
基于DE-ELM 的林业信息文本分类算法
2015-12-20 06:58王明月许莉薇
计算机工程与设计 2015年9期
陈 宇,王明月,许莉薇
(东北林业大学 信息与计算机工程学院,黑龙江 哈尔滨150040)
0 引 言
国外对文本分类技术[1]的研究起步较早,并且现阶段发展也比较完善。常用的文本分类算法包括K 邻近算法、贝叶斯算法、决策树、BP神经网络算法等。我国对文本分类算法的研究起步较晚,初期我国主要对国外技术总结,随后是对传统算法的优化改进,扩大了文本特征的选择的范围,随着文本分类技术的进步,现阶段我国文本分类技术发展的也较好,研究出许多适合文本分类的算法,但是仍存在一些缺陷,在实际应用时因为训练样本存在差异,所以使得分类算法对分类结果差异较大,因此本文研究的重点就是如何提高对不同类文本分类的准确率和效率。
现阶段对于林业信息文本分类的研究甚少,因此如何提高林业信息文本分类的正确率,是一个重要的研究内容。
将差分演化算法与极端学习机算法结合,两种算法取长补短,提出了一种基于差分演化优化极端学习机的林业信息文本分类算法。首先,利用中科院分词系统对不均衡林业信息文本进行预处理;其次,使使用经典的TF-IDF公式计算文本分词的特征值,构成特征矩阵[2];然后,对特征矩阵降维;最后,利用差分演化优化极端学习机算法构造分类器,以达到分类的目的。通过大量实验验证该算法已达到预期目的,有较高的分类正确率,并且准确率明显高于BP神经网络、极端学习机分类方法,为林业信息文本分类提供了参考。
1 关键技术
1.1 林业信息文本表示
假设所有林业信息文本有n 个特征,形成n 维的向量空间,每个林业信息文本d 被表示成n 维的特征向量
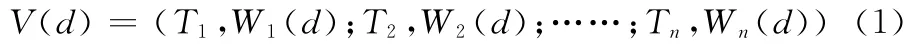
式中:Ti——n个分词中的一个,Wi(d)——Ti在文本d 中的权值,文本分词的权值通过TF-IDF公式计算[3]
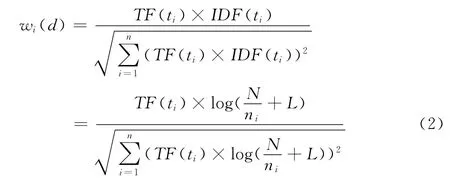
式中:wi(d)——计算出的特征词Ti的权值,TF(ti)——特征词Ti在d 中出现的次数,N ——样本总个数,ni——出现了Ti的林业信息样本的个数。
1.2 林业信息文本特征选择
设n个样本,样本有p 项 指标[4]:X1,X2,...XP,得到初始特征矩阵为

其中

综合指标向量X 是p 个向量X1,X2,...XP作线性组合
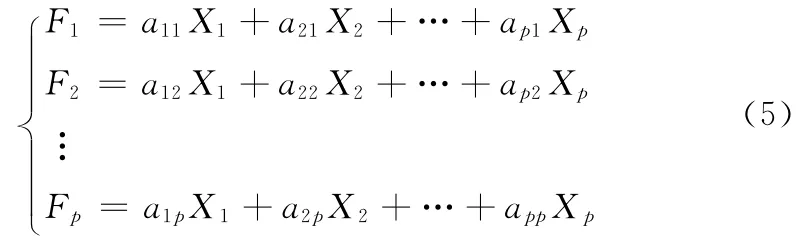
可简写为

系数ai=(a1i,a2i,…,api)的限制条件
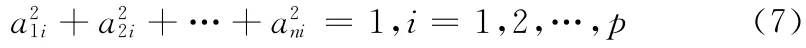
特征矩阵的协方差矩阵是S =(sij)p×p:
其中

计算S的特征值λ1≥λ2≥…≥λn>0与对应单位向量

X 的第i个主成分为Fi=a′ix,i=1,2,…,p。
主成分的确定根据贡献率αi和累积贡献率G(r)

