
一种基于连体段的维吾尔文单词特征提取方法∗
2015-11-02 06:57苏佩佩哈力木拉提买买提艾尔肯赛甫丁王剑
新疆大学学报(自然科学版)(中英文) 2015年4期
苏佩佩,哈力木拉提买买提,艾尔肯赛甫丁,王剑
(新疆大学 信息科学与工程学院;多语种信息技术重点实验室,新疆乌鲁木齐 830046)
0 引言
维吾尔文字符识别在预处理后,首先要进行字符切分,把单个的字母切分出来,再对单个的字母进行特征提取,这样需要考虑字符的切分准确率,同时要考虑切分过程中出现的粘连和错切的情况,这些都是很繁琐的工作.为避免这些问题,本文选择了放弃字符切分的部分,对整个单词直接进行特征提取.
文字字符识别一般要求特征维度小,并且尽量保证不同字符的特征差别大.特征维度小能减少很多繁琐的工作,同时提高识别的准确率和速度.但是现实中字符识别往往是维度小、特征差别小且识别准确率低.为了提高识别率,传统方法选择高维度,但是这样降低了识别速度,加大了计算量.所以目前急需一种实现小维度高识别率的方法.
本文研究对维吾尔文整个单词识别的方法,即减少了字符识别这一过程,同时也省去字符切分和单个字符识别后再整合成单词识别的工作.这个过程大大减少了特征提取和识别的计算量,同时要求也更高.它要求所提取的特征能很好的识别整个单词,通过单词特征的唯一性来达到识别的目的.这里我们采取的是轮廓特征作为主要特征,每个单词都有其对应的基线[3]域,并且单词都是由几个连体段构成,连体段又由几个字符组成.根据基线域,我们把轮廓特征分成三部分,基线上的轮廓特征、基线中的轮廓特征和基线下的轮廓特征.基线上的轮廓特征和基线下的轮廓特征描述的是单词轮廓的外轮廓,即点轮廓.基线中的轮廓特征描述的是内轮廓,也就是孔轮廓,此方法能很好的解决低维度、识别效果差的缺陷.
维吾尔文单词由一些连体段组成,而连体段则由单个的字符组成,所以要对单词进行特征提取,首先要对连体段进行提取,本文讲述了连体段的划分、轮廓特征提取,以及需要涉及到的一些图像处理技术.
1 连体段以及单词的划分和轮廓的获取
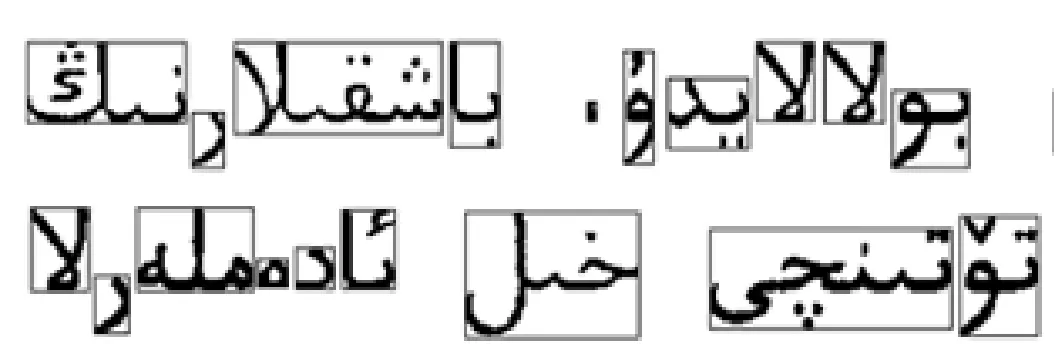
图1 连体段的矩形图
从图中看出,一个单词由几个连体段组成,并且每个连体段之间有一定的间距,每个单词之间也有一定间距,可以根据间距的大小来区分单词和连体段.通过水平投影和垂直投影得到连体段的四个坐标点,画出其对应的矩形就可以得到如图所示的矩形,将连体段划分出来.
1.1 图像水平投影和垂直投影
水平投影就是把图像投影到X轴上所组成的的图像,我们对要进行投影的图像,根据先行后列的方式扫描,如果发现该点为黑点,则把该点投影到该行的最左边,依次累加.而原来的像素点就不存在了,或者变成白点像素,直至扫描完所有的图像,则水平投影就完成了,它最终的图像是二值化图像.在对图像进行水平投影之前,先要对文档图形进行文本行的提取.
