
面向多线程应用的片上多核处理器私有LLC优化
2015-06-27 08:26:03吴建宇彭蔓蔓
计算机工程 2015年1期
吴建宇,彭蔓蔓
(湖南大学信息科学与工程学院,长沙410082)
面向多线程应用的片上多核处理器私有LLC优化
吴建宇,彭蔓蔓
(湖南大学信息科学与工程学院,长沙410082)
片上多核处理器已逐渐取代传统超标量处理器成为集成电路设计的主流结构,但芯片的存储墙问题依旧是设计的一个难题。CMP通过大容量的末级高速缓存来缓解访存压力。在软件编程模式向多线程并行方式转变的背景下,针对多线程应用在多核处理器上的Cache访问特征,提出一种面向私有末级Cache的优化算法,通过硬件缓冲器记录处理器访存地址,从而实现共享数据在Cache间的传递机制,有效降低Cache失效开销。实验结果表明,在硬件开销不超过Cache部件0.1%的情况下,测试用例平均加速比为1.13。
片上多核处理器;存储墙;末级Cache;失效开销;缓冲器
1 概述
随着集成电路工艺的不断发展,晶体管的尺寸越来越小,传统处理器以提高频率、增加流水线深度和增加功能部件的方式来提高性能将无法持续,片上多核处理器以功耗效率高、复杂度更低和高性价比等优势,成为学术或工业界的主流处理器体系结构[1-2]。当芯片上集成的处理器核心增多,处理器对存储器访问速度、带宽的要求随之变高,但受主存访问周期长和片外引脚数目受限等因素的影响,存储墙问题日趋严重。为了有效缓解处理器片外访存的压力,当代处理器设计已经将一半以上的片上晶体管资源用于最后一级高速缓存,Intel Xeon E5-2600[2]处理器仅末级Cache(Last Level Cache,LLC)容量就高达20 MB。
另一方面,软件开发技术也在发生巨大改变,以往的并行技术只是应用于少数的科学计算、大数据处理等专业应用领域。随着芯片内集成处理器核数目的飞速发展,计算机编程模型正在由传统串行编程向并行编程转变,如任务并行编程模型[3-5]以开发难度低、执行效率高等优点受到广泛研究和应用。
本文基于LLC为私有架构,针对并行多线程应用的访存特点,提出一种缩短Cache失效开销的MAOPL (Multi-threaded Applications-oriented Approach toOptimize Private LLC)算法,其基本思想是在多线程应用程序运行时,如果一个线程需要对共享数据进行访问,则将相邻处理器私有Cache体存储的有效数据通过总线调入数据请求处理器的本地Cache,从而降低Cache失效后的开销。
2 研究背景
2.1 CMP存储结构
目前,多核处理器Cache通常具有多级结构(通常为2级至3级),从L1 Cache到LLC结构越来越复杂、速度越来越慢、容量越来越大。绝大多数的L1 Cache是私有的,但LLC存在共享和私有2种基本方式。在共享设计中,LLC统一编址,供所有处理器使用,因此,空间利用率高,但速度受到最大线延迟影响,访问周期长。在私有设计中,LLC被分成相互独立的Cache块,放置在各自处理器附近,供处理器单独使用。在本文中称各自处理器私有的LLC为本地Cache体,否则称为相邻Cache体。所有私有LLC通过一条高速总线进行通信。因为私有LLC设计简单,所以具有较快的访问速度。但当运行的程序集较大时,私有设计可能引发失效率增加。片上多核处理器LLC的优化技术实质上就是汲取2种不同设计的优点,减少各自的不足。
2.2 相关工作
私有LLC由于结构相对简单,可以与处理器更紧密结合,相对共享方式,具有访问延迟小、性能隔离等优势,但私有LLC只能被各个处理器核单独使用,无法根据应用动态调整,私有LLC结构空间利用率相对较低。有研究表明,对大多数应用而言,私有LLC设计具有更高的性价比[6]。
为了提高空间利用率,文献[7]提出了合作式Cache(Cooperative Cache,CC)算法,通过增加一个一致性引擎(CCE)将各私有Cache连接,聚合成一个逻辑上的共享体,将本地Cache体中替换出来的块以一定的概率放入相邻Cache体中,称为溢出(spilling),当再次访问该块时可以直接访问,从而降低了Cache的失效率。但CC算法只是简单地以概率控制溢出流向[8],没有考虑应用的行为特征,实际上合作机制效率取决于应用的Cache行为特征。文献[8]提出了一种动态溢出(Dynamic Spill Receive, DSR)算法,通过感知上层应用的效能来决定牺牲块溢出的流向。文献[9]认为DSR算法是以单个应用为单位来划分效能,粗粒度划分不适用于低层次溢出流向控制,进一步提出了面向 Cache组层次的SNUG(Set-level Non-Uniformity identifier and Grouper)算法,针对Cache组不同的容量要求,实现牺牲块在Cache组间的溢出机制。
文献[10]考虑了处理器负载均衡和牺牲块的可重用性问题,通过Cache总线将重用性高的牺牲块保存至同层的其他私有LLC中,提高了Cache命中率。文献[11]提出了基于应用行为识别(BICS)的私有LLC溢出技术,该技术可以在线确定应用的Cache访问特性,从而决策是否将牺牲块溢出至同层的其他私有Cache体。
已有工作的重点在于私有LLC的合作或是多道单线程应用的Cache行为研究,本文是针对多线程应用在私有LLC上的行为特点,通过降低Cache失效开销,实现私有LLC优化机制。
2.3 多线程应用访存分析
目前并行程序开发常用的方法是调用系统函数(pthread)启动多线程或利用并行编程语言(MPI, OpenMP,TBB[5],CILK++[4])。不同编程语言面向的环境各不相同,下面分别使用 Pthread和OpenMP环境下实现矩阵相乘算法来分析多线程应用的访存特征。原始串行实现部分代码如下,本文将共享数据定义为2个或以上线程对同一地址块进行读写操作。
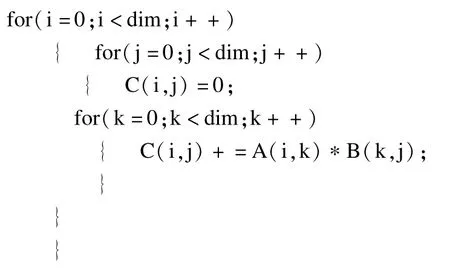
OpenMP是面向共享内存的多处理器并行编程语言,适用于划分力度较小的并行开发,主要通过编译指导语言来指导并行化,代码如下所示。# program omp parallel for shared为编译指导语句,通过该语句指导编译器实现for循环的并行化,shared (A,B,C)表示A,B,C数组为子线程共享数据。

