
基于神经认知计算模型的高分辨率遥感图像场景分类
2015-06-05 15:31付征叶郑逢斌
系统工程与电子技术 2015年11期
刘 扬,付征叶,郑逢斌
(1.河南大学空间信息处理实验室,河南开封475004;2.河南大学环境与规划学院,河南开封475004;3.河南大学计算机与信息工程学院,河南开封475004;4.河南大学软件学院,河南开封475004)
基于神经认知计算模型的高分辨率遥感图像场景分类
刘 扬1,2,3,付征叶4,郑逢斌1,3
(1.河南大学空间信息处理实验室,河南开封475004;2.河南大学环境与规划学院,河南开封475004;3.河南大学计算机与信息工程学院,河南开封475004;4.河南大学软件学院,河南开封475004)
通过大脑对外界环境感知的神经结构与认知功能的相关研究,构建仿脑的媒体神经认知计算(multimedia neural cognitive computing,MNCC)模型。该模型模拟了感官的信息感知、新皮层功能柱的认知功能、丘脑的注意控制结构、海马体的记忆存储和边缘系统的情绪控制环路等大脑基本的神经结构和认知功能。在此基础上,构建基于MNCC的高分辨率遥感图像场景分类算法。首先,图像经仿射变换后切分为若干图块,通过深度神经网络提取图块的稀疏激活特征,采用概率主题模型获取图块初始场景类别,并利用图块分类错误信息反馈控制场景显著区特征的提取;其次,根据图块的上下文获取场景语义的时空特征,并在此基础上进行图块分类和场景预分类;最后,用场景预分类误差构造奖惩函数,控制和选择深度神经网络中场景区分度较大的稀疏激活特征,并通过增量式强化集成学习,获得最后的场景分类。在两个标准的高分辨率遥感图像数据集上的实验结果表明,MNCC算法具备较好场景分类结果。
媒体神经认知计算;遥感场景分类;深度神经网络;稀疏激活特征;概率主题模型;增量式强化集成学习
0 引 言
场景分类是学习和发现图像与场景语义内容标签的一个映射过程。按照感知数据源可将场景分类划分为视觉场景分类和听觉场景分类两种常见感觉类型的场景。源于机器视觉的视觉场景分类研究,根据特征提取的层次一般又可分为低层特征描述和中层特征描述的两大主流方法;根据语义分类标签的设置情况又有监督学习、无监督学习、半监督学习之分。低层特征描述常采用场景图像的颜色描述[1]、基于对象的特征描述[2]、方向梯度[3]及密度特征描述[4]、特征点描述[56]、变换域的纹理描述[7]等。全局的低层特征往往无法反映局部对象,在此基础上,考虑局部低层特征描述[8]、多局部特征融合[9]以及集成学习[10]来提高场景分类的识别率。
由于低层特征描述往往泛化性能差,难用于处理训练集以外的图像分类,目前场景分类算法大部分集中在基于中层语义建模的场景分类。中层语义是低层特征的一种聚集和整合,具体包括语义的属性、对象和局部语义概念(如语义主题模型、稀疏表示)等,其本质是基于统计分布建立低层特征与语义的联系。基于视觉词袋(bag of VisTerm,Bo V)模型的场景分类是目前广泛采用的中层语义算法。Bo V模型无需分析场景具体目标组成,根据场景低层特征统计特性建立视觉单词,然后利用文本相关模型来处理图像内容的表示[11]。考虑图像空间关系[12]、尺度和层次关系[13]、上下文关系[14]可获得有效的描述场景的视觉单词。
与经典的采用统计直方图特性提取空间语义相比,基于概率主题模型(probabilistic topic model,PTM)的Bo V可采用无监督方法简洁地表示复杂语义的概率分布。采用PTM可对视词进行降维,并用学到的中层语义的主题特征替代原有低层特征,以减少高层语义与底层图像特征的语义映射复杂度。PTM和变分推理是处理不确定性和复杂性问题的有力工具,具有雄厚的数理基础。概率图常见的概率潜在语义分析(probabilistic latent semantic analysis,p LSA)模型[15]和隐狄利克雷分配(latent Dirichlet allocation,LDA)模型[16]都是将特征向量降维到潜在语义空间的生成模型。此外,考虑视词的空间共生关系和上下文关系,将有助于提升场景结构语义的解释[17]。但目前BoV模型的视词数量设置多少为宜尚无定论,且生成对象也往往与训练样本有较大相关度,而这是影响算法鲁棒性的重要因素。
针对传统BoV模型缺乏空间语义描述、字典学习和特征编码的不足,基于稀疏编码的BoV模型可减轻特征编码的自适应问题,并减少字典长度对分类性能的敏感度。稀疏表示是对大脑皮层编码神经生理机制的模拟,稀疏编码寻找一组超完备基向量来高效地表示样本数据语义,是一种无监督学习方法。基于有监督子空间建模、多层次和多尺度稀疏表示的场景分类[18]在处理高维图像分类具有一定的优势。
模拟大脑层次结构的深度网络在图像分类、语音识别和文本处理也取得显著成果。深度学习对低层数据先采用无监督的预训练多层神经网络,形成属性、类别或特征的中层语义的抽象表示,在此基础上再通过监督分类器训练发现高层语义特征描述。相关研究表明,基于深度卷积神经网络的图像分类方法[19]可有效减轻图像几何变形所造成的分类效果不好和过学习问题的影响。
中层语义场景分类在一定程度上缓解语义鸿沟的问题,但对场景尺度变化、传感器拍摄角度和时空差异、语义对象组合变化往往缺乏有效措施。稀疏编码和深度学习较高的算法复杂度是制约其在遥感图像场景分类进一步应用的重要因素。尤其是对高分辨率遥感图像的场景分类这一特殊的大数据量、场景对象构造复杂的特殊问题,其算法的鲁棒性差、复杂度高问题仍然有较大的提升空间。本文在分析大脑的神经认知计算机理的基础上,基于深度学习的神经计算理论和基于概率统计学习的认知计算架构,建立了媒体的认知神经计算(multimedia neural cognitive computing,MNCC)模型,并在此基础上实现高分辨率遥感图像的场景分类算法。
1 媒体神经认知计算模型
MNCC旨在探索非结构化、海量多模态、复杂时空分布的多媒体信息处理的语义鸿沟和维度灾难问题的解决方案。在宏观的系统行为层面上,MNCC利用认知计算探索大脑信息加工的机理和认知过程;在微观的生理机理层面上,MNCC研究神经网络机制,模拟生物神经系统的结构特征和生物神经信息的处理机理。MNCC建立感觉媒体信息处理的可计算模型,实现表示媒体内容分析和处理的仿脑算法。
1.1 MNCC模型描述
脑的功能与结构是目前已知最为复杂的系统,为简化设计,图1示意了根据人脑连接组计划宏观连接研究、活动图项目功能性的连接研究以及人类大脑模拟项目最新公布数据构造的认知功能及神经系统的基本结构。神经科学和认知科学研究认为,端脑的新皮层是认知智能处理重要部分,丘脑是信息进出及选择性注意的控制开关,海马体及边缘系统是记忆及情绪控制器。
在此基础上,本文建立了一种仿脑的基于MNCC的场景分类模型。模型采用仿射变换后的图像Iab经分块后训练深度神经网络来提取媒体的深度网络的激活稀疏特征SparseFeature;通过显著性控制提取选择性注意特征Saliency Feature,再由PTM提取图块的显著区若干主题Topic Feature;进一步采用增量式多分类器(iKNN,iPGM,iDBN)集成,获得主题的图块类别SubClassfication;图块类别按照时间上下文(图块按照显著度大小时序扫描的先后)和空间上下文(原图显著图在分块后的空间邻域关系)进行时空组合,通过增量式多分类器(iNB,iSVM)集成获得场景分类Category。而在训练时,由获得的场景预分类误差构造Reward奖惩函数,实现分类特征的增强学习。

