
基于决策树技术的CET-4成绩数据挖掘研究
2015-12-01 07:06刘静
赤峰学院学报·自然科学版 2015年24期
刘静
(阜阳师范学院 教育科学学院,安徽 阜阳 236037)
基于决策树技术的CET-4成绩数据挖掘研究
刘静
(阜阳师范学院 教育科学学院,安徽 阜阳 236037)
本文运用决策树分类技术进行数据挖掘,从中发现CET-4考试四个部分对总成绩的影响程度.其中由决策树提取出分类规则,对于大学英语教学具有一定的指导意义.
数据挖掘;决策树;ID3算法
1 引言
CET-4考试是国家教育部组织的标准化英语教学水平考试,教育管理机构把它当作检查大学英语教学效果的一个有效尺度.每一年学校的数据库系统中都存放着海量的CET-4成绩信息,学校的数据库能够实现数据的快速录入、查找、计算等操作,却无法发现成绩数据中隐藏的关系和规则.本文主要研究的就是如何从海量数据中发现隐藏的关系和规则,分析潜在影响学生成绩的因素,从而为提高教学质量与教育管理提供依据.
2 数据挖掘决策树技术
数据挖掘是指从大量的数据中通过算法发现隐藏于其中关系和规则的过程.数据挖掘有很多领域,分类就是非常重要的一个分支.决策树是一种较为流行的分类技术,采用自顶向下的递归方式生成一个类似于流程图的树型结构.
3 ID3算法
1986年J·Ross Quinlan提出了著名的ID3算法.该算法就是信息增益属性划分,找出分裂后信息增益属性最大的再次划分.然后继续同样的过程,直到生成的决策树能完美分类训练样例.
4 决策树技术在CET-4成绩分析中的应用
4.1数据获取和数据预处理
4.1.1数据的获取
从教务处下载了我校普通本科班2012届学生某专业某次四级成绩汇总表.

图1 大学英语四级成绩原始数据
4.1.2数据预处理
去除原有数据源EXCEL表格中的不相关字段,保留CET-4总成绩、听力成绩、阅读成绩、写作成绩、综合测试成绩.使用忽略元组的方法将缺考学生的记录删除,共计175条.经过数据预处理后参加模型构建的样本数共计3384条,而预处理前的样本总数是3559条,样本的有效率达90.8%.
将样本数据进行离散化的处理.CET-4考试的试卷总分数为710分,将425分作为分割点,把CET-4成绩字段y离散为“pass”、“nopass”两个部分.
听力部分满分249分,阅读部分满分249分,写作和翻译部分满分142分,综合部分满分70分.分别将听力字段(st)、阅读字段(sy)、写作和翻译字段(sx)、综合字段(sz)的所有记录按照 st<=125、125<=st<199、st>=199、sy<=125、125<=sy<199、sy>=199、sx<=71、71<=sx<100、st>=100、sz<35、35<=sz<45、sz>=45离散化为“C”、“B”、“A”三段.
4.2决策树分类模型的构造
根据ID3算法构造决策树,操作过程如下:
(1)计算决策树分类属性的期望信息量
经过数据预处理、离散化操作后,用于构造决策树的记录为3384条,其中,“pass”和“nopass”记录分别为2015条、1359条.由公式定计算出分类属性的期望信息量为:
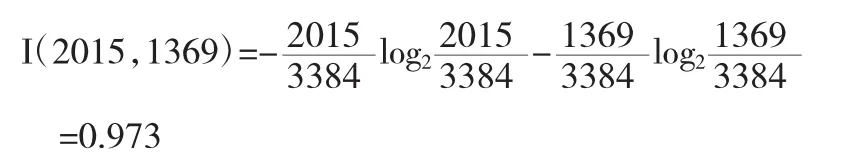
(2)依次算出st、sy、sx、sz 4个属性字段的信息量
算出st属性字段的信息量.st值为“C”的样本数707个,记为 (25,682);st值为“B”的样本数2580个,记为(1893,687);st值为“A”的样本数97个,记为(97,0).

计算sy的信息量.sy值为“C”的样本数468个,记为(7,461);sy值为“B”的样本数2747个,记为(1839,908);sy值为“A”的样本数169个,记为(169,0).
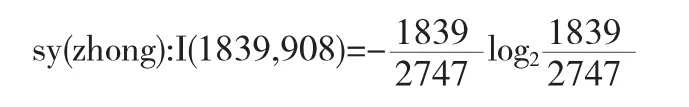

