
对中国基础通货膨胀指标的研究
2015-06-06 11:50:48MarleneAmstad马国南
财务与金融 2015年5期
Marlene Amstad 叶 欢 马国南
对中国基础通货膨胀指标的研究
Marlene Amstad 叶 欢 马国南
对于货币政策决策者和市场参与者来说,通货膨胀都是个关键的宏观经济变量。论文建立了一个新的中国基础通货膨胀度量指标(CUIG),可以区分趋势和噪声,可以按日计算,而且使用了可能影响通货膨胀的大量经济变量。该指标的构造方法以Forni等人2000年的动态因子模型研究成果为基础,并已经在纽约联储和瑞士央行进行了成功的运用。和CPI相比,这个指标更平滑,但也不像传统核心通胀指标那样去除了过多波动性。这个指标能紧密追踪CPI,同时能提供传统核心通胀指标不包含的额外信息。最后,预测统计检验证明这个指标在不同的样本区间对CPI的预测表现都好于传统核心通胀指标。
通货膨胀 动态因子模型 预测
一、导 言
通货膨胀是重要的宏观经济指标。在大多经济体中,度量通货膨胀最重要的指标是各国统计部门公布的消费价格指数(CPI)或个人消费支出(personal consumption expenditures,PCE)指数的同比增长率,但这些官方通货膨胀指标至少存在三个问题:一是短期波动明显,很难判断指标的变化是临时性的还是发生了趋势改变。二是只包含价格变量,而不包含会影响通货膨胀的失业率和产出缺口等信息,即忽视了关于当前和未来通货膨胀的许多其他可用信息。三是通常每月公布,这在正常情况下是够用的,但在经济出现剧烈波动的时期,例如在全球金融危机时,可能需要一个频率更高的通胀指标。
为了解决波动性过大的问题,学者们提出了“核心通货膨胀”方法。这些度量方法通过剔除波动性大的特定价格分项或者降低它们的权重来减小波动。最常见的核心通胀度量方法是剔除食品和/或能源价格。也有方法剔除某个时点特定比率(如25%)的最高和最低的价格变动,即“修削均值(trimmed mean)通货膨胀”。这些方法假设大的价格变动是临时性的,但剔除这些价格变动可能损失有助于预测通胀的信息。
为了解决信息少和频率低的问题,也可以使用基于市场交易的通货膨胀指标,例如根据通胀保值债券(treasury inflation protected securities,TIPS,或者叫实际债券)和名义债券(不提供通胀保值)收益率之差算出的盈亏平衡通货膨胀率。这种通货膨胀率每天都有数据,而且它反映的是市场对通胀的判断,包括各种各样的信息。但它具体包括哪些信息,它们的权重如何变化,都是不明确的。
中国已经每月公布两种传统的核心通货膨胀度量:剔除食品的CPI(CPI_nf)和剔除食品及能源的CPI(CPI_nfe)。但中国目前没有通胀保值债券,不能推算盈亏平衡通货膨胀率。
在这篇文章中,我们建立了一个新的度量指标——中国基础通货膨胀指标(Chinese underlying inflation gauge,CUIG)。它更为平滑,是以一个大数据集为基础的,并可以每日计算。要强调的是,我们的CUIG指标并不能被解读为替代CPI的通货膨胀度量指标,而是为了提供一个新的补充性的通货膨胀信号。
CUIG以一个已经被证明非常有用的计量经济模型为基础,这个模型常用来为不同经济体预测经济增长(GDP)和通货膨胀。在构造CUIG时,我们使用与构造美国通货膨胀指标的纽约联储基础通货膨胀指标(FRBNY staff underlying inflation gauge)和瑞士通货膨胀指标的瑞士央行动态因子通货膨胀指标(SNB dynamic factor inflation)同样的模型和参数设定 (Amstad,Ye and Ma,2014 and Amstad and Potter,2009;Amstad and_Fischer,2009a)。虽然文献中有很多类似的GDP和通货膨胀预测研究,但据我们所知,这是这种模型第一次应用于新兴市场国家和中国。