图1 大脑的神经认知计算框架
模型具体可用如下映射描述:
MNCC:<Iab,an,sm,ssl,STC,Reward,

式中,Iab为仿射图像子块;an为iDBN激活特征;sm为图像的视觉显著图;ssl为图块类别;STC为场景时空上下文描述;Reward为奖惩函数;Train Label为场景增量集成分类结果;Category为图像人工类别语义标注。如图2所示,MNCC模型的信息处理包括以下7个基本过程。
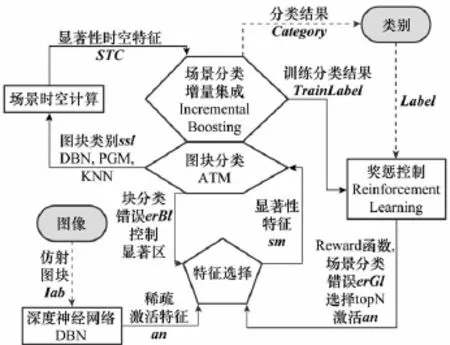
图2 基于MNCC的场景分类模型
步骤1图像分块与仿射预处理
Affine:Img→Iabk
步骤2基于深度神经网络的稀疏激活特征提取
iDBN:igk→ank
步骤3注意显著区的反馈控制和选择
Attention:<Rewardk,igk,erBlk>→smk
步骤4特征增强学习
Reinforcement:<slk,erGl>→Rewardk
步骤5基于作者主题模型的图块分类
iATM:ssk→sslk
步骤6图块的时空上下文语义计算Memory:<slk,smk>→<STC>
步骤7图块分类和场景分类的增量集成
IBoosting:<sslk,igk,STC,Train Labeli>→
<Train Labe li+1>
1.2 图像分块与仿射预处理
为了实现使图像的提取特征具备放缩、旋转和平移的不变性,先对原始图像Img进行仿射变换得图像

式中,tl(λ)为平移矢量;zm(δ)为放缩因子;rt(θ)为旋转矩阵。其次对仿射图像做分块处理,设图像块大小为bk×bk,如图3所示,重叠分块的块重叠面积为块大小的bk2/4。第k块仿射图像为
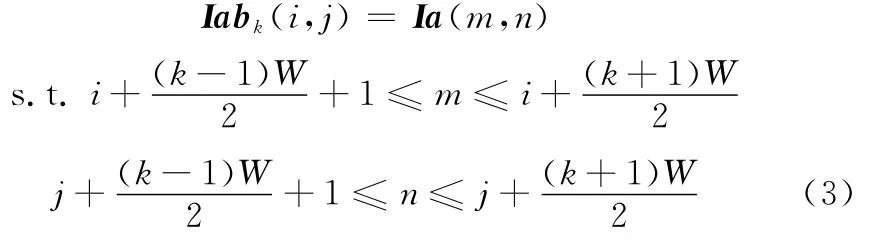

