
基于观点袋模型的汽车评论情感极性分类
2015-04-21 08:43王素格李德玉
中文信息学报 2015年3期
廖 健,王素格,2,李德玉,2,张 鹏
(1. 山西大学 计算机与信息技术学院,太原 030006;2. 山西大学 计算智能与中文信息处理教育部重点实验室,太原 030006)
基于观点袋模型的汽车评论情感极性分类
廖 健1,王素格1,2,李德玉1,2,张 鹏1
(1. 山西大学 计算机与信息技术学院,太原 030006;2. 山西大学 计算智能与中文信息处理教育部重点实验室,太原 030006)
该文针对网络评论倾向分级问题,提出了一种基于观点袋模型和语言学规则的多级情感分类方法。通过分析句子中的词性搭配关系,设计了12种抽取特征-观点搭配模式,并对存在问题给出了解决策略。依据汉语用词特点和词汇在汽车领域的特殊用法,提出搭配四元组的情感倾向极性值计算方法。在此基础上,利用获取的搭配四元组及其情感倾向极性,建立文本的向量化表示,并构造了权重计算公式。最后,利用文本余弦相似度计算方法实现对评论文本的五级情感极性分类。通过在COAE2012任务3的汽车数据集上进行的测试,取得了较好的分类结果。
情感分类;观点袋模型;词性搭配
1 引言
随着互联网的快速发展,普通网络用户已经从单纯的信息接受者逐渐变成信息生产者,各类微博、论坛、电商中存在大量具有评论性和主观倾向性的文本,例如商品评价、跟帖等。据统计,44%新闻文本包含观点信息[1]。通过分析商品评论,可以让普通用户更容易了解某些产品的主流市场评价,方便用户做出更正确的消费决定,对商家而言,也能利用这类结果来获得最直观的市场反馈,据此做出更有针对性的市场决策。
篇章级文本通常包含了作者的多种观点,特别是关于产品的评论可能涉及到产品的多个方面,这些方面的倾向性有时并不一致。例如,“路虎的动力强劲,但油耗太大。”,分别从动力和油耗两个方面表达了完全相反的情感倾向。因此,综合考虑产品的各方面的评价观点是进行篇章级文本的倾向分类研究的基础。
搭配通常被认为是一种具有任意性和可重复性的词语组合[2-3],大量的研究表明,搭配是一种行之有效的文本表示形式[4-5]。Qu等人[6]提出了观点袋(bag-of-opinions)模型对商品评论自动进行评价极性分类,他们将文本转化成基准词(root word)与修饰词(modifier word)的搭配,并使用岭回归(ridge regression)模型对每个观点词进行打分,但仅考虑到了否定副词对情感搭配的反转作用,没有考虑到程度副词对于情感极性的影响。Thet等人[7]使用句法依赖将句子转换为子句,通过构造一系列规则计算各子句的情感极性,依照子句归属计算各方面极性值,他们据此构造分类器对电影评论文本分类,取得理想的效果。王素格等[8]提出了一种混合语言信息的词语搭配的倾向判别方法,她们使用词性匹配模式抽取词语搭配,总结出了六种搭配模式并确定各自的概率潜在语义模型,以此判别搭配的情感倾向。
第四届中文倾向性分析评测(COAE2012)[9]首次要求对于篇章的观点倾向极性进行打分。文献[10]利用篇章中正负面句子数将文本向量化表示后计算余弦相似度文献。文献[11]采用欠采样集成学习的方法,构建了SVM、朴素贝叶斯、最大熵三种分类器并予以综合。文献[12]基于语言学特征,重点关注了篇章中的归总句对篇章极性的影响。文献[13]通过建立情感词典和基于情感文本训练语料来获取句子中的情感要素,通过将单一情感要素和复合情感要素汇总计算,作为情感极性判断的依据。文献[14-15]均采用建立情感词典或观点词词典的方法,统计观点词的词频和极性。其中,文献[15]以特征-观点词对的形式表示文本,但没有更细致地考虑副词对极性的加强或减弱作用。同时,对于搭配的情感倾向仅考虑了观点词的极性,而没有对整个搭配进行综合考量。
本文对汽车领域的评论文本开展研究,利用已有的资源,建立了汽车方面特征词典和情感词词典。考虑了12种模式的词语词性搭配,利用建立的语言学规则自动对抽取出的搭配四元组进行极性分类,以此将特征值建立文本的向量化表示,并进行五级情感极性分类。
2 汽车评论文本搭配抽取
本文利用词语搭配模式抽取文本句子中特征、程度、观点、反转,以此建立四元组,其中,每个四元组表示一个观点,这样可对文本建立观点袋模型。
2.1观点袋模型
Qu等人[6]最早提出了观点袋(bag-of-opinions)模型,该文将文本表示成为(root,modifier,negator)三元组。在此基础上,本文考虑到汉语的用词特点以及副词对观点倾向的加强或减弱影响,将文本表示为特征-观点的观点袋模型,即
其中,opi表示第i个观点,用特征-观点搭配四元组表示,fei,cdi,seni,ndi分别为特征词、程度副词、情感词和否定副词。N表示每篇文本中特征-观点搭配四元组op的个数。
2.2 12种词性搭配模式
本文使用中科院ICTCLAS[16]对文本进行分词,利用文献[17]中的汽车领域中的特征词典,对特征词表进行重新绑定以降低分词错误对结果的影响,并将其词性标注为fe。在此基础上,本文依据词性设计了12种搭配模式。
对于二元搭配,文献[3]统计结果显示候选搭配词一般出现在目标词后三个词长度范围内。本文在此基础上,将模式进行了扩展,通过实验考察了词语之间窗口长度对情感词语搭配的影响。各搭配模式所对应的词窗口大小设置,如表1所示。

