
基于信任模型填充的协同过滤推荐模型
2015-06-09 12:33杨兴耀吐尔根依布拉音英昌甜
计算机工程 2015年5期
杨兴耀,于 炯,2,吐尔根·依布拉音,廖 彬,2,英昌甜
(1.新疆大学信息科学与工程学院,乌鲁木齐830046;2.新疆大学软件学院,乌鲁木齐830008)
基于信任模型填充的协同过滤推荐模型
杨兴耀1,于 炯1,2,吐尔根·依布拉音1,廖 彬1,2,英昌甜1
(1.新疆大学信息科学与工程学院,乌鲁木齐830046;2.新疆大学软件学院,乌鲁木齐830008)
针对传统协同过滤模型中存在的数据稀疏性问题,提出一种基于信任模型填充的协同过滤推荐模型。对信任属性进行研究,通过建立信任模型对评分矩阵进行预填充以提高数据存储密度,利用相似性模型分别从项目和用户属性的角度度量项目相似性,通过自适应协调因子协调处理两方面的相似性度量结果,获得最终的项目预测评分,基于不同的数据集进行实验验证,结果表明,在不同的数据集中,与传统的协同过滤模型相比,该模型能够有效地处理评分矩阵的数据稀疏性问题,提高系统评分预测的准确度,平均改进程度为8%。
推荐系统;协同过滤;信任模型;用户属性;相似性模型;平均绝对误差
1 概述
互联网信息的海量增长,使得人们在快速访问各种信息资源的同时,也导致了“信息过载”问题,它实际上是信息产生速度与信息处理速度之间的一种矛盾。为了协调这个矛盾,帮助用户在信息海洋中快速准确地寻找到自己需要的信息内容,研究人员提出了推荐系统[1]。推荐系统作为建立在海量数据挖掘基础上的一种高级商务智能系统,它能够为用户提供个性化的决策支持和信息服务,从而减轻用户在面对海量信息时盲目搜索的烦恼。目前推荐系统已经广泛应用到互联网服务的各个领域中,例如音乐视频推荐、社交网络等,成为各大信息服务提供商应对信息过载问题的重要手段。其中最典型并且具有良好应用前景的领域是电子商务,如在线零售巨头亚马逊成功地将推荐技术应用于商品推荐[2],使得2012年第二财季的营业收入达到了128.3亿美元,这一数据与去年同期的99亿美元相比大涨了约29%。
推荐系统主要通过研究用户的行为偏好特征,主动进行计算分析来发现用户的兴趣所在,它由3个重要的模块组成:用户建模模块,推荐对象建模模块以及推荐模型模块。其中推荐模型模块是系统的核心,它连接着建模后的用户和推荐对象两部分,其性能直接影响着系统的性能。为此,推荐模型模块成了众多学者研究的焦点。为获得较好的系统性能,很多的研究成果围绕其而展开,由此在不同的应用环境中出现了各种不同的推荐模型[1-4]。其中关于协同过滤推荐模型的研究最为广泛,这主要是因为协同过滤模型的基本思想比较简洁,较为符合人们的日常行为习惯,如通常会根据朋友的推荐来进行一些决策、选择等。
尽管如此,协同过滤模型在实际应用中还存在一些问题亟待解决,典型的如数据稀疏性问题[5],该问题产生的主要原因在于推荐系统中用户项目的数量很大,而用户关于项目的评价数据又非常少,平均不足1%。关于这一问题,传统的协同过滤模型在度量对象相似性的过程中,采取了各种补救措施,但这些措施大多需要与对象相似性相关联。这样做存在一定的缺陷,因为相似性本身在数据稀疏性条件下是不可靠的。为此本文从信任入手,建立一种独立于传统相似性的用户信任模型来对稀疏数据进行填充,并在此基础上提出一种基于信任模型填充的协同过滤推荐模型(Collaborative Filtering Aecommendation Model Based on Trust Model filling,CFTM),以提高系统推荐性能。
2 相关工作
经过多年的应用和研究,协同过滤推荐模型已经成为目前个性化推荐系统中应用最为广泛的推荐技术[3],其原理是通过最近邻度量技术为需要获得信息推荐的用户即目标用户快速寻找到具有相似兴趣爱好的用户近邻,然后综合近邻感兴趣的内容将其推荐给目标用户。与此同时,协同过滤模型也面临着很多问题,通常情况下它仅能为那些拥有大量评价信息的用户和项目进行有效推荐,而在数据稀疏性条件下却并不能发挥出应有的推荐潜力,即出现数据稀疏性问题。
针对数据稀疏性问题,通常的处理方法可以分为2类:
(1)在数据稀疏性程度不变的情况下提高现有推荐模型的精度,这种方法比较普遍,且一般情况下若无专门说明均属于此类。例如文献[6]利用自动权重因子动态结合项目属性相似度和评分相似度,提出了一种改进相似性度量方法的协同过滤推荐算法(Collaborative Filtering Recommendation Algorithm on Improved Similarity Measure Method,CFIM),实验结果表明,该算法在现有条件下可以有效提高推荐的稳定性和精确度。文献[7]针对单一评分相似度的缺陷,提出了一种基于用户间多相似度的协同过滤推荐算法(Collaborative Filtering Recommendation Algorithm Based on User’s Multi-similarity, UMCF),即综合不同项目类型的用户评分相似度来计算用户对未评分项目的预测评分,实验结果证明了该算法在提高预测准确性及推荐质量方面的有效性。此外还有基于项目和信任的协同过滤推荐算法[8]等,这里不再叙述。
(2)采用一些填充模型对稀疏数据进行预填充,以提高数据存储密度,该方法通常比较复杂,但收效较好。如文献[9]对此提出一种基于项目属性和云填充的协同过滤推荐算法(Collaborative Filtering Recommendation Algorithm Based on Item Attribute and Cloud Model Filling,IACF),算法利用云模型对用户评分矩阵进行填充,并在此基础上利用协调因子构建了一种新的项目相似性度量。实验结果证明了所提算法可以有效解决由于数据稀疏性问题而导致的相关问题。文献[10]在对传统的未评分数据缺省值填充法和众数填充法进行研究的同时,考虑了用户评分的尺度问题,最终提出了一种优化稀疏数据集的方法,实验结果表明了该方法在提高系统推荐质量方面的有效性。此外还有基于径向基函数神经网络的解决方法[11]等,这里不再叙述。
上面提到的各种解决方法虽然从不同角度缓解了数据稀疏性问题,但都还存在着某些缺陷。关于该问题,近年来兴起的信任模型特别值得关注,它为人们解决问题提供了一种新的思路。因为在评价数据极端稀疏即信息不全的条件下,用户通常无法准确寻找到与自己相似的对象,而是直接向自己比较信任的对象,如亲戚、朋友来咨询相关的意见,这个过程实用有效,但重难点在于信任的度量问题。目前在协同过滤过程中考虑信任问题,虽然已经有了一些研究成果,但这些成果有相当一部分是以相似性本身作为信任值的,例如基于信任模型的协同过滤推荐算法[12]。还有一部分研究成果虽然专门度量了用户的信任问题,但却最终和相似性结合在了一起作为对象的最终相似性度量,如文献[13-14]。而有些遗憾的是,这些成果并未将信任作为一个独立的概念进行研究,并有针对性地将其应用到推荐中去。
事实上,信任在人们行为活动中的重要性固然不言而喻,但它却是一个相对模糊的概念,涉及到的方面很多,以致于至今都未能给出一个令人信服的定义[12,15]。目前在推荐系统中给出的一个较为完整的定义是:信任是指接受推荐者对提供推荐者特定行为的主观可能性预测,它是一种单向、相对、局限在一定范围内的主观反映[15]。鉴于此,本文在信任方面不再拘泥于信任的形式化定义,转而重点关注信任所包含的属性,这样可以对信任本身有一个更加客观、明确的认识。
信任模糊且难以琢磨,但确具有一些公认的属性,根据目前的一些信任定义及相关的信任研究成果,信任的属性通常包含主观性、不对称性、传递性、动态性、可度量性等[12-15]。除此之外,本文认为信任还应当重点关注一些其他属性:
(1)情境性:信任关系是建立在一定上下文环境基础上的,信任度的大小与信任度量时的条件、环境密切相关。
(2)可信性:信任的决定性因素,它取决于对象本身的诚实、能力、经验等,是一个对象值得和获取其它对象信任的基础。
(3)网络性:信任是在一定范围内各种交互数据的统计结果,它通常以一个对象为中心向与之有交互纪录的其他对象辐射,辐射强度与交互频率密切相关,最终构成一张有向信任网络。
(4)依赖性:对象之间的信任是互为基础和相互依存的,一个对象的信任度改变会因为传递性而波及到其他对象,引起一系列连锁反应。
需要说明的是,信任的各个属性之间不是相互独立的,而是相互关联的,在实际的信任度量体系中某些属性甚至会出现交叉、冲突的情况,这些都是正常的。另外在信任的实际度量过程中,完整地考虑各种属性难度是很大的而且通常没有必要,因而需要根据信任对象所处的情境进行相应的加强和减弱,以便对对象间的信任程度进行较好的量化,量化后的信任值称之为信任度。
