
认知诊断计算机化自适应测验中新的选题策略:结合项目区分度指标*
2016-01-10 00:48郑蝉金边玉芳宋乃庆夏凌翔
心理学报 2016年7期
郭 磊 郑蝉金 边玉芳 宋乃庆 夏凌翔
(1西南大学心理学部,重庆 400715) (2西南大学统计学博士后科研流动站,重庆 400715)(3中国基础教育质量监测协同创新中心西南大学分中心,重庆 400715) (4江西师范大学心理学院,南昌 330022)(5北京师范大学中国基础教育质量监测协同创新中心,北京 100875) (6西南大学基础教育研究中心,重庆 400715)
1 引言
近些年,国内外心理测量着重于形成性评估(formative assessment
),它要求提供给教育工作者和学生更多的测验信息,以帮助教师教学和学生改进。基于此,认知诊断评估(Cognitive Diagnostic Assessment,
CDA)通过测查学生是否掌握了某一知识领域内的认知属性和技能而蓬勃发展。计算机化适应性测验(Computerized adaptive testing,
CAT)是量体裁衣式的新型测验形式,在美国得以广泛运用,例如研究生入学考试(Graduate Record Examination
,GRE)、美国护士资格考试(The National Council of State Boards of Nursing,
NCSBN)等。和传统纸笔测验相比,CAT测验长度更短,能力估计精度更高。将CDA和CAT结合兼具二者优势,能够快速精准地得到学生知识状态(Knowledge State,
KS),该测验形式被称作认知诊断计算机化自适应测验(Cognitive Diagnostic Computerized adaptive testing,
CD-CAT;Cheng,2009)。和传统CAT一样,CD-CAT同样具有5个重要组成部分(郭磊,2014)。其中,研究最多的当属选题策略(Cheng,2009;Wang,Chang,&Douglas,2012;Wang,Chang,&Huebner,2011;Xu,Chang,&Douglas,2003;毛秀珍,辛涛,2011;尚志勇,丁树良,2011;汪文义,丁树良,宋丽红,2014),因为选题策略的好坏不仅影响测验效率,还影响题库的使用情况,通常被视作CAT系统的核心成分。CD-CAT在形成性评估中的一个重要作用是让教师能在课堂中快速地掌握学生的学习动态。例如,上课前几分钟,教师用较短的测验可以初步掌握学生的知识状态,便于接下来有针对性地进行课堂教学。因此,如何能在较短测验中准确地估计学生的知识状态尤为重要,这就跟选题策略息息相关。目前,在众多选题策略中,效果较好并且应用较多的是后验加权库尔贝克-莱布勒信息量法(Posterior-Weighted Kullback-Leibler,
PWKL;Cheng,2009)。该方法将每次更新后的被试知识状态的后验概率作为权重融合到库尔贝克-莱布勒信息量(Kullback-Leibler information
)指标中,大大提高了被试KS的估计精度。但PWKL指标仅从个体层面(person-level
)对KL信息量进行加权,并未考虑项目质量对估计精度的影响,属于单源指标(single-source index
)。在经典测验理论(Classical Test Theory
,CTT)和项目反应理论(Item Response Theory
,IRT)中,题目的质量决定着测验的质量,而题目质量中比较关键的指标之一就是项目区分度(item discrimination
)。项目区分度较高,表明该题目能够较好地区分出高能力被试和低能力被试,这也是测验编制所追求的目标之一。正是基于项目区分度如此重要的作用,Chang和Ying (1999)在传统CAT中提出了著名的a分层选题法。他们建议在测验初期使用区分度较低的项目,因为测验初期对被试能力值的估计还不是很精确,无需使用项目信息量较高的项目,等到测验后期需要对被试能力值进行精确估计时,再使用高区分度的项目。同样,在CDA领域,我们仍需考虑项目质量的问题。若项目区分度较高,则题目能够区分出掌握该题目所考察属性的被试和未掌握该题目所考察属性的被试的能力(power
)就较大(Rupp,Templin,&Henson,2010)。可以看出,不论测验理论是CTT,IRT,还是CDA,项目区分度均是用来衡量题目能否有效区分出高能力被试和低能力被试(或不同知识状态)的关键指标。Rupp等(2010)书中第13章总结了当前CDA中常用的一些项目区分度指标,主要包括两大类:一类是基于CTT思想提出的项目区分度指标,另一类是基于KL信息量提出的项目区分度指标。另一方面,Wang(2013)基于互信息理论提出了互信息选题方法(Mutual Information Method
