
基于MapReduce的隐私保护的关联规则挖掘算法的研究
2015-05-30 20:22熊富蕊桑应朋
智能计算机与应用 2015年6期
熊富蕊 桑应朋

摘要:主要针对关联规则中的Apriori算法在执行过程中产生大量候选集和重复扫描数据库会使串行算法的时间复杂度高和执行率低的缺点,提出了一种基于MapReduce的并行关联规则挖掘算法,对传统的关联规则算法进行并行优化。在Hadoop平台上进行了单机测试和集群测试。分析得出基于MapReduce的关联规则算法克服了串行算法产生大量候选集和重复扫描数据库的两大缺点,从而提高了执行效率。此外,针对目前数据隐私泄露的严重现象,在进行并行化的数据挖掘之前,使用加随机数的方法来保护数据的隐私,并验证了保护数据在关联规则挖掘中保留了高可用性。
关键字:MapReduce;Apriori;Hadoop;隐私保护
中图分类号:TP391 文献标识码 A文章编号:2095-2163(2015)06-
Abstract:The main disadvantage of Apriori algorithm for association rule mining is that it produces large amounts of candidate sets and database scannings during execution, making the serial algorithm having high time complexity and low implementation rate. This paper proposes a new algorithm based on MapReduce,which optimizes the traditional association rule algorithm in a parallel way.Simulations based on the hadoop platform are performed on one single machine and clusters. The results demonstrate that our new algorithm based on MapReduce overcomes the disadvantage of the serial algorithm.Whats more, considering the serious phenomenon of data privacy leaking, the paper uses randomization to protect data privacy before they are mined, and shows the randomized data keep a high utiltity for association rule mining.
Keywords: MapReduce;Apriori;Hadoop;Privacy_Preserving
0 引言
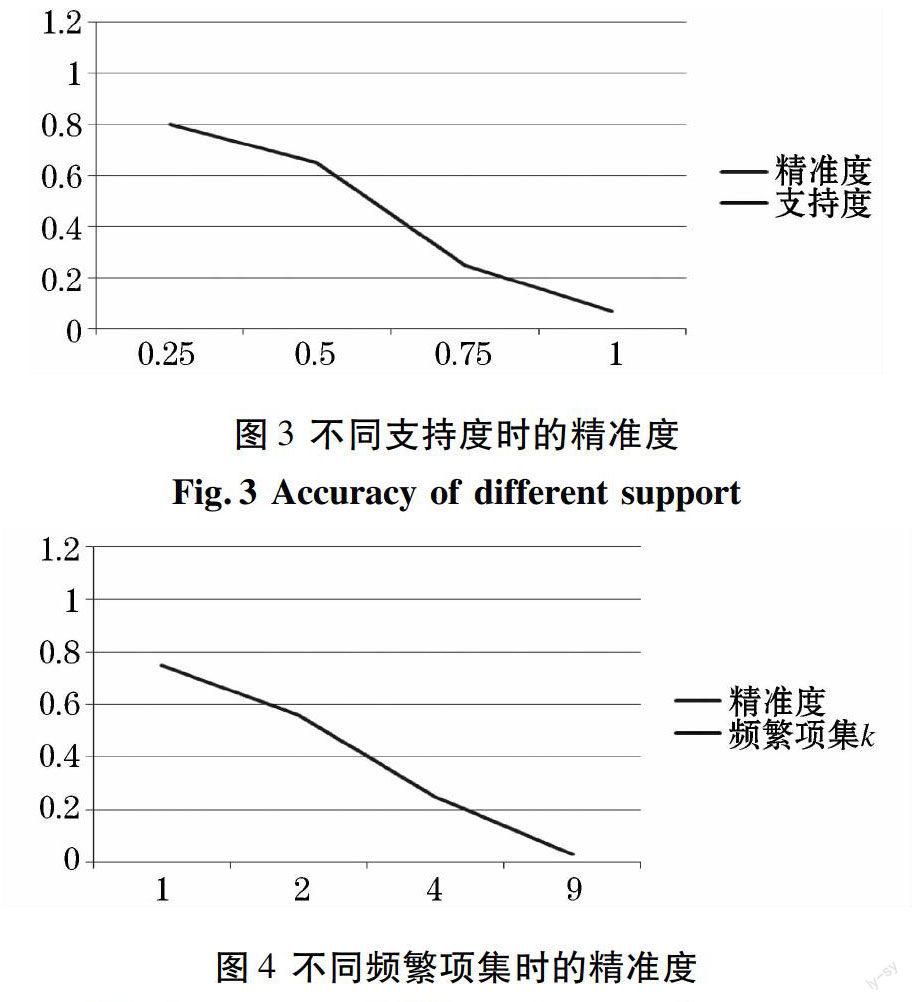
随着各行各业的快速发展,大量的数据开始出现和累积。然而,如何从这些数据中,提取出所需要的有用信息,则已成为时下研究关注、且瞩目的一个焦点问题。作为一个分析工具,数据挖掘可以从大量数据集中发现有趣、有用的信息。现如今数据挖掘的技术已经开始用于商业用途,藉此提高商业价值。数据挖掘主要分为三大领域:分类分析、聚类分析和关联规则分析。尤其是,关联规则分析已经获得了数据挖掘中比较重要的领域地址,具体实现主要分为两步:发现频繁项目集和生成关联规则。关联规则中的一种基本算法就是Apriori算法。该算法在执行过程中会产生大量的候选集,并且还要多次重复扫描数据库。由此可知,随着数据的逐渐增加,有如Apriori这样的传统挖掘算法已经不能快速有效地分析获取有用的信息。基于以上背景所述,本文提出了一种新的基于MapReduce的并行关联规则的算法。此外,随着挖掘技术的不断进步,使得一些敏感、有用的信息相继公开,这就增加了原始数据的风险性。因此,基于隐私保护[1-2]的需求,本文即在数据挖掘前使用了添加随机数的方法,从而实现对数据隐私的保护。
