类型”“相关属性”,因此,拆分的结果有3种,分别是实例、相关属性和相关概念类型。例如,提问“中共十一届三中全会是何时召开的?”,拆分结果为实例“中共十一届三中全会”,相关属性“会议时间”。
系统根据提问语句的切分结果,将常见问句划为10种提问模式(表5),并给出相应的查询方式,系统根据查询方式拟定相关实体检索语句和关联检索语句。例如“提问模式2”对应的是实体检索;“提问模式7”对应的是关联检索。由于关联检索查询时间与查询路径有关,系统设定问答式检索的查询路径长度不超过2。图7~图15给出每个查询实例的结果界面。
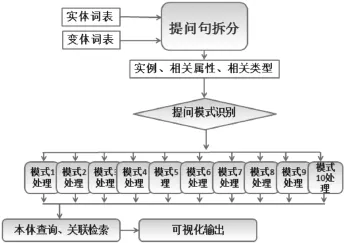
图8 基于自然语言的问答式检索流程

图9 问答式检索界面
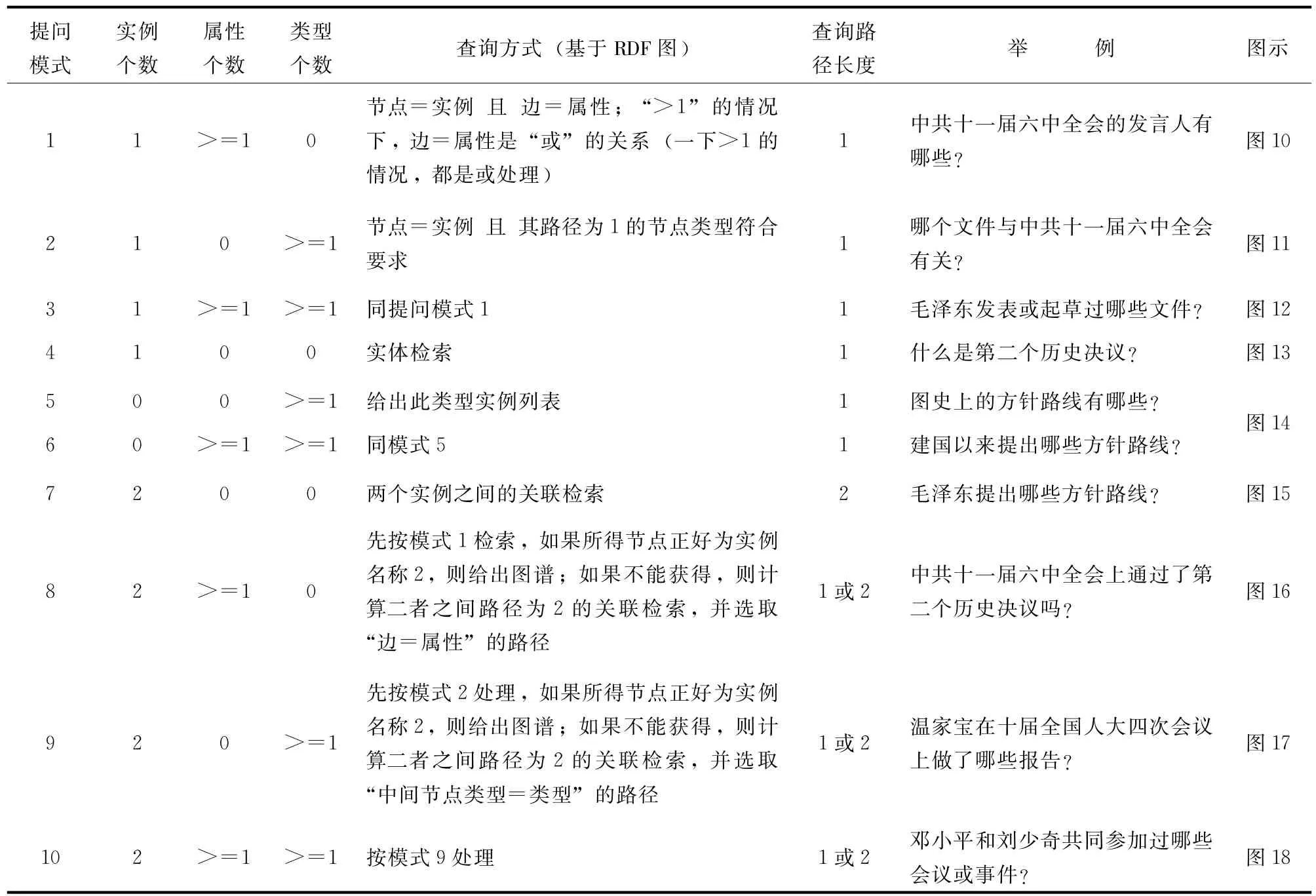
表5 提问模式

图10 模式1

图11 模式2

图12 模式3