图3 仿射图像的分块处理
考虑到不同波段对场景的贡献,分别对可见光图像RGB 3波段分别执行上述预处理。
一张图像最后获得如图4所示的训练图像。这样做的原因是由于后续处理的深度神经网络的训练参数较多,需要海量的大数据进行训练。当训练的数据量充足,其参数调优较易进行;而训练数据量少时,较多的网络参数易产生过拟合的问题。
1.3 基于深度神经网络的特征提取
深度学习是相对浅层学习而言的一种新兴的机器学习手段。相比传统的神经网络的BP算法和浅层学习模型算法(如SVM,Boosting方法)而言,浅层模型依赖于人工特征的抽取,模型注重的是分类和预测,其抽取特征的好坏将直接影响系统的性能。深度模型强调多层架构,利用逐层初始化,减少梯度弥散,通过对大数据学习,解决大量网络参数的非凸优化问题。深度模型常见有受限波尔兹曼机(restricted Boltzmann machine,RBM)、深度信念网络(deep belief networks,DBN),卷积神经网络(convolution neuralnetworks,CNN)、自动编码器(auto-encoder)。这里采用增量栈式稀疏自编码神经网络(incremental stacked sparse auto encoders,iSSAE),通过预训练提取参数去初始化增量式深度信念网络(incremental deep belief networks,iDBN)。iSSAE是一种可用于高维数据降维无监督特征学习多层的前向神经网络。其每层损失函数为
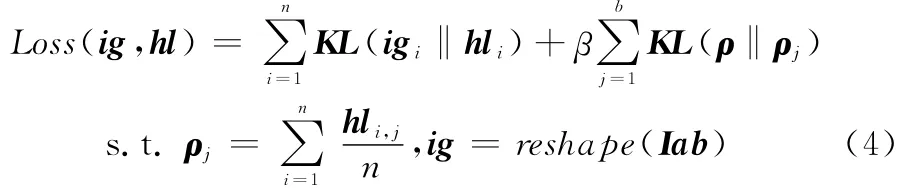
式中,输入样本用ig表示图块矩阵Iab拉伸而成的向量;hl为隐层输出;KL为散度;稀疏约束项中ρj为第j个隐层神经元的激活率。初始用非监督学习特征通过编码器使重构误差最小,用本层编码器产生特征去训练下一层,这样逐层训练获得网络权重后去初始化第L层的前馈网络的权重nwi,j。设po为预期值,yo为输出值,网络误差函数为er,η为学习率,利用BP算法的梯度下降求权值的变化及误差的反向传播,修正和精调权重nwi,j。
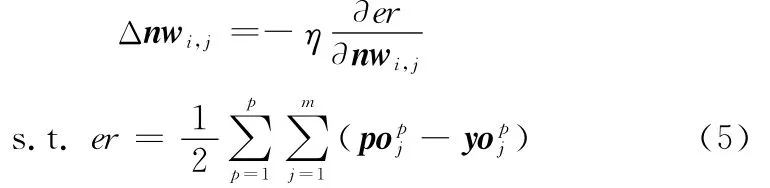

图4 图块的分块仿射处理
1.4 深度神经网络的神经元激活特征提取
由于多层网络算法复杂度较高,当网络层次增加,网络规模大,训练样本多,网络收敛非常缓慢。由于网络初始化时采用了iSSAE的权重,在经过BP微调后,net的神经元激活情况将能反应样本自身的类别信息。
为提高效率,这里采用未充分训练深度神经网络iDBN的net神经元对训练样本的激活数据作为显著性特征[19]提取的数据源,图5示意了iDBN每层神经元激活情况。

图5 iDBN的激活神经元
第nl层神经元激活值为
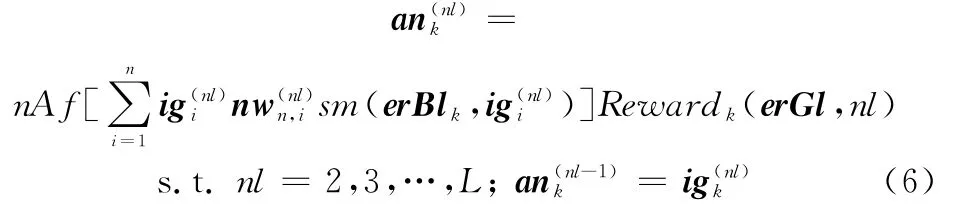
式中,n Af(·)为神经元激活函数;Reward为特征显著性奖惩控制函数;sm为显著性控制函数;ig(nl)为第nl层神经元输入ig;nw为网络权重。
1.5 显著区的反馈与特征的增强学习
显著性控制通过提取图像块的低频差分边缘信息产生视觉显著图sm,这里采用谱残差方法提取显著图:

式中,erBl是用于控制显著区的图块分类错误率;F(·)和F-1(·)描述傅里叶变换及逆变换;G(·)是高斯平滑滤波函数;Hn是进行均值滤波的n×n方阵;和A分别是傅里叶变换相位谱和振幅谱;和分别是傅里叶变换的虚部和实部;Λ是谱残差。由于深度网络训练需要较长训练时间才能收敛,为了加快训练速度,在有限的训练次数情况下,模型采用增强学习的反馈机制,根据结果调整显著区的特征权重,奖惩函数设计为
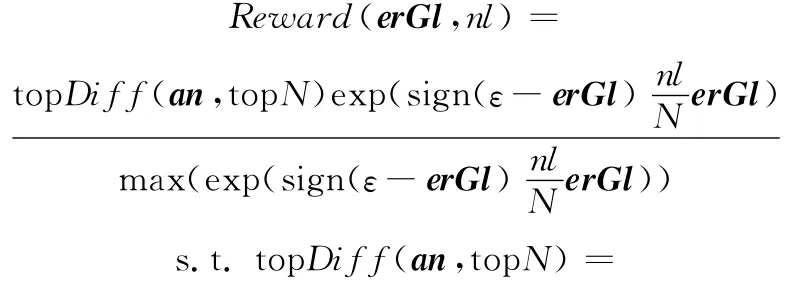

