
基于CEEMDAN-排列熵和泄漏积分ESN的中期电力负荷预测研究
2015-06-27 05:50李军李青
电机与控制学报 2015年8期
李军, 李青
(兰州交通大学自动化与电气工程学院,甘肃兰州730070)
基于CEEMDAN-排列熵和泄漏积分ESN的中期电力负荷预测研究
李军, 李青
(兰州交通大学自动化与电气工程学院,甘肃兰州730070)
针对中期电力负荷预测,提出一种具有自适应噪声的完整集成经验模态分解(CEEMDAN) -排列熵和泄漏积分回声状态网络(LIESN)的组合预测方法。CEEMDAN方法在负荷序列分解的每一阶段添加特定的白噪声,通过计算唯一的余量信号以获取各个模态分量,与EEMD方法相比,其分解过程是完整的。为降低负荷非平稳性对预测精确度的影响以及减小计算规模,采用CEEMDAN-排列熵方法将负荷时间序列分解为具有复杂度差异的不同子序列,通过分析各个子序列的内在特性,分别构建相应的LIESN预测模型,最终对预测结果进行叠加。将该方法应用于不同地区的中期峰值电力负荷预测实例中,并与其他组合预测以及单一预测方法进行比较。实验结果表明,所提出的方法有很高的预测精确度,显示出其有效性和应用潜力。
负荷预测;组合模型;集成经验模态分解;回声状态网络;排列熵
0 引 言
负荷预测一直是电力系统调度和发展规划中必不可少的部分,其通常受到温度、季节、经济等因素的影响,这使得做出精确的预测往往变得很困难,在未来统一的智能电网的环境下,构建适应性更强的电力负荷中长期预测模型[1,2],对智能电网的发展规划和运行调度具有重要意义。
由于电力负荷值是受众多因素影响的非平稳时间序列,对负荷变化特性的先验分析有助于提高负荷预测的精确度。经验模态分解(Empirical Mode Decomposition,EMD)是近年来由Huang[3]提出的一种处理非线性和非平稳信号的分解方法,相对于小波分析等其它信号处理方法而言,该方法不需要事前设定基函数,克服了依赖于主观经验影响的缺点,但其分解过程中易出现模态混叠现象,影响分解效果。集成经验模态分解(EEMD)[4],通过添加辅助噪声来消除EMD出现的模态混叠现象,通过多次实验,抵消和抑制分解结果中噪声所产生的影响,是对EMD方法的改进,然而,在有限次实验的集成平均后,其重构分量中仍然含有一定幅值的残留噪声,虽然可以通过增大集成次数来降低重构误差,但却增加了计算规模。在EEMD的基础上,一种具有自适应白噪声的完整集成经验模态分解方法[5](Complete Ensemble Empirical Mode Decomposition with adaptive noise,CEEMDAN)被提出,它在分解的每一阶段添加自适应的白噪声,通过计算唯一的余量信号获取各个模态分量,与EEMD方法相比,无论集成次数为多少,重构误差几乎为零,其分解过程具有完整性,克服了EEMD分解效率低的问题。EMD与支持向量机(SVM)结合以及EEMD与动态神经网络结合的组合预测方法[6-7]已应用于短期电力负荷预测中。EMD与SVM的组合预测方法[8]已应用于风电功率预测中,与单一预测方法相比,上述方法均取得了不错的预测效果。
回声状态网络(ESN)由Jaeger[9]提出,其优点是网络的隐含层由几百到几千个大量稀疏连接的内部神经元组成,称为状态储备池(state reservoir, SR),SR使ESN具有极强的短期记忆能力。SR的权值在网络初始化时随机产生且无需训练,仅需训练与输出层连接的网络权值。因此,即使是对具有数千个内部神经元的大规模网络,也易实现在线学习。ESN方法目前已成功应用于短期负荷预测中[10]。作为ESN的延伸和推广,泄漏积分ESN[11-12]((leaky integrator echo state network, LiESN)通过泄漏率和时间常数的调节能实现对慢特性和连续动态系统的学习,它是一种学习能力更强的动态递归神经网络。
鉴于CEEMDAN与LiESN各自的优点,提出一种CEEMDAN-排列熵与LiESN相结合的组合预测方法。首先利用CEEMDAN将非平稳的负荷时间序列分解为一系列具有不同特征尺度的本征模态信号(intrinsic mode function,IMF)。其次,考虑到排列熵算法[13]能够有效放大时间序列的微弱变化,对时间序列的变化具有很高的敏感性,还具有算法简单、计算效率高等优点,可利用排列熵对各IMF分量进行复杂度分析,根据熵值的不同将熵值相近的IMF进行组合叠加,以降低对各IMF分量分别进行预测的计算规模。最后,利用LIESN对合并后的各子序列分别进行预测,并进行叠加,以得到最终的预测结果。将所提出的组合预测方法分别用于不同地区的中期峰值负荷预测实例中,在同等条件下,还将与现有的组合与单一预测方法进行比较,以验证本文方法的有效性。
