
基于人工混响的声源空间距离恢复模型
2015-12-20 06:58:58张茂胜
计算机工程与设计 2015年9期
王 樱,张茂胜,姜 林
(武汉大学 计算机学院 国家多媒体软件工程技术研究中心,湖北 武汉430070)
0 引 言
现有的3D (three diminutions)视频技术虽然已经能为观众提供较好的视觉体验,但3D 音频技术相对滞后,目前市面销售的产品主要是沿用原有的立体声或环绕声技术。用户若想达到身临其境的视听感受,必须要有与3D 视频内容同步的3D 声场听觉效果,这使得3D 音频技术迎来了前所未有的发展机遇。法国电信在动态图像专家 (moving pictures experts group,MPEG)会 议 上 对3D 音 频 给 出 了明确的定义[1],根据法国电信对3D 音频的定义,与传统立体声或环绕声相比,3D 音频技术更注重为听音者提供更好的声源方向感和距离感。目前基于耳机回放的3D 音频实现技术主要有德国波鸿大学Jens Blauert提出的头相关传输函数(head related transfer function,HRTF),该函数真实地模拟出声波从声源传输到双耳的整个过程,是一个与个体体征相关的物理量。HRTF 通常在消音室中通过测量人工头或者真人双耳内接收到的冲激信号获得[2]。国内外的相关机构纷纷对HRTF进行了实际测量:Algazi对45个真人进行测量,得到了CIPIC的HRTF库,该库包含了25个不同水平角和50个不同高度角的1250个位置的HRTF;谢菠荪等通过对52名受试者进行测量,建立了中国人样本的高空间分辨率的HRTF以及受试者生理尺寸的数据库,上述工作主要是针对远场 (声源距离大于1 m)固定距离条件下对HRTF进行测量;龚枚等采用人工头对多个距离的HRTF进行了测量,建立了高空间分辨率的近场头相关传输函数数据库。实验测量方法获得的HRTF 数据距离恢复的效果虽然精确,但是实验过程十分繁琐,人力和时间成本很高[3]。针对HRTF存在的不足,本文在HRTF恢复方向的前提下,提出了一种空间距离恢复模型,在该模型中,采用人工混响的方法模拟3D 视频中声源所在环境的混响,结合人耳距离感知机理控制音频信号对声源进行距离恢复,得到与3D 视频空间信息相匹配的3D 音频,然后通过耳机进行回放。实验结果表明,该方法可以实现声源距离的恢复,恢复效果与采用最新的多距离HRTF 库时相当,且存储需求更低,实现起来更简单,实用性更强。
1 基于人工混响的空间距离恢复模型