式中,ε为增强阈值参数,ε∈(0,1),默认ε=0.5;erGl为图像场景分类错误率;nl为网络层级,且N≥nl;top Diff通过排序选择异类间区分度最大,且同类间区分度最小的前top N个an。
1.6 基于作者主题模型的图块分类
图模型是采用图来表达变量之间的概率相关关系的基于贝叶斯规则的概率模型。图模型经典方法包括基于有向无环图表达因果关系的贝叶斯网络,基于无向图来表达变量间的相互作用的马尔可夫随机场,以及在文本分类和图像处理广泛应用的PTM。PTM将文档理解成若干隐含主题组合而成,隐含主题是文档中的特定词汇的一种概率分布。与iSSAE类似,PTM也是生成模型,可通过参数估计寻找一个多项式分布的低维主题集合。由于网络神经元个数较多,直接作为分类特征相对比较困难,为此采用PTM模拟皮层的认知推理过程。
如图6所示,这里采用基于BoV的增量式作者主题模型(incremental author topic model,iATM)对特征做进一步分类,iATM是一种将生成模型与判别模型相结合对有监督LDA模型。为方便描述,设tp为主题Topic,ss和vt分别表示图块类别SubSceneLabel和图块的视词,即iATM中的作者author和单词word;为将神经元an激活特征运用于iATM,先将an归一化到[0,1]区间,并放大100倍,再向下取整得
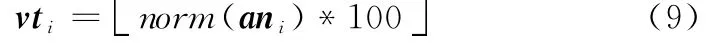

图6 作者主题模型

设tpi=j,ssi=k代表图块Iab中第i个视词分配给第j个主题和第k个图块类别。vti=m代表第i个视词是词典中第m个词汇,tp-i,ss-i代表除第i个视词之外其余视词的主题和图块类别的分配。通过Gibbs采样,对于每个视词,根据下面公式为其采样图块类别ss和主题tp,其中φm,j,θk,j分别表示对Θ和Φ分布的估算。



1.7 图块的场景时空上下文计算
由于一幅原始的训练图像进行仿射变换后被分成若干图块。根据显著性与选择性注意关系:每个图块按照显著度逆序排列将构成注意转移的时序关系;图块的空间领域关系则构成空间上下文关系。二者共同构成一幅图像场景内对象的时空上下文。为便于计算,设图块的类别数为K,取块平均显著度最高的前N块图块,每个图块的8邻域图块类别作为图像场景对象的空间特征描述:
SCi=<NumBs(sl1),NumBs(sl2),…,NumBs(slK)>
(17)
式中,NumBs(sli)是统计当前3×3图块中类别为sli的块个数。各图块按照显著度均值大小逆序构成注意的时序转移序列。选择前N个注意块,每个注意块取前驱和后继2个图块的8邻域类别的直方图作为图像场景对象注意转移的时间描述。若当前为显著度最大的第一图块(i=1),则只统计其显著度后继(i=2)的8邻域图块的类别的直方图;若当前为最后一块(i=N),则只统计其显著度前驱(i=N-1)的8邻域图块的类别的直方图;对于其他情况,同时统计显著度前驱i-1和显著度后继i-1的8邻域图块的类别构成时序特征描述:

式中,NumBt(sli)是统计当前块前驱和后继两个3×3图块中类别为sli的块个数。最后将图像场景对象的空间特征描述SC和时序特征描述TC组合构成2K维描述每块图像的时空上下文信息。取前N块显著度最高的图像块构成序列N×2K维矩阵STC:

图7为一幅图像场景显著对象B点与前驱A和后继B的时空关系,STC记录了图像的时空上下文特征,可避免BoV模型的上下文无关的缺点,为下一步场景计算提供基础。
1.8 图块分类和场景分类的增量集成
增量学习方法指能不断从环境新样本学习新知识,并能保留大部分已学习知识。增量学习与在线学习非常相似。与批量学习算法不同的是,一般认为增量学习不需重复处理已处理数据和学习新类别,学习新知识能且保留前期学习大部分知识,即可渐进地从新数据学习新知识。
由于算法在实现图块的分类采用了iDBN、iKNN和iATM 3种增量学习分类器,而最后的场景分类采用了基于Bo V的iNB和时空相关性的iSVM 2种增量学习分类器。二者分类结果都需要采用集成学习思想获得最后分类结果。首先把图块Iabk的iATM分类结果ssliATM(ank)、iKNN分类结果ssliKNN(ank)及iDBN分类结果ssliDBN(igk)采用概率分布加权集成为图块分类结果
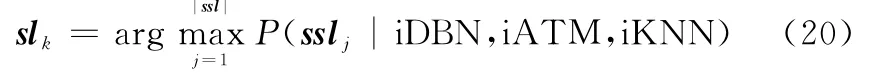

图7 图像场景的时空上下文描述示意
场景分类先分别采用iSVM进行时空相关性场景分类和基于Bo V的iNB进行场景分类:

式中,STC为场景时空上下文的N×2K维特征;Bov Hist为图像全部图块类别的统计直方图;SLiSVM(sl)为iSVM场景分类结果,SLBoV(sl)为iNB场景分类结果。最后整幅图像基于分类器性能增量加权集成,设wtc为性能权重,场景分类结果Train Label为
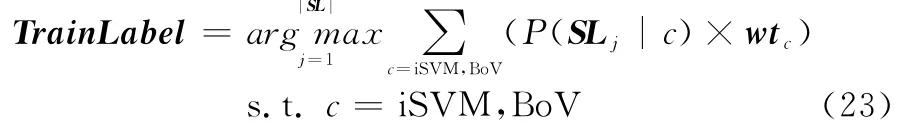
2 基于MNCC模型的遥感图像场景分类
图8示意了基于MNCC模型的遥感图像场景分类的训练算法数据处理流程,具体训练和测试算法如下。

