
融合热门度因子基于标签的个性化图书推荐算法*
2015-06-09 18:43徐文青双林平
图书情报研究 2015年3期
徐文青 双林平
(浙江工业职业技术学院图书馆 绍兴 312000)
融合热门度因子基于标签的个性化图书推荐算法*
徐文青 双林平
(浙江工业职业技术学院图书馆 绍兴 312000)
依照Web2.0的“社会化标注”思想,针对基于内容的推荐算法(CBR)和协同过滤推荐算法(CF)存在的不足,提出了基于读者标签(Tags)的、融合图书“热门度”因子的个性化图书推荐的两个改进算法。利用统计分析软件R,重点对改进后的CBR算法进行实验分析和验证,结果表明,改进算法的图书个性化推荐效果有明显改善。
图书个性化服务 推荐算法 标签 热门度
1 引言
图书馆作为学习者和研究者获取知识的重要场所,长期以来扮演着“被动”服务提供者的角色。通常图书馆信息服务系统所提供的查询和搜索功能主要取决于读者自己的主动操作,系统无法主动有效地针对某一读者的历史研究领域、借阅行为、兴趣偏好等提供个性化服务。随着现代信息技术的发展,“个性化”、“主动式”的图书推荐服务越来越受到重视。图书个性化推荐服务是根据不同读者的兴趣特征和历史借阅记录等信息,主动帮助读者从浩瀚的馆藏中发现其可能感兴趣的图书资源,并及时向读者推荐。除图书馆以外,目前个性化推荐服务还被应用在诸多其它领域,如:电子商务、Web信息检索等[1]。
早期的图书个性化推荐算法,主要利用读者的历史借阅记录进行“兴趣建模”[2],并在此基础上选择不同的推荐算法,以达到个性化服务的目标。随着信息技术的发展,特别是Web2.0的“社会化标注”思想[3-4]的出现,为图书馆个性化服务提供了一种新的途径。互联网上的社会化标注是指用户可以自由、自主地对网络资源打上特定的“标签(Tags)”。标签是用户根据各自认知、需求、偏好对感兴趣资源的一种个性化注释,是用户为资源添加的自定义关键词。在众多用户的分布式协同下,信息资源将被自组织和自分类,从而为用户对资源的浏览、回顾、组织、管理、检索及共享提供了可能,更重要的是在此基础上出现了个性化信息资源推荐机制。
参照“社会化标注”思想,若在图书馆藏信息管理系统的查询、检索和流通功能中,通过建立一种辅助机制,使读者可以对馆藏资源依据其个人的学术喜好、研究兴趣和主观分类加入特定的“标签”,留下其特有的个性化标注信息,在此基础上,便能实现本文所述的基于标签的图书个性化推荐服务。具体实现中,由于标签的数量和图书馆馆藏量通常相差好几个数量级,因而基于标签的分类推荐算法所需要处理的数据量远远小于馆藏索引信息的数据总量,从而使得基于标签的图书推荐系统拥有比较高的运行效率。
现有的一些基于标签的网络资源推荐算法,其主要思路是计算用户与资源的“匹配度”。匹配度较高的一些资源被视为候选推荐对象。分析发现,这些相似算法在“匹配度”的计算过程中,大多忽略了资源“热门度”这一重要的因子[3,5-6]。而从图书馆个性化服务的特性看,“热门度”无疑应在图书资源的推荐中起到重要的作用,成为个性化推荐算法的关键因子。基于以上分析,本文的主要工作是研究基于用户标签的图书资源个性化推荐算法,重点考虑结合“热门度”因子对已有算法加以改进,以期获得更好的推荐效果。
2 数据结构及符号说明