3 基于信任填充的协同过滤推荐模型
信任无处不在,它对于人们行为活动的影响是直接而明显的,甚至成为一种前提条件。在由不同用户的活动数据构成的推荐系统中,信任的作用就显得尤为明显。针对其中的数据稀疏性问题,一定程度上也可以通过信任模型来缓解,为此本文提出了一种基于信任模型填充的协同过滤推荐模型,下面将从基本概念入手,介绍其工作原理直到最终的推荐完成。
3.1 信任模型的建立
推荐系统中包含着各种各样的数据,其中不可或缺的数据包括用户-项目评价数据、用户属性数据、项目属性数据等,这些数据也大致构成了本文信任度度量的情境。情境虽然有些简单,但却足以说明问题,可以在相当程度上反映每个用户的信任程度。
表1给出了一个略去时间维的m×n阶的评分矩阵,其中,m为系统中用户的数目;n为项目的数目;矩阵中的元素ru,i为用户u关于项目i的评分;0表示用户未对项目评分。
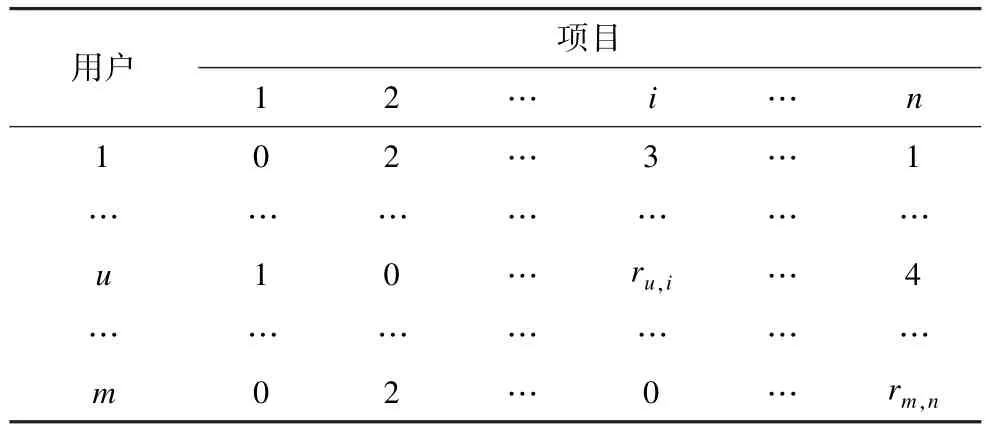
表1 用户-项目评分矩阵
3.1.1 可信度
下面首先基于矩阵R计算一个用户的可信性,可信性的大小称为可信度,它应该主要从用户评价等级、专业等级、评价偏差、活跃等级4个方面来进行衡量:
(1)用户评价等级:一个用户评价项目的数量越大,它的评价质量往往越高,这一点符合常理,即通常所谓的“见多识广”。为此,定义Qu={i∈I|ru,i≠0}为用户u评价过的项目集合,I为系统中的项目集合,“||”表示集合中的元素个数。则用户u的评价等级Nu表示为:
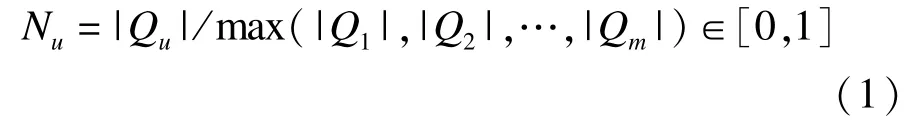
可以看出,Nu是用户评价项目数量的一个相对量,分母应该为“|I|”,却为某用户评价项目的最大值。这样做主要是因为系统中的|I|值太大,会使得Nu趋于0,失去了意义。而上述的做法却较好地避免了这个问题,同时可以鼓励用户多进行评价。
(2)专业等级:用户在某一方面具有专业能力、经验,显然它的可信程度会更高,更有说服力。这一点可以从矩阵R中反映出来,不过还需要借助系统中的项目属性数据。根据项目属性,系统会将所有录入的项目划分为不同的主题、类别等,表2给出了经过整理后一个简单的项目属性数据表,其中,A,B分别为项目主题;“1”表示项目属于该主题;“0”表示不属于。
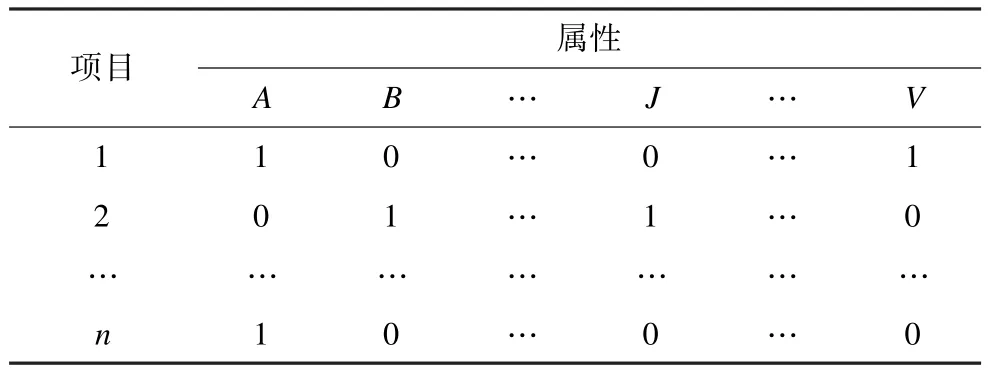
表2 项目属性数据样例
在这种情况下,一个专业用户显然会在一个主题或者少数几个主题的项目上投入较多的精力,从而表现为在相应主题上给出较多的评价。为此,令Tu,i={i∈I|ru,i≠0∧i∈A}为用户u评价过的并且属于某个主题A的项目集合,T为系统中获得过用户评价,且属于主题A的所有项目集合,于是用户u的专业等级Eu表示为:
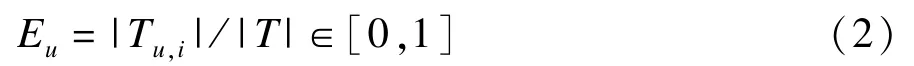
可以看出,Eu同样是一个相对量,分母可为属于主题A的所有项目数,这样做的原因与在Nu中相同。而且Eu的计算方法在一个项目同时属于多个主题的情况下同样适用。
(3)评价偏差:仅凭Nu和Eu还不足以证明一个用户的可信程度,还需看它在实际项目评价中的表现如何。为此,令Du为用户u项目评价的偏差度,表示如下:
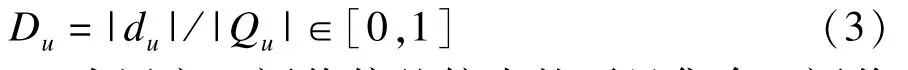
其中,du为用户u评价偏差较小的项目集合。评价偏差的判别标准是取一个参考值,用户的评价若与该参考值的偏差在一定范围内,如小于ε,则认为该评价偏差较小,并将评价对应的项目加入集合du中。现在问题的关键在于参考值选取,通常一个项目获得的评价均值可以在很大程度上表明该项目真正的品质或质量,因此可以选取该值作为参考值用来衡量用户评价的偏差,对于u和项目i:
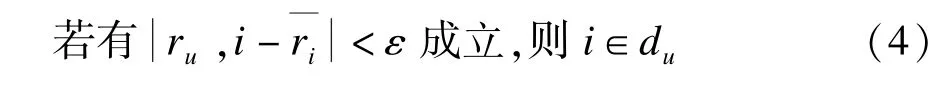
其中,为评价均值;ε为一常数,取值范围可以为[0,1],值越小表明要求越严格,相应的Du值就越小,文中实验的ε值取经验值0.5,这样的取值不至于苛刻,且可以获得较好的实验效果。
