
文本挖掘和聚类技术在信息服务事件智能分析的应用研究
2015-10-19 13:49:18梁浩波林浩钊封祐钧
电脑知识与技术 2015年20期
梁浩波 林浩钊 封祐钧
摘要:文本挖掘和聚类分析是数据挖掘的重要内容之一,其应用十分广泛。本文首先对文本挖掘技术和聚类分析的基本概念进行系统地归纳总结,然后将文本挖掘和聚类分析技术应用于信息服务事件的智能分析中,实现信息服务客户群的细分以及信息系统热点问题发现,从而大大提升信息服务水平。
关键词:文本挖掘;聚类分析;信息服务;客户细分
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2015)20-0143-02
ITSM(IT服务管理),它是一套面向过程、以客户为中心的规范的管理方法,它通过集成IT服务和业务,协助企业提高其IT服务提供和支持能力,而ITSM服务管理系统则是ITSM方法论的系统实现,具有变更管理、配置管理、请求管理、事件管理、知识管理等功能模块。
ITSM服务管理系统中的事件管理模块中详细记录了信息服务人员与企业员工问题事件交互的信息,其中包括事件报告人、事件报告人部门、事件分类、事件描述等。但由于这些信息服务事件信息一般以文本方式存放,传统的数据分析的工具和软件无法对其内容进行分析,导致长期以来信息服务事件描述所蕴含的价值无法得以利用。本文综合利用文本挖掘和聚类分析技术,实现信息服务事件的智能分析,以实现信息服务水平的提升。
1 文本挖掘技术概述
文本挖掘又称为文本数据挖掘或文本知识发现,是指为了发现知识,从文本数据中抽取隐含的、以前未知的、潜在有用的模式的过程,它是个分析文本数据,抽取文本信息,进而发现文本知识的过程。
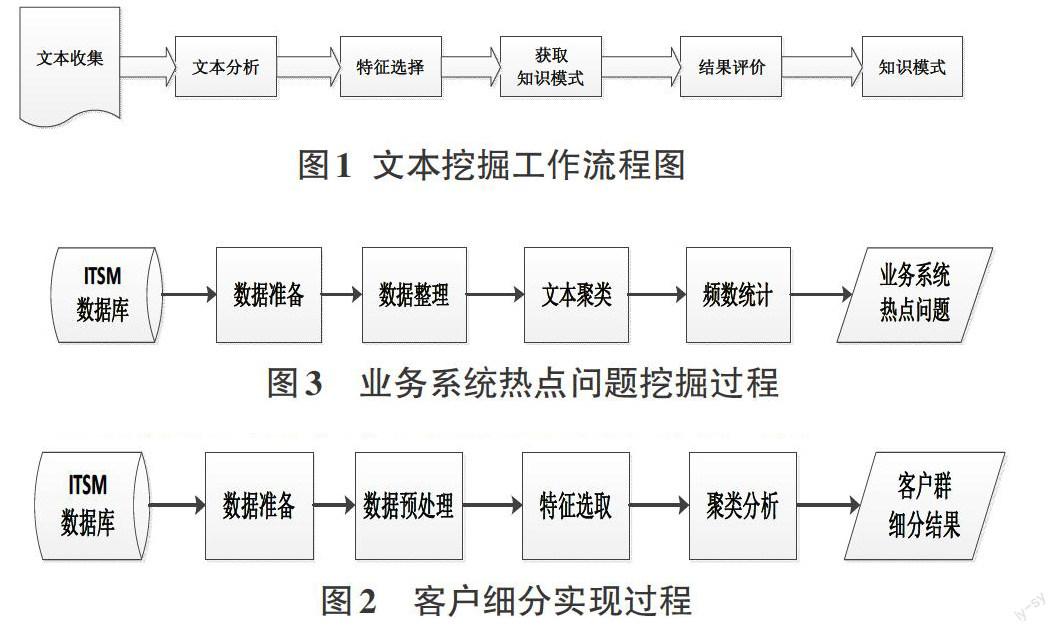
文本挖掘的具体流程如图1所示:
1)文本收集:在文本挖掘前应尽可能寻找和检索所有被认为可能与当前挖掘工作有关的文本。
2)文本分析:由于文本不仅是非结构化或半结构的,而且文本的内容是人类所使用的自然语言,所以文本如果不经过特别加工,数据挖掘技术无法直接应用于其上。文本分析首先要提取文本的特征,然后再结构化表示这些特征。
3)特征选择:经过文本分析得到的特征有必要进行特征选择, 以降低特征的维数。通过特征选择, 就可以得到代表文档集合的有效的、精简的特征子集, 并在此基础上开展各种文档挖掘工作。
4)获取知识模式:该阶段的目标是应用有效的文本挖掘算法挖掘出一些有用的知识模式。这些知识模式主要包括: 文本总结、文本分类、聚类分析、关联规则、趋势预测等。
5)结果评价:对文本挖掘算法发现的知识模式进行评估。比较常用的评估方法有准确率( Precision) 、召回率( Recall) 等。
图1 文本挖掘工作流程图
2 聚类分析技术概述
聚类就是对物理对象或抽象对象进行分组的过程,所生成的组称为簇,簇是数据对象的集合。簇内部任意对象之间应该具有较高的相似度,而属于不同簇的两个对象之间应该具有较高的相异度。
一般而言,主要的基本聚类算法可以划分为如下几类:
1)基于划分方法的聚类:给定一个n个对象的集合,划分方法构建数据的k个分区,其中每个分区表示一个簇,并且k<=n。也就是说,它把数据划分为k个组,使得每个组至少包含一个对象。大部分划分方法是基于距离的。
2)基于层次方法的聚类:层次方法创建给定数据对象集的层次分解。根据层次分解如何形成,层次方法可以分为凝聚的或分裂的方法。
3)基于密度方法的聚类:其主要思想是只要“邻域”中的密度(对象或数据点的数目)超过某个阈值,就继续增长给定的簇。这样的方法可以用来过滤噪声或离群点,发现任意形状的簇。
4)基于网格方法的聚类:把对象空间量化为有限个单元,形成一个网络结构,所有的聚类操作都在这个网格结构(即量化空间)上进行。
3 信息服务事件智能分析应用
ITSM信息服务系统详细记录了信息服务人员与企业员工问题事件交互的详细信息,其中包括事件报告人、事件报告人部门、事件分类、事件描述等。为挖掘信息服务事件所蕴含的价值,一方面通过聚类分析实现信息服务客户群细分,获取各客户群的信息服务需求特征,有助于为各客户群提供个性化信息服务;另一方面,获取各主营业务系统热点问题,可作为日后业务系统培训的重点内容,使系统培训更具有针对性。
3.1 聚类分析实现信息服务客户群细分
实现思路:以各部门对各主营业务系统的信息服务报障数作为客户细分的重要指标,利用聚类分析技术以部门为对象进行客户群划分。