本文主要构建了CUIG,并将它的统计特征与CPI和传统核心通货膨胀指标进行了比较。文章的其余部分结构如下:第二节介绍了估计方法。第三节讨论使用的数据集,包括数据种类和质量,样本长度和春节效应。第四节说明参数选择的原因。第五节通过比较平滑性、与CPI的相关性以及和传统核心通货膨胀指标相比增加的额外信息来考察CUIG的统计特征。按照Cogley(2002)和其他学者的方法,我们也考察了不同基础通货膨胀指标进行通货膨胀预测的相对表现。第六节做出结论:CUIG在经典预测检验中的表现超过了传统核心通货膨胀指标,为货币政策决策者和市场参与者提供了更多的信息。
二、方 法
我们选用的模型应该具有两个特征 (Amstad,叶和马,2015):
首先,模型要能产生一个平滑的信号来区别噪声和趋势,同时又和传统的核心通胀指标相反,不直接剔除变量。我们使用傅里叶变换来完成这个目标,它是把一个时间序列(所谓“时间域”)写成若干个正弦函数(所谓“频域”)的数学公式。单个正弦函数有三个特征:振幅(对平均值的最大偏离)、频率(1秒内发生的循环个数)和相位(先行或滞后)。高频率代表波动剧烈的时序,而低频率代表平滑的时序。把时间序列转化为在频域上表达,使得研究者能区别噪声和趋势的定义,剔除明确定义的频率带宽。
其次,它应该能把多个变量综合为一个或几个变量。为了建立一个可以持续更新的信号,我们需要模型要能处理一个特别大的数据集。随着时间的流逝,与通货膨胀相关的变量可能发生变化,在中国这样一个快速发展的新兴市场经济体中尤其如此。如果频繁改变数据集,就很难判断得到的信号的变化是因为数据集本身变化还是通胀形势出现了变化。因此,应该尽量保持数据集不变,使数据集包含与通胀相关的尽可能多的变量,在每次更新时,模型将决定不同输入变量的权重,来解释每个时点通货膨胀的变化。
从我们的需求看,因子模型是个很明显的选择。在因子模型中,Forni,Hallin,Lippi and Reichlin (2000)提出的广义因子模型(后面简称为FHLR)特别适合我们的目的,因为它在平滑输入变量时正是使用的傅里叶变换,而且它可以处理大量的数据。
假设一个i=1,…N个时序的面板,xit=(x1t,x2t…, xNt)′是0均值的宽平稳过程的实现,并把它看作是一个无穷序列的元素。在传统的动态因子方法中,假设每个时间序列都有测量误差,可以分解为两个不可观测的正交部分的和:
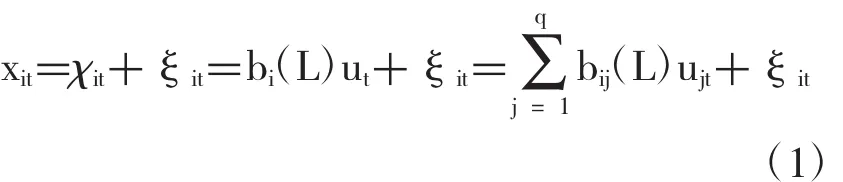
其中χit是共有的部分,由具有非奇异谱密度矩阵的q个动态共有冲击ut=(u1t,u2t…,uqt)驱动,ξit是特异的部分,反映测量误差和局部冲击。bi(L)是s阶滞后多项式的向量,反映因子动态。对于所有的k 和i,ξit都和共有冲击ut-k是正交的。传统的动态因子模型假设特异部分ξit都是相互正交的。Forni et al.(2000)提出了一个广义动态因子模型,放松了这个假设,允许有限的动态相关性。由于正交性不再作为xit和ξit理论上的差异,就需要Forni et al. (2000)给出的其他假设。在满足这些假设时,上面描述的模型就是个广义动态因子模型。
为了根据每日公开的信息考察最及时的数据信息,我们使用的数据在末端是不平衡的。因此
有些序列结束于T期,其他则结束于T+1,…, T+w期。把变量xi,t重新排序为:
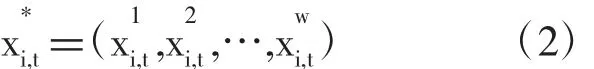