表1 情感搭配模式与窗口大小
其中,v、a、cd、nd分别表示动词、形容词、程度副词和否定副词。词窗口设置以特征词为基准向前、后各开辟三或五个词长。
2.3 最小支持度minsup
根据 2.2节设计的搭配模式,在抽取搭配过程中,对于出现频率极小的搭配四元组,本文认为其对文档的情感倾向极性分类的作用不大。主要原因: ①搭配四元组确实是出现次数比较低; ②由于网络不规范用语错误所致。因此,本文引入了最小支持度minsup对抽取的搭配四元组进行限制。对于搭配四元组opi,最小支持度计算见公式(1)所示。
(1)

2.4 模式存在的问题与解决策略
在抽取搭配四元组时,有时会遇到模式冲突和情感词并列的问题。针对这些情况,给出如下解决策略。
(1) 模式冲突
① 对于v+fe、a+fe、fe+a、fe+v四种不含副词的搭配模式,有时会出现与带有副词的搭配模式出现交集的情形。例如: “发动机非常好”按照模式fe+a可以抽出(发动机,null,好,null),而按照fe+nd+cd+a则会得到(发动机,非常,好,null)。
策略1: 当同一子句中出现特征词与情感词相同的短搭配和长搭配时,舍去短搭配。
② 对于同一句子中同一个特征词fe依表1中E+F和F+E类型均能抽取出搭配四元组。
策略2: 在保留最长搭配的前提下,使用公式(2)计算op中特征与情感词对(fe,sen)的互信息值,取互信息值最大的搭配作为该句子的抽取搭配四元组。

(2)
其中,p(fe,sen)和p(sen,fe)表示op中特征词与情感词对(fe,sen)和(sen,fe)同现的概率,p(fe)表示特征fe出现的概率,p(sen)表示情感词sen出现的概率。
(2) 模式中情感词并列
在汉语中,顿号“、”和“,”以及“和”,用于并列连用的单字、词语[18]。
策略3: 当多个特征词存在并列关系且搭配同一情感词,或是多个并列情感词均修饰同一特征时,分别抽取所有的特征与情感词搭配,而不受词窗口长度限制。例如: “驾驶很轻盈、很舒适”可以得到两个搭配四元组(驾驶,很,轻盈,null)和(驾驶,很,舒适,null)。
3 搭配倾向与情感分类
本文参考汉语词语搭配的特点,结合汽车领域内的特有形式,构造了一系列规则计算搭配四元组的情感极性值,以此计算特征权重将文本向量化表示,并进行情感极性分类。
3.1 建立情感词典与副词词典
本文通过构建情感词词典和副词词典为搭配四元组中的情感词和副词提供倾向极性,以便进行搭配四元组的自动情感倾向极性分类。
本文收集了汉语中常用的程度副词cd以及否定副词nd,建立了副词词典,共计196个。词典的构成如表2所示。
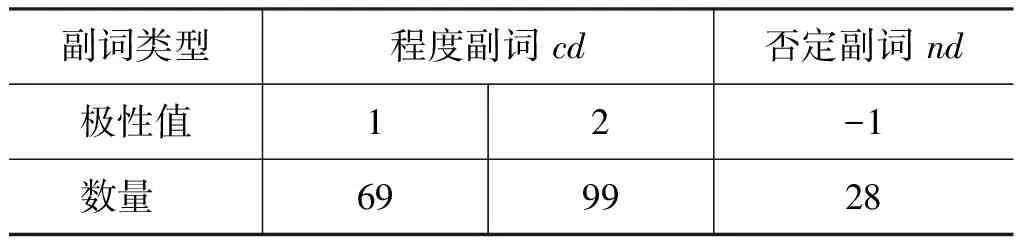
表2 副词词典
对于情感词词典,本文将山西大学中文评价词词表和大连理工大学信息检索研究室的情感词汇本体[19]合并建立情感词词典。词典规模如表3所示。