基于标签的个性化推荐算法的数据结构主要涉及:用户、标签、书籍及它们的三元关系(某读者给某本书打上某个标签)。我们用一个四元组D=
其中:U表示读者集合,集合内元素记为:u1,u2,……,un∈U;T表示标签集合,集合内元素记为:t1,t2,……,tm∈T;B表示书籍集合,集合内元素记为b1,b2,……,bl∈B;A表示读者对书籍添加标签的三元关系集,即:A⊆{(ui,tj,bk):1≤i≤n,1≤j≤m,1≤k≤l}。
此外,用UTi=(uti1,uti2,…,utim)来表示读者i使用标签的情况,表示用户ui使用标签tj次数,这里X{exp}为“示性函数”。当布尔表达式exp为真时X=1,否则为0。
同样,用类似方法表示书籍被标签的情况:BTK=(btk1,btk2,…,btkm)。其中:btkj=∑ni=1X{(ui,tj,bk)∈A}表示书籍bk被标签tj标记次数。在此我们需要对其进行“归一化”处理,即:BT*K=
3 CBR、CF推荐算法及其改进
3.1 基于内容的推荐算法(CBR)
一般的图书推荐算法其基本思想是:首先计算读者对馆藏资源的“评分”,然后依据评分高低向读者推荐。而基于内容的推荐算法(Content-Based Recommendation,简称CBR)的评分计算思想根据读者使用标签数据UTi与书籍被标签数据BT*K的匹配程度,计算出读者ui对于书籍bK的评分值[7]。此时,评分值的计算非常自然的可以使用内积法,即:

不难看出,依上式计算出的评分值仅依赖于图书的被标签数据和读者使用的标签数据。它并不直接来源于读者的评价,而是间接地通过对相关标签的计算而得。当然,在一定程度上标签本身也能反映读者对某一个资源的兴趣和偏好。CBR算法之所以被称为“基于内容”,正是由于它没有直接使用读者对书籍的评价,而是通过反映书籍内容的标签间接计算评分值。
3.2 协作过滤算法(CF)
协作过滤算法(Collective Filtering,简称CF),是在基于内容的推荐算法基础之上,进一步考虑了不同读者之间的关联性,通过将相似度较高的读者加以综合考虑,从而实现资源推荐的一种算法。
很显然,协作过滤算法的关键在于如何确定用户相似度的计算方法。通常的方法包括以下几种:
欧几里得距离法:即把用户评分I(ui,bK),k= 1,2,…,l,看做一个l维向量,然后计算其欧氏距离,即两个读者的相似度为:
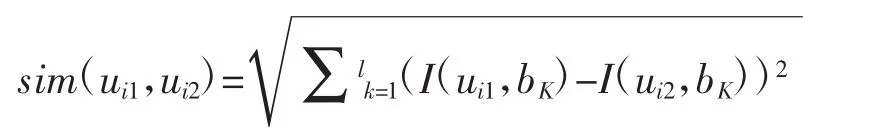
余弦相似性:即同样将用户评分看做维向量,然后计算两个向量夹角的余弦值,即他们的相似度为:

这里:I(ui)=(I(ui1,b1),(I(ui1,b2),…,(I(ui1,bl))。
相关相似性:即用Pearson相关系数计算读者相关度:
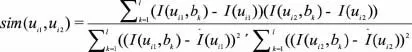
无论采用哪种办法,当求得一组读者的相似度后,可以根据其值的大小确定一个阀值thv,并取每个点的临近集Vi为|sim(ui1,ui2)|<thv⇔ui2∈Vi1|。
3.3 算法的改进
