
中国和加拿大合作出生队列研究数据统一及共享方法
2015-06-08 10:31周光迪吴美琴赵丽吴宇航翁鑫宇蒋聪赵莎莎王伟业
中国医药生物技术 2015年6期
周光迪,吴美琴,赵丽,吴宇航,翁鑫宇,蒋聪,赵莎莎,王伟业
出生缺陷、代谢综合征、儿童孤独症、多动症、哮喘、糖尿病、不孕不育、肥胖、心脑血管疾病等多种疾病都与胎儿期的环境暴露关系密切[1-2],所以出生队列研究等针对生命早期环境暴露的研究近年来迅速发展,对病因学研究有着关键的推动作用。大样本量对于统计结果准确性的提升至关重要,单个项目常因资源不足而影响统计分析,而大型队列项目所需的资源量从时间、人力和物力方面难以实现,这样的矛盾直接影响了基于队列数据的后续研究[3]。因此,非常有必要整合不同队列之间的信息,并进行共享,来解决大样本量和大资源消耗量之间的矛盾[4]。
项目资源之间的信息统一(data harmonization)与共享(data sharing)在国际上已经开展多年,最显著的例子是生物医学资源整合机构 BBMRI 采用分布式中心(distributed hub)的模式,将样本和数据存储于分布式中心,由虚拟的中心用联邦制方式管理数据[5]。目前,国内资源共享的项目尚缺乏经验和模式。信息共享模式主要有三种,第一种为直接集中数据,将各中心数据直接集中在一起,统一管理、分析、利用。优点是标准统一、便于大数据整合,缺点是可变性小,可行性低。因为各研究中心往往有不同的研究偏向,不同的具体条件,不同的知情同意与伦理法规。在这样的前提下,强行统一变量的选择和数据标准并不现实,几乎无法实施。第二种共享模式为通过最小数据集,即不同项目按相同的定义和标准来收集共同的最核心数据,用这些核心数据来代表研究群体的特性,并在项目之间共享。这种模式的可行性和可变性比直接集中数据高得多,所以多家国家标准化研究机构都聚焦于某一特定领域数据集,开展多中心合作。第三种共享模式是在项目已经进行、数据已经收集后,再开始数据共享工作,就会发现由于项目各方的变量定义、收集标准、数据分级等很多问题上不一致,即使只是实验检测方法或标准的不同,都会给数据共享造成困难。这样的情况下需要首先转换统一变量,让数据同质化、提升数据的相容性。这种模式的主要步骤是针对已经完成和存在的信息资源首先分析可能统一的数据元素,将统一后的数据元素作为多方共同的数据集,再通过分析在统一数据元素的前提下的项目信息,以适应前瞻性队列项目的需要。
本文将要介绍的中国和加拿大合作出生队列数据信息共享项目(简称中加出生队列项目)是一个大型队列数据共享项目,参加本项目的队列包括中方的上海儿童优生队列(SBC),加方的 3D(design-develop-discover)出生队列和母婴环境化学物质研究(maternal-infant research on environmental chemicals,MIREC)出生队列。其中 SBC 计划招募 4000 位孕妇,3D 和 MIREC 计划招募 2000 和2500 位孕妇。三个队列的研究方向各有不同,其共同焦点是探索环境因素影响胎儿在母体子宫内发育及出生后发育生长至成人阶段可能出现的不良影响。在三个队列分别进行了一段时间后,中加双方才开始接洽队列信息共享的工作,所以本项目需要整合三个队列的数据资源,但已经存在的数据存在异质性而无法直接整合。