基于人工混响的空间距离恢复模型结构框架如图1所示。

图1 基于人工混响的空间距离恢复模型结构框架
该模型主要由距离感知模块,最佳混响时间模块,人工混响模块3个模块构成。首先,将3D 视频场景中已知声源所在空间体积V 和声源类型输入到最佳混响时间模块,通过体积V 和声源类型确定模拟房间的最佳混响时间T60,将得到的最佳混响时T60间分别输入到距离感知模块和人工混响模块中;然后,距离感知模块根据输入的声源距离信息和最佳混响时间T60,计算得到恢复距离时所需的直混能量比 (direct-to-reverberation ratio,DRR),将DRR 输入到人工混响模块中;最后,人工混响模块根据输入的DRR 和T60对输入的立体声信号SDirect分别对左右声道进行处理,最终将携带声源距离信息的3D 音频信号SOut输出,输出的信号通过耳机进行回放。每个模块具体介绍如下所示。
1.1 距离感知模块
杜伦大学的Jonathan S.Berry指出[4],影响距离感知的因素主要有声音的强度、DRR、频谱和双耳差异 (时间差和强度差)。从人耳感知角度来说,房间反射在人耳对距离的感知中起着至关重要的作用。在现实真实房间中,当声源与听音者之间的距离增加时,声音的强度和DRR 会随之减小,当声源距离增加一倍时,人耳接收到的强度会减少6dB,但声音的强度线索主要应用于无混响无反射的理想环境中,此外,频谱和双耳线索容易受到墙面、空气等的影响。因此,包含强度信息的DRR 相较于其它距离感知线索,能为听音者提供更准确的声源距离信息。
赫尔辛基理工大学的Sampo于2009年提出了DRR 与声源距离关系模型[5]

令

则式 (1)简化为

其中,r为人耳感知声源的距离,rc为临界距离 (或称为混响半径,V 为房间体积,T60为混响时间,在rc处直达声与混响声的能量相等),临界距离是房间的属性,与声源无关。DRR 表示听音点处直达声与混响声的能量比,EDirect表示直达声的能量,EReverb表示混响声的能量,对于固定的声源,混响声的能量基本保持不变,当距离增加一倍时,DRR 减少6db,减少的能量主要来自直达声能量的减少[6]。由式 (1)、式 (2)、式 (3)、式 (4)可 以 看 出,DRR 决定了听音者所感知到的声源距离。因此,在对模拟的环境和信号类型有一定的先验知识的情况下,通过控制DRR 可以恢复声源的距离。
1.2 最佳混响时间模块
混响时间是声学设计中声能定量估算的重要评价指标[7]。通常用 “T60”来表示,单位是秒 (s),菲茨罗伊公式是专门为家庭环境而设定的混响时间计算公式