,MIM),模拟研究结果表明 MIM 在大多数实验条件下的判准率要优于PWKL,特别是在测验长度较短(5题)时,但 MIM并未考虑项目区分度信息。与传统CAT一样,在CD-CAT的实际应用中,不容忽视的一个重要问题是项目曝光问题。当前CD-CAT着重于测量精度的实现,较少考虑项目曝光问题,导致题库使用极其不均匀,优质题目曝光十分严重(Wang et al.,2011)。在选题策略的研究中,估计精度和项目曝光度往往是相互制约的。因此,要全面考察一个选题指标的好坏,并与实际应用情景相符,对项目过度曝光的控制是很重要的。但即使是在 Wang (2013)的研究中,也未曾考虑曝光控制问题。
查阅国内外相关文献,将区分度信息纳入CD-CAT选题过程的研究并不多,据我们所知,汪文义等(2014)基于CTT的思想将项目区分度信息纳入选题策略中进行了研究,但该方法不仅在加权形式上与 Rupp等(2010)提出的加权形式不同,而且也不是对PWKL指标的加权。除此之外,尚未见到基于KL信息量提出的项目区分度加权指标。因此,本文以确定性输入,噪音“与”门(the Deterministic Inputs,Noisy “and”Gate
,DINA)模型为例(DINA 模型是认知诊断研究中最常使用的模型,由于 DINA模型参数较少、简单易懂、方便解释,因此成为了许多研究者修正和拓展的基础模型),将项目区分度信息融入选题策略中,对 PWKL指标进行修正,提出4个新的多源选题指标(multiple-source index
),分别称作:基于经典测验理论的项目区分度加权法(CTT-analogous item-discrimination-posterior-weighted Kullback-Leibler
,CIDPWKL)、基于KL信息量的全局项目区分度加权法(KLI-based global-itemdiscrimination-posterior-weighted Kullback-Leibler,
GIDPWKL)、基于KL信息量的属性层面项目区分度加权法(KLI-based attribute-specific-itemdiscrimination-posterior-weighted Kullback-Leibler,
AIDPWKL)、以及使用汪文义等(2014)提出的权重加权方法(本文将该方法称作 KLEDPWKL法),并在加入曝光控制技术下,将4种新方法和PWKL、MIM 在不同实验条件下进行系统比较,以验证新方法的优越性。本文按如下方式组织。首先对DINA模型进行简单介绍,其次对 PWKL、4种新的选题方法、以及MIM方法进行详细介绍。第四部分和第五部分分别进行两个模拟研究,最后部分为本文的研究结论,讨论及展望。
2 DINA模型简介
DINA模型是具有显式项目特征函数的诊断模型(Haertel,1989;Junker &Sijtsma,2001),其数学表达式为:
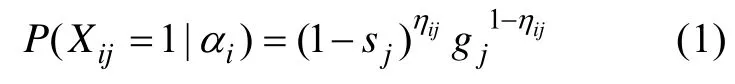
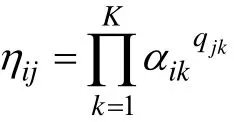
3 相关选题策略介绍
Cheng (2009)在提出了PWKL指标的同时还提出了 HKL指标,并通过模拟研究发现两者的表现相差无几。由此表明,仅仅在 PWKL指标中融入KS之间距离的加权做法收效不大。受Cheng的研究和项目区分度效能的启发,一个更加合适的权重应该是 CDA中的项目区分度(请见本文 3.3和3.4部分介绍)。因为项目区分度不仅包含了项目是如何考察K
个属性的信息(即Q矩阵中的q
向量),还包含了项目参数以及被试KS之间不同组合提供的信息,提供的信息更加丰富。下面将分别对本文涉及的6种选题方法进行介绍。3.1 PWKL指标
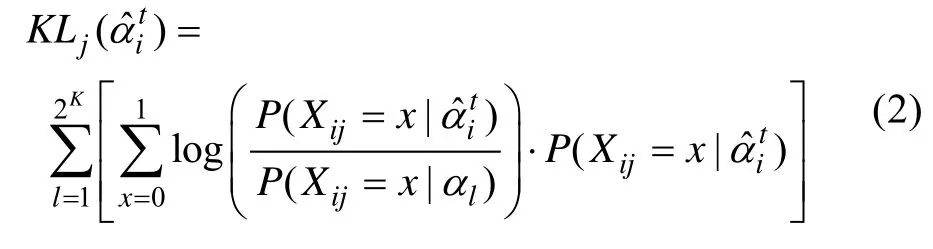
但KL选题策略中KL指标是计算当前估计的KS与所有可能KS之间的KL距离的等权之和,该做法不太合理。Cheng (2009)认为,随着被试作答项目数量的增长,被试能提供更多的诊断信息,因此各种可能的KS之间的后验概率差异会越来越大,即该被试从属于某类KS的可能性会逐渐增大。于是,她利用后验概率对 KL信息量进行修正,提出了PWKL方法,PWKL指标为:
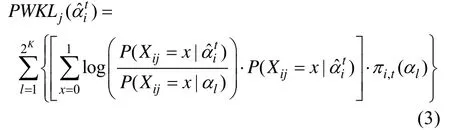
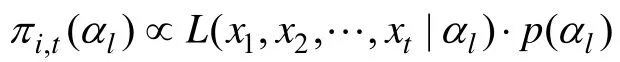
3.2 CIDPWKL指标
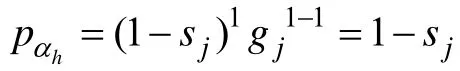
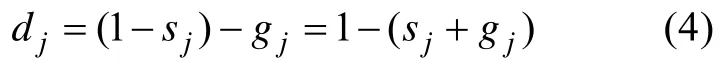
可以看出,一个题目的猜测参数和失误参数的和越小,该题目的区分度就越大。因此,结合了基于CTT思想推导出的项目区分度后,CIDPWKL指标的公式如下:
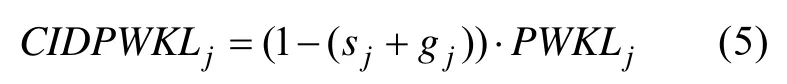
CIDPWKL指标选择题目的标准是:从剩余题库中选择具有最大CIDPWKL信息量的题目给被试作答。
3.3 GIDPWKL指标