三方的变量选择、定义、标准都有巨大差异,已经不可能统一标准收集数据或直接统一数据集,所以将首先同质化三个队列项目的数据,再进行数据共享。像中加出生队列项目这样各方先收集数据、再接洽整合数据资源的情况普遍存在,但缺少数据同质化和整合的模式和方法。队列项目,尤其是跨国的队列项目之间的数据资源整合,往往面对多重的伦理法规限制,各方的数据统一后也不一定能够整合。中加出生队列项目在实现三个队列研究数据共享、为病因学研究提供大数据分析结果的同时,更能为类似情况的国际数据共享合作项目提供模式和方法上的重要参考,并为如何在符合国际伦理规范的前提下进行跨国数据共享树立范例。
1 方法
1.1 制定数据词典
数据词典定义数据流图中的各个成分的具体含义,对数据流图中出现的每一个数据流、文件、加工给出详细定义。在中加合作项目中,三个队列根据加方其他机构在相同方面的研究经验以及规范化工作流程及 Maelstrom 技术要求,制定各自的数据词典。
1.2 建立双方数据集交流平台
将三个队列的数据词典上传至 Maelstrom 网站,将其作为三个队列之间的交流平台。Maelstrom 网站公开展示参与队列的数据集,并能够进行相关的搜索和对比,便于参与队列展开数据同质化和共享工作。同时,其他任何对参与队列有兴趣的人都可以通过 Maelstrom 了解参与队列的数据集,并联系队列开展合作。
1.3 统一数据元素和最小数据集
双方相互分析对方的数据词典中参数变量内容,了解各自项目研究信息内容的设计,充分交流三个队列的研究方向。在 Maelstrom 网站上使用 Search Harmonization Potential 功能,搜索出三方都收集的变量,对这些变量进行可同质化水平划分,分为“完全相容”、“部分相容”、“完全不相容”三个级别。完全相容的变量可以直接共享;部分相容的变量进行同质化转化、规范数据交换格式后再共享;完全不相容的便不能共享。在选择变量和转化变量后,制定编写合作方能共享的最小数据集。
2 结果
2.1 制定数据词典
在本项目中,根据加方其他机构在相同方面的研究经验以及规范化工作流程及 Maelstrom 技术要求,中加双方三个队列制定了各自的数据词典。仅队列 SBC 的数据词典就前后编写了 7 版,反复修订后最终定稿。表1 列出了三个队列的变量总数。表2 对比了三个队列关于孕妇血压参数的标签。
2.2 建立双方数据集交流平台
本项目参与构建了 Maelstrom 网站(https://www.maelstrom-research.org/)作为公开的信息交流平台。网站上展示了项目的基本情况、数据集、变量,具有同质化搜索功能,也提供一些信息同质化的教程和参考文献(图1~3)。
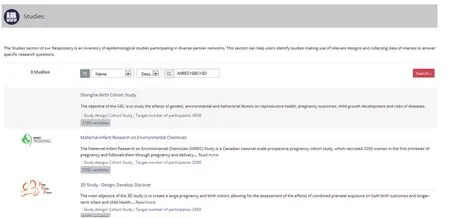
图1 Maelstrom 网站上中加项目三方队列的概况
2.3 统一数据元素和最小数据集
数据元素是用一组属性描述定义、标识、表示和允许值的一个数据单元。最小数据集是为特定目的收集的、最少的、被用户和利益相关人认可的一组选择性的核心数据。出生队列研究的最小数据集收集的数据是反映出生队列研究所关心科学问题的核心数据,该数据在跨研究小组、跨地区研究机构之间的共享有助于发挥最小数据集信息的利用价值,提高队列研究水平和数据的利用效率。

表1 三个队列的变量总数

