
基于主动学习的SVM维吾尔语情感分析研究∗
2015-11-02 06:57李响吐尔根依布拉音卡哈尔江阿比的热西提买合木提买买提
新疆大学学报(自然科学版)(中英文) 2015年4期
李响,吐尔根依布拉音,卡哈尔江阿比的热西提,买合木提买买提
(1.新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046;2.新疆大学 新疆多语种信息技术重点实验室,新疆 乌鲁木齐 830046)
0 引言
在互联网时代普及的同时,网民们在互联网上获取知识和发布信息也随之增加,网络上出现大量带有情感的文本.然而这些信息的杂乱无序可能会误导人们,所以对这些信息的有效处理已成为一个很重要的课题.情感分类[1]是指对文本的情感进行不同类别的分析任务.目前对于研究情感分类已有数年,最常用的分类方法一般都是基于监督的学习[2].但监督学习有一个很致命的缺陷,就是需要大量的已标注的训练语料.小规模的语料较为好取,所以如何在小规模语料下获取较好的情感分类是值得研究的.
一般来说,半监督学习(Semi-supervised Learning)和主动学习(Active Learning)是常用的小规模样本分类方式.半监督学习是利用一些虽然没有标注却隐含能进行分类信息的大量数据,从而提高分类性能.此种方法在目前的情感研究中逐渐备受关注[1,3].主动学习是另一种降低标注语料规模的方法.这种方法通过主动的选择一些“优秀的”分类样本,然后参与分类,可以在少量的标注语料条件下还能得到较好的分类结果.与此相反,主动学习的方法情感分类研究还很少,这方面的研究还属于起步阶段[4−6].
本文在维吾尔语情感分类中加入了主动学习的方法,使用基于用户关系的Guduk维吾尔文微博网站中获取的语料[7],并用已有的基于众包的舆情语料标注方法获取少量标注语料[8].出于情感语料库的缺乏,为节省人力,该文使用聚类代表性,分类不确定性以及二者差异性三种策略去进行主动学习的标注,以此来扩大情感语料库的规模.
1 相关工作
近年来,自然语言处理研究领域的热点渐渐转为情感分析.情感分析可以分为基于机器学习的方法和基于情感词典或者知识系统的方法.其中,基于机器学习的方法主要有NB(朴素贝叶斯)、SVM(支持向量机)和最大熵方法等[9−11].Pang等首次在情感分类中使用基于监督的机器学习方法.许多后续研究的目的都是要提高监督学习方法的性能,例如抽取主观句[12]、寻找上层分类特征[13]和利用主题部分相关信息[14].
基于机器学习的维吾尔文情感分析还处于初级阶段,文献[15]通过人工抽取的方法收集了维吾尔句子里能表达情感的关键词和短语来建立情感词典.因人工抽取情感词费时费力,文献[16]通过使用条件随机场(CRFs)的方法分析维吾尔语的特征,并建立情感特征模版,利用此模型来自动识别情感词.田生伟等人[17]对维吾尔语情感分类使用了多个算法,如Naive Base、ME和SVM,对于这些算法使用了互信息、文档频率等特征提取的方法,其中ME和SVM对维吾尔语情感分类有较好的效果.
主动学习历来受人们关注,因为主动学习可以使机器学习更加人性化,更具有人工智能.目前有三类主动学习算法:第一种是减少分类误差来进行抽样,以达到抽样的样本更接近分类器的样本[18];第二种是通过找寻和分类器最不确定的样本,这样更能体现样本多样性[19];第三种是设置不同分类器同时抽样,找到差异最大的样本[20].
主动学习的方法在情感分类研究中才刚刚开始.文献[21]只是在大规模未标注语料中找到了适合学习的样本,这种基于深度置信网络的方法较为复杂,但也是主动学习的一种.文献[3]采用了主动学习三类中的第二种方法,即找到最不确定的样本或有歧义的样本,然后直接构建分类器.不过使用的主动学习策略相对简单,只能当作一种辅助.本文把三种策略的主动学习方法加入维吾尔语情感分类器,并验证了这个方法的有效性.这个方法可以在仅有的标注语料下,挑选出一些对分类器更为有用的适用的样本,这样可以获得更准确分类结果以便进行后续的学习.
