
基于PCA算法的人脸识别
2015-12-18 13:17黄华盛杨阿庆
电子科技 2015年8期
黄华盛,杨阿庆
(广东科技学院计算机系,广东东莞 523000)
人脸识别包括了图像预处理、特征提取与选择、分类识别这几个阶段。其中,特征的提取和选择是关键的一步。如何提取出区分度高的特征,决定了最终识别的准确率。特征提取是人脸识别的关键。
基于代数的特征提取方法是当前人脸识别的主流,且取得了较好的实验效果[1]。在此类的特征抽取方法中,基于主成份分析(PCA)是应用较广的人脸识别方法。PCA算法从图像的整体代数特征出发,使用K-L变换,提取出图像最主要的特征空间,去除数据冗余和噪声。
Simvich和Kirby首先将PCA变换用于人脸图像的最优表示[2],Pentland使用PCA算法进行人脸识别,在200个人的3 000幅图像中得到95%的正确识别率[3]。本文使用PCA算法进行人脸识别,并在 ORL人脸库[4]和 YALE人脸库[5]进行了实验。其结果表明,该方法对简单状况下的人脸图像有较高的识别率。
1 主成分分析方法
1.1 主成分分析的提出
主成分分析(PCA)方法是应用最广泛的特征提取方法之一,其是一种统计学方法,在信号处理、模式识别、数字图像处理等领域己得到了广泛的应用[6]。PCA是构造图像子空间的数学基础。其从图像整体代数特征出发,基于图像的总体信息进行分类识别[7]。主成份分析法能提取出图像数据的主要特征(主元),使数据能在更易于分类的子空间中被表示,同时降低数据维数,防止数据冗余,因此在人脸识别的研究中得到广泛应用。
1.2 主成份分析算法
1.2.1 训练过程
PCA算法训练过程的目标就是寻找一个变换矩阵,将高维的原始样本空间压缩到一个低维的特征子空间,使得样本数据在特征子空间中的分布更加紧凑,且更利于分类[8]。