从上述两个算法分析中不难看出,在计算评分值和用户相似度中,尚存在以下问题:首先,在评分值的计算中,由于我们计算内积时对书籍的标签数据采取了归一化处理,这个过程实际上忽略了书籍的“热门度”这一重要因素。由于“热门度”是对某一图书资源被读者标签次数的一种度量,很显然,其值的大小反映了该资源受读者欢迎的程度,必须在推荐算法中加以重点利用。其次,在相似度计算中,由于计算内积前对读者标签数据未作归一化处理,将导致计算所得的相似度在某些情况下“失真”。如以下情况:读者A使用标签Tag1四次、标签Tag2两次,读者B使用Tag1两次、Tag2一次,那么在改进前的算法中,他们之间计算所得的“相似距离”是比较大的(表示两个读者的兴趣差异较大),但是这与实际情况不相符合。
综上所述,必须考虑在计算评分值的过程中将用户标签数据作归一化处理,同时在书籍被标签数据中加入“热门度”因子。需要注意的是,这里把热门度纳入考虑范围之内,并不意味着只需简单使用归一化之前的数据,如果是这样,则会让书籍热门度在评价中占据过大的权重。举例来说,若图书A被标签50次,图书B被标签100次,直接使用归一化前的数据计算评价度,两者将会相差两倍!这显然是不合理的。为此,在我们的改进算法中将使用一个保序变换来解决这个问题。
3.4 变换函数选择
基于上面的分析,我们的变换函数应当满足保序、且在被标签次数>0的范围内,变换后的两数比值不能过大,尽量做到可以使比值在[0.5,2]的范围内。为此,可以考虑使用指数函数,即:
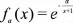
当然,上述变换函数选择不是唯一的。本文之所以采用指数函数是因为其比较简单,且既能达到将书籍的热门度加入评价考虑范围,又对评价结果不产生过大影响这样的效果。
3.5 CBR及CF改进算法描述
综上,经过改进之后,基于内容的推荐算法(NCBR)基本流程如下:①计算每本图书的被标签总数:;②通过变换被标签总数计算热门度系数:;③计算所有用户对每本图书的评分值:;④对图书按照评价度排序,并作推荐。

表1 用户、标签、书籍的三元关系
改进后的协作过滤算法(NCF)如下:①对用户数据做归一化处理:;②使用归一化后数据重新计算评价度:;③使用新计算的评价度,并选择某种相似度计算方法(欧氏距离、余弦相似性或者相关相似性),计算用户相似度sim(ui,uj);④选择阀值,并取每个用户ui的临近用户集Vi;⑤结合临近用户集,计算评价度:
4 实验分析
为了验证改进后算法的实际效果,在某职业技术学院图书馆做了实验分析(10位读者使用8个标签对20本书籍进行标签),采集了读者、图书、标签等相关原始数据,利用专业统计分析软件R进行了实验分析。由于实验规模较小以及读者样本数量的限制,协作过滤算法(CF)的实际效果难以体现。究其原因是因为实验样本中每个读者的临近集或者太少,或者就是几乎覆盖了全部测试读者,导致算法无法显现预期的推荐效果。
以下主要针对加入书籍热门度之后的改进算法(NCBR)与原基于内容的推荐算法(CBR)的实验结果比较分析。用户、标签、书籍的三元关系见表1,其中(i,j)处的数据表示读者j对图书i所添加的标签编号。经过计算,图书被标签情况如图1所示,经过指数函数变换后的热门度系数如图2所示。可以看到,在变换之后除了图书3因为没有被标记过,系数是0之外,其它书籍的系数都在[0.6,1]区间内,这是比较理想的情况。这里变换选用的系数α=0.5。
