
基于深度学习的手写数字分类问题研究*
2015-05-23 07:50宋志坚重庆交通大学信息科学与工程学院重庆400074重庆交通大学交通运输学院重庆400074
重庆工商大学学报(自然科学版) 2015年8期
关键词:深度学习
宋志坚,余 锐(.重庆交通大学信息科学与工程学院,重庆400074; .重庆交通大学交通运输学院,重庆400074)
基于深度学习的手写数字分类问题研究*
宋志坚1,余锐2
(1.重庆交通大学信息科学与工程学院,重庆400074; 2.重庆交通大学交通运输学院,重庆400074)
摘要:手写体数字因其书写风格差异大、上下文无关及识别准确度要求高等原因导致其识别难度大,针对手写体数字识别的特点及要求,使用深度学习算法进行分类,通过对样本的训练完成手写体数字的识别,同时与SVM算法及BP神经网络分类效果进行对比;实验结果表明深度学习在识别手写体数字时具有更高的准确率。
关键词:手写体数字识别;深度学习;样本训练
由于不同的人所写的数字体形态各异,千差万别,书写不规范导致手写数字识别的复杂性,而手写体数字的识别是建立在特征提取及比较的基础之上的。按照提取字符特征的不同,现有的数字手写体识别算法大体上可以分为两类:一类是基于结构特征的手写体数字识别算法。它们通过识别字符图像内部包含的凹陷区特征、轮廓特征结构突变点特征等基元,采用模板匹配的方式实现手写体数字的自动识别[1,2]。这类方法能够直观地描述字符的结构,但是存在着对字符形变及噪声缺乏鲁棒的问题;另外一类是基于统计特征的手写体数字识别算法。这类算法基于对大量样本的表征、变换和学习,通过估计不同样本类别的特征空间分布训练相应的分类器,并利用这些分类器对未知模式进行分类[3,4]。当训练样本选取得足够充分时,这类方法能够具有很好的识别能力。
针对手写体识别的特点及要求,分析现有算法存在的问题,使用深度学习进行手写体数字识别。算法能够通过使用大量的简单神经元组成的网络,利用输入与输出之间的非线性关系,对复杂函数进行近似,对观测样本进行拟合,并在学习输入样本本质特征的抽取上体现了强大的能力,实现了手写体数字的自动识别。
1 深度学习
深度学习(Deep Learning)的概念由Geoffrey Hinton等人提出,与传统机器学习相比,整合特征抽取和分类器到一个学习框架下,克服了传统方法中,特征选取困难等问题。
深度学习是通过大量的简单神经元组成,每层的神经元接收更低层的神经元的输入,通过输入与输出之间的非线性关系,将低层特征组合成更高层的抽象表示,并发现观测数据的分布式特征。通过自下而上的学习形成多层的抽象表示,并多层次的特征学习是一个自动地无人工干预的过程。根据学习到的网络结构,系统将输入的样本数据映射到各种层次的特征,并利用分类器或者匹配算法对顶层的输出单元进行分类识别等。
1.1深度学习的基本思想
假设一个系统S,它是一个n层(S1,S2,…,Sn)的结构,I是系统的输入,O是系统输出,形象地表示为:I=>S1=>S2=>…=>Sn=>O,如果输出O等于输入I,物理意义也就是表明在经过系统变化之后,输入I的信息量没有任何损失,和原始的输入保持了不变,这表明了输入I经过每一层Si均没有丢失任何信息,即在任何一层Si,它都是输入I也就是原始信息的另外一种表示。
1.2受限玻尔兹曼机(RBM)
1.2.1RBM的模型定义
与传统神经网络相比,深度学习一个重要的突破就在于,在一定程度上克服了浅层神经网络训练的效率和效果问题。而在Hinton等人提出来的框架中,这种深度学习的学习策略,就是在进行多层的模型全局学习之前,先将多层神经网络分解为若干个受限玻尔兹曼机(Restricted Boltzmann Machine,简称RBM)的叠加,并逐层训练RBM。因此RBM作为深度学习中一个非常重要的基础模型。
RBM是一个随机的二值化对称连接的神经网络,是一种特殊形式的对数线性马尔可夫随机场(MRF),也就是说其能量函数关于其自由参数是线性的。它包含了一组可视单元v∈{ 0,1}D,和一组隐藏单元h∈{ 0,1}P。当参数一定时,对于一个受限的玻尔兹曼机(RBM)来说,其能量定义为
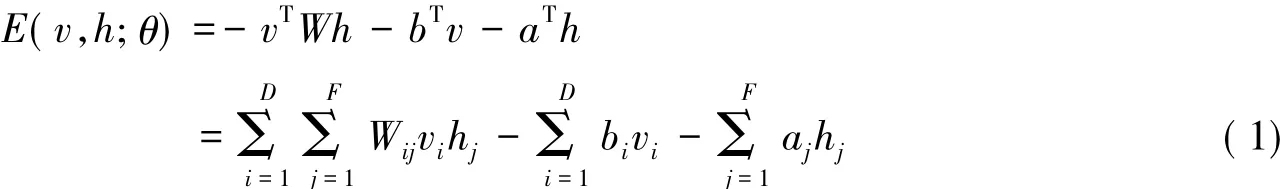
这里θ={ W,b,a}是RBM模型的参数,其中Wij表示可视层节点vi到隐层节点hi的链接权重,bi和aj是偏置项。RBM的状态符合玻尔兹曼分布的形式,即可视节点和隐层节点的联合概率分布被定义为

