
基于动态机制的主题事件中的时间识别和规范化
2015-05-30 10:48:04李风环郑德权赵铁军
智能计算机与应用 2015年6期
李风环 郑德权 赵铁军


摘 要:事件中与主题相关的时间信息体现了事件在时间维度的特征。而当前面向事件的时间识别大多是基于句子或短语的,并采用静态时间值机制。本文提出了一个面向主题事件的时间识别模型。该模型采用参考时间动态选择机制对时间表达式进行规范化,然后利用设置了优先级的关键词,将基于句子或短语的时间识别转化为基于篇章的时间识别,从而识别主题事件中的时间。改善了纯粹基于关键词或静态参考时间机制的主题事件中的时间识别的性能。
关键词:主题事件;时间表达式规范化;时间识别;参考时间;动态
中图分类号:TP391 文献标识号:A 文章编号:2095-2163(2015)06-
Abstract: Temporal information related to topic event reflects temporal characteristic of events. Most research on time recognition is sentence-oriented or phrase-oriented, and adopts static mechanism. A time recognition model for topic event is proposed in this paper. Dynamic choosing mechanism of reference time is developed for normalizing temporal expressions, then key words are assigned to different priorities. Sentence-level or phrase-level time recognition is transformed into document-level in topic event. The performance is improved greatly compared to the algorithm just based on key word or reference time static choosing strategy.
Keywords: Topic Event; Temporal Expression Normalization; Time Recognition; Reference Time; Dynamic
0 引言
人们不止关注一个动作的发生和变化,更多的是想关注一个专题事件整体的信息框架和发展过程。本文根据这一现象提出面向主题事件的时间识别和规范化。目前规范化处理主要采用两种参考时间选择机制,即上下文无关策略[1]和上下文局部相关策略[2]。但是研究发现这两种机制都不适用于真实的新闻文本,因为固定的时间值或者规则[3-4]仅仅能解决静态的单一时态参照选择问题,对于动态变化的真实语境下的时间表达式不适合[5]。研究者对时间表达式的识别和规范化已经提出了很多方法。主要是基于规则[6]和机器学习[7-8]的方法。基于规则的方法简单,易于理解,便于扩展。但是缺点是人工工作量较大,早期的方法完全使用人工方式来构建规则,后期则先通过一些机器标注的方法对文本进行预处理,然后根据标注结果构建规则。基于机器学习方面,D.Ahn[7]和K.Hacioglu[8]分别进行了尝试,研究中首先将语料进行预处理,接着有选择地抽取特征,通过分类器训练模型进行时间表达式的标注。Lin等人[9]采用动态方法来处理隐式时间表达式,用新的计分模型来确定网页的关注时间并设计了基于时间和文本相关度的时间-文本检索排序方法。赵旭剑等人[10]在时间表达式的规范化方面,选择了动态基准时间选择机制,并对模糊时间表达式根据场景依赖性进行了去模糊处理,达到了较好的效果。
当前面向事件的时间识别大多是基于句子或短语的,并采用静态时间值机制。针对上述问题,本文提出了一个面向主题事件的时间识别模型,该模型采用参考时间动态选择机制对时间表达式进行规范化,然后将基于句子或短语的时间识别转化为基于篇章的时间识别。改善了纯粹基于关键词或静态参考时间机制的性能。本文内容包括两个任务:时间表达式的识别和规范化,以及主题事件片段的时间识别。