1 EEMD和CEEMDAN方法
EMD是一种分析非线性和非平稳信号的自适应信号分解方法,类似于小波分析,但克服了小波分解需要合理选择小波基函数的困难,其本质是将原始信号按不同波动的尺度依次分解,得到一系列具有不同幅值的本征模态分量(intrinsic mode function,IMF)。EMD方法中的IMF必须满足:1)极值点个数和过零点的数目必须相等或至多相差一个; 2)由局部最大值点构成的上包络线和局部最小值点构成的下包络线得到的均值处处为0。
1.1 EEMD方法
作为一种噪声辅助数据分析方法,EEMD通过往原信号中多次添加不同的白噪声,分别进行EMD分解,然后对多次EMD分解的IMF进行平均而得到最终的实际分量,它能有效地改善EMD方法所存在的模态混叠现象,多次集成平均也起到抵消白噪声影响的作用。
EEMD算法的实现如下:
1)令s(n)表示原始信号序列,vi(n)代表第i次实验中添加的具有标准正态分布的白噪声序列。第i次的信号序列表示为si(n)=s(n)+vi(n),其中i=1,…,I表示实验次数。
2)将每一次实验产生的信号序列si(n)进行EMD分解,得到IMFik(n),其中k=1,…,K表示分解的IMF模态个数。
3)定义s(n)的第k个模态分量为IMFk,相应的对IMFik进行平均得到
1.2 CEEMDAN方法
EEMD所添加的白噪声序列通过有限次平均后,并未完全抵消,重构误差的大小依赖于集成的次数,虽然随着平均次数的增多可以逐渐减小,但很大程度上又增加了计算耗时。CEEMDAN方法通过在每个阶段添加有限次的自适应白噪声,能实现在较少的平均次数下,其重构误差几乎为0。因此,CEEMDAN可以克服EMD所存在的模态混叠现象,同时解决了EEMD分解的不完整性以及依靠增大集成次数来降低重构误差而导致的计算效率低的问题。
在EEMD分解中,包含不同白噪声的si(n)在每一次实验中均进行不同的IMF分解。因此,每一次分解产生的余量信号均不同,即
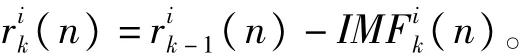
在EEMD的基础上,CEEMDAN通过添加自适应的白噪声以及计算唯一的余量信号获取IMF,以克服EEMD的不足,使得重构信号后与原信号几乎完全相同。
定义算子Ek(·)为通过EMD方法所产生的第k个模态分量,CEEMDAN所产生第k个模态分量记为IMF~k,CEEMDAN具体的算法实现如下:
1)与EEMD分解方法相同,CEEMDAN针对信号s(n)+ε0vi(n)进行I次实验,通过EMD方法分解以获取第一个模态分量,计算
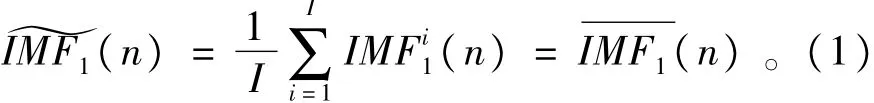
2)在第一阶段(k=1),计算第一个唯一的余量信号,即计算r1(n)=s(n)-IMF~1(n)。
3)进行i次实验(i=1,…,I),每次实验中,对信号r1(n)+ε1E1(vi(n))进行分解,直到得到第一个EMD模态分量为止。在此基础上,计算第二个模态分量如下
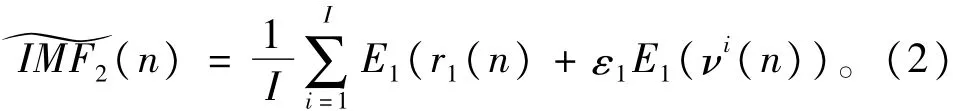
4)对其余每个阶段,即k=2,…,K,计算第k个余量信号,与步骤3的计算过程一致,计算第k+1个模态分量如下:
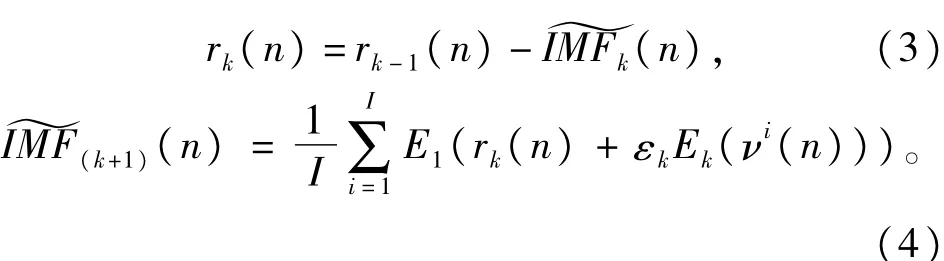
5)执行步骤4,直至所获取的余量信号不再可能进行分解时为止,其判断的标准为余量信号的极值点个数至多不超过两个。
算法终止时,所有模态分量的数量为K。最终的余量信号为:
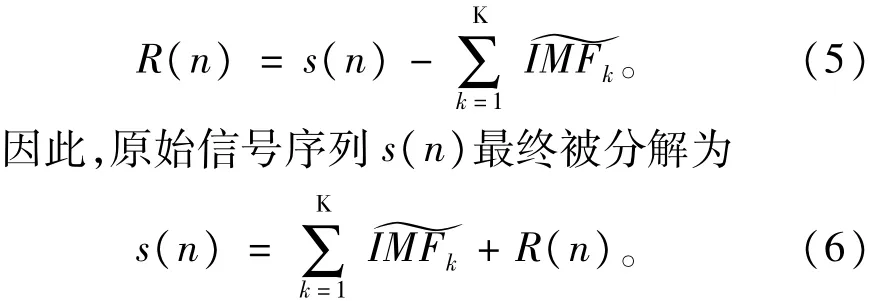
从CEEMDAN的算法实现及式(6)可看出,其分解过程是完整的,能对原始信号进行精确重构。算法实现中,在每一模态分解阶段,能够通过系数εk选择合适的信噪比(SNR)。
2 排列熵
一种衡量时间序列复杂性的测度——排列熵(Permutation Entropy,PE)由文献[13]提出,与Lyapunov指数相似,PE对时间序列的变化具有很高的敏感性,可检测出复杂动力学系统的突变现象。
考虑时间序列{s(n),n=1,2,…,N},对其进行相空间重构,得到重构向量
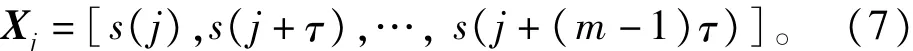
其中m表示嵌入维数,τ为延迟时间,下标j=1,2,…,N-(m-1)τ。重构向量Xj可作为矩阵X的行向量,将矩阵X的每一行,即各重构向量Xj重新进行升序排列,有其中j1,j2,…,jm表示重构向量中各个元素所在列的索引号。若存在:s(k+(jp-1)τ)=s(k+(jq-1) τ),则按j值的大小来进行排序。