(4)活跃等级:在进行项目评价时,通常会咨询专家的意见。一个专家被咨询的次数反映了这个专家的阅历、经验等。为此下面再介绍一个活跃等级Ru的概念,用来衡量一个用户的经验值,不过这首先得取决于其专业等级Eu。具体的做法是,按照将每个项目对应用户u的Eu,按照取值大小进行降序排列,然后挑选前面M个用户作为项目评价时值得咨询的用户。这样统计每个用户在项目咨询用户队列中出现的总次数,计算其所占比例即得Ru值。显然Ru∈[0,1]值越大,表明用户提供建议次数越多,经验越丰富。
基于上述用户u的Nu,Eu,Du和Ru,以及相应的权重w11,w12,w13和w14,最终用户的可信度Tru可表示为:
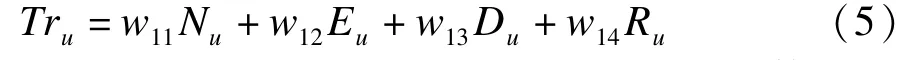
其中,w11+w12+w13+w14=1,关于权重的具体取值可以采取多种方式,如专家经验值、机器学习等,本文采用后者中的粒子群优化法,在训练数据集中不断进行交叉验证,最终获取一组较优的权重值,例如产生的其中一组权重值为(0.23,0.20,0.42,0.15)。
需要说明的是,Tru是一个可扩展性的概念,当需要考虑新的因素时,比如用户评价的稳定性问题,它可以进行进一步扩展。此外,Tru还可以看作一个维度可扩展性的向量,当需要扩展时,其维度可以由4维扩展至更大的维度,具体的处理方式视应用环境而定。
3.1.2 信任度建立
对于2个用户u,v,获得用户的综合可信度Tru和Trv后,便可以以此为基础进行交互建立对对方的信任度。由于交互行为需要双方对共同的对象有实际的交易数据以用作评估,满足这一要求的在矩阵R中即为用户的公共评价项目集合Iu,v,因此该过程必须以Iu,v={i∈I|ru,i≠0∧rv,i≠0}为基础。
在建立信任度的过程中,一方通常会向另一方咨询建议,当获得的建议与自己的初步想法大致一致时,该建议被视为有效建议,会被采纳,双方的信任感加强,否则视为无效建议。基于这样的一般过程,定义双方的信任度函数DT(u,v):
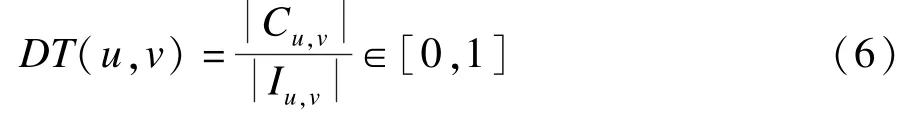
其中,Cu,v为Iu,v中用户v为u评分预测偏差较小的项目集合,这里关于项目i∈Iu,v采用的评分预测函数为:
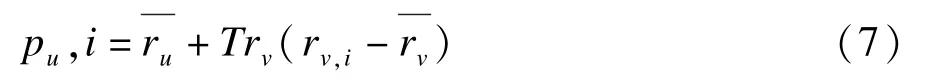
其中,和为用户的评分均值,其他符号的含义不再解释。为衡量预测偏差,定义与ε类似的另一常数ε1,取值范围仍为[0,1],为简单起见,具体取值与ε值相同,此时:

3.1.3 信任度度量
函数DT(u,v)相当于用户间的直接信任度,它满足信任的不对称性原则,即DT(u,v)≠DT(v,u)。除此之外,还需要度量用户间的间接信任度,又称为推荐信任度,因为通过自己的亲历和第三者的描述,才可以从不同角度更好的建立信任关系,推荐信任度的模型为:
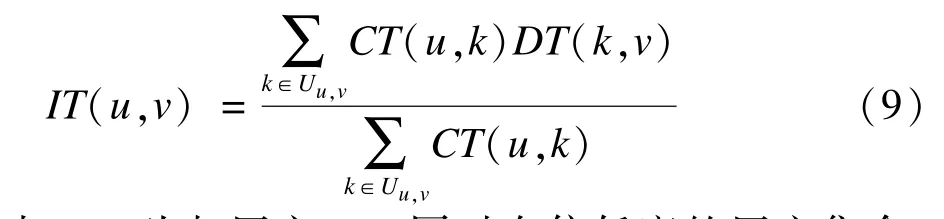
其中,Uu,v为与用户u,v同时有信任度的用户集合,这一点比采用公共项目集合更合理,而CT(u,k)为u对k另一种信任关系的度量,可以采用一种新的方法来计算 CT(u,k),为简单期间,本文仍然使用DT(u,k)。可以看出,IT(u,v)∈[0,1]同样满足信任的不对称性原则,它是u综合与v有信任关系的用户k对v的直接信任度而最终得到对v的推荐信任度。
结合用户u,v的直接信任度DT(u,v)和推荐信任度IT(u,v),可以获得用户间的最终信任度:
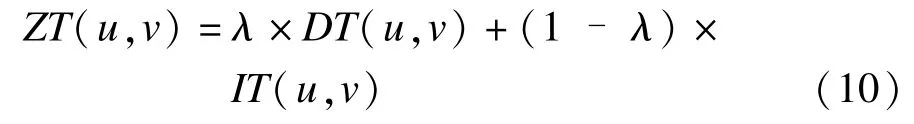
其中,λ为协调因子用作协调两方面信任度的结果,取值范围为[0,1]。对于λ的取值,本文不同于以往在[0,1]中取一系列观察值的做法,而是采用一种自适应模型来动态取值,这样可以在实际运行中随着条件的改变进行动态调整,从而增强了适应性。λ取值的具体表达式如下:
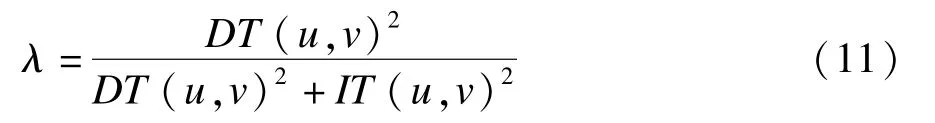
可以看出,当DT(u,v)为0时,λ为0,此时完全按照IT(u,v)来计算用户的信任度;反之当λ为1时,则完全按照DT(u,v)来计算用户的信任度。关于λ,不同用户间的DT(u,v)不同,它对ZT(u,v)的影响程度也不同,λ值满足这一点。而且当DT(u, v)较高时,说明用户此时在直接信任度方面具有更高的信任度,用户间的信任度应该更多的从这方面来考虑,λ值同样满足这一点,从而说明了λ取值的合理性。
3.2 信任填充矩阵