对整幅图像进行水平投影后,发现每个文本行的水平投影图都是有间距的.我们可以根据这些间距来判断文本行的高度值,确定它的起始点和高度值.由于文本行的宽度和整幅图像的宽度是一致的,这样就得到了本文行的四个坐标点,然后我们对图像进行感兴趣区域的划分,就能把文本行提取出来,如图2所示.

图2 一个带基线的文本行
从图中可以看出,对于每个文本行来说,可以求出其基线,然后求出倾斜角,为图像的预处理做铺垫.每个文本行都有自己的水平投影图和垂直投影图,通过对文本行的投影得到对应的连体段和单词.同样,对文本行进行垂直投影,也发现每个单词、每个连体段都有间距,根据间距得到连体段的水平宽度、水平起始点和宽度,然后结合文本行的高度,对连体段进行扫描,进行水平投影,就可以得到连体段的高度起始点和高度值,根据这四个坐标点就能得到连体段的区域.对文本行进行水平投影如图3所示.
从图中可以看出,文本行的水平投影图上下之间有一定的间距,根据这个间距可以划分开文本行,唯一不足的地方就是,对其水平投影是需要对其图像进行扫描,扫描针对每个像素点,不可避免的加大了计算量.

图3 文本行水平投影图
垂直投影就是把图像投影到Y轴上所组成的的图像.我们对要进行投影的图像,根据先列后行的方式扫描,如果发现该点为黑点,则把该点投影到该列的最下边,依次累加.原来的像素点就不存在了,或者变成白点像素,直至扫描完所有的图像,则垂直投影就完成了,它最终的图像也是二值化图像.同样的,在对图像进行垂直投影之前,先要对文档图形进行本文行的提取,文本行图像进行垂直投影后,发现本文行的垂直投影图都是有间距的,我们可以根据这些间距来判断文本行连体段的水平值、起始点和宽度值,如图4所示.

图4 本行的垂直投影图
从图中可以看出,文本行中的连体段在垂直投影后会有一定的间距.可以根据这个间距得到连体段水平位置的起点和终点,对文本行进行垂直投影,发现间距有大有小,其中间距大的是单词间的间距,间距小的是连体段间的间距.有一个临界值,大于等于这个临界值就是单词间的距离,小于的自然就是连体段间的距离.我们在对单词进行特征提取之前,也要根据这些特点进行单词间的划分.
1.2 单词划分
对于单词的划分,也是用水平投影和垂直投影分别得到单词的高度起始点、高度值、水平起始点和宽度值,然后根据这四个值来进行单词的划分.事实上连体段之间的间距小于单词之间的间距,在扫描本文行的时候判断字符之间的间距是否大于这个单词之间的最小值,如果大于则是单词的区分,如果小于就是连体段的区分.在单词的统计中要记录下它有多少个连体段组成,把每个连体段的特征要区分开,那么几个连体段也就成了单词的特征,把所有特征组合成一个特征向量,这个向量就是这个单词的主特征向量.如图5所示,显示了单词划分的图示,利用矩阵记录单词的四个坐标点,以此来定位单词的位置,同时记录所有单词编号,把具有相同特征的单词编号放到一起,便于实验结果统计.

图5 部分单词划分图
这些特征相同的编号表示的单词可能是同一个单词,也可能是不同的单词.这里也会出现在连体段划分过程中出现的划分区间过大、划分空白、划分重复等情况.如图6所示,展示了单词错分的示意图.
1.3 轮廓的提取

图6 部分单词错分图
轮廓[1]就是一系列的点,这些点代表图像的边界点,形成了一条曲线.根据不同的方法这些曲线的形成也会不一样,但都是存储图像的轮廓信息.轮廓有外轮廓和内轮廓之分,外轮廓就是外面边界的曲线,内轮廓就是图像里面边界的曲线,俗称孔,有孔的地方就会有内轮廓.在识别过程中,要先把感兴趣的区域目标提出来,然后通过颜色纹理提取目标的前景图,在根据前景图进一步把目标轮廓提出来,这就是目标轮廓的提取.对于连体段来说图像区域存在孔,就是内边界,形成的轮廓就是内轮廓,如图7所示.而外面的点或者其它形状图像都只有外轮廓.区域的边界提取和外轮廓的跟踪是为提取图像的边界特征做铺垫.