表3 情感词词典构成
3.2 搭配四元组的情感倾向极性
3.2.1 特征词与情感词分类
本文使用文献[17]中的汽车领域特征词作为本文的特征词典。并对其进行如下处理。
(1) 特征词分类
在汉语中,有些词带有明显的情感倾向,而有些词语尽管本身是中性的,但在特定的语境中搭配上带有情感倾向或中性的其他词语时,亦可表现出情感倾向[3]。我们分析了汉语用词特点,并考虑了汽车领域的一些特殊用法,本文使用的特征词分类如表4所示。

表4 各类型特征词集的规模
(2) 情感词分类
对于一些描述物体的物理性质的中性情感词,虽然其本身并不具备情感倾向,但与不同的特征词搭配会出现截然不同的情感倾向。本文选取了文献[20]中归纳的部分中性形容词,将最常见的12种中性词单独列出处理,即描述物体的体积、面积、长度、质量、数量等物理性质的,表达“大”、“小”、“高”、“低”、“长”、“短”、“软”、“硬”、“轻”、“重”、“多”、“少”这12种概念的词语,并扩展加入了这些形容词的比较级和最高级形式。对这12种中性词,再将其分为四类,如表5所示。

表5 各类型情感词集的规模及其情感极性值
3.2.2 搭配四元组的情感倾向计算
为了计算搭配四元组op的情感极性值,假设s(op),s(cd),s(nd),s(sen)分别表示搭配四元组op、程度副词cd、否定副词nd以及情感词sen的情感极性值,当程度副词或否定副词出现缺省时,极性值默认值为1。对于特征词和情感词的不同类别,分三种情况计算搭配四元组op的情感极性值。
① 若op中的fe∈Sr且sen∈Snp1∨sen∈Snp2∨sen∈Snn1∨sen∈Snn2,则
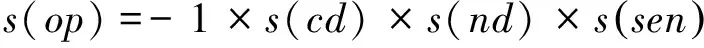
这类特征词可与“大”、“高”等概念的中性情感词搭配时具有极性反转作用,例如,
s(油耗,很,高,null)=-1×s(很)×s(null)×s(高)= -1×2×1×1= -2;
② 若op中的fe∈Sd且sen∈Snp1∨sen∈Snp2∨sen∈Snn1∨sen∈Snn2,则
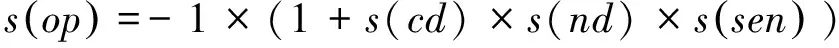
这类特征词的出现通常意味着贬义倾向,且同样对表示“大”、“高”等概念的中性情感词具有反转作用,例如,
s(侧倾,非常,大,null)=-1×(1+s(非常) ×s(null) ×s(大))=-1×(1+(2×1)×1)=-3;
③ 若op不满足①和②的条件时,则
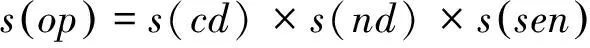
这类搭配四元组的情感极性主要由情感词sen和副词搭配决定,例如,
s(内饰,null,漂亮,不)=s(null)×s(不)×s(漂亮)= 1×-1×1= -1。
对于搭配四元组op,为了使最终情感极性值满足s*(op)∈{-2,-1,0,1,2},我们使用公式(3)对s(op)进行修正。
(3)
3.3 文本情感极性分类过程
(1) 文本表示
通常的文本分类问题将文本表示成特征为分量的向量空间模型。对于第i篇文本Di向量化表示为:
N表示特征词总数,这里wik表示第i篇文本的第k个特征feik的权重。当一个特征feik存在多个搭配时,采用各搭配的情感极性值的算术平均值作为feik的情感极性值。其权重wik计算见公式(4)。
(4)