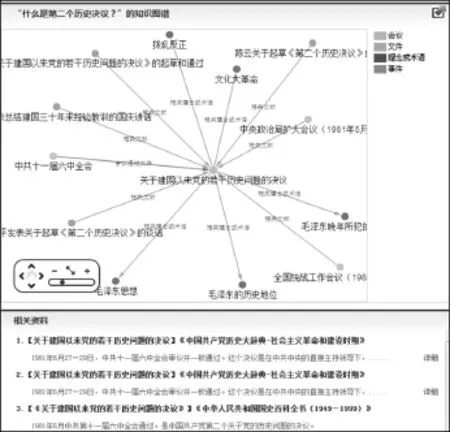
图13 模式4
图14 模式5和6
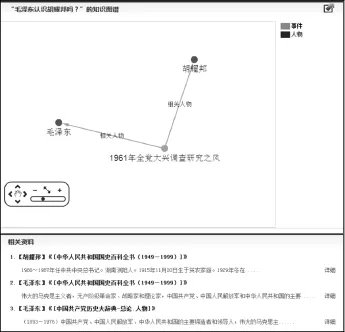
图15 模式7

图16 模式8
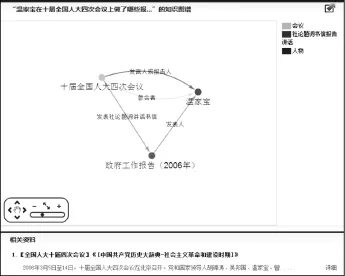
图17 模式9
3.2 超文本检索
无论是知识来源窗口显示的工具书语料,还是全文检索结果界面(见图19),所有语料都经过实体词表标注,不同概念类型用不同颜色表示,用户点击这些有颜色的实体词,可以进行二次知识库检索和全文检索,多次跳转到新的知识图谱和相关工具书语料。
3.3 知识来源揭示
由于在素材遴选和信息抽取过程中,系统记录了实例和事实的来源语料,在知识库检索过程中,用户点击实例或知识图谱中节点之间的连线,可查看来源语料,这丰富了知识图谱的表达形式,也体现了知识库的责任意识和工具书的权威性。

