
基于非特定发音人拉祜语孤立词语音识别研究
2015-11-14 03:20:32王米利佘玉梅刘敬凤潘文林
云南民族大学学报(自然科学版) 2015年4期
王米利,佘玉梅,2,苏 洁,刘敬凤,潘文林,2
(1.云南民族大学数学与计算机科学学院,云南昆明650500)
(2.云南民族大学云南省高校物联网应用技术重点实验室,云南昆明650500)
语音识别的研究起始于20世纪50年代,由最初对元音、辅音、数字以及孤立词的识别,到大词汇量、非特定人、连续语音的识别,语音识别技术取得了巨大的成就.线性预测分析算法、动态规划的算法,动态时间规整技术[1]、矢量量化、隐马尔可夫模型[2]、N元文法统计语言模型、深度神经网络模型等技术广泛的应用到语音识别中来,极大的推动了语音识别的发展[3].我国少数民族语音识别开始于20世纪90年代,起步较晚,藏语、维语、蒙语在语音识别和语音翻译方面取得较多的研究成果,其他民族语言语音识别技术研究相对落后,甚至是空白[4].
拉祜族是云南省25个少数民族之一,拉祜语从语系、语族、语支来说,属于汉藏语系藏缅语族彝语支的一个独立语言[5].拉祜族原来没有文字,20世纪初,美国传教士用罗马文字创制了一套拉祜文,新中国成立后,政府和拉祜族知识分子进行调查研究在此基础上制定了统一的拉祜文[6].使用拉祜语为第一母语的人口有30多万,但掌握拉祜文字的人很少.拉祜族大部分居住在云南省境内的普洱、临沧、西双版纳、玉溪、红河5个州市内,他们的受教育程度较低,语言是他们获取大量外界信息的主要障碍之一.因此,开展借助于计算机或软件工具的拉祜语音识别、语音翻译是有必要的.小词汇量非特定人语音识别是语音识别领域重要的分支[7].
1 拉祜语语音
拉祜语分两大方言:拉祜纳和拉祜熙,平时说的拉祜语标准语是指拉祜纳方言.拉祜语以前没有文字,拉祜语的传承是靠口口相传,因此拉祜语的词汇更加生活化,日常生活用语和劳作用语大量的传承了下来.根据文献[3]得知拉祜语的使用现状,目前拉祜语的高频词汇包括从汉语、傣语借词在内有将近2 000个词汇.拉祜语的基本词汇即你(nawl)、我(ngal)、她(yawd)、太阳(mudni)、山(qhaw)、河(lawl)等,基本词汇量在300~500之间,本次实验使用200个基本词汇的语音进行实验.
拉祜语共有24个辅音音位,30个声母,19个元音,7个调值,5个舒声,2个促声.
1)30个声母:
P [p ]、ph[ph]、b[b]、m[m]、f[f]、v[v]、t[t]、th[th]、d[d]、n[n]、l[l]、z[ts]、zh[tsh]、dz[dz]、s[s]、r[z]、k[k]、kh[kh]、g[g]、w[w]、ng[η]、h[x]、x[γ]、q[q]、qh[qh]、c[t∫]、ch[t∫h]、j[dз]、sh[∫]、y[з].
2)19个韵母:9个单韵母,10个复韵母.
a[A]、i[i]、e[e]、ie[ε]、u[u]、o[ϖ]、aw[ə]、eo[γ]、eu[ω]ia[ia]、iao[iau]、iu[iu]、ei[ei]、ai[ai]、ao[au]、ou[ou]、ui[ui]、ua[ua]、uai[uai][ə:].
3)音节结构由元音+声调,或辅音+元音+声调构成,没有带辅音尾的音节.