1 国内外研究现状
现在国内外已经应用很多方法解决关联规则挖掘算法[3-6]。随着大量数据的产生,各种并行关联规则算法也随即陆续提出。例如:CD (Count Distribution) CaD(Candidate Distribution) and DD (Data Distribution)[7-8],这些算法可以运用于云计算环境。但是算法却都具有缺乏同步性的缺点。
文献[9]针对Apriori算法产生大量候选项集的缺点,提出了一种频繁模式算法(FP),是一种不用生成候选项目集,实现Apriori的算法。可以快速构建挖掘模型,是一种高效的关联规则算法。
文献[10-13]提出了基于MapReduce的Apriori并行算法,利用Hadoop平台的多个节点并行运算的Apriori算法。可以有效地实施并行化,但仍会产生大量候选项集。
2 基础理论概述
2.1关联规则挖掘和Apriori算法
设I={i1,i2…,im}是项的集合。给定一个交易数据库D,其中每个事务T是I的非空子集,即,每一個交易都与一个唯一的标识符TID(Transaction ID)对应。关联规则在D中的支持度(support)是D中事务同时包含A、B的百分比,即P(A∪B);置信度(confidence)是D中事务已经包含A的情况下,包含B的百分比,即P(B|A)。如果满足最小支持度阈值和最小置信度阈值,则认为关联规则是有趣的[14]。关联规则的挖掘分为两个步骤:
(1)找出所有满足最小支持度的频繁项集;
(2)由频繁项集产生满足最少支持度和最少置信度的强关联规则。
Apriori算法是最具影响的一类关联规则挖掘算法,使用一种逐层搜索的迭代方法。其具体实现过程为:首先,找出1-项集的集合(L1),用L1去找频繁2项集L2。依次下去,直至不能找到频繁k项集。每寻获一个LK都需要扫描一次数据库。所以,需要多次重复扫描数据库导致时间复杂度较高和执行效率降低。伪代码如下[15]:
输入:交易数据库D,最小支持度min_sup。
输出:频繁集L
L1=find_frequent_1_itemset(D);//产生1-频繁集
for(k=2;Lk-1!=?;k++){
Ck=apriori_gen(Lk-1,min_sup);//产生k-候选集
for each transaction t in D{
Ct=subset(Ck,t);//获得事务t包含的候选项集
for each candidate c in Ct
c.count++; }
Lk={c∈Ck|c.count>=min_sup}; }
L=?kLk;
Procedure apriori_gen(Lk-1:frequent(k-1)-itemset;min_sup:support)
Foreach itemset l1 in Lk-1
Foreach itemset l2 in Lk-1
If( (l1 [1]=l2 [1])&&( l1 [2]=l2 [2])&& …&&(l1 [k-1]then{ c = l1 link l2 // 连接步:产生候选
if has_infrequent_subset(c, Lk-1) then
delete c; // 剪枝步:删除非频繁候选
else add c to Ck; }
Return Ck;
Procedure has_infrequent_subset(c:candidatek-itemset;
Lk-1 :frequent(k-1)-itemsets)
For each (k-1)-subset s of c
If s?Lk-1 then
Return true;
Return false;
2.2Hadoop平台