实验中,选择累积贡献率达到99%的主成分,n个文本在所选r 个主成分的得分

1.3 林业信息文本分类算法
传统的极端学习机算法和BP神经网络算法受林业信息样本影响较大,因此不同样本分类的正确率差异大,差分演化优化极端学习机算法实验得到了较好的效果,分类结果精准并且正确率分布均匀。
1.3.1 极端学习机算法 (ELM)
设ELM 算法 的代价函数E0,则

式 中:N0——林 业 信 息 文 本 的 数 量;——隐 层 数;βi=(βi1…βic)T,βi——输出权值;ωi=(ωi1…ωin),ωi——输入权值;xj0=(xj01…xj0n),xj0——林业信息文本的特征矩阵;bi——隐层偏差;tj0=(tj01…tojc),tj0——林业信息文本的种类;函数g(wi·x0j+bi)——隐层激活函数;n——林业信息样本的维数,c——林业信息样本的种类总数,也就是输出结果[5]。
ELM 的思路为求E0,之后Min E0
[6],所以问题转化成当下式成立的解(i=1,2,…珦N)、^β

上式参数描述为

H0表示隐层输出

由于ELM 算法的激活函数无穷可微,所以ELM 算法能够描述为求解H0β=T0的范数最小。即

H+0是矩阵H0的广义逆。
在rank(H0)=N 条件下,通过正交投影法求得H+0

算法运行步骤如下:
(1)βi 和bi初始化;
(2)计算H0;
(3)计算输出结果^β。
1.3.2 差分演化算法 (DE)
差分演化算法在求解最优化问题时,是一种高效有潜力的算法[7],在只能计算领域已成为一个研究热点。差分演化算法是演化算法的一种[8],但是其性能优于普通的演化算法,在解决优化问题时,收敛速度快[9]。DE 主要包括:变异、杂交、选择[10]。
首先,使用下式得到变异个体

式中:Vi—— 新变异个体,Xi=(i=1,2,…,Np)表示群体 中 第i 个 个 体,i,i1,i2,i3选 取 不 同 值,i1,i2,i3∈{1,2,…,Np},Np是种群大小,且Np≥4,F ∈[02]是控制参数,以对(Xi2-Xi3)进行调整。
然后,杂交程序是个体Xi与Vi的重新组合后生产新成员Ui
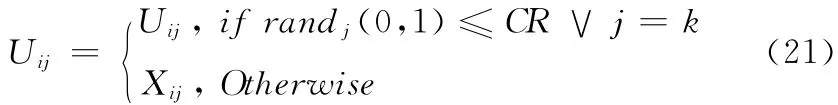
式中:CR ——DE 算法中的主要参数,表示杂交概率;k∈{1 ,2,…,D },D 表示问题搜索空间维数。
最后,选择过程就是在Xi和Ui中选择适合种群发展的个体
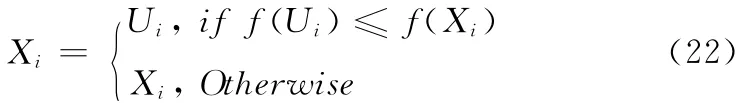
1.3.3 DE-ELM 算法
极端学习机算法由于初始输入值的选择是随机赋值,因此会对输出权值矩阵造成影响,引入差分演化算法,对极端学习机算法进行优化,获得最小隐含层输出权值。
DE-ELM 算法执行如下:
(1)初始化种群:参数NP、F、CR 初始化赋值。新种群:x(t)=(x1(t),x2(t),…xN(t)),每个个体表示林业信息文本的特征矩阵m×d 维,表示为m×d =D。
(2)种群中的个体分别进行DE 算法的 (3)步,先通过式 (20)变异后获得 新个体Vi(t),新老个体杂交后形成个体Ui(t),之后选取有竞争力的个体,选取过程如下
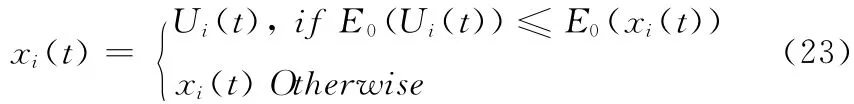
式中:E0(·)代表式 (13)中MinE0,即为种群中每个个体的目标函数值。
(3)设置迭代误差,根据迭代次数判断程序是否终止。若在迭代次数范围内继续 (2)步,否则进入 (4)步。
(4)输出EO(best),和对应的^β。
(5)程序结束。
2 实验结果
实验初步针对林业信息文本样本进行选择,林业信息的5个类别:花、树木、虫、土壤、水,训练样本和测试样本是每个类别选取50个,测试样本是对原训练样本数据加高斯白噪声产生,样本总共500个。
实验过程中,初始化种群,设置种群数NP =200,杂交概率CR =0.8,缩放因子F =0.02,在选取不同的隐含层节点数时,获得的目标函数的最小值也是不一样的。训练和测试样本初始特征矩阵维数均为250×1127维,降维后形成新的特征矩阵维数均为250×213维,文本类别总数K =5。
图1中,实验过程选取隐含层节点数为5,随着差分演化优化极端学习机算法的迭代次数的增加,目标函数的值在不断减小,逐渐接近最优值,最后接近于0。