从算法的评价度计算结果可以看出,热门度系数的加入对书籍的评价度产生了不小的影响。由于所有读者对全部书籍的标签为一个10×20的矩阵,在此仅以读者1的推荐图书情况来分析算法结果。图3和图4分别为读者1在两种评分算法下的书籍评价度输出结果。不难看出,如果取评价度最高的3本书作为推荐图书的话,那么在不考虑书籍热门度情况下入选的图书为{1,5,8},而在加入热门系数之后推荐的图书则成了{1,9,20}。为了显示出书籍热门度在其中作用,我们给出图书被标签次数如表2。
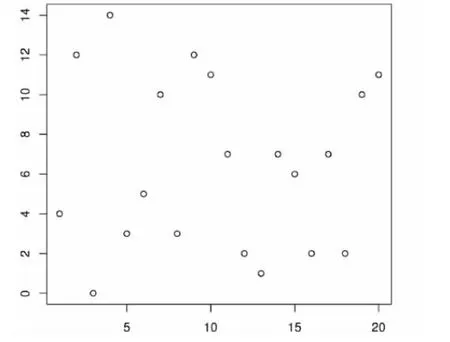
图1 图书被标签数
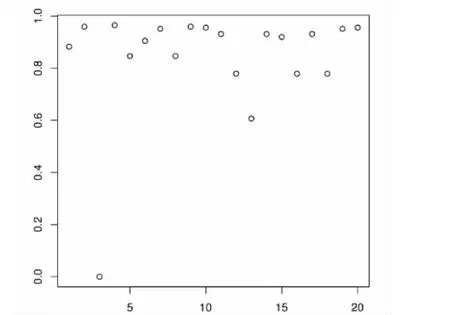
图2 图书热门度系数
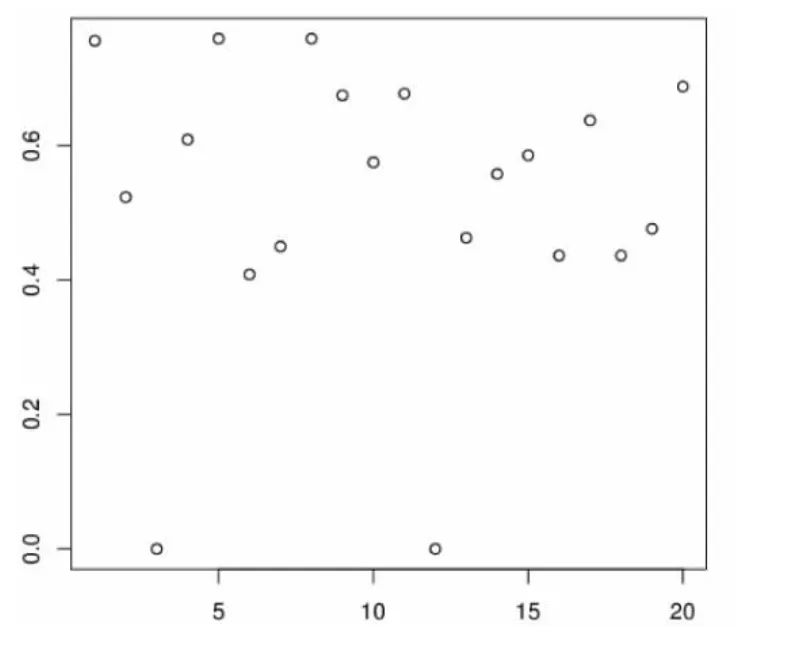
图3 算法CBR下读者1的评价度
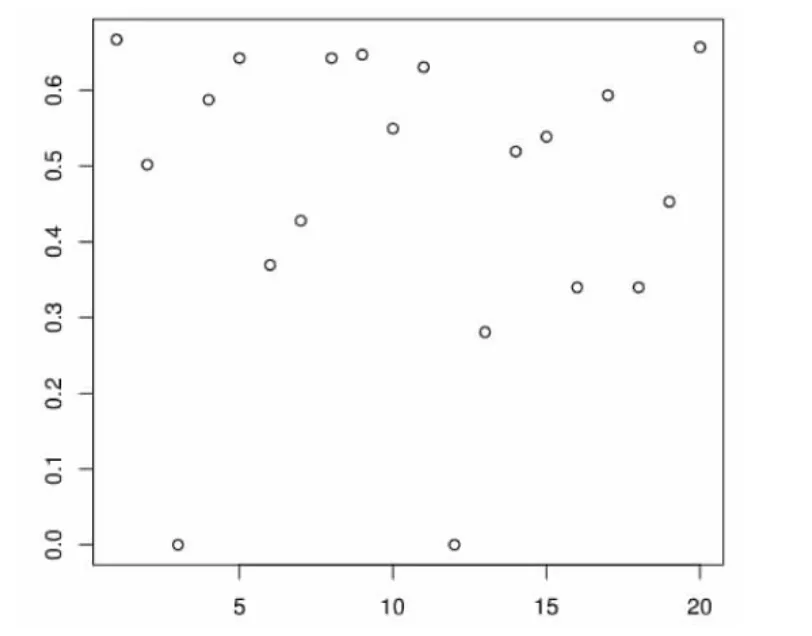
图4 算法NCBR下读者1的评价

表2 图书被标签次数
读者1对应的标签数据为(5,0,3,2,1,1,1,1),5本图书对应被标签的数据依次为:(2,0,0,0,1,1,0,0),(2,0,0,0,0,0,0,1),(2,0,0,0,1,0,0,0),(5,3,0,0,0,0,3,1),(1,0,3,3,0,0,3,1)。可以看出,读者1对于带有标签1,3,4的书籍比较感兴趣,而用不考虑热门度的CBR算法计算得出的推荐图书{5,8}虽然都被Tag1标签较多,但是实际上它们的热门度是很低的(仅被标签3次)。而图书{9,20}在热门度很高的情况下(被标签分别11,12次),与读者1的偏好非常匹配,书籍9主要被标记为1号标签,而书籍20主要被标记为3,4号标签。这说明在考虑了热门程度之后的推荐结果是非常合理的。
5 结语
随着数字图书馆的发展,个性化图书推荐系统的地位日益重要。相关调查结果显示,读者对图书借阅的个性化服务需求程度是个性化服务功能需求中最高的[8]。本文所讨论的融合热门度因子基于标签的个性化图书推荐算法,利用了Web2.0的社会化标注原理,非常适用于图书馆的个性化推荐服务。后续将在目前工作的基础上,引入聚类方法,进一步优化推荐算法。
[1] 李树青,徐 侠,许敏佳.基于读者借阅二分网络的图书可推荐质量测度方法及个性化图书推荐服务[J].中国图书馆学报,2013(3):83-95.
[2] 徐文青,范一鸣.扩展的VSM图书馆读者兴趣建模技术研究[J].图书情报工作,2012(5):119-122,138.
[3] 田莹颖.基于社会化标签系统的个性化信息推荐探讨[J].图书情报工作,2010(1):50-53,120.
[4] 吴思竹.社会标注系统中标签推荐方法研究进展[J].图书馆杂志,2010(3):48-52.
[5] 陈毅波,揭志忠,吴产乐.基于同义标签分组的协同推荐[J].湖南大学学报(自然科学版),2011(5):83-88.
[6] 蔡孟松,李学明,尹衍腾.基于社交用户标签的混合top-N推荐方法[J].计算机应用研究,2013(5):1309-1311,1344.
[7] 张 红,甘利人,薛春香.基于标签聚类的电子商务网站分类目录改善研究[J].现代情报,2012(1):3-7.