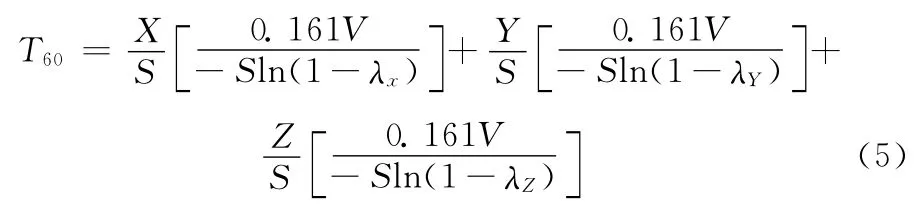
式中:V——房间容积,S——房间表面积的总和,X、Y、Z——三对墙面 (6 个墙面)各自的面积,λx、λy、λz——每面墙对应的吸声系数,该公式考虑了矩形房间内三对墙面吸声能力不同时的情况。当三面墙的吸声能量相同时,式 (5)可简化为赛宾公式

式中:λ——房间六面墙的平均吸声系数。
混响时间的长短直接影响着听音者感知声音的效果,混响时间太短,声音发干,声音听起来不自然;混响时间太长,声音听起来混浊不清。不同类型的音频信号对混响时间的要求各不相同。一般来说,为了保证有足够的清晰度,语音信号相对于音乐信号要求混响时间要短一些。然而,要对混响时间进行有效的控制,就需要了解不同环境下的最佳混响时间范围。最佳混响时间范围是反映房间声学特性的基本参数,经过长时间对各种不同环境的混响进行大量的调查与分析,众多声学专家总结了它们的最佳范围,可在房间体积对应的混响时间正负10%的浮动区间选择最佳混响时间[8],如图2所示。因此,在已知模拟环境的体积V 和音频信号类型的情况下,可以得到模拟房间的最佳混响时间T60。
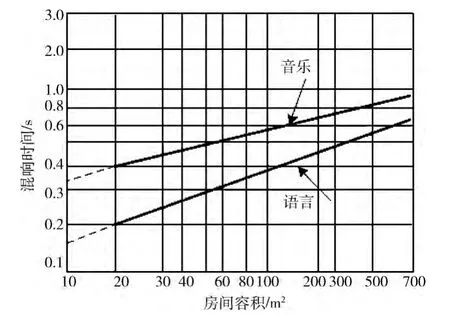
图2 不同房间体积下的最佳混响时间
1.3 人工混响模块
在室内声场中,人们听到的声音主要由直达声、近次反射声和混响声3部分组成,如图3所示。

图3 室内声场的组成
其中,直达声SDirect,是指由声源发出后未经过反射而直接到达听音者的声音。近次反射声SE-Reverb,是声源发出的声音经周围界面单次或少数次反射后,比直达声到达听者晚50ms以内的全部反射声。由于人耳听觉的延迟效应,人耳不能将直达声和近次反射声区分开来。比直达声晚到50ms以上的多次反射声都称为后期混响声SL-Reverb,其脉冲序列幅度随时间成指数衰减,回声密度与时间的平方成正比[9]。
目前人工混响主要有两种实现方法,一种是用房间脉冲响应法 (room impulse response,RIR),一种是延时反馈网络法 (delay feedback network,DFN)。采用RIR 需要提前获取模拟房间的脉冲响应,并且在模拟混响时不能调整混响参数,只能模拟某一房间固定位置的听音效果;相反,采用DFN 模拟混响时可以通过对滤波器的某些系数进行设置而方便地调整混响参数,具有更强的灵活性和实用性[10]。其中,Moorer混响模型是目前应用最广泛的一种延时反馈网络混响模型,其原理如图4所示。