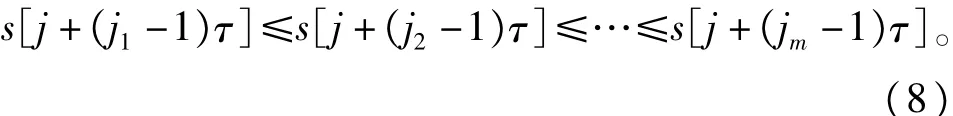
所以,对于时间序列{s(n),n=1,2,…,N}重构所得的矩阵X中的每一行,均可得到一组符号序列
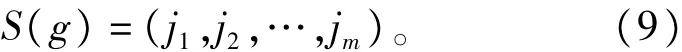
其中g=1,2,…,l。那么共有l≤m!种不同符号序列的排列方式。计算每一种符号序列出现的概率P1,P2,…,Pl,显然
所以,仿照Shannon熵的形式,定义时间序列{s (n),n=1,2,…,N}的PE为
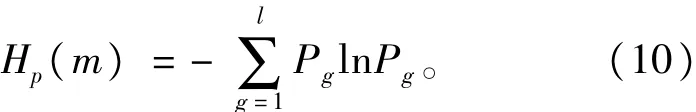
当Pg=1/m!时,Hp(m)达到最大值ln(m!)。因此,可将排列熵Hp(m)进行归一化处理,即

显然,Hp的取值范围为0≤Hp≤1,Hp值的大小反映了时间序列的随机性程度。Hp越大,说明时间序列的随机性越强。由式(7)可知,计算PE时,嵌入维数m和时延τ需要预先确定。文献[13]建议m取3~7,对时间序列的计算影响较小,通常取1即可。
3 回声状态网络
3.1 ESN网络
ESN网络部分地反映了大脑学习机制的某些特点,它具有很强的非线性逼近能力。ESN必须满足回声状态特性(echo state property,ESP),即在一定条件下,存在一个回声函数,使得网络状态可由历史输入及输出序列唯一确定。
ESN的基本结构如图1所示,从图中可看出网络分为输入层、隐含层、输出层三层。输入层以及隐含层与输出层之间的虚线连接为输出权值,实线部分的连接权值在网络训练前一经产生就不再改变,仅虚线连接部分的权值在网络训练中需要学习,即ESN只需计算与输出层连接的网络权值,完成训练学习,这与传统的递归神经网路需要训练所有的权值有明显不同,这也极大提高了ESN网络的学习速度。
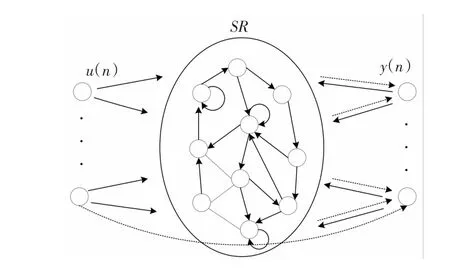
图1 ESN的基本结构Fig.1 The basic structure of echo state network
ESN网络的SR是由大量随机生成且稀疏连接的神经元组成,蕴含了系统的运行状态,并具有记忆功能,形成一个巨大的动态记忆库。网络初始化时, SR中的神经元之间的连接权值随机产生,并保持1%~5%的稀疏连接度。
可以证明[9,11],ESN状态储备池SR的连接权矩阵的谱半径小于1时,该网络是渐近稳定的。
设在n时刻的网络输入、隐含层及输出层向量为:u(n)=(u1(n),…,u~K(n))T、x(n)=(x1(n),…,x~N(n))T及y(n)=(y1(n),…,y~L(n))T。则ESN网络输入、隐含层及输出层的维数分别为~K、~N及~L。输入连接权矩阵Win∈R~N×~K,状态池连接权矩阵W∈R~N×~N,反馈连接权矩阵Wfb∈R~N×~L,W的谱半径为ρ,v(n+1)∈R~N×1为具有均匀分布的噪声向量,则ESN网络的状态方程为
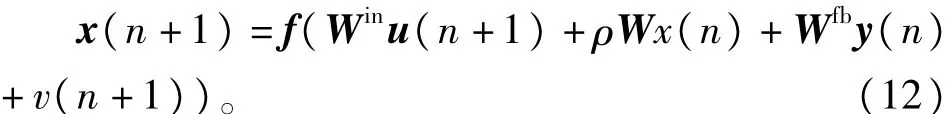
其中f=[f1,f2,…,f~N]T为激活函数,可取为双曲正切函数。
若σmax为W的最大特征值,且σmax(W)=1,谱半径ρ满足0≤ρ<1,可以证明ESN网络具有ESP特性[9]。
3.2 泄漏积分ESN网络
LIESN网络的输入、隐含层及输出向量的定义以及输入连接权矩阵Win,状态池连接权矩阵W,反馈连接权矩阵Wfb的定义同3.1节,则在LIESN中,其动态神经元x(t)的连续状态微分方程可表示为
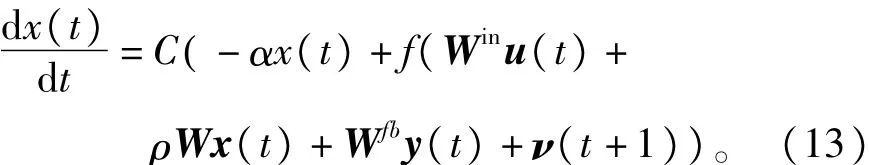
其中C>0,α>0表示SR的神经元泄漏率参数。取步长为1,将式(13)离散化,则可得到给定离散输入u(n)的网络状态方程为
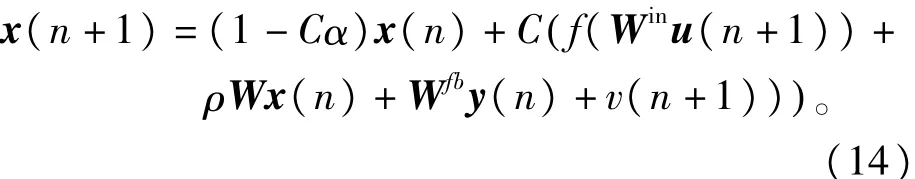
由式(14)看出,当C,α分别取1时,式(14)即为基本的ESN网络。如果ρ满足0≤ρ<1,同时σmax(W)=1,C>0,α>0且Cα≤1,网络则具有ESP特性[11-12]。
LIESN的网络输出方程表示为
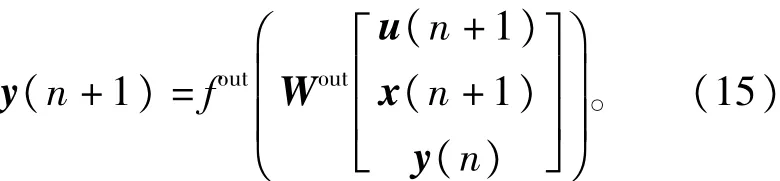
其中fout可取为双曲正切函数,输出权矩阵Wout∈R~L×(~K+~N+~L),矩阵符号[·]表示ESN的输入层、隐含层以及输出层向量的合并。
概言之,LIESN网络中,每一个状态神经元具有低通滤波或具有指数光滑的特性,其泄漏率参数控制在前一时刻的神经元状态的保持程度。因此,较小的Cα取值可导致内部神经元状态x(n)的较慢变化,从而进一步增强ESN的短时记忆能力。
若训练样本集定义为
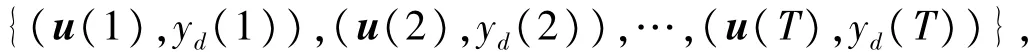
