
面向军事特种医学深网信息的自动获取技术研究
2015-05-07 07:48仇顺海
海军医学杂志 2015年3期
杨 柳,仇顺海
互联网上存在的国外军事特种医学研究信息具有一定的保密性和时效性,采用简单搜索方式难以查取。因信息大多在深网中存在,采用人工跟踪和捕获的方式耗费时间多,数据初加工的人力消耗大,不利于数据的长期积累。
1 研究背景
由于科研任务的需要,笔者在开展网上特种医学资源研究时接触到大量处于网站深层结构中的拒绝链接或未被链接的“孤岛网页”、动态网页等深网数据。这些网页因隐藏的专业数据数量多,且发展速度快,成为重要的网络数据来源。据统计,大约一半的军事医学研究类数据存在于主体明确的网络数据库中,其中,部分隐蔽数据难以通过普通搜索引擎但可以通过相关技术手段追踪获取[1]。
由于深网数据数量多、链接层次深,利用传统人工追踪和获取方式进度慢,人力和物力消耗大,不利于深网信息的长期提取。针对此特点,笔者提出利用已较为成熟的计算机技术和信息技术,研究适用于深网的信息抽取和索引方法,以形成对信息资源自动捕获的数据建构模式。
2 面向深网资源的信息抽取与分类技术研究
笔者以实现深网信息自动化获取为研究目标,从面向深网资源的搜索提取方法、面向实体层Web的信息索引和分类技术、面向用户的信息检索平台建设3个技术层面展开研究,有计划地将大量无序的特色网络资源实现自有化并得以快捷利用。
2.1 基于半监督顺序回归模型的爬虫算法 在资源搜索方面,将搜索目标设定为通常无法订购但军事特种医院特点鲜明的特色资源。通常,这些网络资源都是以深网的方式存储,并且无法直接获取。为此,笔者研究了面向深网的信息提取技术,研究并实现了一种面向军事特种医院资源的基于半监督顺序回归模型的快速爬虫算法[2]。
此算法主要包括以下3个步骤:首先,根据军事特种医院网站资源的特点,利用半监督顺序回归的方法构造深网页面分类器,定义所需的主题相关的网页分为N个不同的层次。此时层次的数量级根据所给定网站资源特点设定。一般情况下,N≤4。其次,构造深网链接信息抽取器,抽取对应N层次的有效链接。在提取这些链接信息时,采用多线程的方法完成。最后,把深网页面分类器的分类作为指导,形成特征库,利用让爬虫自动提取满足要求的链接特征,快速实时地找到各层有效链接。
对于爬行过程而言,笔者具体采用如下方法:在开始爬行前,把预先定义的符合特种医院资源信息的种子放入最低层的链接队列中,链接信息提取器从深网页面中抽取满足特点规则的链接信息,包括链接的网址、页面标题,链接的锚属性等信息,并同时交付链接特征学习器。在链接特征学习器中,笔者将采用深度机器学习方法,将这些特征进行归类、分析。然后,按照上述方法,将所有N层队列中的链接进行爬行。对于同一层次的链接,根据预先定义的规则让距离网站主页近的链接先爬行。这样,既可以爬行到最佳的链接,又保证让所有的链接都被爬行到。系统运行结果表明笔者提出的爬行策略能够提取深网中有效链接的基本特征,并过滤掉无关链接,提高了爬虫的速度和准确度。
2.2 面向实体层Web的信息索引技术[3]采用高效的爬虫技术从Deep Web上抽取出的军事特种医院特点鲜明的特色资源之后,将其存储在本地数据库中。对于索引而言,由于军事特种医院信息的特色,其索引对象可表示为Web实体(Web Entity)。Web实体通常具有各种属性,并由属性进行描述。如海军信息、潜水艇实体,具有长、宽、重量、下水深度等属性,可以将军事特种医院信息划归为多种不同实体。
显然,进行实体搜索,索引的对象为实体而非页面,其索引域为实体的各个属性。用户进行检索时,搜索器根据搜索关键字来查询实体索引域,然后进行综合排序。基于此,笔者提出了一种基于迭代和组合的信息抽取方法,实现Web实体的信息抽取及其索引建立[4]。图1为整个基于迭代和组合的信息抽取和索引方法实现框架图。为实现此信息抽取方法,首先生成简单的页面索引。页面层的索引技术,主要采用基于关键字的倒排排序方法,然后再对其按实体关键属性进行分类。其次,采用学习和深度搜索的方法抽取基本实体属性信息。在该过程,首先利用基于反馈的条件随机域模型来抽取实体的属性信息,之后通过快速排序及其深度搜索方法穷尽搜索包含某些特定实例的所有页面集。采用基于反馈的条件随机域模型的基本思想是先从已有的实体集中构造训练数据集,采用预先定义的规则对训练数据集中的页面进行有条件的标注,然后进行模型训练[5]。在训练中,笔者采用基于反馈的方式进行,即通过已有的训练结果对训练模型进行反馈,提高训练的速度和效率,最终使得抽取精度较高。最后,在迭代抽取和组合集成过程中,采用方法的基本原理是[6]:对所有的待抽取页面集,进行用户交互定义的页面快速分割,将页面分割成多个不同的部分。然后,根据实体模型,对于还未抽取的相关实体属性,采用上述的抽取方法进行迭代抽取,并将抽取的数据结果集成在一起,最后构成一个完整可信的信息实体。

