
改进模糊聚类的云任务调度算法
2015-12-20 06:58:58苑迎春王雪阳
计算机工程与设计 2015年9期
胡 蒙,苑迎春,王雪阳
(河北农业大学 信息科学与技术学院,河北 保定071001)
0 引 言
目前,已有的云任务调度研究[1-8]主要针对云平台中全体资源,当任务量大、资源数多时任务选择资源的时间开销很大,致使云平台调度效率较低,因此找到恰当的方法对资源进行合理划分从而缩小资源选择的范围十分必要。聚类是一种有效的对目标进行分类的手段。关于资源聚类的研究集中于最近几年,多是基于集群、网格环境下的[9-11],研究云计算平台下的还较少。郭等[12]提出了一种云计算环境下针对工作流任务的聚类调度算法,提高了工作流任务的调度性能,该算法将资源划分到可选和备用两个聚类中,在对任务队列进行调度时,只是根据任务的最好最坏完成时间差,并没有考虑任务本身的资源偏好;李等[13]基于资源公平分配原则提出了一种两级调度算法,该算法在资源聚类基础上引入任务资源偏好,将任务依次进行调度,保证了较高的用户满意度,但是由于两个聚类之间资源差异较大,容易造成性能最好和最差的聚类间完成时间差较大,致使总的完成时间较长、资源利用率较低。
本文针对现有算法的不足之处,提出一种改进模糊聚类的云任务调度算法。该算法是在传统的模糊聚类基础上进行改进的任务调度算法,依据设定的阈值对任务分配实施调整,最大限度体现任务调度的公平性,有助于提高系统的资源利用率。
1 问题描述
云计算环境中有大量的计算型资源、带宽型资源、存储型资源等各类资源。不同任务对这些资源的偏好不同,有些计算型的任务希望获得处理器性能较好的计算型资源,有些网络交互型的任务对处理器性能要求不高,却需要保证足够的带宽型资源。因此,本文要解决的问题就是针对云计算环境下的任务模型和资源模型,研究如何将一批任务合理地分配到一组资源上,既能使算法的执行时间较短,又能保证这批任务总体完成时间最短且负载均衡。
1.1 任务模型
云计算环境下的任务 (本文中简称为云任务)可以分为相互间独立的元任务和相互间存在约束关系的依赖任务两类。本文的研究对象只考虑元任务,为以后继续研究依赖任务打下基础。
假设用户提交的任务集合中包含m 个云任务,这m 个任务相互独立且大小不一。以Cloudlet表示第i个任务,它的特性可以用一维向量来描述Cloudlet= {cloudletid,cloudletuserid,cloudletlength,cloudletPEs,cloudletbw,cloudletstor,cloudletifile,cloudletofile}。其中,参数cloudletid为任务编号,cloudletuserid为任务隶属的用户编号,cloudletlength为任务长度(单位:MI,百 万 条 指 令 数 目),cloudletPEs、cloudletbw、cloudletstor为用户所期望的PE数、带宽大小(单位:MB/s)、存储空间大小 (MB),cloudletifile、cloudletofile分别为输入输出文件大小。
云任务Cloudlet 的计算需求可由下式计算得到:cloudletcomp=cloudletlength/cloudletPEs。
1.2 资源模型
