
不确定数据集的模式挖掘
2015-05-12 09:41陈凤娟
商丘师范学院学报 2015年12期
陈凤娟
(辽宁对外经贸学院 基础教研部,辽宁 大连 116052)
不确定数据集的模式挖掘
陈凤娟
(辽宁对外经贸学院 基础教研部,辽宁 大连 116052)
在传统的事务数据库中,频繁模式的挖掘是一个已经有很多较好解决办法的问题,但是在不确定数据集上,仅仅提出了几种频繁模式的挖掘技术,而这些新技术对于不确定数据集中的项的不确定性的处理效果不是很好.本文主要探讨在可能世界的概念下,用基于抽样的方法来处理不确定数据,并在此基础上,研究在保证较低的精度损失下优化频繁模式挖掘算法.
不确定数据集,模式挖掘,期望支持度
0 引 言
关联规则分析是数据挖掘的最重要工作之一,它最早的应用在购物篮分析中.一个事务数据集包含很多的事务,而每一个事务由多个项组成,每个项表示一个顾客在每次购物中购买的商品[1].事务数据库被用来发现不同项集之间的关联,以便发现顾客的购买规律,为销售商的销售决策提供建议.关联规则分析的一个最关键、最重要的步骤就是挖掘频繁模式.
在频繁模式挖掘中,事务数据集通常用一个二元矩阵来表示,其中,矩阵的每一行表示一个事务,而每一列表示事务中出现的一个项.矩阵中的一个元素Mij的值是1或0,分别表示项j在事务i中出现和不出现.在这种基本的事务数据模型中,一个项在一个事务中,要么出现,要么不出现,没有其他可能.相对于不确定数据集,这种数据库也称为确定数据库.在确定数据库中挖掘频繁模式的方法已经提出了很多,它们使用多种方法对事务数据库进行模式挖掘.
但是,在很多应用中,一个项在一个事务中不是出现或不出现,而是用一个存在概率来表示该项在该事务中出现的可能性大小.例如,实验测量搜集的数据,或用传感器采集的数据,它们都存在着不确定性.从这类具有不确定数据中挖掘频繁模式是比从传统的确定事务数据库中挖掘频繁模式要困难的工作.因为,对于每个项,我们无法确定它在数据集中是否出现,只知道其出现的可能性大小.如果把原来的二元矩阵变成一个概率矩阵,即原来用0或1表示项的出现情况,现在用其对应的概率值来表示,把这种矩阵模型称为不确定数据模型.
本文主要研究从不确定数据集中挖掘频繁模式的方法,根据由项在事务中出现的可能性组成的矩阵,由统计学的一些概率分布规律,探讨在抽样的基础上,挖掘出不确定事务数据集中的频繁模式,并尽量控制由抽样导致的数据精确度降低问题,保证算法的效率的同时,也不降低挖掘结果的精确度.
1 可能世界与期望支持度
在确定数据库中,项在事务中出现的个数可以用支持度来表示,只要对数据库进行一次扫描,就能统计出项的支持度.而在不确定数据集中,无法明确的知道项是出现还是不出现,因此,原有的计数方式就无法使用了.在项的统计独立假设的前提下,数据集中所有事务的项可以用新的计数方法来表示,即期望支持度,它是基于可能世界对于不确定数据库的解释得出的支持度.
对于任意给定的一个项x和每一个事务t,存在两个可能世界的集合,一个集合中的所有可能世界,x在t中出现,另一个可能世界的集合中,x在t中不出现.第一类可能世界的集合的概率由x在t中出现的存在概率P(x,t)来给出,而另一类可能世界的集合的概率由1-P(x,t)来给出.一个单个的可能世界的概率P(W)是通过将该世界中所有的项的存在概率与该世界中不存在的项的1-其存在概率相乘得到的[2].
通过不确定数据和可能世界的分析,可以用可能世界来表示项集X的支持度.给定一个可能世界Wi和一个项集X,定义P(Wi)是可能世界Wi的概率,而S(X,Wi)是项集X在可能世界Wi中的支持度,Ti,j表示可能世界Wi中的第j条记录Tj包含的项集.假设记录中的项的概率是通过独立观察得到的,那么可能世界Wi的概率和项集X的期望支持度可以通过下面的两个公式得到.