2 语音识别原理及过程
基于HMM模型的HTK工具箱是由英国剑桥大学工程系(CUED)研发的,用于语音识别研究.基于HTK工具箱的拉祜语音识别的过程,如图1:

2.1 准备拉祜语音
针对拉祜语音的特点,在专业的语言教师帮助下,确定录音内容为拉祜语日常生活高频词汇.邀请云南民族大学拉祜语班2011级和2012级的男女同学各2位来录音.他们来自澜沧拉祜族聚集的村寨,母语为拉祜语,均能流利地用母语交流,且发音清晰.在实验室安静环境下,利用软件Cool Edit pro2.1录音.共录200条拉祜语孤立词的语音.每个孤立词8遍录音.部分拉祜语孤立词列表如表1:
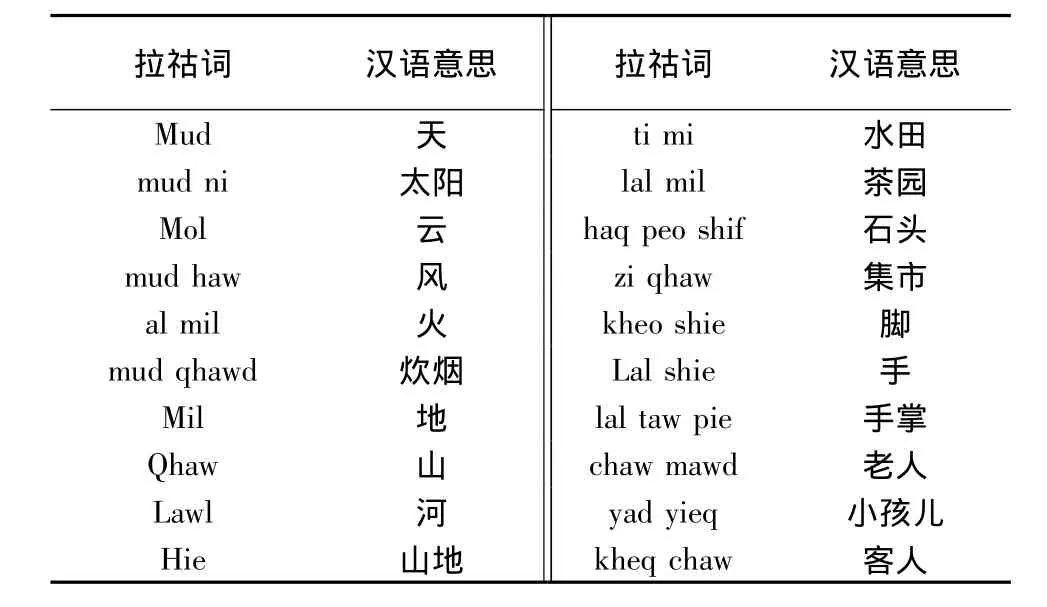
表1 部分拉祜语孤立词列表
2.2 语音标注
HTK工具箱中的HSlab标注工具使用起来不方便,且易出错,换用专业的语音学软件Praat来对拉祜语孤立词语音做标注,把Praat做好后的.txtgrid标注文件转化为HTK工具可以识别的lab文件.
2.3 拉祜语孤立词特征提取
特征提取是对原始的语音信号运用一定的数字信号处理技术进行适当的处理,从而得到一个矢量序列,这个矢量序列可以代表原始的语音信号所携带的信息.语音信号特征参数为45维,选用14个MFCC系数,加上F0能量,15个一阶MFCC倒谱系数,15个二阶的MFCC倒谱系数,具有较好的识别率[8].调用HTK中的Hcopy工具,对孤立词语音信号进行特征提取.其中配置文件参数的设置:预加重系数0.97,滤波器组内滤波器个数是22,Mel倒谱的频道数是26,加窗函数为汉明窗.配置文件内容如下:
#
#Example of an acoustical analysis configuration file
##声学分析配置文件
#SOURCEFORMAT=HTK #定义声音文件的形式
SOURCEFORMAT=WAV
TARGETKIND=MFCC_0_D_A #定义特征参数的类型
WINDOWSIZE=250000.0 #帧长为25 ms
TARGETRATE=100000.0 #移帧10 ms
NUMCEPS=14#MFCC系数为14(从c1到c14)
USEHAMMING=T #使用汉明窗
PREEMCOEF=0.97 #预加重系数为0.97
NUMCHANS=26 #滤波器通道数为26
CEPLIFTER=22 #倒谱liftering的长度
#The End
配置文件参数设置好,特征提取的命令:
Hcopy—A—D—C analysis.conf-S targetlist_train.txt.
其中analysis.conf就是上述的配置文件名,targetlist_train.txt文件指明了语音文件的路径及对应特征mfcc文件存储的路径.
特征参数MFCC的系数较大,又加上语音数目较大,特征提取这一过程在个人电脑上运行需要15 min.命令执行完毕在对应的目录中生成语音特征mfcc文件.生成的mfcc文件是一组矢量序列,是数字化的表示而非波形或语音文件,不具有直观可视性.提取的特征能否可靠的表示原始语音主要依靠配置文件中各项参数的选取,提取的特征是否有效的表示了原始语音可以从识别过程中匹配的结果看到.如果提取的特征有效的表示了原始语音,则语音的识别率就较高,反之,识别效果较差,需要调整参数重新实验.