云计算环境中的资源多是指通过虚拟化技术呈现给用户的虚拟资源。假设一个资源集合中包含n 个虚拟机资源,这n个虚拟机资源性能不一。以Vm 表示第j 个资源,它的特 性 可 以 用 一 维 向 量 描 述Vm = {Vmid,VmuserId,VmCPU,VmMIPS,Vmbw,Vmstor}。其中,Vmid为资源编号,VmuserId为资源隶属的云服务商编号,VmCPU为资源的CPU数目,VmMIPS表示每秒执行的百万条指令数目,Vmbw、Vmstor分别为资源的通信能力、存储能力。
资源的计算能力表示为:Vmcomp=Vmcpu×VmMIPS,值越大该资源计算性能越好。
资源j的综合性能由式 (1)计算得出
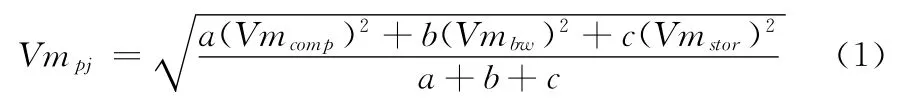
其中,a、b、c分别表示资源的3项性能参数的经验系数。
聚类资源综合性能crpj由某一类型聚类内所有资源的综合性能均值求得
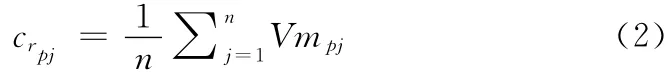
2 基于模糊聚类和Min-Min的调度算法
本文考虑到任务选择资源的盲目性对任务执行情况有一定程度的影响,提出了基于资源模糊聚类的任务调度算法,在聚类内使用Min-Min启发式算法进行调度,并在此基础之上进行了适当的改进,以提高系统资源利用率,保证系统负载均衡性。算法主要分为模糊聚类、任务分配和算法改进3个过程。
2.1 资源聚类划分过程
在云计算环境中,一方面,难以描述任务对资源的需求;另一方面,由于云计算环境的动态性,亦难以精确描述资源本身的属性。因此,要恰如其分地进行任务与资源的匹配调度自然也具有模糊性。本文使用模糊C 均值聚类方法 (FCM)[14],按照资源多维属性特征进行模糊划分,聚类的主要步骤如下:
步骤1 以n个资源的属性值Vmcomp,Vmbw和Vmstor建立初始化样本矩阵Rn×3,rij为矩阵中的一个元素,代表第i个资源的第j维性能。
步骤2 对步骤1中的矩阵Rn×3根据式 (3)进行标准化处理得到r′ij,再根据式 (4)将数据压缩到 [0,1]之间,得到r″ij

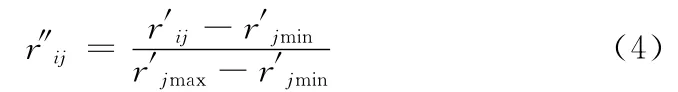
其中,r′jmin和r′jmax分别为r′1j,r′2j,...,r′nj中的最小值和最大值。
步骤3 将n个资源按照性能划分为3个类别,即设定聚类中心数目为3个,初始化隶属度矩阵U。
步骤4 根据式 (5)计算3个聚类中心

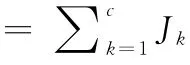
其中,uki表示数据i 对模糊组k 的隶属度,i∈[0,1];ck是模糊组k 的聚类中心;dki=ck-xi是第i 个数据与第k个聚类中心与之间的欧氏距离;m ∈[1,∞)是一个加权指数,最佳取值范围为 [1.5,2.5],一般取m=2。
若J<阈值ε,或达到迭代次数t,则聚类结束。否则,继续步骤6。
步骤6 按照式 (6)重新计算隶属度U,返回步骤4
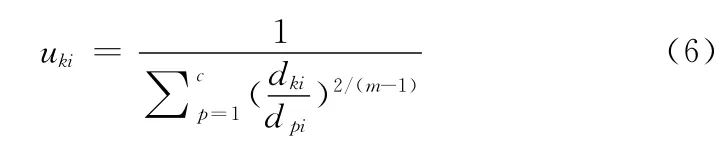
经过此模糊聚类算法运算,最终将云平台中n 个资源划分为3个聚类,分别为:计算型资源集 (CompCluster)、带宽型资源集 (BwCluster)、存储型资源集 (StorCluster)。
2.2 基于Min-Min的任务分配过程
根据任务偏好类型将任务分配到2.1节生成的3个聚类集资源上。具体算法步骤如下:
(1)若云任务列表CloudletList非空,根据式 (7)计算任务偏好类型,将任务添加到相应的计算型任务队列CompCloudletList、带宽型任务队列BwCloudletList、存储型任务队列StorCloudletList
