
基于R语言多元分析的教育统计应用研究
2015-11-22 03:00:54李国军
鞍山师范学院学报 2015年2期
李国军
(鞍山师范学院物理科学与技术学院,辽宁鞍山114007)
R是GNU系统的一个自由、免费、源代码开放的软件,主要用于统计分析与数据可视化.R基于S语言,由MathSoft公司的统计科学部进一步完善,后再由Auckland大学的Robert Gentleman和Ross Ihaka及其他志愿人员开发成为R系统.R语言分析速度可媲美商业软件MATLAB[1].由R语言、LaTeX、Java及最常用C语言和Fortran撰写的千种软件包,增加了R语言功能.目前R语言用于经济计量、财经分析、人文科学研究以及人工智能.近几年来,在众多的统计学软件(如SAS、SPSS、Excel、S-plus、Minitab、Statistica、Eviews)中,R语言逐渐崭露头角.2011年世界编程语言排行榜中,R语言首次进入前20,这意味着R语言已成为统计领域中的主要编程语言.
1 主成分分析与探索性因子分析
主成分分析(Principal Component Analysis,PCA)是一种数据降维技术,它能将大量相关变量转化为一组很少的不相关变量,这些变量称为主成分.探索性因子分析(Exploratory Factor Analysis,EFA)是一系列用来发现一组变量的潜在结构的方法.它通过寻找一组更小的、潜在的或隐藏的结构来解释已观测到的、显式的变量间的关系[2].二者的目的都是降维,区别不在研究目的而在于数学模型[3].图1中展示了可观测变量(X1到X5)、主成分(PC1、PC2)、因子(F1、F2)和误差(e1到e5)的主成分模型和探索性因子模型.
主成分与因子分析实例:对表1中800名学生5门课程的成绩进行主成分与因子分析.
1.1 R语言主成分分析
mydata=read.table("student.csv",head=T);myprin=princomp(mydata,cor=T,rotation="varimax")#其中:mydata是原始数据矩阵;cor指定相关系数矩阵,默认为协差阵;rotate指定旋转的方法,默认varimax最大方差旋转,还可设promax斜交旋转.#
summary(myprin,loading=T)计算结果如表 2,表 3.

表1 800名学生5门课程的成绩(局部)

表2 相关矩阵特征值

表3 主成分载荷
由于前二个主成分的累计贡献率已经达到78.54%,接近80%.所以取前二个主成分来降维.此外还可以通过screeplot(myprin,type="line")利用碎石图2观察二个主成分比较合适.
其值分别为:
1.2 R语言极大似然法因子分析
myfactor=factanal(mydata,factor=2,score="regression",rotation="varimax")#其中:mydata是原始数据矩阵;rotate指定旋转的方法,默认最大方差旋转(varimax);factor设定因子个数;scores值分别为 "none""regression""Bartlett"(主成分法,主因子法不再讨论).myfactor计算结果如表 4、5、6,其统计数学模型与意义略.
Test of the hypothesis that 2 factors are sufficient.
The chi square statistic is 0.38 on 1 degree of freedom.
The p-value is 0.539
还可以通过 biplot(myfactor$score,myfactor$loading)观察二个因子作用效果.各科因子表达式为:math=0.672F1+0.386F2;phi=0.808F1+0.259F2;chem=0.814F1+0.374F2;lit=0.206F1+0.536F2;eng=0.358F1+0.729F2;可见 F1 为"文科因子",F2 为"理科因子"[4].