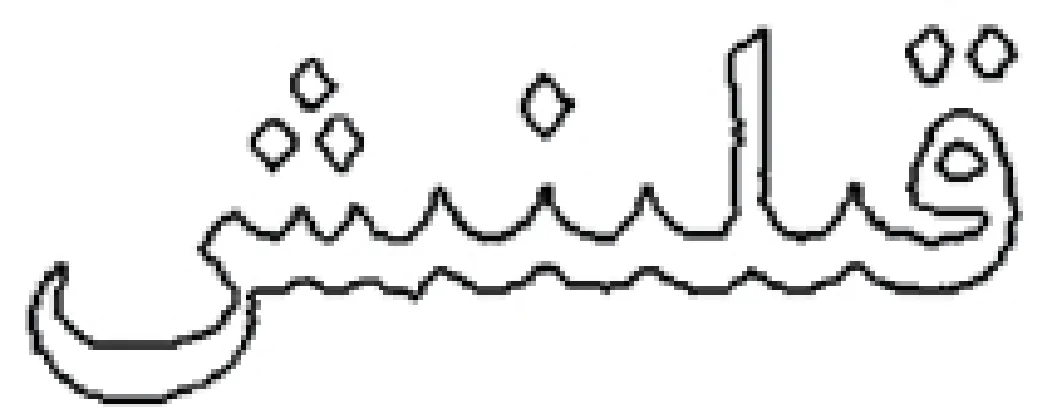
图7 单词的轮廓示意图
轮廓跟踪是对某一像素点根据某一跟踪原则确定下个像素点的过程.二值图像的轮廓跟踪大致步骤如下:
1)定义数组director[]用于存储相邻像素间的方位,数组可以取值:右,右上,上,左上,左,左下,下,右下;定义边界点存储数组edge[].
2)先行后列顺序扫描字符图像块,找到第一个值为0的点,它是最右上方的边界点,记为a.
3)以a为起始点,检查a的director[k]方向的下一个像素点的值,k=0,1,2,3,4,5,6,7.检查8个方向的像素值,如果有一个为255,则它是边界点,如果有多个255,则有多个边界点,并将该点存入边界数组edge[k]内,同时记录序号k按director[k]数组值的方向第一个从0到255的顺序,则director[k]方向的像素点将作为下一个搜寻的点.
4)如果搜索到点返回到a点,则结束该过程.
2 连体段特征提取
2.1 特征概述
鉴于维吾尔文的字符有很多的特征,例如轮廓、Freeman链码[9]、Hu矩、面积、周长等等,相应的就有特征向量用于存储这些特征.也有主特征和辅助特征,重点在于主特征的分析上,不同的特征对于不同的字符有不同的效果.有时候为了识别出字符的唯一性,不得不启用很多的特征,但是这样增加了计算量,也影响了速度.为此对于整个单词的识别我们要尽量少选一些特征,对连体段的特征进行分析整理,找出便于识别的最佳的特征组合.不同的特征之间的组合特征会有很多的差异,找出合适的组合就能有意想不到的效果,但是这个工作需要很多的尝试和测试.本文采用了连体段的轮廓作为主要的特征,再辅以其它的特征,对单词进行识别.
特征一般分为物理、结构、数学三种,也可以分为局部特征、全局特征和结构特征.不同特征适合不同的地方.对于连体段特征一般要求:具有较高的区分能力、高稳定性、高效率、高速度、计算量少等等.同时特征向量尽可能少,特征越多,计算量越复杂,往往在实际的应用差强人意,为此应该结合实际需求和程序可行性,找出高效的特征.
2.2 连体段特征提取
前面介绍连体段的划分,同时通过基线的直线拟合,求出该连体段的基线域,再找出该连体段的轮廓.基线中的孔记为内轮廓,基线域上的点或者其它形式的部分称为基线上的外轮廓,基线域下的点或者其它形式的部分称为基线下的外轮廓.对于每个连体段来说,都有自己的内轮廓和基线域上外轮廓以及基线域下外轮廓.对连体段中轮廓进行分析,包括基线域上的外轮廓个数、基线域中的内轮廓个数以及基线域下的外轮廓个数.本文利用字符串Sa1a2a3来保存连体段的轮廓特征,前面S表示一个连体段,后面的三个数字a1a2a3分别为:a1代表基线域上外轮廓数,a2代表内轮廓数,a3代表基线域下外轮廓数.图8所示连体段的轮廓特征为S235,基线域上外轮廓数a1为2,内轮廓数a2为3,基线域下外轮廓数a3为5.
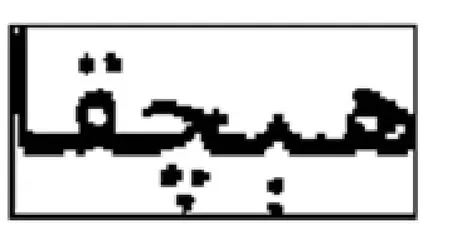
图8 连体段的轮廓特征为S235
2.3 特征组合
连体段的特征已经统计出来.单词的特征包含了每个组成它的连体段的特征、连体段的顺序及连体段的个数.如果有相同特征的不同单词,需要继续添加辅助特征加以区分,这属于二次识别的范畴.对于辅助特征,没有具体的范畴,对于短特征向量的不同单词来说,面积、长度、波峰等等都有可能区分开来,对于长特征向量不同单词来说,面积、长度等就起不到作用,所以辅助特征我们要根据具体的情况具体分析.图9展现了该单词的连体段和单词的切分图.