(2) 缺省值的补充
当有些特征在某些篇章中缺失时,说明作者并未对该特征发表自己的看法,因此,不能简单将其倾向极性赋为0值。本文依据训练集中其他文档的对应倾向极性,将同一极性值下的所有文档用于对这类缺失特征值进行补充。
当s(feik)=0时,使用如下公式(5)~(7)对其进行缺省值补充。
(5)
(6)
(7)

对于测试集中的文本极性值为0的特征项,使用测试集中全部文档的该特征项非0项的均值作为该特征极性值的补充。
(3) 文本相似度计算
为了对文本进行情感极性分类,本文使用了文本相似度方法。对于训练集中第c类文档集的类中心的第k个特征词feck,其权重计算见公式(8)。
(8)
利用公式(8),得到第c类中心文档如下:

(9)
其中,wik表示第i篇文档的第k个特征的权重。
4 实验结果及分析
4.1 实验数据与评价指标
本文使用COAE2012任务3的汽车语料作为实验数据,共计8 000篇。其中,训练集3 000篇,测试集5 000篇。分析发现,评测数据存在较严重的不平衡性,训练集和测试集中中性文档即极性值为3的文档分别占总体的71.8%和72.96%。实验过程中我们也发现,数据的这种不平衡性将对结果产生一定负面的影响。
本文使用COAE2012任务3使用的两个指标进行结果评价: 精确率(accuracy)以及平均均方错误率(Mean Square Error,MSE)。accuracy和MSE的计算方法如公式(10)及(11)所示。
(10)
(11)
公式(10)中,accuracy为分类正确的文档数与测试集文档总数的比值。公式(11)中,N表示测试样本总数,i表示样本编号,answeri表示答案中的每个样本的打分,resulti为提交系统的答案中每个样本的打分。
4.2 实验结果及分析
对于文本情感极性分类,按照3.3节文本情感极性分类过程,我们进行了如下实验。
实验1: 最小支持度阈值确定
本实验利用第2.2节设计的搭配四元组抽取模式,以及第2.3节构造的最小支持度minsup,选取了minsup在[5.0E-4,4.5E-3]之间跨度为2.0E-4的21个值分别对测试集文本进行情感搭配抽取并进行文档倾向极性分类,实验结果见图1、2。
(1) 图1随着minsup的增加,抽取的搭配四元组越来越少,minsup的取值与抽取出的搭配四元组数目成反比。当在minsup≤5.0E-4时与不引入minsup进行限制相比较,抽取出的搭配数完全一致,