其中xJi,(tJ=1,…,w)把变量根据最后一个观测值的时点T+J-1分组。同样的,协方差矩阵也分块如下:
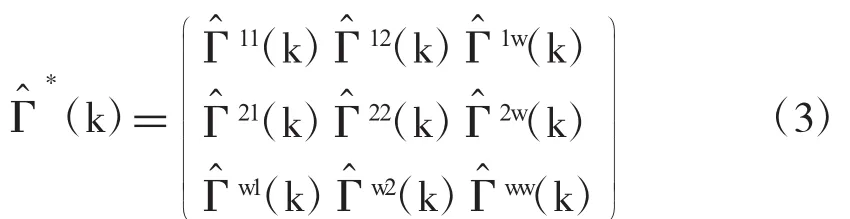
模型估计使用MATLAB软件,所用程序根据Forni,Hallin,Lippi,and Reichlin(2000)的原始程序改编。
三、数 据
这一节讨论了生成CUIG的数据集,讨论了数据口径和质量、样本长度和春节效应。数据集是一个包含473个数据的面板,这些数据覆盖了中国经济的关键方面。
(一)数据范围和质量
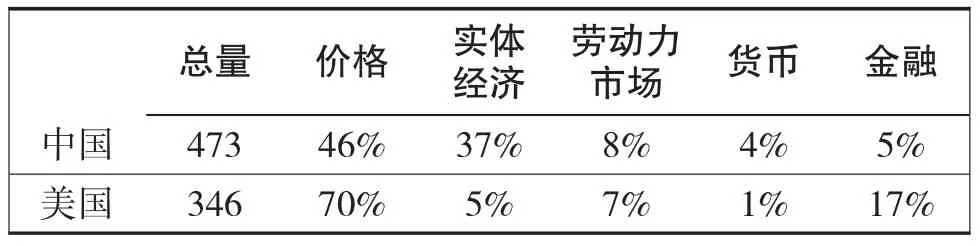
表1 中国和美国输入变量的数量和构成
我们的数据集包括以下五个主要的种类:(1)价格;(2)经济活动;(3)劳动力市场;(4)货币和信贷;(5)金融市场。在实践中,我们尽量把数据集保持在可操作的规模,选择每类数据中最典型的指标。
我们的数据集一共包含473个变量,而美国类似的通货膨胀指标(Amstad,Potterand Rich,2014)有346个变量,瑞士(Amstad and Fischer,2009a and b)有454个变量。表1展示了中国和美国这五个种类数据的分布。由于目标变量是通货膨胀,因此价格类是最多的,在中国占整个数据集近一半,在美国占三分之二。
具体来说,价格类包括所有主要的价格指标,例如CPI及其构成、零售价格指数(RPI)、生产者价格指数(PPI)、企业商品价格指数(CGPI)和进出口价格指数。经济活动类包括名义和实际数据,例如工业增加值、投资、零售、贸易、住户调查和公司调查。劳动力市场数据主要包括平均工资和总工资,就业和失业。货币和信贷数据包括关键的货币总量、银行贷款和存款。金融市场数据包括利率、汇率和股票市场价格指数。最后,由于中国越来越融入全球市场,我们的数据集也包括主要的国际商品价格和中国最大的五个贸易伙伴的一些选定的数据。每个贸易伙伴占中国出口总量的百分比都不少于5%,合计占中国出口的70%。
我们的数据集有五个重要特征。第一,大多数数据变量是月度的,但一些经济活动和劳动力市场变量是季度的,而大多数金融市场数据是日度的。
第二,最理想的情况是所有的时间序列都应该是名义值。但受数据可得性限制,我们也考虑以实际绝对额、名义同比增速和实际同比增速的形式存在的变量。
第三,数据集中所有数据都没有进行季节调整,因为模型的滤子将以谱密度分析为基础,统一地通过除去所有变量中某些高频部分对所有变量进行季节调整。
第四,我们对受到春节效应影响的序列进行了调整,因为春节效应是因为春节在一月和二月不规则地移动,不符合规律的季节性模式。我们使用取1月和2月平均值的现实方法除去春节效应的影响。
第五,为了得到一个无偏的信号,数据集中所有数据都检验了平稳性并做了相应处理,对I(1)数据取一阶差分,对I(2)数据取对数后差分。
根据菲利普斯曲线,劳动力市场状況对通货膨胀有较大影响。但中国劳动力市场数据目前覆盖面有限,质量还不理想。我们还是把这些劳动力市场数据放进数据集中,因为未来随着数据质量的提高,它们与通胀的相关性可能也会增强。我们也加入了住户收入调查数据来补充工资数据,减弱它们的质量风险。
(二)样本长度
模型要求所有的数据起始点相同,选择数据集时需要同时权衡样本大小和样本长度。一方面,数据集应该尽可能大,能覆盖上面讨论过的所有数据。另一方面,为了得到稳定的通货膨胀信号,数据集又要足够长,要包含数个通货膨胀周期。我们选择数据集从2001年1月开始,主要是以下两个原因:
首先,许多序列在2001年之后有更详细的分项数据。另外,在20世纪末,中国大多数消费价格已经完成自由化,能更好地反映基础通胀压力。