Pthread是由POSIX提出的一套通用线程库,通常的执行模式采用Fork-Join形式。在开始执行的时候,只有一个主线程存在,主线程在运行过程中,如果碰到需要并行计算的时候,派生出子线程执行并行任务,在并行代码结束执行后,派生线程退出,并将执行结果传递给主线程。代码如下所示,pthread_creat(),pthread_join()函数分别用于创建和合并函数,func指针函数用于给每个子线程分配任务。数组matrixA,matrix,matrixC作为共享数据划分给子线程使用。

由上文的分析可知,在多线程应用中存在共享数据用于线程间的通信、同步等操作。图1选取了PARSEC[12]测试集中部分程序的共享数据分布图,图中B16~B128分别表示Cache行Block为16 Byte~128 Byte大小。从图可知,bodytrack,x264等程序中共享数据的比例高达50%。

图1 PARSEC部分用例共享数据分布
3 MAOPL算法
在并行应用中,共享数据块被多个进程进行读写操作。基于Cache的工作机制,当任意一个处理器在读写共享数据发生Cache失效时,会向下一级存储器请求缺失数据,每个私有Cache会在本地存储一份共享数据的拷贝。由于主存与Cache的访问开销不在一个数量级,往往LLC失效后需要上百个时钟周期从主存读取数据。因此MAOPL算法采用缓冲器的形式,记录近期处理器访问的地址。当某个处理器访问共享数据,但本地Cache体发生失效时,可以在缓存器中查找该数据所在处理器的ID,通过总线将共享数据调入本地Cache体,实现Cache间共享数据传输,极大地减少了失效开销。
3.1 MESI一致性协议
当系统中有多个处理器时,同一份内存可能会被拷贝到多个处理器的本地缓存中。为了防止多个拷贝之间的不一致,必须维护多个缓存的一致性。MESI是一种被广泛采用的缓存一致性协议,MESI协议为每个Cache行维护2个状态位,使得每个Cache行处于4个状态(M,E,S,I)之一,各个状态的含义如下:
(1)M:被修改的。处于这一状态的数据只在本CPU中有缓存,且其数据已被修改,没有更新到内存中。
(2)E:独占的。处于这一状态的数据只在本CPU中有缓存,且其数据没有被修改,与内存一致。
(3)S:共享的。处于这一状态的数据在多个CPU中有缓存。
(4)I:无效的。本CPU中的这份缓存已经无效了。
处理器对Cache进行读写操作时,会触发总线事务(BusRd:总线读,BusRdx:总线写)广播给其他处理器。处理器对总线进行侦听,在需要时进行相应Cache行的状态转化。图2为MESI协议状态转换图,例如当CORE0和CORE1分别保存A地址数据时,当CORE0对A地址数据进行修改后,会引起总线事务BusRdX A,CORE1本地Cache将Tag值为 A的 Cache行的状态由共享态变成无效态。