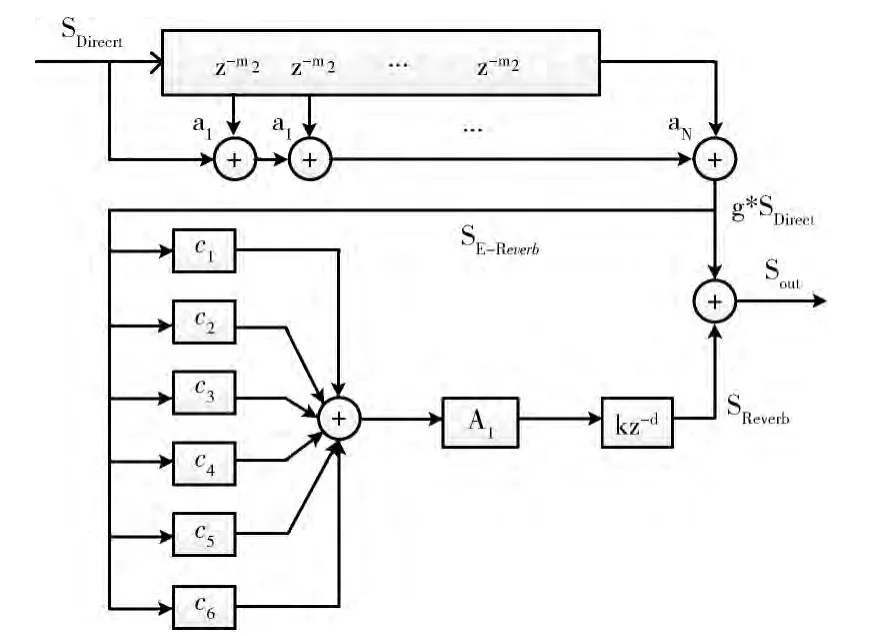
图4 Moorer混响模型
由图4可知,在Moorer混响模型中主要由两部分构成,一部分由19 阶FIR 滤波器构成,它主要模拟40—50 ms内声音的衰减,包含直达声和早期反射声。第二部分由6个并联的梳妆滤波器c1—c6和一个串联的全通滤波器A1以及一个延时模kz-d。6个并联的梳状滤波器为混响效果提供了延迟较长的回声,在每个梳状滤波器的反馈支路上加入一个单极点的低通滤波器,该滤波器可以降低高频成分的混响时间;全通滤波器用来增加反射声波密度.通过调整各个滤波器中的延时可以增大回声密度。梳妆滤波器和全通滤波器的延时选择参照文献 [11]中标准,梳状滤波器的反馈增益系数a可由式计算得到

式中:t——延迟时间,T60——混响时间,由我们自己设定。在Moorer模型中,通过调整直达声SDirect增益因子g即可实现对DRR 的控制。
2 仿真及主观测试结果
为了验证本文所提方法的有效性,分别对待测信号2个方位角对应的6个固定距离进行恢复,测试序列的方位角 (水平角,高度角)分别为 (0°,0°)和 (90°,0°),恢复的距离为0.3 m,0.5 m,0.75 m,1.0 m,1.3 m,1.6 m,测试所用的序列均选自国际标准组织MPEG 的标准测试序列,包括语音和音乐序列。实验中模拟的环境体积为50m2,由图2可知,对于语音信号,模拟的最佳混响时间为0.3s;对于音乐信号,模拟的最佳混响时间为0.5s。
在仿真实验中,用matlab软件对语音信号进行了模拟仿真,给出了原始语音与加了混响后的语音的时域对比波形图,如图5所示;通过模拟距离感知模块,绘出了语音信号和音乐信号恢复各距离时对应的DRR,如图6所示。
图5为人工混响仿真,通过将原始语音和加混响后的语音图进行对比,由于模拟了声源所在环境的反射声,加了混响后的语音声音强度大于原始语音的强度;图6为语音信号和音乐信号DRR 与恢复距离间关系,从图中可以看出随着声源距离的增加,DRR 减小,由于对于固定的声源混响声的能量不变,DRR 的减小主要是由直达声的能量减小造成。
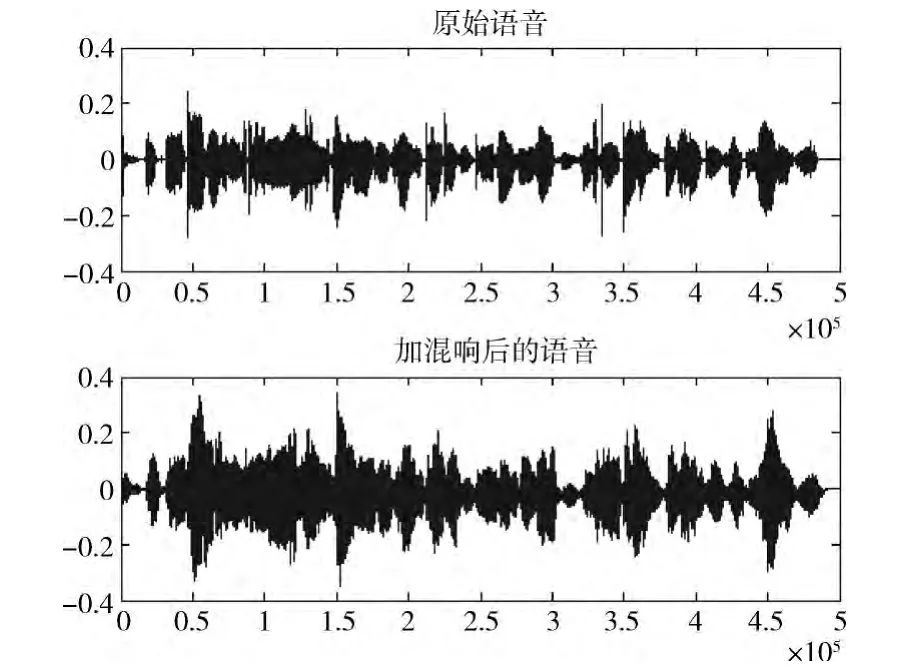
图5 人工混响仿真 (语音信号)
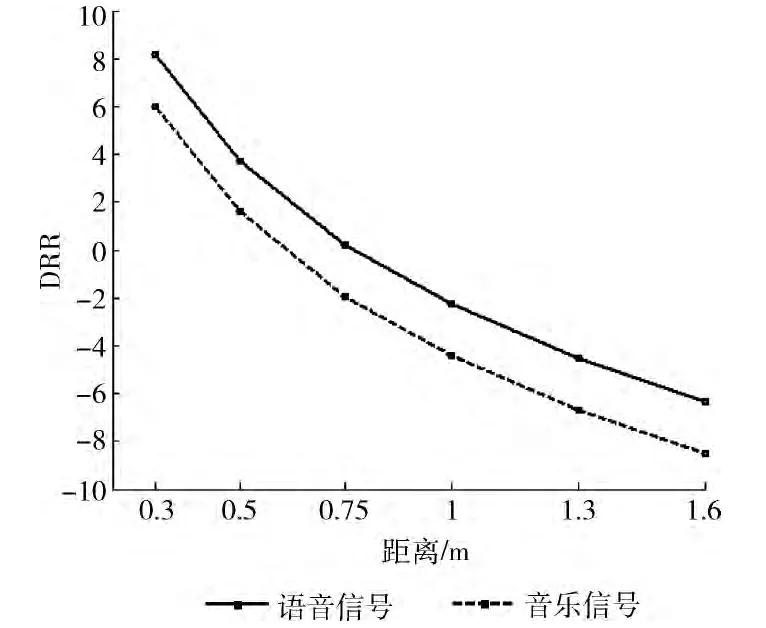
图6 距离感知关系仿真 (语音信号和音乐信号)