(1)
(2)
其中,W是从不确定数据集D得到的所有可能世界的集合.
使用上面的公式来计算Se(X)需要穷举所有的可能世界,并计算项集X在所有可能世界中的支持度.因为可能世界的个数是2m,其中,m是不确定数据库D中所有记录中出现的所有项的总和,所以用这个公式来计算Se(X)是不可行的.因此,可以用下面的公式来计算Se(X)[3].
(3)
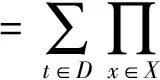
2 不确定数据集的抽样
为了分析不确定数据集,首先把不确定数据集与抽样建立联系,这种联系是依据数据集中给定的存在概率来建立的.对于每个事务t和事务t中的每个项i,生成一个独立的随机数r,并且r∈[0,1],然后把r和项i的概率值p进行比较.如果p≥r,那么项i就在当前的抽样事务中出现,否则,项i在当前的抽样事务中就不出现.对于不确定数据集中的每一条事务,重复上面的步骤n次,n是给定的一个常数.这样得到的数据集就是一个确定数据集,就可以使用现有的确定数据集的挖掘方法来挖掘.但是为了估计一个项集在不确定数据集中的支持度,由上面方法得到的抽样数据集中,该项集的支持度计数需要除以n.
这种抽样的方法物理上实例化了不确定数据集,并对其进行存储,但是在实例化的过程中,把该数据集放大了n倍,这样就需要更多的存储空间.但是,对于大多数有效的模式挖掘算法,不需要去实现这个抽样数据集.毕竟,大多数有效的技术只从磁盘读取数据集一次,之后,可以用高效的数据结构把数据集放入内存.所以,在数据集首次从磁盘读入内存时,可以立即在内存中生成抽样[4].
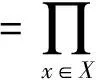
E[S]=expSup(X)
因此,和S是期望支持度的一个近似的无偏估计,并且其方差随n值的增加而线性递减.使用Hoeffding不等式,可以得到给定误差率时,需要抽样的数据集的个数,即n的个数.当数据集D包含10万条概率事务时,对于一个项集X,为了获得99%的X支持度的近似值,即只有1%的误差,我们需要近似抽样一个数据集D的实例.
3 频繁模式挖掘
在传统的确定数据库中,有多种有效的技术可以挖掘频繁模式,其中,FP-Tree采用了前缀树的结构存储事务,并使用前缀树结构提出了PF-Growth[5]算法,而hyper-linkedarray结构被用于构造H-mine算法[6],最简单应用也最广的是Apriori算法,它采用宽度优先的方法,思路简单,不需要额外的存储结构.但是这些方法都不能直接应用于不确定数据集.因此,不确定数据集上的频繁模式挖掘需要在原有的传统的方法的基础上进行改进,以实现对概率模型数据的挖掘.
U-Apriori是一个基于Apriori算法的不确定数据集频繁模式挖掘算法,但是由于它在生成候选集和对候选集进行测试时,需要不断的扫描数据集,因此算法的可扩展性不是很好.UCP-Apriori算法是基于增量剪枝技术的算法,它在扫描数据集时动态地构成一个支持度的上界并不断的更新这个上界.只要项集的最大的可能值低于阈值,这个项集就被剪枝[7].这种方法提高了Apriori类的不确定频繁模式挖掘的效率.
UF-growth算法是扩展FP-growth算法而来的不确定数据中的频繁模式挖掘算法.它基于一种类似FP-tree的结构UF-tree数据结构,把不确定数据集用该结构进行存储.在UF-tree结构中,只有当一个事务中的项和项的期望支持度都与树中的结点相同,二者才合并为一个结点,这就导致UF-tree的树结构的压缩性很差[8].提高树的存储压缩性,可以用离散化期望支持度来避免很多不同的期望支持度.另外,还有一些扩展已有的经典频繁模式挖掘算法,来实现对不确定数据集的频繁模式挖掘的方法,如UH-mine算法.这些算法仍然存在它们在确定数据库中存在的问题,而且,在不确定数据集中,计算量要远远大于确定数据集.