图1 minsup的不同取值对搭配抽取的影响

图2 极性分类实验结果
因此本文以5.0E-4作为minsup起始取值。而当minsup值大于0.002 7时,抽取出的搭配四元组已不足5 000个,对部分文档而言,搭配四元组已无法刻画其整体情感极性倾向。
(2) 图2是在minsup取不同值下抽取的21组搭配集合,分别对文档进行情感极性分类的结果。在minsup=0.000 9时,情感极性分类达到最佳效果。当minsup取值过小时,抽取的搭配四元组包含大量无用或者无意义的搭配四元组,对准确刻画文档情感倾向产生了干扰效果。当minsup大于 0.002 7 后,由搭配四元组刻画的文档的情感倾向将随着minsup的增大趋向于中性即极性值为3,但由于数据较为严重的不平衡性,整体结果最终会稳定在72.96%,即全部分类至第三类中。
实验2: 与COAE2012文档倾向极性分类其他结果的比较
根据实验1中各种最小支持度得到的分类结果,本实验选取minsup=0.000 9,与COAE2012其它文档倾向极性分类结果相比较,实验结果见表6。
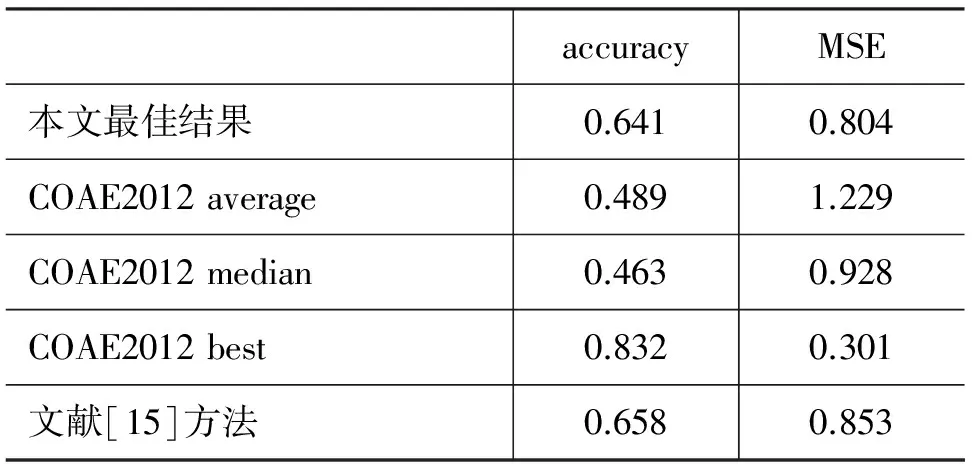
表6 实验结果与COAE2012其他结果的比较
由表6可以看出,COAE2012 best>文献[15]方法结果>本文最佳结果>COAE2012 average>COAE2012 median,本文的方法处于中上水平。
通过分析各参评单位在COAE2012该任务中取得的结果,取得最好成绩的是中国传媒大学[12],他们利用了篇章中归总句的特性进行了分类,通过加大篇章中归总句的权重对篇章进行打分。文献[15]采用的特征-观点表示方法与本文类似,其accuracy结果与本文最好结果近似,但本文的MSE值较低,表明本文方法分类错误的偏离程度较小,且本文无需训练分类器,所采用的特征词表规模较文献[15]的小,在低维特征下依然能对文本的情感进行较准确的刻画,显示出本文的方法具有一定的可行性与有效性。
5 结束语
本文考察了词性间的搭配关系,设计了12种词性搭配模式。对于不同类型的词汇在特定领域下的特殊表达,设计了一系列的规则函数自动对抽取出的搭配四元组进行情感倾向极性分类。为了从篇章级文本中抽取特征-观点搭配四元组并建立观点袋模型,过滤掉一些无意义搭配,引入最小支持度minsup对抽取搭配进行限制,通过考察所有minsup取值对情感搭配关系抽取以及情感倾向极性分类的影响,确定minsup的最优取值。为了检验本文的方法对篇章级文本情感极性分类的有效性,使用了COAE2012任务3的汽车语料。利用训练集生成其类别中心文档,在测试集上分别与各类别中心文档计算余弦相似度,将测试集文档分类到最相似的类别中。与COAE2012评测结果相比较,本文的方法处于中上水平,显示其具有一定的可行性和有效性,然而本文的方法需要使用已有的领域本体特征,抽取的情感搭配无法覆盖全部的文档,同时没有考虑归总句对篇章极性的影响。因此,如何自动建立领域本体知识库,引入对归总句权重影响的研究,并对搭配模式进一步细化将是我们今后深入研究的课题。
[1] Wiebe J, Bruce R, Bell M, et al. A corpus study of evaluative and speculative language[C]//Proceedings of the 2nd ACL SIGdial Workshop on Discourse and Dialogue. USA: ACL, 2001: 1-10.
[2] Xia Y Q, Xu R F, Wong K F, et al. The unified collocation framework for opinion mining[C]//Proceedings of Machine Learning and Cybernetics, 2007 International Conference on. IEEE, 2007, 2: 844-850.
[3] 王素格. 基于 Web 的评论文本情感分类问题研究 [D]. 上海: 上海大学, 2008.
[4] Smadja F. Retrieving collocations from text: Xtract[J]. Computational linguistics, 1993, 19(1): 143-177.
[5] 王素格, 杨军玲, 张武. 自动获取汉语词语搭配[J]. 中文信息学报, 2006, 20(6): 31-37.
[6] Qu L, Ifrim G, Weikum G. The bag-of-opinions method for review rating prediction from sparse text patterns[C]//Proceedings of the 23rd International Conference on Computational Linguistics. Association for Computational Linguistics, 2010: 913-921.
[7] Thet T T, Na J C, Khoo C S G. Aspect-based sentiment analysis of movie reviews on discussion boards[J]. Journal of Information Science, 2010, 36(6): 823-848.
[8] 王素格, 杨安娜. 基于混合语言信息的词语搭配倾向判别方法[J]. 中文信息学报, 2010, 24(3): 69-74.
[9] 刘康, 王素格, 廖祥文,等. 第四届中文倾向性分析评测总体报告[C]//Proceedings of the COAE2012, Nanchang, China,2012:1-33.