[8] 杨 涛,曹树金.图书馆用户的个性化服务需求实证研究[J].大学图书馆学报,2011(2):76-85.
(责任编校 骆雪松)
Personalized Tag-based Book Recommendation Algorithm Combined with the Factor of Popularity
Xu Wenqing,Shuang Linping
Zhejiang Industry Polytechnic College Library,Shaoxing 312000,China
In accordance with“socialized tagging”of Web 2.0 and in view of the shortcomings of the content-based recommendation algorithm(CBR)and the collaborative filtering recommendation algorithm(CF),we proposed two refined book recommendation algorithms which are based on tags and combined with the factor of popularity.In this paper, a small-scale experiment using statistical analyzing software R was made along with an analysis of the refined content-based recommendation algorithm(NCBF).The experimental results show that the refined algorithms remarkably improved the effectiveness of personalized recommendation algorithm.
personalized book service;recommendation algorithm;tag;popularity
G252
徐文青,女,1968年生,馆员,研究方向为图书个性化服务等,发表论文6篇;双林平,女,1964年生,馆员,研究方向为数字图书技术等,发表论文12篇。
*本文系浙江工业职业技术学院2013年科研计划项目“个性化图书服务系统的应用研究”(项目编号:2014242)的研究成果之一
猜你喜欢
公民与法治(2022年10期)2022-10-12
疯狂英语·新读写(2022年6期)2022-06-08
疯狂英语·读写版(2022年6期)2022-06-08
当代作家(2018年11期)2018-11-27
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
海外星云(2016年7期)2016-12-01
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
大众创业(2009年10期)2009-10-08