图8 场景分类处理流程
2.1 基于MNCC场景分类的训练算法
输入<Img Traini,Train Labeli>,i∈[1,N],N为训练数据组数
输出MNCC模型参数:iDBN,iKNN,iATM,iNB,iSVM
设置初始的图块分类误差erBl为0,场景分类误差erGl为0;
While(挑选待训练<ImgTraini,Train Labeli>≠φ)
{
步骤1根据图像分块与仿射预处理映射Affine:ImgTrain→Iabk,转换仿射图块为矢量igk;
步骤2基于映射iDBN:igk→ank训练获得深度神经网络稀疏激活特征ank;
步骤3由选择性注意Attention:<Rewardk,igk,erBlk>→smk获得显著区smk;
步骤4根据增强学习Reinforcement:<slk,erGl>→Rewardk获得特征的反馈增强参数Rewardk;
步骤5由作者主题模型iATM、iDNN和iKNN计算图块分类ssliATM、ssliKNN和ssliDBN,获得3种分类器参数iATM,iKNN和iDBN,然后集成图块分类slk,并计算图块分类错误率erBl;
步骤6由映射Memory:<slk,smk>→<STC>计算图块对象的时空上下文STC;
步骤7由场景集成映射IBoosting:<sslk,igk,STC>→<PreTrain Label>获得场景预分类标签,并计算图像分类错误率erGl。
}
由场景分类增量式集成映射IBoosting:<sslk,igk,STC,PreTrain Label>→<Train Label>获得最后场景。
2.2 基于MNCC场景分类的测试算法
输入ImgTest,Label,MNCC模型参数(iDBN,iKNN,iATM,iNB,iSVM)
输出Test Label,Accuracy
步骤1图像进行分块预处理Block:Img Test→Ibk,拉伸图块为矢量igk;
步骤2由iDBN参数计算深度神经网络的稀疏激活特征ank;
步骤3由iDBN,iKNN,iATM参数计算子图块的预分类ssliATM,ssliKNN,ssliDBN,并集成图块预分类结果slk;
步骤4设图块初始分类错误率erBl为0,由原始图像Img Test计算显著区smk;
步骤5由映射Memory:<slk,smk>→<STC>计算图块对象的时空上下文STC;
步骤6由场景分类集成映射Boosting:<sslk,igk>→<TrainLabel>计算最后场景类别,并计算场景分类错误率。
3 实验与讨论
3.1 实验数据集
(1)MNIST手写数字识别数据集(http:∥yann.lecun.com/exdb/mnist/)。由于手写数字识别MNIST数据集图像结构语义相对简单,在本文中用其验证MNCC模型的一些基本参数。MNIST数据集含有手写阿拉伯数字0~9的60 000个训练数据集和10 000个测试数据集两种图像,图像灰度级为8,分辨率为28像素×28像素,共784维的向量表征。
(2)武汉大学高分卫星遥感图像场景(high-resolution satellite scene,HRSS)数据集(http:∥dsp.whu.edu.cn/cn/staff/yw/HRSscene.html)。HRSS数据集源于Google Earth,共包括19类场景的RGB可见光高分遥感图像。其中每一类场景含有大约50多幅图像,共计1 005幅3波段的高分遥感图像,图像分辨率600像素×600像素,空间分辨率约为1 m。实验随机选择每类30幅作为训练集,其余作为测试集。
(3)加州大学默塞德土地利用遥感图像(university of California Merced land use,UCMLU)数据集(http:∥vision.ucmerced.edu/datasets/landuse.html)。UCMLU数据集包含共21类土地利用3波段的高分遥感图像,图像分辨率256像素×256像素,每类包含100幅图像,总计2 100幅图像。实验随机选择每类40幅作为训练集,其余作为测试集。
3.2 模型参数设置与性能影响
为便于计算,将HRSS和UCMLU两个数据集的RGB图像的3个波段数据分别统一地降采样为120像素× 120像素,图块划分为28像素×28像素。由于模型包含大量参数,不同参数对模型性能有较大的影响,下面就模型的各个部分参数进行实验和调整。
3.2.1 分块与仿射参数
图像分块目的是实现场景的内容分析,分块大小直接影响稀疏字典的容量,而大容量的字典学习需要更多训练样本和训练时间。仿射变换的目的是使提取的稀疏特征更具备鲁棒性,在稀少样本的情况下,通过仿射变化可获取不同位置多角度和多尺度的训练样本。
图9显示了HRSS数据集里桥梁Br G、住宅区Rs T和山区Mo T 3类6个图像的仿射变换及分块情况,然后统一降采样为28像素×28像素图块,最后拉伸为784维矢量。仿射变换和分块情况如图9所示。其中图9(g)的分块大小为100、块重叠度为100/50=50%;图9(h)的分块大小为32、块重叠度为32/20=16%;图9(i)的分块大小为100、块重叠度为100/50=50%、平移参数为50、旋转角度为45°~135°、放缩比例为1.2。分块越大,块覆盖度越小,特征的整体性较好有利于大尺度目标识别;分块越小,块覆盖度越大,有利于局部特征提取,对小目标效果较好。

图9 图像分块与仿射变换
3.2.2 用于稀疏激活特征提取的iSSAE和iDBN参数设置
由于深度架构有利于特征提取,但随着网络层数越多,网络神经元个数增加,达到网络收敛的训练次数将增加。此外对于固定的训练次数,网络的学习率和冲量因子是制约特征提取的重要参数。学习率影响着网络收敛的速度,甚至影响网络能否收敛,学习率设置偏小可以保证网络收敛,但是收敛较慢;相反,学习率设置过大则有可能使网络训练不收敛,影响识别效果。在满足场景类别识别的情况下,增加隐含层节点的个数对于场景识别率的影响一般不大,但是节点个数过多会增加运算量,造成训练收敛时长增加。实验设置网络层数layer=6、每层神经元个数Num=[100 80 60 40 60 80]、学习率alpha=0.1、冲量因子momentum=0.01、训练次数numepochs=500。
3.2.3 特征提取的显著区反馈控制和增强学习参数设置
图块分类错误率erBl对显著度影响情况如图10(a)所示。区域显著性受控于图块的分类误差,误差越大注意度越大。特征选择top N=|an|/10;图10(b)和图10(c)显示了ε=0.5时,场景分类错误率erGl对不同iDBN层数的奖惩影响。当图像场景分类错误率较大时(erGl>ε),iDBN的层数越高获得奖惩权重越小,且场景分类错误率越大,奖惩权重越大;当图像场景分类错误率较小时(erGl<ε),iDBN的层数越高获得奖惩权重越大,且场景分类错误率越小,奖惩权重越大。