(1)读入人脸库。读入建库的图像,将每张二维图像转化为一维向量。假设每张图像的宽度为w,高度为h,则图片为w×h的矩阵。将图像转化为一维矩阵,令m=w×h,则转化后的图像x是m×1的矩阵。若假设建库的图像个数是n,则训练集X构成m×n的矩阵。第i幅人脸可表示为x,整个训练集X可表示为X=
(2)对训练集X,求图像每个维度的平均值mean,则mean为m×1的矩阵,且
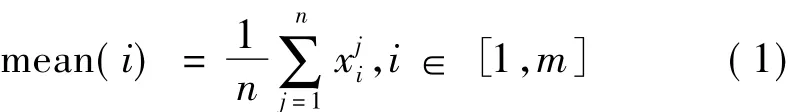
(3)将训练集X中每个图像的数据减去平均值mean,得到矩阵X1
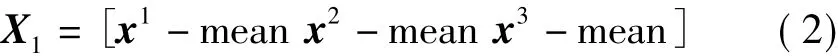
(4)使用式(3),求得训练样本的协方差矩阵∑。对协方差进行特征分解,求取特征根λ和对应的特征向量P0。根据特征根λ的数值,取前t个特征根,则其对应的特征向量Pt就是训练过程所求的转换矩阵

(5)利用式(4),将训练样本投影到子空间,得到的投影系数Y为表征训练样本的特征数据。Y为t×n的矩阵,其中的第i列Y(i)就是第i张图像在子空间的特征数据

1.2.2 测试过程

图1 ORL人脸库中某个人的10幅图像
(1)读入一张人脸图像,将二维图像转化为一维向量X1,同时减去平均值mean,同训练过程。
(2)令Y1=PtX1,将测试图像投影到子空间中,得到测试图像在人脸子空间中的特征数据Y1。
(3)将Y1和训练样本的特征数据Y进行匹配,使用分类器便可得到人脸图像的所属类别。
1.2.3 分类器
本文使用最近邻分类器进行分类。假设训练图像在子空间中的特征数据是Y1,Y2,…,Yn(n是训练图像的总数),且每张图像所属的类别分别为W1,W2,…,Wn。当给定一个测试图像Z的特征数据Yk,定义Y与Yk之间的距离为