其中u(n)表示n时刻的输入向量,yd(n)是相应的期望输出,n=1,2,…,T,且T为训练样本集的最大长度。通过训练,使LIESN网络的输出y(n)逼近期望输出yd(n)。
具体算法实现如下:
1)网络结构的确定,即定义输入层、隐含层、输出层的维数~K、~N及~L;
2)网络初始化。Win、Wfb分别由位于[-0.2, 0.2]、[-1,1]区间上的均匀分布随机数预先设定,W是由位于[-1,1]区间上的均匀分布随机数生成,其网络连接稀疏度为min(10/N,1),谱半径ρ小于1;
3)定义矩阵M、T。在样本数据驱动下运行网络,为消除网络起始瞬态的影响,丢弃前T0个值。在时刻T0后,收集网络在不同时刻的输入层、隐含层状态向量和输出层向量的合并(u(n),x(n),yd(n-1)),作为状态收集矩阵M的列向量,M∈R(~K+~N+~L)×(T-T0+1);矩阵T的列向量由不同时刻的期望输出yd(n)的反双曲正切函数tanh-1d(n)构成,
LIESN的输出权矩阵Wout可由状态收集矩阵M及矩阵T计算,即:

4)考虑到M中的(T-T0+1)≥(K+N+L),因此Wout的稳定最小二乘解可采用岭回归方法,也称之为Tikhonov正则化方法进行求解,即
Wout=TMT(MMT+χI)-1。(17)其中χ为正则项系数,单位阵I∈R(~N+~K+~L)×(~N+~K+~L)。
算法实现中,χ的作用是消除普通线性最小二乘方法求解中出现的病态不适定问题,从而提高了求解Wout的稳定性。
另一方面,岭回归方法通过在式(17)中施加χ求解Wout,在本质上可归结为如下的最小化问题,即
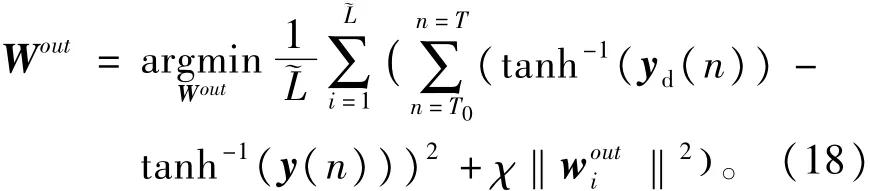
其中woiut为Wout的行向量,‖·‖表示欧式范数。
式(18)中,χ‖woiut‖2为一个正则化或权值衰减项,惩罚过大的Wout,Wout过大则导致网络不稳定,易产生病态解。正则化方法的求解则在训练误差和输出权值矩阵之间起到了很好的“折衷”作用,避免了网络训练时出现的数据“过拟合”问题及由反馈所引起的不稳定性。当χ=0时,式(18)则简化为普通线性最小二乘方法的求解。χ越大,正则化效果越强。
网络训练的均方误差为
M SE=
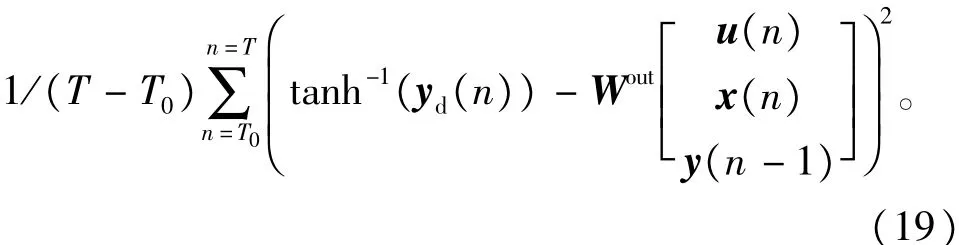
其中yd(n)为导师信号,y(n)为LIESN的输出。
4 中期峰值电力负荷预测实验
由于电力负荷预测的复杂性,除了考虑电力负荷历史负荷值外,还需要考虑其它因素的影响,包括日历信息、节假日信息、气象信息等因素。日历因素用来区分周末与工作日电力负荷需求的不同,气象因素主要包括温湿度、风速、云雾信息等,气象与负荷值之间有着一定的复杂关系,在实际的电力负荷预测中,由于待预测日的气象因素,如天气温度等本身未知,这就需要提前预测温度,且通常提供的历史气象数据也很有限。若考虑气象因素,则在增加预测难度的同时,并不一定会明显提高预测精度[16]。由于预测温度将增加预测的难度,因此,本节的预测实例中,可采用数据分割的方法获取训练数据集,以弥补气象因素的影响,并按照时间序列建模方式,将日历、节假日等特征信息也作为预测输入。预测模型如下
y(t)=fi(t)(xt),∀t=Δ…l。(20)其中f(·)用LIESN构建,i(t)表示对数据进行分割后的不同时间段,Δ表示嵌入维数,xt除了包含历史负荷值(yt-1,yt-2,…,yt-Δ)之外,还包括日历、节假日特征。
实验采用迭代预测方式进行,即训练时采用式(20)所示的单步预测模型,测试时,递推地将本次的预测输出作为下一次预测输入,滚动进行直至结束。
预测评价指标采用最大绝对值误差(maximal error,ME),平均绝对值百分比误差(mean absolute percentage error,MAPE),均方根误差(mean square error,MSE))。即ME=max|yi-yˆi|,MAPE=100
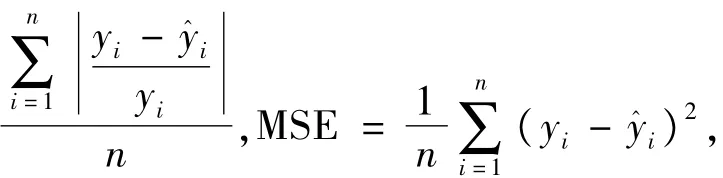
其中yi表示实际负荷值,yˆi表示模型的预测值,n表示待预测的天数。
4.1 欧洲地区电力负荷竞赛实验
实验选取欧洲EUNITE网络组织的全球电力负荷预测竞赛实例,并提供了斯洛伐克国家东部电力公司的实际数据集,其数据从以下网址获取http:// neuron.tuke.sk/competition/index.php。具体包括1997年到1998年每隔半小时的电力负荷值,1995年到1998年每天的平均温度,1997年到1999年1月的节假日信息,预测目标为1999年1月份每日最大负荷值,即峰值预测。即分别选取1997年和1998年1至3月、10月至12月期间的数据作为训练数据集来进行预测。