其次,2000年至2001年,中国的通货膨胀动态似乎发生了明显的机制变化在2000年以前,中国的通货膨胀率要高得多,而且波动很大,在超过20%的高峰和明显通货紧缩的低谷间波动。而在后一个时期,即2001年1月至2013年12月,中国经济经历了至少三个“表现良好”的通货膨胀周期,通货膨胀要比之前上世纪八十年代和九十年代的两个周期低得多,波动性也小得多。另外,2000年之后中国的通货膨胀动态更多地与国内和外部的周期性冲击相关,与管制价格的自由化及投资和工资设定预算软约束行为的相关性减弱(Kojima et al,2005)。
有很多因素可以解释2000年之后通货膨胀机制变化的原因,包括计划经济向市场经济转变,价格管制的放松,供给增加,宏观经济管理能力提高,逐渐变化的汇率机制和外部冲击等(Giradin et al 2014)。中国2001年加入WTO也是其经济的一个重要拐点,一是为了准备迎接更多的外国竞争,国内经济进行了广泛的结构改革,二是中国经济越来越融入全球市场。选择样本起始点为2001年1月,可以提取一个反映最近的中国通货膨胀模式的通胀信号。
样本中仍有三分之一(176个)的数据序列的起始点在2001年以后。为了补齐数据开端的缺失观测值,我们使用一个名为“搭桥”的简单回归方法。假设样本范围是t期到T期,短数据序列Y从t’期到T期,要补齐t期至t’期的Y的缺失值。首先,选择另一个长度覆盖整个样本期的序列X作为Y的解释变量,在t’期至T期估计一个简单的线性回归方程Y=α+β*X。然后,使用估计出来的参数α和β的值计算t期至t’期的Y的拟合值。最后把得到t期至t’期拟合值和t’期至T期的实际值放在一起,就得到完整的t期到T期的序列Y。在这个方法中,长序列X就像一座桥一样,因此要仔细选择与Y高度相关的X。在大多数情况下,我们选择一个范围更广的全样本变量作为其较短的子项的搭桥变量。
这种方法让我们能补齐短数据前端的缺失值,同时不在数据集中引入额外的信息。我们比较了分别从整个数据集和剔除了补齐序列的数据集提取的信号,发现两者非常相似,证明补齐的短数据并不会扭曲最终的信号。但我们还是数据集里加入这些短数据,因为它们可能在未来变得更加重要,能为通胀信号提供信息。
四、模型参数的确定
这一节讨论使用第三节中的数据建立第二节中的模型需要选定的参数。主要需要确定两个参数:一是每个输入变量要除去的频率带的宽度(b),二是要估计的共有因素的个数(q)。
(一)对平滑程度的选择
我们把短于12个月的频率定义为噪声。我们选择剔除短于12个月的周期,主要基于三个考虑。

表2 CPI和不同频率被去除的CUIG的标准差(S.D.)
首先,这个选择背后的原理是货币政策通常不能影响一年内的通货膨胀,因为货币政策存在时滞。其次,在美国和瑞士的案例中,纽约联储和瑞士央行的模型分别决定忽略短于1年的周期。第三,我们在表2和图1左图展示了CUIG对于不同带宽的敏感性。如果去掉12个月以下的频率,得到的CUIG保留了多于80%的CPI波动性。如果短于2年或3年的频率被去掉,相应的CUIG波动性就分别跌至65%和49%。这样波动性就下降过多,可能失去很多信息。
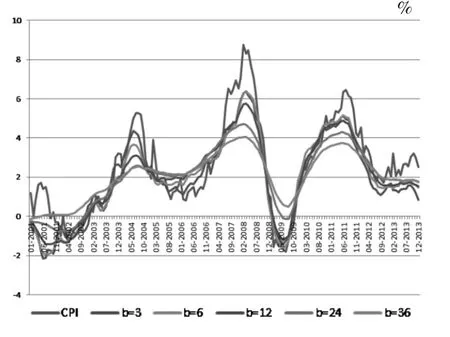
图1 不同频率被去除的CUIG
(二)因子数量的选择
因子模型的主要特征是:它能把许多输入变量的信息总结为有限几个正交的因子。通常根据因子对输入变量的联合变化性的解释份额排序,将其记为第一个、第二个、第n个因子。因子数量应该足够高到能反映基础输入变量的特征,又要足够低到确保模型的节俭性。对于宏观经济应用研究,学者们的共识是两个因子就应该能反映输入变量的特征。在构建基础通胀指标时,常常直接认为这两个因子分别反映实际的和名义的驱动因素。
数据来源:作者计算。
表3 CPI和不同因子个数的CUIG的标准差(S.D.)