2 维吾尔语情感语料处理
2.1 语料的获取
维吾尔语语料的获取可以从维吾尔语网站获取.维吾尔语网站不断建立以及内容更新,可以成为获取语料的首要手段.本文使用网络爬虫把网站中的语料获取下来,然后去除图像等非文本符号,只保留含有评论的文本[5].
2.2 语料的人工标注
用本小组已有的基于众包的舆情语料标注方法[6],可以对已获取的语料进行篇章级、段落级、句子级以及词语级进行情感标注.众包的任务外派给不确定的群体,而外包则是外派给确定的个体.此外,外包强调的是高度专业化,众包则相反,更有针对性和创作自由,对多学科的创新往往具有巨大的潜力.
2.3 情感表示
众包平台标注格式可用向量表示,每个所需标注的语料使用7种不同强度向量来表达此语料的情感程度.我们将情感分为乐(Joy)、好(Good)、怒(Anger)、哀(Sorrow)、惧(Fear)、恶(Hate)、惊(Surprise)这7种情感.每一个情感取值区间在0-1之间.
3 分类方法与聚类方法
3.1 SVM模型
对于各种语言分类,SVM(支持向量机)模型都很适合.本文使用SVM的方法来训练和分类维吾尔语情感文本.
该算法的原理:为区分类别,需要找到一个超平面,把不同的类别通过这个超平面进行分类.此外保证每个类别能在超平面两侧达到最大空白区域时,精度便能达到一定标准[22].
对于给定训练集:(xi,xj),i=1,2,...,n,x∈Rd,y∈{+1,−1},其中xi是特征向量,y是标注,d是特征维数.这里假设超平面为ω·x+b=0,如果样本数据线性可分,就可以找到这样的两个超平面使得这两个平面之间没有样本点,并且这两个超平面之间的距离是最大的.对于两个平面之间没有样本点,相当于yi(ω·i+b)>1,i=1,2,...,n.两个超平面之间的距离=2/|ω|,最大化这个间隔相当于最小化|ω|.解决最优分类平面的问题就转换成了一个带有约束性的二次线性规划的问题.
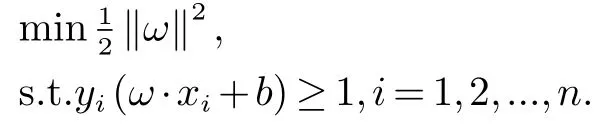
根据优化理论可得最终的决策函数为:
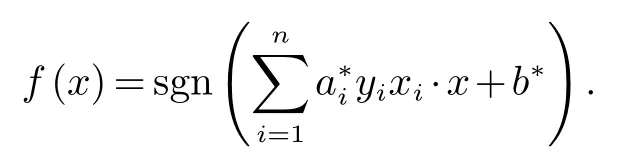
3.2 k-means聚类
对于没有标注的语料,我们需要使用无监督的机器学习算法.其中,k-means聚类较为简单又很有效.使用k-means聚类把未标注的语料划分为多个具有代表性的类簇.这里的每个类的质心在后续的主动学习策略中将体现出文本的代表性.在聚类的过程中,我们对已经转化为VSM的维吾尔语语料使用余弦定理来计算每个样本之间的距离,并划分为各个类.
4 主动学习的维吾尔语情感分类
SVM模型适用于各种语言,同样对于维吾尔语进行适当的预处理,就能很好的在SVM中运行.下面针对维吾尔语进行语料预处理,把原SVM模型改进为可以对维吾尔语进行情感分类的模型.
4.1 语料预处理
维吾尔语和英文类似,使用空格空开每个词,可以进行简单的分词.对分过词的维吾尔语我们需要做空间向量模型(VSM),然而维吾尔语向量化基本等同于其它语言.一般选用带有特征值的词作为向量模型,现在常用的计算特征词的方法就是使用TF-IDF(词频逆向文档频率).通过此算法选取的特征词一般能显示出文本的主题.在维吾尔语中也适用于此方法.下面给出TF-IDF计算公式[23].
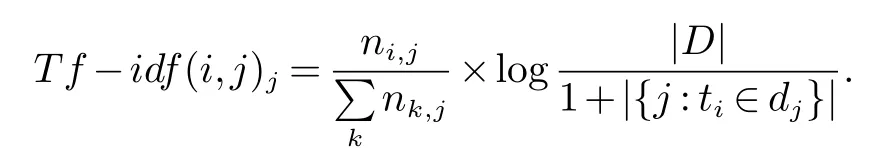
其中i代表文档数目,j表示每篇文档中带有特征的情感词数目,D是选取文档总数,n代表选取的特征词.通过此算法,可以构建向量空间模型.