考虑到原始负荷序列的非平稳性,首先用CEEMDAN方法对训练数据集的原始负荷序列进行分解,结果如图2所示。实验中,加入了实验次数I=200组白噪声信号,其标准差为0.2。
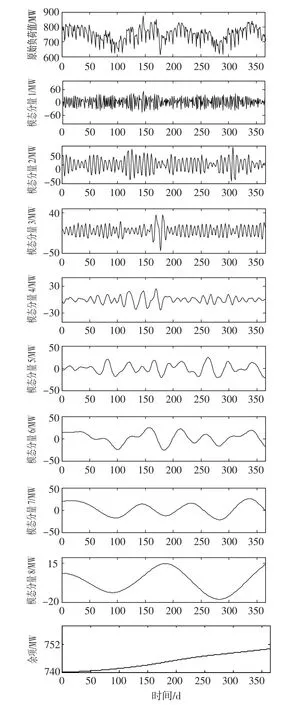
图2 CEEMDAN的分解结果Fig.2 The result of CEEMDAN decomposition
EEMD和CEEMAAN两种分解方法的重构误差则由图3给出,从图3看出,在添加200组白噪声的情况下,CEEMDAN分解的重构误差≤1×10-7,而EEMD分解方法的重构误差显然受到集成次数大小的影响[4],在本例I值不大的情况下,远大于CEEMDAN分解方法的重构误差,因此,EEMD方法在一定程度上影响了对负荷序列分解的完整性,另一方面,EEMD方法为了降低重构误差,以达到同样的精确度,则需要较多的实验次数,从而又导致过重的计算规模与时间开销。
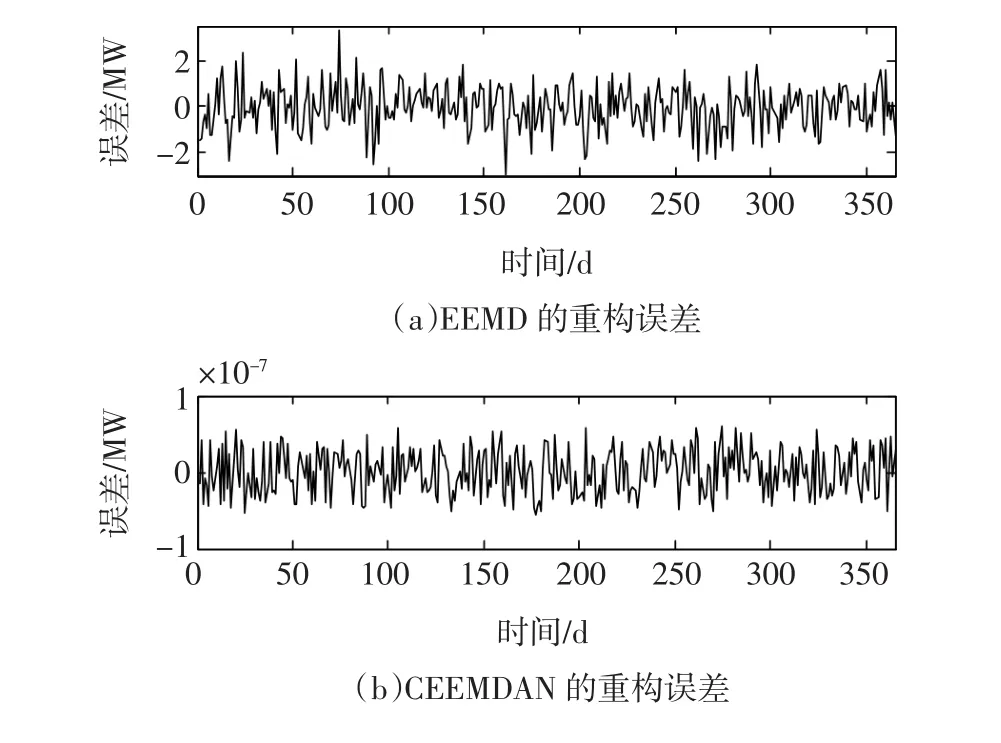
图3 基于不同分解方法的重构误差Fig.3 Reconstruction error for different decomposition methods
其次,由于负荷序列的非平稳性使得CEEMDAN分解后的IMF分量较多,为了减小分别构建子序列预测模型的计算规模,采用PE算法对每一IMF分量进行复杂度评估,进而进行相应的合并与重组。计算PE时,延迟时间τ对结果的影响较小,取1即可,通过实验,当嵌入维数m取3时,各IMF分量的变化规律比较明显。因此,图4给出了m为3时各IMF分量PE值的计算结果。从图4可以看出,各IMF分量的PE值随着IMF分量频率的降低呈递减趋势,这也说明从高频到低频分量序列的随机性程度是减小的。考虑到PE值的大小及兼顾CEEMDAN的分解结果,以熵值相似性及接近程度为依据对各分量进行合并,具体的合并情况如表1所示。其中,随机性最强且对预测结果影响最大的IMF1分量的PE值最大且明显有别于其它分量; IMF2和IMF3的PE值呈现出一定程度的相似性,差值为0.01,可以合并;IMF4、IMF5相邻且PE差值为0.2,因此将其进行合并;IMF6~IMF8的PE值差异较小,约为0.14,余项分量R的PE值为0,将其看作平稳分量可与IMF6~IMF8进行合并。

表1 各IMF分量和余项的合并结果Table 1 Combination results of IMF s&residual
合并后的重组子序列,其频率和振幅是随时间变化的,为有针对性的建立不同的预测模型,与文献[14]一致,需要计算其平均周期T和平均振幅A,具体结果如表2所示。

图4 各IMF分量的排列熵Fig.4 Permutation entropy of each IMF component
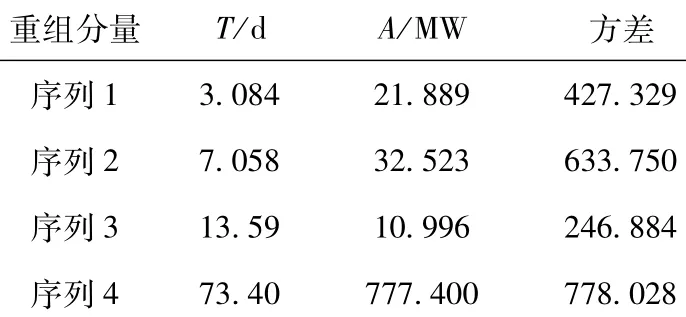
表2 各子序列的内在特性分析Table 2 Intrinsic characteristics analysis of each subsequence
从表2看出,序列1仅包含一个分量,其平均周期最小,振幅相比序列4小很多方差却较大,表明其随机性很强,这与PE一致,代表波动性最强的分量,可以看作是高频分量,周期大约为3天,因此取嵌入维Δ=3。序列2的规律性很好,该分量反映了负荷以一周为周期的波动,可看作周期分量,周期大约为7天,取Δ=7。序列3的周期大约为14天,且其方差和振幅都较小,说明其波动相对较小,为降低计算量,取Δ=3即可;序列4的振幅和周期都最大,整体波动趋于平缓,可以看作趋势分量,因此也可取Δ=3。重组后的四个子序列波形由图5给出。
最后,针对各重组分量形成的子序列分别建立四个不同的LIESN预测模型进行预测。预测模型的输入还包括日历和节假日信息。日历信息用7位二进制编码表示,节假日和非节假日用1位二进制码表示。第1个子序列的LIESN预测模型的输入为11维,第2个子序列的LIESN预测模型的输入为15维,第3与第4个子序列的LIESN预测模型的输入均为11维,各子序列的预测结果叠加即得到最终的组合预测结果。详细的总体预测流程如图6所示。
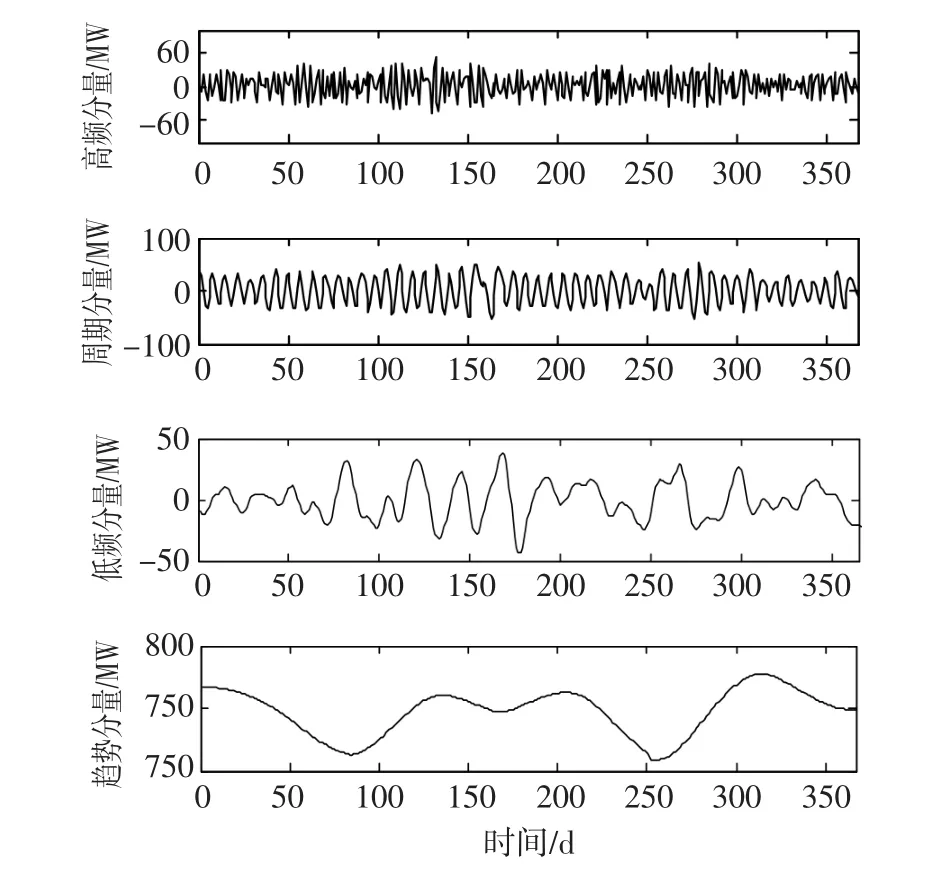
图5 经CEEMDAN-排列熵处理后的重组分量Fig.5 Recombination com ponent processed by CEEMDAN-PE method
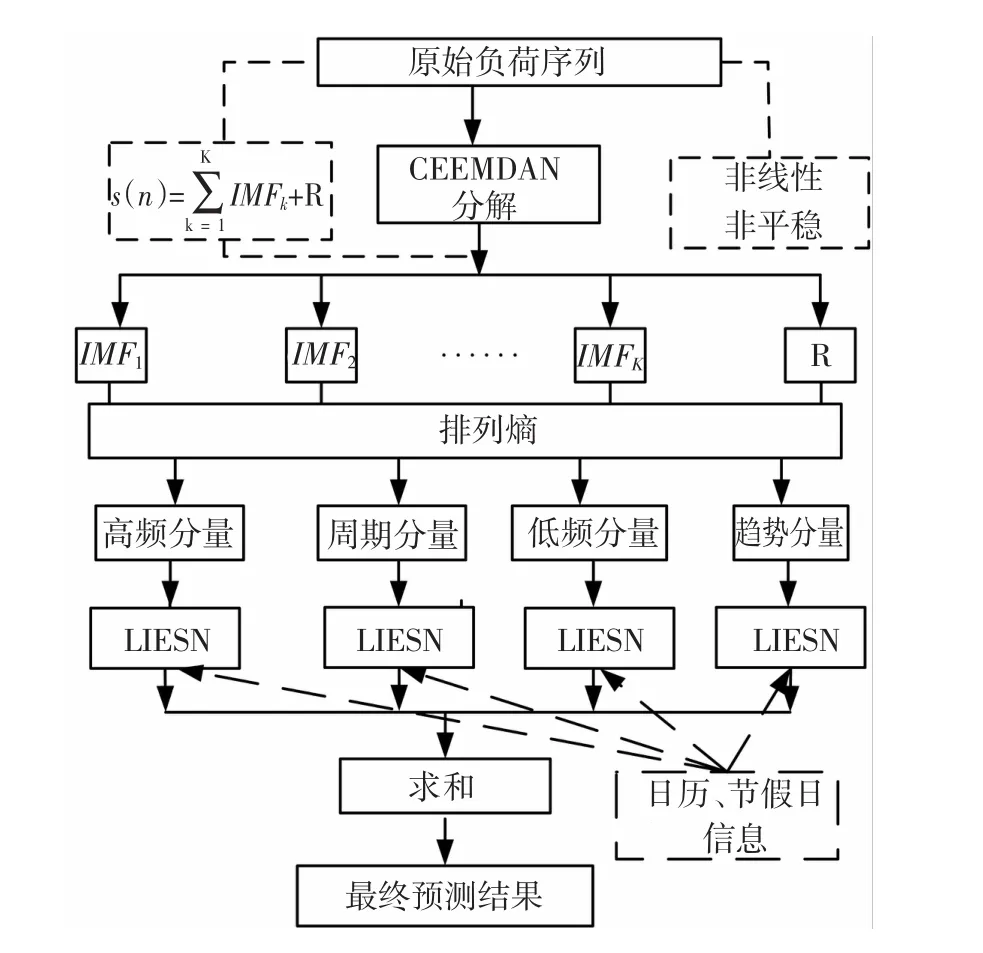