图1 DE-ELM 在林业信息文本数据集上的收敛
从图1可以看出,当隐含层节点数一定时,随着迭代次数的增加目标函数逐渐接近最小值。在表1中则当迭代次数一定时,随着隐含层数的增加,算法误差逐渐降低。在隐层节点40,DE-ELM 的测试误差率远小于ELM。所以,选择隐含层数为40和迭代次数20的DE-ELM 分类器与BP神经网络、SVM 支持向量机算法进行对比。

表1 隐含层数对算法的影响 (迭代次数为20次)
从表2中,BP神经网络与差分演化优化极端学习机算法的误差率较低,实验结果比较理想,但是DE-ELM 优于BP。
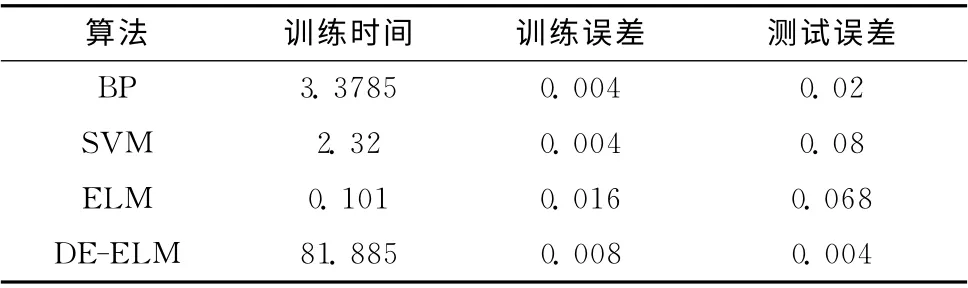
表2 4种算法性能对比
使用BP、SVM、ELM、DE-ELM 这4 种方法分类,选取相同的样本,测试结果如图2所示,横坐标是测试样本数目,纵坐标是分类器分类的正确率。

图2 分类算法正确率分布
在图2中,能够分别看出4种分类方法在处理不同类别文本时分类的正确率,算法对于不同的样本的分类情况。BP神经网络和差分演化优化极端学习机算法分类时性能较稳定,每类的分类正确率都较高,但是DE-ELM 性能更佳。
使用250个林业信息测试样本,从图3 中4 种分类方法正确率对比能看出每个分类器的分类效果。
实验结果可知,本文提出的基于差分演化优化极端学习机的林业信息文本分类算法能够实现对5类林业信息文本精准与快速的分类,分类效果明显优于神经网络、SVM分类算法,提出极端学习机算法的同时,优化初始算法,使得优化后的极端学习机有较强的分类能力;分类正确率均匀分布,能力较强。