维吾尔语是黏着性语言,如果情感词带有否定效果会在词的后面带有否定尾缀,在统计TF-IDF时应当把带有否定词缀的情感词逆置,即把这种带有否定词缀的句子的情感类别放入相反的类别里.
把语料做以上处理生成VSM(向量空间模型),在普通SVM模型中即可进行维吾尔语情感分类的分析.同时加入如下的三个主动学习策略来进行主动学习的维吾尔语情感分类.
4.2 主动学习策略
4.2.1 样本差异性
已标注的样本和未标注的样本理论上是有差距的.当然,在进行新的样本标注时,有更大差异性的样本就会更值得标注.这样标注的样本可以扩充之前的分类信息,获得更有用的分类信息.为了计算未标注样本的差异性,计算每个未标注样本到已标注样本的中心距离,样本之间的距离越大,那么它们之间差异性就会越大.然后把样本差异性和分类不确定性最大的样本取出并进行人工标注,把这些新的样本放入已标注的样本集中.使用如下公式计算需要人工标注的样本:
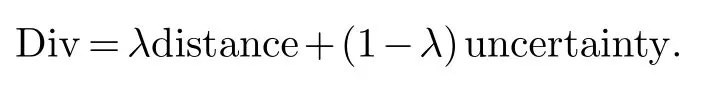
其中,distance代表未标注样本到已标注样本中心的距离,uncertainty代表未标注样本的不确定性,λ为人为定义的偏向系数,0<λ<1,本文中λ取0.5.
4.2.2 聚类代表性
聚类代表性指使用聚类算法对未标注的语料进行无监督的机器学习,让这些带有情感色彩的句子分为各个小类,然后在每个小类中算它们的质心,这个质心代表这个小类的点,这样每个小类的代表性就能体现.
4.2.3 分类不确定性
一般把已标注的样本,称为确信样本,这样的信息可以放入分类器进行分类.但是,无法确定的样本,即未标注的样本不能被分类.因此,这种不确定性可以衡量样本对分类器的重要程度.在引入不确定性前,先用少量已标注语料训练一个分类模型,然后使用这个分类器对带有不确定性的未标注样本进行分类测试,选取分类结果中类别后验概率最接近0.5(分类模型认为是不确定性最高的样本)作为候选样本.
4.3 主动学习策略算法
基于三种策略的主动学习算法:
输入:标注样本L,未标注样本U;
输出:新的标注样本L.
程序:
1).取样本L训练,构造分类器M;
2).对样本U使用聚类算法,生成具有代表性的各个小类;
3).计算每个小类的质心,即为每个具有代表性的样本;
4).使用分类器M对具有代表性的样本进行分类,获得每个样本对于样本L的不确定性;
5).对每个具有代表性的样本进行差异性计算;
6).选择差异性最大的样本做人工标注并加入样本集L中.
此算法把三种策略集合为一体筛选需要人工标注的样本.也可分别拿出每个策略进行单一筛选.
5 实验结果
实验采用维吾尔文微博网站Guduk微博上获取的具有情感色彩的微博19967条[5].实验中400条样本使用众舆情语料标注平台进行人工标注当作已标注样本以构造分类器.另取600条作为测试样本.剩下样本做未标注样本.分类算法使用libsvm2.0工具包(http://www.csie.ntu.edu.tw/∼cjlin/libsvm/),聚类算法使用自己编写的k-means算法.
通常在情感分析中使用准确率作为分类效果的衡量标准.计算公式如下:

本实验分别使用三种策略进行100,300,1000条语料的选择,我们把主动学习的策略简化描述,把随机选取的语料即获取未经过处理的语料进行标注的方法称为RAND,把分类不确定性方法称为UNCE,把聚类代表性方法称为REPR,把样本差异性方法称为Div.
表1是对原分类器加100条语料的分类结果.可以看出每种带有主动学习的方法都比随机选取进行标注的分类效果要好,另外把三种主动学习策略结合的效果更佳.