表2 三个队列关于孕妇血压参数的标签对比
对于完全相容的变量,各方对变量的定义和数据处理方式基本一致,可以直接共享数据;而对于部分相容的变量,双方的提问方法、数据采集方式或其他操作细节存在差异,但本质科学问题相同,可以通过特定方式将变量转化一致,使得这些变量也能够完成数据相容。对于不能相容的变量,由于各方的变量定义和数据收集方式存在不可调和的矛盾,无法共享数据。例如,中加双方对于“装修”的科学定义不同,双方在相关问题上无法共享数据。中方定义为房屋的粉刷、装饰、修葺;而加方定义为新的装饰、家具,这样的定义差距无法调和,双方在“装修”问题上研究的不是同一科学问题。
根据目前的研究进展,三个出生队列所收集的数据能形成 18 个可能会产生最小数据集的研究方向,包括:母亲年龄、家庭收入、婚姻状态、种族、孕前期 BMI 指数、孕期吸烟状况、孕期饮酒状况等。本研究项目已经完成关于孕期吸烟情况调查和妊娠高血压数据的最小数据集的编写。表3是这两个数据集所包含变量数的具体情况。
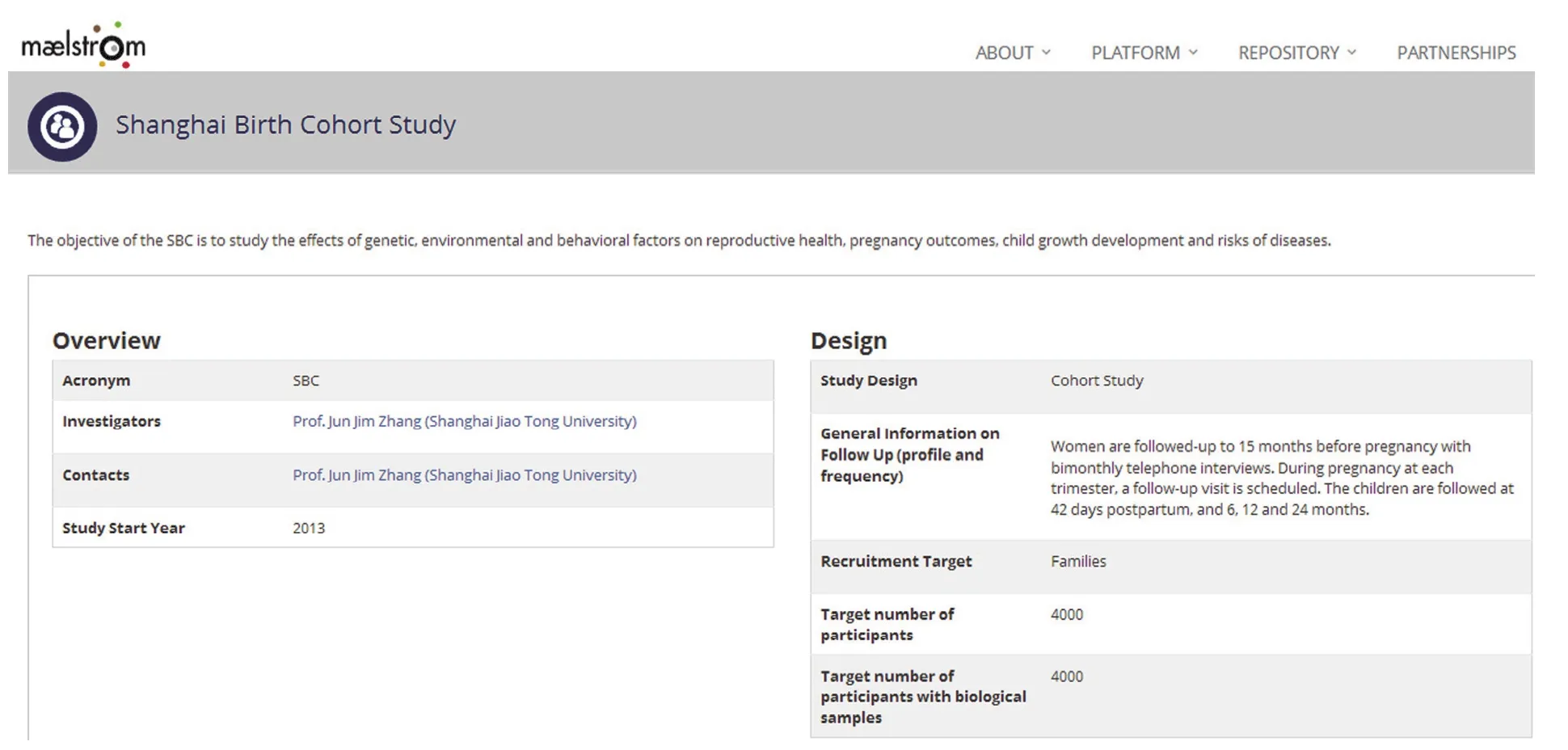
图2 Maelstrom 上队列 SBC 的简介
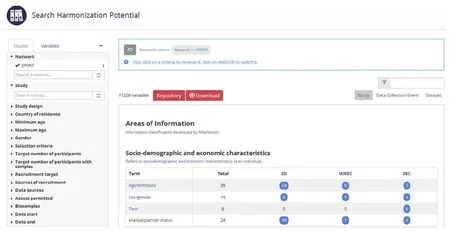
图3 Maelstrom 上对三个队列同质化潜能搜索的结果

表3 孕期吸烟情况与妊娠高血压的最小数据集包含变量数
3 讨论
现在,多方参与的队列信息资源共享项目很多,但存在的难点和问题也不少。第一,不同的出生队列研究方向不同,收集的变量不同,且缺乏统一的数据收集标准与交换格式,致使收集的数据可比性无法得到保证,数据存在很大的异质性,缺乏共享前提。跨系统、跨部门、跨地区的数据共享受到数据异质性的制约,同时数据的重复采集还导致了资源的浪费。因此,如何提高不同队列之间的数据相容性,是很有现实意义的问题。其次,在管理层面上实现数据的整合共享也存在一些困难,国内目前缺乏多中心研究合作的成功模式,如何借鉴国外的先进经验,并研发完善国内适用的多中心研究资源共享的整合方法,值得我们探索和思考。第三,伦理和法律对数据的整合共享有多重限制,尤其是跨国项目。捐献者的知情同意有可能规定数据不能提供给他人,法律也可能规定某类研究的数据只能在某个范围内运用。而中加出生队列项目在这三个问题上都有创新性的解决方案。
国际上的多方数据共享项目,一般都是在开始项目之前,就有共享数据的意愿,因此在项目设计时,从招募捐献者,变量的选择和定义,变量可同质化的潜力水平衡量,到共享平台的搭建,都会考虑到后期共享数据的需要,例如著名的 BioSHaRE 项目[6]。但国内这样的前瞻性共享项目很少。中加出生队列项目是在各个项目开始后才开始接洽数据共享,项目设计、捐献者招募、变量选择、数据收集等过程均已完成,此时想要用预见性的模式来完成共享是不可能的。那么,先收集数据再共享的前提下,数据共享需要首先完成数据的同质化。参与中加项目的三方队列首先完成了数据词典的编写,这是为了便于三方了解彼此的研究方向,三方在哪些领域出现研究交集,在哪些方面的变量能够共享,在同一变量的定义、收集与质控标准上有何异同、怎样实现数据的同质化。随后又建立了数据交流的网络平台Maelstrom,便于多方交流,并统一了能够同质化的变量和最小数据集。