Hadoop是一个开发和运行处理大规模数据的软件平台,是Appach的一个基于java语言推出的开源软件框架,可以实现在大量计算机组成的集群中对海量数据进行分布式计算[16]。Hadoop的框架最核心的设计就是:HDFS和MapReduce。在此,对其分述如下。
HDFS(Hadoop Distributed File System)是一个分布式文件系统,由一个名称节点(NameNode)和N个数据节点(DataNode)组成,每个节点均是一台普通的计算机。NameNode 是一个通常在 HDFS 实例中的单独机器上运行的软件,具体负责管理文件系统名称空间和控制外部客户机的访问。NameNode 决定是否将文件映射到 DataNode 上的复制块上。Hadoop 集群包含一个 NameNode 和大量 DataNode。DataNode 响应来自 HDFS 客户机的读写请求。同时还响应来自 NameNode 的创建、删除和复制块的命令[17]。
MapReduce是一种并行编程模型,其基于HDFS拓展实现,可用于大规模数据集的并行计算。MapReduce编程模型的原理是:MapReduce 以函数方式提供了 Map 和 Reduce 来进行分布式计算。Map 相对独立且并行运行,对存储系统中的文件按行处理,处理后产生键值(key/value)对。Reduce则以 Map 的输出作为输入,相同键值的记录汇聚到同一 reduce,再对这组记录进行操作,相应将产生新的key/value对集合[18]。
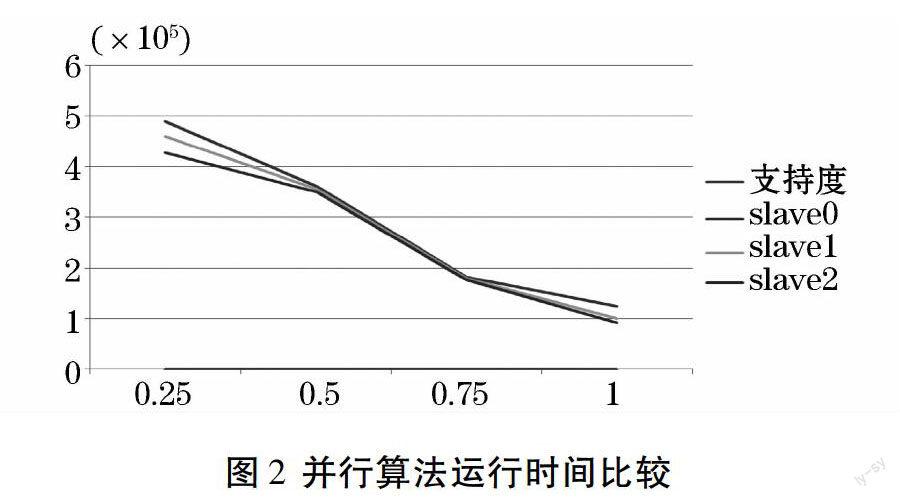
3 基于Mapruduce的隐私保护的关联规则挖掘算法
该算法的思想是:首先通过加随机数的方式对原始的数据D进行保护,得到变换后的数据D1。然后使用mapreduce的分布式编程原理,将原始数据集按行划分为多个小数据集,分布到三個节点上。稍后每个节点对输入的数据块分配一个map,通过map函数执行,并采用一种改进的Apriori算法计算满足最小支持度的候选项目集。最后使用reduce函数获得频繁项目集,再将得到的数据集存放在HDFS上。主要实现步骤为:
(1)在每个节点上对原始数据D添加随机数变成D1。
(2)第一阶段:
在每个节点上用map函数对数据进行操作,分割的整个数据集作为输入,产生键值对
Struct hashnode{
Map mapnode;
Boolean isleafnode;
List items;
}
在datanode上用reduce函数对map输出结果进行整合。将结果返回给namenode节点。Reduce函数输出结果为key/value对,key代表频繁1项集元素,value为出现该键值的次数。并且将结果存储在HDFS中。生成1频繁项目集。
(2)第二阶段:直接从HDFS中取出数据,此时的数据已经不是最初数据库中的原始数据,而是前一阶段产生的1频繁项目集,这样就大大的缩减了候选项集的数目。此后再通过map/reduce函数重复以上的步骤,依次找到2频繁项目集、k频繁项目集。
(1)-(3)伪代码如下:
Map task:
输入:改变后分割数据D2
输出:对,key代表频繁项目集的元素
map(object, D2)
C=G-Apriori(D2)
Foreach itemset item in C
Out(item,one);
End foreach
End map
End
Reduce task
输入:
参考文献:
[1]ZHU Jianming, ZHANG Ning, LI Zhanyu Li. A new privacy preserving association rule mining algorithm based on hybrid partial hiding strategy[J]. Bulgarian Acadmeny Of Sciences,2013,13(special issue):41-50.