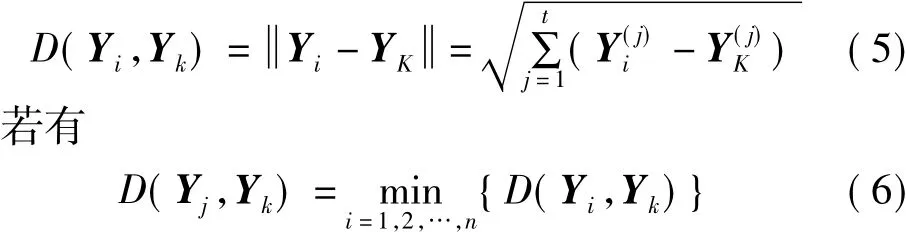
则最近邻分类器的分类决策是

2 实验结果
为了测试PCA算法的识别性能,本文采用ORL人脸数据库[4]和 YALE人脸数据库[5]进行了识别对比实验。
2.1 针对ORL人脸库的实验
ORL人脸库是英国剑桥大学实验室研究制作的人脸数据库。该数据库中包括40个人,每人10幅不同的图像,共400幅。每幅原始图像为256个灰度级,分辨率为112×92。ORL人脸图像是在不同时间、不同光照、不同表情和不同脸部细节的条件下拍摄的。人脸库中某个人的10幅图像,如图1所示。
在ORL数据库中,每个人有10幅图像。实验中,随机抽取其中的几幅图像作为训练集,另外的图像作为测试集。表1给出了不同数量训练样本下,PCA算法在ORL人脸库中识别率的比较。从表1中可看出,随着训练样本数量的增加,识别率也会呈现出上升的趋势。
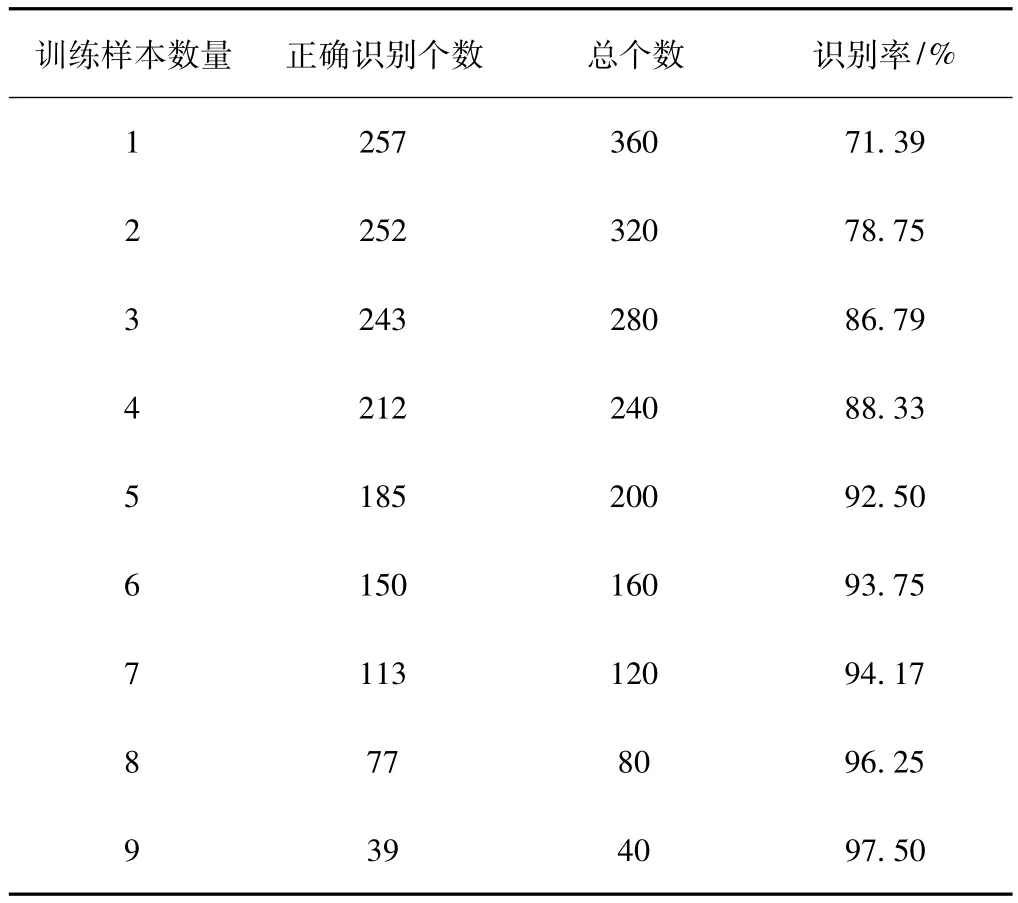
表1 不同数量训练样本下在ORL人脸数据库中的识别率比较
表2给出了在不同特征维度下,PCA算法在ORL人脸库中识别率的比较。从表2中可看出,当特征维度较小时,随着特征维度的增加,识别率迅速提高。但特征维度提高到31维后,随着特征维度的增加,识别率并未发生变化。因此,前面的31个维度对于人脸识别是重要的特征,而后面的特征对人脸识别并无影响。
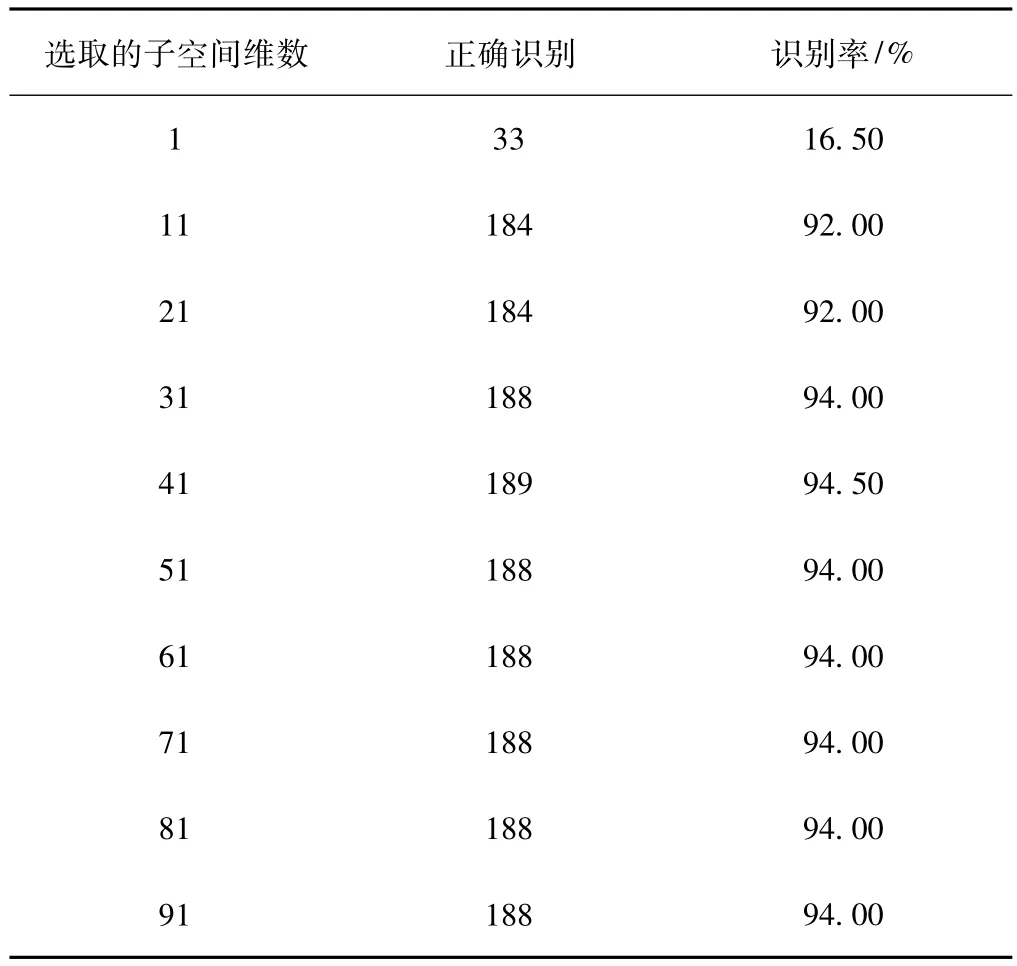
表2 不同特征维数在ORL人脸数据库中的识别率比较
2.2 在YALE人脸数据库上的实验
为检验在不同条件下本文算法的识别率,在YALE人脸数据库上进行了识别效果的对比实验。YALE人脸库有15个人,每个人11幅图像,共有165幅人脸图像。这些照片在不同的光照条件和脸部表情下拍摄。相比ORL人脸库,YALE人脸库的识别难度更高,因其中还包括了大部分的背景区域。图3是YALE人脸库中某人的11幅图像。