[10] 唐都钰, 石秋慧,王沛,等. HITIRSYS:COAE2012情感分析系统[C]//Proceedings of the COAE2012, Nanchang, China, 2012: 44-52.
[11] 林莉媛, 苏艳,戴敏,等. Suda_SAM_OMS情感倾向性分析技术报告[C]//Proceedings of the COAE2012, Nanchang, China, 2012:69-76.
[12] 程南昌, 侯敏,腾永林,等. 基于文本特征的语篇倾向性分析研究[C]//Proceedings of the COAE2012, Nanchang, China, 2012: 89-94.
[13] 刘楠, 贺飞艳,彭敏,等. 基于情感要素的否定句极性判别方法[C]//Proceedings of the COAE2012, Nanchang, China, 2012: 123-131.
[14] 魏现辉, 任巨伟,何文泽,等. DUTIR COAE2012评测报告[C]//Proceedings of the COAE2012, Nanchang, China,2012: 34-43.
[15] 崔安颀, 张永锋,刘奕群,等. 基于情感词典的中文倾向性分析[C]//Proceedings of the COAE2012, Nanchang, China,2012: 118-122.
[16] 计算所汉语词法分析系统ICTCLAS. http://www.ictclas.cn/.
[17] 王素格, 尹学倩, 李茹, 等. 基于非完备信息系统的评价对象情感聚类[J]. 中文信息学报, 2012, 26(4): 98-102.
[18] 宁鸿彬, 徐同. 新颁《标点符号用法》通释[M]. 教育科学出版社, 1992.
[19] 徐琳宏, 林鸿飞, 潘宇,等. 情感词汇本体的构造[J]. 情报学报, 2008, 27(2): 180-185.
[20] 顾正甲, 姚天昉. 评价对象及其倾向性的抽取和判别[J]. 中文信息学报, 2012, 26(4): 91-97.
The Bag-of-Opinions Method for Car Review Sentiment Polarity Classification
LIAO Jian1, WANG Suge1,2,LI Deyu1,2, ZHANG Peng1
(1. School of Computer & Information Technology, Shanxi University, Taiyuan, Shanxi 030006, China; 2. Key Laboratory of Computational Intelligence and Chinese Information Processing of Ministry of Education, Shanxi University, Taiyuan, Shanxi 030006, China)
Focused on the online review sentiment polarity classification problem, a multi-level sentiment classification method is proposed based on bag-of-opinion model and a set of linguistic rules. According to the part-of-speech of each word in the sentences, 12 patterns are designed for the feature-opinion pairs’ extraction, which enable to represent the whole text in a series of four-tuple of “feature, degree word, opinion word, negation word”. After designing the estimation of the sentiment priority of the four-tuple, the cosine similarity is further adopted for a 5-level sentiment polarity classification. Experiments on the dataset from COAE2012 Task 3 car dataset indicate a good result compared to the performances of the other runs in COAE.
sentiment classification; bag of opinion; POS collocation
1003-0077(2015)03-0113-08
2013-04-08 定稿日期: 2013-07-31
国家自然科学基金(61175067,61272095); 山西省自然科学基金(2010011021-1,2013011066-4); 山西省科技攻关项目(20110321027-02);山西省留学基金(2013-014)
TP391
A
猜你喜欢
计算机系统应用(2021年9期)2021-10-11
韩国语教学与研究(2021年3期)2021-03-16
时代英语·高一(2019年5期)2019-09-03
娃娃画报(2019年8期)2019-08-05
天然产物研究与开发(2018年9期)2018-10-08
计算机技术与发展(2018年8期)2018-08-21
计算机应用与软件(2018年1期)2018-02-27
中国机械工程(2017年22期)2017-12-02
航天返回与遥感(2014年1期)2014-07-31
高中生学习·高三版(2014年3期)2014-04-29