图10 特征显著区增强和反馈
3.2.4 主题数量对iATM图块分类影响
图11显示了主题数量对图块iATM分类影响,其中6类图块大小为28像素×28像素,迭代次数N=500,主题分布的Dirichlet先验的超参数取|tp|/50和Φ取200/|vt|。由图可见当主题数量设置|tp|=100时,分类准确度趋于较高的稳定区间。主题数量是原始特征降维后的中间描述,对一般算法而言,主题数量设置过大会引起效率下降,且算法复杂度增加;而主题设置数量过小则提取的中间描述无法反映场景的内在特征。
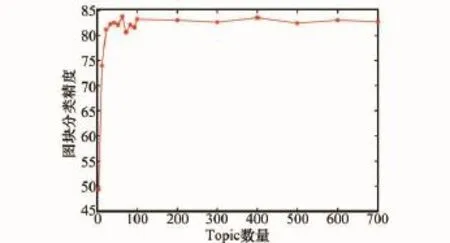
图11 主题数量对图块iATM分类影响
3.2.5 图块分类集成和场景分类集成权重设置
由于图块的分类采用iDBN,iATM和iKNN 3种分类器的概率分布加权进行集成,其中iATM和iKNN是在iDBN的激活神经元的稀疏特征基础上进一步分类,当iDBN训练没有收敛时,iATM和iKNN可相互弥补,进一步弥补iDBN的缺陷,而iKNN是一种简单而稳健的分类器,支持增量学习、能对超多边形的复杂决策空间建模,但其模型过于简单,特征维度增加会导致计算量剧增,需大规模存储支持。iATM可对数据进行降维,采用的主题特征可有效缩小语义鸿沟问题。但是由于其假定各主题是独立的,这与实际情况并不相符,且一般不能根据场景类别数量自适应地设置主题数量,因此iATM的分类参数设置一般较困难。
根据分类器性能,场景分类采用基于时空相关性的iSVM场景分类和基于Bo V的iNB场景分类结果进行加权集成。由于基于Bo V的iNB场景分类是上下文无关的,时空相关性的iSVM场景分类是考虑时空上下文的,二者权重不同将影响场景分类的结果。Bo V的iNB场景分类器权重增加,对应纹理场景分类(如牧场MeD、山区Mo T)有利,时空相关性的iSVM场景分类器权重增加,则对于多目标对象的复杂场景(如机场AiP、港口Po T)或大型目标(如桥梁Br G、池塘PoD)场景分类有利。
3.3 场景分类算法结果
为验证模型的增量学习能力,选择MNIST数据集的10个手写阿拉伯数字进行分类实验。这里数字图像不进行分块处理和仿射处理,将60 000个训练样本分120个批次,每次500个图像进行增量训练。
图12为算法随训练样本数量逐渐递增,分类准确度的变化情况。从图中可见MNCC模型的算法具备渐进地从新数据学习类别特征的功能,随着训练样本的新增,样本的测试准确率呈现逐渐提升趋势。实验也发现增量学习在训练时间上和内存需求量大大减少。与不采用增量学习算法相比,最终的平均分类准确度变化不大,基于增量学习的MNCC算法最终平均分类准确度可达99.58%

图12 MNCC算法中MNIST数据集的增量学习性能

图13 MNCC算法中在数据集的场景分类准确度
图13为MNCC算法在数据集HRSS和数据集UCMLU进行遥感场景分类情况(其中图中的图标为从本类场景选择的一幅训练的图像作为本场景代表,柱的高度为本场景的分类准确度)。在19类场景的HRSS数据集中场景Beach(BeC),Forest(FoE)和Port(Po T)取得较高的分类准确度,场景Meadow(MeD),Industrial(In T)和Residential(Rs T)分类准确度低,平均分类准确度84.73%;在21类场景的UCMLU数据集分类准确度高的有Forest(FoE),Agricultural(Ar L),River(RiV)和Mobilehomepark(MhP),分类准确度低的有Sparseresidential(Sp R),Golfcourse(GoC)和Runway(RuW),平均分类准确度88.26%。
两个遥感数据集的相同语义的类别中Forest(FoE),Beach(BeC)识别准确度相差不大,而其余4类River(RiV)和Parking(Pk G);Overpass(VaS)和Viaduct(VaS),Agricultural(Ar L)和Farmland(Ar L)识别准确度变化较大。图14显示了MNCC算法数据集HRSS和数据集UCMLU遥感场景的分类混淆矩阵。整体上看MNCC对于对象纹理单一,差异性小的场景(如海滨BeC、森林FoE、农田Ar L)分类准确度高。对语义对象复杂,而图像差异性大,需要间接解释的场景(如高尔夫球场GoC、跑道Ru W、稀疏居民点Sp R)分类准确度低。场景本身存在二义性(如工业区In T和居民区Rs T,草地MeD和河流RiV)也是造成误分的重要原因。
表1~表3显示了不同算法在MNIST、HRSS和UCMLU数据集的分类准确度。MNCC不分块和仿射变换。其中MNIST数据集实验选取类别数为10;UCMLU数据集实验选取类别数为21;HRSS数据集对MNCC算法选取类别数为19,其他算法选取类别数均为12。