图6 基于CEEMDAN-排列熵与LIESN的组合预测流程Fig.6 Combined forecasting flow chart based on CEEMDAN-PE and LIESN method
由LIESN构建的各子序列预测模型中,SR的大小,谱半径ρ、时间常数C、泄漏率α、正则化系数χ和网络连接稀疏度S等参数可通过交叉验证的方法选取,以得到较优的实验结果。具体参数的取值如表3所示。
为进一步衡量本文方法的预测效果,本文方法还与EEMD-ESN、CEEMDAN-ESN等组合预测及LiESN等单一预测方法进行了比较。不同预测方法的预测结果由图7给出,从图7可看出,CEEMDAN -排列熵与LIESN的组合预测方法显示出很好的预测效果。同时,表4还列出了不同预测方法的预测误差指标。从表4可以看出,本文方法的预测精度均优于其他方法所获得的结果。同时,还与使用该数据集的相关文献的研究结果进行了对比。文献[15]使用多种组合核函数构成的相关向量机进行预测,模型的输入为18维,其最优的MAPE= 1.157,ME=31.71,取得了较好的预测效果。本文方法的ME值略高于文献[15]的最优结果,MAPE值与其最优结果相当。
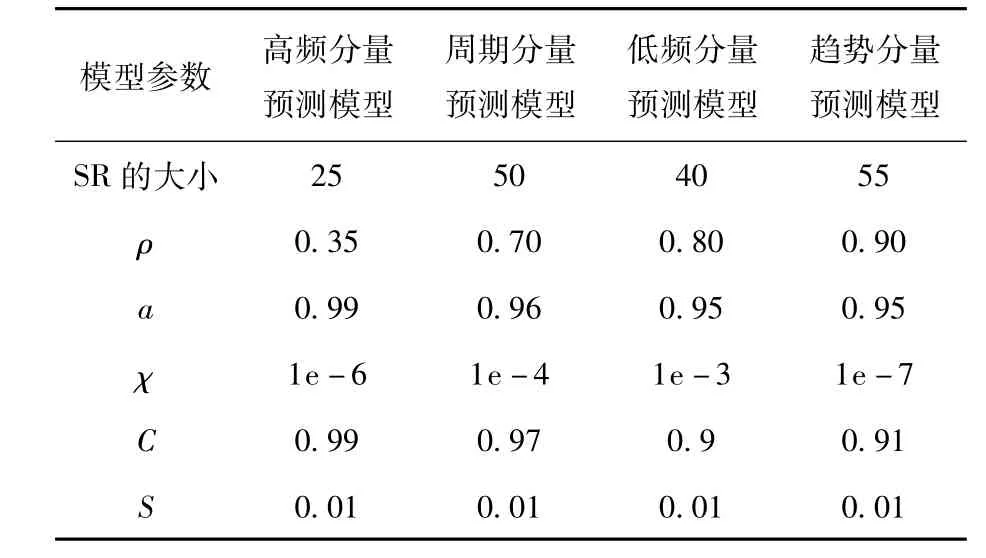
表3 不同LIESN模型的参数取值Table 3 Parameter values of each different LIESN model
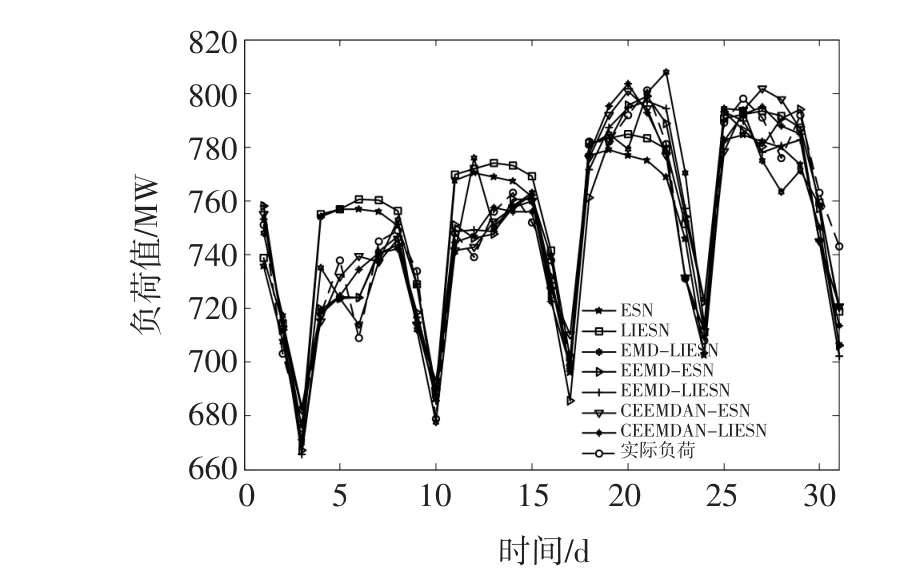
图7 日峰值负荷预测结果比较Fig.7 Comparison of daily peak load forecasting results
文献[16-20]的预测结果与本文方法的比较如图8所示。其中,文献[16]使用了标准SVM方法进行预测,其预测结果由LIBSVM软件获得,赢得了当年EUNITE竞赛的第1名。文献[17]将贝叶斯方法与SVM的学习用于前馈神经网络的一种结构选择上,取得了较好的预测效果;文献[18]将特征选择方法与SVM结合,构建新的预测模型;文献[19]将K近邻局部预测与SVM方法相结合,构建预测模型;文献[20]则提出一种基于局部加权的SVM预测方法,也取得了较好的预测效果。从图8可以看出,相比文献[16]~[20]而言,本文方法的MAPE值最低,分别提升了40.51%、33.71%、31.76%、23.68%和17.7%,这更进一步验证了本文方法的有效性。
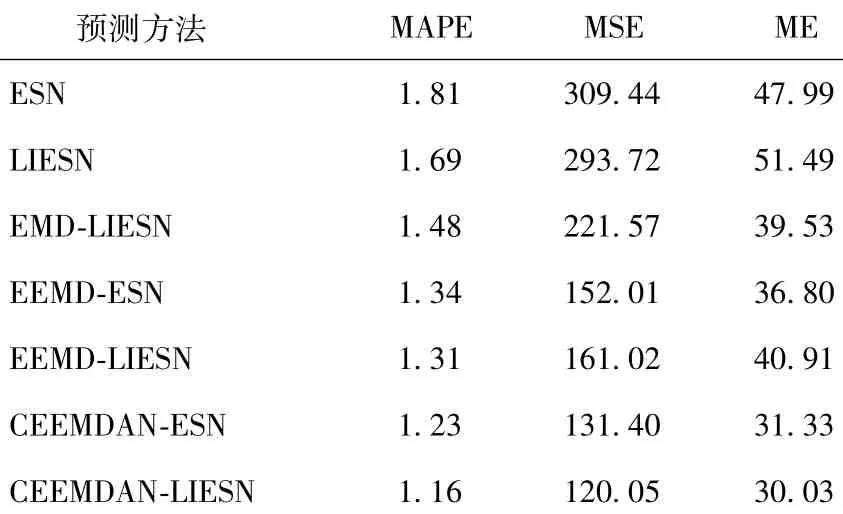
表4 CEEMDAN-LiESN与其他预测方法的性能比较Table 4 Performance comparison of CEEMDAN-LiESN and other prediction methods
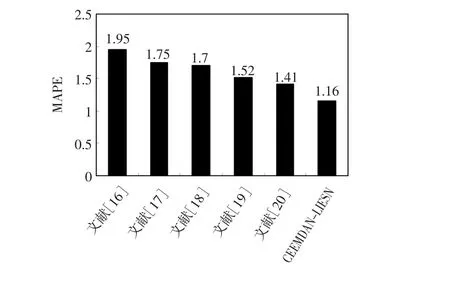
图8 CEEMDAN-LIESN与使用EUNITE竞赛数据集的其他模型的比较Fig.8 Comparison of CEEMD-LIESN model and other models using EUNITE competition dataset
4.2 新英格兰地区电力负荷预测实验
实验选取美国新英格兰地区2006至2008年以小时为间隔的实测电力负荷数据集,预测目标为2008年5月4日至24日未来21天的日峰值负荷。同样采用数据分割的思想来选取训练数据集,即分别选取2006、2007年4至5月以及2008年4月的数据为训练数据集。
首先,同实验一,CEEMDAN分解方法取实验次数I=200,白噪声信号标准差为0.2,其分解结果如图9所示。
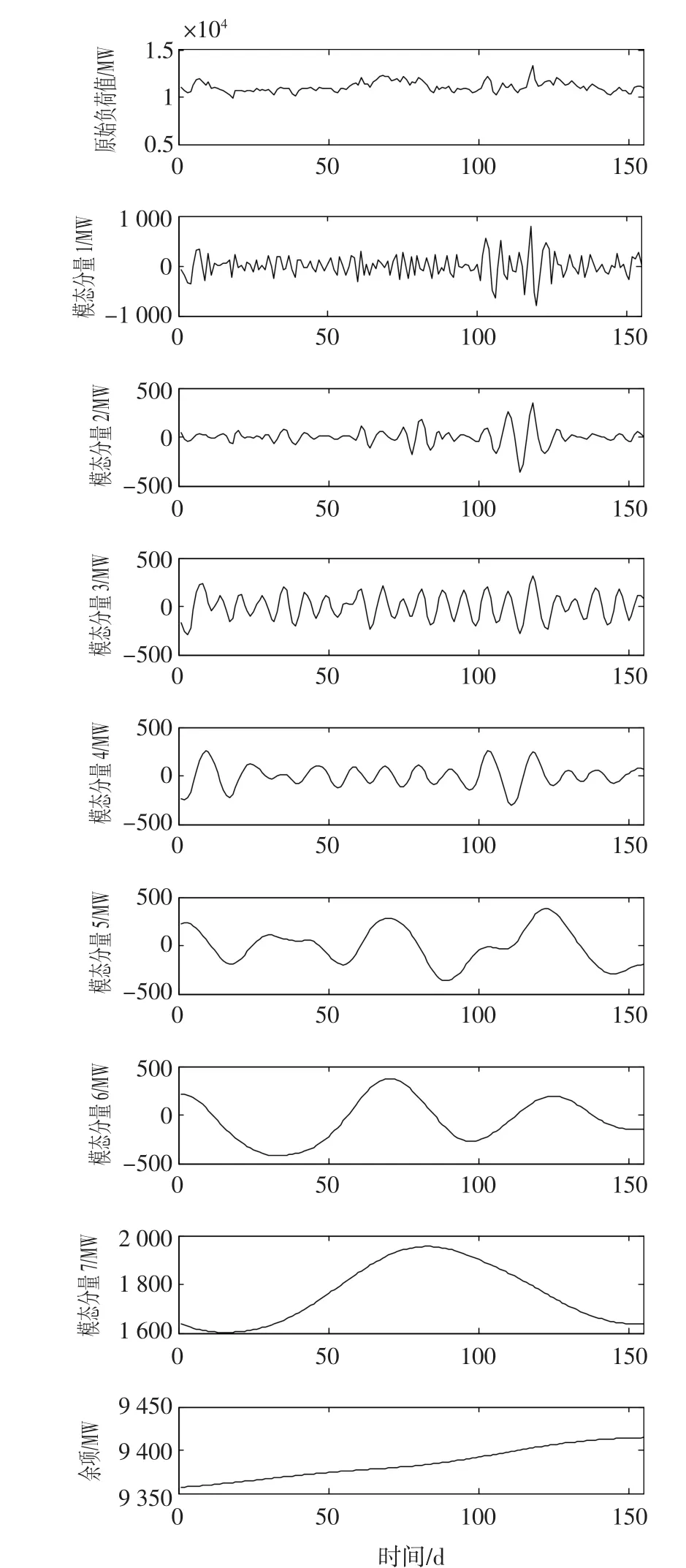
图9 CEEMDAN的分解结果Fig.9 The result of CEEMDAN decomposition
EEMD和CEEMDAN两种分解方法的重构误差由图10给出,在本例负荷功率幅值较大的情形下,相对于实验一,EEMD的重构误差也相应增大,幅值范围达到-30~40MW,而CEEMDAN方法的重构误差依然几乎为0。因此,EEMD方法所产生的较大重构误差会为最终的预测带来累积误差,而CEEMDAN方法克服了这一缺点,具有更好的分解完整性,有利于提高负荷预测的精度。
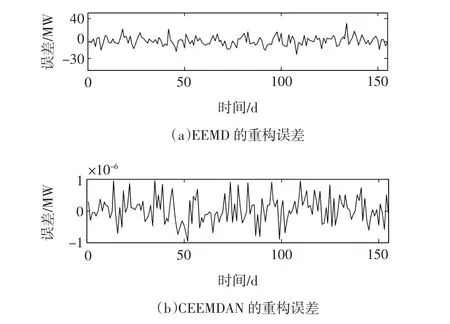
图10 基于不同分解方法的重构误差Fig.10 Reconstruction error for different decom position m ethods