在评分矩阵R中,当获取用户间的信任度以后,目标用户便可以向比较信任的用户们提出建议咨询,即对未评分项目进行评分预测,具体步骤为:
孟鲁司特联合丙酸氟替卡松对儿童变应性鼻炎的疗效及血清IgE和炎性因子的影响(胡丽敏 闫志毓 郭光良)2∶99
(1)根据信任度大小选取一定数目信任度较大的用户建立信任近邻集合Trustu,这一步是关键。鉴于矩阵R的数据稀疏性,本文遵循“高度信任的朋友的朋友也是值得信任的”原则,不仅在与目标用户存在信任关系的用户中寻找信任用户,而且还在信任用户的信任用户中寻找信任用户。这样做符合信任的传递性原则,而且理论上可无限传递下去,但实际上根据信任的逐级衰减规律,当进行二三级传递之后,对象之间的信任程度就已经很小。为此,为降低计算复杂度和提高有效性,本文采取两级传递原则,最终目标用户与通过信任传递后的用户w的信任度表达式为:
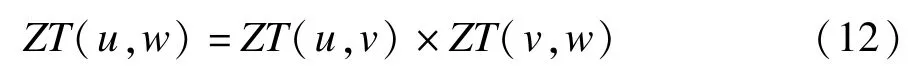
(2)根据集合Trustu中用户的评分,对目标用户未评分的项目利用预测函数进行评分预测。通常的预测函数有均值函数、权重函数以及修正的权重函数等,本文采用修正的权重函数来进行预测,其表达式为:
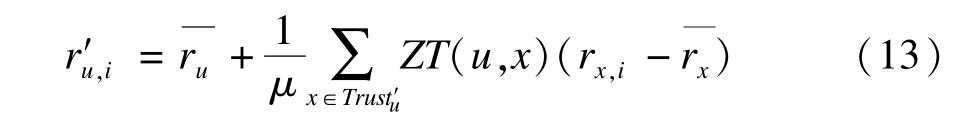
其中,r′u,i为预测评分;,Trust′u= {x∈Trustu∧rx,i≠0}为在Trustu中对项目i进行过评价的用户构造用户子集合,当Trust′u为空时,评分预测无法进行,此时r′u,i=0。然后将r′u,i填充到矩阵R的相应位置。
(3)重复进行步骤(1)、步骤(2),直到用户所有未评分项目的评分预测完毕,并填入到矩阵R的相应位置中去,最终获得填充后的评分矩阵,即信任填充矩阵TR。
3.3 项目相似性度量
矩阵TR大大提高了矩阵R的数据密度,基于TR可以从项目的角度出发获得项目相似性,常用的相似性模型有余弦模型、修正的余弦模型、Pearson相关系数模型以及受约束的 Pearson相关系数模型等。
本文采用第3种模型,因为在同等情况下它拥有更加优秀的性能[16]。Pearson模型的取值范围为[-1,1],其中,正值表示正相关,值越大相似性程度越高,负值表示负相关,对于项目i,j,表达式如下:
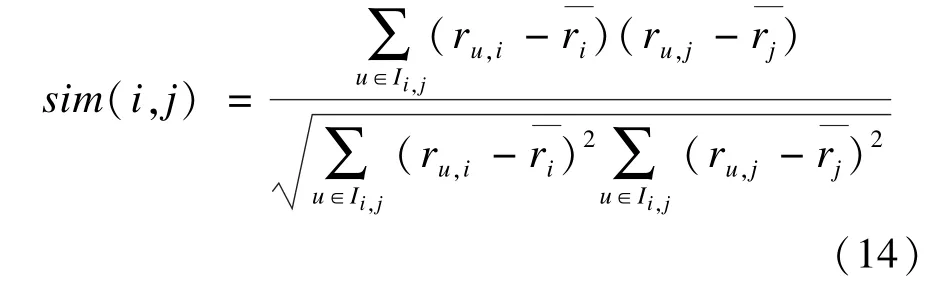
其中,Ii,j={i∈I|ru,i≠0∨ru,j≠0}表示矩阵R中项目i,j获得用户评价的用户并集集合。这样做相对于通常的I′i,j={i∈I|ru,i≠0∧ru,j≠0},一方面有利于发挥信任模型的作用,另一方面也可以避免I″i,j= {i∈I|r′u,i≠0∧r′u,j≠0}或者I‴u,v={i∈I|r′u,i≠ 0∨r′u,j≠0}所带来的计算复杂性。对于相似性sim(i, j),本文选取值大于0的项目对,因为通常的研究认为当值小于等于0时,对象之间便没有相似性。
除了项目的Pearson相关相似性,在实际中项目的相似性还体现在赢得用户的关注方面,即对于2个相似的项目,对它们感兴趣的用户类型也大致相同。为此可以从用户方面入手,通过对对项目进行评价过的用户特征进行分析,来了解到底哪些类型的用户对该项目比较感兴趣,或者说该项目可以满足用户的哪些属性需求,以此来度量项目相似性。不过,这一点需要借助用户属性数据来实现,用户属性数据与项目属性数据的格式大致相同,限于篇幅,这里不再给出。具体的做法是统计出对项目进行过评价的用户属性数量,当某一属性出现的频率相对较高时,说明项目可以较好地满足用户的这一属性需求。这样获得关于项目的用户评价属性次数向量,其维度与用户的属性个数相同如均为l,例如对于项目i, j来说,其用户评价属性次数向量Si,Sj如下:

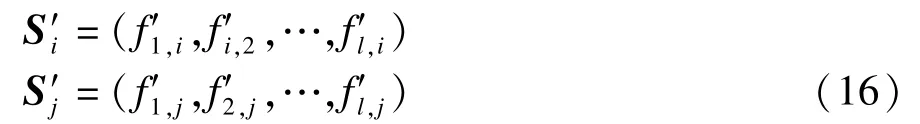
对于2个向量,本文仍然采用上文的Pearson模型来度量其相似性用sims(i,j)表示,表达式如下:
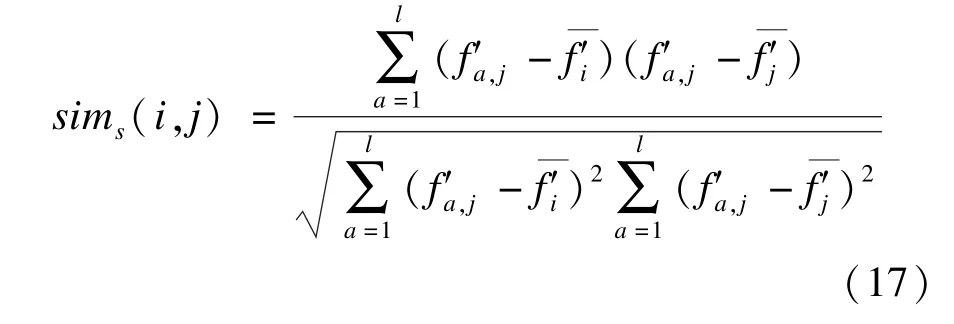
sim(i,j)和sims(i,j)分别从评分方面和用户方面度量了项目的相似性,综合两方面,可以获得更为全面的项目相似性用sim(i,j)表示:
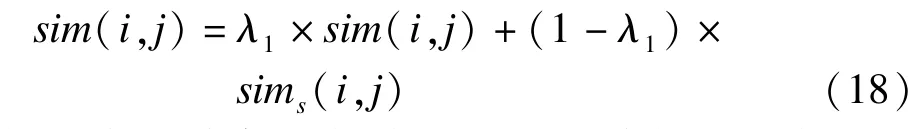