图14 场景分类混淆矩阵

表1 算法在MNIST数据集的分类准确度 %

表2 算法在HRSS数据集的分类准确度 %

表3 算法在UCMLU数据集的分类准确度 %
由于MNIST数据集是手写体阿拉伯数字,其图像的语义内容和对象复杂度明显要比遥感场景小,而HRSS和UCMLU数据集属于高分辨率遥感影像,MNIST实验结果中整体平均分类准确度明显要比HRSS和UCMLU数据集高。
由于MNCC模型设计考虑了神经结构的分层处理,利用稀疏激活的特征基于概率推理进行分类,模型的这种仿脑机理是算法精度提升的保证。实验发现MNCC算法在UCMLU数据集场景要比在HRSS数据集分类准确度高3.5%。虽然UCMLU数据集多了2个场景,但UCMLU数据集的训练数据(2 100)也远大于HRSS数据集(1 005),可见MNCC算法准确度提升需要训练数据的增加。一般而言,待分类场景越多,深度网络和概率计算达到指定分类准确度所需的训练样本也越多,实验也表明MNCC模型具备一定的大数据分析和处理能力。由于Mncc Train训练算法对图像分块和仿射预处理,模型对测试图像的平移、放缩、旋转具备一定鲁棒性,但算法复杂度较高,下面就MNCC模型训练及测试,分析其算法复杂度。
3.4 MNCC场景分类算法复杂度分析
Mncc Train训练算法和MnccTest测试算法的复杂度主要集中在主题模型iATM、深度神经网络iSSAE和iDBN。具体对于Mncc Train算法的步骤2和步骤5,Mncc Test算法的步骤2和步骤3。
设训练样本总数量为s、增量样本为r,iATM变量个数为n,采用Gibbs抽样技术对iATM的变量进行抽样,则对iATM中所有结点抽样一次的复杂度为O(sn),iATM算法Gibbs抽样m次的复杂度为O(msn)。若深度神经网络有d个参数,iSSAE和iDBN有h层,则iSSAE算法复杂度为O(shd3+sd3)=O(shd3),iDBN算法复杂度为O(sh2h+sd3)=O(sd3)(一般情况h≪d)。常规Mncc Train批处理算法总体复杂度为O(smn+shd3+sh2h+sd3)=O(smn+shd3),而采用增量学习的Mncc Train算法复杂度为O(rmn+rhd3),在本质上并未减少算法复杂度,但由于单次训练的样本数量r远小于s,因此有效地降低了学习过程的计算复杂度。而Mncc Test总体算法复杂度为O(mn+2h)。在整体上Mncc Train算法复杂度要远高于Mncc Test算法复杂度,这在一定程度上与仿生学意义上的学习和分类的生物特性是一致的。
4 结 论
本文分析场景分类相关领域研究的热点和存在的问题,在大脑对感知外界环境的神经结构与认知功能的相关研究基础上,构建仿脑的MNCC模型,并实现基于MNCC的高分辨率遥感图像场景分类算法。实验并分析了模型相关参数设置对算法性能的影响。在标准高分辨率遥感图像场景数据集上的分类实验结果表明,本算法在分类准确度上与所列方法相比表现出明显的优势。虽然增量学习可显著地降低算法的运行时间,但MNCC算法本身尚有较大的并行处理的改进空间,进一步工作我们将研究基于集群计算、多核运算和GPU提升算法性能,并将其运用于高分辨率SAR图像的场景分类中。
参考文献:
[1]Van de Sande K E A,Gevers T,Snoek C G M.Evaluating color descriptors for object and scene recognition[J].IEEE Trans.on Pattern Analysis and Machine Intelligence,2010,32(9):1582- 1596.
[2]Li L J,Su H,Lim Y,et al.Objects as attributes for scene classification[M]∥Kutulakos K N.Trends and topics in computer vision.Berlin Heidelberg:Springer,2012:57- 69.
[3]Zhou L,Hu D W,Zhou Z T.Scene recognition combining structural and textural features[J].Science China-Information Sciences,2013,56(7):1- 14.
[4]Cheriyadat A M.Unsupervised feature learning for aerial scene classification[J].IEEE Trans.on Geoscience and Remote Sensing,2014,52(1):439- 451.
[5]Nanni L,Lumini A.Heterogeneous bag-of-features for object/scene recognition[J].Applied Soft Computing,2013,13(4):2171- 2178.
[6]Han P,Xu J S,Zhao A J.Target classification using SIFT sequence scale invariants[J].Journal of Systems Engineering and Electronics,2012,23(5):633- 639.
[7]Qian X M,Guo D P,Hou X S,et al.HWVP:hierarchical wavelet packet descriptors and their applications in scene categorization and semantic concept retrieval[J].Multimedia Tools and Applications,2014,69(3):897- 920.
[8]Ryu H,Chung W K.Scene recognition with omnidirectional images in low-textured environments[J].Electronics Letters,2014,50(5):368- 369.
[9]Yu J,Tao D C,Rui Y,et al.Pairwise constraints based multiview features fusion for scene classification[J].Pattern Recognition,2013,46(2):483- 496.
[10]Qian X M,Tang Y Y,Yan Z,et al.ISABoost:a weak classifier inner structure adjusting based AdaBoost algorithm-ISABoost based application in scene categorization[J].Neurocomputing,2013,103:104- 113.
[11]Zhao L J,Tang P,Huo L Z.A 2-D wavelet decomposition-based bag-of-visual-words model for land-use scene classification[J].International Journal of Remote Sensing,2014,35(6):2296- 2310.
[12]Shabou A,LeBorgne H.Locality-constrained and spatially regularized coding for scene categorization[C]∥Proc.of the IEEE Conference on Computer Vision and Pattern Recognition,2012:3618- 3625.
[13]Zhou L,Zhou Z T,Hu D W.Scene classification using a multiresolution bag-of-features model[J].Pattern Recognition,2013,46(1):424- 433.
[14]Bolovinou A,Pratikakis I,Perantonis S.Bag of spatio-visual words for context inference in scene classification[J].Pattern Recognition,2013,46(3):1039- 1053.
[15]Fan Y H,Qin S Y.Optimizing decision for scene classification based on latent semantic analysis[J].Journal of Computer-Aided Design&Computer Graphics,2013,25(2):175- 182.(范玉华,秦世引.基于潜在语义分析的场景分类优化决策方法[J].计算机辅助设计与图形学学报,2013,25(2):175- 182.)
[16]Kusumaningrum R,Wei H,Manurung R,et al.Integrated visual vocabulary in latent Dirichlet allocation-based scene classification for IKONOS image[J].Journal of Applied Remote Sensing,2014,8(1):3690- 3708.
[17]Xu K,Yang W,Chen L J,et al.Satel lite image scene categorization based on topic models[J].Geomatics and Information Science of Wuhan University,2011,36(5):540- 543.(徐侃,杨文,陈丽君,等.利用主题模型的遥感图像场景分类[J].武汉大学学报(信息科学版),2011,36(5):540- 543.)