根据抽样的方法,可以把Eclat算法修改为U-Eclat算法[9],实现对不确定数据集的模式挖掘.U-Eclat算法基于Eclat算法,在第一次扫描数据集时,相关的项及其出现的事务表都被存储在内存,称为tid-list结构.然后用深度优先搜索策略生成候选集,并通过对它们子集的tid-list进行交运算,得到它们的支持度.U-Eclat算法的扩展主要在于读不确定数据集中的事务然后把它们按照抽样的方法进行实例化.具体地说,就是给定一个具体的n值,对每条事务t和事务中的每个项i,生成n个在0和1之间的独立随机变量,然后把这n个随机变量与项i的概率值p相比较,如果该随机变量大于概率p,则该事务出现在项i的tid-list中,如果该随机变量不大于概率值p,则该事务不出现在项i的tid-list中.得到新的抽样数据集后,就在上面运行Eclat算法,挖掘出频繁模式.
4 结束语
不确定数据集中的频繁模式挖掘是很多数据挖掘工作的基础,采用抽样的方法实例化不确定数据集,能保证挖掘需要的精度,同时不需要对已有的传统算法进行大量的修改,减少了算法的计算工作量.
[1]AgrawalR,ImielinskiT,SwamiAN.Miningassociationrulesbetweensetsofitemsinlargedatabases[M].SIGMOD, 1993.
[2]BenjellounO,SarmaAD.ULDBs:Databaseswithuncertaintyandlineage[M].VLDB, 2006.
[3]ChuiC,KaoB,HungE.“Miningfrequentitemsetsfromuncertaindata[M].PAKDD, 2007.
[4]CaldersT,GarboniC,GoethalsB.Efficientpatternminingofuncertaindatawithsampling[M].PAKDD, 2010.
[5]HanJ,PeiJ,YinY.Miningfrequentpatternswithoutcandidategeneration[M].SIGMOD, 2000.
[6]AggarwalC,LiY,WangJ.Frequentpatternminingwithuncertaindata[M].KDD, 2009.
[7]ChuiC,KaoB.Adecrementalapproachforminingfrequentitemsetsfromuncertaindata[M].PAKDD, 2008.
[8]AggarwalC,YuP.Asurveyofuncertaindataalgorithmsandapplications[J].IEEETKDE, 2009,21(5).
[9]MohammedJ.Zaki,SrinivasanParthasarathy,etc.Newalgorithmforfastdiscoveryofassociationrules[M].KDD, 1997.
[责任编辑:王军]
Pattern mining of uncertain datasets
CHEN Fengjuan
(Basic Teaching and Research Section,Liaoning University of International Business and Economics, Dalian 116052,China)
Mining frequent pattern from transactional datasets is a popular problem which has some good algorithmic solutions.In the case of uncertain datasets, however, several new techniques have been proposed.Unfortunately, these proposals often suffer when a lot of items occur with many different probabilities.In this paper, we focus on the method based on sampling by instantiating possible worlds of the uncertain data.Then we study the optimized frequent pattern mining algorithm which gains efficiency at a surprisingly low loss in accuracy.
uncertain dataset;pattern mining; expected support
2015-10-08
陈凤娟(1979-),女,辽宁本溪市人,辽宁对外经贸学院副教授,硕士,主要从事数据挖掘、无线传感器网络的研究.
TP311.12
A
1672-3600(2015)12-0016-04
猜你喜欢
中国交通信息化(2022年10期)2022-11-17
中学生数理化·中考版(2022年6期)2022-06-05
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
河南水利年鉴(2020年0期)2020-06-09
天津科技大学学报(2018年4期)2018-08-22
长春大学学报(2013年8期)2013-06-21
中南民族大学学报(自然科学版)(2011年2期)2011-02-07
网络安全与数据管理(2010年1期)2010-05-18