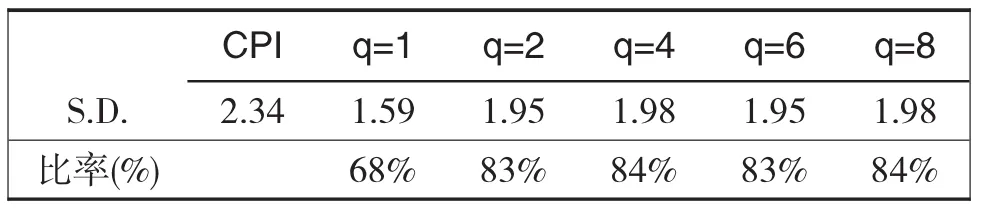
在这篇文章里我们也使用两因子方法,主要有三个原因。首先,在我们这个应用中,我们并不直接使用因子作为信号,而是用因子作为解释变量对CPI进行回归,将得到的估计值定义为CUIG。其次,在美国(Amstad,Potter and Rich,2014)和瑞士(Amstad and Fischer,2009b)的案例中,已经证明两个因子是合适的。第三,敏感性分析显示两个以上的因子影响很有限。图1右图和表3给出了选择因子个数为1、2、4、6和8时的CUIG结果。这些CUIG的拐点区别很小,但因子数定为1的CUIG明显不同,它的标准差仅是目标变量CPI的66%。在选定因子个数为2及以上时,这个比率提高并停留在80%左右。
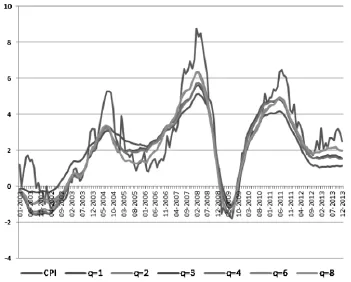
图2 不同因子个数的CUIG
五、统计特征和预测表现
在这一节,我们对比传统核心通胀指标,对CUIG进行评估,首先比较它们的统计特征,然后进行经典预测检验。
我们选择对比的传统核心通胀指标包括国家统计局公布的剔除食品的CPI(CPI_nf)和剔除食品及能源的CPI(CPI_nfe)。为了参考,我们也在预测检验中加入了一个中国人民银行工作人员内部使用的核心通胀指标(UCPI),它剔除了波动性更大的新鲜食品价格而不是全部的食品价格以及一些政府定价产品的价格。为了比较预测能力,所有的序列都要2001年开始。我们同样使用“搭桥”方法补齐这些核心通胀指标。
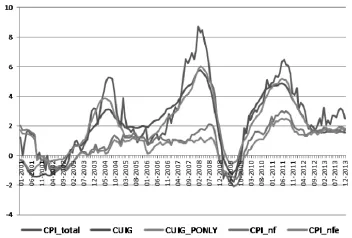
图3 CPI、CUIG和传统核心通货膨胀度量
图3显示两个传统核心通胀指标的波动性大幅减小。CPI的波动范围在-2%到+8%,而CPI_nf和CPI_nfe都只在-2%到+2%。在CPI的三次高峰中,有两次传统通胀指标都没有提前警告债券投资者和政策决策者会有一个上升的通胀趋势。
(一)统计特征
在这一节中,我们对比传统核心通胀指标,使用三个统计标准“平滑性”、“与CPI的相关性”和“额外信息”评估CUIG的作用。
平滑性是一个好的通货膨胀指标的重要特征,因为它减弱了决策者对短期波动的依赖。同时,作为通胀指标,它需要与CPI有较高的相关性。第三个标准是这个通胀指标是否能提供比公开的传统核心通胀指标更多的信息。为了确保检验的稳健性,我们使用了两种CUIG:以全部数据集为基础的基准CUIG和以价格数据子集为基础的CUIG(CUIG_ponly)。CUIG和CUIG_ponly使用同样的构建方法和参数设定。
1、平滑性
根据标准差矩阵,CUIG和CUIG_ponly的波动性都比CPI低约20%,但都比传统核心通胀指标高(表4)。这反映了一个在建立中国核心通胀指标时常常谈到的困境(ADB (2008),Cheung et al (2008)):从CPI中剔除食品价格减小了波动性,同时损失了宝贵的信息。虽然官方CPI中食品和能源价格的权重还未公布,但可以肯定的是这个权重比美国高得多(ADB,2008)。另外,如果从CPI中剔除食品和能源,CPI的波动性减小太多,同时也损失了可能对预测CPI非常有用的信息。CPI_nf把CPI的波动性减小了一半,CPI_nfe甚至减小了三分之二。

表4 标准差
2、与CPI的相关性
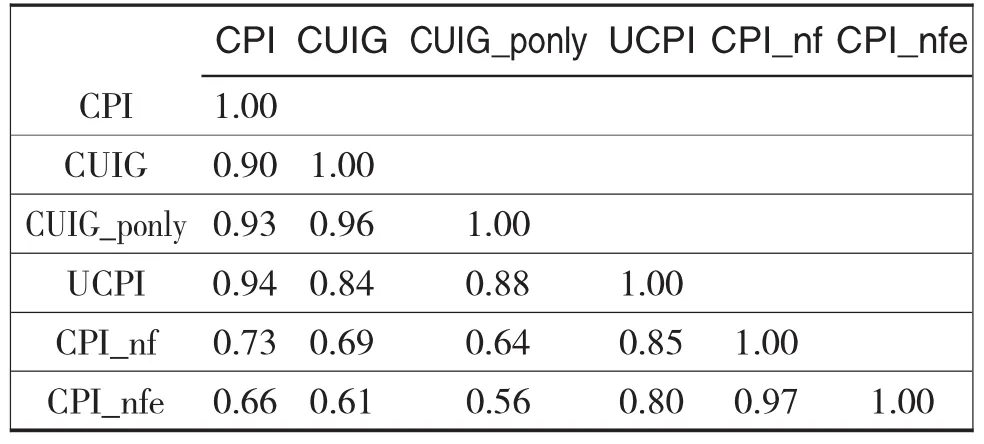
表5 相关系数
如表5所示,CUIG和CUIG_ponly都能紧密追踪CPI,相关系数均约0.9-0.91。然而,传统核心通胀指标如CPI_nf和CPI_nfe与CPI的相关系数就小得多(0.75和0.71)。UCPI与CPI的相关性最高,达到0.95。
3、额外信息
我们使用两种统计方法评估一个通胀指标是否在统计上与另一个指标相似或不同:一是简单的不同核心指标间的相关系数,二是主成分分析。
如果两个通胀指标相关系数低,则它们是非常不同的通胀信号。如表5所示,CUIG和CUIG_ponly与传统核心度量(剔除食品的CPI和剔除食品及能源的CPI)相关性最低(0.69-0.75)。同时,中国人民银行监测的UCPI与传统核心通胀指标和我们的CUIG、CUIG_ponly的相关系数均为0.8左右。很明显CUIG和CUIG_ponly提供了与传统核心通胀指标不同的信号,与剔除食品的CPI和剔除食品及能源的CPI区别更大。这个结论可以由CPI和所有考察的通胀指标的一个简单的主成分分析(PCA)进一步证明。如表6所示,所有通胀指标96%的变动都能由两个因子解释。从各变量在前两个主成分中的系数看,CUIG、CUIG_ponly和CPI相似,而CPI_nf和CPI_nfe则与CPI明显不同,UCPI介于两者之间。