[18]Dai D X,Yang W.Satellite image classification via two-layer sparse coding with biased image representation[J].IEEE Geoscience and Remote Sensing Letters,2011,8(1):173- 176.
[19]Gong Y,Wang L,Guo R,et al.Multi-scale orderless pooling of deep convolutional activation features[C]∥Proc.of the European Conference on Computer Vision,2014:392- 407.
[20]Belongie S,Malik J,Puzicha J.Shape matching and object recognition using shape contexts[J].IEEE Trans.on Pattern Analysis and Machine Intelligence,2002,24(4):509- 522.
[21]Kégl B,Busa-Fekete R.Boosting products of base classifiers[C]∥Proc.of the 26th Annual International Conference on Machine Learning,2009:497- 504.
[22]LeCun Y,Bottou L,Bengio Y,et al.Gradient-based learning applied to document recognition[J].Proc.of the IEEE,1998,86(11):2278- 2324.
[23]Dan C C,Ueli M,Luca M G,et al.Deep big simple neural nets excel on handwritten digit recognition[J].Neural Computation,2010,22(12):1- 14.
[24]Yang Y,Newsam S.Bag-of-visual-words and spatial extensions for land-use classification[C]∥Proc.of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems,2010:270- 279.
[25]Zheng X W,Sun X,Fu K,et al.Automatic annotation of satellite images via multifeature joint sparse coding with spatial relation constraint[J].IEEE Geoscience and Remote Sensing Letters,2013,10(4):652- 656.
[26]Risojevic V,Babic Z.Aerial image classification using structural texture similarity[C]∥Proc.of the IEEE International Symposium on Signal Processing and Information Technology,2011:190- 195.
郑逢斌(1963- ),通信作者,男,教授,博士研究生导师,博士,主要研究方向为空间信息处理、自然语言处理。
E-mail:zhengfb@henu.edu.cn
Scene classification of high-resolution remote sensing image based on multimedia neural cognitive computing
LIU Yang1,2,3,FU Zheng-ye4,ZHENG Feng-bin1,3
(1.Laboratory of Spatial Information Processing,Henan University,Kaifeng 475004,China;2.College of Environment and Planning,Henan University,Kaifeng 475004,China;3.College of Computer Science and Information Engineering,Henan University,Kaifeng 475004,China;4.College of Software,Henan University,Kaifeng 475004,China)
According to the related research of the brain of neural structures and cognitive function which apperceive the external environment,the brain-like model of multimedia neural cognitive computing(MNCC)is built.The model simulates the basic neural structures and the cognition of brain,such as the sensory information perception,the cognition of the neocortex column,the attention control structure of the thalamus,the hippocampus memory and emotional control circuits of the limbic system,and a scene classification MNCC-based algorithm for high-resolution remote sensing images is established.Firstly,the algorithm extracts sparse activation features of the deep neural network from the sub-blocks image after affine transformation,and gets initial category of the sub-blocks image with the probability topic model,then controls features extraction of the saliency area by sub-block classification error.Secondly,the temporal-spatial features of scene semantic are acquired by sub-blocks context,then sub-blocks categorization and scene pre-classification are processed to obtain initial scene labels.Finally,the scene pre-classification error is used for construction rewards function to control and select the most discrimination sparse activation features of deep neural network,and the final scene label is ob-___tained by the incremental reinforced ensemble learning algorithm.Experiment results show that the MNCC al-gorithm presented in this paper has better performance of scene classification on the two standard high-resolution remote sensing scene datasets.
multimedia neural cognitive computing(MNCC);remote sensing scene classification;deep neural networks;sparse activation feature;probabilistic topic model;incremental reinforced ensemble learning
TP 391.41
A
10.3969/j.issn.1001-506X.2015.11.31
刘 扬(1971- ),男,副教授,硕士研究生导师,博士研究生,主要研究方向为媒体神经认知计算、时空信息高性能计算。
E-mail:ly.sci.art@gmail.com
付征叶(1963- ),女,讲师,硕士,主要研究方向为空间数据处理。
E-mail:fuzhy@henu.edu.cn
1001-506X(2015)11-2623-11
2014- 08- 15;
2015- 04- 09;网络优先出版日期:2015- 07- 06。
网络优先出版地址:http://www.cnki.net/kcms/detail/11.2422.TN.20150706.1705.013.html
国家自然科学基金(61305042,61202098);河南省教育厅科学技术研究重点项目(13A520071)资助课题
猜你喜欢
房地产导刊(2022年4期)2022-04-19
曲阜师范大学学报(自然科学版)(2021年3期)2021-08-26
数学小灵通(1-2年级)(2021年4期)2021-06-09
开放教育研究(2020年2期)2020-03-31
山东农业工程学院学报(2020年12期)2020-03-19
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