而由于伦理法规的限制,中加出生队列项目不能以数据池的方法来共享数据[7],因为合作队列 MIREC 所在地的法律规定,MIREC 的数据只能够留在本地。所以 MIREC 的数据只能经过数据屏蔽处理,通过分布式统计,再以总结分析结果的方式共享[8-9]。但是,总结式的分析结果相对于数据池的结果具有一定的片面性,不能等同于真正的大数据分析结果,数据池的共享方式能提供的结果更为客观。所以,在伦理法律允许的前提下,SBC 将与 3D 通过统一的数据集的方法,将数据整合在一起,相当于加大样本量[10],统一进行查询、分析。在本项目中,同时使用两种共享模式,因为既需要满足伦理法规的要求,又需要尽可能用更客观的方式分享数据。其他的项目也可以考虑通过多种数据共享模式来满足参与项目所面对的不同伦理法规需要。另外,除了查询分析,SBC、3D、MIREC 的研究结论也可以互作验证性的比较分析,提高统计结果的可信度和可靠性。
多中心临床研究如果能在实施前统一信息的内容、采集方式、方法和处理标准,就能极大地提升后续的数据统一成功率和工作效率。然而和中加出生队列类似,国内的大多数数据共享项目都是在数据收集开始后才有共享意向,这样的流程导致不同项目之间的数据很大的异质性。如何同质化数据、实现数据的融合,采用什么方式在满足伦理法规的条件下充分共享数据,使多方的共享意愿变为现实是非常急迫的问题。中加项目针对数据已经收集、数据异质性已经存在、无法直接整合数据的前提下,通过自有的工作流程实现了数据的同质化,为数据的整合扫平障碍。在事先未统一设计的队列研究所获得数据的同质化和共享问题上,中加项目作出了意义重大的探索性工作,其模式和方法有着重要推广的价值。截至目前为止,中加出生队列项目已经完成了数据词典的制定,建立了数据集交流平台,转化和统一了部分共享课题的数据集,接下来中加项目将在数据共享模式上继续下一步工作,在工作过程中进一步探索并建立跨国家、跨地区队列合作模式,促进多中心信息整合和科研合作,为之后的中外国际队列数据共享项目提供可参考的操作方式。
[1]Winckelmans E, Cox B, Martens E, et al.Fetal growth and maternal exposure to particulate air pollution--More marked effects at lower exposure and modification by gestational duration.Environ Res, 2015,140:611-618.
[2]Manzano-Salgado CB, Casas M, Lopez-Espinosa MJ, et al.Transfer of perfluoroalkyl substances from mother to fetus in a Spanish birth cohort.Environ Res, 2015, 142:471-478.
[3]Bebu I, Lachin JM.Large sample inference for a win ratio analysis of a composite outcome based on prioritized components.Biostatistics,2015, pii:kxv032.