Henson和Douglas (2005)指出,如果某个项目能够很好地区分相似的 KS,那么它也能够较好地区分差异较大的KS。基于此,他们提出了全局项目区分度指标CDI (Cognitive Diagnostic Index
)。题目j
的CDI计算公式如下: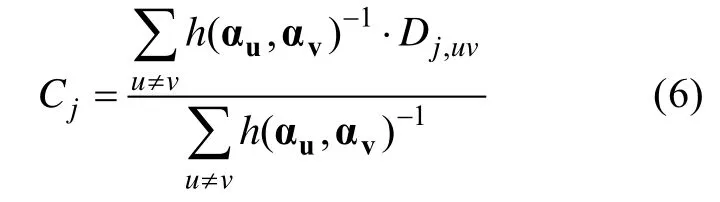
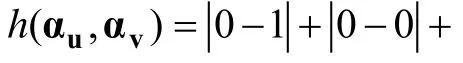
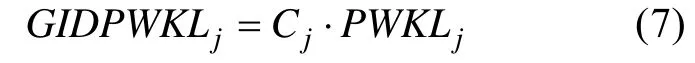
GIDPWKL指标选择题目的标准是:从剩余题库中选择具有最大 GIDPWKL信息量的题目给被试作答。
3.4 AIDPWKL指标
Henson,Roussos,Douglas和He (2008)提出了属性层面(attribute-specific
)的项目区分度指标C
,该指标表示项目j
能够区分掌握属性k
和未掌握属性k
的效能(power
)。基于D
矩阵,C
关注只在属性k
上有差异的那些元素。例如,测验考察3个属性,那么在第一个属性上有差异的元素共包括 8组:000和100、100和000、010和110、001和101、110和010、101和001、011和111、111和011。类似地,可以在D
矩阵中找出在第二个和第三个属性上有差异的元素。由此,项目j
在第k
个属性上的区分度计算公式如下: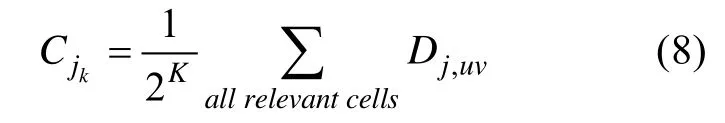
i
考察的属性个数多于项目j
,则项目i
的属性区分度个数也要多于项目j
,因此,项目i
能够贡献的效能就越多。基于此,结合了属性层面的项目区分度指标C
后,AIDPWKL指标的公式如下: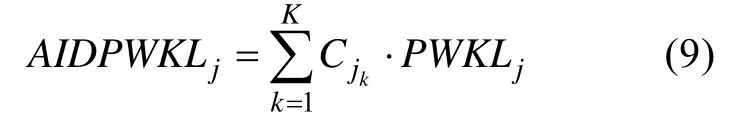
AIDPWKL指标选择题目的标准是:从剩余题库中选择具有最大 AIDPWKL信息量的题目给被试作答。
3.5 MI指标
给定两个随机变量X
和Y
,互信息为两变量边际分布的乘积f
(x
)f
(y
)与它们联合分布f
(x
,y
)的KL距离,其表达式为: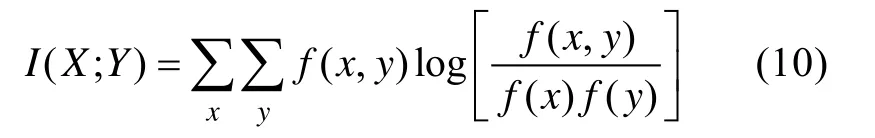
I
(X
;Y
)测量了X
和Y
之间的依赖程度,X
能够提供给Y
越多信息(或Y
能够提供给X
越多信息【互信息的对称性】),I
(X
;Y
)越大。在CD-CAT中,互信息可以看作是临近两次后验概率分布的期望 KL距离(expected KL distance
)。Wang (2013)将KS为α的被试作答完t
-1题的后验概率π
(α|x)替换公式(10)中的f
(y
),将给定作答完t
-1题在第t
题上反应的二项分布p
(x
|x)替换公式(10)中的f
(x
),并通过简单的运算,得到了互信息指标为:

MI指标选择题目的标准是:从剩余题库中选择具有最大MI值的题目给被试作答。
3.6 KLEDPWKL指标
汪文义等(2014)提出了 KLED 选题方法,在DINA模型下可以将其换算为:
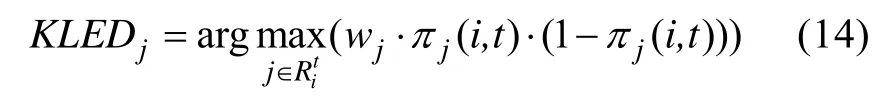
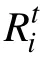
w
与PWKL结合后的KLEDPWKL计算公式如下: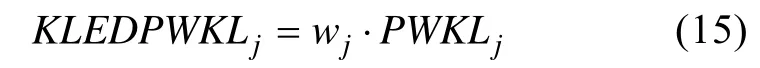
KLEDPWKL指标选择题目的标准是:从剩余题库中选择具有最大KLEDPWKL值的题目给被试作答。
4 模拟研究1
4.1 研究目的
采用蒙特卡洛模拟方法,在固定测验长度条件下比较6种选题策略:PWKL法、CIDPWKL法、GIDPWKL法、AIDPWKL法、KLEDPWKL法和MIM法,重点考察不同选题策略对被试KS估计精度的影响。其中,PWKL法作为基线。所有程序采用Matlab 2012b进行编程。需要指出的是,在进行新方法的编程时,可以提前将D
矩阵以及相应的C
和C
计算好。在每次使用项目区分度信息时,直接从该矩阵中调取即可,这样可以有效提高选题速度。除了一开始计算D
矩阵等需要较短的时间以外,整个选题过程所用时间和PWKL所用时间基本相同。4.2 研究设计
本研究中的Q矩阵包括两种结构(如表1所示):(1)简单结构(S)中包含800题,考察相互独立的6个属性,每个属性有20%的项目考察,每个项目至少考察一个属性;(2)复杂结构(C)中每个属性有 50%的项目考察,其余条件同简单结构。项目的s参数和g参数越小,项目的质量越高,本研究的题目质量包括两个水平:(1)高质量题目的s参数和g参数被定义为平均数为0.1,波动范围为0.05,因此均从U
(0.05,0.15)中抽取;(2)低质量题目的s参数和g参数的波动范围与高质量题目相同,其平均数被定义为0.2,因此均从U
(0.15,0.25)中抽取。测验长度为5题和10题,分别表示较短测验长度和中等测验长度(Wang,2013)。1000个被试KS的真值按照高阶DINA模型生成(Wang,2013),其中高阶能力值θ