其次,采用PE算法对每一IMF分量进行复杂度评估,然后进行相应的合并与重组,计算PE时,τ取1,m取3时,PE值较为明显地体现出各IMF分量的变化规律。图11给出了各IMF分量的PE值计算结果,以熵值相似性及接近程度为依据对各分量进行合并,具体的合并情况如表5所示。其中,随机性最强且对预测结果影响最大的IMF1分量的PE值最大,明显有别于其它分量;IMF2和IMF3的PE值非常接近,相差0.07,可以合并;IMF4和IMF5的PE熵值相差0.24,可以合并;IMF6和IMF7的PE值相差0.13,余项分量R的PE值为0,将其看作平稳分量与IMF6、IMF7进行合并。表5列出了合并结果。
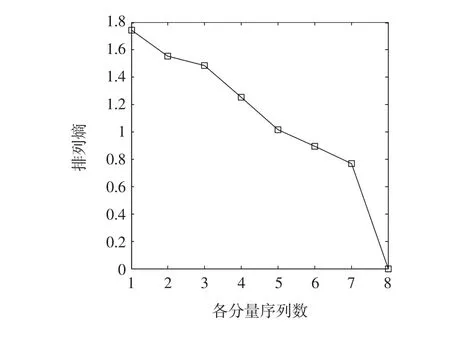
图11 各IM F分量的排列熵Fig.11 Permutation entropy of each IMF component
为有针对性的建立不同预测模型,计算合并后的各子序列的平均周期T和平均振幅A,具体计算结果如表6所示。

表5 各IMF分量和余项的合并结果Table 5 Combination results of IMFs&residual
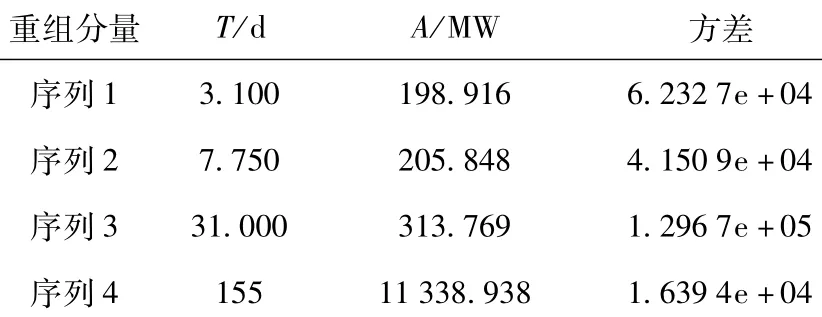
表6 各子序列的内在特性分析Table 6 Intrinsic characteristics analysis of each subsequence
从表6可以看出,序列1仅包含一个分量,其平均振幅最小但方差却大于序列2和序列4的方差,表明其随机性很强,这与PE一致,代表波动性最强的分量,可以看作是高频分量,周期约为3天,因此取Δ=3。序列2的规律性很好,且该分量大致反映了负荷以一周为单位的波动,可看作周期分量,周期约为8天,取Δ=8。序列3的周期约为一个月,结合图9可以看出,其包含的分量IMF4和IMF5相比前三个IMF分量波动趋于平缓,说明其波动相对较小,可以看作低频分量,为降低计算量,取Δ=3;序列4振幅最大,方差却最小,整体波动更为趋于平缓,可以看作趋势分量,因此也可取Δ=3。重组后的四个子序列波形由图12给出。
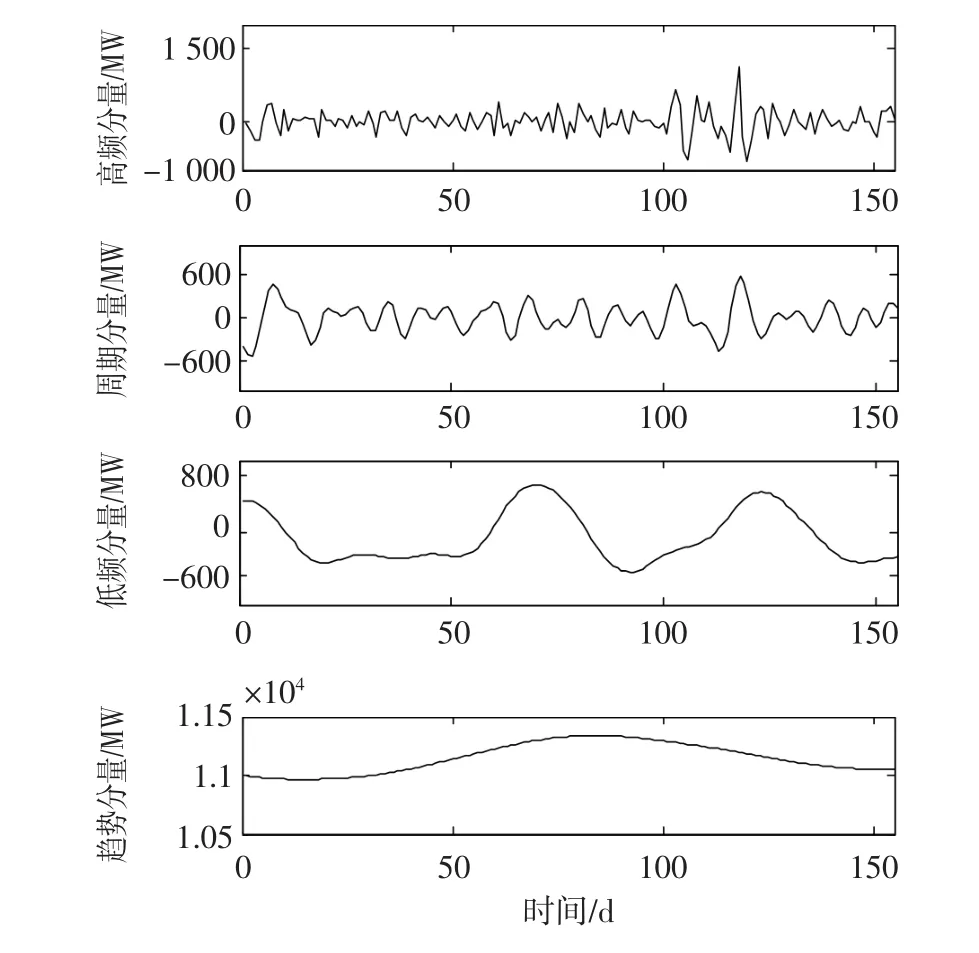
图12 CEEMDAN-排列熵处理后的重组分量Fig.12 Recombination com ponent processed by CEEMDAN-PE method
最后,针对各重组分量所形成的子序列分别建立四个不同的LIESN预测模型,预测模型输入也包含了日历和节假日信息。各子序列预测模型的具体参数取值如表7所示。

表7 不同LIESN模型的参数取值Table 7 parameter values of each LIESN model
本文方法与EEMD-ESN、CEEMDAN-ESN等组合预测方法及LIESN等单一预测方法的预测效果比较由图13给出,不同预测方法的预测误差指标由表8给出,可以看出,本文方法依然取得了最好的预测效果。
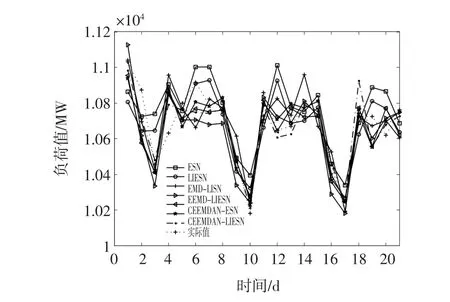
图13 日峰值负荷预测结果比较Fig.13 Comparison of daily peak load forecasting results
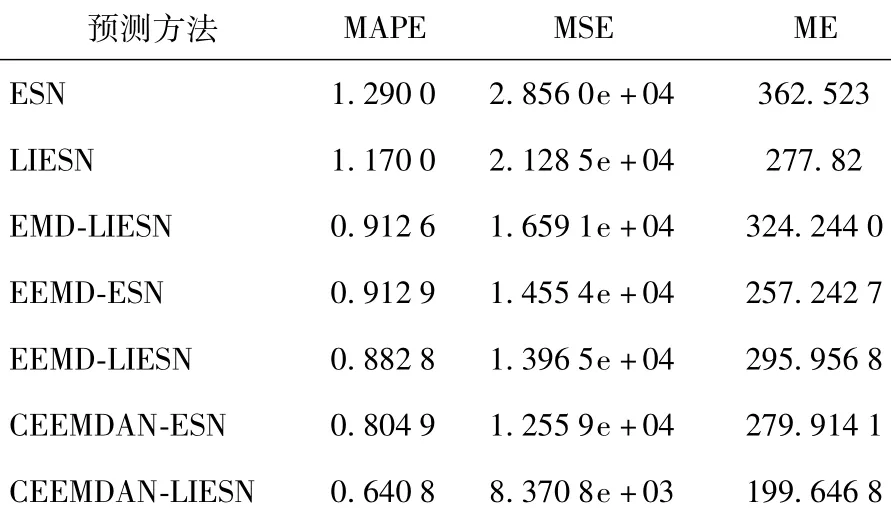
表8 CEEMDAN-LIESN与其他预测方法的性能比较Table 8 Performance com parison of CEEMDAN-LIESN and other prediction methods
5 结 论
本文提出了一种基于CEEMDAN-排列熵和LIESN结合的中期峰值负荷预测方法。针对负荷序列的非平稳性,利用CEEMDAN方法自适应地将其分解为一系列不同尺度的分量,与EEMD方法相比,它能实现对幅值较大数据分解的完整性,有利于进一步提高预测精确度。与此同时,将排列熵引入到各IMF分量的复杂度评估中,以PE值为依据对各IMF分量进行重新组合,产生新的复杂度差异明显的子序列,以有效降低组合预测方法的计算规模。最后,将具有良好学习性能的LIESN方法分别应用于合并后的各子序列建模中,通过应用于不同地区的电力负荷峰值预测实例验证了本文方法的有效性,它能取得很高的预测精确度,具有很好的应用潜力。
[1] 康重庆,夏清,张伯明.电力系统负荷预测研究综述与发展方向的探讨[J].电力系统自动化,2004,28(17):1-11. KANG Chongqing,XIA Qing,ZANG Boming.Review of power system load forecasting and its development[J].Automation of E-lectric Power Systems,2004,28(17):1-11.