其中,P(v,h;θ)这种分布被称之为玻尔兹曼分布函数;而Z(θ)是一个分布和,又或者叫做归一化常数。那么RBM模型分配给可视节点v的概率:

由于RMB模型二分结构的这一特殊性,隐层节点可以清楚地同可视层区分开来:
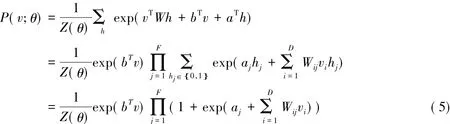
由于在RBM中,同一层节点之间是互不相联的,因此,在给定其中一层节点状态时,另一层节点之间的状态条件分布相互独立,即:

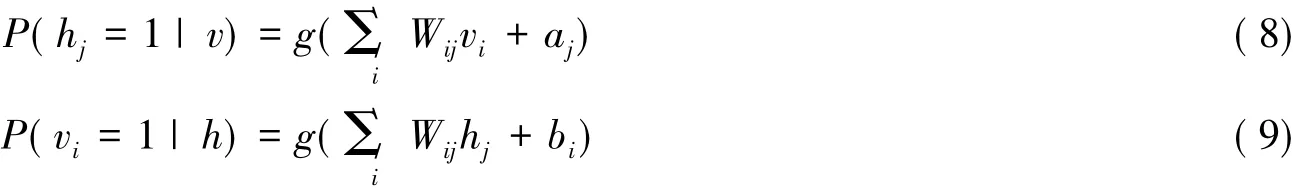
其中,g(x)为sigmoid函数,g(x) = 1/(1 + exp(-x) )是一个逻辑函数。
1.2.2RBM的学习
RBM可利用极大似然法学习[5]。在给定训练数据v1,v2,…,vD。学习RBM相当于最大化目标函数logP(v;θ)。这种情况下,先对一般数据进行推导。给定某个点x可以用函数的形式表示记为f(x;θ),此处θ是模型的参数向量。那么x的概率P(x;θ)可以表示为

其中,Z(θ)是分配函数,定义为

学习模型参数θ,可以通过最大化一组训练数据X=x1,x2,…,xk的概率,即:

那么:
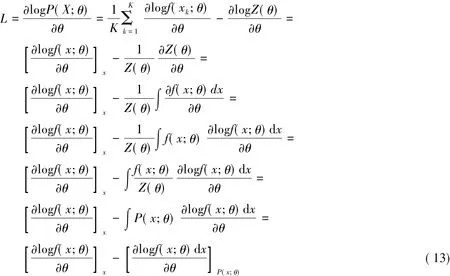
可根据减号将公式分为正项(positive phase)和负项(negative phase)两个部分。对于正项部分,表示的是满足训练数据分布中的数据期望,可以通过遍历所有训练数据算出来。而对于负项部分,表示的是概率密度分布为p(x;θ)的函数f(x)的均值。
同样地,RBM模型的参数以及其分布概率函数,根据极大似然准则可以从公式(1)推导出:
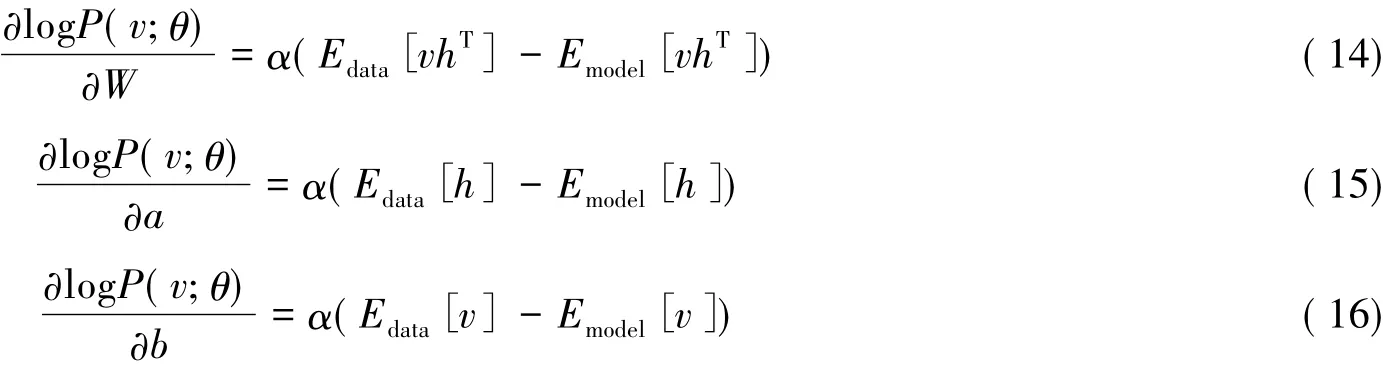
在RBM中,正项表示满足Pdata(h,v;θ) = P(h|v;θ) Pdata(v)这数据分布的平均值,而负项是满足模型定义的分布的数据期望,这个均值在采用极大似然算法中复杂度为min{ D,F}的指数级,也就是输入节点或隐藏层节点数目的指数级。这个积分的计算通常来讲不是线性可算的。此时对分布p(x)下的样本进行大量采样并求其均值就可以逼近原积分结果。对于各态遍历的马尔可夫过程,随着转移次数的增多,随机变量的取值分布将不受随机变量初始值的影响,最终都会收敛于唯一的平稳分布[6]。这意味着,不论随机变量的初始值设为多少,经过足够多次转移之后,变量取各值的概率总会不断接近于该过程的平稳分布。显然,如果为了获取某个目标分布下采样,只需要模拟以其为平稳分布的马尔可夫过程,并执行足够多次的概率转移得到一个与样本分布接近的平衡分布。
1.3深度信念网络
全局优化具有多个隐藏层的深度信赖网络往往是难以处理的,而为了取得较好的优化性能,贪婪算法是可以用于此处的,即逐层优化,每次只学习相邻两层RBM模型参数,并通过这样子贪婪地逐层学习以获得全局的DBNs[7]。通过贪婪算法获得的深度信赖网络根据最终的感兴趣的判别准则进行微调就可以获得最终深度信赖网络,也就是把一个DBNs网络分层,对每一层进行无监督学习,最后对整个网络用监督学习进行微调。过程可以归为两部分:
(1)预训练。深度信赖网络分解成由相邻两层构成的一系列受限的玻尔兹曼机,逐层训练参数,初始化深度信赖网络:首先将经验数据v作为输入,训练第一层受限波尔兹曼机的权值系数矩阵W1;接着将W1固定,通过p(h1|v) = p(h1|v,W1),训练出第一层受限波尔兹曼机的隐层向量h1;将h1作为第二层受限波尔兹曼机的输入,训练第二层受限波尔兹曼机的权值系数矩阵W2;递归地计算出每一层的隐含单元向量和权值系数矩阵。
(2)微调。为了使得模型具有更好的表现能力,当完成一组RBM之后,将其展开,然后采用back propagation的方法,运用梯度下降法对整个DBNs进行优化。
这个基于贪婪的学习方法无论是在预训练还是微调阶段在时间复杂度上和空间复杂度上均是线性的。所以在进行大规模数据的学习时,这个方法是非常有效的。
2 实例结果及结论
在实验中选取样本库中手写体数字进行训练及测试,实现分类预测,表1为选取样本数。分别根据每个数字的训练集进行训练,使用测试集测试效果,对于每种数字识别正确率如表2。