1 基于动态选择机制的时间表达式的识别和规范化
中文表达式是多种多样的,包括明确的时间表达式和隐式时间表达式[10]。在此,给出这两类表达式的具体含义。
(1) 显式时间表达式(Explicit Time,ET):能够直接在时间轴上定位准确的时间,不需要进行转换,比如“2008年5月12日”、“2008-05-12”等。
(2) 隐式时间表达式(Implicit Time,IT):需通过上下文和先验知识进行确定准确时间,且需要转换,比如“5月12日”、“两天以前”等。还包括基于事件的时间,比如:“汶川地震发生后两小时”等。
时间表达式的表现规则是多种多样的,不仅包括外部规则,还有内部规则。时间表达式的出现总是伴随着相应事件的发生,并且和关联的名词、动词、介词等构成了外部规则,比如:在北京时间+time+发生。如果一个句子的出现符合该规则,则认为“发生”前面的词语为时间表达式。内部规则是时间表达式本身的组织结构,通常,时间表达式包括年月日时分秒,描述方式如:“2008年5月12日”、“2008-05-12”等。如果一个时间表达式满足这种规则,相应位置的数字就被识别为特定的时间。显式时间表达式的内部规则相对比较明显和统一,因此对显式时间表达式利用内部规则模式匹配的方法進行识别和规范化,规范化后的时间格式如“年-月-日”,并且被标记为“ET”。
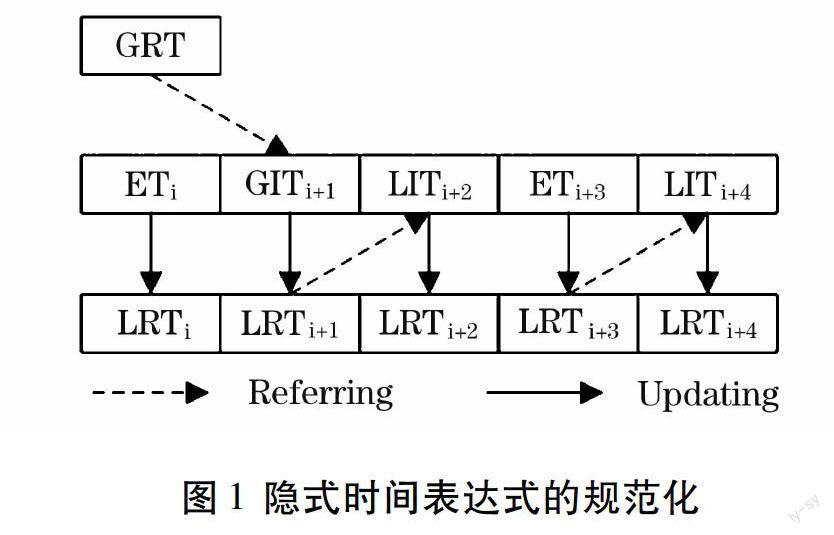
隐式时间表达式利用基于规则的方法进行规范化,该过程需要确定参考时间、偏移粒度、偏移量。规范化后的时间被标记为“IT”。偏移量和偏移粒度由时间表达式本身的语义决定。偏移量是相对参考时间的偏移量,偏移粒度是时间表达式本身的粒度。比如“5月”或“12日”这样的隐式时间, 偏移量和偏移粒度能够很明确地获得,因此这样的表达式能够很容易被规范化。但是像“昨晚” 和“当时”等表达式,研究则创建了一个隐式时间表达式参照表来获得偏移量、偏移粒度以及参考时间类型。隐式时间转换参考表根据语料获取并进行扩展,组成四元词对的形式,如(今晚,0,天,GRT)可以扩展出(明晚,1,天,GRT),参考表如表1所示。本文并没有对所有时间进行转换,因为一些表达式转换后并不能对具体时间的确定起到作用,反而会影响时间确定的效果,比如“近期”,“震后”,“将来”等。隐式时间表达式规范的参考时间有两种:全局参考时间和局部参考时间。
(1) 全局参考时间(Global Reference Time,GRT):以报道时间或者新闻的发布时间作为参考时间,推测出时间表达式的具体时间信息。
(2) 局部参考时间(Local Reference Time,LRT):以最近的叙述时间为参考时间,即以前一个时间表达式的信息为参考来推断当前时间表达式的具体时间信息。
本文选用动态参考时间选择机制,全局隐式时间表达式(Global Implicit Time, GIT)选用全局参考时间,局部隐式时间表达式(Local Implicit Time,LIT)选用局部参考时间。同时需要维护局部参考时间表的更新,以确保最新的局部参考时间和隐式时间表达式的及时性。局部参考时间列表的维护和隐式时间表达式的转化如图1所示。
2主题事件片段时间识别
主题事件片段对应于一篇新闻报道,因此主题事件片段时间的识别是基于篇章的。事件发生的时间常常是和能代表事件的关键动名词相关联。对于主题事件片段时间的识别,一般是把每个关键动名词前面的时间表达式识别出来,如果没有,则识别后面的时间表达式,然后再考虑其他的关键动名词。由于时间信息一般出现在关键词的前面,因此研究中改变了关键词的检索方式。而且还需要确定主题事件片段的发生时间,所以这些关键动名词要尽可能地覆盖语料中所有事件片段。同时,每一个关键动名词对于时间识别的影响不是同等重要的,在此即对动名词的优先级进行了设置,关键词的确定方法如下:
(1) 根据TFIDF(Term Frequency,Inverse Document Frequency)公式来确定时间表达式所在句子中的词语的权重,选取权重最高的词语,作为一个关键动名词,并把该词语的优先级设为最高。
(2) 对不包含已确定关键词,但包含时间表达式的句子中的词语,应用TFIDF公式,选取权重最高的词语,作为一个关键动名词,并把该词语的优先级设为其次。
(3) 重复(2)中的过程,直到语料中的所有文件都能找出关键动名词,形成最初的关键动名词表。