[2] 郑高,肖建.基于区间二型模糊逻辑的电力负荷预测研究[J].电机与控制学报,2012,16(9):26-32. ZHENG Gao,XIAO Jian.Forecasting study of power load on interval type-2 fuzzy logicmethod[J].Electric Machines and Control,2012,16(9):26-32.
[3] HUANG N E,SHEN Z,LONG SR,et al.The empiricalmode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis[J].Proceedings of the Royal Society of London-Series A:Mathematical,Physical and Engineering Sciences,1998,454(1971):903-995.
[4] WU Z,HUANG N E.Ensemble empiricalmode decomposition:a noise-assisted data analysismethod[J].Advances in Adaptive Data Analysis,2009,1(01):1-41.
[5] TORRESM E,COLOMINASM A,SCHLOTTHAUER G,et al. A complete ensemble empiricalmode decomposition with adaptive noise[C]//IEEE International Conference on Speech and Signal Processing(ICASSP),May,22-27,2011,Prague,Czech.2011: 4144-4147.
[6] 祝志慧,孙云莲,季宇.基于EMD和SVM的短期负荷预测[J].高电压技术,2007,33(5):118-122. ZHU Zhihui,SUN Yunlian,JI Yu.Short-term Load Forecasting Based on EMD and SVM[J].High Voltage Engineering,2007, 33(5):118-122.
[7] 刘岱,庞松岭,骆伟.基于EEMD与动态神经网络的短期负荷预测[J].东北电力大学学报,2009,29(6):20-26. LIU Dai,PANG Songling,LUO Wei.Power system short-term load forecasting based on EEMD and dynamic neural network[J]. Journal of Northeast DianLi University,2009,29(6):20-26.
[8] 叶林,刘鹏.基于经验模态分解和支持向量机的短期风电功率组合预测模型[J].中国电机工程学报,2011,31(31):102 -108. YE Lin,LIU Peng.Combined Model Based on EMD-SVM for Short-term Wind Power Prediction[J].Proceedings of the CSEE, 2011,31(31):102-108.
[9] JAEGER H,HAASH.Harnessing nonlinearity:Predicting chaotic systems and saving energy in wireless telecommunication[J]. Science,2004,304(2):78-80.
[10] DEIHIMIA,SHOWKATIH.Application of echo state networks in short-term electric load forecasting[J].Energy,2012,39 (1):327-340.
[11] JAEGER H,LUKOSEVICIUSM,POPOVICID.Optimization and applications of echo state networkswith leaky integrator neurons[J].Neural Networks.2007,20(3):335-352.
[12] HOLZMANN G,HAUSER H.Echo state networks with filter neurons and a delay&sum readout[J].Neural Networks,2010, 23(2):244-256
[13] BANDT C,BEMD P.Permutation entropy:a natural complexity measure for time series[J].Physical Review Letters,2002,88 (17):174102-1~174102-4.
[14] 牛东晓,李媛媛,乞建勋,等.基于经验模式分解与因素影响的负荷分析方法[J].中国电机工程学报,2008,28(16): 96-102. NIU Dongxiao,LI Yuanyuan,QI Jianxun,etc.A Novel Approach for Load Analysis Based on EmpiricalMode Decomposition and Influencing Factors[J],Proceedings of the CSEE,2008,28 (16):96-102.
[15] 段青,赵建国,马艳.优化组合核函数相关向量机电力负荷预测模型[J].电机与控制学报,2010,14(6):33-38. DUAN Qing,ZHAO Jianguo,MA Yan.Relevance vector machine based on particle swarm optimization of compounding kernels in electricity load forecasting[J].Electric machines and Control,2010,14(6):33-38.
[16] CHEN B J,CHANGMW,LIN C J.Load forecasting using support vectormachines:A study on EUNITE competition 2001[J]. IEEE Trans.on Power Systems,2004,19(4):1821-1830.
[17] FERREIRA V H,ALVES da Silva A P.Toward estimating autonomous neural network-based electric load forecasters[J]. IEEE Trans.on Power Systems,2007,22(4):1554-1562.
[18] TAO X,RENMU H,PENGW,etal.Input dimension reduction for load forecasting based on support vector machines[C]//Proceedings of the 2004 IEEE International Conference on Electric Utility Deregulation,Restructuring and Power Technologies (DRPT),April5-8,2004,Beijing,China.2004:510-514.
[19] ELATTAR E E,GOULERMAS JY,Wu Q H.Forecasting electric daily peak load based on local prediction[C]//IEEE International Conference on Power&Energy Society General Meeting (PESGM),July 26-30,2009,Calgary,AB,Canada.2009:1 -6.
[20] ELATTAR E E,GOULERMASJY,Wu QH.Electric load forecasting based on locally weighted support vector regression[J]. IEEE Trans.on Systems,Man,and Cybernetics,Part C:Applications and Reviews,2010,40(4):438-447.
(编辑:贾志超)
Medium term electricity load forecasting based on CEEMDAN-permutation entropy and ESN w ith leaky integrator neurons
LIJun, LIQing
(School of Automation and Electrical Engineering,Lanzhou Jiaotong University,Lanzhou 730070,China)
Based on complete ensemble empiricalmode decomposition with adaptive noise(CEEMDAN)-permutation entropy and echo state network with leaky integrator neurons(LIESN),a kind of combined forecastingmethod was proposed formedium-term power load forecasting.In the CEEMDAN method,a particularwhite noise was added ateach stage of the decomposition and a unique residue was computed to obtain each intrinsic model function(IMF),compared with EEMD,the resulting decomposition is complete.In order to weaken the influence of non-stationary effects of the load series on the prediction accuracy and reduce computation scale,the load time series was decomposed into a series of subsequences with obvious differences in complex degree by using CEEMDAN-permutation entropy,and the corresponding LIESN forecasting model was built respectively by analyzing the inner characteristics of each subsequence.Simultaneously,the ultimate forecasting results can be obtained by the superposition of the corresponding forecastingmodel.The proposedmethod was applied to electricity peak load forecasting instances in different areas and compared with other combined and single forecastingmethods.Experiment results confirm that the proposed method has a high prediction precision,and show the effectiveness and applicability.
load forecasting;combined model;ensemble empiricalmode decomposition;echo state network; permutation entropy
10.15938/j.emc.2015.08.011
TM 715
A
1007-449X(2015)08-0070-11
2014-04-02
国家自然科学基金(51467008);甘肃省高等学校基本科研业务费专项资金项目(620026)
李 军(1969—),男,博士,教授,研究方向为计算智能与系统建模、预测与控制;李 青(1989—),男,硕士研究生,研究方向为计算智能与电力负荷预测。
李 军