图3 分类器分类总结果对比
3 结束语
基于差分演化优化极端学习机的林业信息文本分类算法,使用权值计算公式TF-IDF计算权值后对初始特征矩阵降维,构造林业信息文本的特征矩阵,来反映文本的特征。使用ELM 算法,通过对其优化,实现了林业信息文本的快速与准确的分类。实验结果表明DE-ELM 算法适用于林业信息文本的分类,分类正确率高于分类算法神经网络、SVM,为林业信息文本分类开拓了新思路,有较高的实用价值。
[1]HU Zewen,WANG Xiaoyue.Quantitative analysis and review of text classification research of home and abroad[J].Competitive Intelligence,2011,55 (6):78-82 (in Chinese). [胡 泽文,王效岳.国内外文本分类研究计量分析与综述 [J].竞争情报,2011,55 (6):78-82.]
[2]QI Xiaoming.The research of text classification based on artificial bee colony algorithm and improved KNN algorithm [D].Shanghai:Shanghai Jiao Tong University,2013:1-20 (in Chinese).[戚孝铭.基于蜂群算法和改进KNN 的文本分类研究 [D].上海:上海交通大学,2013:1-20.]
[3]ZHENG Junfei.Improvement on feature selection and classification algorithm for text classification [D].Xi’an:Xi’an Electronic and Science University,2012:3-20 (in Chinese).[郑俊飞.文本分类特征选择与分类算法的改进 [D].西安:西安电子科技大学,2012:3-20.]
[4]WANG Yafei.Research on feature dimension reduction in text classification[D].Changchun:Changchun University of Technology,2010:5-40(in Chinese).[王雅菲.文本分类中特征降维方法的研究[D].长春:长春工业大学,2010:5-40.]
[5]WANG Xinying,HAN Min.Multivariate chaotic time series prediction based on extreme learning machine [J].Journal of Physics,2012,61 (8):1-9 (in Chinese) [王新迎,韩敏.基于极端学习机的多变量混沌时间序列预测 [J].物理学报,2012,61 (8):1-9.]
[6]TANG Xiaoliang, HAN Min.A semi-supervised learning method based on extreme learning machine [J].Journal of Dalian University of Technology,2010,50 (5):771-776 (in Chinese).[唐晓亮,韩敏.一种基于极端学习机的半监督学习方法 [J].大连理工大学学报,2010,50 (5):771-776.]
[7]YUAN Jingsui.Differential evolution algorithm research summary [J].Science Research in University,2013,29 (1):1-2(in Chinese).[袁菁穂.差分演化算法研究综述 [J].高校理科研究,2013,29 (1):1-2.]
[8]MENG Ying,LUO Ke,LIU Jianhua,et al.K-medoids clus-tering algorithm method based on differential evolution [J].Application Reaearch of Computers,2012,29 (5):1651-1653(in Chinese).[孟颖,罗可,刘建华,等.一种基于差分演化的K-medoids 聚 类 算 法 [J].计 算 机 应 用 研 究,2012,29(5):1651-1653.]
[9]AO Youyun,CHI Hongqin.A survey of multi-objective different evolution algorithm [J].Journal of Frontiers of Computer Science and Technology,2009,3 (3):235-246 (in Chinese).[敖友云,迟洪钦.多目标差分演化算法研究综述 [J].计算机科学与探索,2009,3 (3):235-246.]
[10]JIA Liyuan,ZHANG Chi.Self-adaptive differential evolution[J].Journal of Central South University (Science and Technology),2013,44 (9):3759-3765 (in Chinese).[贾丽媛,张弛.自适应差分演化进化算法 [J].中南大学学报 (自然科学版),2013,44 (9):3759-3765.]
猜你喜欢
新世纪智能(数学备考)(2021年5期)2021-07-28
中华养生保健(2020年7期)2020-11-16
测控技术(2018年10期)2018-11-25
自动化学报(2018年2期)2018-04-12
制造技术与机床(2017年4期)2017-06-22
家教世界·创新阅读(2016年11期)2016-12-27
天津护理(2016年3期)2016-12-01
故事会(2016年15期)2016-08-23
信息安全研究(2015年3期)2015-02-28
太空探索(2014年1期)2014-07-10