表3是采用不同数量训练样本下PCA算法的识别率比较。其中PCA的特征维数为90。
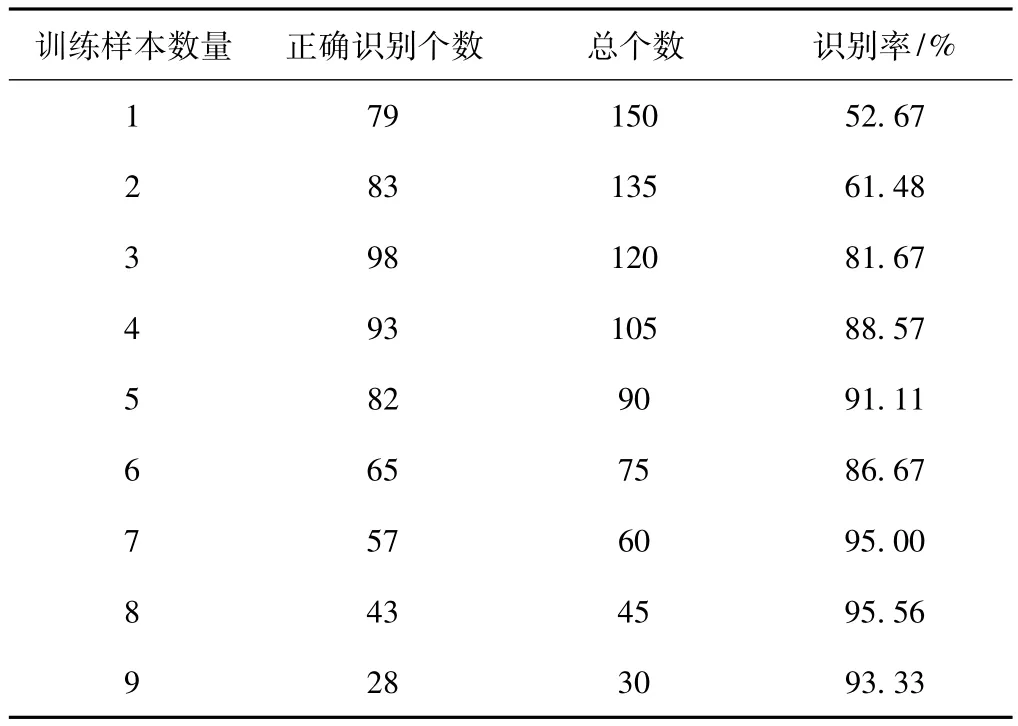
表3 不同数量训练样本下PCA算法的识别率比较
表4是采用不同特征维数下PCA算法的识别率比较。其中,对每个人的11幅人脸图像,随机取6幅作为训练集,另外5个作为测试集。
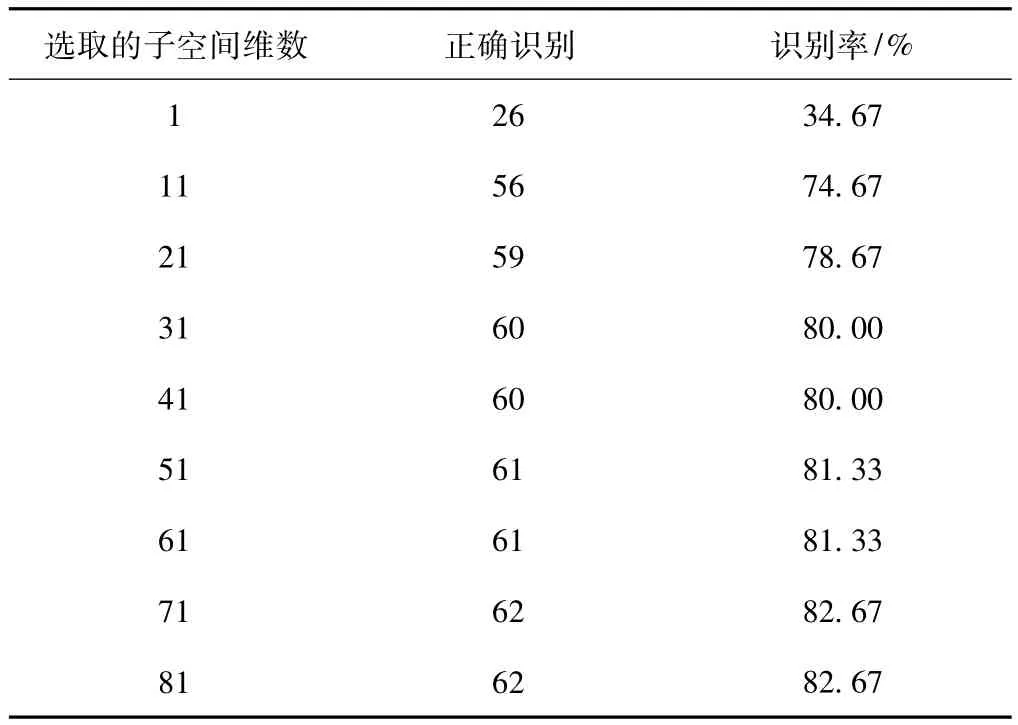
表4 不同特征维数下PCA算法的识别率比较
通过对两个人脸数据库进行的对比实验可看出,本文采用的PCA算法对简单状态下的人脸图像能进行有效地识别。表1和表3则表示了在相同特征维数的情况下,随着训练样本数量的增加,识别率也随之提高。表2和表4则表示了在相同训练样本的情况下,随着特征维数的增加,识别率由迅速提高转向逐渐缓和。因此,在进行人脸识别的过程中,只需取前面的部分特征便可进行有效地识别,即能保证识别精度,又能降低特征维数,从而提高了识别速度。
4 结束语
本文采用PCA算法进行人脸图像的识别。该方法提取出原始数据中的主要特征,减少数据冗余,使得数据在一个低维的特征空间被处理,同时保持原始数据的大部分信息,从而解决了数据空间维数过高的问题[6]。实验结果表明,本文采用的方法对简单状态下的人脸图像能有效识别,但对于背景较为复杂的人脸区域,识别精度还有待提高。
[1] 林宇生.一种对角LDA算法及其在人脸识别上的应用[J].中国图像图形学报,2008(4):686 -690.
[2] Kirby M,Sirovich L.Applicafion of the KL procedure for the characterization of human faces[J].IEEE Transactions on Pattern Anal.Machine Intell,1990,12(1):103 -108.
[3] Turk M,Pentland A.Eigenfaces for recognition[J].Journal Cognitive Neuroscicnce,1991,3(1):71 -86.
[4] ORL.ORL face database[EB/OL].(2001 -01 -31)[2014-11 - 29]http://www.uk.research.att.com/face database.html.
[5] YALE.YALE face database[EB/OL].(2002 - 02 - 12)[2014 - 11 -29]http://cvc.yale.edu/projects/yalefaces/yalefaces.html
[6] 程永.基于结构主元分析的人脸识别方法[D].中山:中山大学,2005.
[7] 周涛.基于PCA的人脸识别研究[D].南京:南京理工大学,2004.
[8] 崔法毅.改进的 Fisher鉴别分析两步算法研究及其在人脸识别中的应用[D].秦皇岛:燕山大学,2012.
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2020年3期)2020-07-27
计算机工程(2020年3期)2020-03-19
科技创新与应用(2020年6期)2020-02-29
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
中国交通信息化(2016年2期)2016-06-06