从标准正态分布N (
0,1)中抽取,斜率λ
从对数正态分布中抽取,截距λ
从标准正态分布中抽取。在高阶DINA模型中,被试i
在属性k
上的掌握情况为: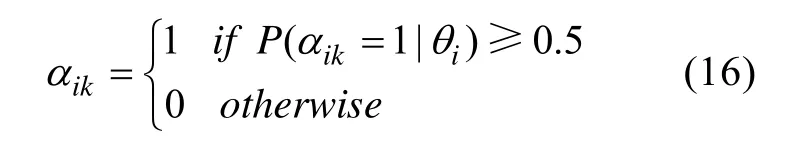
因此,本研究共包括 2(Q矩阵结构)× 2(题目质量)× 2(测验长度)×6(选题策略)=48 种实验条件。每个实验条件重复30次以减小随机误差。

表1 简单结构和复杂结构中每个属性的项目比例
Wang等(2011)提出了两种 CD-CAT中的曝光控制方法:限制进度法(Restrictive Progressive method
,RP)和限制阈值法(Restrictive Threshold method
,RT)。估计精度和项目曝光度往往是相互制约的,比起RT法,RP法在平衡估计精度和项目曝光度方面做得更好,而且本文的目的也并非比较不同曝光控制方法之间的差异,因此,本文借用 RP法的思想作为曝光控制方法(由于篇幅所限,RP法请参见相关文献)。具体而言,当采用本文提出的新选题策略时,按RP法的思想将Wang等(2011)提出的原始公式中的PWKL指标分别替换成CIDPWKL、GIDPWKL、AIDPWKL、KLEDPWKL和MIM 指标,从而实现对题目的曝光控制。其中,允许的最大曝光率设置为0.2,β
=2。4.3 评价指标
(1)平均属性判准率(Average Attribute Correct Classification Rate
,AACCR)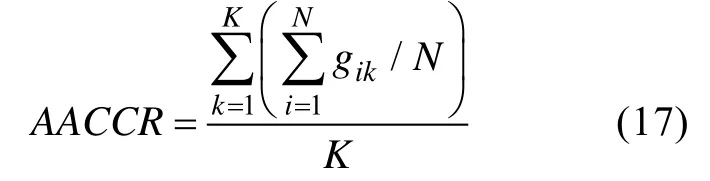
K
个属性,有N
个被试参加了测验,现在考察第k
个属性,如果被试i
掌握(未掌握)第k
个属性,今诊断其掌握(未掌握)该属性,则表明对第k
个属性判准了一次,记为g
=1,否则g
=0。(2)模式判准率(Pattern Correct Classification Rate
,PCCR)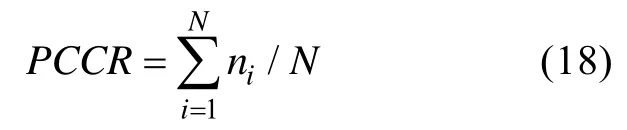
PCCR
考察被试属性掌握模式(α
=(α
,α
,…,α
))的返真性。假设测验共考察了K
个属性,有N
个被试参加了测验,被试i
真实的属性掌握向量记为X,但把该被试归类为 Ζ,如果有X=Z,记n
=1;否则记n
=0。(3)测验重叠率
测验重叠率被定义为两个随机抽取的被试作答相同题目的期望数除以测验长度,计算公式如下:
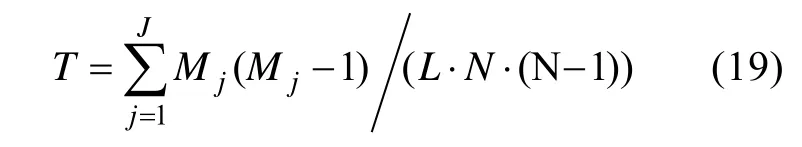
T
表示测验重叠率,M
是第j
个题目被调用的次数,J
是题库大小,L
是测验长度,N
是被试人数。测验重叠率越小,说明两个随机抽取的被试作答相同题目的比例越小。(4)题库使用均匀性指标,卡方χ
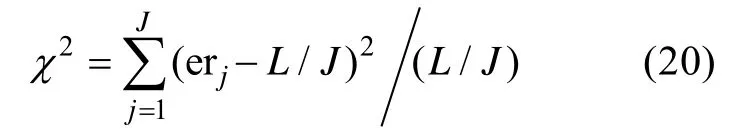
er
是第j
个题目的曝光率,其大小等于作答题目j
的被试人数除以参加测验的总被试人数,其余符号定义同测验重叠率指标。χ
越小越好,χ
越小,说明整个题库使用越均匀。除上述指标外,研究结果还记录了题库中未使用的题目数量。
4.4 研究结果
表2和表3分别是简单结构和复杂结构中6种选题策略在不同测验长度和不同题目质量下的平均属性判准率和模式判准率。由结果可知,在各种实验条件下,与PWKL方法相比,其余5种选题策略的AACCR和PCCR均有不同程度的提高。整体上来看,表现最好的是GIDPWKL指标,其判准率的增长幅度均是最大的,如表2和表3中粗体数值所示。表现次之的是AIDPWKL方法。而CIDPWKL、KLEDPWKL和MIM方法并未呈现出一致的表现结果。例如在简单结构×5题×高质量题目实验条件下,KLEDPWKL的判准率要高于 CIDPWKL和MIM,但在简单结构×5题×低质量题目实验条件下,MIM的判准率要高于其余两种方法。具体来看,在绝大多数实验条件下,测验长度越短,GIDPWKL和AIDPWKL方法的优势越明显,且均要优于其余方法。例如,在简单结构中题目质量较高时,测验长度为5题条件下,与PWKL相比,GIDPWKL和AIDPWKL的AACCR值分别提高了0.025和0.019;PCCR值分别提高了0.051和0.049;当测验长度增加至10题时,GIDPWKL和AIDPWKL的AACCR值分别提高了0.017和0.014;PCCR值分别提高了0.033和0.022。而 CIDPWKL、KLEDPWKL 和MIM之间并没有展现出一致的优势结果,但三者的表现相差无几。
大部分实验结果表明,题目质量越高,GIDPWKL和AIDPWKL方法的优势越明显,且均要优于其余方法。例如,在简单结构中测验长度为5题时,高题目质量条件下,与 PWKL相比,GIDPWKL和AIDPWKL的AACCR值分别提高了0.025和0.019;PCCR值分别提高了0.051和0.049;低题目质量条件下,GIDPWKL和AIDPWKL的AACCR值分别提高了0.024和0.005;PCCR值分别提高了0.037和0.032。而CIDPWKL、KLEDPWKL和MIM 之间并没有展现出一致的优势结果,但三者的表现相差无几。