表6 主成分分析
(二)预测表现
为了辨别出最好的基础通胀度量,我们使用一个被广泛接受设定背景(Rich and Steindel,2007)下的经典预测检验。
进行检验首先要选择预测合适的样本期。样本期太长可能包括不同的通货膨胀机制,而太短的样本期可能在统计上不显著,或者代表性不足。此外,在通货膨胀表现非常平稳的时期,变化最小的信号(例如一个常数)可能比从前期波动较大的通货膨胀中提取的信号表现更好。因此,要选择一个通胀表现出显著波动性的时期进行检验,而且要尝试不同的子样本区间。2001年之后的中国通货膨胀在2008年之前比较平稳,而在2008年之后波动较大。然而,由于我们的样本仅从2001年开始,而且估计期不能短于预测期,因此我们使用以下两个预测样本期:包含危机年份的2008-2013年,以及包含一个完整的上升下降通胀周期的2006-2013年。
首先我们考察形如估计方程(4)的预测结果:
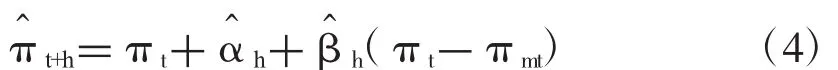
其中πt是t期的通货膨胀率,πmt代表要考察的核心通胀指标是使用至t期的数据估计的回归系数。
估计从2001年开始。我们将CUIG的预测表现与CPI_nf和CPI_nfe比较。为了检验稳健性,在CUIG之外,我们也在预测检验中包括了CUIG_ponly。和预测表现评估的通常做法一致,我们也包括CPI本身的12个月滞后(CPI12)作为随机游走基准。
表7表明CUIG和CUIG_ponly预测CPI的表现在完整周期和危机样本中都明显优于传统核心通胀指标,CUIG的RMSE最低。为了进一步分析CUIG的预测表现,我们应用了Diebold-Mariano (1995)检验程序,以CUIG为基准,判断其RMSE是否显著优于其他各指标RMSE。我们得到了五个很有意义的观察结果。
首先,CUIG的RMSE显著低于传统核心通胀指标,也低于CUIG_ponly。CUIG在2006-2013年完整周期和2008-2013的危机样本中都显著好于CPI_nf。只有在2008-2013年的危机年份中,相对于CPI_nfe,CUIG和CUIG_ponly优越性的显著性水平是12%,不那么明显。然而,在2006-2013年的完整周期中,CPI_nfe在3%的显著性水平上比CUIG和CUIG_ponly表现得更差。

表7 预测表现
第二,结果表明CUIG和CUIG_ponly的预测误差确实有显著差异。这个结果与美国案例(Amstad, Rich and Potter,2014)中使用类似方法建立通胀指标并进行相同检验得到的结果相同。然而,在中国的案例中,显著性水平略低。作为敏感性测试,我们对一个较短的样本期做了同样的评估,发现如果把样本末端取2012年6月,CUIG和CUIG_ponly的预测误差就没有显著差异了(见表8)。这个结果跟Holz and Mehrotra (2013)的发现是一致的,他们发现中国劳动力成本的提高没有完全传导至最终价格,在可贸易品部门和整个经济体中都是如此。我们把这个解释为中国CPI中某些价格变量,尤其是食品价格具有决定性影响的另一个证据。在中国CPI篮子中,虽然食品的权重没有公开,但估计达到30%(ADB,2008),而在美国食品只占16%。以后食品变量的重要性可能下降,CUIG可能会表现得比CUIG_ponly更好。
第三,所有基础通胀指标都比CPI本身的12阶滞后表现好。并不让人意外的是,在通货膨胀波动特别大时,随机游走预测在完整循环和危机样本中都是所有指标中预测误差最大的。

表8 不同样本长度的预测表现比较

1、均方根误差(Root Mean Square Errors,RMSE)。2、Diebold Mariano(DM)统计量。3、Diebold Mariano似然性(DM p值)。注:RMSE越小,则预测误差越小。DM统计量及DM p值反映其他变量的RMSE是否与CUIG的RMSE存在显著差异。数据来源:作者计算。
第四,传统核心通胀度量CPI_nf和CPI_nfe在所有样本中的预测表现都相当类似。这个结论和Rich and Steindel(2007)对美国的研究结论一致,证明不同的传统核心通胀指标在预测表现上区别不大。
第五,常见的传统核心通胀指标与其他指标相比的相对预测表现,在危机期间好于危机之前。这个结果也和Amstad,Rich and Potter(2014)对美国的研究一致。
(三)意义