图2 MESI协议状态转换
3.2 MAOPL总体结构
为了记录处理器近期的访问地址,本文设计了一个N组的缓冲器(Buffer),与总线相连并实时侦听总线事务。如当CORE0读取A地址数据时,引起总线事务BusRd A,缓冲器侦听到该事件后,分别将数据地址A、处理器ID存入缓冲器中;如果是对A地址数据进行写,那么在侦听到BusRdx A后,将最新数据所在处理器ID存入地址项为A的缓冲器中。缓冲器采用Cache中LRU替换算法对N组数据进行插入、提升和替换选择等操作。在查找缓冲器项时,采用硬件并行的查找方式。以4核CMP结构为例,图3表示算法的硬件拓扑结构,表1为缓冲器中每一项所包含的数据。

图3 算法总体结构

表1 缓冲器长度参数说明
3.3 算法处理步骤
MAOPL算法的基本思想是每当发生本地Cache体失效时,尽量从速度更快的相邻Cache体中调入数据,而不是访问下一级存储器。图4为MAOPL算法流程。

图4 MAOPL算法流程
处理器访问LLC,如果命中则返回请求数据;否则,LLC失效后,处理器按照访问地址首先在缓冲器中查找是否存在该地址项,如果缓冲器命中,命中项PID值(假设为CORE0)指示最新数据所在的处理器。本文引入文献[7]中提出的Cache总线数据传输机制,将CORE0中相应数据调入本地Cache,并将数据返回给处理器;如缓冲器失效,则从下一级存储器调入数据到本地Cache,并返回给处理器。
下面以处理器COREj对A数据写命中后引发COREi读A数据失效的处理过程为例,进一步阐述该算法思想,其余情况处理过程类似。图5为算法步骤示意图,步骤中省略了缓冲器硬件并行查找、Cache总线的数据传输等细节。

图5 算法步骤示意图
算法各模块说明如下:
(1)Write to A:处理器COREj对A地址数据进行写操作。
(2)BusRdx A:为了保持数据一致性,MESI协议引发总线BusRdx事件,使其他保存 A数据的Cache行状态转为无效态。同时,在本文中,在缓冲器中建立相应信息。
(3)Read miss A:处理器COREi对A地址数据进行读操作,因为A被COREj修改,导致Cache读失效。
(4)Detect hit A:当Cache失效时,先在缓冲器中查询是否存在A的信息。
(5)Transport A:缓冲器命中后,根据PID值及数据的物理地址A,可在相应的Cache块中迅速找到数据,并传入本地Cache中。
4 实验平台及结果
4.1 实验平台及方法
本文所提出的算法是基于片上多核体系,末级Cache为私有结构。实验采用MARSS[13]模拟器,测试集程序为PARSEC,操作系统为Linux 2.6内核,通过仿真平台上的运行时间来测试算法性能。MAOPL算法中缓冲器硬件及数据访问流程通过修改模拟器的存储部分实现。MARSS是由SUNY大学开发的一款基于X86体系结构的全系统多核精确模拟器,由ptlsim和qemu 2个仿真器耦合而成,可以运行不经修改的操作系统。表2为模拟器具体的参数配置。

表2 处理器配置
PARSEC(The Princeton Application Repository for Shared-Memory Computers)由普林斯顿大学2008年开发,是一个多线程应用程序组成的测试程序集,代表了未来运行在片上多核系统中的共享内存应用程序的发展趋势,主要包括视频编码技术、金融分析和图像处理等应用程序。本文从PARSEC测试集中选取了blackschole,bodytrack,dedup,ferret, freqmine,swaptions,vips,x264等8个测试用例,程序运算规模采用输入中等(simmedium)数据包。
4.2 实验结果
在实验中,基于对缓冲器硬件性能的估计,将Cache失效后访问缓冲器查找时间设置为10个时钟周期,相邻Cache体传输数据到私有Cache体的时间为20个时钟周期,即从缓冲器中查找到完成Cache间数据传输总开销时间为30个时钟周期,缓冲器组间替换策略采用LRU替换算法。考虑到测试程序工作集大小、并发线程数目等多种因素,通过实验发现,缓冲器数目N取256~512较为适中。实验中,在缓冲器上设置了访问和命中计数器,图6为缓冲器的命中概率百分比。