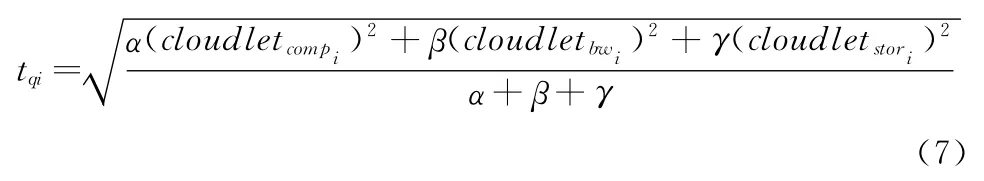
其中,α,β,γ∈ [0,1],分别是云任务对3 种资源需求的经验系数。
(2)根据Min-Min算法分别将CompCloudletList分配到CompCluster聚类中、将BwCloudletList分配到BwCluster、将StorCloudletList分配到StorCluster中,具体算法步骤如下:
步骤1 判断任务集合是否为空,不为空,则执行步骤2;否则跳到步骤8。
步骤2 对于所有任务,分别计算其映射到资源集合上的预计完成时间ETCij。
步骤3 对于所有任务,求出它们映射到所有可用资源上的最早完成时间ECTij=ETCij+rtj,rtj表示机器j 的就绪时间。
步骤4 根据步骤3的结果,找出最早完成时间最小的任务ti和所对应的资源rj。
步骤5 将任务ti映射到资源rj上;并将该任务从任务集合中删除。
步骤6 更新资源rj的期望就绪时间rtj。
步骤7 更新其它任务在资源rj上的最早完成时间;回到步骤1。
步骤8 结束。
2.3 算法性能的改进
运用Min-Min算法进行调度时,总是选择预计完成时间最小的任务执行,导致性能差的资源利用率较低,导致负载不均衡。为了克服这个缺点,提出一种改进策略。旨在使完成时间最小的聚类集的资源不再处在空闲状态,使完成时间最大的聚类集的资源从繁忙的调度中解放出来,从而提高资源利用率,保证负载均衡性。具体步骤如下:
步骤1 分别计算每个聚类的完成时间makespan,并两两计算聚类间的完成时间差D,分别记录最大值Dmax、最小值Dmin,以及其所对应的聚类集编号ii、jj。
步骤2 若Dmax<阈值θ,则步骤4,否则执行步骤3。
步骤3 如果newMakespan<makespan,则继续步骤3,否则转步骤4。
在聚类ii中找到完成时间最小的任务Cloudleti以及它对应的资源Vmj;在聚类jj中找到使Cloudleti完成时间最小的资源Vmk。将Cloudleti重新分配到Vmk上,并更新Vmj和Vmk的就绪时间。
步骤4 调度算法结束,退出程序。
3 仿真实验及结果分析
3.1 实验环境
本文算法在云计算仿真平台CloudSim[15]下进行实验验证。仿真实验是在模糊聚类基础之上分别实现了Round Robin、Min-Min和改进算法,并针对时间跨度、平均响应时间、平均资源利用率3个指标对算法进行了评价。
在仿真实验中,任务和虚拟机资源分别是由任务发生器CloudletGenerator和资源发生器VmGenerator随机生成的,每次实验时,可以指定任务个数和每个任务属性值的范围,以及资源个数和每个资源性能的取值范围。其具体实验环境设置如下:
(1)云平台参数设置:云平台设有10个数据中心,每个数据中心4 台主机,每台主机配置如下:PE 个数为1,2,4个随机生成、处理器速度为2000 MIPS、内存4GB、磁盘1 TB、带宽10 GB/s,数据中心特征:系统架构为x86,操作系统为Linux,虚拟机为Xen。
(2)任务参数设置:根据用户请求创建云任务,任务长度分布在区间 [500,4000],期望带宽大小范围为[1000,4000],期望存储空间大小范围为 [500,3000]。
(3)虚拟机资源参数设置:虚拟机CPU 个数取值为{1,2,4},处理器速度范围为 [500,1000],带宽大小范围为 [500,3000],存储空间大小范围为 [512,2048]。