Q矩阵结构的复杂性也会影响不同选题方法的表现。在大部分实验条件下,Q矩阵越复杂,不同选题方法的AACCR和PCCR的增长幅度也越大。例如,测验长度为10题的高质量题目条件下,在复
杂结构中,GIDPWKL、AIDPWKL、CIDPWKL、KLEDPWKL和MIM的 AACCR值分别提高了0.021,0.015、0.007、0.013和0.015;PCCR值分别提高了0.056、0.043、0.034、0.041和0.038;在简单结构中,GIDPWKL、AIDPWKL、CIDPWKL、KLEDPWKL和MIM的 AACCR值分别提高了0.017,0.014、0.010、0.008和0.011;PCCR值分别提高了0.033、0.022、0.019、0.014和0.020。
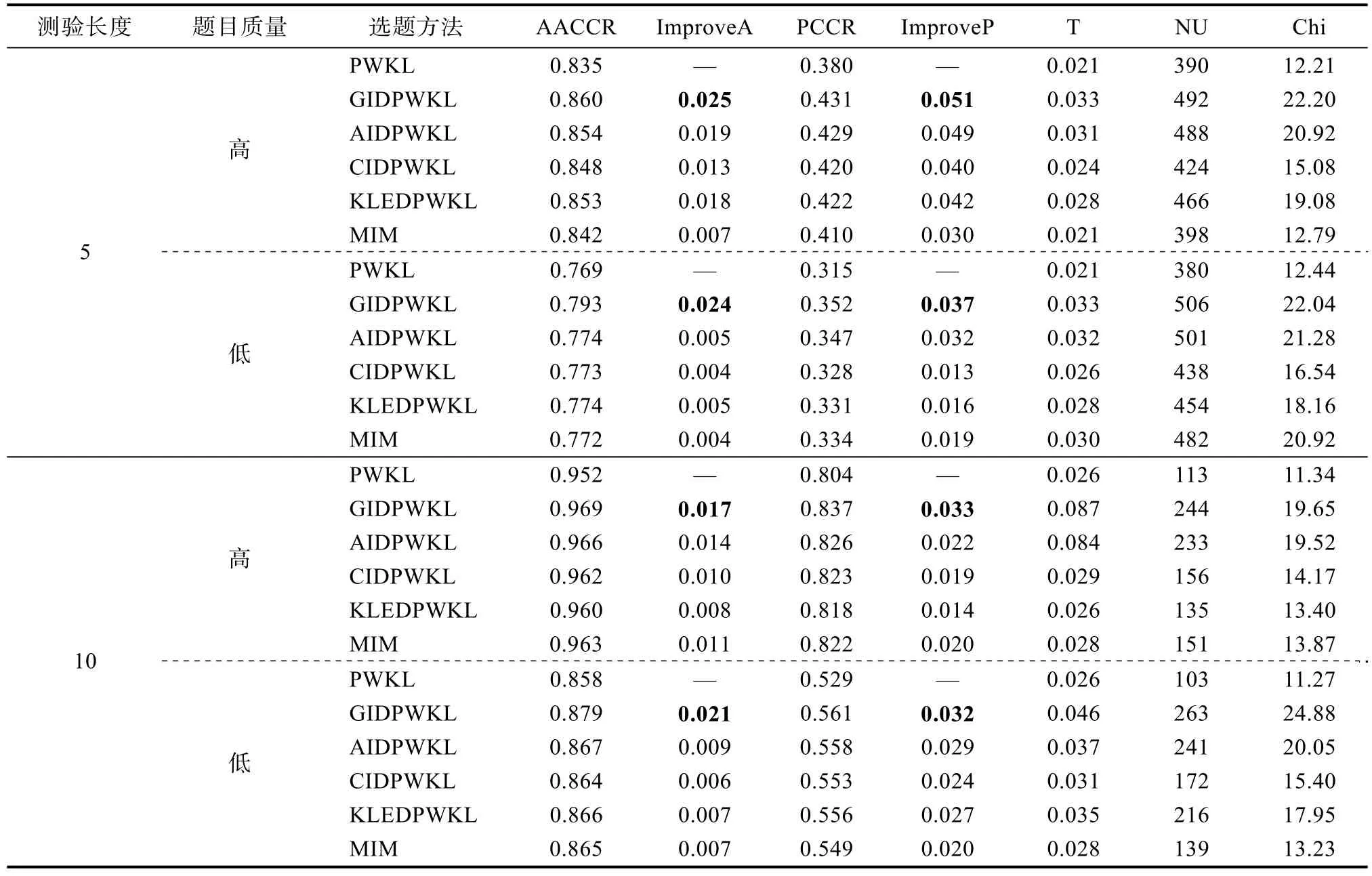
表2 简单结构下不同选题策略的判准率及题库使用情况
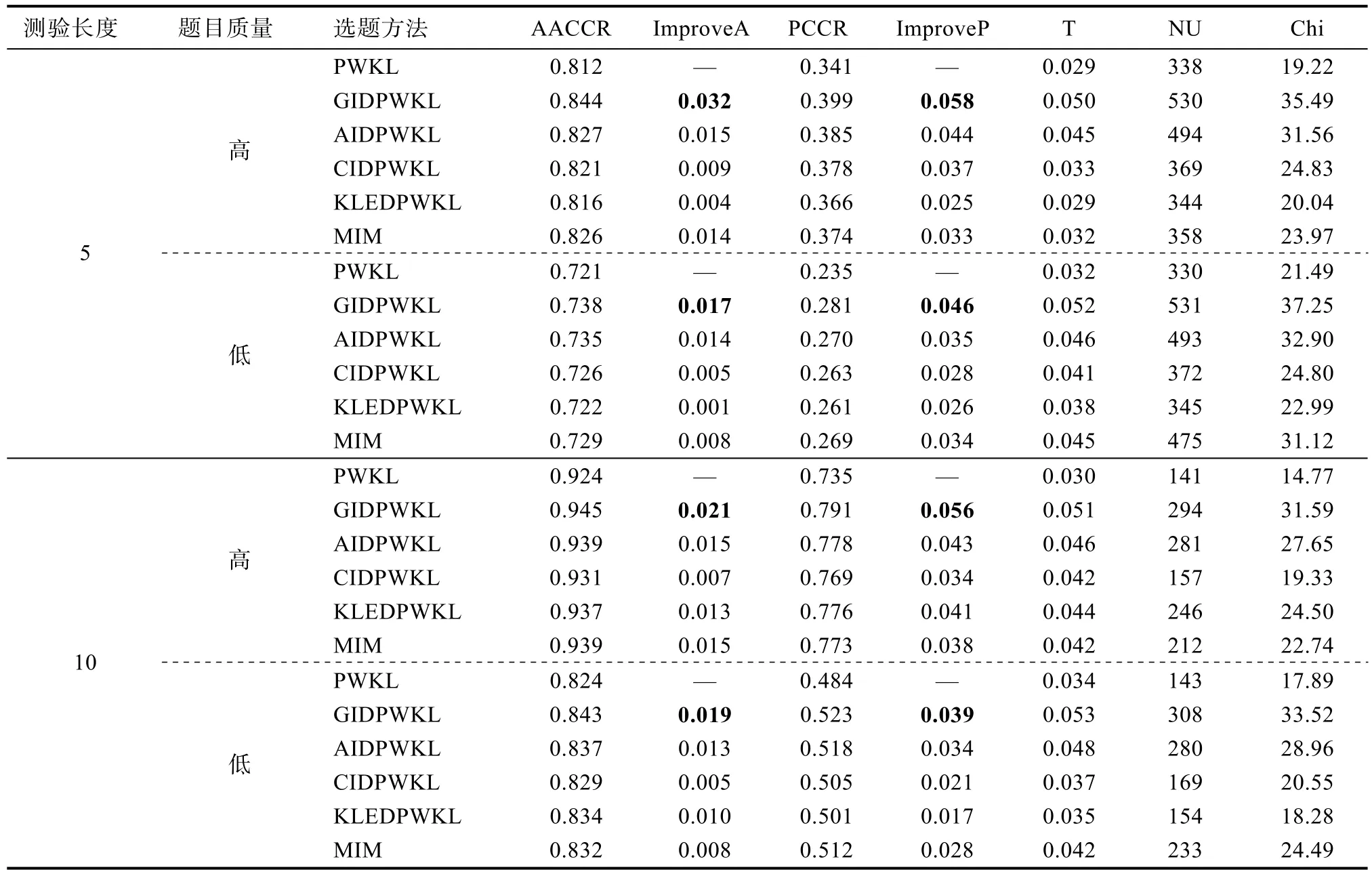
表3 复杂结构下不同选题策略的判准率及题库使用情况
在题库使用情况上,由于GIDPWKL和AIDPWKL方法的判准精度更高,因此这两种方法的测验重叠率,未使用的题目数量以及卡方值也是最大的,其余3种方法虽然判准精度比GIDPWKL和AIDPWKL低,但它们的题库使用情况要更好。该结果正是CAT形式测验中精度与题库使用情况的权衡(trade-off
)问题的体现。由于本研究加入了曝光控制,因此题库使用情况是可以控制在预期范围之内的。5 模拟研究2
5.1 研究目的
采用蒙特卡洛模拟方法,在固定测验精度(Hsu,Wang,&Chen,2013;Tatsuoka,2002;郭磊,2014),即变长终止规则条件下比较6种选题策略。重点考察不同选题策略下的测验使用情况,主要包括平均测验长度 Mean,测验长度的标准差 SD,最大测验长度Max和最小测验长度Min。其中,PWKL法作为基线。所有程序采用Matlab 2012b进行编程。将测验的使用情况作为该研究的评价指标是因为:比较不同的选题策略质量差异时(控制其他条件均相同),若使用定长终止规则,那么判准率高的选题方法较好;若使用变长终止规则,即在固定终止精度时,主要看平均用题量,即平均用题量少的选题方法较好。因此,在研究 2中,我们不再关注判准精度,而是比较不同方法的测验使用情况。
5.2 研究设计
由于研究2采用变长终止规则,一个比较简单可行的做法是通过改变被试KS后验概率分布中的最大值(记作P
)来控制终止精度(Tatsuoka,2002)。本研究的终止精度包括3个水平:P
=0.7,P
=0.8和P
=0.9,其余条件同研究1。郭磊、郑蝉金和边玉芳(2015)提出了3种变长CD-CAT的项目曝光控制方法,研究结果表明,修正的RT法和修正的RP法在项目曝光率的控制上存在过度控制现象,而simple法不存在该现象,并且操作更加简洁,因此,本文选用simple法作为变长CD-CAT中的曝光控制方法。同时为了不让变长CD-CAT的题目过长,与实际情况更加贴近,本文将测验长度上限设置为30题(郭磊等,2015)。simple法是在选题指标前乘以曝光控制因子f
,计算公式如下: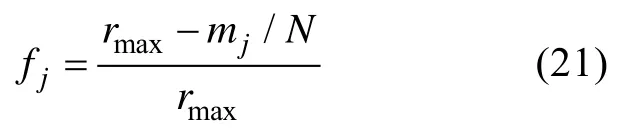
r
为允许的最大项目曝光率(本研究设置为0.2),m
为第j
个项目当前的被调用次数,N
为参加测验的总人数。5.3 评价指标
由于研究2和研究1的目的不同,因此,本研究的评价指标主要是测验的使用情况,主要包括平均测验长度 Mean,测验长度的标准差 SD,最大测验长度Max和最小测验长度Min。
5.4 研究结果
表4和表5是6种选题策略的测验使用情况。由结果可知,与PWKL方法相比,其余5种方法的平均测验长度更少,其中表现最好的依然是 GIDPWKL方法。
从表4结果可以看出,除了按照最大测验长度终止以外,大部分的实验条件下,其余 5种方法的最大测验长度要低于 PWKL方法,最小测验长度和PWKL相差无几。该结果表明其余 5种方法较PWKL方法的优势所在:在具有相同测量精度时,可以有效降低被试作答的最大测验长度。
与 AIDPWKL、CIDPWKL、KLEDPWKL和MIM相比,GIDPWKL的平均测验长度与PWKL的平均测验长度之差是最大的(除表5中最后一行以外),节约的平均题目数量介于 0.47~0.87之间,如表5中粗体数值所示。该结果表明,4种新方法和MIM的选题效率更高,在相同的测验情景中,新方法能够用更少的题目达到与 PWKL方法相同的测量精度。
值得注意的是,不论采用何种方法,随着终止精度P