其中,λ1与λ类似,同为协调因子用来协调两方面相似性度量的结果,取值范围为[0,1],其具体取值同样采用自适应的方式:
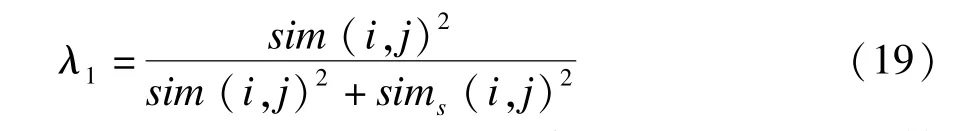
可以看出,λ1为0时,此时完全按照sims(i,j)结果来计算项目相似性,而当λ1为1时,则完全按照sim(i,j)来计算项目的最终相似性。
3.4 预测推荐与时间复杂度
根据项目的sim(i,j)值,首先选取值较大的相似项目来为目标项目i构造近邻集合Ki,它是协同过滤模型的基础,质量好坏直接关系着最终评分预测的准确性。然后利用Ki中的项目近邻为目标用户未评分的项目进行评分预测,具体的方法是:针对项目i,首先在Ki中选取目标用户u对其进行过评价的项目构造项目子集合ki={x∈Ki∧ru,x≠0},然后利用预测函数以相似性值为权重,加权用户u关于项目的评分,最终生成u关于i的预测评分Pu,i。关于预测函数,同样选取修正的权重函数,表达式如下:
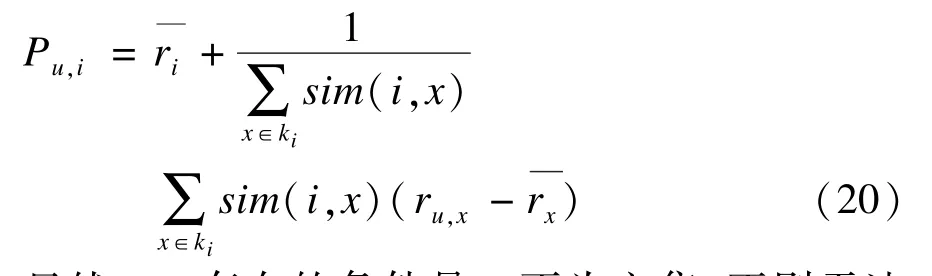
显然,Pu,i存在的条件是ki不为空集,否则无法为用户u进行评分预测。如此完成u关于所有未评分项目的评分预测,然后选取预测评分值最高的N个项目向u进行推荐,最终完成整个推荐过程。
关于模型的时间复杂度,由于整个模型需要分为多个步骤完成,而且除最后的预测与推荐外,其他的步骤均可以在系统后台通过离线的方式完成,所以这里不对其进行时间复杂度分析。而对于预测与推荐过程,它属于网站在线阶段需要完成的任务,需要花费的时间较短,同时也是系统性能的直观体现,因而需要了解它在整个过程中的具体时间复杂度。
在预测与推荐过程中,假设需要选取数目Q(Q为某一常数且Q<<n)的相似项目为目标项目构造近邻集合,然后预测函数需要经过常数次的加法、乘法操作来获得用户关于项目的评分。此过程最多需要进行n次,最后选取N个项目进行推荐,因而此过程模型的复杂度为O(n)。
4 实验验证与分析
4.1 数据集
实验使用的数据集是目前推荐模型研究广泛使用的Movielens 100K数据集,由美国Minnesota大学GroupLens Research实验室提供,并且可公众公共访问:http://www.grouplens.org。该数据集包含943个匿名用户关于1 682部电影的100 000个评分记录,其中每个用户至少对其中的20部电影进行评分,评分值范围为1~5的整数,5表示评价最高,用户最喜欢,0则表示用户未给出评分。除评分数据外,数据集中还包含了用户、项目的属性数据,例如用户的性别、年龄、职业等,以及项目的名称、上映年份、风格流派等,其中用户的职业(艺术家、教育者、律师等)和项目的风格流派(惊悚片、爱情片、冒险片等)是本文实验需要用到的。
为进一步检验推荐模型的有效性,除了Movielens 100 K数据集以外,实验还将引入另外一个 Movielens 1M 数据集,它同样由 GroupLens Research实验室提供。与Movielens 100 K不同的是,Movielens 1M 的数据量更大,里面包含了6 040个匿名用户关于3 706部电影的1 000 209个评分数据,且同样包含了用户、项目的属性数据,可以满足实验对于对象属性数据的需求。
实验中将2个数据集的用户-项目评分数据按照80%和20%的比例划分为两部分,前者作为训练集使用,用来构造推荐模型,后者作为测试集使用,用来检验模型的性能。
4.2 评估标准
关于推荐系统预测准确性的评估标准有很多,通常分为决策支持精度标准和统计精度标准两大类,本文采用后者中的平均绝对误差(Mean Absolute Error,MAE)来对评分预测的准确性进行评估。MAE作为一种常用的直观的度量误差的标准,原理是通过计算用户关于项目的预测评分与实际评分之间的偏差来表征预测的准确性,表达式如下:
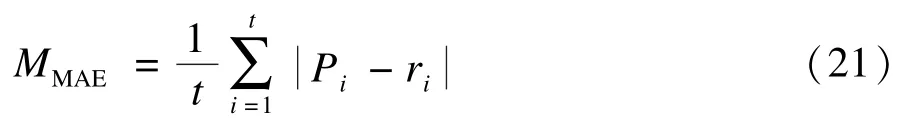
其中,测试数据集中的项目预测评分集合为{P1,P2,…,Pt},Pi为其中的一个预测评分,而ri则为与Pi对应的实际项目评分集合{r1,r2,…,rt}中的项目评分,t为集合中的评分数目。可以看出,MAE值越小,说明推荐模型的准确性程度越高。
4.3 协调因子比较