2.4 拉祜语孤立词模型训练
HMM模型每个状态输出的是连续密度函数;高斯混合HMM模型,在每个状态输出函数中增加高斯密度函数(即正态分布函数).高斯混合度N是指在该状态的输出函数中加入N个高斯密度函数[9].以高斯混合数为2的HMM模型状态输出函数为例,如图2.

1)模型定义.使用了6状态左右跳转的HMM模型,使用39维的mfcc特征,第1和第6状态为连接状态,不产生输入和输出,对状态2至状态5进行定义,每个状态使用39维的均值和协方差;单高斯HMM模型(即在6状态左右跳转的HMM模型状态2至状态5,每个状态增加1个高斯混合数)、2mixtures HMM模型(即在6状态左右跳转的HMM模型状态2至状态5,每个状态增加2个高斯混合数)和4mixtures HMM模型(即在6状态左右跳转的HMM模型状态2至状态5,每个状态增加4个高斯混合数).
2)模型初始化.调用初始化函数 HInit和HCompv.HMM模型,只需调用HInit进行初始化即可;高斯混合的HMM模型要先调用HInit对模型进行初始化,再调用HCompv计算出全局的均值和协方差,并赋给每一个初始化模型,使每个初始模型有相同的均值和方差.
3)训练.初始化完成后,对每个词的HMM模型用HRest重估函数迭代直至收敛,通过change量度标示收敛性,一旦这个量度值不再从一个HRest迭代到下个迭代减少(绝对值),过程就该停止了,一般迭代2~3次即可达到收敛,对每个词的HMM模型都迭代3次,得到孤立词收敛稳定的HMM模型.
2.5 利用HTK工具箱对拉祜语孤立词识别
准备好待识别的语音,和前面训练的语音一样,做好标注,提取语音特征.在进行识别之前还需建立孤立词词典和语法,并调用Hparse函数生成语法网络.对训练过的HMM模型建立模型的主宏文件,并调用基于最大似然概率的HVite算法进行识别.最后利用HTK工具箱中统计工具HResults求出识别正确率.

其中,H为被识别正确的单词数,S为被错误识别的单词数,D为删除的单词数,I为插入的单词数,N为识别的单词总数.本次识别只有孤立词没有句子,所以sent行的正确率为孤立词的正确识别率.
3 实验结果
3.1 特定发音人拉祜语孤立词识别结果
特定发音人孤立词识别是指同一孤立词训练使用的语音和识别使用的语音均由同一位发音人发音.
实验用200个孤立词同一个人发音的6组语音,用5组语音来训练孤立词模型,另1组语音来识别,识别结果如表2:

表2 特定人语音识别结果
对于特定发音人的拉祜语孤立词识别,发音人的发音特征和发音习惯是稳定的,识别率随着孤立词数目的增加平稳变化,有所降低.但在实际应用中都是面对非特定发音人的语音识别,具有较高识别率的特定发音人的识别在实际应用中有一定的局限性.
3.2 非特定发音人拉祜语孤立词识别结果
非特定发音人拉祜语孤立词识别是指同一孤立词的训练语音和识别语音由2位或2位以上发音人发音.
本次实验使用3位发音人各2遍的发音作为训练语音,另外一位发音人的发音作为测试语音;MFCC选取13系数42维的特征参数;HMM模型使用8状态的HMM模型.200孤立词的测试结果如下,识别正确率为98.50%.
HMM模型拉祜语孤立词非特定发音人识别结果见表3.

表3 非特定发音人孤立词测试结果
3.3 混合高斯度对非特定发音人孤立词识别的影响
当混合高斯数目增加到4时,如图4识别正确率为100%,有效提高了识别正确率,保证了识别系统的质量.
试验发现:对拉祜语孤立词语音识别,增加HMM模型的高斯混合度有效提高了非特定发音人孤立词的识别正确率.同实验室其他语种(普米语)30个孤立词非特定发音人语音识别中,加入高斯混合数后,识别率反而有所下降.文献[10]试验表明,随着高斯混合数的增加,识别正确率也随着增加;但高斯混合数增加到一定值(80)时,识别正确率达到最高;高斯混合数继续增加,识别正确率反而下降.高斯混合度对拉祜语孤立词识别正确率的影响是否也符合这一规律,需要增加拉祜语孤立词的数目来进一步研究.