的增大,平均测验长度和最大测验长度均增大,该结果和Hsu等(2013)的研究结果一致。Q矩阵结构和题目质量均会影响这几种选题策略的测验使用情况。例如,当固定Q矩阵结构时,题目质量越高,平均测验长度和最大测验长度越小;当固定题目质量时,Q矩阵结构越简单,平均测验长度和最大测验长度越小。该结果表明,在实际编制Q矩阵和题目时,应注重提高题目的质量和适当减小Q矩阵的复杂性。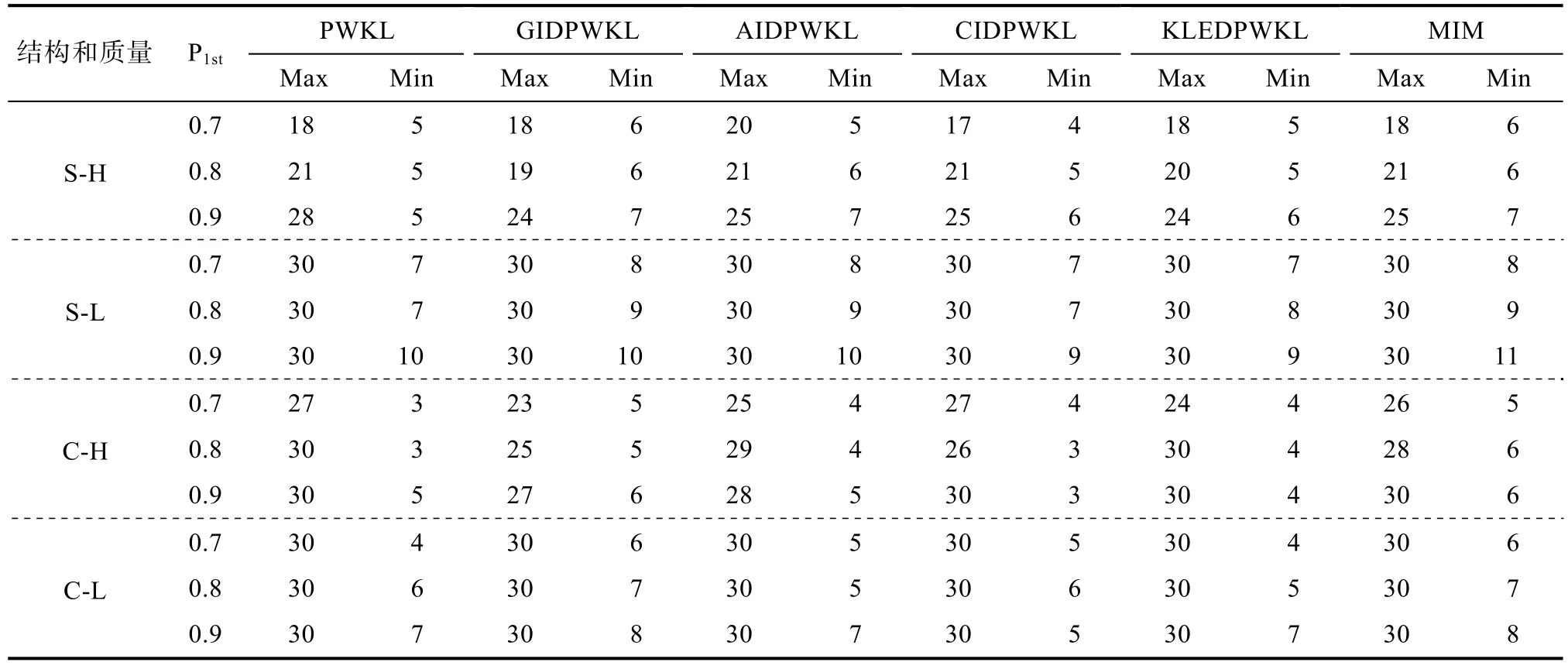
表4 变长终止规则下测验长度的最大值和最小值
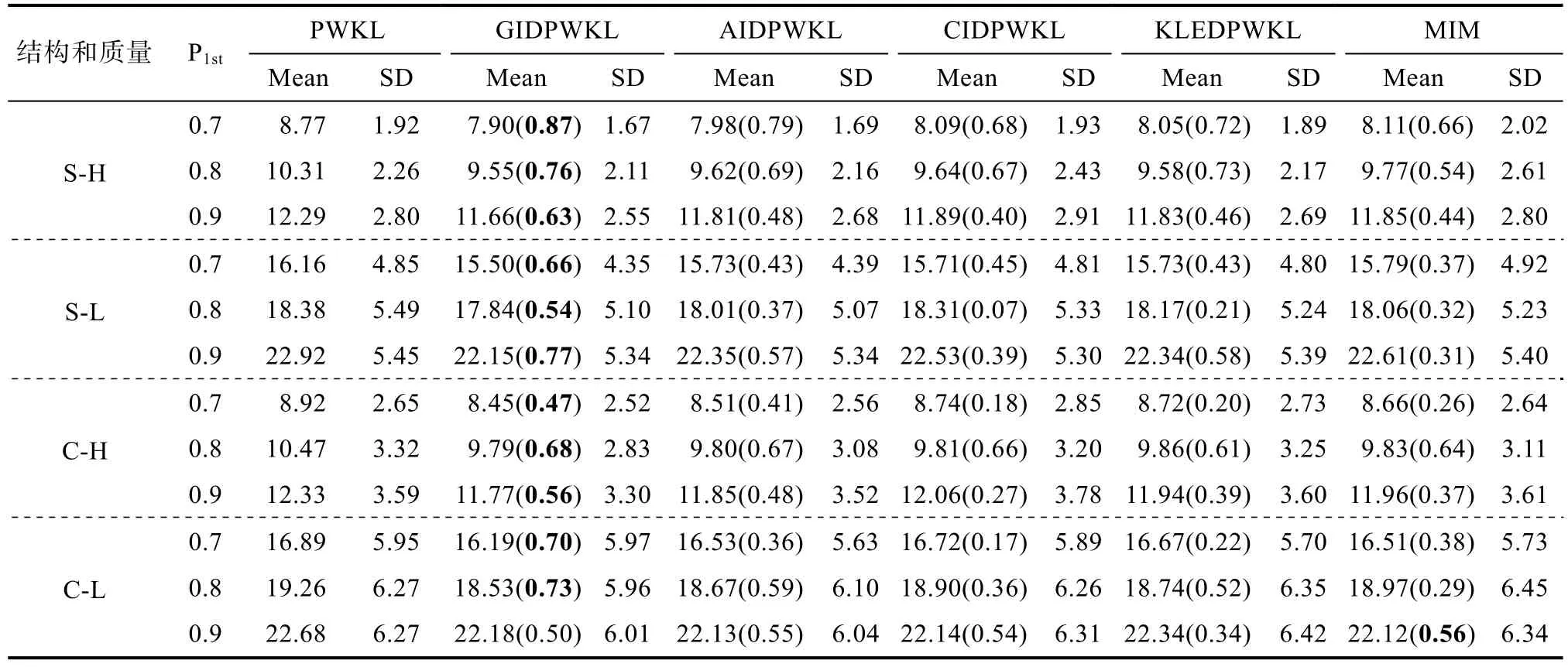
表5 变长终止规则下测验长度的平均值和标准差
6 研究结论
本文首先指出了传统的 PWKL指标仅考虑了被试 KS后验分布所提供的信息,并未关注在选题过程中题目能够提供的项目层面的信息,因此,PWKL属于单源指标。随后,本文将能够提供更加丰富信息的项目区分度融入到 PWKL指标中,对PWKL指标进行了修正,提出了4种新的多源选题指标:GIDPWKL、AIDPWKL、CIDPWKL和KLEDPWKL指标。另一方面,根据 Wang (2013)的研究结果表明:MIM 在大部分实验条件下的表现要优于 PWKL,特别是在测验长度较短时。但Wang本人并未考虑在曝光控制条件下MIM的表现,目前也没有新方法与MIM之间的比较研究。因此,本文通过两个模拟研究,在控制项目曝光基础上,系统比较了这 6种方法在不同实验条件下的表现,并得到以下结论:
(1)在定长测验情景下,不论实验条件如何改变,4种新方法以及MIM方法的平均属性/模式判准率均要高于原始的PWKL方法。4种新方法中表现最好的是GIDPWKL,PCCR最大增幅高达5.8个百分点(复杂结构×高质量题目×5题),这意味着在1000人参加的较短测验中,比 PWKL方法可以多判准58人;
(2)在定长测验情景下的绝大多数实验结果表明,测验长度越短,新方法的优势越明显。表现最好的是 GIDPWKL方法,之后是 AIDPWKL方法,而CIDPWKL、KLEDPWKL和MIM方法的优势随实验条件不同而不同。该结果表明,新的选题策略在测验初期就会收到较大成效,能够加快对被试KS判准的速度;
(3)在定长测验情景下的绝大多数实验结果表明,题目质量越高,新方法的优势越明显。表现最好的是 GIDPWKL方法,之后是 AIDPWKL方法,其余 3种方法(CIDPWKL、KLEDPWKL和MIM)之间并没有展现出一致的优势结果,但三者的表现相差无几。该结果表明,项目区分度信息的确可以,也应该作为另一方面的信息源加入到选题过程中,以此提高被试KS的判准率;
(4) Q矩阵结构的复杂性影响着不同选题策略的表现。从实验结果可以看出,与简单结构相比,复杂结构的Q矩阵更能体现出新方法的优势,表明新方法更能有效处理复杂的测验情景;
(5)在变长测验情景下,4种新方法及MIM的平均测验长度要低于 PWKL方法,表现最好的是GIDPWKL方法。该结果表明新方法能够用更少的题目达到与PWKL方法相同的测量精度,效率更高。
(6)整体来看,4种新方法以及MIM均比PWKL表现好。但相对而言,在4种新方法中,CIDPWKL和KLEDPWKL的表现不如 GIDPWKL和AIDPWKL。这是因为 CIDPWKL和KLEDPWKL指标的项目区分度比较简单,只考虑了项目参数的信息(即s和g参数),而其余二者是基于D
计算得到的项目区分度,能提供的区分信息更加丰富。本文提出的 4种新方法通过将项目区分度作为权重融入PWKL指标中,提高了选题效率。一个良好的选题方法的标准应该是在固定测验长度时,具有较高的判准率;或在固定测验精度时,具有较少的测验长度,而不是看该指标/方法应该有多复杂。根据实验结果表明,本文提出的4种新方法在较短测验长度时,比PWKL更加高效。根据上述结论,多源指标是更加有效的选题策略。在定长测验中,GIDPWKL方法的判准率是最高的;在变长测验中,GIDPWKL方法的平均测验长度是最少的,因此,在实际应用中应该首选测验效率最高的GIDPWKL方法。
7 讨论及展望
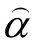
本文成功地将项目区分度信息融入到传统的PWKL指标中,取得了令人满意的结果,但仍有继续可以研究的地方:
(1)本研究仅选用了 DINA模型作为认知诊断模型进行研究,而融合模型(Fusion Model
,FM)被认为是目前最优的诊断模型,本文提出的4种新方法在FM中表现如何,特别是CIDPWKL表现如何值得进一步研究。在FM中,基于CTT思想的项目区分度指标不再是公式(4)所示,而是下式: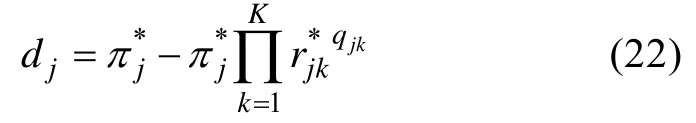
(2)本研究并未考虑一些非统计约束条件,例如内容平衡(Mao &Xin,2013),答案平衡和属性平衡(Cheng,2010)等因素对新方法的影响,未来可以进行这方面的研究。
(3)本研究是从项目区分度角度对 PWKL进行的改进,未来研究可以考虑其他加权方法。例如,可以根据Rupp等(2010;P242)提出的计算属性标准误的方法,将计算出来的属性标准误作为权重,考察利用属性标准误进行加权方法的效果。