3.2 性能评价指标
Makespan表示任务总体完成时间,是指从第一个任务进入云平台到最后一个任务完成的这段时间,即所有任务总体完成时间,如式 (8)所示
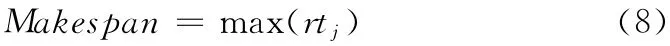
其中,rtj是资源j 的就绪时间。
任务响应时间 (response time,RT)是指一个任务从进入云平台开始到这个任务完成的这段时间,即任务的等待时间加上执行时间。m 个任务的平均任务响应时间(average response time,ART)计算公式如下

平均资源利用率 (average resource utilization ratio)通过以下公式计算得到
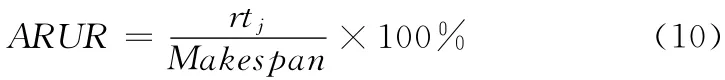
3.3 实验及结果分析
仿真实验的目的共有两个:①将无聚类Min-Min和聚类后Min-Min算法进行比较,验证聚类算法的优越性;②研究在聚类基础之上如何将任务进行调度使得算法性能更优。为此,设置了下面两组实验。
3.3.1 实验1:无聚类Min-Min和聚类后Min-Min算法执行时间比较
在本次实验中,设置云任务集中任务个数m= {100,200,300,400,500,600,800,1000},资源集中资源个数n= {10,20,30,40,50,60,80,100},由设计的随机任务发生器和随机资源发生器生成任务列表和资源列表,比较无聚类Min-Min和聚类后Min-Min的算法执行时间,比较结果如图1所示,其中横轴表示每次调度中云任务个数 (单位:个),纵轴表示算法的执行时间 (单位:ms)。
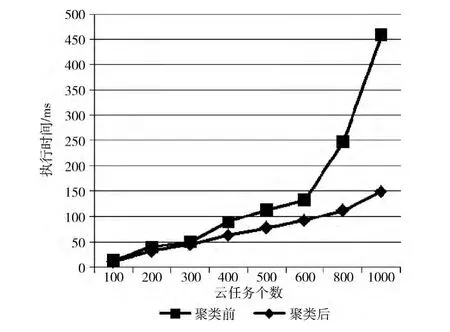
图1 算法执行时间对比
由图1可以看出,本次实验中,聚类后的Min-Min算法执行时间明显小于无聚类的Min-Min算法,而且随着任务数量的增加,聚类后算法效率提高的越多。当任务个数较多时,如m=1000时,聚类后比无聚类的Min-Min算法在执行时间上提高了207.38%。在任务个数较少时,如m=100时,由于图上纵轴间隔大,不能很明显的显示出两个算法的好坏,而从实验数据上来看,聚类后比无聚类的Min-Min算法在执行时间上提高了18.18%。
3.3.2 实验2:多次调度中,改进算法与传统聚类算法的性能比较
在本次实验中,设置云任务集合中任务个数m ={100,110,120,130,140,150},资源集合中资源个数n的取值范围为 [15,25],由设计的随机发生器Cloudlet-Generator和VmGenerator生成任务列表和资源列表,分别比较 聚 类 后 的Round Robin (FCMRR 算 法)、Min-Min(FCMMM 算法)和本文算法3种算法的Makespan、平均响应时间和平均资源利用率3项性能指标,比较结果如图2、图3、图4 所示,其中横轴均表示云任务个数 (单位:个),纵轴依次表示Makespan (单位:s)、平均响应时间(单位:s)、平均资源利用率。
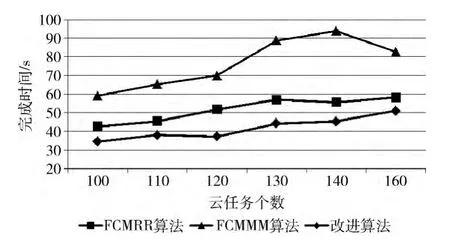
图2 Makespan对比
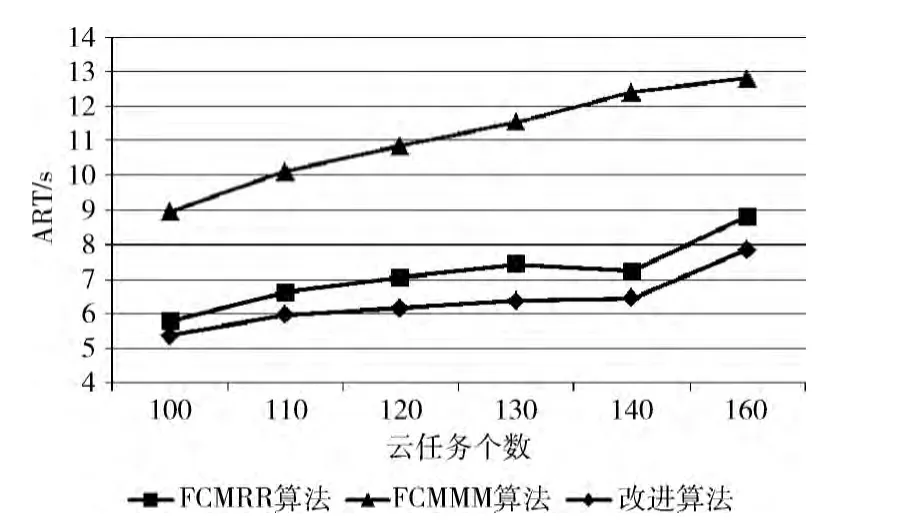
图3 平均响应时间对比
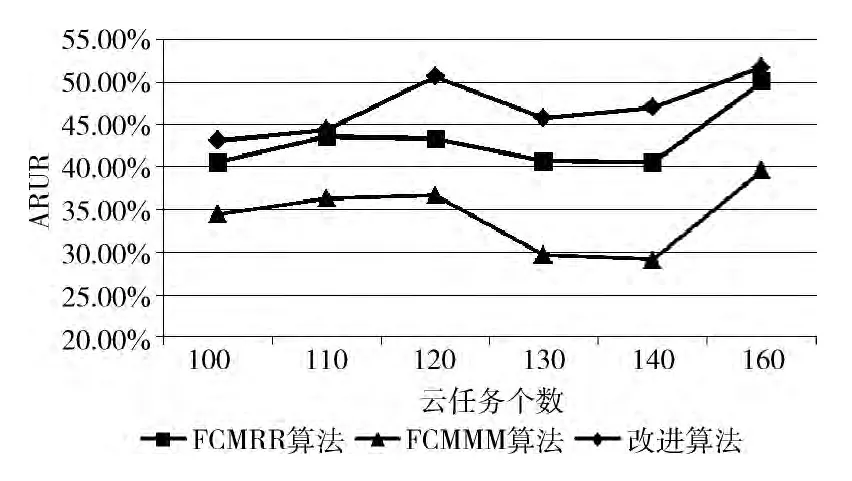
图4 系统资源利用率对比