图9 单词和连体段对比图
它的主轮廓特征可以表示为S213S000S110S101.利用字符串来表示,一个变量就能表示很多轮廓特征,减少了特征向量的维度,同时也提高了识别的精度.该单词由四个连体段组成(维吾尔文读取的时候是从右到左,这和英文单词的读取方式刚好相反),四个连体段就应该用四个S字符串表示,每一个S代表一个连体段.从图中可以看出单词第一个连体段S213有两个基线上的外轮廓、一个基线中的内轮廓和三个基线下的外轮廓;第二个连体段S000有零个基线上的外轮廓、零个基线中的内轮廓和零个基线下的外轮廓;第三个连体段S110有一个基线上的外轮廓、一个基线中的内轮廓和零个基线下的外轮廓;第四个连体段S101有一个基线上的外轮廓、零个基线中的内轮廓和一个基线下的外轮廓,由此就组成了单词的主轮廓特征字符串S213S000S110S101.根据这个字符串特征向量要是不能唯一识别单词,就需要另外的额外辅助特征加以识别.这里展示部分单词特征如图10,前面的数字代表单词的序号,根据序号就直接可以定位单词,大大节省了空间和时间.
该图展示了一篇文章部分单词的轮廓特征.对其所有特征字符串进行排序就可以得到相同特征的单词是否是同一个单词,可以确定单词的唯一性,也就确定了识别该单词的准确率.

图10 部分单词轮廓特征统计
在统计完主轮廓特征后,开始识别,对其所有字符串进行排序,把字符串相同的放在一起,同时通过查询序号判断是否为同一单词,如果是同一单词,说明该特征能唯一识别该单词(当然需要多篇文章的证实,仅仅凭一两篇文章是没有说服力的);如果不是同一个单词的话,需要借助另外的辅助特征来进行二次识别.如图11所示,展示了同一特征对应相同的单词和同一特征对应不同的单词的情况.在一篇文章中141S210S000S000S000、151S210S000S000S000、171S210S000S000S000三个单词特征相同,单词也是同一个单词,识别就是成功的;80S100、107S100两个单词特征相同,但是单词不是同一个单词,识别失败,需要借助辅助特征进行二次识别,如图11所示.
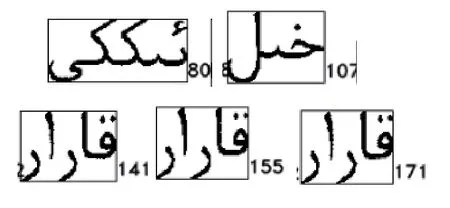
图11 相同特征对应的单词对比
3 实验结果及分析
一篇文章由单词和特殊字符组成,这里不考虑特殊字符,在识别的过程中先把它们排除掉,然后对文章进行统计.一般同一特征对应不管是同一单词还是不同单词,它们的比例在20%-30%之间,在这些单词中再选出同一特征对应的不同单词,这些单词的识别仅仅靠主轮廓的识别是不够的,要重新选取辅助特征进行二次识别,直到都能唯一的对应.同时在全篇文章中找出提取轮廓特征错误的单词,通过手工的进行更正.这样的单词特别少,产生的原因很多,没必要重新提取,重新提取也会影响其它单词的特征提取.对于这少部分尽量简单处理,不要影响大局.
对于识别不唯一的需要借助新的辅助特征的单词,进行二次识别,然后把这些特征向量和对应的单词放入匹配库中.每识别一篇文章,在得出唯一的特征向量以后,就把不同特征的单词和特征向量再次放入匹配库中.如果在匹配库中遇到相同特征的对应不同的单词,和在文章一样,继续借助辅助特征识别这些单词,直至唯一对应单词.随着匹配库的不断扩大,以后单词识别会越来越快,准确率也会越来越高.