表4 特殊方差

表5 因子载荷

表6 因子对方差贡献
2 判别分析与聚类分析
判别分析(discriminiant analysis)是用于判断样品所属类型的一种统计分析方法,有Fisher确定性判别,Bayes概率性和距离判别.聚类分析(cluster analysis)是研究“物以类聚"的一种方法,也称群分析、点群分析、簇群分析等,有针对操作对象的基于样本的Q型聚类和基于变量的R型聚类之分,也有根据聚类方法的系统聚类(hierachical cluster method)、快速聚类(Kmeans cluster method)等之分[5].聚类分析和判别分析都是研究分类问题,但两者有本质的区别:判别分析是已知分类情况,将未知个体归入正确类别;聚类分析是分类情况未知,对数据结构进行分类.
判别与聚类实例分析:表7是4组教师X1-4对学生面试的平均成绩和最终的分类A-B(合格与不合格表,左部是已知分类,右部是未知分类)分数表,对其进行判别分析与聚类分析.
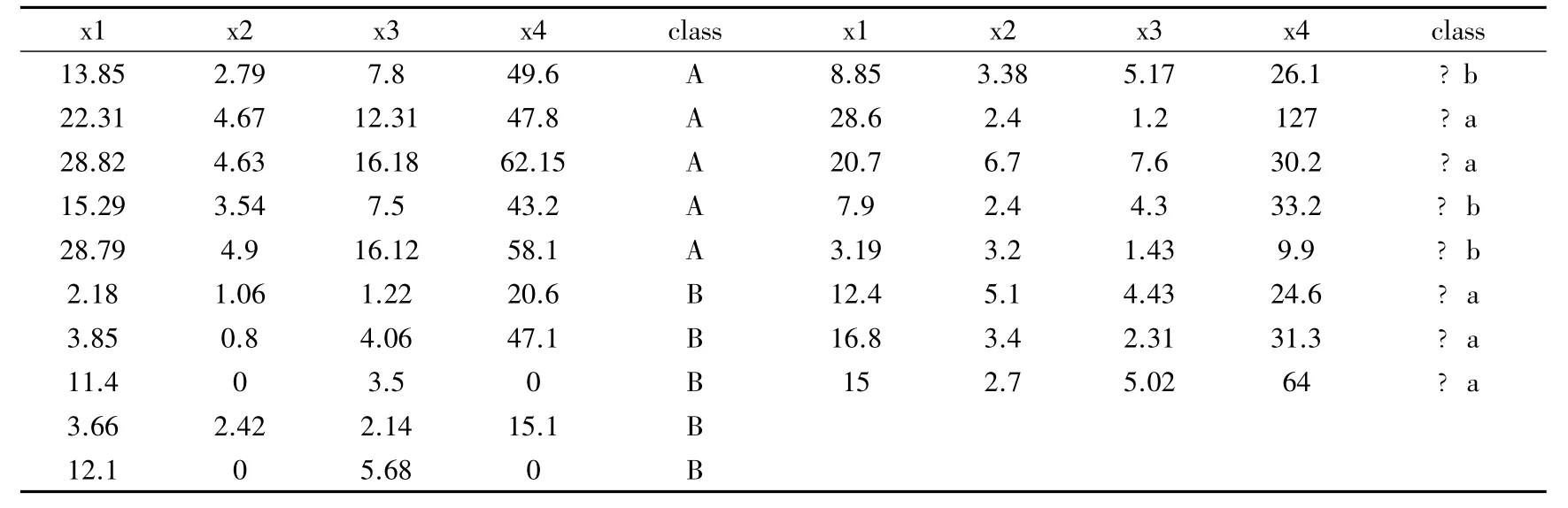
表7 教师-学生面试成绩和分类表
2.1 R语言Fisher线性判别分析
library(MASS);mydata2=read.table("clipboard",header=T)#选取表 7 左侧数据#
mylda=lda(class~.,mydata2);
mydata3=read.table("clipboard",header=T)#选取表7右侧数据#
mypredict=predict(mylda,mydata3)计算结果见表8,其统计数学模型略,统计意义见图3.
$class
[1]B A A B B A A A
Levels:A B
plot(mypredict$x,type="n")
text(mypredict$x,levels(mypredict$class)[mypredict$class],col=unclass(mypredict$class))
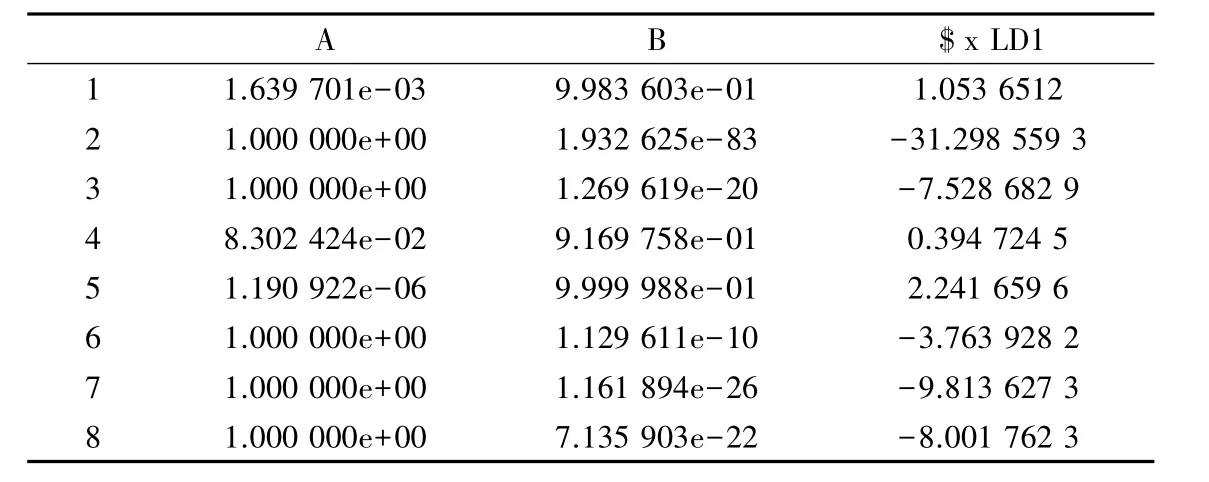
表8 $posterior与$x
2.2 R语言系统聚类分析
mydata4=rbind(mydata2,mydata3)#将右侧8名学生成绩追加到左侧10名学生成绩下面,形成18名学生成绩#
mydata5=dist(mydata4[1:4])
myhc=hclust(dist(scale(mydata5)),"ward")#method 可选 "complete","single","median"#
plot(myhc)其统计数学模型略,统计意义见图4.
3 相关分析与对应分析
相关关系是一种非确定性的关系.相关分析(correlation analysis)利用变量对之间的相关关系来反映两组指标之间的整体相关性的分析方法.当一组数据有两个变量时,即组内相关用相关系数表示;当一组数据有多个变量,一组数据有一个变量时,即二组间的相关用复相关系数衡量;当二组数据都有多个变量时,二组间的相关用典型相关分析(canonical correlation analysis)[6].对应分析(Correspondence analysis)也称关联分析、R(变量之间关系)-Q(样品之间关系)型因子分析,分析由定性变量构成的交互汇总表(变量与样品之间对应关系)来揭示变量间的联系.二者在汉语中易混淆,因而放在一起说明.