图18 模式10

图19 工具书语料的超文本检索

图20 查看知识来源
4 结 语
本文充分利用国史工具书语料,构建国史知识库并提供多样化检索,检索入口为“中华人民共和国史教育网(http:∥www.hprc.org.cn/)”的“国史百科”栏目。“国史百科”超越了大多数在线百科的全文检索功能,其基于知识库的丰富语义,不仅提供人物、事件、文献、术语导航,还提供时序检索、关联检索和问答式检索,首次在检索结果界面同时提供知识图谱和工具书原文,这种方式,全方位展示了国史概念之间的关系,实现了知识图谱漫游式检索,既丰富了用户的检索体验,又保证了知识库的严谨性和规范性。该项研究对普及国史知识和深入国史研究提供帮助。
参考文献
[1]董慧,余传明,杨宁.基于本体的数字图书馆检索模型研究(Ⅲ)——历史领域资源本体构建[J].情报学报,2006,(5):564-574.
[2]董慧,徐雷,王菲,等.语义分析系统研究(Ⅰ)——史籍语义分析流程[J].情报学报,2014,33(2):183-194.
[3]董慧,徐雷,王菲,等.语义分析系统研究(Ⅱ)——史籍推理机制[J].情报学报,2014,33(2):195-203.
[4]董慧,徐雷,王菲,等.语义分析系统研究(Ⅲ)——中华史籍语义分析系统实现[J].情报学报,2014,33(2):204-214.
[5]吴丽杰.基于本体的特色数据库知识组织研究[J].图书馆学刊,2012,(3):41-43.
[6]彭炜明,宋继华.《资治通鉴》历史领域本体构建及其应用研究[J].中文信息学报,2010,(2):33-38.
[7]丁晟春,傅柱.基于航天叙词表的领域本体半自动化构建研究[J].情报理论与实践,2011,(11):113-116.
[8]王颖,张智雄,孙辉,等.国史知识的语义揭示与组织方法研究[J].中国图书馆学报,2015,(4):55-64.
[9]王昊,谷俊,苏新宁.本体驱动的知识管理系统模型及其应用研究[J].中国图书馆学报,2013,(2):98-110.
[10]Natalya F.Noy and Deborah L.McGuinness.Development 101:A Guide to Creating Your First Ontology[OL].http:∥wenku.baidu.com/view/30fb4b956bec0975f465e2bf.html,2013-07-25.
[11]孙辉,王颖,张智雄.本体构建中的协同问题研究——以中华人民共和国史本体为例[J].情报学报.
(本文责任编辑:郭沫含)
Building and Retrieval of Knowledge Base on the Contemporary Chinese History Using Reference Books
Sun Hui1Wang Ying2Zhang Zhixiong2
(1.Institute of Contemporary China Studies,Chinese Academy of Social Science,Beijing 100009,China;2.National Science Library,Chinese Academy of Sciences,Beijing 100190,China)
Refrence books are basic resource in building knowledge base.This paper gave the process of building and retrieval knowledge base using reference books.It researched the role of reference books in the knowledge base building from the perspective of concept relation model building,the initial instance acquisition and knowledge base editing.The variant terms derived from reference books can help realize question-and-answer retrieval.It also pointed out the role of reference books in hypertext retrieval.
reference books;Chinese history;knowledge base;semantic retrieval
10.3969/j.issn.1008-0821.2016.01.012
G254.92
A
1008-0821(2016)01-0064-10
1 基于工具书语料的知识库构建和检索流程框架
2015-10-20
中国社会科学院哲学社会科学创新工程信息化项目“中华人民共和国史教育网”的研究成果之一。
孙 辉(1971-),女,副编审,博士,研究方向:信息组织,知识管理。
利用语义技术构建历史领域知识库,增强历史认知,促进历史普及,辅助历史研究或资源检索,已经成为重要的知识服务方式。武汉大学董慧教授早在2006年就以《国共合作通史五卷本》为蓝本构建国共合作历史本体[1],2014年又以中华书局出版的《二十四史》为蓝本实现中华史籍语义分析系统[2-4],吴丽杰[5]通过人工构建东北抗战史本体辅助资源组织,彭炜明以《资治通鉴》为蓝本构建资治通鉴本体[6]等,上述文献面向不同时代的历史知识领域,在概念关系模型构建、信息抽取、语义推理、知识库检索和资源组织等方面做了有益的尝试。由于历史领域知识存在模糊性和不确定性,选择史料而不是一味依靠专家头脑中的知识作为知识库的知识来源,能够保证知识库的严谨和规范,其知识有据可查,这种构建方法越来越成为一种趋势。历史学科的特点是,越是近期的历史,史料越丰富。中华人民共和国史(简称国史)指1949年建国以后的历史,这段时期的史料比古代史和近代史的总和还要多。如何选择合适的历史语料作为国史知识库的知识来源,是构建国史知识库必须考虑的问题。本文认为,大型词表、词典、百科类的工具书由数位领域专家数年集体创作而成,是对领域知识提炼加工的结晶,其体例、选材、文字组织和术语表达都有一定规范,包含了学科领域的基本知识。固化在工具书中的知识具有权威性、完整性、规范性、一致性,对于构建领域知识库来说,工具书是高度浓缩、转化度比较高的语料。因此,建议借鉴自然科学领域利用叙词表构建领域知识库的经验[7],研究国史知识的语义揭示和组织方法[8],利用工具书语料构建国史领域基本知识库,再通过其他研究成果类语料对知识库进行补充。本文首先给出基于工具书语料的知识库构建和检索流程,从概念关系模型构建、初始实例获取和知识库编辑等方面探讨基于工具书语料的国史知识库构建,除了实现对象属性检索和对象语义关联检索外,还利用工具书衍生的变体词表实现问答式语义检索,并指出工具书语料在知识来源揭示、超文本检索方面的作用。本文重点介绍工具书语料在国史知识库构建和检索中的作用,关于本系统架构和功能平台实现,另文讨论。
猜你喜欢
英语世界(2021年13期)2021-01-12 05:47:51
中华诗词(2019年2期)2019-11-15 08:27:56
中华诗词(2019年1期)2019-08-23 08:24:20
三门峡职业技术学院学报(2019年4期)2019-05-20 09:37:18
——小学语文阅读教学中使用工具书的指导
陕西教育·教学(2017年9期)2017-04-14 12:59:39
国家图书馆学刊(2016年2期)2016-10-09 06:19:31
中国火炬(2015年7期)2015-07-31 17:39:57
中国火炬(2015年6期)2015-07-31 17:25:51
江西理工大学学报(2014年4期)2014-02-28 11:32:10
黑龙江史志(2013年7期)2013-08-15 00:46:01