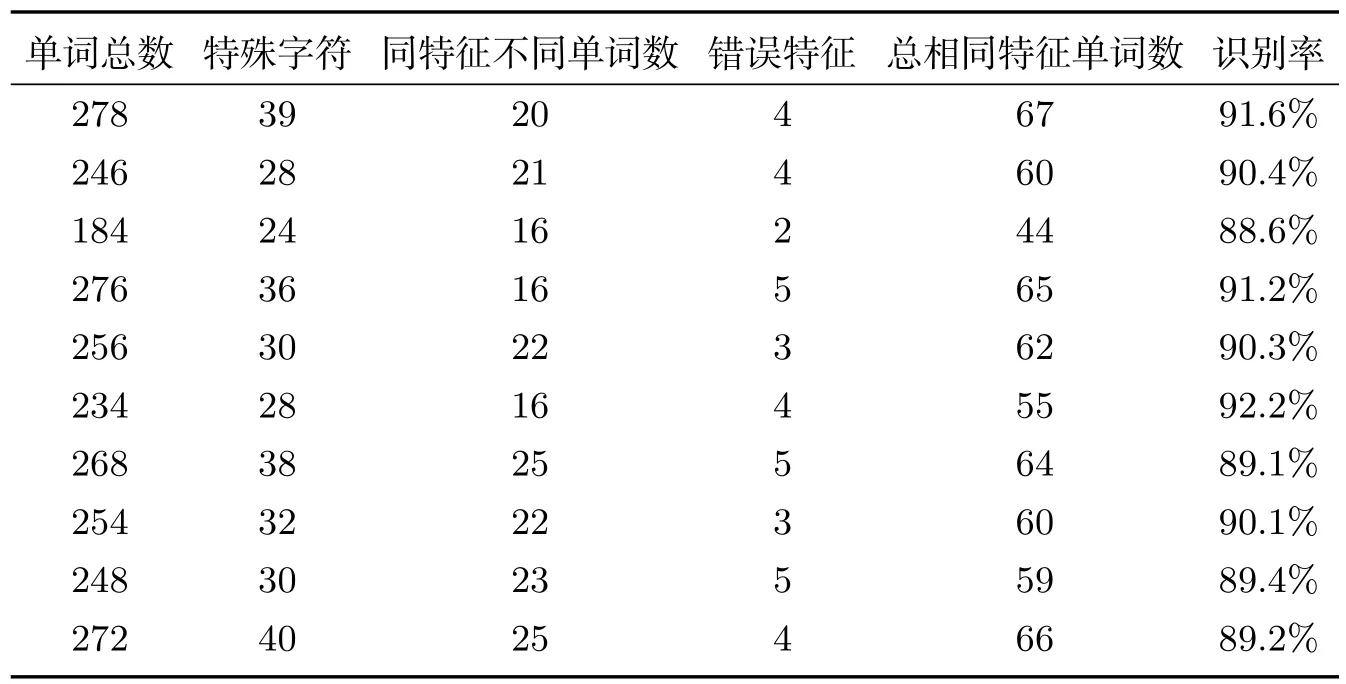
表1 十幅文档图像单词识别率
我们对二十篇文章做了基本的统计,得出了大部分日常生活中用到的单词的特征向量,在表1中列出了十篇文章的统计情况,每篇文章的识别率、错误率基本差不多,没有太大的差别.由此我们得出一个平均的单词识别率.以后想提高单词识别率,可以在此基础上进行改善.这个过程需要一个很大的硬盘存储空间.对于本系统来说,最大的难点就是如何有效的找出辅助特征,因为不同于单个字符有很多特征,通过归一化以后,很多特征都可以区分开字符,单词没办法归一化,并且针对整个单词的特征少之又少,所以辅助特征的选取是个难点.同时匹配库的管理也是一个难点,因为在识别一篇文章后,需要和整个匹配库进行对比,这在效率上就大打折扣,并且在遇到同一特征对应不同的单词时,也需要辅助特征的选取,随着匹配库的扩大,速度的处理会越来越慢,但是识别率会越来越高.
4 结论
本文提出了一种以连体段为基本单位的单词整体特征提取的方法,采取了低维度的轮廓特征作为主特征,对连体段的轮廓特征用字符串形式进行存储,整合之后成为单词的轮廓特征,用以在识别过程中作为主要的识别特征,对于不能进行识别的单词借助辅助特征进行二次识别.经过实验测试,本系统识别率约为90%.本研究为以后维吾尔文单词识别研究特供了一个新的思路,可以在此基础上进行改善,进一步提高提取特征的唯一性和单词的识别率.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
装备制造技术(2020年1期)2020-12-25
制造技术与机床(2019年11期)2019-12-04
电子制作(2019年15期)2019-08-27
数学大世界(2019年7期)2019-05-28
电子制作(2018年19期)2018-11-14
中华建设(2017年1期)2017-06-07
中国交通信息化(2017年4期)2017-06-06
自动化学报(2017年11期)2017-04-04