在主观测试实验中,参与主观测试的听音者由具有听音测试经验的8名人员构成,每名测试人员进行四组听音测试,每组12 个样本 (对)。模拟的结果通过与采用HRTF恢复的距离进行对比,其中,采用HRTF方法模拟的距离对应的HRTF均来自于北京大学的HRTF库,打分标准如表1所示,其中,A 代表采用本文方法恢复的距离,B代表HRTF方法恢复的距离。为防止听音者听觉疲劳,在所有实验中,每播放完12个样本 (对)休息5 min。每听完一条样本 (对),听音者有5s的时间根据表1的打分标准进行打分。主观测试结果如图7所示。

表1 距离感知差异
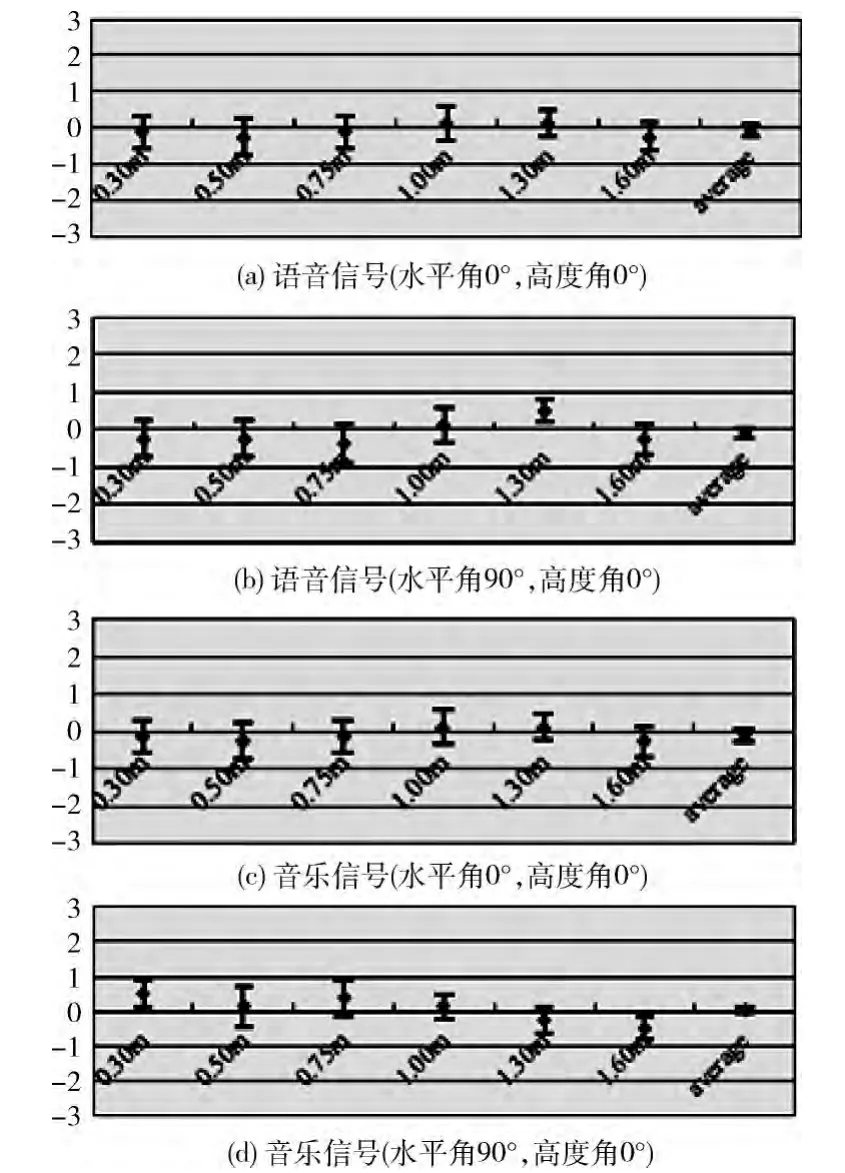
图7 主观测试实验结果
图7为主观测试实验结果,其中图7 (a)、(b)为语音信号测试结果,图7 (c)、(d)为音乐信号测试结果。从测试结果可以看出,整体上通过人工混响方法控制DRR 恢复的距离效果和HRTF恢复控制的效果相当,测试人员总体打分分值处于-1到1之间,平均值接近0;其次,对于体积大小相同的房间,由于语音信号要求的清晰度高于音乐信号,使得语音信号所在房间的混响时间小于音乐信号所在房间的混响时间,在该种条件下,人耳对于语音信号的整体距离感知效果稍好于音乐信号。
3 结束语
针对采用HRTF方法恢复距离时需要大量的测试样本且恢复效果与个体特征相关,本文在采用HRTF 恢复方向的前提下提出了一种基于人工混响的声源空间距离恢复模型,通过已知3D 视频场景中的声源空间距离信息,采用人工混响方法模拟声源所在环境的混响,结合人耳距离感知的机理控制音频信号的直达声和混响声的能量比,对声源距离进行恢复。通过仿真结果及主观测试实验可以看到,本文提出的方法在不需要大量数据采集处理获取多距离HRTF的情况下,距离恢复效果和采用最新的多距离HRTF时相当,存储需求更低,且提出的模型更简单,实现起来更容易,实用性更强,能够给听音者提供更加逼真的空间感距离感,实现从传统音频到3D 音频的转换。下一步工作将着重于通过与3D 视频结合,通过实时地提取声源在3D 视频中的空间位置信息实现对整个三维空间的距离进行恢复,使观众能够同时享受视觉和听觉上的盛宴。
[1]San-Jose,ISO/IECJTCI/SC29/WG11 (MPEG),DocumentM23748,Use cases and possible material for 3D Audio [C]//99th MPEG Meeting,2012.