计算sz的信息量.sz值为“C”的样本数442个,记为(53,389);sz值为“B”的样本数2360个,记为(1414,946);sz值为“A”的样本数582个,记为(548,34).
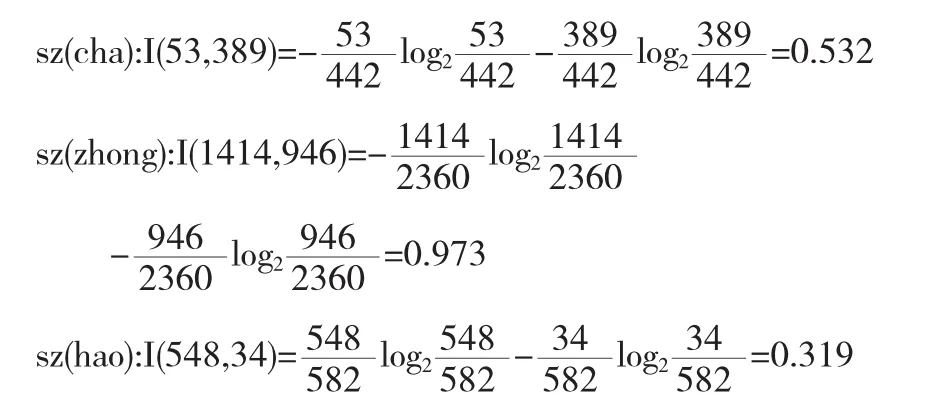
计算sx的信息量.sx值为“C”的样本数645个,记为(59,586);sx值为“B”的样本数2333个,记为(1560,773);sx值为“A”的样本数406个,记为(396,10).

(3)分别计算st、sy、sx、sz的信息熵

(4)分别计算出st、sy、sx、sz的信息增益量

比较以上4个属性字段的信息增益量,找出信息增益量最大的st字段,把该字段当作决策树的根节点,计算st字段的3个属性值构造出下面的分支.

图2 CET-4决策树
(5)提取分类规则
研究显示,在CET-4考试中,对CET-4分数影响最大的是听力部分,然后是阅读,接下来是写作和综合.下面从决策树模型中,根据分类结果为“pass”或“nopass”,提取得到了学生能否能够通过CET-4考试的分类规则.
提取出CET-4考试结果为“pass”的分类规则为:
IF“st”=“A”,THEN分类结果是“pass”;
IF“st”=“B”AND“sy”=“A”,THEN分类结果是“pass”;
IF“st”=“B”AND“sy”=“B”AND“sx”=“B”,THEN分类结果是“pass”;
IF“st”=“B”AND“sy”=“B”AND“sx”=“A”,THEN分类结果是“pass”;
IF“st”=“B”AND“sy”=“B”AND“sx”=“B”AND“sz”=“A”,THEN分类结果是“pass”;
提取出CET-4考试结果为“nopass”的规则为:
IF“st”=“C”,THEN分类结果是“nopass”;
IF“st”=“B”AND“sy”=“C”,THEN分类结果是“nopass”;
IF“st”=“B”AND“sy”=“B”AND“sx”=“B”AND“sz”=“C”,THEN分类结果是“nopass”;
IF“st”=“B”AND“sy”=“B”AND“sx”=“B”AND“sz”=“B”,THEN分类结果是“nopass”.
5 结论
由决策树提取出来的分类规则,可以辅助指导大学生的英语学习.CET-4考试中,听力部分对能否通过CET-4考试起到了关键性的作用;然后,是阅读部分,对CET-4考试影响较大;最后,写作部分和综合部分对CET-4考试的影响较小.在英语学习中有些学生认为,CET-4考试中,阅读和写作是决定CET-4成绩高低的关键,这种认识缺少科学依据,学生需要扭转观念,尽早调整自己的英语学习计划,将听力部分作为复习重点来强化练习.同学们在备考的过程中,可以参考决策树模型以及分类规则的结果,找出自己英语学习中的短板,进一步强化自己的长项,制定适合自己的学习目标和学习计划,进行针对性的复习,科学有效的提高CET-4成绩.
〔1〕Jiawei Han,Micheline Kamber.数据挖掘:概念与技术[M].北京:机械工业出版社,2007.188-198.
〔2〕王永梅,胡学钢.决策树中ID3算法的研究[J].安徽大学学报(自然科学版),2011(3):35-37.
〔3〕刘红岩,等.数据挖掘中的数据分类综述[J].清华大学学报(自然科学版),2002,42(6):727-730.
〔4〕陈昌川.数据挖掘在大学英语考试中的应用研究[D].重庆:重庆大学,2009.
〔5〕韩亚峰.P2P流媒体数据调度策略研究[J].河南科技学院学报(自然科学版),2013,41(1):86~90.
〔6〕张科星.基于云计算的数字资源系统设计[J].河南科技学院学报(自然科学版),2013,41(1):91~94.
TP391
A
1673-260X(2015)12-0018-02
猜你喜欢
江苏科技信息(2022年16期)2022-07-17
甘蔗糖业(2022年2期)2022-05-22
房地产导刊(2022年1期)2022-02-28
湖南林业科技(2021年3期)2021-12-02
沉积与特提斯地质(2019年4期)2019-07-19
西南交通大学学报(2018年5期)2018-11-08
新闻传播(2016年11期)2016-07-10
图书馆建设(2015年10期)2015-02-13
新世纪图书馆(2014年7期)2014-09-19
图书馆建设(2014年3期)2014-02-12