由图2可见,改进算法在完成时间上,明显低于FCMRR 算法和FCMMM 算法,这是因为改进算法在任务调度时采用的Min-Min算法,而Min-Min的调度目标就是基于最早完成时间的任务优先调度,所以任务集合整体完成时间要比FCMRR 算法小,而改进算法又针对聚类间完成时间差异大于阈值θ 时进行了改进,使得完成时间比FCMMM 算法进一步缩短。从图3 可以看出,改进算法使得任务的平均响应时间显著缩短。如,当任务数m=由110变为120 时,改进算法的平均响应时间增加了3.17%,FCMRR、FCMMM 分别增加了6.48%、7.37%。由此可以看出,改进算法平均响应时间增幅不大,比较稳定。由图4可以看出,FCMMM 算法平均资源利用率均在40%以下,因为采用传统Min-Min算法,而Min-Min的缺点就是负载不均衡。改进算法针对聚类间完成时间差异大于阈值θ时进行了改进,系统资源利用率均在40%以上,略高于FCMRR 算法,明显高于FCMMM 算法。
综合以上分析可知,在云计算环境中,改进算法不仅执行效率显著提高,而且又能在一定程度上缩短任务集合的Makespan和任务的平均响应时间,且能提高系统的资源利用率保持系统负载均衡性。
4 结束语
本文针对云计算环境下的独立任务调度问题进行研究,总结了传统调度算法的特点。通过深入分析云平台中资源的特性,提出了一种改进模糊聚类云任务算法。该算法首先将资源特征矢量化,并基于这些特征进行模糊聚类,明显缩小了任务选择资源的范围,从而有效降低了算法的执行时间。最后,通过实验分析可知,与传统聚类算法相比,该算法一方面有效的缩短了云任务集合的完成时间和平均响应时间,另一方面,从系统角度来看,显著提高了系统的资源利用率,并保持了负载均衡性。
在下一步研究中,将会考虑资源和任务的动态性等因素,对调度算法作进一步研究,以适应动态的云计算环境。
[1]Wang LZ,Ranjan R,Chen JJ,et al.Cloud computing:Methodology,systems and applications [M].Boca Raton:CRC Press,2012:20-25.
[2]Daniel Nurmi,Rich Wolski,Chris Grzegorczyk.The eucalyptus open source cloud computing system [C]//Proceeding of the Cluster Computing and the Grid.California:University of California,2009.
[3]CHEN Kang,ZHENG Weimin.Cloud computing:System instances and current research [J].Journal of Software,2009,20 (5):1339-1347 (in Chinese). [陈康,郑纬民.云计算:系统 实 例 与 研 究 现 状 [J].软 件 学 报,2009,20 (5):1339-1347.]
[4]CHEN Quan,DENG Qianni.Cloud computing and its key techniques[J].Journal of Computer Applications,2009,29(9):2562-2567 (in Chinese).[陈全,邓倩妮.云计算及其关键技术 [J].计算机应用,2009,29 (9):2562-2567.]