(4) 对关键动名词表进行基于领域和同义词进行扩展,形成最终的关键动名词表。
主题事件片段时间识别的步骤如下:
(1) 规范化显式和隐式时间表达式;
(2) 按照上述方法确定具有优先级属性的关键动名词表;
(3) 按照优先级依次查找每个关键动名词的前面是否有规范化后的时间表达式,如果有,则把该时间作为主题事件片段时间,不再继续查找;
(4) 如果所有的关键动名词之前都没有规范化后的时间表达式,则按照优先级依次查找关键动名词之后的时间表达式,如果有,则把该时间作为主题事件片段的时间,不再继续查找;
(5) 如果所有关键动名词之后都没有规范化后的时间表达式,则认为为空。
3 实验结果与结论分析
本文在ACE07语料上进行了时间表达式的识别和规范化,识别结果如表2所示,规范化结果如表3,表4和表5所示。本文主要是时间规范化和主题事件片段的时间识别,因此没有对时间表达式的识别进行对比分析,而只是针对时间规范化的参考时间选择策略进行了分析,对比实验分别选择上下文无关策略和上下文局部相关策略。时间表达式规范化包括3组实验:
(1) 在正确识别的表达式上的实验,记为:RC。
(2) 在所有识别的表达式上的实验,记为:R。
(3) 在语料中标注的所有表达式上的实验,记为:G。
从表3,表4和表5的实验结果看出,本文算法的性能明显超过了另外两种策略。正确率最高提高了18%。相对于上下文局部相关算法,本研究解决了在参考时间选择过程中,仅仅考虑局部语境而忽视了时间表达式本身的语义问题。同时相对于上下文无关策略,其采用文档的报道时间或者发布时间作为全局参考时间,所有的时间表达式都选用相同的参考时间,就使其具有了一定的局限性。ACE07语料中有很多基于事件的时间表达式,比如:“年前”和“个把小时”等,这类时间表达式很难规范化,因此当在语料中标注的所有表达式上进行时间表达式规范化时,效果反而可能是最差的。
为了研究主题事件片段时间识别的性能,本文从网站爬取了1 890篇地震事件。因为语料中不但有对当天事件的报道,还有跟踪报道,因此不能单纯地选用局部参考时间,这将显著影响了实验效果。根据本文算法的特点,实验分为3个阶段,每个阶段的实验效果如表6所示。
(1) 阶段1:选用局部参考时间规范化隐式时间表达式,检索所有关键动名词前面的时间表达式,如果所有关键词前面都没有规范后的时间表达式,则检索关键词后面的时间表达式。
(2) 阶段2:根据语义不同,隐式时间进行规范化时动态选择全局和局部参考时间。
(3) 阶段3:由于关键词对时间确定的影响不是同等重要的,因此对关键词设置了优先级,依据优先级,依次处理每一个关键词。
可以看到,隐式时间规范化改进处理后,结果并没有显著的改进。经分析,地震新闻报道中,由于地震的发生几乎都是瞬时的,因此全局时间和局部时间的时间差不是很大,除非是专题报道或灾后重建这样的报道中,时间差相对较大。设置了关键词的优先级后,实验效果得到了较大的提高,说明不同关键词对于时間表达式识别的影响还是有一定的差距的,并验证了本文方法的可行性和有效性。由于本文没有处理基于事件的时间,比如“汶川地震”,如果文章中提到这个词,将会直接联想到发生时间是“2008年5月12日”,但在实现过程中没有对此信息进行处理。下一步要考虑基于事件的时间。同时,本文与冯礼的方法[11]进行了比较,可以看到本文方法的实验效果大大好于对比方法,如表6所示。
4 结束语
当前面向事件的时间识别大多是基于句子或短语的,并采用静态时间值机制。针对这些问题,本文提出了一个面向主题事件的时间识别模型。该模型采用参考时间动态选择机制对时间表达式进行规范化,然后利用设置了优先级的关键词,将基于句子或短语的时间识别转化为基于篇章的时间识别,从而识别主题事件中的时间。实验表明,在时间表达式规范化任务中,参考时间动态选择机制比上下文无关策略和上下文局部相关算法取得了更高的正确率;关键动名词优先级的设置,大大改善了主题事件片段的时间识别效果。
参考文献:
[1] WU Mingl, LI Wenjie, LU Qin, et al. CTEMP: A Chinese temporal parser for extracting and normalizing temporal information[C]// Proceedings of IJCNLP, Berlin, Heidelberg, Germany: Springer-Verlag, 2005: 694-706.