Chang,H.H.,&Ying,Z.L.(1999).α-stratified multistage computerized adaptive testing.Applied Psychological Measurement,23
(3),211–222.Cheng,Y.(2009).When cognitive diagnosis meets computerized adaptive testing:CD-CAT.Psychometrika,74
(4),619–632.Cheng,Y.(2010).Improving cognitive diagnostic computerized adaptive testing by balancing attribute coverage:The modified maximum global discrimination index method.Educational and Psychological Measurement,70
(6),902–913.Guo,L.(2014).Variable-length cognitive diagnostic computerized adaptive testing:Termination rules,exposure control and quality monitoring technique
(Unpublished doctorial dissertation).Beijing Normal University.[郭磊.(2014).变长认知诊断计算机化自适应测验:终止规则、曝光控制及题库质量监控技术
(博士学位论文).北京师范大学.]Guo,L.,Zheng,C.J.,&Bian,Y.F.(2015).Exposure control methods and termination rules in variable-length cognitive diagnostic computerized adaptive testing.Acta Psychologica Sinica,47
(1),129–140.[郭磊,郑蝉金,边玉芳.(2015).变长 CD-CAT中的曝光控制与终止规则.心理学报,47
(1),129–140.]Haertel,E.H.(1989).Using restricted latent class models to map the skill structure of achievement items.Journal of Educational Measurement,26
(4),301–321.Henson,R.,&Douglas,J.(2005).Test construction for cognitive diagnosis.Applied Psychological Measurement,29
(4),262–277.Henson,R.,Roussos,L.,Douglas,J.,&He,X.M.(2008).Cognitive diagnostic attribute-level discrimination indices.Applied Psychological Measurement,32
(4),275–288.Hsu,C.L.,Wang,W.C.,&Chen,S.Y.(2013).Variable- length computerized adaptive testing based on cognitive diagnosis models.Applied Psychological Measurement,37
(7),563–582.Junker,B.W.,&Sijtsma,K.(2001).Cognitive assessment models with few assumptions,and connections with nonparametric item response theory.Applied Psychological Measurement,25
(3),258–272.Mao,X.Z.,&Xin,T.(2011).Improvement of item selection method in cognitive diagnostic computerized adaptive testing.Journal of Beijing Normal University (Natural Science),47
(3),326–330.[毛秀珍,辛涛.(2011).认知诊断 CAT中选题策略的改进.北京师范大学学报 (自然科学版),47