协调因子有不同的取值方案,下面将选取经验值因子(Experience Value Factor,EF)和不确定近邻因子(Uncertain Neighbor Factor,UF)2种方案,与本文的自适协调因子(Adaptive Coordination Factor, AF)进行比较,以了解不同的协调因子对推荐模型性能的影响。实验利用协调因子来协调基于用户和基于项目的相似性结果,其中的相似性模型统一为Pearson相关模型,相关参数设置见所在文献。图1给出了不同协调因子基于Movielens 100K数据集在不同项目近邻数目条件下的MAE比较结果。
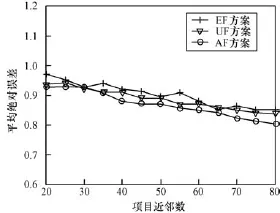
图1 不同协调因子的性能比较
从图1可以看出,比较EF和UF,AF模型在不同近邻数目条件下均表现出优秀的性能。这主要是因为AF中的λ1可以根据相似性度量结果来自动调整不同相似性所占的权重,从而可以获得更加准确的项目相似性,利于构造项目近邻集合。比较而言, UF则要人为设置调和参数,并需要对不同的参数设置结果进行实验观察验证,这会在很大程度上影响模型的性能,尤其是在实验条件不断变化的时候。同样EF也面临着与UF类似的问题,以致于使得模型的预测性能降低。
4.4 推荐模型比较
本节将选取CFIM[6]、UMCF[7]、IACF[9]模型与提出的CFTM模型在不同的项目近邻数目条件下进行实验比较,以检验不同协同过滤推荐模型的具体性能。实验以 MAE为评估标准,并分别基于Movielens 100K和Movielens 1 M数据集进行。
如图2所示,CFTM在实验开始时与IACF的性能相比并不占优势,仅比UMCF的表现略好,CFIM的表现就更差一些。这可能是由于IACF事先对稀疏的评分矩阵进行了预填充,并采用了相对较好的协调因子的原因。随着实验的进行,项目近邻数目的增加使得各个模型的性能表现均有所改善。此时CFTM相对IACF的性能优势也逐渐明显起来,这是因为CFTM一方面从信任的角度对评分矩阵进行了合理的填充,另一方面其项目相似性分别从用户和项目两方面入手,并利用λ1进行自动调整从而获得了更为准确的相似性度量结果。反观IACF,尽管缓解了数据稀疏性问题,但却需要根据实验条件来不断的获取最佳协调因子,会在相当程度上对模型的性能造成影响,尤其是在实际应用中对系统的性能影响会更大。在同等条件下,UMCF从用户的角度仅通过无优化的Pearson相关模型和余弦模型来获得分类的用户相似性,以及CFIM从项目的角度结合项目属性来获得项目相似性,其性能表现就要更差一些。
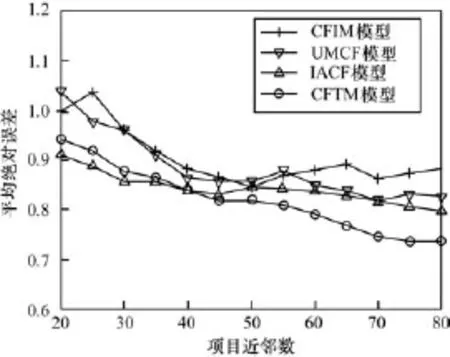
图2 基于MovieLens 100 K的性能比较
图3 的实验结果表明,在数据量更大的情况下, CFTM模型相比其他推荐模型仍然表现出更加优秀的性能,从而证明了所提模型在各种数据环境下具有较好的适应性。此外值得关注的是 IACF与UMCF模型相比,性能优势变得明显起来。出现这种情况主要是由于随着数据量的增大,IACF中的“云填充”模式能够很好地利用数据量增大带来的好处对用户的评分向量进行分析处理,从而为更好地度量项目相似性提供基础。比较IACF而言,UMCF和CFIM模型却没有这样的优势,以致在同等条件下性能表现较差。
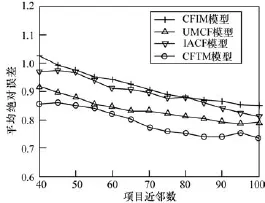
图3 基于MovieLens 1M的性能比较
5 结束语
本文从信任的角度出发,对传统的协同过滤推荐模型及其通常面临的数据稀疏性问题进行分析,结合信任模型提出了一种基于信任模型填充的协同过滤推荐模型。模型分析了信任包含的多个属性,并综合各个属性建立直接信任模型和推荐信任模型对原始的评分矩阵进行了填充,最终分别基于Movielens 100K和Movielens 1M数据集对获得的推荐模型进行了性能实验。实验结果证明,利用信任概念来解决数据稀疏性问题的思路是可行而且有效的,具体表现为与现有的改进协同过滤模型相比,所提模型在评分预测准确性方面具有明显的性能优势。下一步的研究是将信任的动态性属性体现在信任模型中,建立合理有效的时效函数,加强目前评价权重,同时降低时间较久的评价权重。
[1]刘建国,周 涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1):1-15.