[2] 林静, 曹德芳, 苑春法. 中文时间信息的TIMEX2自动标注[J]. 清华大学学报, 2008, 48(1): 117-120.
[3] 赵华. 话题检测与跟踪关键技术研究[D]. 哈尔滨: 哈尔滨工业大学, 2008.
[4] HE Dan, PARKER D S. Topic dynamics: An alternative model of ‘Bursts in streams of topics[C]// Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA: ACM, 2010:443-452.
[5] 趙旭剑. 中文新闻话题动态演化及其关键技术研究[D]. 合肥: 中国科学技术大学, 2012.
[6] LLIDO D, BERLANGA R, ARAMBURU M J. Extracting temporal references to assign document event-time periods[C]// Proceedings of the 12th International Conference on Database and Expert Systems Applications, Berlin, Heidelberg, Germany: Springer-Verlag, 2001: 62-71.
[7] AHN D, ADAFRE S F, De RIJKE M. Towards task-based temporal extraction and recognition[C]// Proceedings of Annotating, Extracting, and Reasoning about Time and Events, Dagstuhl, Germany: Internationales Begenungs-und Forschungszentrum Informatik (IBFI), 2005:05151.
[8] HACIOGLU K , CHEN Ying, DOUGLAS B. Automatic time expression labeling for English and Chinese text[C]// Proceedings of Computational Linguistics and Intelligent Text Processing (CICLing), Berlin, Heidelberg, Germany: Springer-Verlag, 2005, 3406: 548-559.
[9] LIN Sheng, JIN Peiquan, ZHAO Xujian, et al. Exploiting temporal information in Web Search[J]. Expert Systems with Applications, 2014, 41(2): 331-341.
[10] ZHAO Xujian, JIN Peiquan, YUE Lihua. Automatic temporal expression normalization with reference time dynamic-choosing[C]// Proceedings of Coling, Stroudsburg, PA, USA: Association for Computational Linguistics, 2010:1498-1506.
[11] 冯礼. 基于事件框架的突发事件信息抽取[D]. 上海: 上海交通大学, 2008.
猜你喜欢
开封文化艺术职业学院学报(2020年6期)2020-08-07 02:59:00
疯狂英语·新策略(2020年7期)2020-07-30 03:22:02
数学物理学报(2020年2期)2020-06-02 11:29:10
安顺学院学报(2020年1期)2020-04-05 10:57:20
新世纪智能(英语备考)(2019年9期)2019-11-04 00:46:24
现代计算机(2019年6期)2019-04-08 00:46:50
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