总的来说,结果说明政策决策者和市场参与者使用不同的核心通胀指标互为补充是很有意义的。传统核心通胀指标容易计算和解释,而CUIG在预测中显然表现得更好。UCPI看起来是两者的混合,它在预测表现上与CPI_nf、CPI_nfe这两个传统核心通胀指标并没有统计上的不同,但在统计分析中它被分到和CUIG一组,反映出某些相似性(这种相似性证明保留部分食品价格的重要性)。把CUIG和其他所有核心通胀指标区分开来的特征是:CUIG包含更多数据,而其他方法剔除数据。
一方面,剔除法指标具有容易计算和容易向公众沟通的优点。另一方面,在某些特定价格分项(比如食品)变得不再重要的同时,劳动力市场和金融市场变得更加重要,这样在预测通胀时加入额外数据可能越来越重要。总之,政策决策者和市场参与者可以使用我们讨论过的所有的核心通胀指标,包括这个新建立的CUIG,共同判断通胀趋势。
六、结 论
这篇文章第一次介绍并建立了一个中国新的基础通胀指标(CUIG),讨论了建立该指标的模型的计算和参数设定。我们的模型和参数设定类似纽约联储基础通货膨胀指标和瑞士央行动态因子通货膨胀指标。我们简述了数据方面的挑战,并对比其他传统核心通胀指标(剔除食品的CPI和剔除食品及能源的CPI)比较了CUIG的统计特征和预测表现。CUIG能区分趋势和噪声,以大数据集为基础,而且可以每日计算。这些特性使得CUIG和其他核心通胀指标明显区别开来,它可以作为一个货币政策决策者和市场参与者使用的一个新的通胀度量。
CUIG比CPI波动小,但不像中国传统核心通胀指标那样丢失过多波动性。CUIG紧密追踪CPI的走势,同时能提供传统核心通胀指标不具备的额外信息。最后,我们通过一个统计预测检验证明CUIG在不同的样本区间对CPI的预测表现都优于传统核心通胀指标。
[1]Amstad,M.,叶欢和马国南 (2015):“对中国基础通货膨胀指标的研究”,中国人民银行工作论文No.2015/5
[2]Altissimo,F.,A.Bassanetti,R.Cristadoro,M.Forni,M. Hallin,M.Lippi,L.Reichlin,and G.Veronese(2001): “EuroCOIN:A Real Time Coincident Indicator for the Euro Area Business Cycle”,CEPR discussion paper No. 3108
[3]Altissimo,F.,B.Mojon,P.Zaffaroni(2009):“Can aggregation explain the persistence of inflation?”,Journal of Monetary Economics,vol.56,no.2,pp.231-241
[4]Amstad M.,Simon Potter and Robert Rich(2014):“The FRBNY staff Underlying Inflation Gauge(UIG)”,FRBNY Staff Report,No.671 and BIS Working Paper,No.453
[5]Amstad M.,Ye Huan and Guonan Ma (2014):“Developing an Underlying Inflation Gauge for China”,BIS working paper,No.465
[6]Amstad,M.and Simon Potter(2009):“Real-time Underlying inflation gauge for Monetary Policy Makers”, FRBNY Staff Report,No.420
[7]Amstad M.and Fischer A.(2009a):“Are Weekly Inflation Forecasts Informative?”,Oxford Bulletin of Economics and Statistics,2009,Vol.71,Issue 2(04)
[8]Amstad M.and Fischer A.(2009b):“Do macroeconomic announcements move inflation forecasts?”,Federal Reserve of St.Louis Review,2009,II 91 (5 Part 2), 507-518
[9]Asia Development Bank(2008):“Dealing with inflation”, in Asia Economic Monitor,pp 48-66,July.