[2]YIN Fuliang,WANG Lin,CHEN Zhe.Review on 3Daudio technology [J].Journal on Conmunications,2011,32 (2):130-138 (in Chinese).[殷福亮,汪林,陈喆.三维音频技术综述 [J].通信学报,2011,32 (2):130-138].
[3]YU Guangzheng,XIE Bosun,RAO Dan.Near-field headralated transfer functions of a artificial head and its characteristics[J].Acta Acustica,2012,37 (4):378-385 (in Chinese).[余光正,谢菠荪,饶丹.人工头近场头相关传输函数及其特性 [J].声学学报,2012,37 (4):378-385].
[4]Jonathan S.Berry,David AT Roberts,Nicolas S Holliman.3Dsound and 3Dimage interactions:A review of audio-visual depth perception [J].Proc.SPIE 9014,Human Vision and Electronic Imaging XIX,2014,3 (1):1-16.
[5]Sampo Vesa.Binaural sound source distance learning in rooms[J].IEEE Transactions on Audio,Speech & Language Processing,2009,17 (8):1498-1507.
[6]Yan-Chen Lu,Martin Cooke.Binaural estimation of sound source distance via the direct-to-reverberant energy ratio for static and moving sources [J].IEEE Transactions on Audio,Speech &Language Processing,2010,18 (7):1793-1805.
[7]Sklevik,Magne.Reverberation time-the mother of all room acoustic parameters [J].20th International Congress on Acoustics,2010,3 (2):2508-2512.
[8]MENG Zihou.Research on the acoustical psychology of reverberation perception [J].Applied Acoustics,2013,32 (2):81-90 (in Chinese).[孟子厚.混响感知的听觉心理 [J].应用声学,2013,32 (2):81-90.]
[9]Vesa Vlimki,Julian D Parker,Lauri Savioja.Fifty years of artificial reverberation [J].IEEE Transactions on Audio,Speech&LanguageProcessing,2012,20 (5):1421-1448.
[10]ZHANG Lei.The research and implementation of digital reverberator [D].Dalian:Dalian University of Technology,2010:28-32 (in Chinese).[张磊.数字效果器的研究与实现[D].大连:大连理工大学,2010:28-32.]
[11]Udo Zolzer,Xavier,DAFX-Digital Audio Effects[M].England:Wiley,2011:170-180.
猜你喜欢
新作文·小学低年级版(2022年6期)2022-08-30 03:01:54
声学技术(2021年3期)2021-07-14 01:22:24
汉字汉语研究(2019年2期)2019-08-27 00:48:06
舰船电子工程(2018年11期)2018-11-26 07:55:08
剧作家(2018年2期)2018-09-10 01:47:18
演艺科技(2016年10期)2016-11-26 22:03:20
演艺科技(2016年7期)2016-11-16 08:49:40
演艺科技(2016年4期)2016-11-16 07:41:44
小学教学设计(英语)(2016年4期)2016-04-16 06:34:50
西北工业大学学报(2015年3期)2015-12-14 13:08:44