3.1 R语言典型相关分析
相关分析的实例分析:对表1中800名学生5门课程的成绩,前二个为理科为一组,后二个为文科一组,分析二组相关关系.mydata=read.table("clipboard",header=T);mydatacan=scale(mydata)mycan=cancor(mydatacan[,1:2],mydatacan[,4:5])u=as.matrix(mydatacan[,1:2])%*%mycan$xcoefv=as.matrix(mydatacan[,4:5])%*%mycan$xcoefpar(mfrow=c(2,2))for(i in 1:2)for(j in 1:2)plot(u[,i],v[,j])par(mfrow=c(1,1));其统计数学模型略,统计意义明显的是图5中1行2列,文理相关成线性但不十分明显,其中数学与语文相关相对更紧密.
3.2 R语言对应分析
对应分析的实例分析:针对不同学业成绩的学生对学校教学满意度调查交叉表(表9),分析成绩与满意度的对应关系.
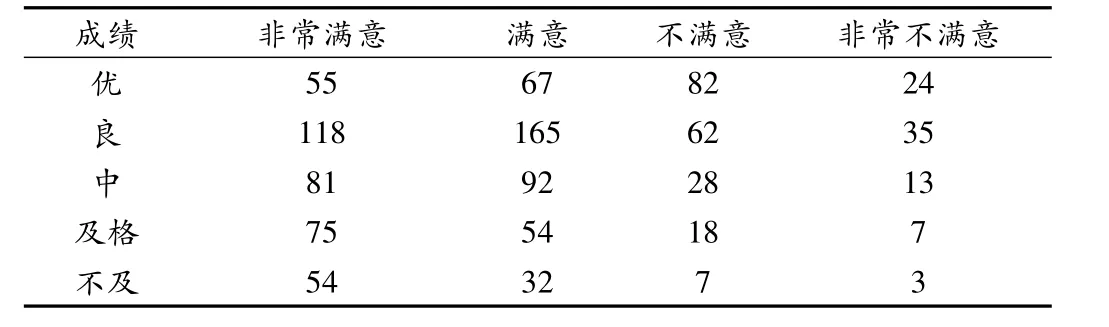
表9 学生成绩-教学满意度表
library(MASS);mydata=read.table("clipboard",header=T);mydatacor=mydata[,2:5];rownames(mydatacor)=mydata[,1];mycor=corresp(mydatacor,2);biplot(mycor)
其统计数学模型略,统计意义见图6.
4 小结
教育多元统计是统计学应用的重要组成部分之一,笔者用教育统计实例说明了其具体使用过程.这一过程中有两个方面需要说明:一是没有进行统计数学公式的推演,因为稍显厚重的统计学原理中都会给以解释;二是没有对实例中分析结果的统计学意义进行详细的说明,因为分析的结果(图、表)已展示得很直观了.
[1]R 语言.百度百科[DB/OL].http://baike.baidu.com,2014-05-10.
[2]Robert I,Kabacoff.R 语言实战[M].北京:人民邮电出版社,2013.
[3]吴喜之.复杂数据统计方法:基于R的应用[M].北京:中国人民大学出版社,2013.
[4]汤银才.R语言与统计分析[M].北京:高等教育出版社,2008.
[5]王斌会.多元统计分析及R语言建模[M].广州:暨南大学出版社,2010.
[6]薛毅.统计建模与R软件[M].北京:清华大学出版社,2007.
猜你喜欢
体育科技文献通报(2022年3期)2022-05-23 13:46:54
新高考·高二数学(2022年3期)2022-04-29 05:08:09
电子测试(2017年15期)2017-12-18 07:19:27
中学数学杂志(初中版)(2016年5期)2016-11-01 11:22:43
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
高中生学习·高三版(2014年3期)2014-04-29 06:11:18
高中生学习·高三版(2014年3期)2014-04-29 06:10:49
河南科技(2014年5期)2014-02-27 14:08:47
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