[10]Borio,C.and A.Filardo(2007):“Globalisation and inflation:New cross country evidence on the global deter-minants of domestic inflation”,BIS Working Paper,no 227
[11]Cheung,L.,J Szeto,C.Tam and S.Chan(2008):“Rising food prices in Asia and implications for monetary policy”,Hong Kong Monetary Authority Quarterly Bulletin,September,pp 1-10
[12]Cogley,T.(2002):“A Simple Adaptive Measure of Core Inflation”,Journal of Money,Credit and Banking,Vol. 34.No.1,February,pp.94-113
[13]Cristadoro,R.,M.Forni,L.Reichlin,and G.Veronese (2005):“A Core Inflation Index for the Euro Area”, Journal of Money,Credit and Banking,vol.37,no.3,pp. 539-560
[14]Diebold,F.and R.Mariano(1995):“Comparing Predictive Accuracy”,JournalofBusiness and Economic Statistics,vol.13.no.3,pp.253-263
[15]Funke,M.,A.Mehrotra and H.Yu (2014):“Tracking Chinese CPI inflation in real time“,Empirical Economics,vol.47,July
[16]Forni,M.,M.Hallin,M.Lippi and L.Reichlin(2000): “The generalized factor model:identification and estimation”,The Review of Economics and Statistics,vol.82, pp.540-554
[17]Giannone,D.,L.Reichlin,and L.Sala (2005):“Monetary Policy in Real Time”,NBER Chapters,in:NBER Macroeconomics Annual 2004,Volume 19,pp.161-224
[18]Giannone,D.and T.D.Matheson(2007):“A New Core Inflation Indicator for New Zealand”,International Journal of Central Banking,vol.3(4),pp.145-180,December
[19]Girardin,E.,S.Lunven and G.Ma (2014):“Inflation and China’s monetary policy reaction function:2002-2013”,BIS Papers 77,pp.159-170
[20]Holz,Carsten and Aaron Mehrotra (2013):“Wage and price dynamics in a large emerging economy:The case of China”,BIS Working Papers 409
[21]Kojima,R.,S.Nakamura and S.Ohyama (2005):“Inflation Dynamics in China”,Bank of Japan Working Paper Series,No.05-E-9
[22]Reis,Ricardo,Mark W.Watson (2010):“Relative Goods'Prices,Pure Inflation,and the Phillips Correlation”,American Economic Journal:Macroeconomics,vol. 2(3),pp.128-57,July
[23]Rich,R.and C.Steindel (2007):“A Comparison of Core Inflation”,Federal Reserve Bank of New York E-conomic Policy Review
[24]Sargent,T.and C.Sims(1977):“Business cycle modeling without pretending to have too much a priori economic theory”,Working Papers55,FederalReserve Bank of Minneapolis
[25]Shu and Tsang(2005):“Adjusting for the Chinese New Year:an operational approach”,HKMA Research Memo 22/2005.
[26]Stock,J.H.and M.W.Watson(1999):“Forecasting Inflation”,Journal of Monetary Economics,vol.44(2),pp. 293-335,October
[27]Watson (2004):“Comment on Giannone,Reichlin and Sala's'Monetary Policy in Real-time”,June 2004
[28]Zhang Xiaojing(2012):“China’s Inflation:Demand-Pull orCost-Push?”,Asian Economics Papers 11:3,pp. 92-106
Developing an Underlying Inflation Gauge for China
Marlene Amstad,YE Huan,MA Guo-nan
Statistics and Analysis Department,the People's Bank of China,Beijing 100800
Current and prospective inflation matters a lot to monetary policy makers and market participants.This paper develops a new underlying inflation gauge for China (CUIG)which differentiates between trend and noise,is available daily and uses a broad set of variables that potentially influence inflation.Its construction follows the works at other major central banks and adopts the methodology of a dynamic factor model developed by Forni et al. (2000).Our CUIG is less noisy but still closely tracks the headline CPI.It does not suffer from the excess volatility reduction that plagues traditional core inflation measures and instead provides additional information.Finally,when forecasting the headline CPI,our CUIG outperforms traditional core measures over different samples.
Inflation;Dynamic Factor Model;Forecast
F830
A
本文是中国人民银行调查统计司和国际清算银行(BIS)亚太代表处合作研究的成果
Marlene Amstad,国际清算银行经济顾问;研究方向:金融学
叶欢,中国科学院数学与系统科学研究院博士研究生,任职于中国人民银行调查统计司;研究方向:金融学;北京,100800
马国南,经纶国际经济研究院和Bruegel资深研究员;研究方向:金融学
猜你喜欢
军事文摘(2022年14期)2022-08-26 08:16:40
军事文摘(2022年14期)2022-08-26 08:16:22
军事文摘(2022年12期)2022-07-13 03:12:18
小学生学习指导(高年级)(2021年4期)2021-04-29 02:17:10
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
河北理科教学研究(2020年2期)2020-09-11 06:15:48
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
数学学习与研究(2017年3期)2017-03-09 18:12:42
中国老区建设(2016年1期)2016-02-28 09:32:00
数学年刊A辑(中文版)(2015年2期)2015-10-30 01:56:14