客户细分实现过程如图2所示:
1)数据准备:从ITSM服务管理系统中导出某指定时间段的ITSM事件单;包括事件ID、事件报告人、事件报告部门、事件性质、事件类别等字段信息。
2)数据预处理:采用数据清理、数据归约、数据变换等多种数据预处理技术,解决现实数据中存在不完整的、不正确的或含噪声的、不一致的问题,提高数据质量。
3)特征选取:按照事件类别,以部门为单位,汇总统计出各部门各业务系统的报障数,用于标识各部门的特征。
4)聚类分析:将每个部门单位看作是一个独立的对象,该部门单位各业务系统报障数看作是该对象的属性值,各对象的相异度则根据描述对象的属性值进行计算。在本实验中,采用k-means聚类算法(相异度采用的度量指标是对象间的距离),根据各部门单位的业务系统报障数的特点,进行信息服务客户群的细分,得到客户群细分结果。
模型应用前景:通过聚类;分析对信息服务群进行细分,同一客户群的部门单位具有相似的信息服务需求特征,有助于日后为各客户群提供个性化信息服务,提升客户体验。
图2 客户细分实现过程
3.2 文本挖掘归纳业务系统最热点问题
实现思路:ITSM中有关业务系统咨询问题是以文本方式存放,而中文语句无法用一般统计软件进行简单的数量统计。本文基于中文文本挖掘技术,实现对业务系统咨询问题的自动分类(简称“文本聚类”)。根据聚类后的结果,统计各类事件的出现频数,从而得到各业务系统的热点问题。
业务系统热点问题挖掘实现过程如图3所示:
1)数据准备:从ITSM服务管理系统中导出某指定时间段的ITSM事件单;包括事件ID、事件报告人、事件报告部门、事件性质、事件类别等字段信息。
2)数据整理:根据事件类别字段,将涉及某一指定业务系统的所有事件的描述信息汇总,得到一个文本文件。
3)文本聚类:首先采用IK Analyzer工具包对文本文件进行中文分词,并通过词频统计提取出关键词。然后将提取的关键词作为事件描述的聚类特征,并给每个事件添加“类标签”。
4)频数统计:根据事件的“类标签”进行事件频数统计,并根据业务知识得到各业务系统热点问题。
模型应用前景:通过文本挖掘技术得到各主营业务系统热点问题,可作为日后业务系统培训的重点内容,使系统培训更具针对性,提高系统培训效果。
图3 业务系统热点问题挖掘过程
4 结语
通过文本挖掘和聚类分析等数据挖掘技术,一方面对信息服务群进行细分,获取各客户群的信息服务需求特征,有助于为各客户群提供个性化信息服务;另一方面获取各主营业务系统热点问题,可作为日后主营业务系统培训的重点内容,使系统培训更具有针对性,并提高系统培训效果。上述两个措施,能有效地帮助信息服务人员了解用户对信息服务更深层次、更真实的需求,有助于提升信息服务人员服务能力,进一步提高信息服务质量。
参考文献:
[1] 谌志群, 张国煊. 文本挖掘研究进展[J]. 模式识别与人工智能, 2005,18(1):66-74.
[2] 程志, 黄荣怀. 文本挖掘及其教育应用[J]. 现代远距离教育, 2008(2):71-73.
[3] 谌志群, 张国煊. 文本挖掘与中文文本挖掘模型研究[J]. 情报科学, 2007, 25(7):1047-1051.
[4] 唐守忠. 文本挖掘关键技术研究[D]. 北京: 北京林业大学, 2013.
[5] Feldman R,Hirsh H,Dagan I. Mining Text Using Keyword Distributions[J]. Journal of Intelligent Information Systems, 1998, 10(3): 281-300.
猜你喜欢
软件导刊(2016年12期)2017-01-21 15:55:21
电子技术与软件工程(2016年22期)2016-12-26 20:29:58
中国远程教育(2016年9期)2016-11-19 12:26:00
大经贸(2016年9期)2016-11-16 16:16:46
新世纪图书馆(2016年9期)2016-11-15 02:09:52
价值工程(2016年29期)2016-11-14 02:28:03
科技视界(2016年18期)2016-11-03 22:02:50
中国市场(2016年33期)2016-10-18 12:16:58
科技视界(2016年21期)2016-10-17 19:25:20
科技视界(2016年20期)2016-09-29 12:32:48