(3),326–330.]Mao,X.Z.,&Xin,T.(2013).The application of the monte carlo approach to cognitive diagnostic computerized adaptive testing with content constraints.Applied Psychological Measurement,37
(6),482–496.Rupp,A.A.,Templin,J.,&Henson,R.A.(2010).Diagnostic measurement:Theory,methods,and applications
.New York:Guilford Press.Shang,Z.Y.,&Ding,S.L.(2011).The exploration of item selection strategy of computerized adaptive testing for cognitive diagnosis.Journal of Jiangxi Normal University(Natural Science),35
(4),418–421.[尚志勇,丁树良.(2011).认知诊断自适应测验选题策略探新.江西师范大学学报 (自然科学版),35
(4),418–421.]Tatsuoka,C.(2002).Data analytic methods for latent partially ordered classification models.Journal of the Royal Statistical Society:Series C (Applied Statistics),51
(3),337–350.Templin,J.L.,&Henson,R.A.(2006).Measurement of psychological disorders using cognitive diagnosis models.Psychological Methods,11
(3),287–305.Wang,C.(2013).Mutual information item selection method in cognitive diagnostic computerized adaptive testing with short test length.Educational and Psychological Measurement,73
(6),1017–1035.Wang,C.,Chang,H.H.,&Douglas,J.(2012).Combining CAT with cognitive diagnosis:A weighted item selection approach.Behavior Research Methods,44
(1),95–109.Wang,C.,Chang,H.H.,&Huebner,A.(2011).Restrictive stochastic item selection methods in cognitive diagnostic computerized adaptive testing.Journal of Educational Measurement,48
(3),255–273.Wang,W.Y.,Ding,S.L.,&Song,L.H.(2014).Item selection methods for balancing test efficiency with item bank usage efficiency in CD-CAT.Journal of Psychological Science,37
(1),212–216.[汪文义,丁树良,宋丽红.(2014).兼顾测验效率和题库使用率的CD-CAT选题策略.心理科学,37
(1),212–216.]Xu,X.L.,Chang,H.H.,&Douglas,J.(2003).A simulation study to compare CAT strategies for cognitive diagnosis
.Paper presented at the Paper presented at the annual meeting of National Council on Measurement in Education,Montreal,Canada.猜你喜欢
中学生数理化·八年级数学人教版(2019年11期)2019-09-10
小天使·一年级语数英综合(2018年10期)2018-10-16
教育教学论坛(2017年1期)2017-02-08
福建中学数学(2016年5期)2016-11-29
考试周刊(2016年88期)2016-11-24
小雪花·成长指南(2016年8期)2016-09-21
新高考·高三数学(2016年2期)2016-05-27
新财富(2016年4期)2016-04-21
计算机应用文摘·触控(2015年6期)2015-06-26
少年科学(2014年10期)2014-11-14