[2]每日经济新闻.推销高手亚马逊的秘密[EB/OL].[2013-06-12].http://finance.ifeng.com/roll/201208 02/6859986. shtml.
[3]许海玲,吴 潇,李晓东,等.互联网推荐系统比较研究[J].软件学报,2009,20(2):350-362.
[4]杨兴耀,于 炯.融合奇异性和扩散过程的协同过滤模型[J].软件学报,2013,24(8):1868-1884.
[5]姜 维,庞秀丽.面向数据稀疏问题的个性化组合推荐研究[J].计算机工程与应用,2012,48(21):21-25.
[6]吴月萍,郑建国.改进相似性度量方法的协同过滤推荐算法[J].计算机应用与软件,2011,28(10):7-9.
[7]范 波,程久军.用户间多相似度协同过滤推荐算法[J].计算机科学,2012,39(1):23-26.
[8]朱丽中,徐秀娟,刘 宇.基于项目和信任的协同过滤推荐算法[J].计算机工程,2013,39(1):58-62.
[9]孙金刚,艾丽蓉.基于项目属性和云填充的协同过滤推荐算法[J].计算机应用,2012,32(3):658-660.
[10]刘庆鹏,陈明锐.优化稀疏数据集提高协同过滤推荐系统质量的方法[J].计算机应用,2012,32(4): 1082-1085.
[11]王 洋,骆力明.一种解决协同过滤数据稀疏性问题的方法[J].首都师范大学学报:自然科学版,2012, 33(4):1-5.
[12]夏小伍,王卫平.基于信任模型的协同过滤推荐算法[J].计算机工程,2011,37(21):26-28.
[13]卢竹兵,吴卫华,王 剑,等.基于信任管理机制的推荐系统研究[J].计算机工程与设计,2012,33(2): 566-569.
[14]杨长春,孙 婧.用户多兴趣信任度的个性化推荐[J].计算机工程与应用,2012,48(32):80-84.
[15]蔡 浩,贾宇波,黄成伟.结合用户信任模型的协同过滤推荐方法研究[J].计算机工程与应用,2010, 46(35):148-151.
[16]Bobadilla J,Ortega F,Hernando A.A Collaborative Filtering Similarity Measure Based on Singularities[J]. Information Processing and Management,2011,48(2): 204-217.
编辑 索书志
Collaborative Filtering Recommendation Model Based on Trust Model Filling
YANG Xingyao1,YU Jiong1,2,Turgun Ibrahim1,LIAO Bin1,2,YING Changtian1
(1.College of Information Science and Engineering,Xinjiang University,Urumqi 830046,China;
2.School of Software,Xinjiang University,Urumqi 830008,China)
Aiming at the problem of data sparsity in traditional collaborative filtering models,a collaborative filtering recommendation model based on trust model filling is proposed.The model gives emphasis to the trust attributes,and prefills the rating matrix by establishing trust model,in order to improve the data storage density.It obtains the similarity between items from the perspective of items and user attributes by similarity models.It coordinates the two types of similarity measurements by a self-adaptive coordination factor to gain final rating predictions of items.Experimental results,tested in different data sets,show that the newly proposed model can efficiently solve the problem of data sparsity in rating matrix,and provide better prediction accuracy of ratings involving an average improvement of 8%,compared with traditional collaborative filtering models.
recommendation system;collaborative filtering;trust model;user attribute;similarity model;Mean Absolute Error(MAE)
1000-3428(2015)05-0006-08
A
TP311
10.3969/j.issn.1000-3428.2015.05.002
国家自然科学基金资助项目(61262088,61063042);新疆大学优秀博士创新基金资助项目(XJUBSCX-2011007);新疆维吾尔自治区自然科学研究基金资助项目(2011211A011)。
杨兴耀(1984-),男,博士研究生,主研方向:推荐系统,网格计算,云计算;于 炯、吐尔根·依布拉音,教授、博士、博士生导师;廖 彬、英昌甜,博士研究生。
2014-07-25
2014-09-17E-mail:yangxy@xju.edu.cn
中文引用格式:杨兴耀,于 炯,吐尔根·依布拉音,等.基于信任模型填充的协同过滤推荐模型[J].计算机工程, 2015,41(5):6-13.
英文引用格式:Yang Xingyao,Yu Jiong,Turgun Ibrahim,et al.Collaborative Filtering Recommendation Model Based on Trust Model Filling[J].Computer Engineering,2015,41(5):6-13.