[4]Howe D, Costanzo M, Fey P, et al.Big data: The future of biocuration.Nature, 2008, 455(7209):47-50.
[5]Muilu J, Peltonen L, Litton JE.The federated database--a basis for biobank-based post-genome studies, integrating phenome and genome data from 600,000 twin pairs in Europe.Eur J Hum Genet, 2007,15(7):718-723.
[6]Doiron D, Burton P, Marcon Y, et al.Data harmonization and federated analysis of population-based studies: the BioSHaRE project.Emerg Themes Epidemiol, 2013, 10(1):12.
[7]Pisani E, AbouZahr C.Sharing health data: good intentions are not enough.Bull World Health Organ, 2010, 88(6):462-466.
[8]Jones EM, Sheehan NA, Masca N, et al.DataSHIELD -- shared individual-level analysis without sharing the data: a biostatistical perspective.Norsk Epidemiologi, 2012, 21(2):231-239.
[9]Fortier I, Burton PR, Robson PJ, et al.Quality, quantity and harmony:the DataSHaPER approach to integrating data across bioclinical studies.Int J Epidemiol, 2010, 39(5):1383-1393.
[10]Smith-Warner SA, Spiegelman D, Ritz J, et al.Methods for pooling results of epidemiologic studies: the pooling project of prospective studies of diet and cancer.Am J Epidemiol, 2006, 163(11):1053-1064.
猜你喜欢
中国药学药品知识仓库(2022年8期)2022-05-09
华人时刊(2021年23期)2021-03-08
科学导报·学术(2020年26期)2020-10-21
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
福建基础教育研究(2019年4期)2019-05-28
军营文化天地(2018年2期)2018-12-15
中国知识产权(2018年10期)2018-11-02
现代交际(2018年11期)2018-09-26
影视与戏剧评论(2016年0期)2016-11-23