图6 缓冲器命中率分布
在测试程序运行完后,取原运行时间与本次运行时间比值为算法的加速比,图7为不同条件下相对于未修改前的加速比。

图7 测试用例性能加速比
4.3 实验分析
4.3.1 算法性能分析及硬件开销
有如下公式:

在式(1)中,Ttotal表示每条指令平均执行时间;Tclock表示CPU的时钟周期;Tmem表示访问存储器周期;CPI为平均每条指令执行的周期数。在式(2)中,TL1,TL2分别表示第1级和第2级Cache的命中时间;HL1,HL2分别表示第1级和第2级Cache的命中率;TL2miss表示二级Cache的失效开销。假设主存平均访问时间为200个周期,不考虑地址转换等其他因素,那么TL2miss为200个周期。在本文中引入缓冲器,当L2发生miss时,先查找缓冲器,若缓冲器命中,则从相应的附近Cache读入数据,否则从主存中读取数据。缓冲器命中总开销TBufferHit为30周期;而缓冲器失效开销TBufferMiss为缓冲器查找时间与访主存时间之和,即210个周期。

若命中率Hpredict为50%,则二级Cache失效开销由式(3)可知,TL2miss为120,与原始相比,可以较大地减少访存时间。
令处理器核数为P个,主存地址为A位,每一个Cache块大小为B,则缓冲表中每一项大小M=lbP+A+1-lbB,缓冲表硬件总开销为M×N。设处理器数目P为8,地址为A为32 bit,Cache块大小B为64 Byte,当缓冲器组数N为256或512,缓冲器硬件开销分别为960 B和1 920 B,若私有Cache为2 MB大小,则缓冲器硬件开销比例分别占整个私有
Private LLC Optimization of Chip Multi-processors Oriented to Multi-threaded Application
WU Jianyu,PENG Manman
(College of Information Science and Engineering,Hunan University,Changsha 410082,China)
The design of processors changes from traditional superscalar ones to Chip Multi-processors(CMP).CMP becomes the mainstream of computer architecture.But the memory wall problem is still one of the design challenges.With the help of large volume last level Cache,CMP succeeds to relieve memory pressure.The pattern of software programming changes toward the parallel mode.This paper presents an algorithm about Last Level Cache(LLC)optimization on CMP, based on characteristic of Cache access.By the use of the hardware buffer recording processors’access address,the algorithm enables the transfer mechanism of shared data between Caches,and reduces Cache miss penalty effectively. Experimental results show that,average speedup of test is 1.13 when the cost of hardware is less than 0.1%of Cache.
Chip Multi-processors(CMP);memory wall;Last Level Cache(LLC);failure overhead;buffer
1000-3428(2015)01-0316-06
A
TP303
10.3969/j.issn.1000-3428.2015.01.059
国家自然科学基金资助项目(61173037)。
吴建宇(1987-),男,硕士研究生,主研方向:计算机体系结构;彭蔓蔓,教授、博士生导师。
2013-12-23
2014-02-17 E-mail:jianyu_wu@yeah.net
中文引用格式:吴建宇,彭蔓蔓.面向多线程应用的片上多核处理器私有LLC优化[J].计算机工程,2015,41(1): 316-321.
英文引用格式:Wu Jianyu,Peng Manman.Private LLC Optimization of Chip Multi-processors Oriented to Multi-threaded Application[J].Computer Engineering,2015,41(1):316-321.
猜你喜欢
轻兵器(2022年3期)2022-03-21 08:37:28
铁道车辆(2021年4期)2021-08-30 02:07:14
测控技术(2018年6期)2018-11-25 09:50:12
测控技术(2018年8期)2018-11-25 07:42:08
环球市场(2017年36期)2017-03-09 15:48:21
电子设计工程(2015年8期)2015-02-27 12:05:26
河南科技(2014年16期)2014-02-27 14:13:22
电子设计工程(2014年19期)2014-02-27 12:00:54
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
——以冶金企业为例
河南科技(2011年8期)2011-10-26 07:12:30