图1 基于迭代和组合的信息抽取和索引方法
2.3 面向用户的分布式信息检索平台建设 在此分布式信息检索平台建设中,根据用户的需求,采用上述相关关键技术,设计了一个面向用户的分布式信息检索平台。本平台的后端服务器采用主从分布式架构,总体架构如图2所示。
本检索平台由3个主要部分构成,分别为:总体控制服务器、半监督顺序回归爬虫服务器和迭代与组合实体索引检索服务器。其中,总体控制服务器主要负责整个爬虫系统的整体控制管理、各个服务器之间消息的发送、传递以及任务的分配等等;半监督顺序回归爬虫服务器主要负责爬行深网,下载军事特种医院信息网页,并抽取网页中包含的各种实体信息;索引检索服务器主要负责接收采集到的特种医院军事等实体信息,并以建立索引,为用户提信息搜索等服务[7]。
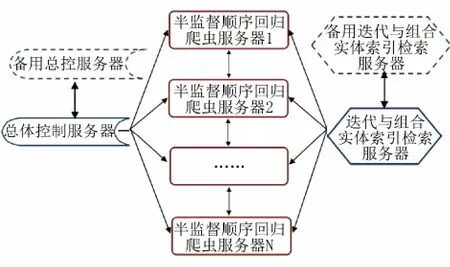
图2 分布式信息检索平台后端服务器
此外,为了保证系统运行的可靠性,总体控制服务器和迭代与组合实体索引检索服务器均采用了双机热备份的方式,以维护服务器和对应的备用服务器之间数据的同步。本系统中的控制服务器是采用按用户指定的静态任务分配模式来进行网页采集,所以控制服务器和它的备用服务器之间的通信量不会太大,之间的数据同步压力并不大,从而可以解决主从式分布爬虫系统中控制服务器的效率瓶颈问题。
综上所述,采用基于顺序回归模型的爬虫方法,跟踪搜集获取深网中不定期发布的各类难以获取的专业文献信息,准确度和时效性均高于利用人工进行数据筛选的方式;采用基于迭代和组合的信息抽取和索引方法,结合面向军事特种医学学科的网络实体信息分类技术,可以实现专业文献分类架构及其专业分类简表的构建,获取数据的基本属性识别率达到85%以上。结合上述关键技术,可有效提高构建基于深网信息的军事特种医学全文数据信息检索平台的速度。
[1] 宋晖,张岭,叶允明,等.基于标记树对象抽取技术的Hiddenweb获取研究[J].计算机工程与应用,2002,38(23):9-12.
[2] 郑冬冬,赵朋朋,崔志明.DeepWeb爬虫研究与设计[J].清华大学学报:自然科学版,2005,45(51):1896-1902.
[3] Barbosa L,Freire J.An Adaptive Craw1er for Locating Hidden Web Entry Points[C].In Proeeedings of WWW,2007:441-450.
[4] 高岭.Deepweb分类搜索引擎关键技术研究[D].苏州:苏州大学,2007.
[5] Panagiotis G Ipeirotis,Luis Gravano.C1assification-aware hiddenweb text Database se1ection[J].ACM TOIS,2008,26(2):1-48.
[6] Jayant M,David K,Lucja K.Goog1e's Deep-Web Craw1[C].In Proceedings of the VLDB,2008.
[7] 王娜,常珍珠.泛在网络中信息资源管理的国内外研究综述[J].图书馆学研究,2014,14(1):13-18.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
小学科学(学生版)(2021年2期)2021-03-29
军民两用技术与产品(2021年10期)2021-03-16
成都信息工程大学学报(2021年6期)2021-02-12
今日农业(2019年14期)2019-09-18
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2018年2期)2018-04-18
农村百事通(2017年9期)2017-07-07