[5]ZHOU Fachao,WANG Zhijian,YE Feng.Research of a novel cloud task scheduling algorithm [J].Journal of University of Science and Technology of China,2014,44 (7):590-591(in Chinese).[周发超,王志坚,叶枫.一种新型的云任务调度算法研究 [J].中国科学技术大学学报,2014,44 (7):590-591.]
[6]HUANG Jun,WANG Qingfeng,LIU Zhiqin,et al.Cloud task scheduling based on resource state colony optimization [J].Computer Engineering and Design,2014,35 (9):3305-3307(in Chinese).[黄俊,王庆凤,刘志勤,等.基于资源状态蚁群算法的云计算任务分配 [J].计算机工程与设计,2014,35(9):3305-3307.]
[7]YING Changtian,YU Jiong,YANG Xingyao.Energy-aware task scheduling algorithms in cloud computing [J].Microelectronics & Computer,2012,29 (5):189-191 (in Chinese).[英昌甜,于炯,杨兴耀.云计算环境下能量感知的任务调度算法 [J].微电子学与计算机,2012,29 (5):189-191.]
[8]SHI Jinfa,JIAO Hejun.Optimization of cloud resource online scheduling on multidimensional QoS [J].Computer Engineering and Design,2013,34 (12):4300-4302 (in Chinese).[施进发,焦合军.面向多维度QoS的云资源在线调度优化研究 [J].计算机工程与设计,2013,34 (12):4300-4302.]
[9]GUO Dong.Grid resources’selection based on applicationpreference based fuzzy clustering [D].Changchun:Jilin University,2009:15-20 (in Chinese). [郭东.基于应用偏好模糊聚类的网格资源选择 [D].长春:吉林大学,2009:15-20.]
[10]CHEN Zhigang,YANG Bo.Task scheduling based on multidimensional performance clustering of grid service resources[J].Journal of Software,2009,20 (10):2766-2774 (in Chinese).[陈志刚,杨博.网格服务资源多维性能聚类任务调度 [J].软件学报,2009,20 (10):2766-2774.]
[11]NIE Jing.Research on grid resource based on fuzzy clustering[D].Nanjing:Nanjing University of Information Science &Technology,2011:19-21 (in Chinese). [聂靖.网格资源模糊聚类研究 [D].南京:南京信息工程大学,2011:19-21.]
[12]GUO Fengyu,YU Long,TIAN Shengwei,et al.Workflow task scheduling algorithm based on resource clustering in cloud computing environment [J].Journal of Computer Applications,2013,33 (8):2154-2157 (in Chinese).[郭凤羽,禹龙,田生伟,等,云计算环境下对资源聚类的工作流任务调度算法 [J].计算机应用,2013,33 (8):2154-2157.]
[13]LI Wenjuan,ZHANG Qifei,PING Lingdi,et al.Cloud scheduling algorithm based on fuzzy clustering [J].Journal on Communications,2012,33 (3):146-154 (in Chinese).[李文娟,张启飞,平姈娣,等,基于模糊聚类的云任务调度算法 [J].通信学报,2012,33 (3):146-154.]
[14]QU Fuheng,CUI Guangcai,LI Yanfang,et al.Fuzzy clustering algorithm and its application [M].Beijing:Defense Industry Press,2011:50-58 (in Chinese).[曲福恒,崔广才,李岩芳,等.模糊聚类算法及应用 [M].北京:国防工业出版社,2011:50-58.]
[15]Buyya R,Ranjan R,Calheiros RN.Modeling and simulation of scalable cloud computing environments and the CloudSim toolkit:challenges and opportunities [C]//Proceedings of the 7th High Performance Computing and Simulation Conference.New York,USA:IEEE Press,2009:21-24.
猜你喜欢
消费电子(2022年7期)2022-10-31 06:17:34
制造技术与机床(2019年4期)2019-04-04 12:22:06
中国化肥信息(2019年6期)2019-01-19 13:10:42
经济技术协作信息(2018年5期)2019-01-19 08:39:16
测控技术(2018年7期)2018-12-09 08:58:00
消费导刊(2017年24期)2018-01-31 01:29:29
电子制作(2017年20期)2017-04-26 06:57:48
印制电路信息(2015年6期)2015-12-30 12:57:48
信息通信技术(2015年6期)2015-12-26 01:16:54
华东理工大学学报(自然科学版)(2015年4期)2015-12-01 04:00:45