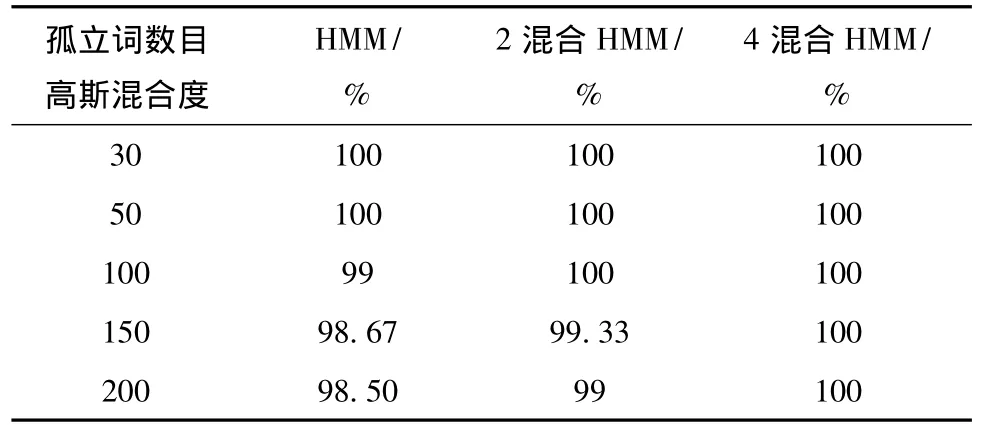
表4 增加混合高斯数目孤立词的识别率
4 结语
本文基于HTK对拉祜语孤立词的语音识别,通过对拉祜语语音进行特征的分析、提取MFCC特征参数,建立每个拉祜语孤立词的HMM模型,最后采用Viterbi算法进行模型的识别和匹配.本文通过对特定发音人和非特定发音人的拉祜语孤立词进行识别,发现特定发音人发音较稳定,识别率随着拉祜语孤立词数目的增加平稳变化,孤立词数目达到200时,识别正确率仍维持在75%.对于非特定发音人的拉祜语孤立词语音识别,随着拉祜孤立词数目的增加,识别率有所下降,原因是由于孤立词数目增加,数据稀疏,需要加大训练语音的数量,使得训练更加充分.非特定发音人的拉祜语孤立词语音识别,随着高斯混合数的增加,识别正确率也随着提高.以后将进一步研究随着高斯混合数的增加,拉祜孤立词识别正确率是否不再提高.
[1]VINTSYUK T K.Speech recogniton by dynamic programming[Z].Kibernetika:1975.
[2]JELINEK F.Continuousspeech recognition by statistical methods[J].IEEE.1976:6.
[3]TAMAKI N,MATSUOKA S,HARADA K.Recent application and development in speech recognition technologies[J].NTTReview.1994,3(16):66-75.
[4]王昆仑,吐尔洪江·阿布都克力木.我国少数民族语音技术研究进展[Z].兰州:2009.
[5]扎拉.拉祜语基础教程[M].昆明:云南大学出版社,2008:1-360.
[6]刘劲荣.云南拉祜族文字使用的历史与现状[J].云南师范大学学报:哲学社会科学版,2008(06):53-59.
[7]周卓然.小词汇量非特定人语音识别系统的研究[D].重庆:重庆大学,2012.
[8]张令通.基于HTK的白族语音识别方法[J].大理学院学报,2013(10):27-32.
[9]胡航.现代语音信号处理[M].北京:电子工业出版社,2014:1-407.
[10]陈泉金.基于HTK的连续语音识别技术研究[D].南京:南京邮电大学,2010.
猜你喜欢
数学小灵通(1-2年级)(2024年4期)2024-05-14 09:30:52
创造(2022年9期)2022-10-15 02:30:50
计算机工程(2020年3期)2020-03-19 12:24:50
小学生学习指导(低年级)(2019年6期)2019-07-22 03:33:10
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
文史杂志(2019年3期)2019-04-29 01:51:40
中国交通信息化(2018年3期)2018-06-13 03:27:58
中国(韩文)(2016年9期)2016-10-09 01:09:57
中国交通信息化(2016年2期)2016-06-06 07:28:02
四川师范大学学报(自然科学版)(2015年2期)2015-02-28 14:07:36