[2]AGRAWAL D, AGGARWAL C C. On the design and quantification of privacy preserving data mining algorithms[C]// PODS '01 Proceedings of the twentieth ACM SIGMOD-SIGACT-SIGART symposium on Principles of databases,New York:ACM,2002:247-255.
[3]TOIVONEN H.Sampling large databases for association rules[C]// Intl.Conf.on Very Large Databases,Bombay,India:ACM,1996:134–145.
[4]SAVASERE A ,OMIECINSKI E , SHAMKANT B. Et al. An efficient algorithm for Mining Association Rules in Large Databases[C]// Proceedings of the 21th International Conference on Very Large Data Bases, San Francisco:Morgan Kaufmann Publishers Inc,1995 :432-444.
[5]FANG Min , SHIVAKUMAR N ,GARCIA-MOLINA H ,et al. Ullman, computing iceberg queries efficiently[C]//Proceedings of the 24rd International Conference on Very Large Data Bases,New York:Morgan Kaufmann,1998:299-310.
[6]QURESHI Z,BANSAL J, BANSAL S. A survey on association rule mining in Cloud Computing[J].International Journal of Emerging Technology and Advanced Engineering,2013,3(4):2250-2459.
[7]ASHRAFI M Z, TANIAR D, SMITH K. ODAM: An optimized distributed association rule mining algorithm[J]. Distributed Systems Online IEEE, 2004, 5(3):1.
[8]LI L, ZHANG M. The strategy of mining association rule based on Cloud Computing[J]. IEEE, 2011, 52(1391):475-478.
[9] SANJEEV R, GUPTA P. Implementing improved algorithm
over APRIORI data mining association rule algorithm[J].IJCST,2012,3(1):2250-2459.
[10] CHEN SY, LI Jiahong Li, LIN Kechung Lin, et al.
Using MapReduce framework for mining association rules[C]//
Springer Science+Business Media Dordrecht,TaiWan:NSC,2013:723-731.
[11] RIONDATO M, DEBRABANT J A, FONSECA R, et al. PARMA: a parallel randomized algorithm for approximate association rules mining in MapReduce[C]// Proceedings of the 21st ACM international conference on Information and knowledge management,New York:ACM, 2012:85-94.
[12] YANG Xinyue, LIU Zhen, FU Yan. MapReduce as a programming model for 1ssociation rules algorithm on hadoop[C]// 3rd International Conference on Information Sciences and Interaction Sciences. Chengdu: IEEE,2010:99-102.
[13]LI N, ZENG L, HE Q, et al. Parallel implementation of Apriori Algorithm based on MapReduce[C]// Proceedings of the 2012 13th ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and ParallelDistributed Computing. USA:IEEE Computer Society,2012:236-241.
[14]LIN Xueyan. MR-Apriori:Association rules algorithm based on MapReduce[A]. IEEE Beijing Section.Proceedings of 2014 IEEE 5th International Conference on Software Engineering and Service Science[C].Beijing:IEEE Beijing Section,2014:4.
[15]ZHANG CS, LI ZY, ZHENG DS. An improved algorithm for Apriori. Fourth[C]// Proceedings of the 1st International Workshop on Education Technology and Computer Science, ETCS 2009,v1,Wuhan:IEEE,2009:995-998.
[16]孫赵旭,谢晓兰,周国清,等. 基于Hadoop的Apriori算法与实现[J]. 桂林理工大学学报,2014(3):584-588.
[17]郝晓飞,谭跃生,王静宇. Hadoop平台上Apriori算法并行化研究与实现[J]. 计算机与现代化,2013(3):1-4+8.
[18]LIN M Y, LEE P Y, HSUEH S C. Apriori-based frequent itemset mining algorithms on MapReduce[C]// Proceedings of the 6th International Conference on Ubiquitous Information Management and Communication,New York:ACM,2012:20-22.
猜你喜欢
大众投资指南(2021年35期)2021-02-16
电脑爱好者(2020年18期)2020-09-26
电脑爱好者(2017年9期)2017-06-01
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
计算机工程(2014年6期)2014-02-28
电子设计工程(2014年18期)2014-02-27
网络安全与数据管理(2010年1期)2010-05-18
浙江师范大学学报(自然科学版)(2010年2期)2010-01-11
网络与信息(2009年9期)2009-10-30