表1 训练样本数及测试样本数

表2 实验识别结果统计 %
从实验结果可看出,SVM算法优于BP神经网络算法,识别效果大幅度提高,而Deep Learning算法又在SVM算法的基础进一步提高,达到98%以上,识别效果令人满意。
3 结语
深度学习算法的优越性逐步在被发掘,在数字识别领域已经达到一个高度,同时其推广程度相当高,还可以使用在手写汉字系统、图片收索引擎等方面具有巨大的发展潜力。
参考文献:
[1]陈军胜.组合结构特征的自由手写体数字识别算法研究[J].计算机工程与应用,2013,49(5):179-184
[2]吴忠,朱国龙,黄葛峰,等.基于图像识别技术的手写数字识别方法[J].工业控制计算机,2011,21(12):48-51
[3]石会芳,胡小兵,刘瑞杰,等.基于启发式GA-SVM的手写数字字符识别的研究[J].计算机技术与发展,2012,22(10):5-9
[4]石会芳.支持向量机及其在手写数字识别中的应用[D].重庆:重庆大学,2013
[5]HINTON G.A Practical Guide to Training Restricted Boltzmann Machines[J].Report of Momentum,2010,9(1):1-20
[6]LIU J S.Monte Carlo Strategies in Scientific Computing[M].Berlin Heidelberg:Springer Verlag,2008
[7]BENGIO Y,LAMBLIN P,POPOVICI D,et al.Greedy Layer-wise Training of Deep Networks[J].Advances in Neural Information Processing Systems,2007,19-153
Research on the Classification of Handwriting Number
Based on Deep Learning
SONG Zhi-jian1,YU Rui2
(1.School of Computer science and technology,Chongqing Jiaotong University,Chongqing 400074,China; 2.School of transportation,Chongqing Jiaotong University,Chongqing 400074,China)
Abstract:It is difficult to recognize handwriting number,because writing styles are different,context is free and recognition requires high accuracy.According to the characteristics and requirements of handwriting number recognition,this paper uses the Deep Learning algorithm for classification,based on the sample of training to recognize the handwriting number.
At the same time,the experiment compared the classification effect with that of SVM algorithm and BP neural network.The experimental results show that the Deep Learning of handwriting number in recognition has a higher accuracy.
Keywords:handwriting number recognition; Deep Learning; sample training
中图分类号:O224
文献标志码:A
文章编号:1672-058X(2015) 08-0049-05
doi:10.16055/j.issn.1672-058X.2015.0008.011
收稿日期:2014-10-21;修回日期:2014-12-11.
*基金项目:重庆市自然科学基金计划项目(CSTC2011jjA0893).
作者简介:宋志坚(1990-),男,内蒙古包头人,硕士研究生,从事机器学习研究.
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27
中国远程教育(2016年11期)2016-12-27
现代商贸工业(2016年25期)2016-12-26
江苏教育·中学教学版(2016年11期)2016-12-21
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
考试周刊(2016年94期)2016-12-12
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