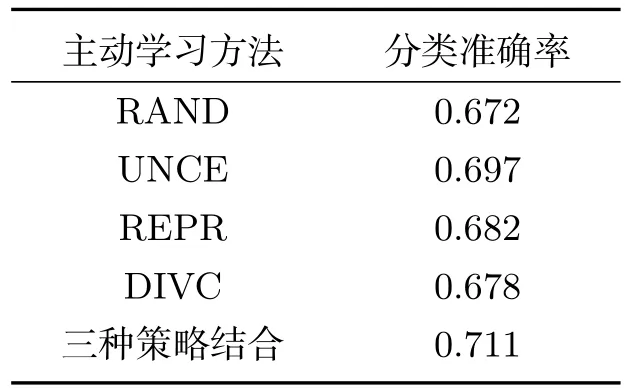
表1 加入100条语料分类结果
表2和表3分别是加入300和1000条语料的分类结果,可以发现,当越多的语料加入后,信息越来越饱和,准确率也逐渐提高,而且发现主动学习的策略在加入300条语料的分类结果超过了加入1000条语料随机抽取的方法.
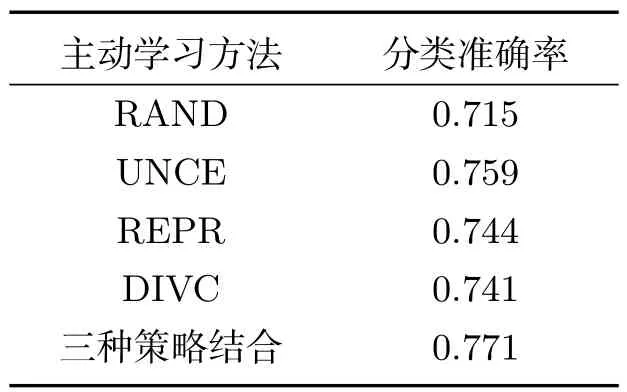
表2 加入300条语料分类结果
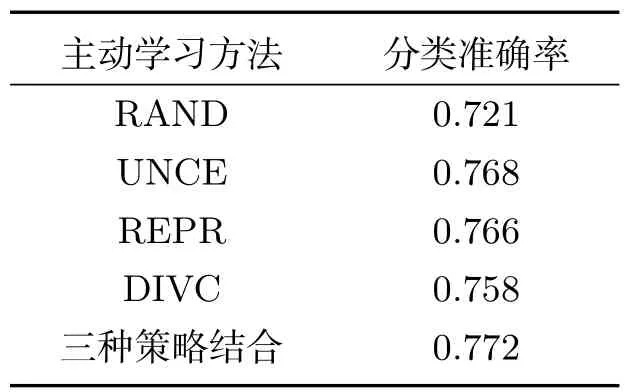
表3 加入1000条语料分类结果
使用不同策略后加入不同规模大小的语料再进行分类的准确率对比如图1.可以看出在语料规模增加后,每个策略都有明显的提高,但是在一定语料的加入后,准确率就有了一定饱和,不再上升.
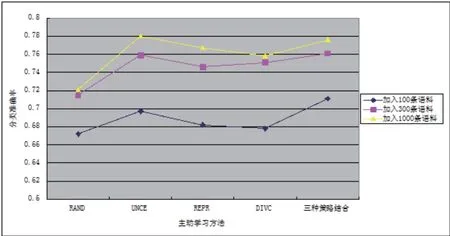
图1 在不同策略下加入不同大小语料的分类准确率
6 总结
本文在加入三种主动学习的策略选择更适合分类的语料标注.实验表明,基于代表性和基于不确定性的主动学习策略对于分类器准确率的提高要好于其它二者,并且把三种主动学习策略进行结合对于分类器的准确率也有稳定的提高.
加入主动学习的SVM分类器对维吾尔语情感分析的准确率有少部分提高,使得在较少标注语料的分类器下筛选更为有用的语料.但是SVM本身的准确率还有待于提高,接下来的工作需要选择合适的参数提高SVM的准确率,并扩充语料的规模,提高分类的准确率.
猜你喜欢
通信技术(2021年12期)2022-01-25
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
自动化学报(2017年4期)2017-06-15
新疆大学学报(哲学社会科学版)(2015年5期)2015-10-12
语言与翻译(2015年1期)2015-07-18
语言与翻译(2015年4期)2015-07-18
民族古籍研究(2014年0期)2014-10-27
航天返回与遥感(2014年5期)2014-07-31
外语教学理论与实践(2014年2期)2014-06-21
